
Introducción a la API basada en componentes
Publicado: 2022-03-10Este artículo se actualizó el 31 de enero de 2019 para responder a los comentarios de los lectores. El autor agregó capacidades de consulta personalizada a la API basada en componentes y describe cómo funciona .
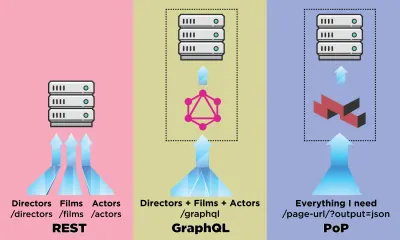
Una API es el canal de comunicación para que una aplicación cargue datos desde el servidor. En el mundo de las APIs, REST ha sido la metodología más consolidada, pero últimamente se ha visto eclipsada por GraphQL, que ofrece importantes ventajas frente a REST. Mientras que REST requiere múltiples solicitudes HTTP para obtener un conjunto de datos para representar un componente, GraphQL puede consultar y recuperar dichos datos en una sola solicitud, y la respuesta será exactamente lo que se requiere, sin obtener más o menos datos como suele ocurrir en DESCANSO.
En este artículo, describiré otra forma de obtener datos que diseñé y denominé "PoP" (y de código abierto aquí), que amplía la idea de obtener datos para varias entidades en una sola solicitud introducida por GraphQL y lo toma como un un paso más allá, es decir, mientras que REST obtiene los datos de un recurso y GraphQL obtiene los datos de todos los recursos en un componente, la API basada en componentes puede obtener los datos de todos los recursos de todos los componentes en una página.
El uso de una API basada en componentes tiene más sentido cuando el sitio web se construye utilizando componentes, es decir, cuando la página web se compone iterativamente de componentes que envuelven otros componentes hasta que, en la parte superior, obtenemos un único componente que representa la página. Por ejemplo, la página web que se muestra en la imagen a continuación está construida con componentes, que están delineados con cuadrados:
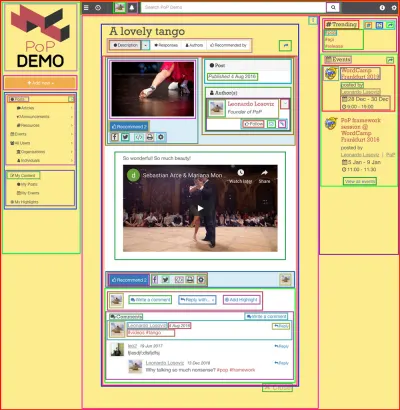
Una API basada en componentes puede realizar una única solicitud al servidor solicitando los datos de todos los recursos de cada componente (así como de todos los componentes de la página), lo que se logra manteniendo las relaciones entre los componentes en la propia estructura de la API.
Entre otros, esta estructura ofrece los siguientes beneficios:
- Una página con muchos componentes activará solo una solicitud en lugar de muchas;
- Los datos compartidos entre los componentes se pueden obtener solo una vez de la base de datos e imprimirse solo una vez en la respuesta;
- Puede reducir en gran medida, incluso eliminar por completo, la necesidad de un almacén de datos.
Los exploraremos en detalle a lo largo del artículo, pero primero, exploremos qué componentes son realmente y cómo podemos construir un sitio basado en dichos componentes y, finalmente, exploremos cómo funciona una API basada en componentes.
Lectura recomendada : Introducción a GraphQL: por qué necesitamos un nuevo tipo de API
Construyendo un sitio a través de componentes
Un componente es simplemente un conjunto de piezas de código HTML, JavaScript y CSS juntas para crear una entidad autónoma. Esto puede luego envolver otros componentes para crear estructuras más complejas y también ser envuelto por otros componentes. Un componente tiene un propósito, que puede variar desde algo muy básico (como un enlace o un botón) hasta algo muy elaborado (como un carrusel o un cargador de imágenes de arrastrar y soltar). Los componentes son más útiles cuando son genéricos y permiten la personalización a través de propiedades inyectadas (o "accesorios"), de modo que puedan servir para una amplia gama de casos de uso. En el caso extremo, el sitio mismo se convierte en un componente.
El término "componente" se usa a menudo para referirse tanto a la funcionalidad como al diseño. Por ejemplo, con respecto a la funcionalidad, los marcos de JavaScript como React o Vue permiten crear componentes del lado del cliente, que pueden auto-renderizarse (por ejemplo, después de que la API obtiene los datos requeridos) y usar accesorios para establecer valores de configuración en su componentes envueltos, lo que permite la reutilización del código. En cuanto al diseño, Bootstrap ha estandarizado cómo se ven y se sienten los sitios web a través de su biblioteca de componentes front-end, y se ha convertido en una tendencia saludable para que los equipos creen sistemas de diseño para mantener sus sitios web, lo que permite que los diferentes miembros del equipo (diseñadores y desarrolladores, pero también mercadólogos y vendedores) para hablar un lenguaje unificado y expresar una identidad consistente.
La creación de componentes en un sitio es una forma muy sensata de hacer que el sitio web sea más fácil de mantener. Los sitios que utilizan marcos de JavaScript como React y Vue ya están basados en componentes (al menos en el lado del cliente). El uso de una biblioteca de componentes como Bootstrap no necesariamente hace que el sitio esté basado en componentes (podría ser una gran cantidad de HTML); sin embargo, incorpora el concepto de elementos reutilizables para la interfaz de usuario.
Si el sitio es una gran mancha de HTML, para que podamos dividirlo en componentes debemos dividir el diseño en una serie de patrones recurrentes, para lo cual debemos identificar y catalogar secciones en la página en función de su similitud de funcionalidad y estilos, y dividir estos las secciones en capas, lo más granular posible, tratando de que cada capa se centre en un solo objetivo o acción, y también tratando de hacer coincidir las capas comunes en diferentes secciones.
Nota : El "Diseño atómico" de Brad Frost es una excelente metodología para identificar estos patrones comunes y construir un sistema de diseño reutilizable.
Por lo tanto, construir un sitio a través de componentes es similar a jugar con LEGO. Cada componente es una funcionalidad atómica, una composición de otros componentes o una combinación de los dos.
Como se muestra a continuación, un componente básico (un avatar) se compone iterativamente de otros componentes hasta obtener la página web en la parte superior:

La especificación API basada en componentes
Para la API basada en componentes que he diseñado, un componente se llama "módulo", por lo que de ahora en adelante los términos "componente" y "módulo" se usan indistintamente.
