
Comience con Node: una introducción a las API, HTTP y ES6+ JavaScript
Publicado: 2022-03-10Probablemente haya oído hablar de Node.js como un "tiempo de ejecución de JavaScript asíncrono basado en el motor de JavaScript V8 de Chrome" y que "utiliza un modelo de E/S sin bloqueo y controlado por eventos que lo hace liviano y eficiente". Pero para algunos, esa no es la mayor de las explicaciones.
¿Qué es Node en primer lugar? ¿Qué significa exactamente que Node sea "asincrónico" y en qué se diferencia de "sincrónico"? ¿Cuál es el significado de "impulsado por eventos" y "sin bloqueo" de todos modos, y cómo encaja Node en el panorama general de las aplicaciones, las redes de Internet y los servidores?
Intentaremos responder a todas estas preguntas y más a lo largo de esta serie a medida que analizamos en profundidad el funcionamiento interno de Node, aprendemos sobre el Protocolo de transferencia de hipertexto, las API y JSON, y creamos nuestra propia Bookshelf API utilizando MongoDB, Express, Lodash, Mocha y Handlebars.
¿Qué es Node.js?
El nodo es solo un entorno, o tiempo de ejecución, dentro del cual se ejecuta JavaScript normal (con pequeñas diferencias) fuera del navegador. Podemos usarlo para crear aplicaciones de escritorio (con marcos como Electron), escribir servidores web o de aplicaciones, y más.
Con bloqueo/sin bloqueo y sincrónico/asincrónico
Supongamos que estamos haciendo una llamada a la base de datos para recuperar propiedades sobre un usuario. Esa llamada tomará tiempo, y si la solicitud está "bloqueando", eso significa que bloqueará la ejecución de nuestro programa hasta que se complete la llamada. En este caso, hicimos una solicitud “sincrónica” ya que terminó bloqueando el hilo.
Entonces, una operación síncrona bloquea un proceso o subproceso hasta que se completa esa operación, dejando el subproceso en un "estado de espera". Una operación asíncrona , por otro lado, es sin bloqueo . Permite que la ejecución del subproceso continúe independientemente del tiempo que tarde en completarse la operación o el resultado con el que se complete, y ninguna parte del subproceso cae en un estado de espera en ningún momento.
Veamos otro ejemplo de una llamada síncrona que bloquea un hilo. Supongamos que estamos creando una aplicación que compara los resultados de dos API meteorológicas para encontrar su diferencia porcentual en la temperatura. De forma bloqueada, hacemos una llamada a Weather API One y esperamos el resultado. Una vez que obtenemos un resultado, llamamos a Weather API Two y esperamos su resultado. No se preocupe en este punto si no está familiarizado con las API. Los cubriremos en una próxima sección. Por ahora, piense en una API como el medio a través del cual dos computadoras pueden comunicarse entre sí.
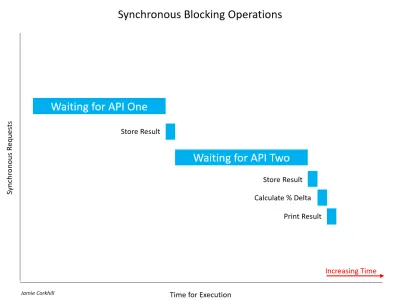
Permítanme señalar que es importante reconocer que no todas las llamadas sincrónicas necesariamente se bloquean. Si una operación síncrona puede lograr completarse sin bloquear el subproceso o causar un estado de espera, no fue un bloqueo. La mayoría de las veces, las llamadas síncronas se bloquearán y el tiempo que tarden en completarse dependerá de una variedad de factores, como la velocidad de los servidores de la API, la velocidad de descarga de la conexión a Internet del usuario final, etc.
En el caso de la imagen de arriba, tuvimos que esperar bastante para recuperar los primeros resultados de API One. A partir de entonces, tuvimos que esperar el mismo tiempo para obtener una respuesta de API Two. Mientras esperaba ambas respuestas, el usuario notaría que nuestra aplicación se bloquea (la interfaz de usuario literalmente se bloquearía) y eso sería malo para la experiencia del usuario.
En el caso de una llamada sin bloqueo, tendríamos algo como esto:

Puede ver claramente cuánto más rápido concluimos la ejecución. En lugar de esperar en API One y luego esperar en API Two, podríamos esperar a que ambos se completen al mismo tiempo y lograr nuestros resultados casi un 50 % más rápido. Tenga en cuenta que una vez que llamamos a API One y comenzamos a esperar su respuesta, también llamamos a API Two y comenzamos a esperar su respuesta al mismo tiempo que One.
En este punto, antes de pasar a ejemplos más concretos y tangibles, es importante mencionar que, para simplificar, el término "Synchronous" generalmente se abrevia como "Sync", y el término "Asynchronous" generalmente se abrevia como "Async". Verá que esta notación se usa en los nombres de métodos/funciones.
Funciones de devolución de llamada
Quizás se esté preguntando, "si podemos manejar una llamada de forma asincrónica, ¿cómo sabemos cuándo finaliza esa llamada y tenemos una respuesta?" En general, pasamos como argumento a nuestro método asíncrono una función de devolución de llamada, y ese método "devolverá la llamada" a esa función en un momento posterior con una respuesta. Estoy usando las funciones de ES5 aquí, pero actualizaremos a los estándares de ES6 más adelante.
function asyncAddFunction(a, b, callback) { callback(a + b); //This callback is the one passed in to the function call below. } asyncAddFunction(2, 4, function(sum) { //Here we have the sum, 2 + 4 = 6. }); Tal función se denomina "Función de orden superior" ya que toma una función (nuestra devolución de llamada) como argumento. De manera alternativa, una función de devolución de llamada podría tomar un objeto de error y un objeto de respuesta como argumentos y presentarlos cuando la función asíncrona esté completa. Veremos esto más tarde con Express. Cuando llamamos a asyncAddFunction(...) , notará que proporcionamos una función de devolución de llamada para el parámetro de devolución de llamada de la definición del método. Esta función es una función anónima (no tiene nombre) y está escrita utilizando la sintaxis de expresión . La definición del método, por otro lado, es una declaración de función. No es anónimo porque en realidad tiene un nombre (que es "asyncAddFunction").
Algunos pueden notar confusión ya que, en la definición del método, proporcionamos un nombre, que es "devolución de llamada". Sin embargo, la función anónima pasada como tercer parámetro a asyncAddFunction(...) no conoce el nombre, por lo que permanece anónima. Tampoco podemos ejecutar esa función en un punto posterior por su nombre, tendríamos que volver a pasar por la función de llamada asíncrona para activarla.
Como ejemplo de una llamada síncrona, podemos usar el método readFileSync(...) Node.js. Nuevamente, nos mudaremos a ES6+ más tarde.
var fs = require('fs'); var data = fs.readFileSync('/example.txt'); // The thread will be blocked here until complete.Si estuviéramos haciendo esto de forma asíncrona, pasaríamos una función de devolución de llamada que se activaría cuando se completara la operación asíncrona.
var fs = require('fs'); var data = fs.readFile('/example.txt', function(err, data) { //Move on, this will fire when ready. if(err) return console.log('Error: ', err); console.log('Data: ', data); // Assume var data is defined above. }); // Keep executing below, don't wait on the data. Si nunca antes ha visto return usado de esa manera, solo estamos diciendo que detenga la ejecución de la función para que no imprimamos el objeto de datos si el objeto de error está definido. También podríamos haber envuelto la declaración de registro en una cláusula else .
