
Conversión de imagen a texto con React y Tesseract.js (OCR)
Publicado: 2022-03-10Los datos son la columna vertebral de cada aplicación de software porque el propósito principal de una aplicación es resolver problemas humanos. Para resolver los problemas humanos, es necesario tener cierta información sobre ellos.
Dicha información se representa como datos, especialmente mediante computación. En la web, los datos se recopilan principalmente en forma de textos, imágenes, videos y muchos más. A veces, las imágenes contienen textos esenciales que deben procesarse para lograr un propósito determinado. Estas imágenes se procesaron principalmente de forma manual porque no había forma de procesarlas mediante programación.
La incapacidad de extraer texto de las imágenes fue una limitación de procesamiento de datos que experimenté de primera mano en mi última empresa. Necesitábamos procesar las tarjetas de regalo escaneadas y teníamos que hacerlo manualmente ya que no podíamos extraer el texto de las imágenes.
Había un departamento llamado "Operaciones" dentro de la empresa que era responsable de confirmar manualmente las tarjetas de regalo y acreditar las cuentas de los usuarios. Aunque teníamos un sitio web a través del cual los usuarios se conectaban con nosotros, el procesamiento de las tarjetas de regalo se realizaba manualmente en segundo plano.
En ese momento, nuestro sitio web se construyó principalmente con PHP (Laravel) para el backend y JavaScript (jQuery y Vue) para el frontend. Nuestra pila técnica era lo suficientemente buena para trabajar con Tesseract.js siempre que la gerencia considerara que el problema era importante.
Estaba dispuesto a resolver el problema, pero no era necesario hacerlo desde el punto de vista de la empresa o de la dirección. Después de dejar la empresa, decidí investigar un poco y tratar de encontrar posibles soluciones. Eventualmente, descubrí OCR.
¿Qué es OCR?
OCR significa "Reconocimiento óptico de caracteres" o "Lector óptico de caracteres". Se utiliza para extraer textos de imágenes.
La evolución de OCR se remonta a varios inventos, pero Optophone, "Gismo", el escáner plano CCD, Newton MesssagePad y Tesseract son los principales inventos que llevan el reconocimiento de caracteres a otro nivel de utilidad.
Entonces, ¿por qué usar OCR? Bueno, el reconocimiento óptico de caracteres resuelve muchos problemas, uno de los cuales me motivó a escribir este artículo. Me di cuenta de que la capacidad de extraer textos de una imagen garantiza muchas posibilidades, como:
- Regulación
Toda organización necesita regular las actividades de los usuarios por algunas razones. La regulación podría usarse para proteger los derechos de los usuarios y protegerlos de amenazas o estafas.
La extracción de textos de una imagen permite que una organización procese información textual en una imagen para la regulación, especialmente cuando las imágenes son proporcionadas por algunos de los usuarios.
Por ejemplo, la regulación similar a Facebook de la cantidad de textos en imágenes utilizadas para anuncios se puede lograr con OCR. Además, ocultar contenido confidencial en Twitter también es posible gracias a OCR. - Capacidad de búsqueda
La búsqueda es una de las actividades más comunes, especialmente en Internet. Los algoritmos de búsqueda se basan principalmente en la manipulación de textos. Con el reconocimiento óptico de caracteres, es posible reconocer caracteres en imágenes y utilizarlos para proporcionar resultados de imagen relevantes a los usuarios. En resumen, ahora se pueden buscar imágenes y videos con la ayuda de OCR. - Accesibilidad
Tener textos en las imágenes siempre ha sido un desafío para la accesibilidad y la regla general es tener pocos textos en una imagen. Con OCR, los lectores de pantalla pueden tener acceso a textos en imágenes para brindar la experiencia necesaria a sus usuarios. - Automatización del procesamiento de datos El procesamiento de datos está mayormente automatizado para escalar. Tener textos en las imágenes es una limitación para el procesamiento de datos porque los textos no se pueden procesar excepto manualmente. El Reconocimiento Óptico de Caracteres (OCR) hace posible la extracción de textos en imágenes mediante programación, asegurando así la automatización del procesamiento de datos, especialmente cuando se trata del procesamiento de textos en imágenes.