La relación de todos los módulos que se envuelven entre sí, desde el módulo superior hasta el último nivel, se denomina "jerarquía de componentes". Esta relación se puede expresar a través de una matriz asociativa (una matriz de clave => propiedad) en el lado del servidor, en la que cada módulo establece su nombre como el atributo clave y sus módulos internos bajo los modules de propiedad. Luego, la API simplemente codifica esta matriz como un objeto JSON para el consumo:
// Component hierarchy on server-side, eg through PHP: [ "top-module" => [ "modules" => [ "module-level1" => [ "modules" => [ "module-level11" => [ "modules" => [...] ], "module-level12" => [ "modules" => [ "module-level121" => [ "modules" => [...] ] ] ] ] ], "module-level2" => [ "modules" => [ "module-level21" => [ "modules" => [...] ] ] ] ] ] ] // Component hierarchy encoded as JSON: { "top-module": { modules: { "module-level1": { modules: { "module-level11": { ... }, "module-level12": { modules: { "module-level121": { ... } } } } }, "module-level2": { modules: { "module-level21": { ... } } } } } }La relación entre los módulos se define estrictamente de arriba hacia abajo: un módulo envuelve a otros módulos y sabe quiénes son, pero no sabe, y no le importa, qué módulos lo envuelven a él.
Por ejemplo, en el código JSON anterior, module module-level1 sabe que envuelve módulos module-level11 y module-level12 y, transitivamente, también sabe que envuelve module-level121 ; pero al módulo module-level11 no le importa quién lo envuelve, por lo tanto, no conoce module-level1 .
Con la estructura basada en componentes, ahora podemos agregar la información real requerida por cada módulo, que se clasifica en configuraciones (como valores de configuración y otras propiedades) y datos (como los ID de los objetos de la base de datos consultados y otras propiedades) , y colocado en consecuencia bajo las entradas modulesettings y moduledata :
{ modulesettings: { "top-module": { configuration: {...}, ..., modules: { "module-level1": { configuration: {...}, ..., modules: { "module-level11": { repeat... }, "module-level12": { configuration: {...}, ..., modules: { "module-level121": { repeat... } } } } }, "module-level2": { configuration: {...}, ..., modules: { "module-level21": { repeat... } } } } } }, moduledata: { "top-module": { dbobjectids: [...], ..., modules: { "module-level1": { dbobjectids: [...], ..., modules: { "module-level11": { repeat... }, "module-level12": { dbobjectids: [...], ..., modules: { "module-level121": { repeat... } } } } }, "module-level2": { dbobjectids: [...], ..., modules: { "module-level21": { repeat... } } } } } } } A continuación, la API agregará los datos del objeto de la base de datos. Esta información no se coloca debajo de cada módulo, sino en una sección compartida llamada bases de databases , para evitar la duplicación de información cuando dos o más módulos diferentes obtienen los mismos objetos de la base de datos.
Además, la API representa los datos del objeto de la base de datos de manera relacional, para evitar la duplicación de información cuando dos o más objetos de la base de datos diferentes están relacionados con un objeto común (como dos publicaciones que tienen el mismo autor). En otras palabras, los datos del objeto de la base de datos se normalizan.
Lectura recomendada : Creación de un formulario de contacto sin servidor para su sitio estático
La estructura es un diccionario, organizado bajo cada tipo de objeto en primer lugar y el ID de objeto en segundo lugar, del cual podemos obtener las propiedades del objeto:
{ databases: { primary: { dbobject_type: { dbobject_id: { property: ..., ... }, ... }, ... } } }Este objeto JSON ya es la respuesta de la API basada en componentes. Su formato es una especificación en sí mismo: siempre que el servidor devuelva la respuesta JSON en su formato requerido, el cliente puede consumir la API independientemente de cómo se implemente. Por lo tanto, la API se puede implementar en cualquier idioma (que es una de las bellezas de GraphQL: ser una especificación y no una implementación real ha permitido que esté disponible en una gran cantidad de idiomas).
Nota : en un próximo artículo, describiré mi implementación de la API basada en componentes en PHP (que es la que está disponible en el repositorio).
Ejemplo de respuesta de API
Por ejemplo, la siguiente respuesta de la API contiene una jerarquía de componentes con dos módulos, page => post-feed , donde el módulo post-feed recupera las publicaciones del blog. Tenga en cuenta lo siguiente:
- Cada módulo sabe cuáles son sus objetos consultados de la propiedad
dbobjectids(ID4y9para las publicaciones del blog) - Cada módulo conoce el tipo de objeto para sus objetos consultados de la propiedad
dbkeys(los datos de cada publicación se encuentran enposts, y los datos del autor de la publicación, correspondientes alauthorcon la ID proporcionada en la propiedad de la publicación, se encuentran enusers) - Dado que los datos del objeto de la base de datos son relacionales, la propiedad
authorcontiene el ID del objeto del autor en lugar de imprimir los datos del autor directamente.
{ moduledata: { "page": { modules: { "post-feed": { dbobjectids: [4, 9] } } } }, modulesettings: { "page": { modules: { "post-feed": { dbkeys: { id: "posts", author: "users" } } } } }, databases: { primary: { posts: { 4: { title: "Hello World!", author: 7 }, 9: { title: "Everything fine?", author: 7 } }, users: { 7: { name: "Leo" } } } } }Diferencias en la obtención de datos de API basadas en recursos, basadas en esquemas y basadas en componentes
Veamos cómo se compara una API basada en componentes, como PoP, al obtener datos, con una API basada en recursos, como REST, y con una API basada en esquemas, como GraphQL.
Digamos que IMDB tiene una página con dos componentes que necesitan obtener datos: "Director destacado" (que muestra una descripción de George Lucas y una lista de sus películas) y "Películas recomendadas para ti" (que muestra películas como Star Wars: Episodio I — La amenaza fantasma y Terminator ). Podría verse así:
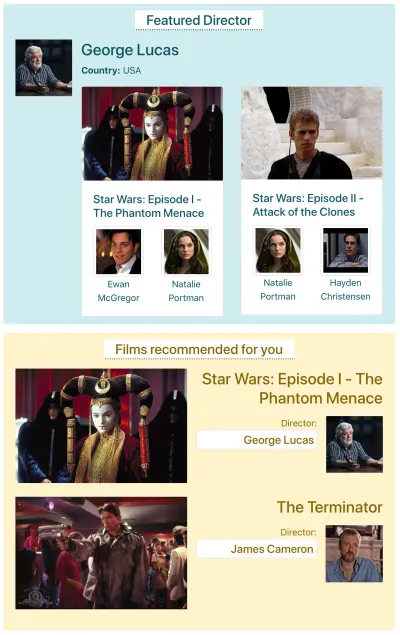
Veamos cuántas solicitudes se necesitan para obtener los datos a través de cada método API. Para este ejemplo, el componente "Director destacado" trae un resultado ("George Lucas"), del cual recupera dos películas ( Star Wars: Episodio I: La amenaza fantasma y Star Wars: Episodio II: El ataque de los clones ), y para cada película dos actores (“Ewan McGregor” y “Natalie Portman” para la primera película, y “Natalie Portman” y “Hayden Christensen” para la segunda película). El componente “Películas recomendadas para ti” trae dos resultados ( Star Wars: Episodio I — La Amenaza Fantasma y Terminator ), y luego trae a sus directores (“George Lucas” y “James Cameron” respectivamente).
