
15 preguntas y respuestas de la entrevista de aprendizaje automático para 2022
Publicado: 2021-01-08¿Eres alguien que desea hacer una carrera exitosa en Machine Learning? Si es así, ¡genial para ti!
Pero primero, debe prepararse para romper el hielo: la entrevista de ML.
Dado que el proceso de preparación para una entrevista puede ser abrumador, hemos decidido intervenir: ¡aquí hay una lista seleccionada de las 15 preguntas más frecuentes en las entrevistas de aprendizaje automático!
- ¿Cuál es la diferencia entre el aprendizaje profundo y el aprendizaje automático?
Mientras que Machine Learning implica la aplicación y el uso de algoritmos avanzados para analizar datos, descubrir los patrones ocultos dentro de los datos y aprender de ellos, y finalmente aplicar los conocimientos aprendidos para tomar decisiones comerciales informadas. En cuanto al aprendizaje profundo, es un subconjunto del aprendizaje automático que implica el uso de redes neuronales artificiales que se inspiran en la estructura de la red neuronal del cerebro humano. Deep Learning es ampliamente utilizado en la detección de características.
- Definir: precisión y recuperación.
La precisión o el valor predictivo positivo mide o, más precisamente, predice el número de verdaderos positivos declarados por un modelo en comparación con el número de positivos que realmente declara.
La tasa de recuperación o de verdaderos positivos se refiere a la cantidad de positivos declarados por un modelo en comparación con la cantidad real de positivos presentes en todos los datos.

Únase al curso de aprendizaje automático en línea de las mejores universidades del mundo: maestrías, programas ejecutivos de posgrado y programa de certificado avanzado en ML e IA para acelerar su carrera.
- Explique los términos "sesgo" y "varianza". '
Durante el proceso de entrenamiento, el error esperado de un algoritmo de aprendizaje generalmente se clasifica o descompone en dos partes: sesgo y varianza. Mientras que 'sesgo' es una situación de error causada por el uso de suposiciones simples en el algoritmo de aprendizaje, 'varianza' denota un error causado por la complejidad de ese algoritmo de aprendizaje en el análisis de datos. El sesgo mide la proximidad del clasificador promedio creado por el algoritmo de aprendizaje a la función de destino, y la varianza mide cuánto varía la predicción del algoritmo de aprendizaje para diferentes conjuntos de datos de entrenamiento.
- ¿Cómo funciona una curva ROC?
La ROC o la curva característica operativa del receptor es una representación gráfica de la variación entre las tasas de verdaderos positivos y las tasas de falsos positivos en diferentes umbrales. Es una herramienta fundamental para la evaluación de pruebas de diagnóstico y, a menudo, se utiliza como una representación de la compensación entre la sensibilidad del modelo (verdaderos positivos) y la probabilidad de activar falsas alarmas (falsos positivos).
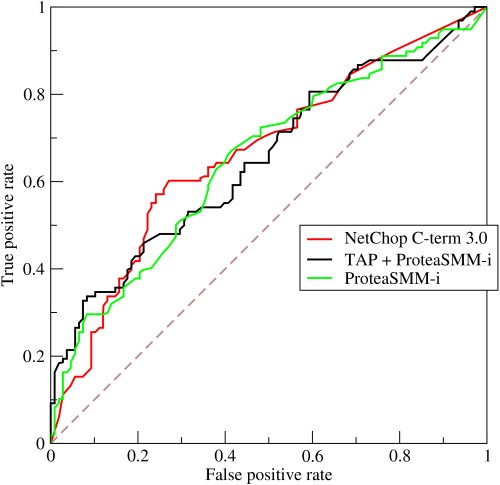
Fuente
- La curva representa el compromiso entre sensibilidad y especificidad: si la sensibilidad aumenta, la especificidad disminuirá.
- Si la curva bordea más hacia el eje izquierdo y la parte superior del espacio ROC, la prueba suele ser más precisa. Sin embargo, si la curva se acerca a la diagonal de 45 grados del espacio ROC, la prueba es menos precisa o confiable.
- La pendiente de la línea tangente en un punto de corte indica la Relación de Verosimilitud (LR) para ese valor particular de la prueba.