- Digitalización de materiales impresos
Todo se está digitalizando y aún quedan muchos documentos por digitalizar. Los cheques, certificados y otros documentos físicos ahora se pueden digitalizar con el uso del reconocimiento óptico de caracteres.
Descubrir todos los usos anteriores profundizó mis intereses, así que decidí ir más allá haciendo una pregunta:
"¿Cómo puedo usar OCR en la web, especialmente en una aplicación React?"
Esa pregunta me llevó a Tesseract.js.
¿Qué es Tesseract.js?
Tesseract.js es una biblioteca de JavaScript que compila el Tesseract original de C a JavaScript WebAssembly, lo que hace que OCR sea accesible en el navegador. El motor Tesseract.js se escribió originalmente en ASM.js y luego se transfirió a WebAssembly, pero ASM.js todavía sirve como respaldo en algunos casos cuando WebAssembly no es compatible.
Como se indica en el sitio web de Tesseract.js, admite más de 100 idiomas , orientación de texto automática y detección de scripts, una interfaz simple para leer párrafos, palabras y cuadros delimitadores de caracteres.
Tesseract es un motor de reconocimiento óptico de caracteres para varios sistemas operativos. Es software libre, publicado bajo la Licencia Apache. Hewlett-Packard desarrolló Tesseract como software propietario en la década de 1980. Fue lanzado como código abierto en 2005 y su desarrollo ha sido patrocinado por Google desde 2006.
La última versión, la versión 4, de Tesseract se lanzó en octubre de 2018 y contiene un nuevo motor OCR que utiliza un sistema de red neuronal basado en la memoria a largo plazo (LSTM) y está destinado a producir resultados más precisos.
Descripción de las API de Tesseract
Para comprender realmente cómo funciona Tesseract, debemos desglosar algunas de sus API y sus componentes. De acuerdo con la documentación de Tesseract.js, hay dos formas de abordar su uso. A continuación se muestra el primer enfoque y su desglose:
Tesseract.recognize( image,language, { logger: m => console.log(m) } ) .catch (err => { console.error(err); }) .then(result => { console.log(result); }) } El método de recognize toma la imagen como su primer argumento, el idioma (que puede ser múltiple) como su segundo argumento y { logger: m => console.log(me) } como su último argumento. Los formatos de imagen compatibles con Tesseract son jpg, png, bmp y pbm, que solo se pueden proporcionar como elementos (img, video o lienzo), objeto de archivo ( <input> ), objeto blob, ruta o URL de una imagen e imagen codificada en base64. . (Lea aquí para obtener más información sobre todos los formatos de imagen que Tesseract puede manejar).
El idioma se proporciona como una cadena como eng . El signo + podría usarse para concatenar varios idiomas como en eng+chi_tra . El argumento de idioma se utiliza para determinar los datos de idioma entrenados que se utilizarán en el procesamiento de imágenes.
Nota : encontrará todos los idiomas disponibles y sus códigos aquí.
{ logger: m => console.log(m) } es muy útil para obtener información sobre el progreso de una imagen que se está procesando. La propiedad del registrador toma una función que se llamará varias veces mientras Tesseract procesa una imagen. El parámetro de la función de registro debe ser un objeto con workerId , jobId , status y progress como sus propiedades:
{ workerId: 'worker-200030', jobId: 'job-734747', status: 'recognizing text', progress: '0.9' } El progress es un número entre 0 y 1, y es un porcentaje para mostrar el progreso de un proceso de reconocimiento de imágenes.
Tesseract genera automáticamente el objeto como un parámetro para la función de registro, pero también se puede proporcionar manualmente. A medida que se lleva a cabo un proceso de reconocimiento, las propiedades del objeto logger se actualizan cada vez que se llama a la función . Por lo tanto, se puede usar para mostrar una barra de progreso de conversión, modificar alguna parte de una aplicación o para lograr cualquier resultado deseado.
El result en el código anterior es el resultado del proceso de reconocimiento de imágenes. Cada una de las propiedades de result tiene la propiedad bbox como las coordenadas x/y de su cuadro delimitador.