Al igual que nuestro asyncAddFunction(...) , el código detrás de la fs.readFile(...) sería algo así como:
function readFile(path, callback) { // Behind the scenes code to read a file stream. // The data variable is defined up here. callback(undefined, data); //Or, callback(err, undefined); }Permítanos ver una última implementación de una llamada de función asíncrona. Esto ayudará a solidificar la idea de que las funciones de devolución de llamada se activen en un momento posterior y nos ayudará a comprender la ejecución de un programa típico de Node.js.
setTimeout(function() { // ... }, 1000); El setTimeout(...) toma una función de devolución de llamada para el primer parámetro que se activará después de que haya ocurrido la cantidad de milisegundos especificada como segundo argumento.
Veamos un ejemplo más complejo:
console.log('Initiated program.'); setTimeout(function() { console.log('3000 ms (3 sec) have passed.'); }, 3000); setTimeout(function() { console.log('0 ms (0 sec) have passed.'); }, 0); setTimeout(function() { console.log('1000 ms (1 sec) has passed.'); }, 1000); console.log('Terminated program');La salida que recibimos es:
Initiated program. Terminated program. 0 ms (0 sec) have passed. 1000 ms (1 sec) has passed. 3000 ms (3 sec) have passed. Puede ver que la primera declaración de registro se ejecuta como se esperaba. Instantáneamente, la última instrucción de registro se imprime en la pantalla, ya que eso sucede antes de que se superen los 0 segundos después del segundo setTimeout(...) . Inmediatamente después, se ejecutan los métodos setTimeout(...) segundo, tercero y primero.
Si Node.js no fuera de bloqueo, veríamos la primera declaración de registro, esperaríamos 3 segundos para ver la siguiente, veríamos instantáneamente la tercera (el setTimeout(...) de 0 segundos y luego tendríamos que esperar una más segundo para ver las dos últimas declaraciones de registro. La naturaleza de no bloqueo de Node hace que todos los temporizadores comiencen a contar desde el momento en que se ejecuta el programa, en lugar del orden en que se escriben. Es posible que desee consultar las API de Node, el Callstack y Event Loop para obtener más información sobre cómo funciona Node bajo el capó.
Es importante tener en cuenta que el hecho de que vea una función de devolución de llamada no significa necesariamente que haya una llamada asíncrona en el código. Llamamos al asyncAddFunction(…) anterior "async" porque asumimos que la operación tarda en completarse, como hacer una llamada a un servidor. En realidad, el proceso de sumar dos números no es asíncrono, por lo que en realidad sería un ejemplo del uso de una función de devolución de llamada de una manera que en realidad no bloquea el hilo.
Promesas sobre devoluciones de llamada
Las devoluciones de llamada pueden volverse desordenadas rápidamente en JavaScript, especialmente las devoluciones de llamada múltiples anidadas. Estamos familiarizados con pasar una devolución de llamada como argumento a una función, pero las Promesas nos permiten agregar o adjuntar una devolución de llamada a un objeto devuelto por una función. Esto nos permitiría manejar múltiples llamadas asíncronas de una manera más elegante.
Como ejemplo, supongamos que estamos haciendo una llamada a la API, y nuestra función, que no tiene el nombre exclusivo de ' makeAPICall(...) ', toma una URL y una devolución de llamada.
Nuestra función, makeAPICall(...) , se definiría como
function makeAPICall(path, callback) { // Attempt to make API call to path argument. // ... callback(undefined, res); // Or, callback(err, undefined); depending upon the API's response. }y lo llamaríamos con:
makeAPICall('/example', function(err1, res1) { if(err1) return console.log('Error: ', err1); // ... }); Si quisiéramos hacer otra llamada a la API usando la respuesta de la primera, tendríamos que anidar ambas devoluciones de llamada. Supongamos que necesito inyectar la propiedad nombre de res1 userName la ruta de la segunda llamada a la API. Tendríamos:
makeAPICall('/example', function(err1, res1) { if(err1) return console.log('Error: ', err1); makeAPICall('/newExample/' + res1.userName, function(err2, res2) { if(err2) return console.log('Error: ', err2); console.log(res2); }); }); Nota : el método ES6+ para inyectar la propiedad res1.userName en lugar de la concatenación de cadenas sería usar "Template Strings". De esa manera, en lugar de encapsular nuestra cadena entre comillas ( ' o " ), usaríamos acentos graves ( ` ) ubicados debajo de la tecla Escape en su teclado. Luego, usaríamos la notación ${} para incrustar cualquier expresión JS dentro los corchetes Al final, nuestra ruta anterior sería: /newExample/${res.UserName} , envuelto en acentos graves.
Está claro que este método de anidar devoluciones de llamada puede volverse bastante poco elegante rápidamente, lo que se conoce como la "Pirámide de la perdición de JavaScript". Saltando, si estuviéramos usando promesas en lugar de devoluciones de llamada, podríamos refactorizar nuestro código del primer ejemplo como tal:
makeAPICall('/example').then(function(res) { // Success callback. // ... }, function(err) { // Failure callback. console.log('Error:', err); }); El primer argumento de la función then() es nuestra devolución de llamada exitosa, y el segundo argumento es nuestra devolución de llamada fallida. Alternativamente, podríamos perder el segundo argumento de .then() y llamar a .catch() en su lugar. Los argumentos para .then() son opcionales, y llamar a .catch() sería equivalente a .then(successCallback, null) .
Usando .catch() , tenemos:
makeAPICall('/example').then(function(res) { // Success callback. // ... }).catch(function(err) { // Failure Callback console.log('Error: ', err); });También podemos reestructurar esto para facilitar la lectura:
makeAPICall('/example') .then(function(res) { // ... }) .catch(function(err) { console.log('Error: ', err); }); Es importante tener en cuenta que no podemos simplemente agregar una llamada .then() a cualquier función y esperar que funcione. La función a la que llamamos tiene que devolver una promesa, una promesa que activará .then() cuando se complete la operación asíncrona. En este caso, makeAPICall(...) hará su trabajo, activando el bloque then() o el bloque catch() cuando se complete.
Para hacer que makeAPICall(...) devuelva una Promesa, asignamos una función a una variable, donde esa función es el constructor de la Promesa. Las promesas pueden cumplirse o rechazarse , donde cumplido significa que la acción relacionada con la promesa se completó con éxito y rechazado significa lo contrario. Una vez que la promesa se cumple o se rechaza, decimos que se ha liquidado y, mientras esperamos que se liquide, quizás durante una llamada asíncrona, decimos que la promesa está pendiente .
El constructor Promise toma una función de devolución de llamada como argumento, que recibe dos parámetros: resolve y reject , que llamaremos en un momento posterior para activar la devolución de llamada exitosa en .then() o la falla de .then() devolución de llamada, o .catch() , si se proporciona.
Aquí hay un ejemplo de cómo se ve esto:
var examplePromise = new Promise(function(resolve, reject) { // Do whatever we are going to do and then make the appropiate call below: resolve('Happy!'); // — Everything worked. reject('Sad!'); // — We noticed that something went wrong. }):Entonces, podemos usar:
examplePromise.then(/* Both callback functions in here */); // Or, the success callback in .then() and the failure callback in .catch(). Tenga en cuenta, sin embargo, que examplePromise no puede aceptar ningún argumento. Eso anula el propósito, por lo que podemos devolver una promesa en su lugar.
function makeAPICall(path) { return new Promise(function(resolve, reject) { // Make our async API call here. if (/* All is good */) return resolve(res); //res is the response, would be defined above. else return reject(err); //err is error, would be defined above. }); } Las promesas realmente brillan para mejorar la estructura y, posteriormente, la elegancia de nuestro código con el concepto de "Promise Chaining". Esto nos permitiría devolver una nueva Promesa dentro de una cláusula .then() , por lo que podríamos adjuntar un segundo .then() a partir de entonces, lo que activaría la devolución de llamada adecuada desde la segunda promesa.
