
HTTP/3: mejoras de rendimiento (parte 2)
Publicado: 2022-03-10Bienvenido de nuevo a esta serie sobre el nuevo protocolo HTTP/3. En la parte 1, analizamos por qué necesitamos exactamente HTTP/3 y el protocolo QUIC subyacente, y cuáles son sus principales funciones nuevas.
En esta segunda parte, nos centraremos en las mejoras de rendimiento que QUIC y HTTP/3 aportan a la carga de páginas web. Sin embargo, también seremos algo escépticos sobre el impacto que podemos esperar de estas nuevas funciones en la práctica.
Como veremos, QUIC y HTTP/3 tienen un gran potencial de rendimiento web, pero principalmente para usuarios en redes lentas . Si su visitante promedio está en una red rápida por cable o celular, probablemente no se beneficiarán mucho de los nuevos protocolos. Sin embargo, tenga en cuenta que incluso en países y regiones con enlaces ascendentes típicamente rápidos, el 1% más lento hasta incluso el 10% de su audiencia (los llamados percentiles 99 o 90 ) aún pueden ganar mucho. Esto se debe a que HTTP/3 y QUIC ayudan principalmente a lidiar con los problemas poco comunes pero potencialmente de alto impacto que pueden surgir en la Internet actual.
Esta parte es un poco más técnica que la primera, aunque descarga la mayoría de las cosas realmente profundas a fuentes externas, enfocándose en explicar por qué estas cosas son importantes para el desarrollador web promedio.
- Parte 1: Historia de HTTP/3 y conceptos básicos
Este artículo está dirigido a personas nuevas en HTTP/3 y protocolos en general, y trata principalmente los conceptos básicos. - Parte 2: Funciones de rendimiento de HTTP/3
Este es más profundo y técnico. Las personas que ya conocen los conceptos básicos pueden comenzar aquí. - Parte 3: Opciones prácticas de implementación de HTTP/3
Este tercer artículo de la serie explica los desafíos que implica implementar y probar HTTP/3 usted mismo. También detalla cómo y si debe cambiar sus páginas web y recursos.
Una introducción a la velocidad
Discutir el rendimiento y la "velocidad" puede volverse complejo rápidamente, porque muchos aspectos subyacentes contribuyen a que una página web se cargue "lentamente". Debido a que aquí nos ocupamos de los protocolos de red, nos centraremos principalmente en los aspectos de la red, de los cuales dos son los más importantes: la latencia y el ancho de banda.
La latencia se puede definir aproximadamente como el tiempo que lleva enviar un paquete desde el punto A (digamos, el cliente) al punto B (el servidor) . Está físicamente limitado por la velocidad de la luz o, en la práctica, qué tan rápido pueden viajar las señales en los cables o al aire libre. Esto significa que la latencia a menudo depende de la distancia física del mundo real entre A y B.
En la tierra, esto significa que las latencias típicas son conceptualmente pequeñas, entre aproximadamente 10 y 200 milisegundos. Sin embargo, esto es solo de una manera: las respuestas a los paquetes también deben regresar. La latencia bidireccional a menudo se denomina tiempo de ida y vuelta (RTT) .
Debido a funciones como el control de congestión (ver más abajo), a menudo necesitaremos bastantes viajes de ida y vuelta para cargar incluso un solo archivo. Como tal, incluso las latencias bajas de menos de 50 milisegundos pueden sumar retrasos considerables. Esta es una de las razones principales por las que existen las redes de entrega de contenido (CDN): colocan los servidores físicamente más cerca del usuario final para reducir la latencia y, por lo tanto, el retraso, tanto como sea posible.
Entonces, se puede decir aproximadamente que el ancho de banda es la cantidad de paquetes que se pueden enviar al mismo tiempo . Esto es un poco más difícil de explicar, porque depende de las propiedades físicas del medio (por ejemplo, la frecuencia utilizada de las ondas de radio), la cantidad de usuarios en la red y también los dispositivos que interconectan diferentes subredes (porque típicamente solo puede procesar una cierta cantidad de paquetes por segundo).
