
Clasificación de imágenes en CNN: todo lo que necesita saber
Publicado: 2021-02-25Tabla de contenido
Introducción
Al revisar el feed de Facebook, ¿alguna vez te has preguntado cómo el software de Facebook etiqueta automáticamente a las personas en una foto de grupo? Detrás de cada interfaz de usuario interactiva de Facebook que ve, hay un algoritmo complejo y sólido que se utiliza para reconocer y etiquetar cada imagen que cargamos en la plataforma de redes sociales. Con cada imagen nuestra, solo ayudamos a mejorar la eficiencia del algoritmo. Sí, la Clasificación de Imágenes es uno de los algoritmos más utilizados donde vemos la aplicación de la Inteligencia Artificial.
En los últimos tiempos, las redes neuronales convolucionales (CNN) se han convertido en uno de los defensores más fuertes del aprendizaje profundo. Una aplicación popular de estas redes convolucionales es la clasificación de imágenes. En este tutorial, repasaremos los conceptos básicos de las redes neuronales convolucionales, veremos las diversas capas involucradas en la construcción de un modelo de CNN y finalmente visualizaremos un ejemplo de la tarea Clasificación de imágenes.
Clasificación de imágenes
Antes de entrar en los detalles del aprendizaje profundo y las redes neuronales convolucionales, comprendamos los conceptos básicos de la clasificación de imágenes. En general, la clasificación de imágenes se define como la tarea en la que damos una imagen como entrada a un modelo construido utilizando un algoritmo específico que genera la clase o la probabilidad de la clase a la que pertenece la imagen. Este proceso en el que etiquetamos una imagen para una clase en particular se llama Aprendizaje Supervisado.
Hay una gran diferencia entre cómo vemos una imagen y cómo la máquina (computadora) ve la misma imagen. Para nosotros, podemos visualizar la imagen y caracterizarla en función del color y el tamaño. Por otro lado, para la máquina, todo lo que puede ver son números. Los números que se ven se llaman píxeles.
Cada píxel tiene un valor entre 0 y 255. Por lo tanto, con estos datos numéricos, la máquina requiere algunos pasos de procesamiento previo para derivar algunos patrones o características específicas que distinguen una imagen de otra. Las redes neuronales convolucionales nos ayudan a construir algoritmos que son capaces de derivar el patrón específico de las imágenes.
Lo que vemos versus lo que ve la computadora
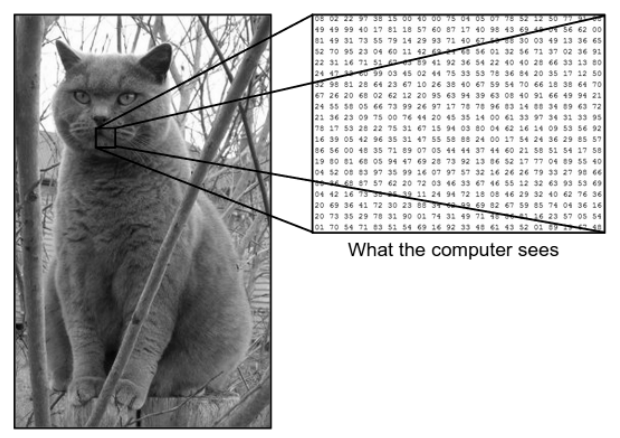 Fuente : diferencia entre la computadora y el ojo humano
Fuente : diferencia entre la computadora y el ojo humano

Aprendizaje profundo para la clasificación de imágenes
Ahora que hemos entendido qué es la clasificación de imágenes, veamos ahora cómo podemos implementarla usando inteligencia artificial. Para ello, utilizamos los populares métodos de Deep Learning. Deep Learning es un subconjunto de inteligencia artificial que utiliza grandes conjuntos de datos de imágenes para reconocer y derivar patrones de varias imágenes para diferenciar entre varias clases presentes en el conjunto de datos de imágenes.
