
Clasificador KNN para aprendizaje automático: todo lo que necesita saber
Publicado: 2021-09-28¿Recuerdas la época en que la inteligencia artificial (IA) era solo un concepto limitado a las novelas y películas de ciencia ficción? Bueno, gracias al avance tecnológico, la IA es algo con lo que ahora vivimos todos los días. Desde que Alexa y Siri están a nuestra entera disposición hasta las plataformas OTT que "seleccionan a mano" las películas que nos gustaría ver, la IA casi se ha convertido en la orden del día y está aquí para decir en el futuro previsible.
Todo esto es posible gracias a los algoritmos avanzados de ML. Hoy, vamos a hablar sobre uno de esos algoritmos ML útiles, el clasificador K-NN.
Una rama de la IA y la informática, el aprendizaje automático utiliza datos y algoritmos para imitar la comprensión humana mientras mejora gradualmente la precisión de los algoritmos. El aprendizaje automático implica entrenar algoritmos para hacer predicciones o clasificaciones y descubrir información clave que impulse la toma de decisiones estratégicas dentro de las empresas y las aplicaciones.
El algoritmo KNN (k-vecino más cercano) es un algoritmo fundamental de aprendizaje automático supervisado que se utiliza para resolver declaraciones de problemas de regresión y clasificación. Entonces, profundicemos para saber más sobre K-NN Classifier.
Tabla de contenido
Aprendizaje automático supervisado vs no supervisado
El aprendizaje supervisado y no supervisado son dos enfoques básicos de ciencia de datos, y es pertinente conocer la diferencia antes de entrar en los detalles de KNN.
El aprendizaje supervisado es un enfoque de aprendizaje automático que utiliza conjuntos de datos etiquetados para ayudar a predecir los resultados. Dichos conjuntos de datos están diseñados para "supervisar" o entrenar algoritmos para predecir resultados o clasificar datos con precisión. Por lo tanto, las entradas y salidas etiquetadas permiten que el modelo aprenda con el tiempo mientras mejora su precisión.

El aprendizaje supervisado implica dos tipos de problemas: clasificación y regresión. En los problemas de clasificación , los algoritmos asignan datos de prueba en categorías discretas, como separar gatos de perros.
Un ejemplo significativo de la vida real sería clasificar los correos no deseados en una carpeta separada de su bandeja de entrada. Por otro lado, el método de regresión de aprendizaje supervisado entrena algoritmos para comprender la relación entre variables independientes y dependientes. Utiliza diferentes puntos de datos para predecir valores numéricos, como proyectar los ingresos por ventas de una empresa.
El aprendizaje no supervisado , por el contrario, utiliza algoritmos de aprendizaje automático para el análisis y la agrupación de conjuntos de datos no etiquetados. Por lo tanto, no hay necesidad de intervención humana ("sin supervisión") para que los algoritmos identifiquen patrones ocultos en los datos.
Los modelos de aprendizaje no supervisados tienen tres aplicaciones principales: asociación, agrupación y reducción de la dimensionalidad. Sin embargo, no entraremos en detalles ya que está más allá de nuestro alcance de discusión.
K-vecino más cercano (KNN)
El algoritmo K-Nearest Neighbor o KNN es un algoritmo de aprendizaje automático basado en el modelo de aprendizaje supervisado. El algoritmo K-NN funciona asumiendo que existen cosas similares cerca unas de otras. Por lo tanto, el algoritmo K-NN utiliza la similitud de características entre los nuevos puntos de datos y los puntos del conjunto de entrenamiento (casos disponibles) para predecir los valores de los nuevos puntos de datos. En esencia, el algoritmo K-NN asigna un valor al último punto de datos en función de su similitud con los puntos del conjunto de entrenamiento. El algoritmo K-NN encuentra aplicación tanto en problemas de clasificación como de regresión, pero se usa principalmente para problemas de clasificación.
Aquí hay un ejemplo para entender el Clasificador K-NN.