Una metáfora de uso frecuente es la de una tubería utilizada para transportar agua. La longitud de la tubería es la latencia, mientras que el ancho de la tubería es el ancho de banda. En Internet, sin embargo, normalmente tenemos una larga serie de conductos conectados , algunos de los cuales pueden ser más anchos que otros (lo que lleva a los llamados cuellos de botella en los enlaces más estrechos). Como tal, el ancho de banda de extremo a extremo entre los puntos A y B a menudo está limitado por las subsecciones más lentas.
Si bien no se necesita una comprensión perfecta de estos conceptos para el resto de esta publicación, sería bueno tener una definición común de alto nivel. Para obtener más información, recomiendo consultar el excelente capítulo de Ilya Grigorik sobre latencia y ancho de banda en su libro High Performance Browser Networking .
Control de Congestión
Un aspecto del rendimiento tiene que ver con la eficiencia con la que un protocolo de transporte puede utilizar el ancho de banda completo (físico) de una red (es decir, aproximadamente, cuántos paquetes por segundo se pueden enviar o recibir). Esto, a su vez, afecta la rapidez con la que se pueden descargar los recursos de una página. Algunos afirman que QUIC de alguna manera hace esto mucho mejor que TCP, pero eso no es cierto.
¿Sabías?
Una conexión TCP, por ejemplo, no comienza simplemente a enviar datos a todo el ancho de banda, ya que esto podría terminar sobrecargando (o congestionando) la red. Esto se debe a que, como dijimos, cada enlace de red tiene solo una cierta cantidad de datos que puede procesar (físicamente) cada segundo. Dale más y no hay otra opción que descartar los paquetes excesivos, lo que lleva a la pérdida de paquetes .
Como se discutió en la parte 1, para un protocolo confiable como TCP, la única forma de recuperarse de la pérdida de paquetes es retransmitir una nueva copia de los datos, lo que requiere un viaje de ida y vuelta. Especialmente en redes de alta latencia (digamos, con un RTT de más de 50 milisegundos), la pérdida de paquetes puede afectar seriamente el rendimiento.
Otro problema es que no sabemos por adelantado cuánto será el ancho de banda máximo . A menudo depende de un cuello de botella en algún lugar de la conexión de extremo a extremo, pero no podemos predecir ni saber dónde estará. Internet tampoco tiene mecanismos (todavía) para señalar las capacidades de los enlaces a los puntos finales.
Además, incluso si supiéramos el ancho de banda físico disponible, eso no significaría que podríamos usarlo todo nosotros mismos. Por lo general, varios usuarios están activos en una red al mismo tiempo, cada uno de los cuales necesita una parte justa del ancho de banda disponible.
Como tal, una conexión no sabe cuánto ancho de banda puede usar de manera segura o justa por adelantado, y este ancho de banda puede cambiar a medida que los usuarios se unen, salen y usan la red. Para resolver este problema, TCP intentará constantemente descubrir el ancho de banda disponible a lo largo del tiempo mediante el uso de un mecanismo llamado control de congestión .
Al comienzo de la conexión, envía solo unos pocos paquetes (en la práctica, entre 10 y 100 paquetes, o alrededor de 14 y 140 KB de datos) y espera un viaje de ida y vuelta hasta que el receptor envía un acuse de recibo de estos paquetes. Si todos son reconocidos, esto significa que la red puede manejar esa tasa de envío y podemos intentar repetir el proceso pero con más datos (en la práctica, la tasa de envío generalmente se duplica con cada iteración).
