
Tutorial de aprendizaje automático: aprenda ML desde cero
Publicado: 2022-02-17La implementación de soluciones de inteligencia artificial (IA) y aprendizaje automático (ML) continúa avanzando en varios procesos comerciales , siendo la mejora de la experiencia del cliente el principal caso de uso.
Hoy en día, el aprendizaje automático tiene una amplia gama de aplicaciones, y la mayoría de ellas son tecnologías con las que nos encontramos a diario. Por ejemplo, Netflix o plataformas OTT similares utilizan el aprendizaje automático para personalizar las sugerencias para cada usuario. Por lo tanto, si un usuario mira con frecuencia novelas policíacas o busca lo mismo, el sistema de recomendaciones basado en ML de la plataforma comenzará a sugerir más películas de un género similar. Del mismo modo, Facebook e Instagram personalizan el feed de un usuario en función de las publicaciones con las que interactúan con frecuencia.
En este tutorial de aprendizaje automático de Python , nos sumergiremos en los conceptos básicos del aprendizaje automático. También hemos incluido un breve tutorial de aprendizaje profundo para presentar el concepto a los principiantes.
Tabla de contenido
¿Qué es el aprendizaje automático?
El término "aprendizaje automático" fue acuñado en 1959 por Arthur Samuel, un pionero en juegos de computadora e inteligencia artificial.
El aprendizaje automático es un subconjunto de la inteligencia artificial. Se basa en el concepto de que el software (programas) puede aprender de los datos, descifrar patrones y tomar decisiones con una mínima interferencia humana. En otras palabras, ML es un área de la ciencia computacional que permite a un usuario alimentar una enorme cantidad de datos a un algoritmo y hacer que el sistema analice y tome decisiones basadas en datos basados en los datos de entrada. Por lo tanto, los algoritmos de ML no se basan en un modelo predeterminado y, en cambio, "aprenden" información directamente de los datos alimentados.
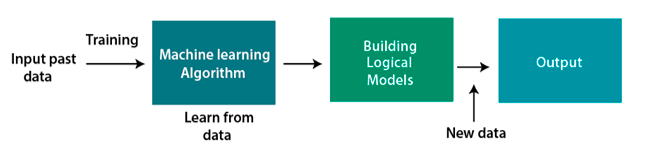
Fuente

Aquí hay un ejemplo simplificado:
¿Cómo escribimos un programa que identifique las flores según el color, la forma de los pétalos u otras propiedades? Si bien la forma más obvia sería crear reglas de identificación estrictas, tal enfoque no hará que las reglas ideales sean aplicables en todos los casos. Sin embargo, el aprendizaje automático toma una estrategia más práctica y robusta y, en lugar de hacer reglas predeterminadas, entrena el sistema alimentándolo con datos (imágenes) de diferentes flores. Por lo tanto, la próxima vez que se le muestre al sistema una rosa y un girasol, puede clasificarlos según la experiencia previa.
Lea Cómo aprender aprendizaje automático: paso a paso
Tipos de aprendizaje automático
La clasificación del aprendizaje automático se basa en cómo un algoritmo aprende a ser más preciso en la predicción de resultados. Por lo tanto, existen tres enfoques básicos para el aprendizaje automático: aprendizaje supervisado, aprendizaje no supervisado y aprendizaje por refuerzo.
Aprendizaje supervisado
En el aprendizaje automático supervisado, los algoritmos se suministran con datos de entrenamiento etiquetados. Además, el usuario define las variables que quiere que evalúe el algoritmo; las variables objetivo son las variables que queremos predecir y las características son las variables que nos ayudan a predecir el objetivo. Entonces, es más como mostrarle al algoritmo la imagen de un pez y decir, "es un pez", y luego mostramos una rana y señalamos que es una rana. Luego, cuando el algoritmo haya sido entrenado con suficientes datos de peces y ranas, aprenderá a diferenciarlos.
Aprendizaje sin supervisión
El aprendizaje automático no supervisado implica algoritmos que aprenden de datos de entrenamiento no etiquetados. Por lo tanto, solo existen las características (variables de entrada) y no hay variables de destino. Los problemas de aprendizaje no supervisados incluyen el agrupamiento, donde las variables de entrada con las mismas características se agrupan y asocian para descifrar relaciones significativas dentro del conjunto de datos. Un ejemplo de agrupamiento es agrupar a las personas en fumadores y no fumadores. Por el contrario, descubrir que los clientes que usan teléfonos inteligentes también comprarán fundas para teléfonos es una asociación.