El principal desafío al que se enfrenta el aprendizaje profundo es que, para una base de datos enorme, lleva mucho tiempo y tiene un alto costo computacional. Sin embargo, las redes neuronales convolucionales, que son un tipo de algoritmo de aprendizaje profundo, abordan bien este problema.
Redes neuronales convolucionales
En Deep Learning, las redes neuronales convolucionales son una clase de redes neuronales profundas que se utilizan principalmente en imágenes visuales. Son una arquitectura especial de las Redes Neuronales Artificiales (ANN) que fue propuesta en 1998 por Yann LeCunn. Las Redes Neuronales Convolucionales constan de dos partes.
La primera parte consta de las capas Convolucionales y las capas de Pooling en las que se lleva a cabo el proceso de extracción de características principales. En la segunda parte, las capas Totalmente Conectada y Densa realizan varias transformaciones no lineales en las características extraídas y actúan como la parte clasificadora. Aprenda CNN para la clasificación de imágenes.
Considere el ejemplo de la imagen que se muestra arriba de lo que ven el ser humano y la máquina. Como vemos, la computadora ve una matriz de píxeles. Por ejemplo, si el tamaño de la imagen es 500×500, entonces el tamaño de la matriz será 500x500x3. Aquí, 500 representa cada alto y ancho, 3 representa el canal RGB donde cada canal de color está representado por una matriz separada. La intensidad de píxeles varía de 0 a 255.
Ahora, para Clasificación de imágenes, la computadora buscará las características en el nivel base. Según nosotros, como humanos, estas características básicas del gato son sus orejas, nariz y bigotes. Mientras que para la computadora, estas características de nivel básico son las curvaturas y los límites. De esta manera, mediante el uso de varias capas diferentes, como las capas convolucionales y las capas de agrupación, la computadora extrae las características del nivel base de las imágenes.
En el modelo de red neuronal convolucional, hay varios tipos de capas, como:
- Capa de entrada
- Capa convolucional
- Capa de agrupación
- Capa completamente conectada
- Capa de salida
- Funciones de activación
Repasemos brevemente cada una de las capas antes de entrar en su aplicación en Clasificación de imágenes.
Capa de entrada
Por el nombre, entendemos que esta es la capa en la que la imagen de entrada se introducirá en el modelo CNN. Dependiendo de nuestros requisitos, podemos remodelar la imagen a diferentes tamaños, como (28,28,3)
Capa convolucional
Luego viene la capa más importante que consiste en un filtro (también conocido como kernel) con un tamaño fijo. La operación matemática de Convolución se realiza entre la imagen de entrada y el filtro. Esta es la etapa en la que la mayoría de las características básicas, como los bordes afilados y las curvas, se extraen de la imagen y, por lo tanto, esta capa también se conoce como capa extractora de características.
Capa de agrupación
Después de realizar la operación de convolución, realizamos la operación de agrupación. Esto también se conoce como reducción de resolución donde se reduce el volumen espacial de la imagen. Por ejemplo, si realizamos una operación de agrupación con un paso de 2 en una imagen con dimensiones de 28 × 28, entonces el tamaño de la imagen se reduce a 14 × 14, se reduce a la mitad de su tamaño original.
Capa completamente conectada
La capa totalmente conectada (FC) se coloca justo antes de la salida de clasificación final del modelo CNN. Estas capas se utilizan para aplanar los resultados antes de clasificarlos. Implica varios sesgos, pesos y neuronas. Adjuntar una capa FC antes de la clasificación da como resultado un vector N-dimensional donde N es un número de clases de las cuales el modelo tiene que elegir una clase.
Capa de salida
Finalmente, la capa de salida consta de la etiqueta que se codifica principalmente mediante el método de codificación one-hot.
Función de activación
Estas funciones de activación son el núcleo de cualquier modelo de red neuronal convolucional. Estas funciones se utilizan para determinar la salida de una red neuronal. En resumen, determina si una neurona en particular debe activarse ("dispararse") o no. Suelen ser funciones no lineales que se realizan en las señales de entrada. Esta salida transformada se envía luego como entrada a la siguiente capa de neuronas. Hay varias funciones de activación como Sigmoid, ReLU, Leaky ReLU, TanH y Softmax.