Al usar REST para representar featured-director componente, es posible que necesitemos las siguientes 7 solicitudes (este número puede variar según la cantidad de datos proporcionados por cada punto final, es decir, la cantidad de sobrebúsqueda que se ha implementado):
GET - /featured-director GET - /directors/george-lucas GET - /films/the-phantom-menace GET - /films/attack-of-the-clones GET - /actors/ewan-mcgregor GET - /actors/natalie-portman GET - /actors/hayden-christensen GraphQL permite, a través de esquemas fuertemente tipados, obtener todos los datos requeridos en una sola solicitud por componente. La consulta para obtener datos a través de featuredDirector para el componente FeaturedDirector se ve así (después de haber implementado el esquema correspondiente):
query { featuredDirector { name country avatar films { title thumbnail actors { name avatar } } } }Y produce la siguiente respuesta:
{ data: { featuredDirector: { name: "George Lucas", country: "USA", avatar: "...", films: [ { title: "Star Wars: Episode I - The Phantom Menace", thumbnail: "...", actors: [ { name: "Ewan McGregor", avatar: "...", }, { name: "Natalie Portman", avatar: "...", } ] }, { title: "Star Wars: Episode II - Attack of the Clones", thumbnail: "...", actors: [ { name: "Natalie Portman", avatar: "...", }, { name: "Hayden Christensen", avatar: "...", } ] } ] } } }Y la consulta del componente "Películas recomendadas para usted" produce la siguiente respuesta:
{ data: { films: [ { title: "Star Wars: Episode I - The Phantom Menace", thumbnail: "...", director: { name: "George Lucas", avatar: "...", } }, { title: "The Terminator", thumbnail: "...", director: { name: "James Cameron", avatar: "...", } } ] } } PoP emitirá solo una solicitud para obtener todos los datos de todos los componentes de la página y normalizar los resultados. El punto final que se llamará es simplemente el mismo que la URL para la que necesitamos obtener los datos, simplemente agregando un parámetro adicional output=json para indicar traer los datos en formato JSON en lugar de imprimirlos como HTML:
GET - /url-of-the-page/?output=json Suponiendo que la estructura del módulo tiene un módulo superior llamado page que contiene módulos featured-director y films-recommended-for-you , y estos también tienen submódulos, como este:
"page" modules "featured-director" modules "director-films" modules "film-actors" "films-recommended-for-you" modules "film-director"La única respuesta JSON devuelta se verá así:
{ modulesettings: { "page": { modules: { "featured-director": { dbkeys: { id: "people", }, modules: { "director-films": { dbkeys: { films: "films" }, modules: { "film-actors": { dbkeys: { actors: "people" }, } } } } }, "films-recommended-for-you": { dbkeys: { id: "films", }, modules: { "film-director": { dbkeys: { director: "people" }, } } } } } }, moduledata: { "page": { modules: { "featured-director": { dbobjectids: [1] }, "films-recommended-for-you": { dbobjectids: [1, 3] } } } }, databases: { primary: { people { 1: { name: "George Lucas", country: "USA", avatar: "..." films: [1, 2] }, 2: { name: "Ewan McGregor", avatar: "..." }, 3: { name: "Natalie Portman", avatar: "..." }, 4: { name: "Hayden Christensen", avatar: "..." }, 5: { name: "James Cameron", avatar: "..." }, }, films: { 1: { title: "Star Wars: Episode I - The Phantom Menace", actors: [2, 3], director: 1, thumbnail: "..." }, 2: { title: "Star Wars: Episode II - Attack of the Clones", actors: [3, 4], thumbnail: "..." }, 3: { title: "The Terminator", director: 5, thumbnail: "..." }, } } } }Analicemos cómo se comparan estos tres métodos entre sí, en términos de velocidad y la cantidad de datos recuperados.
Velocidad
A través de REST, tener que buscar 7 solicitudes solo para renderizar un componente puede ser muy lento, principalmente en conexiones de datos móviles e inestables. Por lo tanto, el salto de REST a GraphQL representa mucho para la velocidad, porque podemos renderizar un componente con solo una solicitud.
PoP, debido a que puede obtener todos los datos de muchos componentes en una sola solicitud, será más rápido para representar muchos componentes a la vez; sin embargo, lo más probable es que no haya necesidad de esto. Hacer que los componentes se rendericen en orden (tal como aparecen en la página), ya es una buena práctica, y para aquellos componentes que aparecen bajo el pliegue, ciertamente no hay prisa por renderizarlos. Por lo tanto, tanto las API basadas en esquemas como las basadas en componentes ya son bastante buenas y claramente superiores a una API basada en recursos.
La cantidad de datos
En cada solicitud, los datos en la respuesta de GraphQL pueden estar duplicados: la actriz "Natalie Portman" aparece dos veces en la respuesta del primer componente, y al considerar la salida conjunta de los dos componentes, también podemos encontrar datos compartidos, como películas Star Wars: Episodio I — La amenaza fantasma .
PoP, por otro lado, normaliza los datos de la base de datos y los imprime solo una vez, sin embargo, lleva la sobrecarga de imprimir la estructura del módulo. Por lo tanto, dependiendo de si la solicitud en particular tiene datos duplicados o no, la API basada en esquemas o la API basada en componentes tendrán un tamaño más pequeño.
En conclusión, una API basada en esquemas como GraphQL y una API basada en componentes como PoP son igualmente buenas en cuanto a rendimiento y superiores a una API basada en recursos como REST.
Lectura recomendada : comprensión y uso de las API REST
Propiedades particulares de una API basada en componentes
Si una API basada en componentes no es necesariamente mejor en términos de rendimiento que una API basada en esquemas, es posible que se pregunte, entonces, ¿qué estoy tratando de lograr con este artículo?
En esta sección, intentaré convencerlo de que una API de este tipo tiene un potencial increíble, proporcionando varias características que son muy deseables, lo que la convierte en un competidor serio en el mundo de las API. Describo y demuestro cada una de sus características únicas a continuación.
Los datos que se recuperarán de la base de datos se pueden deducir de la jerarquía de componentes
Cuando un módulo muestra una propiedad de un objeto DB, es posible que el módulo no sepa o no le importe qué objeto es; todo lo que le importa es definir qué propiedades del objeto cargado se requieren.