Fuente
En la imagen de arriba, el valor de entrada es una criatura con similitudes tanto con un gato como con un perro. Sin embargo, queremos clasificarlo en un gato o un perro. Entonces, podemos usar el algoritmo K-NN para esta clasificación. El modelo K-NN encontrará similitudes entre el nuevo conjunto de datos (entrada) y las imágenes de gatos y perros disponibles (conjunto de datos de entrenamiento). Posteriormente, el modelo colocará el nuevo punto de datos en la categoría de gato o perro en función de las características más similares.
Asimismo, la categoría A (puntos verdes) y la categoría B (puntos naranjas) tienen el ejemplo gráfico anterior. También tenemos un nuevo punto de datos (punto azul) que se incluirá en cualquiera de las categorías. Podemos resolver este problema de clasificación usando un algoritmo K-NN e identificar la nueva categoría de puntos de datos.
Definición de propiedades del algoritmo K-NN
Las siguientes dos propiedades definen mejor el algoritmo K-NN:
- Es un algoritmo de aprendizaje perezoso porque en lugar de aprender del conjunto de entrenamiento inmediatamente, el algoritmo K-NN almacena el conjunto de datos y entrena a partir del conjunto de datos en el momento de la clasificación.
- K-NN también es un algoritmo no paramétrico , lo que significa que no hace suposiciones sobre los datos subyacentes.
Funcionamiento del algoritmo K-NN
Ahora, echemos un vistazo a los siguientes pasos para comprender cómo funciona el algoritmo K-NN.
Paso 1: Cargue los datos de entrenamiento y prueba.
Paso 2: Elija los puntos de datos más cercanos, es decir, el valor de K.
Paso 3: Calcule la distancia de K número de vecinos (la distancia entre cada fila de datos de entrenamiento y datos de prueba). El método euclidiano es el más utilizado para calcular la distancia.
Paso 4: Tome los K vecinos más cercanos en función de la distancia euclidiana calculada.
Paso 5: entre los vecinos K más cercanos, cuente la cantidad de puntos de datos en cada categoría.
Paso 6: asigne los nuevos puntos de datos a esa categoría para la cual el número de vecinos es máximo.
Paso 7: Fin. El modelo ya está listo.
Únase a los cursos de inteligencia artificial en línea de las mejores universidades del mundo: maestrías, programas ejecutivos de posgrado y programa de certificado avanzado en ML e IA para acelerar su carrera.
Elegir el valor de K
K es un parámetro crítico en el algoritmo K-NN. Por lo tanto, debemos tener en cuenta algunos puntos antes de decidir el valor de K.
El uso de curvas de error es un método común para determinar el valor de K. La siguiente imagen muestra curvas de error para diferentes valores de K para datos de prueba y entrenamiento.


Fuente
En el ejemplo gráfico anterior, el error de tren es cero en K=1 en los datos de entrenamiento porque el vecino más cercano al punto es ese mismo punto. Sin embargo, el error de prueba es alto incluso con valores bajos de K. Esto se denomina varianza alta o sobreajuste de datos. El error de prueba se reduce a medida que aumentamos el valor de K., pero a partir de cierto valor de K, vemos que el error de prueba vuelve a aumentar, lo que se denomina sesgo o subajuste. Por lo tanto, el error de los datos de prueba es inicialmente alto debido a la varianza, luego disminuye y se estabiliza, y con un mayor aumento en el valor de K, el error de prueba vuelve a dispararse debido al sesgo.
Por lo tanto, el valor de K en el que el error de prueba se estabiliza y es bajo se toma como el valor óptimo de K. Teniendo en cuenta la curva de error anterior, K=8 es el valor óptimo.
Un ejemplo para comprender el funcionamiento del algoritmo K-NN
Considere un conjunto de datos que se ha trazado de la siguiente manera:

Fuente
Digamos que hay un nuevo punto de datos (punto negro) en (60,60) que tenemos que clasificar en la clase morada o roja. Usaremos K=3, lo que significa que el nuevo punto de datos encontrará los tres puntos de datos más cercanos, dos en la clase roja y uno en la clase morada.
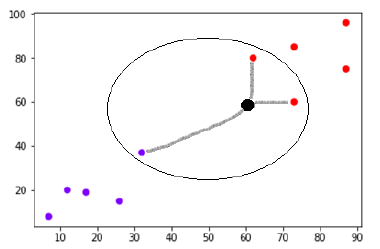
Fuente
Los vecinos más cercanos se determinan calculando la distancia euclidiana entre dos puntos. Aquí hay una ilustración para mostrar cómo se hace el cálculo.

Fuente
Ahora, dado que dos (de los tres) de los vecinos más cercanos del nuevo punto de datos (punto negro) se encuentran en la clase roja, el nuevo punto de datos también se asignará a la clase roja.
Únase al curso de aprendizaje automático en línea de las mejores universidades del mundo: maestrías, programas ejecutivos de posgrado y programa de certificado avanzado en ML e IA para acelerar su carrera.
K-NN como Clasificador (Implementación en Python)
Ahora que hemos tenido una explicación simplificada del algoritmo K-NN, pasemos a implementar el algoritmo K-NN en Python. Solo nos centraremos en el clasificador K-NN.
Paso 1: Importe los paquetes de Python necesarios.