Arquitectura CNN básica
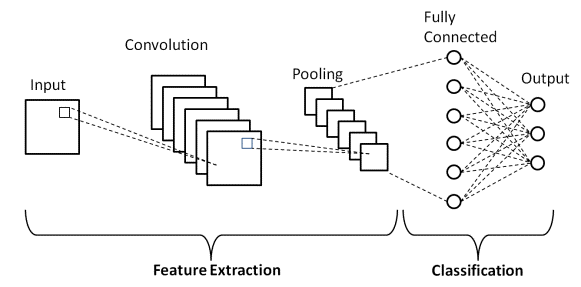
Fuente : Arquitectura básica de CNN
Como se definió anteriormente, el diagrama que se muestra arriba es la arquitectura básica de un modelo de red neuronal convolucional. Ahora que estamos listos con los conceptos básicos de clasificación de imágenes y CNN, profundicemos en su aplicación con un problema en tiempo real. Obtenga más información sobre la arquitectura básica de CNN.
Implementación de Redes Neuronales Convolucionales
Ahora que hemos entendido los conceptos básicos de clasificación de imágenes y redes neuronales convolucionales, visualicemos su implementación en TensorFlow/Keras con codificación Python. En esto, construiremos un modelo de red neuronal convolucional simple con una arquitectura LeNet básica, entrenaremos el modelo en un conjunto de entrenamiento y un conjunto de prueba y finalmente obtendremos la precisión del modelo en los datos del conjunto de prueba.
Conjunto de problemas
En este artículo para construir y entrenar el modelo de red neuronal convolucional, usaremos el famoso conjunto de datos Fashion MNIST. MNIST significa Instituto Nacional Modificado de Estándares y Tecnología. Fashion-MNIST es un conjunto de datos de imágenes de artículos de Zalando, que consta de un conjunto de entrenamiento de 60 000 ejemplos y un conjunto de prueba de 10 000 ejemplos. Cada ejemplo es una imagen en escala de grises de 28×28, asociada con una etiqueta de 10 clases.

Cada ejemplo de entrenamiento y prueba se asigna a una de las siguientes etiquetas:
0 – Camiseta/top
1 – Pantalón
2 – Jersey
3 – Vestido
4 – Abrigo
5 – Sandalia
6 – Camisa
7 – Zapatilla
8 – Bolsa
9 – Botines
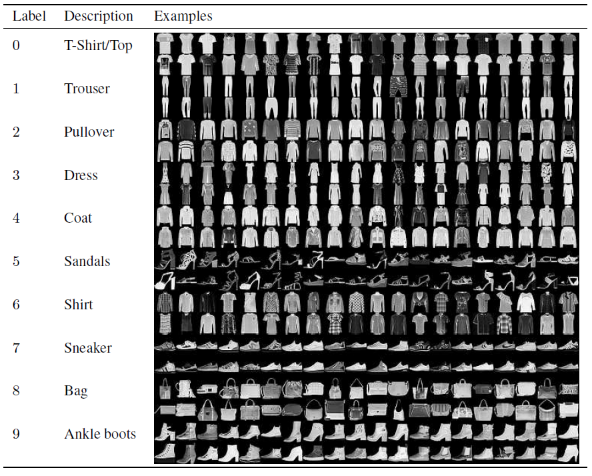
Fuente : Imágenes del conjunto de datos del MNIST de moda
Código de programa
Paso 1: importar las bibliotecas
El primer paso para construir cualquier modelo de aprendizaje profundo es importar las bibliotecas que son necesarias para el programa. En nuestro ejemplo, como estamos usando el marco TensorFlow, importaremos la biblioteca Keras y también otras bibliotecas importantes, como el número para el cálculo y matplotlib para trazar los gráficos.