Al refactorizar nuestra llamada de URL de varias API anterior con Promises, obtenemos:
makeAPICall('/example').then(function(res) { // First response callback. Fires on success to '/example' call. return makeAPICall(`/newExample/${res.UserName}`); // Returning new call allows for Promise Chaining. }, function(err) { // First failure callback. Fires if there is a failure calling with '/example'. console.log('Error:', err); }).then(function(res) { // Second response callback. Fires on success to returned '/newExample/...' call. console.log(res); }, function(err) { // Second failure callback. Fire if there is a failure calling with '/newExample/...' console.log('Error:', err); }); Observe que primero llamamos a makeAPICall('/example') . Eso devuelve una promesa, por lo que adjuntamos un .then() . Dentro de ese then() , devolvemos una nueva llamada a makeAPICall(...) , que, en sí mismo, como se vio anteriormente, devuelve una promesa, permitiéndonos encadenar un nuevo .then() después del primero.
Como arriba, podemos reestructurar esto para facilitar la lectura y eliminar las devoluciones de llamada fallidas para una cláusula genérica catch() all. Entonces, podemos seguir el principio DRY (No se repita), y solo tenemos que implementar el manejo de errores una vez.
makeAPICall('/example') .then(function(res) { // Like earlier, fires with success and response from '/example'. return makeAPICall(`/newExample/${res.UserName}`); // Returning here lets us chain on a new .then(). }) .then(function(res) { // Like earlier, fires with success and response from '/newExample'. console.log(res); }) .catch(function(err) { // Generic catch all method. Fires if there is an err with either earlier call. console.log('Error: ', err); }); Tenga en cuenta que las devoluciones de llamada exitosas y fallidas en .then() solo se activan para el estado de la Promesa individual a la que corresponde .then() . El bloque catch , sin embargo, detectará cualquier error que se active en cualquiera de los .then() s.
ES6 Const vs Let
A lo largo de todos nuestros ejemplos, hemos estado empleando funciones ES5 y la antigua palabra clave var . Si bien millones de líneas de código todavía se ejecutan hoy empleando esos métodos ES5, es útil actualizar a los estándares actuales de ES6+, y refactorizaremos parte de nuestro código anterior. Comencemos con const y let .
Es posible que esté acostumbrado a declarar una variable con la palabra clave var :
var pi = 3.14;Con los estándares ES6+, podríamos hacer eso
let pi = 3.14;o
const pi = 3.14; donde const significa "constante", un valor que no se puede reasignar más adelante. (Excepto por las propiedades del objeto; lo cubriremos pronto. Además, las variables declaradas const no son inmutables, solo lo es la referencia a la variable).
En JavaScript antiguo, bloquee los ámbitos, como los de if , while , {} . for , etc. no afectó a var de ninguna manera, y esto es bastante diferente a los lenguajes de tipo más estático como Java o C++. Es decir, el alcance de var es toda la función que lo encierra, y podría ser global (si se coloca fuera de una función) o local (si se coloca dentro de una función). Para demostrar esto, vea el siguiente ejemplo:
function myFunction() { var num = 5; console.log(num); // 5 console.log('--'); for(var i = 0; i < 10; i++) { var num = i; console.log(num); //num becomes 0 — 9 } console.log('--'); console.log(num); // 9 console.log(i); // 10 } myFunction();Producción:
5 --- 0 1 2 3 ... 7 8 9 --- 9 10 Lo importante a tener en cuenta aquí es que definir un nuevo var num dentro del ámbito for afecta directamente al var num fuera y por encima de for . Esto se debe a que el ámbito de var siempre es el de la función envolvente y no el de un bloque.
Una vez más, de forma predeterminada, var i inside for() tiene como valor predeterminado el alcance de myFunction , por lo que podemos acceder a i fuera del ciclo y obtener 10.
En términos de asignación de valores a las variables, let es equivalente a var , solo que let tiene alcance de bloque, por lo que las anomalías que ocurrieron con var arriba no ocurrirán.
function myFunction() { let num = 5; console.log(num); // 5 for(let i = 0; i < 10; i++) { let num = i; console.log('--'); console.log(num); // num becomes 0 — 9 } console.log('--'); console.log(num); // 5 console.log(i); // undefined, ReferenceError } Mirando la palabra clave const , puede ver que obtenemos un error si intentamos reasignarla:
const c = 299792458; // Fact: The constant "c" is the speed of light in a vacuum in meters per second. c = 10; // TypeError: Assignment to constant variable. Las cosas se vuelven interesantes cuando asignamos una variable const a un objeto:
const myObject = { name: 'Jane Doe' }; // This is illegal: TypeError: Assignment to constant variable. myObject = { name: 'John Doe' }; // This is legal. console.log(myObject.name) -> John Doe myObject.name = 'John Doe'; Como puede ver, solo la referencia en la memoria al objeto asignado a un objeto const es inmutable, no el valor en sí mismo.
Funciones de flecha ES6
Es posible que esté acostumbrado a crear una función como esta:
function printHelloWorld() { console.log('Hello, World!'); }Con funciones de flecha, eso se convertiría en:
const printHelloWorld = () => { console.log('Hello, World!'); };Supongamos que tenemos una función simple que devuelve el cuadrado de un número:
const squareNumber = (x) => { return x * x; } squareNumber(5); // We can call an arrow function like an ES5 functions. Returns 25.Puede ver que, al igual que con las funciones de ES5, podemos tomar argumentos con paréntesis, podemos usar declaraciones de retorno normales y podemos llamar a la función como cualquier otra.
Es importante tener en cuenta que, si bien se requieren paréntesis si nuestra función no toma argumentos (como con printHelloWorld() arriba), podemos eliminar los paréntesis si solo toma uno, por lo que nuestra definición anterior del método squareNumber() se puede reescribir como:
const squareNumber = x => { // Notice we have dropped the parentheses for we only take in one argument. return x * x; }Ya sea que elija encapsular un solo argumento entre paréntesis o no, es una cuestión de gusto personal, y es probable que vea que los desarrolladores usan ambos métodos.
Finalmente, si solo queremos devolver implícitamente una expresión, como con squareNumber(...) arriba, podemos poner la declaración de devolución en línea con la firma del método:
const squareNumber = x => x * x;Es decir,
const test = (a, b, c) => expressiones lo mismo que
const test = (a, b, c) => { return expression }Tenga en cuenta que al usar la abreviatura anterior para devolver implícitamente un objeto, las cosas se vuelven oscuras. ¿Qué impide que JavaScript crea que los corchetes dentro de los cuales debemos encapsular nuestro objeto no son el cuerpo de nuestra función? Para evitar esto, envolvemos los corchetes del objeto entre paréntesis. Esto le permite explícitamente a JavaScript saber que de hecho estamos devolviendo un objeto, y no solo estamos definiendo un cuerpo.
const test = () => ({ pi: 3.14 }); // Spaces between brackets are a formality to make the code look cleaner.Para ayudar a solidificar el concepto de las funciones de ES6, refactorizaremos parte de nuestro código anterior, lo que nos permitirá comparar las diferencias entre ambas notaciones.