Fuente
Paso 2: descargue el conjunto de datos de iris del repositorio de aprendizaje automático de UCI. Su enlace web es "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"
Paso 3: asigne nombres de columna al conjunto de datos.

Fuente
Paso 4: Lea el conjunto de datos en Pandas DataFrame.

Fuente
Paso 5: el preprocesamiento de datos se realiza mediante las siguientes líneas de script.

Fuente
Paso 6: Divida el conjunto de datos en prueba y entrenamiento dividido. El siguiente código dividirá el conjunto de datos en un 40 % de datos de prueba y un 60 % de datos de entrenamiento.

Fuente
Paso 7: el escalado de datos se realiza de la siguiente manera:

Fuente
Paso 8: entrenar el modelo utilizando la clase KNeighborsClassifier de sklearn.

Fuente
Paso 9: Haz una predicción usando el siguiente script:

Fuente
Paso 10: Imprime los resultados.

Fuente
Producción:

Fuente
¿Qué sigue? Regístrese para el programa de certificado avanzado en aprendizaje automático de IIT Madras y upGrad
Suponga que aspira a convertirse en un experto en ciencia de datos o en un profesional del aprendizaje automático. En ese caso, ¡el Curso de Certificación Avanzada en Aprendizaje Automático y Nube de IIT Madras y upGrad es solo para usted!
El programa en línea de 12 meses está especialmente diseñado para profesionales en activo que buscan dominar los conceptos de Machine Learning, Big Data Processing, Data Management, Data Warehousing, Cloud e implementación de modelos de Machine Learning.
Aquí hay algunos aspectos destacados del curso para darle una mejor idea de lo que ofrece el programa:
- Prestigiosa certificación mundialmente aceptada del IIT Madras
- Más de 500 horas de aprendizaje, más de 20 estudios de casos y proyectos, más de 25 sesiones de tutoría de la industria, más de 8 asignaciones de codificación
- Cobertura completa de 7 lenguajes y herramientas de programación
- 4 semanas de proyecto final de la industria
- Talleres prácticos prácticos
- Redes de igual a igual sin conexión
¡Regístrese hoy para obtener más información sobre el programa!
Conclusión
Con el tiempo, Big Data continúa creciendo y la inteligencia artificial se entrelaza cada vez más con nuestras vidas. Como resultado, existe un fuerte aumento en la demanda de profesionales de la ciencia de datos que puedan aprovechar el poder de los modelos de aprendizaje automático para recopilar información y mejorar los procesos comerciales críticos y, en general, nuestro mundo. Sin duda, el campo de la inteligencia artificial y el aprendizaje automático parece prometedor. ¡ Con upGrad , puede estar seguro de que su carrera en el aprendizaje automático y la nube es gratificante!
¿Por qué K-NN es un buen clasificador?
La principal ventaja de K-NN sobre otros algoritmos de aprendizaje automático es que podemos usar convenientemente K-NN para la clasificación multiclase. Por lo tanto, K-NN es el mejor algoritmo si necesitamos clasificar datos en más de dos categorías o si los datos comprenden más de dos etiquetas. Además, es ideal para datos no lineales y tiene una precisión relativamente alta.
¿Cuál es la limitación del algoritmo K-NN?
El algoritmo K-NN funciona calculando la distancia entre los puntos de datos. Por lo tanto, es bastante obvio que es un algoritmo que consume relativamente más tiempo y llevará más tiempo clasificarlo en algunos casos. Por lo tanto, es mejor no usar demasiados puntos de datos mientras usa K-NN para la clasificación multiclase. Otras limitaciones incluyen el alto almacenamiento de memoria y la sensibilidad a funciones irrelevantes.
¿Cuáles son las aplicaciones del mundo real de K-NN?
K-NN tiene varios casos de uso de la vida real en el aprendizaje automático, como la detección de escritura a mano, el reconocimiento de voz, el reconocimiento de video y el reconocimiento de imágenes. En la banca, K-NN se utiliza para predecir si una persona es elegible para un préstamo en función de si tiene características similares a las de los morosos. En política, K-NN se puede usar para clasificar a los votantes potenciales en diferentes clases, como "votará por el partido X" o "votará por el partido Y", etc.