#TensorFlow: Importación de las bibliotecas
importar numpy como np
importar matplotlib.pyplot como plt
% matplotlib en línea
importar tensorflow como tf
de tensorflow importar Keras
Paso 2: obtener y dividir el conjunto de datos
Una vez que hayamos importado las bibliotecas, el siguiente paso es descargar el conjunto de datos y dividir el conjunto de datos de Fashion MNIST en los respectivos 60 000 datos de entrenamiento y 10 000 datos de prueba. Afortunadamente, keras nos brinda una función predefinida para importar el conjunto de datos de Fashion MNIST y podemos dividirlos en la siguiente línea usando una línea de código simple que se entiende por sí misma.
#TensorFlow: obtener y dividir el conjunto de datos
fashion_mnist = keras.conjuntos de datos.fashion_mnist
(imágenes_de_tren_tf, etiquetas_de_tren_tf), (imágenes_de_prueba_tf, etiquetas_de_prueba_tf) = fashion_mnist.load_data()
Paso 3: visualización de los datos
Como el conjunto de datos se descarga junto con las imágenes y sus etiquetas correspondientes, para que sea más claro para el usuario, siempre se recomienda ver los datos para que podamos entender el tipo de datos con los que estamos tratando al construir el Neural Convolucional. Modelo de red en consecuencia. Aquí, con este simple bloque de código que se muestra a continuación, visualizaremos las primeras 3 imágenes del conjunto de datos de entrenamiento que se mezcla aleatoriamente.
#TensorFlow: visualización de datos
def imshowTensorFlow(img):
plt.imshow(img, cmap='gris')
imprimir(“Etiqueta:”, img[0])
imshowTensorFlow(tren_images_tf[0])
Etiqueta: 9 Etiqueta: 0 Etiqueta: 3


La imagen anterior y sus etiquetas se pueden verificar con las etiquetas que se proporcionan en los detalles del conjunto de datos de Fashion MNIST anterior. De esto, inferimos que nuestra imagen de datos es una imagen en escala de grises con una altura de 28 píxeles y un ancho de 28 píxeles.
Por lo tanto, el modelo se puede construir con un tamaño de entrada de (28,28,1), donde 1 representa la imagen en escala de grises.
Paso 4: construcción del modelo
Como se mencionó anteriormente, en este artículo construiremos una red neuronal convolucional simple con la arquitectura LeNet. LeNet es una estructura de red neuronal convolucional propuesta por Yann LeCun et al. en 1989. En general, LeNet se refiere a LeNet-5 y es una red neuronal convolucional simple.
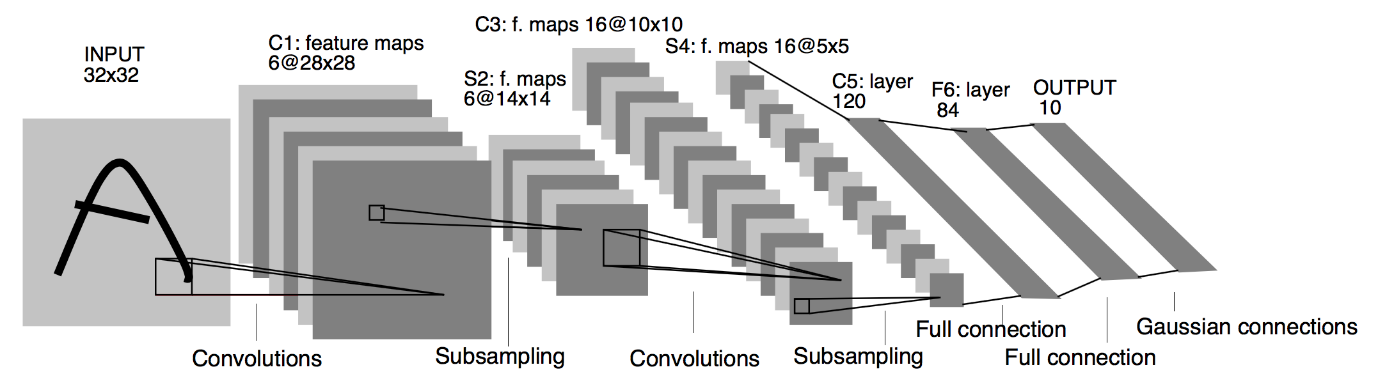
Fuente : La arquitectura LeNet
Del diagrama de arquitectura anterior del modelo LeNet CNN, vemos que hay 5+2 capas. La primera y la segunda capa son una capa convolucional seguida de una capa de agrupación. Nuevamente, las capas tercera y cuarta consisten en una capa convolucional y una capa de agrupación. Como resultado de estas operaciones, el tamaño de la imagen de entrada de 28×28 se reduce a 7×7.