Aquí están las propiedades del objeto de result , sus significados o usos:
{ text: "I am codingnninja from Nigeria..." hocr: "<div class='ocr_page' id= ..." tsv: "1 1 0 0 0 0 0 0 1486 ..." box: null unlv: null osd: null confidence: 90 blocks: [{...}] psm: "SINGLE_BLOCK" oem: "DEFAULT" version: "4.0.0-825-g887c" paragraphs: [{...}] lines: (5) [{...}, ...] words: (47) [{...}, {...}, ...] symbols: (240) [{...}, {...}, ...] }-
text: Todo el texto reconocido como una cadena. -
lines: una matriz de cada línea de texto reconocida por línea. -
words: Una matriz de cada palabra reconocida. -
symbols: Una matriz de cada uno de los caracteres reconocidos. -
paragraphs: Una matriz de todos los párrafos reconocidos. Vamos a discutir la "confianza" más adelante en este artículo.
Tesseract también se puede usar de manera más imperativa como en:
import { createWorker } from 'tesseract.js'; const worker = createWorker({ logger: m => console.log(m) }); (async () => { await worker.load(); await worker.loadLanguage('eng'); await worker.initialize('eng'); const { data: { text } } = await worker.recognize('https://tesseract.projectnaptha.com/img/eng_bw.png'); console.log(text); await worker.terminate(); })();Este enfoque está relacionado con el primer enfoque pero con diferentes implementaciones.
createWorker(options) crea un trabajador web o un proceso secundario de nodo que crea un trabajador de Tesseract. El trabajador ayuda a configurar el motor Tesseract OCR. El método load() carga los scripts centrales de Tesseract, loadLanguage() carga cualquier idioma que se le proporcione como una cadena, initialize() se asegura de que Tesseract esté completamente listo para su uso y luego se utiliza el método de reconocimiento para procesar la imagen proporcionada. El método terminar () detiene al trabajador y limpia todo.
Nota : Consulte la documentación de las API de Tesseract para obtener más información.
Ahora, tenemos que construir algo para ver realmente qué tan efectivo es Tesseract.js.
¿Qué vamos a construir?
Vamos a construir un extractor de PIN de tarjetas de regalo porque extraer el PIN de una tarjeta de regalo fue el problema que condujo a esta aventura de escritura en primer lugar.
Construiremos una aplicación simple que extraiga el PIN de una tarjeta de regalo escaneada . Como me dispuse a construir un extractor de pin de tarjeta de regalo simple, lo guiaré a través de algunos de los desafíos que enfrenté a lo largo de la línea, las soluciones que brindé y mi conclusión basada en mi experiencia.
- Ir al código fuente →
A continuación se muestra la imagen que vamos a utilizar para la prueba porque tiene algunas propiedades realistas que son posibles en el mundo real.

Extraeremos AQUX-QWMB6L-R6JAU de la tarjeta. Entonces empecemos.
Instalación de React y Tesseract
Hay una pregunta que atender antes de instalar React y Tesseract.js y la pregunta es, ¿por qué usar React con Tesseract? En la práctica, podemos usar Tesseract con Vanilla JavaScript, cualquier biblioteca de JavaScript o marcos como React, Vue y Angular.
Usar React en este caso es una preferencia personal. Inicialmente, quería usar Vue, pero decidí usar React porque estoy más familiarizado con React que con Vue.
Ahora, sigamos con las instalaciones.
Para instalar React con create-react-app, debe ejecutar el siguiente código:
npx create-react-app image-to-text cd image-to-text yarn add Tesseract.jso
npm install tesseract.jsDecidí ir con yarn para instalar Tesseract.js porque no pude instalar Tesseract con npm pero yarn hizo el trabajo sin estrés. Puedes usar npm pero recomiendo instalar Tesseract con yarn a juzgar por mi experiencia.
Ahora, comencemos nuestro servidor de desarrollo ejecutando el siguiente código:
yarn starto
npm startDespués de ejecutar yarn start o npm start, su navegador predeterminado debería abrir una página web como la siguiente:

También puede navegar a localhost:3000 en el navegador siempre que la página no se inicie automáticamente.
Después de instalar React y Tesseract.js, ¿qué sigue?