asyncAddFunction(...) , desde arriba, podría refactorizarse desde:
function asyncAddFunction(a, b, callback){ callback(a + b); }para:
const aysncAddFunction = (a, b, callback) => { callback(a + b); };o incluso a:
const aysncAddFunction = (a, b, callback) => callback(a + b); // This will return callback(a + b).Al llamar a la función, podríamos pasar una función de flecha para la devolución de llamada:
asyncAddFunction(10, 12, sum => { // No parentheses because we only take one argument. console.log(sum); }Es claro ver cómo este método mejora la legibilidad del código. Para mostrarle solo un caso, podemos tomar nuestro antiguo ejemplo anterior basado en ES5 Promise y refactorizarlo para usar funciones de flecha.
makeAPICall('/example') .then(res => makeAPICall(`/newExample/${res.UserName}`)) .then(res => console.log(res)) .catch(err => console.log('Error: ', err)); Ahora, hay algunas advertencias con las funciones de flecha. Por un lado, no vinculan this palabra clave. Supongamos que tengo el siguiente objeto:
const Person = { name: 'John Doe', greeting: () => { console.log(`Hi. My name is ${this.name}.`); } } Es posible que espere que una llamada a Person.greeting() devuelva "Hola. Mi nombre es John Doe. En su lugar, obtenemos: “Hola. Mi nombre no está definido”. Esto se debe a que las funciones de flecha no tienen un this , por lo que intentar usar this dentro de una función de flecha tiene como valor predeterminado this del alcance adjunto, y el alcance adjunto del objeto Person es window , en el navegador, o module.exports en Nodo.
Para probar esto, si usamos el mismo objeto nuevamente, pero establecemos la propiedad de name de global this en algo como 'Jane Doe', entonces this.name en la función de flecha devuelve 'Jane Doe', porque global this está dentro de ámbito adjunto, o es el padre del objeto Person .
this.name = 'Jane Doe'; const Person = { name: 'John Doe', greeting: () => { console.log(`Hi. My name is ${this.name}.`); } } Person.greeting(); // Hi. My name is Jane DoeEsto se conoce como 'Alcance léxico', y podemos sortearlo usando la llamada 'Sintaxis corta', que es donde perdemos los dos puntos y la flecha para refactorizar nuestro objeto como tal:
const Person = { name: 'John Doe', greeting() { console.log(`Hi. My name is ${this.name}.`); } } Person.greeting() //Hi. My name is John Doe.Clases ES6
Si bien JavaScript nunca admitió clases, siempre puede emularlas con objetos como el anterior. EcmaScript 6 brinda soporte para clases que usan la class y las new palabras clave:
class Person { constructor(name) { this.name = name; } greeting() { console.log(`Hi. My name is ${this.name}.`); } } const person = new Person('John'); person.greeting(); // Hi. My name is John. La función constructora se llama automáticamente cuando se usa la new palabra clave, a la que podemos pasar argumentos para configurar inicialmente el objeto. Esto debería ser familiar para cualquier lector que tenga experiencia con lenguajes de programación orientados a objetos de tipos más estáticos como Java, C++ y C#.
Sin entrar en demasiados detalles sobre los conceptos de programación orientada a objetos, otro paradigma de este tipo es la "herencia", que consiste en permitir que una clase herede de otra. Una clase llamada Car , por ejemplo, será muy general y contendrá métodos como "detener", "iniciar", etc., que todos los autos necesitan. Entonces, un subconjunto de la clase llamado SportsCar podría heredar operaciones fundamentales de Car y anular cualquier cosa que necesite personalizar. Podríamos denotar tal clase de la siguiente manera:
class Car { constructor(licensePlateNumber) { this.licensePlateNumber = licensePlateNumber; } start() {} stop() {} getLicensePlate() { return this.licensePlateNumber; } // … } class SportsCar extends Car { constructor(engineRevCount, licensePlateNumber) { super(licensePlateNumber); // Pass licensePlateNumber up to the parent class. this.engineRevCount = engineRevCount; } start() { super.start(); } stop() { super.stop(); } getLicensePlate() { return super.getLicensePlate(); } getEngineRevCount() { return this.engineRevCount; } } Puede ver claramente que la palabra clave super nos permite acceder a propiedades y métodos de la clase principal o super.
Eventos de JavaScript
Un Evento es una acción que ocurre a la cual usted tiene la habilidad de responder. Suponga que está creando un formulario de inicio de sesión para su aplicación. Cuando el usuario presiona el botón "enviar", puede reaccionar a ese evento a través de un "controlador de eventos" en su código, generalmente una función. Cuando esta función se define como el controlador de eventos, decimos que estamos "registrando un controlador de eventos". Es probable que el controlador de eventos para el clic del botón de envío verifique el formato de la entrada proporcionada por el usuario, lo desinfecte para evitar ataques como inyecciones SQL o Cross Site Scripting (tenga en cuenta que nunca se puede considerar ningún código en el lado del cliente). Siempre desinfecte los datos en el servidor, nunca confíe en nada del navegador), y luego verifique si esa combinación de nombre de usuario y contraseña existe dentro de una base de datos para autenticar a un usuario y entregarle un token.
Dado que este es un artículo sobre Node, nos centraremos en el modelo de eventos de Node.
Podemos usar el módulo de events de Node para emitir y reaccionar a eventos específicos. Cualquier objeto que emita un evento es una instancia de la clase EventEmitter .
Podemos emitir un evento llamando al método emit() y escuchamos ese evento a través del método on() , ambos expuestos a través de la clase EventEmitter .
const EventEmitter = require('events'); const myEmitter = new EventEmitter(); Con myEmitter ahora una instancia de la clase EventEmitter , podemos acceder a emit emit() y on() :
const EventEmitter = require('events'); const myEmitter = new EventEmitter(); myEmitter.on('someEvent', () => { console.log('The "someEvent" event was fired (emitted)'); }); myEmitter.emit('someEvent'); // This will call the callback function above. El segundo parámetro de myEmitter.on() es la función de devolución de llamada que se activará cuando se emita el evento: este es el controlador de eventos. El primer parámetro es el nombre del evento, que puede ser cualquier cosa que queramos, aunque se recomienda la convención de nomenclatura camelCase.
Además, el controlador de eventos puede tomar cualquier cantidad de argumentos, que se transmiten cuando se emite el evento:
const EventEmitter = require('events'); const myEmitter = new EventEmitter(); myEmitter.on('someEvent', (data) => { console.log(`The "someEvent" event was fired (emitted) with data: ${data}`); }); myEmitter.emit('someEvent', 'This is the data payload'); Mediante el uso de la herencia, podemos exponer los métodos emit emit() y on() de 'EventEmitter' a cualquier clase. Esto se hace creando una clase Node.js y usando la palabra clave reservada extends para heredar las propiedades disponibles en EventEmitter :

const EventEmitter = require('events'); class MyEmitter extends EventEmitter { // This is my class. I can emit events from a MyEmitter object. } Supongamos que estamos construyendo un programa de notificación de colisión de vehículos que recibe datos de giroscopios, acelerómetros y manómetros en el casco del automóvil. Cuando un vehículo choca con un objeto, esos sensores externos detectarán el choque, ejecutarán la función de collide(...) y le pasarán los datos agregados del sensor como un bonito objeto de JavaScript. Esta función emitirá un evento de collision , notificando al proveedor del bloqueo.
const EventEmitter = require('events'); class Vehicle extends EventEmitter { collide(collisionStatistics) { this.emit('collision', collisionStatistics) } } const myVehicle = new Vehicle(); myVehicle.on('collision', collisionStatistics => { console.log('WARNING! Vehicle Impact Detected: ', collisionStatistics); notifyVendor(collisionStatistics); }); myVehicle.collide({ ... }); Este es un ejemplo intrincado, ya que podríamos poner el código dentro del controlador de eventos dentro de la función de colisión de la clase, pero demuestra cómo funciona el modelo de eventos de nodo. Tenga en cuenta que algunos tutoriales mostrarán el método util.inherits() para permitir que un objeto emita eventos. Eso ha quedado obsoleto a favor de ES6 Classes y extends .