De esta manera, la tasa de envío continúa creciendo hasta que no se reconocen algunos paquetes (lo que indica pérdida de paquetes y congestión de la red). Esta primera fase se suele denominar “inicio lento”. Tras la detección de la pérdida de paquetes, TCP reduce la velocidad de envío y (después de un tiempo) comienza a aumentar la velocidad de envío nuevamente, aunque en incrementos (mucho) más pequeños. Esta lógica de reducción y luego crecimiento se repite para cada pérdida de paquete posterior. Eventualmente, esto significa que TCP intentará constantemente alcanzar su cuota de ancho de banda ideal y justa. Este mecanismo se ilustra en la figura 1.
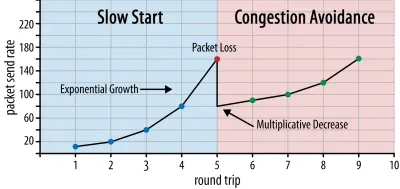
Esta es una explicación extremadamente simplificada del control de la congestión. En la práctica, muchos otros factores están en juego, como la sobrecarga del búfer, la fluctuación de los RTT debido a la congestión y el hecho de que múltiples remitentes simultáneos necesitan obtener su parte justa del ancho de banda. Como tal, existen muchos algoritmos de control de congestión diferentes, y todavía se están inventando muchos hoy en día, y ninguno funciona de manera óptima en todas las situaciones.
Si bien el control de congestión de TCP lo hace sólido, también significa que lleva un tiempo alcanzar las tasas de envío óptimas , según el RTT y el ancho de banda disponible real. Para la carga de páginas web, este enfoque de inicio lento también puede afectar métricas como la primera pintura con contenido, porque solo se puede transferir una pequeña cantidad de datos (de decenas a unos pocos cientos de KB) en los primeros viajes de ida y vuelta. (Es posible que haya escuchado la recomendación de mantener sus datos críticos en menos de 14 KB).
Elegir un enfoque más agresivo podría conducir a mejores resultados en redes de gran ancho de banda y alta latencia, especialmente si no le importa la pérdida ocasional de paquetes. Aquí es donde nuevamente he visto muchas interpretaciones erróneas sobre cómo funciona QUIC.
Como se discutió en la parte 1, QUIC, en teoría, sufre menos la pérdida de paquetes (y el bloqueo de encabezado de línea (HOL) relacionado) porque trata la pérdida de paquetes en el flujo de bytes de cada recurso de forma independiente. Además, QUIC se ejecuta sobre el Protocolo de datagramas de usuario (UDP), que, a diferencia de TCP, no tiene una función de control de congestión incorporada; le permite intentar enviar a la velocidad que desee y no retransmite los datos perdidos.
Esto ha llevado a muchos artículos a afirmar que QUIC tampoco usa el control de congestión, que QUIC puede comenzar a enviar datos a una velocidad mucho más alta que UDP (dependiendo de la eliminación del bloqueo HOL para lidiar con la pérdida de paquetes), que es por eso que QUIC es mucho más rápido que TCP.
En realidad, nada podría estar más lejos de la verdad: QUIC en realidad usa técnicas de administración de ancho de banda muy similares a las de TCP . También comienza con una tasa de envío más baja y la aumenta con el tiempo, utilizando reconocimientos como un mecanismo clave para medir la capacidad de la red. Esto se debe (entre otras razones) a que QUIC debe ser confiable para ser útil para algo como HTTP, porque debe ser justo con otras conexiones QUIC (¡y TCP!), y porque su eliminación del bloqueo HOL no en realidad ayuda contra la pérdida de paquetes muy bien (como veremos a continuación).
Sin embargo, eso no significa que QUIC no pueda ser (un poco) más inteligente sobre cómo administra el ancho de banda que TCP. Esto se debe principalmente a que QUIC es más flexible y fácil de evolucionar que TCP . Como dijimos, los algoritmos de control de congestión todavía están evolucionando mucho en la actualidad y es probable que necesitemos, por ejemplo, modificar las cosas para aprovechar al máximo 5G.