Configuración de un formulario de carga
En este caso, vamos a ajustar la página de inicio (App.js) que acabamos de ver en el navegador para que contenga el formulario que necesitamos:
import { useState, useRef } from 'react'; import Tesseract from 'tesseract.js'; import './App.css'; function App() { const [imagePath, setImagePath] = useState(""); const [text, setText] = useState(""); const handleChange = (event) => { setImage(URL.createObjectURL(event.target.files[0])); } return ( <div className="App"> <main className="App-main"> <h3>Actual image uploaded</h3> <img src={imagePath} className="App-logo" alt="logo"/> <h3>Extracted text</h3> <div className="text-box"> <p> {text} </p> </div> <input type="file" onChange={handleChange} /> </main> </div> ); } export default App La parte del código anterior que necesita nuestra atención en este punto es la función handleChange .
const handleChange = (event) => { setImage(URL.createObjectURL(event.target.files[0])); } En la función, URL.createObjectURL toma un archivo seleccionado a través de event.target.files[0] y crea una URL de referencia que se puede usar con etiquetas HTML como img, audio y video. Usamos setImagePath para agregar la URL al estado. Ahora, ahora se puede acceder a la URL con imagePath .
<img src={imagePath} className="App-logo" alt="image"/> Establecemos el atributo src de la imagen en {imagePath} para obtener una vista previa en el navegador antes de procesarla.
Conversión de imágenes seleccionadas en textos
Como hemos tomado la ruta a la imagen seleccionada, podemos pasar la ruta de la imagen a Tesseract.js para extraer textos de ella.
import { useState} from 'react'; import Tesseract from 'tesseract.js'; import './App.css'; function App() { const [imagePath, setImagePath] = useState(""); const [text, setText] = useState(""); const handleChange = (event) => { setImagePath(URL.createObjectURL(event.target.files[0])); } const handleClick = () => { Tesseract.recognize( imagePath,'eng', { logger: m => console.log(m) } ) .catch (err => { console.error(err); }) .then(result => { // Get Confidence score let confidence = result.confidence let text = result.text setText(text); }) } return ( <div className="App"> <main className="App-main"> <h3>Actual imagePath uploaded</h3> <img src={imagePath} className="App-image" alt="logo"/> <h3>Extracted text</h3> <div className="text-box"> <p> {text} </p> </div> <input type="file" onChange={handleChange} /> <button onClick={handleClick} style={{height:50}}> convert to text</button> </main> </div> ); } export default AppAgregamos la función “handleClick” a “App.js y contiene la API Tesseract.js que toma la ruta a la imagen seleccionada. Tesseract.js toma "imagePath", "idioma", "un objeto de configuración".
El botón a continuación se agrega al formulario para llamar a "handClick", que activa la conversión de imagen a texto cada vez que se hace clic en el botón.
<button onClick={handleClick} style={{height:50}}> convert to text</button>Cuando el procesamiento es exitoso, accedemos tanto a "confianza" como a "texto" del resultado. Luego, agregamos "texto" al estado con "setText (texto)".
Al agregar a <p> {text} </p> , mostramos el texto extraído.
Es obvio que de la imagen se extrae “texto” pero ¿qué es la confianza?
La confianza muestra cuán precisa es la conversión. El nivel de confianza está entre 1 y 100. 1 representa lo peor, mientras que 100 representa lo mejor en términos de precisión. También se puede utilizar para determinar si un texto extraído debe aceptarse como exacto o no.
Entonces la pregunta es ¿qué factores pueden afectar la puntuación de confianza o la precisión de toda la conversión? Se ve afectado principalmente por tres factores principales: la calidad y la naturaleza del documento utilizado, la calidad del escaneo creado a partir del documento y las capacidades de procesamiento del motor Tesseract.
Ahora, agreguemos el siguiente código a "App.css" para darle un poco de estilo a la aplicación.
.App { text-align: center; } .App-image { width: 60vmin; pointer-events: none; } .App-main { background-color: #282c34; min-height: 100vh; display: flex; flex-direction: column; align-items: center; justify-content: center; font-size: calc(7px + 2vmin); color: white; } .text-box { background: #fff; color: #333; border-radius: 5px; text-align: center; }Aquí está el resultado de mi primera prueba :
Resultado en Firefox
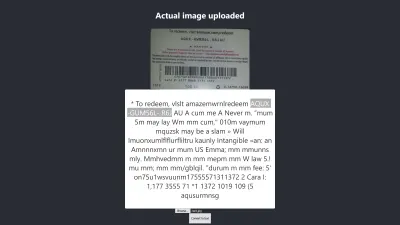
El nivel de confianza del resultado anterior es 64. Vale la pena señalar que la imagen de la tarjeta de regalo es de color oscuro y definitivamente afecta el resultado que obtenemos.