El administrador de paquetes de nodos
Al programar con Node y JavaScript, será bastante común escuchar acerca de npm . Npm es un administrador de paquetes que hace precisamente eso: permite la descarga de paquetes de terceros que resuelven problemas comunes en JavaScript. También existen otras soluciones, como Yarn, Npx, Grunt y Bower, pero en esta sección, nos centraremos solo en npm y en cómo puede instalar dependencias para su aplicación a través de una interfaz de línea de comandos (CLI) simple usándola.
Comencemos de manera simple, con solo npm . Visite la página de inicio de NpmJS para ver todos los paquetes disponibles de NPM. Cuando inicie un nuevo proyecto que dependerá de los paquetes NPM, deberá ejecutar npm init a través de la terminal en el directorio raíz de su proyecto. Se le harán una serie de preguntas que se utilizarán para crear un archivo package.json . Este archivo almacena todas sus dependencias: módulos de los que depende su aplicación para funcionar, scripts, comandos de terminal predefinidos para ejecutar pruebas, compilar el proyecto, iniciar el servidor de desarrollo, etc., y más.
Para instalar un paquete, simplemente ejecute npm install [package-name] --save . El indicador de save garantizará que el paquete y su versión se registren en el archivo package.json . Desde la versión 5 de npm , las dependencias se guardan de forma predeterminada, por lo que se puede omitir --save . También notará una nueva carpeta node_modules , que contiene el código para ese paquete que acaba de instalar. Esto también se puede acortar a solo npm i [package-name] . Como nota útil, la carpeta node_modules nunca debe incluirse en un repositorio de GitHub debido a su tamaño. Cada vez que clone un repositorio de GitHub (o cualquier otro sistema de administración de versiones), asegúrese de ejecutar el comando npm install para salir y buscar todos los paquetes definidos en el archivo package.json , creando el directorio node_modules automáticamente. También puede instalar un paquete en una versión específica: npm i [package-name]@1.10.1 --save , por ejemplo.
Eliminar un paquete es similar a instalar uno: npm remove [package-name] .
También puede instalar un paquete globalmente. Este paquete estará disponible en todos los proyectos, no solo en el que esté trabajando. Haces esto con el indicador -g después de npm i [package-name] . Esto se usa comúnmente para CLI, como Google Firebase y Heroku. A pesar de la facilidad que presenta este método, generalmente se considera una mala práctica instalar paquetes globalmente, ya que no se guardan en el archivo package.json , y si otro desarrollador intenta usar su proyecto, no obtendrá todas las dependencias requeridas de npm install .
API y JSON
Las API son un paradigma muy común en la programación, e incluso si recién está comenzando su carrera como desarrollador, es probable que las API y su uso, especialmente en el desarrollo web y móvil, surjan con mayor frecuencia.
Una API es una interfaz de programación de aplicaciones, y es básicamente un método por el cual dos sistemas desacoplados pueden comunicarse entre sí. En términos más técnicos, una API permite que un sistema o programa informático (generalmente un servidor) reciba solicitudes y envíe respuestas apropiadas (a un cliente, también conocido como host).
Suponga que está creando una aplicación meteorológica. Necesita una forma de geocodificar la dirección de un usuario en una latitud y longitud, y luego una forma de obtener el clima actual o pronosticado en esa ubicación en particular.
As a developer, you want to focus on building your app and monetizing it, not putting the infrastructure in place to geocode addresses or placing weather stations in every city.
Luckily for you, companies like Google and OpenWeatherMap have already put that infrastructure in place, you just need a way to talk to it — that is where the API comes in. While, as of now, we have developed a very abstract and ambiguous definition of the API, bear with me. We'll be getting to tangible examples soon.
Now, it costs money for companies to develop, maintain, and secure that aforementioned infrastructure, and so it is common for corporations to sell you access to their API. This is done with that is known as an API key, a unique alphanumeric identifier associating you, the developer, with the API. Every time you ask the API to send you data, you pass along your API key. The server can then authenticate you and keep track of how many API calls you are making, and you will be charged appropriately. The API key also permits Rate-Limiting or API Call Throttling (a method of throttling the number of API calls in a certain timeframe as to not overwhelm the server, preventing DOS attacks — Denial of Service). Most companies, however, will provide a free quota, giving you, as an example, 25,000 free API calls a day before charging you.
Up to this point, we have established that an API is a method by which two computer programs can communicate with each other. If a server is storing data, such as a website, and your browser makes a request to download the code for that site, that was the API in action.
Let us look at a more tangible example, and then we'll look at a more real-world, technical one. Suppose you are eating out at a restaurant for dinner. You are equivalent to the client, sitting at the table, and the chef in the back is equivalent to the server.
Since you will never directly talk to the chef, there is no way for him/her to receive your request (for what order you would like to make) or for him/her to provide you with your meal once you order it. We need someone in the middle. In this case, it's the waiter, analogous to the API. The API provides a medium with which you (the client) may talk to the server (the chef), as well as a set of rules for how that communication should be made (the menu — one meal is allowed two sides, etc.)
Now, how do you actually talk to the API (the waiter)? You might speak English, but the chef might speak Spanish. Is the waiter expected to know both languages to translate? What if a third person comes in who only speaks Mandarin? What then? Well, all clients and servers have to agree to speak a common language, and in computer programming, that language is JSON, pronounced JAY-sun, and it stands for JavaScript Object Notation.
At this point, we don't quite know what JSON looks like. It's not a computer programming language, it's just, well, a language, like English or Spanish, that everyone (everyone being computers) understands on a guaranteed basis. It's guaranteed because it's a standard, notably RFC 8259 , the JavaScript Object Notation (JSON) Data Interchange Format by the Internet Engineering Task Force (IETF).
Even without formal knowledge of what JSON actually is and what it looks like (we'll see in an upcoming article in this series), we can go ahead introduce a technical example operating on the Internet today that employs APIs and JSON. APIs and JSON are not just something you can choose to use, it's not equivalent to one out of a thousand JavaScript frameworks you can pick to do the same thing. It is THE standard for data exchange on the web.
Suppose you are building a travel website that compares prices for aircraft, rental car, and hotel ticket prices. Let us walk through, step-by-step, on a high level, how we would build such an application. Of course, we need our User Interface, the front-end, but that is out of scope for this article.
We want to provide our users with the lowest price booking method. Well, that means we need to somehow attain all possible booking prices, and then compare all of the elements in that set (perhaps we store them in an array) to find the smallest element (known as the infimum in mathematics.)
How will we get this data? Well, suppose all of the booking sites have a database full of prices. Those sites will provide an API, which exposes the data in those databases for use by you. You will call each API for each site to attain all possible booking prices, store them in your own array, find the lowest or minimum element of that array, and then provide the price and booking link to your user. We'll ask the API to query its database for the price in JSON, and it will respond with said price in JSON to us. We can then use, or parse, that accordingly. We have to parse it because APIs will return JSON as a string, not the actual JavaScript data type of JSON. This might not make sense now, and that's okay. We'll be covering it more in a future article.
Also, note that just because something is called an API does not necessarily mean it operates on the web and sends and receives JSON. The Java API, for example, is just the list of classes, packages, and interfaces that are part of the Java Development Kit (JDK), providing programming functionality to the programmer.