La quinta capa del modelo LeNet es la capa totalmente conectada que aplana la salida de la capa anterior. Seguida de dos capas densas, la capa de salida final del modelo CNN consta de una función de activación Softmax con 10 unidades. La función Softmax predice una probabilidad de clase para cada una de las 10 clases del conjunto de datos Fashion MNIST.
#TensorFlow: construcción del modelo
modelo = keras.Sequential([
keras.layers.Conv2D(input_shape=(28,28,1), filtros=6, kernel_size=5, zancadas=1, padding=”igual”, activación=tf.nn.relu),
keras.layers.AveragePooling2D(pool_size=2, zancadas=2),
keras.layers.Conv2D(16, kernel_size=5, zancadas=1, relleno=”igual”, activación=tf.nn.relu),
keras.layers.AveragePooling2D(pool_size=2, zancadas=2),
keras.layers.Flatten(),
keras.layers.Dense(120, activación=tf.nn.relu),
keras.layers.Dense(84, activación=tf.nn.relu),
keras.layers.Dense(10, activación=tf.nn.softmax)
])
Paso 5: resumen del modelo
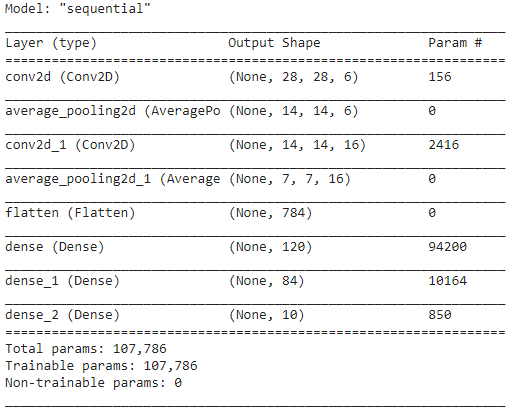
Una vez finalizadas las capas del modelo LeNet, podemos proceder a compilar el modelo y ver una versión resumida del modelo CNN diseñado.
#TensorFlow – Resumen del modelo
model.compile(loss=keras.losses.categorical_crossentropy,
optimizador='adam',
métricas=['acc'])
Resumen Modelo()
En esto, como la salida final tiene más de 2 clases (10 clases), usamos la entropía cruzada categórica como función de pérdida y Adam Optimizer para nuestro modelo construido. El resumen del modelo se muestra a continuación.
Paso 6: entrenar el modelo
Finalmente, llegamos a la parte donde comenzamos el proceso de entrenamiento del modelo LeNet CNN. En primer lugar, remodelamos el conjunto de datos de entrenamiento y lo normalizamos a valores más pequeños dividiéndolos por 255,0 para reducir el costo computacional. Luego, las etiquetas de entrenamiento se convierten de un vector de clase entero a una matriz de clase binaria. Por ejemplo, la etiqueta 3 se convierte en [0, 0, 0, 1, 0, 0, 0, 0, 0]
#TensorFlow – Entrenamiento del modelo
train_images_tensorflow = (train_images_tf / 255.0).reshape(train_images_tf.shape[0], 28, 28, 1)
test_images_tensorflow = (test_images_tf / 255.0).reshape(test_images_tf.shape[0], 28, 28 ,1)
train_labels_tensorflow=keras.utils.to_categorical(train_labels_tf)
test_labels_tensorflow=keras.utils.to_categorical(test_labels_tf)
H = model.fit(train_images_tensorflow, train_labels_tensorflow, epochs=30, batch_size=32)
Al final del entrenamiento después de 30 épocas, obtenemos la precisión y pérdida de entrenamiento final como,
Época 30/30
1875/1875 [==============================] – 4s 2ms/paso – pérdida: 0,0421 – acc: 0,9850
Precisión de entrenamiento: 98.294997215271 %
Pérdida de entrenamiento: 0.04584110900759697
Paso 7: Predecir los resultados
Finalmente, una vez que hayamos terminado con nuestro proceso de entrenamiento del modelo CNN, ajustaremos el mismo modelo en el conjunto de datos de prueba y predeciremos la precisión de 10 000 imágenes de prueba.