- El área bajo la curva mide la precisión de la prueba.
- Explique la diferencia entre los errores de tipo 1 y tipo 2.
El error de tipo 1 es un error de falso positivo que 'afirma' que se ha producido un incidente cuando, de hecho, no ha ocurrido nada. El mejor ejemplo de un error de falso positivo es una falsa alarma de incendio: la alarma comienza a sonar cuando no hay incendio. Al contrario de esto, un error de Tipo 2 es un error falso negativo que 'afirma' que no ha ocurrido nada cuando definitivamente ha ocurrido algo. Sería un error tipo 2 decirle a una mujer embarazada que no está embarazada.
- ¿Por qué se hace referencia a Bayes como "Naive Bayes"?
Naive Bayes se denomina "ingenuo" porque, aunque tiene muchas aplicaciones prácticas, se basa en la suposición de que es imposible encontrar datos de la vida real: todas las características de un conjunto de datos son cruciales, independientes e iguales. En el enfoque Naive Bayes, la probabilidad condicional se calcula como el producto puro de las probabilidades de los componentes individuales, lo que implica la total independencia de las características. Desafortunadamente, esta suposición nunca se puede cumplir en un escenario del mundo real.
- ¿Qué significa el término 'Sobreajuste'? ¿Puedes evitarlo? ¿Si es así, cómo?
Por lo general, durante el proceso de entrenamiento, un modelo recibe grandes cantidades de datos. En el transcurso del proceso, los datos comienzan a aprender incluso de la información inexacta y el ruido presente en el conjunto de datos de muestra. Esto crea una influencia negativa en el rendimiento del modelo con los nuevos datos, es decir, el modelo no puede clasificar con precisión las nuevas instancias/datos aparte de los del conjunto de entrenamiento. Esto se conoce como sobreajuste.
Sí, es posible evitar el Overfitting. Así es cómo:
- Recopile más datos (de fuentes dispares) para entrenar el modelo con diferentes muestras.
- Aplique métodos de ensamblaje (por ejemplo, Random Forest) que utilicen el enfoque de embolsado para minimizar la variación en las predicciones al yuxtaponer los resultados de múltiples árboles de decisión en diferentes unidades del conjunto de datos.
- Asegúrese de utilizar técnicas de validación cruzada.
- Mencione los dos métodos utilizados para la calibración en el aprendizaje supervisado.
Los dos métodos de calibración en el aprendizaje supervisado son: calibración de Platt y regresión isotónica. Ambos métodos están diseñados específicamente para la clasificación binaria.
- ¿Por qué se poda un árbol de decisión?
Los árboles de decisión deben podarse para deshacerse de las ramas con capacidades predictivas débiles. Esto ayuda a minimizar el cociente de complejidad del modelo de árbol de decisión y optimizar su precisión predictiva. La poda se puede hacer de arriba hacia abajo o de abajo hacia arriba. La poda de errores reducidos, la poda de complejidad de costos, la poda de complejidad de errores y la poda de errores mínimos son algunos de los métodos de poda de árboles de decisión más utilizados.

- ¿Qué se entiende por puntuación F1?
En términos simples, la puntuación F1 es una medida del rendimiento de un modelo: un promedio de la precisión y la recuperación de un modelo, siendo los resultados cercanos a 1 los mejores y los cercanos a 0 los peores. La puntuación F1 se puede utilizar en pruebas de clasificación que no dan importancia a los verdaderos negativos.
- Diferenciar entre un algoritmo Generativo y Discriminativo.
Mientras que un algoritmo generativo aprende las categorías de datos, un algoritmo discriminativo aprende la distinción entre diferentes categorías de datos. Cuando se trata de tareas de clasificación, los modelos discriminativos normalmente superan a los modelos generativos.
- ¿Qué es el aprendizaje conjunto?
Ensemble Learning utiliza una combinación de algoritmos de aprendizaje para optimizar el rendimiento predictivo de los modelos. En este método, múltiples modelos como clasificadores o expertos se generan y combinan estratégicamente para evitar el sobreajuste en los modelos. Se utiliza principalmente para mejorar la predicción, la clasificación, la aproximación de funciones, el rendimiento, etc., de un modelo.