Bueno. We know we can talk to a program running on a server by way of an Application Programming Interface, and we know that the common language with which we do this is known as JSON. But in the web development and networking world, everything has a protocol. What do we actually do to make an API call, and what does that look like code-wise? That's where HTTP Requests enter the picture, the HyperText Transfer Protocol, defining how messages are formatted and transmitted across the Internet. Once we have an understanding of HTTP (and HTTP verbs, you'll see that in the next section), we can look into actual JavaScript frameworks and methods (like fetch() ) offered by the JavaScript API (similar to the Java API), that actually allow us to make API calls.
HTTP And HTTP Requests
HTTP is the HyperText Transfer Protocol. It is the underlying protocol that determines how messages are formatted as they are transmitted and received across the web. Let's think about what happens when, for example, you attempt to load the home page of Smashing Magazine in your web browser.
You type the website URL (Uniform Resource Locator) in the URL bar, where the DNS server (Domain Name Server, out of scope for this article) resolves the URL into the appropriate IP Address. The browser makes a request, called a GET Request, to the Web Server to, well, GET the underlying HTML behind the site. The Web Server will respond with a message such as “OK”, and then will go ahead and send the HTML down to the browser where it will be parsed and rendered accordingly.
There are a few things to note here. First, the GET Request, and then the “OK” response. Suppose you have a specific database, and you want to write an API to expose that database to your users. Suppose the database contains books the user wants to read (as it will in a future article in this series). Then there are four fundamental operations your user may want to perform on this database, that is, Create a record, Read a record, Update a record, or Delete a record, known collectively as CRUD operations.
Let's look at the Read operation for a moment. Without incorrectly assimilating or conflating the notion of a web server and a database, that Read operation is very similar to your web browser attempting to get the site from the server, just as to read a record is to get the record from the database.
Esto se conoce como una solicitud HTTP. Está realizando una solicitud a algún servidor en algún lugar para obtener algunos datos y, como tal, la solicitud se denomina apropiadamente "GET", siendo las mayúsculas una forma estándar de indicar dichas solicitudes.
¿Qué pasa con la parte Crear de CRUD? Bueno, cuando se habla de solicitudes HTTP, eso se conoce como solicitud POST. Así como puede publicar un mensaje en una plataforma de redes sociales, también puede publicar un nuevo registro en una base de datos.
La actualización de CRUD nos permite usar una solicitud PUT o PATCH para actualizar un recurso. PUT de HTTP creará un nuevo registro o actualizará/reemplazará el anterior.
Veamos esto un poco más en detalle, y luego llegaremos a PATCH.
Una API generalmente funciona haciendo solicitudes HTTP a rutas específicas en una URL. Supongamos que estamos creando una API para hablar con una base de datos que contiene la lista de libros de un usuario. Entonces podríamos ver esos libros en la URL .../books . Una solicitud POST a .../books creará un nuevo libro con las propiedades que defina (piense en id, título, ISBN, autor, datos de publicación, etc.) en la ruta .../books . No importa cuál sea la estructura de datos subyacente que almacena todos los libros en .../books en este momento. Solo nos importa que la API exponga ese punto final (al que se accede a través de la ruta) para manipular datos. La oración anterior fue clave: una solicitud POST crea un nuevo libro en la ruta ...books/ . La diferencia entre PUT y POST, entonces, es que PUT creará un nuevo libro (como con POST) si no existe tal libro, o reemplazará un libro existente si el libro ya existe dentro de esa estructura de datos antes mencionada.
Supongamos que cada libro tiene las siguientes propiedades: id, título, ISBN, autor, hasRead (booleano).
Luego, para agregar un nuevo libro, como se vio anteriormente, haríamos una solicitud POST a .../books . Si quisiéramos actualizar o reemplazar un libro por completo, haríamos una solicitud PUT a .../books/id donde id es el ID del libro que queremos reemplazar.
Mientras que PUT reemplaza por completo un libro existente, PATCH actualiza algo que tiene que ver con un libro específico, tal vez modificando la propiedad booleana hasRead que definimos anteriormente, por lo que haríamos una solicitud de PATCH a …/books/id enviando los nuevos datos.
Puede ser difícil ver el significado de esto en este momento, ya que hasta ahora hemos establecido todo en teoría, pero no hemos visto ningún código tangible que realmente haga una solicitud HTTP. Sin embargo, llegaremos a eso pronto, cubriendo GET en este artículo, y el resto en un artículo futuro.
Hay una última operación CRUD fundamental y se llama Eliminar. Como era de esperar, el nombre de una solicitud HTTP de este tipo es "ELIMINAR", y funciona de manera muy similar a PATCH, que requiere que se proporcione la ID del libro en una ruta.
Hemos aprendido hasta ahora, entonces, que las rutas son URL específicas a las que realiza una solicitud HTTP, y que los puntos finales son funciones que proporciona la API, que hacen algo con los datos que expone. Es decir, el punto final es una función de lenguaje de programación ubicada en el otro extremo de la ruta y realiza cualquier solicitud HTTP que haya especificado. También aprendimos que existen términos como POST, GET, PUT, PATCH, DELETE y más (conocidos como verbos HTTP) que en realidad especifican qué solicitudes está realizando a la API. Al igual que JSON, estos métodos de solicitud HTTP son estándares de Internet definidos por el Grupo de trabajo de ingeniería de Internet (IETF), en particular, RFC 7231, Sección cuatro: Métodos de solicitud, y RFC 5789, Sección dos: Método de parche, donde RFC es un acrónimo de Solicitud de comentarios.
Entonces, podríamos hacer una solicitud GET a la URL .../books/id donde la ID pasada se conoce como parámetro. Podríamos hacer una solicitud POST, PUT o PATCH a .../books para crear un recurso o a .../books/id para modificar/reemplazar/actualizar un recurso. Y también podemos hacer una solicitud DELETE a .../books/id para eliminar un libro específico.
Puede encontrar una lista completa de los métodos de solicitud HTTP aquí.
También es importante tener en cuenta que después de realizar una solicitud HTTP, recibiremos una respuesta. La respuesta específica está determinada por cómo creamos la API, pero siempre debe recibir un código de estado. Anteriormente, dijimos que cuando su navegador web solicite el HTML del servidor web, responderá con "OK". Eso se conoce como código de estado HTTP, más específicamente, HTTP 200 OK. El código de estado solo especifica cómo se completó la operación o acción especificada en el punto final (recuerde, esa es nuestra función que hace todo el trabajo). Los códigos de estado HTTP son devueltos por el servidor, y probablemente haya muchos con los que esté familiarizado, como 404 Not Found (no se pudo encontrar el recurso o el archivo, esto sería como hacer una solicitud GET a .../books/id donde no existe tal ID.)
Puede encontrar una lista completa de códigos de estado HTTP aquí.
MongoDB
MongoDB es una base de datos NoSQL no relacional similar a Firebase Real-time Database. Hablará con la base de datos a través de un paquete Node como MongoDB Native Driver o Mongoose.
En MongoDB, los datos se almacenan en JSON, que es bastante diferente de las bases de datos relacionales como MySQL, PostgreSQL o SQLite. Ambos se denominan bases de datos, con tablas SQL denominadas colecciones, filas de tablas SQL denominadas documentos y columnas de tablas SQL denominadas campos.
Usaremos la base de datos MongoDB en un próximo artículo de esta serie cuando creemos nuestra primera API Bookshelf. Las operaciones CRUD fundamentales enumeradas anteriormente se pueden realizar en una base de datos MongoDB.
Se recomienda que lea los documentos de MongoDB para aprender a crear una base de datos en vivo en un clúster de Atlas y realizar operaciones CRUD con el controlador nativo de MongoDB. En el próximo artículo de esta serie, aprenderemos a configurar una base de datos local y una base de datos de producción en la nube.