Aprendizaje reforzado
El aprendizaje por refuerzo es una técnica basada en feeds en la que los modelos de aprendizaje automático aprenden a tomar una serie de decisiones en función de los comentarios que reciben por sus acciones. Por cada buena acción, la máquina recibe retroalimentación positiva, y por cada mala, recibe una penalización o retroalimentación negativa. Entonces, a diferencia del aprendizaje automático supervisado, un modelo reforzado aprende automáticamente usando retroalimentación en lugar de datos etiquetados.
Lea también, ¿Qué es el aprendizaje automático y por qué es importante?
¿Por qué usar Python para el aprendizaje automático?
Los proyectos de aprendizaje automático difieren de los proyectos de software tradicionales en que los primeros involucran distintos conjuntos de habilidades, pilas de tecnología e investigación profunda. Por lo tanto, implementar un proyecto exitoso de aprendizaje automático requiere un lenguaje de programación que sea estable, flexible y ofrezca herramientas robustas. Python lo ofrece todo, por lo que en su mayoría vemos proyectos de aprendizaje automático basados en Python.
Independencia de la plataforma
La popularidad de Python se debe en gran parte al hecho de que es un lenguaje independiente de la plataforma y es compatible con la mayoría de las plataformas, incluidas Windows, macOS y Linux. Por lo tanto, los desarrolladores pueden crear programas ejecutables independientes en una plataforma y distribuirlos a otros sistemas operativos sin necesidad de un intérprete de Python. Por lo tanto, entrenar modelos de aprendizaje automático se vuelve más manejable y económico.

Simplicidad y flexibilidad
Detrás de cada modelo de aprendizaje automático hay algoritmos y flujos de trabajo complejos que pueden resultar intimidantes y abrumadores para los usuarios. Pero el código conciso y legible de Python permite a los desarrolladores centrarse en el modelo de aprendizaje automático en lugar de preocuparse por los aspectos técnicos del lenguaje. Además, Python es fácil de aprender y puede manejar tareas complicadas de aprendizaje automático, lo que resulta en una construcción y prueba rápida de prototipos.
Una amplia selección de marcos y bibliotecas.
Python ofrece una amplia selección de marcos y bibliotecas que reducen significativamente el tiempo de desarrollo. Estas bibliotecas tienen códigos preescritos que los desarrolladores usan para realizar tareas generales de programación. El repertorio de herramientas de software de Python incluye Scikit-learn, TensorFlow y Keras para aprendizaje automático, Pandas para análisis de datos de propósito general, NumPy y SciPy para análisis de datos y computación científica, Seaborn para visualización de datos y más.
Aprenda también el preprocesamiento de datos en el aprendizaje automático: 7 pasos sencillos a seguir
Pasos para implementar un proyecto de aprendizaje automático de Python
Si es nuevo en el aprendizaje automático, la mejor manera de aceptar un proyecto es enumerar los pasos clave que debe cubrir. Una vez que tenga los pasos, puede usarlos como plantilla para conjuntos de datos subsiguientes, llenando vacíos y modificando su flujo de trabajo a medida que avanza en etapas avanzadas.
Aquí hay una descripción general de cómo implementar un proyecto de aprendizaje automático con Python:
- Define el problema.
- Instale Python y SciPy.
- Cargue el conjunto de datos.
- Resume el conjunto de datos.
- Visualice el conjunto de datos.
- Evaluar algoritmos.
- Hacer predicciones.
- Presentar resultados.
¿Qué es una red de aprendizaje profundo?
Las redes de aprendizaje profundo o redes neuronales profundas (DNN) son una rama del aprendizaje automático basado en la imitación del cerebro humano. Las DNN comprenden unidades que combinan múltiples entradas para producir una sola salida. Son análogas a las neuronas biológicas que reciben múltiples señales a través de las sinapsis y envían un único flujo de un potencial de acción por su neurona.