Por ejemplo, considere la imagen de abajo. Un módulo carga un objeto de la base de datos (en este caso, una sola publicación), y luego sus módulos descendientes mostrarán ciertas propiedades del objeto, como el title y content :
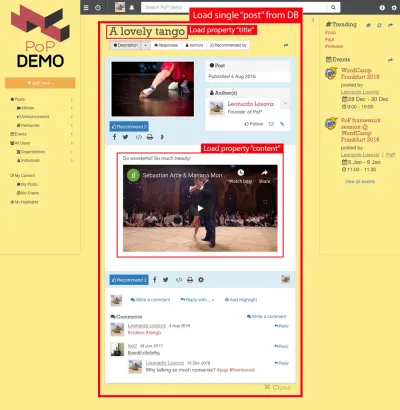
Por lo tanto, a lo largo de la jerarquía de componentes, los módulos de "carga de datos" estarán a cargo de cargar los objetos consultados (el módulo que carga la publicación única, en este caso), y sus módulos descendientes definirán qué propiedades del objeto DB se requieren ( title y content , en este caso).
La obtención de todas las propiedades requeridas para el objeto de base de datos se puede realizar automáticamente atravesando la jerarquía de componentes: comenzando desde el módulo de carga de datos, iteramos todos sus módulos descendientes hasta llegar a un nuevo módulo de carga de datos, o hasta el final del árbol; en cada nivel obtenemos todas las propiedades requeridas, y luego fusionamos todas las propiedades y las consultamos desde la base de datos, todas ellas solo una vez.
En la estructura a continuación, el módulo single-post obtiene los resultados de la base de datos (la publicación con ID 37), y los submódulos post-title y post-content definen las propiedades que se cargarán para el objeto DB consultado ( title y content respectivamente); los submódulos post-layout y fetch-next-post-button no requieren ningún campo de datos.
"single-post" => Load objects with object type "post" and ID 37 modules "post-layout" modules "post-title" => Load property "title" "post-content" => Load property "content" "fetch-next-post-button"La consulta a ejecutar se calcula automáticamente a partir de la jerarquía de componentes y sus campos de datos requeridos, conteniendo todas las propiedades que necesitan todos los módulos y sus submódulos:
SELECT title, content FROM posts WHERE id = 37 Al obtener las propiedades para recuperarlas directamente de los módulos, la consulta se actualizará automáticamente cada vez que cambie la jerarquía del componente. Si, por ejemplo, agregamos el submódulo post-thumbnail , que requiere la thumbnail del campo de datos:
"single-post" => Load objects with object type "post" and ID 37 modules "post-layout" modules "post-title" => Load property "title" "post-content" => Load property "content" "post-thumbnail" => Load property "thumbnail" "fetch-next-post-button"Luego, la consulta se actualiza automáticamente para obtener la propiedad adicional:
SELECT title, content, thumbnail FROM posts WHERE id = 37Debido a que hemos establecido que los datos del objeto de la base de datos se recuperarán de manera relacional, también podemos aplicar esta estrategia entre las relaciones entre los propios objetos de la base de datos.
Considere la imagen a continuación: Comenzando desde el tipo de objeto post y bajando en la jerarquía de componentes, necesitaremos cambiar el tipo de objeto DB a user y comment , correspondiente al autor de la publicación y cada uno de los comentarios de la publicación respectivamente, y luego, para cada comentario, debe cambiar el tipo de objeto nuevamente a user correspondiente al autor del comentario.
Pasar de un objeto de base de datos a un objeto relacional (posiblemente cambiar el tipo de objeto, como en post => author que va de post a user , o no, como en author => seguidores que van de user a user ) es lo que yo llamo "cambiar de dominio". ”.
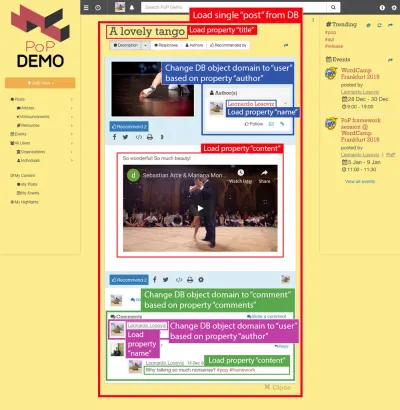
Después de cambiar a un nuevo dominio, desde ese nivel en la jerarquía de componentes hacia abajo, todas las propiedades requeridas estarán sujetas al nuevo dominio:
- el
namese obtiene del objeto deuser(que representa al autor de la publicación), - el
contentse obtiene del objeto decomment(que representa cada uno de los comentarios de la publicación), - El
namese obtiene del objeto deuser(que representa al autor de cada comentario).
Atravesando la jerarquía de componentes, la API sabe cuándo está cambiando a un nuevo dominio y, de manera apropiada, actualiza la consulta para obtener el objeto relacional.
Por ejemplo, si necesitamos mostrar datos del autor de la publicación, el submódulo de apilamiento post-author cambiará el dominio en ese nivel de post al user correspondiente, y desde este nivel hacia abajo, el objeto DB cargado en el contexto pasado al módulo es el usuario. Luego, los submódulos user-name user-avatar en post-author cargarán el name de propiedades y el avatar en el objeto de user :
"single-post" => Load objects with object type "post" and ID 37 modules "post-layout" modules "post-title" => Load property "title" "post-content" => Load property "content" "post-author" => Switch domain from "post" to "user", based on property "author" modules "user-layout" modules "user-name" => Load property "name" "user-avatar" => Load property "avatar" "fetch-next-post-button"Dando como resultado la siguiente consulta:
SELECT p.title, p.content, p.author, u.name, u.avatar FROM posts p INNER JOIN users u WHERE p.id = 37 AND p.author = u.idEn resumen, al configurar cada módulo adecuadamente, no es necesario escribir la consulta para obtener datos para una API basada en componentes. La consulta se produce automáticamente a partir de la estructura de la propia jerarquía de componentes, obteniendo qué objetos deben cargar los módulos de carga de datos, los campos a recuperar para cada objeto cargado definido en cada módulo descendiente y el cambio de dominio definido en cada módulo descendiente.
Agregar, eliminar, reemplazar o modificar cualquier módulo actualizará automáticamente la consulta. Después de ejecutar la consulta, los datos recuperados serán exactamente lo que se requiere, ni más ni menos.
Observando datos y calculando propiedades adicionales
Comenzando desde el módulo de carga de datos hacia abajo en la jerarquía de componentes, cualquier módulo puede observar los resultados devueltos y calcular elementos de datos adicionales en función de ellos, o valores de feedback , que se colocan debajo de los moduledata de entrada.