Creación de una aplicación de nodo de línea de comandos
Al crear una aplicación, verá que muchos autores vuelcan su base de código completa al comienzo del artículo y luego intentan explicar cada línea a partir de entonces. En este texto, tomaré un enfoque diferente. Explicaré mi código línea por línea, construyendo la aplicación a medida que avanzamos. No me preocuparé por la modularidad o el rendimiento, no dividiré la base de código en archivos separados y no seguiré el principio DRY ni intentaré hacer que el código sea reutilizable. Cuando solo se está aprendiendo, es útil hacer las cosas lo más simples posible, y ese es el enfoque que tomaré aquí.
Seamos claros en lo que estamos construyendo. No nos preocuparemos por la entrada del usuario, por lo que no utilizaremos paquetes como Yargs. Tampoco construiremos nuestra propia API. Eso vendrá en un artículo posterior de esta serie cuando hagamos uso de Express Web Application Framework. Tomo este enfoque para no combinar Node.js con el poder de Express y las API, como lo hacen la mayoría de los tutoriales. Más bien, proporcionaré un método (de muchos) mediante el cual llamar y recibir datos de una API externa que utiliza una biblioteca de JavaScript de terceros. La API a la que llamaremos es una API meteorológica, a la que accederemos desde Node y volcaremos su salida en la terminal, quizás con algún formato, conocido como "impresión bonita". Cubriré todo el proceso, incluido cómo configurar la API y obtener la clave de API, cuyos pasos brindan los resultados correctos a partir de enero de 2019.
Usaremos la API de OpenWeatherMap para este proyecto, así que para comenzar, vaya a la página de registro de OpenWeatherMap y cree una cuenta con el formulario. Una vez que haya iniciado sesión, busque el elemento del menú Claves API en la página del panel (ubicado aquí). Si acaba de crear una cuenta, deberá elegir un nombre para su clave API y presionar "Generar". Podría tomar al menos 2 horas para que su nueva clave API funcione y se asocie con su cuenta.
Antes de comenzar a desarrollar la aplicación, visitaremos la documentación de la API para aprender a formatear nuestra clave de API. En este proyecto, especificaremos un código postal y un código de país para obtener la información meteorológica en ese lugar.
De los documentos, podemos ver que el método por el cual hacemos esto es proporcionar la siguiente URL:
api.openweathermap.org/data/2.5/weather?zip={zip code},{country code}En el que podríamos ingresar datos:
api.openweathermap.org/data/2.5/weather?zip=94040,usAhora, antes de que podamos obtener datos relevantes de esta API, debemos proporcionar nuestra nueva clave de API como parámetro de consulta:
api.openweathermap.org/data/2.5/weather?zip=94040,us&appid={YOUR_API_KEY} Por ahora, copie esa URL en una nueva pestaña en su navegador web, reemplazando el marcador de posición {YOUR_API_KEY} con la clave API que obtuvo anteriormente cuando se registró para obtener una cuenta.
El texto que puede ver es en realidad JSON, el idioma acordado de la web como se discutió anteriormente.
Para inspeccionar esto más a fondo, presione Ctrl + Shift + I en Google Chrome para abrir las herramientas para desarrolladores de Chrome y luego navegue a la pestaña Red. En la actualidad, no debería haber datos aquí.
Para monitorear realmente los datos de la red, vuelva a cargar la página y observe cómo se completa la pestaña con información útil. Haga clic en el primer enlace como se muestra en la imagen a continuación.
Una vez que hace clic en ese enlace, podemos ver información específica de HTTP, como los encabezados. Los encabezados se envían en la respuesta de la API (también puede, en algunos casos, enviar sus propios encabezados a la API, o incluso puede crear sus propios encabezados personalizados (a menudo con el prefijo x- ) para devolverlos al crear su propia API ), y solo contienen información adicional que el cliente o el servidor pueden necesitar.
En este caso, puede ver que hicimos una solicitud HTTP GET a la API y respondió con un estado HTTP 200 OK. También puede ver que los datos devueltos estaban en JSON, como se indica en la sección "Encabezados de respuesta".
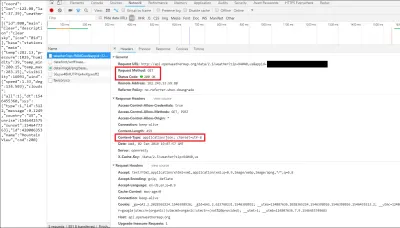
Si presiona la pestaña de vista previa, puede ver el JSON como un objeto de JavaScript. La versión de texto que puede ver en su navegador es una cadena, porque JSON siempre se transmite y recibe a través de la web como una cadena. Es por eso que tenemos que analizar el JSON en nuestro código, para convertirlo en un formato más legible, en este caso (y en casi todos los casos), un objeto JavaScript.
También puede usar la extensión de Google Chrome "JSON View" para hacer esto automáticamente.
Para comenzar a construir nuestra aplicación, abriré una terminal y crearé un nuevo directorio raíz y luego cd en él. Una vez dentro, crearé un nuevo archivo app.js , ejecutaré npm init para generar un archivo package.json con la configuración predeterminada y luego abriré Visual Studio Code.
mkdir command-line-weather-app && cd command-line-weather-app touch app.js npm init code . A partir de entonces, descargaré Axios, verificaré que se haya agregado a mi archivo package.json y observaré que la carpeta node_modules se haya creado correctamente.
En el navegador, puede ver que hicimos una solicitud GET a mano escribiendo manualmente la URL adecuada en la barra de URL. Axios es lo que me permitirá hacer eso dentro de Node.
A partir de ahora, todo el siguiente código se ubicará dentro del archivo app.js , cada fragmento se colocará uno tras otro.
Lo primero que haré es requerir el paquete Axios que instalamos anteriormente con
const axios = require('axios'); Ahora tenemos acceso a Axios y podemos realizar solicitudes HTTP relevantes a través de la constante axios .
Por lo general, nuestras llamadas a la API serán dinámicas; en este caso, es posible que deseemos inyectar diferentes códigos postales y códigos de países en nuestra URL. Por lo tanto, crearé variables constantes para cada parte de la URL y luego las uniré con Cadenas de plantilla ES6. Primero, tenemos la parte de nuestra URL que nunca cambiará, así como nuestra clave API:
const API_URL = 'https://api.openweathermap.org/data/2.5/weather?zip='; const API_KEY = 'Your API Key Here'; También asignaré nuestro código postal y código de país. Dado que no esperamos la entrada del usuario y la codificación de los datos es bastante difícil, también los haré constantes, aunque, en muchos casos, será más útil usar let .
const LOCATION_ZIP_CODE = '90001'; const COUNTRY_CODE = 'us';Ahora necesitamos juntar estas variables en una URL a la que podamos usar Axios para realizar solicitudes GET a:
const ENTIRE_API_URL = `${API_URL}${LOCATION_ZIP_CODE},${COUNTRY_CODE}&appid=${API_KEY}`; Aquí está el contenido de nuestro archivo app.js hasta este punto:
const axios = require('axios'); // API specific settings. const API_URL = 'https://api.openweathermap.org/data/2.5/weather?zip='; const API_KEY = 'Your API Key Here'; const LOCATION_ZIP_CODE = '90001'; const COUNTRY_CODE = 'us'; const ENTIRE_API_URL = `${API_URL}${LOCATION_ZIP_CODE},${COUNTRY_CODE}&appid=${API_KEY}`; Todo lo que queda por hacer es usar axios para realizar una solicitud GET a esa URL. Para eso, usaremos el método get(url) proporcionado por axios .
axios.get(ENTIRE_API_URL) axios.get(...) en realidad devuelve una Promesa, y la función de devolución de llamada exitosa tomará un argumento de respuesta que nos permitirá acceder a la respuesta desde la API, lo mismo que vio en el navegador. También agregaré una cláusula .catch() para detectar cualquier error.
axios.get(ENTIRE_API_URL) .then(response => console.log(response)) .catch(error => console.log('Error', error)); Si ahora ejecutamos este código con node app.js en la terminal, podrá ver la respuesta completa que recibimos. Sin embargo, suponga que solo desea ver la temperatura de ese código postal; entonces, la mayoría de los datos en la respuesta no le serán útiles. Axios en realidad devuelve la respuesta de la API en el objeto de datos, que es una propiedad de la respuesta. Eso significa que la respuesta del servidor se encuentra en realidad en response.data , así que imprimámosla en la función de devolución de llamada: console.log(response.data) .