#TensorFlow: comparación de resultados
predicciones = model.predict(test_images_tensorflow)
correcto = 0
para i, pred en enumerar (predicciones):
si np.argmax(pred) == test_labels_tf[i]:
correcto += 1
print('Exactitud de la prueba del modelo en las {} imágenes de prueba: {}% con TensorFlow'.format(test_images_tf.shape[0],100 * correct/test_images_tf.shape[0]))
La salida que obtenemos es,
Precisión de prueba del modelo en las 10000 imágenes de prueba: 90,67 % con TensorFlow
Con esto damos por concluido el programa de construcción de un Modelo de Clasificación de Imágenes con Redes Neuronales Convolucionales.
Lea también: Ideas de proyectos de aprendizaje automático
Conclusión
Por lo tanto, en este tutorial sobre la implementación de la clasificación de imágenes en CNN, hemos entendido los conceptos básicos detrás de la clasificación de imágenes, las redes neuronales convolucionales junto con su implementación en el lenguaje de programación Python con el marco TensorFlow.
Si está interesado en obtener más información sobre el aprendizaje automático, consulte el Diploma PG en aprendizaje automático e IA de IIIT-B y upGrad, que está diseñado para profesionales que trabajan y ofrece más de 450 horas de capacitación rigurosa, más de 30 estudios de casos y asignaciones, IIIT- B Estado de exalumno, más de 5 proyectos prácticos finales prácticos y asistencia laboral con las mejores empresas.
¿Qué modelo de CNN se considera el más óptimo para la clasificación de imágenes?
El mejor modelo de CNN para la clasificación de imágenes es el VGG-16, que significa Redes convolucionales muy profundas para el reconocimiento de imágenes a gran escala. VGG, que se diseñó como una CNN profunda, supera las líneas de base en una amplia gama de tareas y conjuntos de datos fuera de ImageNet. La característica distintiva del modelo es que cuando se estaba creando, se prestó más atención a la incorporación de excelentes capas de convolución en lugar de centrarse en agregar una gran cantidad de hiperparámetros. Tiene un total de 16 capas, 5 bloques, y cada bloque tiene una capa de agrupación máxima, lo que la convierte en una red bastante grande.
¿Cuáles son las desventajas de usar modelos CNN para la clasificación de imágenes?
Cuando se trata de clasificación de imágenes, los modelos CNN son muy exitosos. Sin embargo, hay varios inconvenientes en el empleo de CNN. Si la imagen a identificar está inclinada o girada, el modelo CNN tiene problemas para identificar la imagen con precisión. Cuando CNN visualiza las imágenes, no hay representaciones internas de los componentes y sus conexiones parte-todo. Además, si el modelo CNN a emplear incluye numerosas capas convolucionales, el proceso de clasificación llevará mucho tiempo.
¿Por qué se prefiere el uso del modelo CNN sobre el ANN para datos de imagen como entrada?
Al combinar filtros o transformaciones, CNN puede aprender muchas capas de representaciones de características para cada imagen proporcionada como entrada. El sobreajuste se reduce ya que la cantidad de parámetros que la red debe aprender en CNN es sustancialmente menor que en las redes neuronales multicapa. Al usar ANN, las redes neuronales pueden aprender una sola representación de características de la imagen, pero, en el caso de imágenes complejas, ANN no podrá proporcionar visualizaciones o clasificaciones mejoradas, ya que no puede aprender las dependencias de píxeles existentes en las imágenes de entrada.