Por ejemplo, el módulo fetch-next-post-button puede agregar una propiedad que indica si hay más resultados para obtener o no (según este valor de retroalimentación, si no hay más resultados, el botón se desactivará u ocultará):
{ moduledata: { "page": { modules: { "single-post": { modules: { "fetch-next-post-button": { feedback: { hasMoreResults: true } } } } } } } }El conocimiento implícito de los datos requeridos disminuye la complejidad y hace que el concepto de "punto final" se vuelva obsoleto
Como se muestra arriba, la API basada en componentes puede obtener exactamente los datos requeridos, porque tiene el modelo de todos los componentes en el servidor y qué campos de datos requiere cada componente. Luego, puede hacer implícito el conocimiento de los campos de datos requeridos.

La ventaja es que la definición de qué datos requiere el componente se puede actualizar solo en el lado del servidor, sin tener que volver a implementar los archivos JavaScript, y el cliente puede volverse tonto, simplemente pidiéndole al servidor que proporcione los datos que necesita. , disminuyendo así la complejidad de la aplicación del lado del cliente.
Además, la llamada a la API para recuperar los datos de todos los componentes de una URL específica se puede realizar simplemente consultando esa URL y agregando el parámetro adicional output=json para indicar la devolución de datos de la API en lugar de imprimir la página. Así, la URL se convierte en su propio punto final o, considerado de otra forma, el concepto de “punto final” queda obsoleto.
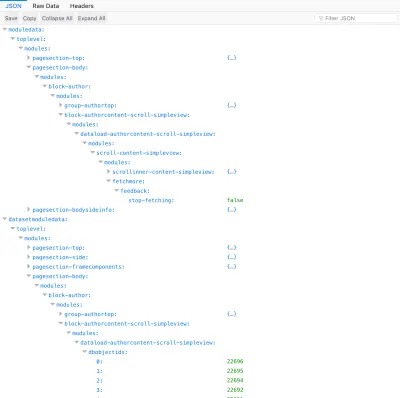
Recuperación de subconjuntos de datos: los datos se pueden recuperar para módulos específicos, encontrados en cualquier nivel de la jerarquía de componentes
¿Qué sucede si no necesitamos obtener los datos de todos los módulos de una página, sino simplemente los datos de un módulo específico que comienza en cualquier nivel de la jerarquía de componentes? Por ejemplo, si un módulo implementa un desplazamiento infinito, al desplazarse hacia abajo debemos obtener solo datos nuevos para este módulo y no para los otros módulos en la página.
Esto se puede lograr filtrando las ramas de la jerarquía de componentes que se incluirán en la respuesta, para incluir propiedades solo a partir del módulo especificado e ignorar todo lo que esté por encima de este nivel. En mi implementación (que describiré en un próximo artículo), el filtrado se habilita agregando el parámetro modulefilter=modulepaths a la URL, y el módulo (o módulos) seleccionado se indica a través de un parámetro modulepaths[] , donde una “ruta del módulo ” es la lista de módulos que comienza desde el módulo superior hasta el módulo específico (por ejemplo module1 => module2 => module3 tiene la ruta del módulo [ module1 , module2 , module3 ] y se pasa como un parámetro de URL como module1.module2.module3 ) .
Por ejemplo, en la jerarquía de componentes debajo de cada módulo tiene una entrada dbobjectids :
"module1" dbobjectids: [...] modules "module2" dbobjectids: [...] modules "module3" dbobjectids: [...] "module4" dbobjectids: [...] "module5" dbobjectids: [...] modules "module6" dbobjectids: [...] Luego, solicitar la URL de la página web agregando parámetros modulefilter=modulepaths y modulepaths[]=module1.module2.module5 producirá la siguiente respuesta:
"module1" modules "module2" modules "module5" dbobjectids: [...] modules "module6" dbobjectids: [...] En esencia, la API comienza a cargar datos a partir de module1 => module2 => module5 . Es por eso que module6 , que viene bajo module5 , también trae sus datos mientras que module3 y module4 no.
Además, podemos crear filtros de módulos personalizados para incluir un conjunto de módulos preestablecidos. Por ejemplo, llamar a una página con modulefilter=userstate puede imprimir solo aquellos módulos que requieren el estado del usuario para representarlos en el cliente, como los módulos module3 y module6 :
"module1" modules "module2" modules "module3" dbobjectids: [...] "module5" modules "module6" dbobjectids: [...] La información de cuáles son los módulos iniciales se encuentra en la sección requestmeta , en la entrada filteredmodules , como una matriz de rutas de módulos:
requestmeta: { filteredmodules: [ ["module1", "module2", "module3"], ["module1", "module2", "module5", "module6"] ] }Esta función permite implementar una aplicación de una sola página sin complicaciones, en la que el marco del sitio se carga en la solicitud inicial:
"page" modules "navigation-top" dbobjectids: [...] "navigation-side" dbobjectids: [...] "page-content" dbobjectids: [...] Pero, a partir de ahí, podemos agregar el parámetro modulefilter=page a todas las URL solicitadas, filtrando el marco y mostrando solo el contenido de la página:
"page" modules "navigation-top" "navigation-side" "page-content" dbobjectids: [...] De manera similar a los filtros de módulo, estado de userstate y page descritos anteriormente, podemos implementar cualquier filtro de módulo personalizado y crear experiencias de usuario ricas.
El módulo es su propia API
Como se muestra arriba, podemos filtrar la respuesta de la API para recuperar datos a partir de cualquier módulo. Como consecuencia, cada módulo puede interactuar consigo mismo de cliente a servidor simplemente agregando su ruta de módulo a la URL de la página web en la que se ha incluido.
Espero que disculpe mi exceso de entusiasmo, pero realmente no puedo enfatizar lo suficiente lo maravillosa que es esta característica. Al crear un componente, no necesitamos crear una API que lo acompañe para recuperar datos (REST, GraphQL o cualquier otra cosa), porque el componente ya puede comunicarse consigo mismo en el servidor y cargar su propio datos: es completamente autónomo y egoísta .
Cada módulo de carga de datos exporta la URL para interactuar con él en la entrada dataloadsource de la sección datasetmodulemeta :
{ datasetmodulemeta: { "module1": { modules: { "module2": { modules: { "module5": { meta: { dataloadsource: "https://page-url/?modulefilter=modulepaths&modulepaths[]=module1.module2.module5" }, modules: { "module6": { meta: { dataloadsource: "https://page-url/?modulefilter=modulepaths&modulepaths[]=module1.module2.module5.module6" } } } } } } } } } }La obtención de datos está desacoplada entre módulos y SECA
Para demostrar que la obtención de datos en una API basada en componentes está altamente desacoplada y SECA (no se repita), primero tendré que mostrar cómo en una API basada en esquemas como GraphQL está menos desacoplada y no esta seco.