Ahora, dijimos que los servidores web siempre tratan con JSON como una cadena, y eso es cierto. Sin embargo, puede notar que response.data ya es un objeto (evidente al ejecutar console.log(typeof response.data) ) — no tuvimos que analizarlo con JSON.parse() . Eso es porque Axios ya se encarga de esto detrás de escena.
La salida en el terminal de la ejecución de console.log(response.data) se puede formatear, "muy impresa", ejecutando console.log(JSON.stringify(response.data, undefined, 2)) . JSON.stringify() convierte un objeto JSON en una cadena y toma el objeto, un filtro y la cantidad de caracteres por los que sangrar al imprimir. Puedes ver la respuesta que esto proporciona:
{ "coord": { "lon": -118.24, "lat": 33.97 }, "weather": [ { "id": 800, "main": "Clear", "description": "clear sky", "icon": "01d" } ], "base": "stations", "main": { "temp": 288.21, "pressure": 1022, "humidity": 15, "temp_min": 286.15, "temp_max": 289.75 }, "visibility": 16093, "wind": { "speed": 2.1, "deg": 110 }, "clouds": { "all": 1 }, "dt": 1546459080, "sys": { "type": 1, "id": 4361, "message": 0.0072, "country": "US", "sunrise": 1546441120, "sunset": 1546476978 }, "id": 420003677, "name": "Lynwood", "cod": 200 } Ahora, es claro ver que la temperatura que estamos buscando se encuentra en la propiedad main del objeto response.data , por lo que podemos acceder llamando a response.data.main.temp . Veamos el código de la aplicación hasta ahora:
const axios = require('axios'); // API specific settings. const API_URL = 'https://api.openweathermap.org/data/2.5/weather?zip='; const API_KEY = 'Your API Key Here'; const LOCATION_ZIP_CODE = '90001'; const COUNTRY_CODE = 'us'; const ENTIRE_API_URL = `${API_URL}${LOCATION_ZIP_CODE},${COUNTRY_CODE}&appid=${API_KEY}`; axios.get(ENTIRE_API_URL) .then(response => console.log(response.data.main.temp)) .catch(error => console.log('Error', error));La temperatura que obtenemos está en realidad en Kelvin, que es una escala de temperatura generalmente utilizada en Física, Química y Termodinámica debido al hecho de que proporciona un punto de "cero absoluto", que es la temperatura a la que se produce todo el movimiento térmico de todo el interior. las partículas cesan. Solo necesitamos convertir esto a Fahrenheit o Celcius con las fórmulas a continuación:
F = K * 9/5 - 459,67
C = K - 273,15
Actualicemos nuestra devolución de llamada exitosa para imprimir los nuevos datos con esta conversión. También agregaremos una oración adecuada a los efectos de la experiencia del usuario:
axios.get(ENTIRE_API_URL) .then(response => { // Getting the current temperature and the city from the response object. const kelvinTemperature = response.data.main.temp; const cityName = response.data.name; const countryName = response.data.sys.country; // Making K to F and K to C conversions. const fahrenheitTemperature = (kelvinTemperature * 9/5) — 459.67; const celciusTemperature = kelvinTemperature — 273.15; // Building the final message. const message = ( `Right now, in \ ${cityName}, ${countryName} the current temperature is \ ${fahrenheitTemperature.toFixed(2)} deg F or \ ${celciusTemperature.toFixed(2)} deg C.`.replace(/\s+/g, ' ') ); console.log(message); }) .catch(error => console.log('Error', error)); Los paréntesis alrededor de la variable del message no son obligatorios, simplemente se ven bien, de forma similar a cuando se trabaja con JSX en React. Las barras invertidas evitan que la cadena de la plantilla formatee una nueva línea, y el método de prototipo replace() String elimina los espacios en blanco mediante expresiones regulares (RegEx). Los métodos prototipo toFixed() Number redondean un flotante a un número específico de lugares decimales, en este caso, dos.
Con eso, nuestro app.js final se ve de la siguiente manera:
const axios = require('axios'); // API specific settings. const API_URL = 'https://api.openweathermap.org/data/2.5/weather?zip='; const API_KEY = 'Your API Key Here'; const LOCATION_ZIP_CODE = '90001'; const COUNTRY_CODE = 'us'; const ENTIRE_API_URL = `${API_URL}${LOCATION_ZIP_CODE},${COUNTRY_CODE}&appid=${API_KEY}`; axios.get(ENTIRE_API_URL) .then(response => { // Getting the current temperature and the city from the response object. const kelvinTemperature = response.data.main.temp; const cityName = response.data.name; const countryName = response.data.sys.country; // Making K to F and K to C conversions. const fahrenheitTemperature = (kelvinTemperature * 9/5) — 459.67; const celciusTemperature = kelvinTemperature — 273.15; // Building the final message. const message = ( `Right now, in \ ${cityName}, ${countryName} the current temperature is \ ${fahrenheitTemperature.toFixed(2)} deg F or \ ${celciusTemperature.toFixed(2)} deg C.`.replace(/\s+/g, ' ') ); console.log(message); }) .catch(error => console.log('Error', error));Conclusión
Hemos aprendido mucho sobre cómo funciona Node en este artículo, desde las diferencias entre las solicitudes síncronas y asíncronas, hasta las funciones de devolución de llamada, las nuevas funciones de ES6, los eventos, los administradores de paquetes, las API, JSON y el Protocolo de transferencia de hipertexto, bases de datos no relacionales. , e incluso creamos nuestra propia aplicación de línea de comandos utilizando la mayor parte de ese nuevo conocimiento.
En los próximos artículos de esta serie, analizaremos en profundidad la pila de llamadas, el bucle de eventos y las API de nodo, hablaremos sobre el uso compartido de recursos de origen cruzado (CORS) y crearemos un Stack Bookshelf API que utiliza bases de datos, puntos finales, autenticación de usuarios, tokens, representación de plantillas del lado del servidor y más.
A partir de aquí, comience a crear sus propias aplicaciones de Node, lea la documentación de Node, salga y encuentre API interesantes o Módulos de Node e impleméntelos usted mismo. El mundo está a tu alcance y tienes al alcance de tu mano el acceso a la mayor red de conocimiento del planeta: Internet. Úsalo a tu favor.
Lectura adicional en SmashingMag:
- Comprensión y uso de las API REST
- Nuevas características de JavaScript que cambiarán la forma en que escribe expresiones regulares
- Mantener Node.js rápido: herramientas, técnicas y consejos para crear servidores Node.js de alto rendimiento
- Creación de un chatbot de IA simple con Web Speech API y Node.js