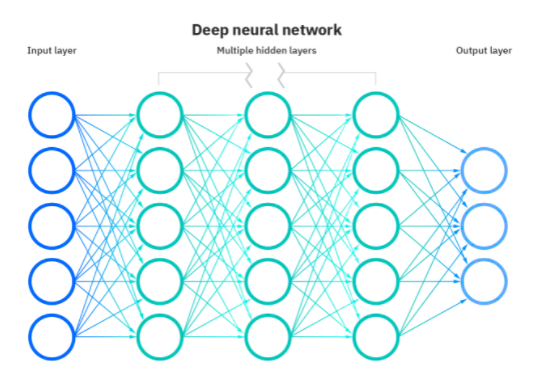
Fuente
En una red neuronal, la funcionalidad similar al cerebro se logra a través de capas de nodos que consisten en una capa de entrada, una o varias capas ocultas y una capa de salida. Cada neurona o nodo artificial tiene un umbral y un peso asociados y se conecta a otro. Cuando la salida de un nodo está por encima del valor de umbral definido, se activa y envía datos a la siguiente capa de la red.
Las DNN dependen de los datos de entrenamiento para aprender y ajustar su precisión con el tiempo. Constituyen herramientas robustas de inteligencia artificial, que permiten la clasificación y agrupación de datos a altas velocidades. Dos de los dominios de aplicación más comunes de las redes neuronales profundas son el reconocimiento de imágenes y el reconocimiento de voz.
camino a seguir
Ya sea para desbloquear un teléfono inteligente con Face ID, buscar películas o buscar un tema aleatorio en Google, los consumidores modernos y digitales exigen recomendaciones más sencillas y una mejor personalización. Independientemente de la industria o el dominio, la IA ha desempeñado y continúa desempeñando un papel importante en la mejora de la experiencia del usuario. Además de eso, la simplicidad y la versatilidad de Python han hecho que el desarrollo, la implementación y el mantenimiento de proyectos de IA sean convenientes y eficientes en todas las plataformas.
Aprenda el curso ML de las mejores universidades del mundo. Obtenga programas de maestría, PGP ejecutivo o certificado avanzado para acelerar su carrera.
Si encontró interesante este tutorial de aprendizaje automático de Python para principiantes, profundice en el tema con la Maestría en Ciencias en Aprendizaje Automático e IA de upGrad . El programa en línea está diseñado para profesionales que trabajan y buscan aprender habilidades avanzadas de inteligencia artificial, como PNL, aprendizaje profundo, aprendizaje reforzado y más.
Puntos destacados del curso:
- Maestría en LJMU
- Ejecutivo PGP de IIIT Bangalore
- Más de 750 horas de contenido
- Más de 40 sesiones en vivo
- Más de 12 estudios de casos y proyectos
- 11 asignaciones de codificación
- Cobertura detallada de 20 herramientas, idiomas y bibliotecas
- Asistencia profesional de 360 grados
1. ¿Python es bueno para el aprendizaje automático?
Python es uno de los mejores lenguajes de programación para implementar modelos de aprendizaje automático. Python atrae tanto a los desarrolladores como a los principiantes debido a su simplicidad, flexibilidad y suave curva de aprendizaje. Además, Python es independiente de la plataforma y tiene acceso a bibliotecas y marcos que hacen que la creación y prueba de modelos de aprendizaje automático sean más rápidas y sencillas.
2. ¿Es difícil el aprendizaje automático con Python?
Debido a la gran popularidad de Python como lenguaje de programación de propósito general y su adopción en el aprendizaje automático y la computación científica, encontrar un tutorial de aprendizaje automático de Python es bastante fácil. Además, la suave curva de aprendizaje, el código legible y preciso de Python lo convierten en un lenguaje de programación fácil de usar para principiantes.
3. ¿Es lo mismo IA y aprendizaje automático?
Aunque los términos IA y aprendizaje automático a menudo se usan indistintamente, no son lo mismo. La inteligencia artificial (IA) es el término general para la rama de la informática que se ocupa de las máquinas capaces de realizar tareas que normalmente realizan los humanos. Pero el aprendizaje automático es un subconjunto de la IA donde las máquinas reciben datos y se entrenan para tomar decisiones basadas en los datos de entrada.