En GraphQL, la consulta para obtener datos debe indicar los campos de datos para el componente, que pueden incluir subcomponentes, y estos también pueden incluir subcomponentes, y así sucesivamente. Luego, el componente superior también necesita saber qué datos requiere cada uno de sus subcomponentes, para obtener esos datos.
Por ejemplo, representar el componente <FeaturedDirector> podría requerir los siguientes subcomponentes:
Render <FeaturedDirector>: <div> Country: {country} {foreach films as film} <Film film={film} /> {/foreach} </div> Render <Film>: <div> Title: {title} Pic: {thumbnail} {foreach actors as actor} <Actor actor={actor} /> {/foreach} </div> Render <Actor>: <div> Name: {name} Photo: {avatar} </div> En este escenario, la consulta de GraphQL se implementa en el nivel <FeaturedDirector> . Luego, si se actualiza el subcomponente <Film> , solicitando el título a través de la propiedad filmTitle en lugar de title , la consulta del componente <FeaturedDirector> también deberá actualizarse para reflejar esta nueva información (GraphQL tiene un mecanismo de control de versiones que puede manejar con este problema, pero tarde o temprano aún deberíamos actualizar la información). Esto produce una complejidad de mantenimiento, que podría ser difícil de manejar cuando los componentes internos cambian con frecuencia o son producidos por desarrolladores externos. Por lo tanto, los componentes no están totalmente desacoplados entre sí.
De manera similar, es posible que deseemos renderizar directamente el componente <Film> para alguna película específica, para lo cual también debemos implementar una consulta GraphQL en este nivel, para obtener los datos de la película y sus actores, lo que agrega código redundante: porciones de la misma consulta vivirá en diferentes niveles de la estructura del componente. Entonces GraphQL no es SECO .
Debido a que una API basada en componentes ya sabe cómo sus componentes se envuelven entre sí en su propia estructura, estos problemas se evitan por completo. Por un lado, el cliente puede simplemente solicitar los datos requeridos que necesita, cualquiera que sea este dato; if a subcomponent data field changes, the overall model already knows and adapts immediately, without having to modify the query for the parent component in the client. Therefore, the modules are highly decoupled from each other.
For another, we can fetch data starting from any module path, and it will always return the exact required data starting from that level; there are no duplicated queries whatsoever, or even queries to start with. Hence, a component-based API is fully DRY . (This is another feature that really excites me and makes me get wet.)
(Yes, pun fully intended. Sorry about that.)
Retrieving Configuration Values In Addition To Database Data
Let's revisit the example of the featured-director component for the IMDB site described above, which was created — you guessed it! — with Bootstrap. Instead of hardcoding the Bootstrap classnames or other properties such as the title's HTML tag or the avatar max width inside of JavaScript files (whether they are fixed inside the component, or set through props by parent components), each module can set these as configuration values through the API, so that then these can be directly updated on the server and without the need to redeploy JavaScript files. Similarly, we can pass strings (such as the title Featured director ) which can be already translated/internationalized on the server-side, avoiding the need to deploy locale configuration files to the front-end.
Similar to fetching data, by traversing the component hierarchy, the API is able to deliver the required configuration values for each module and nothing more or less.
The configuration values for the featured-director component might look like this:
{ modulesettings: { "page": { modules: { "featured-director": { configuration: { class: "alert alert-info", title: "Featured director", titletag: "h3" }, modules: { "director-films": { configuration: { classes: { wrapper: "media", avatar: "mr-3", body: "media-body", films: "row", film: "col-sm-6" }, avatarmaxsize: "100px" }, modules: { "film-actors": { configuration: { classes: { wrapper: "card", image: "card-img-top", body: "card-body", title: "card-title", avatar: "img-thumbnail" } } } } } } } } } } } Please notice how — because the configuration properties for different modules are nested under each module's level — these will never collide with each other if having the same name (eg property classes from one module will not override property classes from another module), avoiding having to add namespaces for modules.
Higher Degree Of Modularity Achieved In The Application
According to Wikipedia, modularity means:
The degree to which a system's components may be separated and recombined, often with the benefit of flexibility and variety in use. The concept of modularity is used primarily to reduce complexity by breaking a system into varying degrees of interdependence and independence across and 'hide the complexity of each part behind an abstraction and interface'.
Being able to update a component just from the server-side, without the need to redeploy JavaScript files, has the consequence of better reusability and maintenance of components. I will demonstrate this by re-imagining how this example coded for React would fare in a component-based API.
Let's say that we have a <ShareOnSocialMedia> component, currently with two items: <FacebookShare> and <TwitterShare> , like this:
Render <ShareOnSocialMedia>: <ul> <li>Share on Facebook: <FacebookShare url={window.location.href} /></li> <li>Share on Twitter: <TwitterShare url={window.location.href} /></li> </ul> But then Instagram got kind of cool, so we need to add an item <InstagramShare> to our <ShareOnSocialMedia> component, too:
Render <ShareOnSocialMedia>: <ul> <li>Share on Facebook: <FacebookShare url={window.location.href} /></li> <li>Share on Twitter: <TwitterShare url={window.location.href} /></li> <li>Share on Instagram: <InstagramShare url={window.location.href} /></li> </ul> In the React implementation, as it can be seen in the linked code, adding a new component <InstagramShare> under component <ShareOnSocialMedia> forces to redeploy the JavaScript file for the latter one, so then these two modules are not as decoupled as they could be.
Sin embargo, en la API basada en componentes, podemos usar fácilmente las relaciones entre los módulos ya descritas en la API para acoplar los módulos. Mientras que originalmente tendremos esta respuesta:
{ modulesettings: { "share-on-social-media": { modules: { "facebook-share": { configuration: {...} }, "twitter-share": { configuration: {...} } } } } }Después de agregar Instagram, tendremos la respuesta mejorada:
{ modulesettings: { "share-on-social-media": { modules: { "facebook-share": { configuration: {...} }, "twitter-share": { configuration: {...} }, "instagram-share": { configuration: {...} } } } } } Y con solo iterar todos los valores en modulesettings["share-on-social-media"].modules , el componente <ShareOnSocialMedia> se puede actualizar para mostrar el componente <InstagramShare> sin necesidad de volver a implementar ningún archivo JavaScript. Por lo tanto, la API admite la adición y eliminación de módulos sin comprometer el código de otros módulos, logrando un mayor grado de modularidad.
Almacén de datos/caché nativo del lado del cliente
Los datos de la base de datos recuperados se normalizan en una estructura de diccionario y se estandarizan para que, a partir del valor de dbobjectids , se pueda acceder a cualquier parte de los datos de las databases de datos simplemente siguiendo la ruta que se indica a través de las entradas dbkeys , cualquiera que sea la forma en que se haya estructurado. . Por lo tanto, la lógica para organizar los datos ya es nativa de la propia API.