- Defina 'Truco del núcleo'.
El método Kernel Trick implica el uso de funciones kernel que pueden operar en un espacio de características implícito y de mayor dimensión sin tener que calcular las coordenadas de los puntos dentro de esa dimensión explícitamente. Las funciones del núcleo calculan los productos internos entre las imágenes de todos los pares de datos presentes en un espacio de características. Este procedimiento es computacionalmente más barato en comparación con el cálculo explícito de las coordenadas y se conoce como Kernel Trick.
- ¿Cómo debe manejar los datos perdidos o dañados en un conjunto de datos?
Para encontrar los datos que faltan o están dañados en un conjunto de datos, debe eliminar las filas y columnas o reemplazarlas con otros valores. La biblioteca de Pandas tiene dos excelentes métodos para encontrar datos perdidos o dañados: isnull() y dropna(). Ambas funciones están diseñadas específicamente para ayudarlo a encontrar las filas/columnas de datos con datos faltantes/corruptos y descartar esos valores.
- ¿Qué es una tabla hash?
Una tabla hash es una estructura de datos que crea una matriz asociativa, en la que una clave se asigna a valores específicos mediante una función hash. Las tablas hash se utilizan principalmente en la indexación de bases de datos.
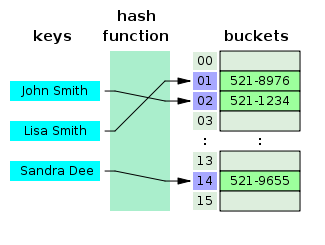
Fuente
Esta lista de preguntas solo pretende presentarle los conceptos básicos del aprendizaje automático y, francamente, estas veinte preguntas son solo una gota en el mar. El aprendizaje automático avanza mientras hablamos y, por lo tanto, con el tiempo, surgirán nuevos conceptos. La clave para clavar sus entrevistas de ML, por lo tanto, radica en albergar un impulso constante de aprender y mejorar. Entonces, comience y navegue por Internet, lea revistas, únase a comunidades en línea, asista a conferencias y seminarios de ML: hay muchas maneras de aprender.
Para ingresar a una gran organización, es esencial un certificado de una institución de renombre. Consulte el programa Executive PG de IIIT-B en aprendizaje automático e inteligencia artificial y obtenga asistencia laboral de las principales firmas de aprendizaje automático e inteligencia artificial.
¿Cuáles son las limitaciones del aprendizaje en conjunto?
Los enfoques de conjunto pueden ayudar en la reducción de la varianza y el desarrollo de modelos más robustos. Sin embargo, existen ciertos inconvenientes en el uso de técnicas de conjunto, como la falta de explicación y rendimiento. Además, tenga en cuenta que la eficacia de los conjuntos se origina en su capacidad para agregar múltiples modelos que se centran en diferentes aspectos del problema. Sin embargo, tienen un período de pronóstico más largo porque es posible que necesite pronósticos de cientos de modelos. Incluso si tienen mejores proyecciones, la ganancia en precisión puede no valer la pena.
¿Cuánto tiempo se necesita para aprender Machine Learning?
Cuando se trata de Machine Learning, las tecnologías complejas utilizadas para el mismo pueden asustar fácilmente a las personas. Sin embargo, entenderlo poco a poco no es difícil. La experiencia previa en estadística, matemáticas avanzadas, etc., sin duda lo ayudará a comprender rápidamente todos los conceptos. Sin embargo, debido a que los antecedentes educativos y las habilidades varían de una persona a otra, una persona puede aprender ML en tres semanas, mientras que otra puede necesitar un año.
¿Cómo se está utilizando el Machine Learning en nuestro día a día?
Gmail clasifica los correos electrónicos como esenciales clasificándolos como Principales, Promociones, Sociales y Actualizar mediante Machine Learning. Las empresas están utilizando redes neuronales para detectar transacciones fraudulentas en función de datos como la última frecuencia de transacciones, el monto de la transacción y el tipo de comerciante. Los detectores de plagio también hacen uso del aprendizaje automático. Cuando se trata de ingeniería de ML, se tarda unos seis meses en terminar.