Si observa más de cerca la imagen de arriba, verá que el pin de la tarjeta es casi exacto en el texto extraído. No es exacto porque la tarjeta de regalo no está muy clara.
¡Oh espera! ¿Cómo se verá en Chrome?
Resultado en Chrome
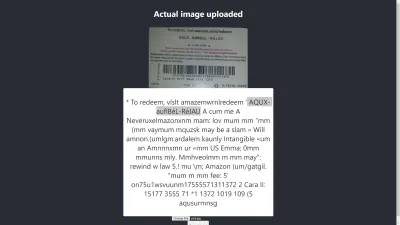
¡Ay! El resultado es aún peor en Chrome. Pero, ¿por qué el resultado en Chrome es diferente al de Mozilla Firefox? Los diferentes navegadores manejan las imágenes y sus perfiles de color de manera diferente. Eso significa que una imagen se puede representar de manera diferente según el navegador . Al proporcionar image.data a Tesseract, es probable que produzca un resultado diferente en diferentes navegadores porque se proporcionan diferentes image.data a Tesseract según el navegador en uso. Preprocesar una imagen, como veremos más adelante en este artículo, ayudará a lograr un resultado consistente.
Necesitamos ser más precisos para estar seguros de que estamos recibiendo o dando la información correcta. Así que tenemos que llevarlo un poco más allá.
Intentemos más para ver si podemos lograr el objetivo al final.
Pruebas de precisión
Hay muchos factores que afectan una conversión de imagen a texto con Tesseract.js. La mayoría de estos factores giran en torno a la naturaleza de la imagen que queremos procesar y el resto depende de cómo el motor Tesseract maneje la conversión.
Internamente, Tesseract preprocesa las imágenes antes de la conversión OCR real, pero no siempre brinda resultados precisos.
Como solución, podemos preprocesar imágenes para lograr conversiones precisas. Podemos binarizar, invertir, dilatar, alinear o cambiar la escala de una imagen para preprocesarla para Tesseract.js.
El preprocesamiento de imágenes es mucho trabajo o un campo extenso por sí solo. Afortunadamente, P5.js ha proporcionado todas las técnicas de preprocesamiento de imágenes que queremos usar. En lugar de reinventar la rueda o usar toda la biblioteca solo porque queremos usar una pequeña parte de ella, he copiado las que necesitamos. Todas las técnicas de preprocesamiento de imágenes están incluidas en preprocess.js.
¿Qué es la binarización?
La binarización es la conversión de los píxeles de una imagen a blanco o negro. Queremos binarizar la tarjeta de regalo anterior para verificar si la precisión será mejor o no.
Anteriormente, extrajimos algunos textos de una tarjeta de regalo, pero el PIN de destino no era tan preciso como queríamos. Por lo tanto, existe la necesidad de encontrar otra forma de obtener un resultado preciso.
Ahora, queremos binarizar la tarjeta de regalo , es decir, queremos convertir sus píxeles a blanco y negro para que podamos ver si se puede lograr un mejor nivel de precisión o no.
Las siguientes funciones se usarán para la binarización y se incluyen en un archivo separado llamado preprocess.js.
function preprocessImage(canvas) { const ctx = canvas.getContext('2d'); const image = ctx.getImageData(0,0,canvas.width, canvas.height); thresholdFilter(image.data, 0.5); return image; } Export default preprocessImage¿Qué hace el código de arriba?
Introducimos lienzo para contener los datos de una imagen para aplicar algunos filtros, para preprocesar la imagen, antes de pasarla a Tesseract para la conversión.
La primera función preprocessImage se encuentra en preprocess.js y prepara el lienzo para su uso al obtener sus píxeles. La función thresholdFilter binariza la imagen convirtiendo sus píxeles a blanco o negro .
Llamemos a preprocessImage para ver si el texto extraído de la tarjeta de regalo anterior puede ser más preciso.