Podemos beneficiarnos de esta situación de varias maneras. Por ejemplo, los datos devueltos para cada solicitud se pueden agregar a un caché del lado del cliente que contiene todos los datos solicitados por el usuario durante la sesión. Por lo tanto, es posible evitar agregar un almacén de datos externo como Redux a la aplicación (me refiero al manejo de datos, no a otras funciones como Deshacer/Rehacer, el entorno colaborativo o la depuración de viajes en el tiempo).
Además, la estructura basada en componentes promueve el almacenamiento en caché: la jerarquía de componentes no depende de la URL, sino de qué componentes se necesitan en esa URL. De esta forma, dos eventos en /events/1/ y /events/2/ compartirán la misma jerarquía de componentes, y la información de qué módulos se requieren se puede reutilizar entre ellos. Como consecuencia, todas las propiedades (aparte de los datos de la base de datos) se pueden almacenar en caché en el cliente después de obtener el primer evento y reutilizarse a partir de ese momento, de modo que solo se deben obtener los datos de la base de datos para cada evento posterior y nada más.
Extensibilidad y reutilización
La sección de databases de datos de la API se puede ampliar, lo que permite categorizar su información en subsecciones personalizadas. De forma predeterminada, todos los datos de los objetos de la base de datos se colocan en la entrada primary ; sin embargo, también podemos crear entradas personalizadas donde colocar propiedades específicas del objeto de la base de datos.
Por ejemplo, si el componente "Películas recomendadas para usted" descrito anteriormente muestra una lista de los amigos del usuario que ha iniciado sesión que han visto esta película en la propiedad friendsWhoWatchedFilm que vieron una película en el objeto de la base de datos de la film , porque este valor cambiará según el usuario que haya iniciado sesión. usuario, guardamos esta propiedad en una userstate de estado de usuario, por lo que cuando el usuario cierra la sesión, solo eliminamos esta rama de la base de datos en caché en el cliente, pero todos los datos primary aún permanecen:
{ databases: { userstate: { films: { 5: { friendsWhoWatchedFilm: [22, 45] }, } }, primary: { films: { 5: { title: "The Terminator" }, } "people": { 22: { name: "Peter", }, 45: { name: "John", }, }, } } }Además, hasta cierto punto, la estructura de la respuesta de la API se puede reutilizar. En particular, los resultados de la base de datos se pueden imprimir en una estructura de datos diferente, como una matriz en lugar del diccionario predeterminado.
Por ejemplo, si el tipo de objeto es solo uno (p. ej., films ), se puede formatear como una matriz para alimentarlo directamente en un componente de escritura anticipada:
[ { title: "Star Wars: Episode I - The Phantom Menace", thumbnail: "..." }, { title: "Star Wars: Episode II - Attack of the Clones", thumbnail: "..." }, { title: "The Terminator", thumbnail: "..." }, ]Soporte para programación orientada a aspectos
Además de obtener datos, la API basada en componentes también puede publicar datos, como crear una publicación o agregar un comentario, y ejecutar cualquier tipo de operación, como iniciar o cerrar sesión del usuario, enviar correos electrónicos, iniciar sesión, análisis, y así. No hay restricciones: cualquier funcionalidad proporcionada por el CMS subyacente se puede invocar a través de un módulo, en cualquier nivel.
A lo largo de la jerarquía de componentes, podemos agregar cualquier número de módulos, y cada módulo puede ejecutar su propia operación. Por lo tanto, no todas las operaciones deben estar necesariamente relacionadas con la acción esperada de la solicitud, como cuando se realiza una operación POST, PUT o DELETE en REST o se envía una mutación en GraphQL, pero se pueden agregar para brindar funcionalidades adicionales, como enviar un correo electrónico. al administrador cuando un usuario crea una nueva publicación.
Entonces, al definir la jerarquía de componentes a través de la inyección de dependencia o archivos de configuración, se puede decir que la API admite la programación orientada a aspectos, "un paradigma de programación que tiene como objetivo aumentar la modularidad al permitir la separación de preocupaciones transversales".
Lectura recomendada : Protección de su sitio con política de características
Seguridad mejorada
Los nombres de los módulos no son necesariamente fijos cuando se imprimen en la salida, pero pueden acortarse, modificarse, cambiarse aleatoriamente o (en resumen) hacerse variables de la forma que se desee. Si bien originalmente se pensó para acortar la salida de la API (para que los nombres de los módulos carousel-featured-posts o drag-and-drop-user-images se puedan acortar a una notación base 64, como a1 , a2 , etc., para el entorno de producción ), esta función permite cambiar con frecuencia los nombres de los módulos en la respuesta de la API por razones de seguridad.
Por ejemplo, los nombres de entrada se denominan de forma predeterminada como su módulo correspondiente; luego, los módulos llamados nombre de username y password , que se representarán en el cliente como <input type="text" name="{input_name}"> y <input type="password" name="{input_name}"> respectivamente, se pueden establecer diferentes valores aleatorios para sus nombres de entrada (como zwH8DSeG y QBG7m6EF hoy, y c3oMLBjo y c46oVgN6 mañana), lo que dificulta que los spammers y los bots se dirijan al sitio.
Versatilidad a través de modelos alternativos
El anidamiento de módulos permite ramificarse a otro módulo para agregar compatibilidad para un medio o tecnología específicos, o cambiar algún estilo o funcionalidad, y luego regresar a la rama original.
Por ejemplo, digamos que la página web tiene la siguiente estructura:
"module1" modules "module2" modules "module3" "module4" modules "module5" modules "module6" En este caso, nos gustaría que el sitio web también funcione para AMP, sin embargo, los módulos module2 , module4 y module5 no son compatibles con AMP. Podemos ramificar estos módulos en módulos similares compatibles con AMP module2AMP , module4AMP y module5AMP , después de lo cual seguimos cargando la jerarquía de componentes original, por lo que solo se sustituyen estos tres módulos (y nada más):
"module1" modules "module2AMP" modules "module3" "module4AMP" modules "module5AMP" modules "module6"Esto hace que sea bastante fácil generar diferentes salidas a partir de un solo código base, agregando bifurcaciones solo aquí y allá según sea necesario, y siempre con alcance y restringido a módulos individuales.
Tiempo de demostración
El código que implementa la API como se explica en este artículo está disponible en este repositorio de código abierto.
Implementé la API de PoP en https://nextapi.getpop.org con fines de demostración. El sitio web se ejecuta en WordPress, por lo que los enlaces permanentes de URL son los típicos de WordPress. Como se señaló anteriormente, al agregarles el parámetro output=json , estas URL se convierten en sus propios puntos finales de API.
El sitio está respaldado por la misma base de datos del sitio web de demostración de PoP, por lo que se puede realizar una visualización de la jerarquía de componentes y los datos recuperados consultando la misma URL en este otro sitio web (por ejemplo, visitando https://demo.getpop.org/u/leo/ explica los datos de https://nextapi.getpop.org/u/leo/?output=json ).