Para cuando actualicemos App.js, ahora debería tener este código:
import { useState, useRef } from 'react'; import preprocessImage from './preprocess'; import Tesseract from 'tesseract.js'; import './App.css'; function App() { const [image, setImage] = useState(""); const [text, setText] = useState(""); const canvasRef = useRef(null); const imageRef = useRef(null); const handleChange = (event) => { setImage(URL.createObjectURL(event.target.files[0])) } const handleClick = () => { const canvas = canvasRef.current; const ctx = canvas.getContext('2d'); ctx.drawImage(imageRef.current, 0, 0); ctx.putImageData(preprocessImage(canvas),0,0); const dataUrl = canvas.toDataURL("image/jpeg"); Tesseract.recognize( dataUrl,'eng', { logger: m => console.log(m) } ) .catch (err => { console.error(err); }) .then(result => { // Get Confidence score let confidence = result.confidence console.log(confidence) // Get full output let text = result.text setText(text); }) } return ( <div className="App"> <main className="App-main"> <h3>Actual image uploaded</h3> <img src={image} className="App-logo" alt="logo" ref={imageRef} /> <h3>Canvas</h3> <canvas ref={canvasRef} width={700} height={250}></canvas> <h3>Extracted text</h3> <div className="pin-box"> <p> {text} </p> </div> <input type="file" onChange={handleChange} /> <button onClick={handleClick} style={{height:50}}>Convert to text</button> </main> </div> ); } export default AppPrimero, tenemos que importar "preprocessImage" desde "preprocess.js" con el siguiente código:
import preprocessImage from './preprocess'; Luego, agregamos una etiqueta de lienzo al formulario. Establecemos el atributo ref de las etiquetas canvas e img en { canvasRef } y { imageRef } respectivamente. Las referencias se utilizan para acceder al lienzo y la imagen desde el componente de la aplicación. Conseguimos tanto el lienzo como la imagen con “useRef” como en:
const canvasRef = useRef(null); const imageRef = useRef(null);En esta parte del código, fusionamos la imagen con el lienzo, ya que solo podemos preprocesar un lienzo en JavaScript. Luego lo convertimos a una URL de datos con "jpeg" como formato de imagen.
const canvas = canvasRef.current; const ctx = canvas.getContext('2d'); ctx.drawImage(imageRef.current, 0, 0); ctx.putImageData(preprocessImage(canvas),0,0); const dataUrl = canvas.toDataURL("image/jpeg");"dataUrl" se pasa a Tesseract como la imagen que se va a procesar.
Ahora, verifiquemos si el texto extraído será más preciso.
Prueba #2

La imagen de arriba muestra el resultado en Firefox. Es obvio que la parte oscura de la imagen se ha cambiado a blanca, pero el procesamiento previo de la imagen no conduce a un resultado más preciso. Es aún peor.
La primera conversión solo tiene dos caracteres incorrectos pero esta tiene cuatro caracteres incorrectos. Incluso intenté cambiar el nivel de umbral, pero fue en vano. No obtenemos un mejor resultado no porque la binarización sea mala, sino porque la binarización de la imagen no corrige la naturaleza de la imagen de una manera que sea adecuada para el motor Tesseract.
Veamos cómo se ve también en Chrome:

Obtenemos el mismo resultado.
Después de obtener un resultado peor al binarizar la imagen, es necesario verificar otras técnicas de preprocesamiento de imágenes para ver si podemos resolver el problema o no. Entonces, vamos a intentar la dilatación, la inversión y el desenfoque a continuación.
Solo obtengamos el código para cada una de las técnicas de P5.js como se usa en este artículo. Agregaremos las técnicas de procesamiento de imágenes a preprocess.js y las usaremos una por una. Es necesario comprender cada una de las técnicas de preprocesamiento de imágenes que queremos usar antes de usarlas, por lo que las discutiremos primero.
¿Qué es la dilatación?
La dilatación es agregar píxeles a los límites de los objetos en una imagen para hacerla más ancha, más grande o más abierta. La técnica de "dilatación" se utiliza para preprocesar nuestras imágenes para aumentar el brillo de los objetos en las imágenes. Necesitamos una función para dilatar imágenes usando JavaScript, por lo que el fragmento de código para dilatar una imagen se agrega a preprocess.js.
¿Qué es el desenfoque?
El desenfoque es suavizar los colores de una imagen al reducir su nitidez. A veces, las imágenes tienen pequeños puntos/parches. Para eliminar esos parches, podemos desenfocar las imágenes. El fragmento de código para desenfocar una imagen se incluye en preprocess.js.
¿Qué es la inversión?
La inversión consiste en cambiar las áreas claras de una imagen a un color oscuro y las áreas oscuras a un color claro. Por ejemplo, si una imagen tiene un fondo negro y un primer plano blanco, podemos invertirla para que su fondo sea blanco y su primer plano negro. También hemos agregado el fragmento de código para invertir una imagen en preprocess.js.
Después de agregar dilate , invertColors y blurARGB a “preprocess.js”, ahora podemos usarlos para preprocesar imágenes. Para usarlos, necesitamos actualizar la función "preprocessImage" inicial en preprocess.js:
preprocessImage(...) ahora se ve así:
function preprocessImage(canvas) { const level = 0.4; const radius = 1; const ctx = canvas.getContext('2d'); const image = ctx.getImageData(0,0,canvas.width, canvas.height); blurARGB(image.data, canvas, radius); dilate(image.data, canvas); invertColors(image.data); thresholdFilter(image.data, level); return image; } En preprocessImage anterior, aplicamos cuatro técnicas de preprocesamiento a una imagen: blurARGB() para eliminar los puntos de la imagen, dilate() para aumentar el brillo de la imagen, invertColors() para cambiar el color frontal y de fondo de la imagen y thresholdFilter() para convertir la imagen a blanco y negro, lo que es más adecuado para la conversión de Tesseract.
ThresholdFilter thresholdFilter() toma image.data y level como sus parámetros. El level se utiliza para establecer qué tan blanca o negra debe ser la imagen. Determinamos el nivel de filtro de thresholdFilter y el radio de blurRGB mediante prueba y error, ya que no estamos seguros de qué tan blanca, oscura o suave debe ser la imagen para que Tesseract produzca un gran resultado.
Prueba #3
Aquí está el nuevo resultado después de aplicar cuatro técnicas:

La imagen de arriba representa el resultado que obtenemos tanto en Chrome como en Firefox.
¡UPS! El resultado es terrible.
En lugar de usar las cuatro técnicas, ¿por qué no usamos dos de ellas a la vez?
¡Si! Simplemente podemos usar las técnicas invertColors y thresholdFilter para convertir la imagen a blanco y negro, y cambiar el primer plano y el fondo de la imagen. Pero , ¿cómo sabemos qué y qué técnicas combinar? Sabemos qué combinar según la naturaleza de la imagen que queremos preprocesar.
Por ejemplo, una imagen digital debe convertirse a blanco y negro, y una imagen con parches debe desenfocarse para eliminar los puntos/parches. Lo realmente importante es entender para qué sirve cada una de las técnicas.
Para usar invertColors y thresholdFilter , debemos comentar blurARGB y dilate en preprocessImage :
function preprocessImage(canvas) { const ctx = canvas.getContext('2d'); const image = ctx.getImageData(0,0,canvas.width, canvas.height); // blurARGB(image.data, canvas, 1); // dilate(image.data, canvas); invertColors(image.data); thresholdFilter(image.data, 0.5); return image; }Prueba #4
Ahora, aquí está el nuevo resultado:

El resultado es aún peor que el que no tiene ningún procesamiento previo. Después de ajustar cada una de las técnicas para esta imagen en particular y algunas otras imágenes, he llegado a la conclusión de que las imágenes con diferente naturaleza requieren diferentes técnicas de preprocesamiento.
En resumen, el uso de Tesseract.js sin preprocesamiento de imágenes produjo el mejor resultado para la tarjeta de regalo anterior. Todos los demás experimentos con preprocesamiento de imágenes arrojaron resultados menos precisos.
Asunto
Inicialmente, quería extraer el PIN de cualquier tarjeta de regalo de Amazon, pero no pude lograrlo porque no tiene sentido hacer coincidir un PIN inconsistente para obtener un resultado consistente. Aunque es posible procesar una imagen para obtener un PIN preciso, tal procesamiento previo será inconsistente cuando se use otra imagen con una naturaleza diferente.
El mejor resultado producido
La siguiente imagen muestra el mejor resultado producido por los experimentos.
Prueba #5

Los textos de la imagen y los extraídos son totalmente iguales. La conversión tiene un 100% de precisión. Traté de reproducir el resultado, pero solo pude reproducirlo cuando usé imágenes de naturaleza similar.