Los enlaces a continuación muestran la API para los casos descritos anteriormente:
- La página de inicio, una sola publicación, un autor, una lista de publicaciones y una lista de usuarios.
- Un evento, filtrando desde un módulo específico.
- Una etiqueta, módulos de filtrado que requieren estado de usuario y filtrado para traer solo una página desde una aplicación de una sola página.
- Una variedad de ubicaciones, para alimentar una escritura anticipada.
- Modelos alternativos para la página “Quiénes somos”: Normal, Imprimible, Embebible.
- Cambiando los nombres de los módulos: original vs destrozado.
- Información de filtrado: solo configuración del módulo, datos del módulo más datos de la base de datos.
Conclusión
Una buena API es un trampolín para crear aplicaciones confiables, fáciles de mantener y poderosas. En este artículo, describí los conceptos que impulsan una API basada en componentes que, creo, es una API bastante buena y espero haberlo convencido a usted también.
Hasta ahora, el diseño y la implementación de la API han implicado varias iteraciones y han llevado más de cinco años, y aún no está completamente lista. Sin embargo, está en un estado bastante decente, no está listo para la producción pero sí como un alfa estable. En estos días, todavía estoy trabajando en ello; trabajando en la definición de la especificación abierta, implementando las capas adicionales (como el renderizado) y escribiendo la documentación.
En un próximo artículo, describiré cómo funciona mi implementación de la API. Hasta entonces, si tiene alguna idea al respecto, ya sea positiva o negativa, me encantaría leer sus comentarios a continuación.
Actualización (31 de enero): capacidades de consulta personalizada
Alain Schlesser comentó que una API que no puede ser consultada de forma personalizada por el cliente no tiene valor, lo que nos lleva de vuelta a SOAP, por lo que no puede competir con REST o GraphQL. Después de darle a su comentario unos días de reflexión, tuve que admitir que tiene razón. Sin embargo, en lugar de descartar la API basada en componentes como un esfuerzo bien intencionado pero aún no del todo hecho, hice algo mucho mejor: pude implementar la capacidad de consulta personalizada para ella. ¡Y funciona como un encanto!
En los siguientes enlaces, los datos de un recurso o colección de recursos se obtienen como se hace normalmente a través de REST. Sin embargo, a través de los fields de parámetros también podemos especificar qué datos específicos recuperar para cada recurso, evitando la obtención excesiva o insuficiente de datos:
- Una sola publicación y una colección de publicaciones que agregan
fields=title,content,datetime - Un usuario y una colección de usuarios agregando
fields=name,username,description
Los enlaces anteriores muestran cómo obtener datos solo para los recursos consultados. ¿Qué pasa con sus relaciones? Por ejemplo, supongamos que queremos recuperar una lista de publicaciones con los campos "title" y "content" , los comentarios de cada publicación con los campos "content" y "date" y el autor de cada comentario con los campos "name" y "url" . Para lograr esto en GraphQL implementaríamos la siguiente consulta:
query { post { title content comments { content date author { name url } } } } Para la implementación de la API basada en componentes, traduje la consulta a su correspondiente expresión de "sintaxis de puntos", que luego se puede proporcionar a través de fields de parámetros. Al consultar sobre un recurso de "publicación", este valor es:
fields=title,content,comments.content,comments.date,comments.author.name,comments.author.url O se puede simplificar, usando | para agrupar todos los campos aplicados al mismo recurso:
fields=title|content,comments.content|date,comments.author.name|urlAl ejecutar esta consulta en una sola publicación, obtenemos exactamente los datos requeridos para todos los recursos involucrados:
{ "datasetmodulesettings": { "dataload-dataquery-singlepost-fields": { "dbkeys": { "id": "posts", "comments": "comments", "comments.author": "users" } } }, "datasetmoduledata": { "dataload-dataquery-singlepost-fields": { "dbobjectids": [ 23691 ] } }, "databases": { "posts": { "23691": { "id": 23691, "title": "A lovely tango", "content": "<div class=\"responsiveembed-container\"><iframe loading="lazy" width=\"480\" height=\"270\" src=\"https:\\/\\/www.youtube.com\\/embed\\/sxm3Xyutc1s?feature=oembed\" frameborder=\"0\" allowfullscreen><\\/iframe><\\/div>\n", "comments": [ "25094", "25164" ] } }, "comments": { "25094": { "id": "25094", "content": "<p><a class=\"hashtagger-tag\" href=\"https:\\/\\/newapi.getpop.org\\/tags\\/videos\\/\">#videos<\\/a>\\u00a0<a class=\"hashtagger-tag\" href=\"https:\\/\\/newapi.getpop.org\\/tags\\/tango\\/\">#tango<\\/a><\\/p>\n", "date": "4 Aug 2016", "author": "851" }, "25164": { "id": "25164", "content": "<p>fjlasdjf;dlsfjdfsj<\\/p>\n", "date": "19 Jun 2017", "author": "1924" } }, "users": { "851": { "id": 851, "name": "Leonardo Losoviz", "url": "https:\\/\\/newapi.getpop.org\\/u\\/leo\\/" }, "1924": { "id": 1924, "name": "leo2", "url": "https:\\/\\/newapi.getpop.org\\/u\\/leo2\\/" } } } } Por lo tanto, podemos consultar los recursos en forma REST y especificar consultas basadas en esquemas en forma GraphQL, y obtendremos exactamente lo que se requiere, sin obtener más o menos datos y normalizando los datos en la base de datos para que no se dupliquen. Favorablemente, la consulta puede incluir cualquier número de relaciones, anidadas en profundidad, y estas se resuelven con tiempo de complejidad lineal: peor caso de O(n+m), donde n es el número de nodos que cambian de dominio (en este caso 2: comments y comments.author ) y m es el número de resultados obtenidos (en este caso 5: 1 publicación + 2 comentarios + 2 usuarios), y el caso promedio de O(n). (Esto es más eficiente que GraphQL, que tiene un tiempo de complejidad polinomial O (n ^ c) y sufre un aumento del tiempo de ejecución a medida que aumenta la profundidad del nivel).
Finalmente, esta API también puede aplicar modificadores al consultar datos, por ejemplo, para filtrar qué recursos se recuperan, como se puede hacer a través de GraphQL. Para lograr esto, la API simplemente se coloca encima de la aplicación y puede usar convenientemente su funcionalidad, por lo que no es necesario reinventar la rueda. Por ejemplo, agregar parámetros filter=posts&searchfor=internet filtrará todas las publicaciones que contengan "internet" de una colección de publicaciones.
La implementación de esta nueva función se describirá en un próximo artículo.