Observación y lecciones
- Algunas imágenes que no están preprocesadas pueden dar resultados diferentes en diferentes navegadores . Esta afirmación es evidente en la primera prueba. El resultado en Firefox es diferente al de Chrome. Sin embargo, el preprocesamiento de imágenes ayuda a lograr un resultado consistente en otras pruebas.
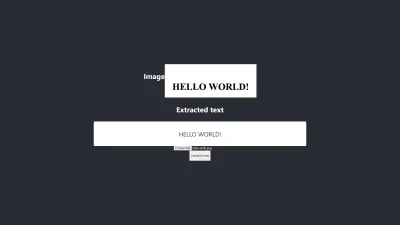
- El color negro sobre un fondo blanco tiende a dar resultados manejables. La imagen a continuación es un ejemplo de un resultado preciso sin ningún procesamiento previo . También pude obtener el mismo nivel de precisión al preprocesar la imagen, pero me llevó muchos ajustes que eran innecesarios.
La conversión es 100% precisa.
- Un texto con un tamaño de fuente grande tiende a ser más preciso.
- Las fuentes con bordes curvos tienden a confundir a Tesseract. El mejor resultado que obtuve se logró cuando usé Arial (fuente).
- Actualmente, OCR no es lo suficientemente bueno para automatizar la conversión de imagen a texto, especialmente cuando se requiere un nivel de precisión superior al 80%. Sin embargo, se puede utilizar para que el procesamiento manual de textos en imágenes sea menos estresante mediante la extracción de textos para su corrección manual.
- OCR actualmente no es lo suficientemente bueno para pasar información útil a lectores de pantalla para accesibilidad . Proporcionar información inexacta a un lector de pantalla puede engañar o distraer fácilmente a los usuarios.
- OCR es muy prometedor ya que las redes neuronales permiten aprender y mejorar. El aprendizaje profundo hará que OCR cambie las reglas del juego en un futuro próximo .
- Tomar decisiones con confianza. Se puede utilizar una puntuación de confianza para tomar decisiones que pueden tener un gran impacto en nuestras aplicaciones. La puntuación de confianza se puede utilizar para determinar si aceptar o rechazar un resultado. A partir de mi experiencia y experimento, me di cuenta de que cualquier puntaje de confianza por debajo de 90 no es realmente útil. Si solo necesito extraer algunos pines de un texto, esperaré un puntaje de confianza entre 75 y 100, y todo lo que esté por debajo de 75 será rechazado .
En caso de que esté tratando con textos sin necesidad de extraer ninguna parte de ellos, definitivamente aceptaré una puntuación de confianza entre 90 y 100, pero rechazaré cualquier puntuación por debajo de esa. Por ejemplo, se esperará una precisión de 90 y superior si quiero digitalizar documentos como cheques, un giro histórico o siempre que sea necesaria una copia exacta. Pero una puntuación entre 75 y 90 es aceptable cuando una copia exacta no es importante, como obtener el PIN de una tarjeta de regalo. En resumen, una puntuación de confianza ayuda a tomar decisiones que afectan a nuestras aplicaciones.
Conclusión
Dada la limitación de procesamiento de datos causada por los textos en las imágenes y las desventajas asociadas con él, el reconocimiento óptico de caracteres (OCR) es una tecnología útil para adoptar. Aunque OCR tiene sus limitaciones, es muy prometedor debido a su uso de redes neuronales.
Con el tiempo, OCR superará la mayoría de sus limitaciones con la ayuda del aprendizaje profundo, pero antes de eso, los enfoques destacados en este artículo se pueden utilizar para lidiar con la extracción de texto de imágenes, al menos, para reducir las dificultades y pérdidas asociadas con el manual. procesamiento , especialmente desde un punto de vista empresarial.
Ahora es tu turno de probar OCR para extraer textos de imágenes. ¡Buena suerte!
Otras lecturas
- P5.js
- Preprocesamiento en OCR
- Mejorar la calidad de la salida
- Uso de JavaScript para preprocesar imágenes para OCR
- OCR en el navegador con Tesseract.js
- Una breve historia del reconocimiento óptico de caracteres
- El futuro de OCR es el aprendizaje profundo
- Cronología del reconocimiento óptico de caracteres