Sin embargo, TCP generalmente se implementa en el núcleo del sistema operativo (SO), un entorno seguro y más restringido, que para la mayoría de los sistemas operativos ni siquiera es de código abierto. Como tal, el ajuste de la lógica de congestión generalmente solo lo realizan unos pocos desarrolladores seleccionados, y la evolución es lenta.
Por el contrario, la mayoría de las implementaciones de QUIC se realizan actualmente en el "espacio del usuario" (donde generalmente ejecutamos aplicaciones nativas) y se hacen de código abierto, explícitamente para fomentar la experimentación por parte de un grupo mucho más amplio de desarrolladores (como ya se muestra, por ejemplo, por Facebook ).
Otro ejemplo concreto es la propuesta de extensión de frecuencia de acuse de recibo retrasado para QUIC. Si bien, de forma predeterminada, QUIC envía un reconocimiento por cada 2 paquetes recibidos, esta extensión permite que los puntos finales reconozcan, por ejemplo, cada 10 paquetes. Se ha demostrado que esto brinda grandes beneficios de velocidad en redes satelitales y de ancho de banda muy alto, porque se reduce la sobrecarga de transmisión de los paquetes de reconocimiento. La adopción de una extensión de este tipo para TCP llevaría mucho tiempo, mientras que para QUIC es mucho más fácil de implementar.
Como tal, podemos esperar que la flexibilidad de QUIC conduzca a una mayor experimentación y mejores algoritmos de control de congestión con el tiempo, lo que a su vez también podría adaptarse a TCP para mejorarlo.
¿Sabías?
El RFC 9002 oficial de QUIC Recovery especifica el uso del algoritmo de control de congestión de NewReno. Si bien este enfoque es sólido, también está algo desactualizado y ya no se usa mucho en la práctica. Entonces, ¿por qué está en el QUIC RFC? La primera razón es que cuando se inició QUIC, NewReno era el algoritmo de control de congestión más reciente que se estandarizó. Los algoritmos más avanzados, como BBR y CUBIC, aún no están estandarizados o se convirtieron en RFC recientemente.
La segunda razón es que NewReno es una configuración relativamente simple. Debido a que los algoritmos necesitan algunos ajustes para lidiar con las diferencias de QUIC con TCP, es más fácil explicar esos cambios en un algoritmo más simple. Como tal, RFC 9002 debe leerse más como "cómo adaptar un algoritmo de control de congestión a QUIC", en lugar de "esto es lo que debe usar para QUIC". De hecho, la mayoría de las implementaciones de QUIC a nivel de producción han hecho implementaciones personalizadas tanto de Cubic como de BBR.
Vale la pena repetir que los algoritmos de control de congestión no son específicos de TCP o QUIC ; pueden ser utilizados por cualquiera de los protocolos, y la esperanza es que los avances en QUIC finalmente lleguen también a las pilas TCP.
¿Sabías?
Tenga en cuenta que, junto al control de congestión, hay un concepto relacionado llamado control de flujo. Estas dos funciones a menudo se confunden en TCP, porque se dice que ambas usan la "ventana TCP" , aunque en realidad hay dos ventanas: la ventana de congestión y la ventana de recepción TCP. Sin embargo, el control de flujo entra en juego mucho menos para el caso de uso de la carga de páginas web que nos interesan, por lo que lo omitiremos aquí. Hay información más detallada disponible.
¿Que significa todo esto?
QUIC todavía está sujeto a las leyes de la física y la necesidad de ser amable con otros remitentes en Internet. Esto significa que no descargará mágicamente los recursos de su sitio web mucho más rápido que TCP. Sin embargo, la flexibilidad de QUIC significa que será más fácil experimentar con nuevos algoritmos de control de congestión, lo que debería mejorar las cosas en el futuro tanto para TCP como para QUIC.
Configuración de conexión 0-RTT
Un segundo aspecto de rendimiento es cuántos viajes de ida y vuelta se necesitan antes de poder enviar datos HTTP útiles (por ejemplo, recursos de página) en una nueva conexión. Algunos afirman que QUIC es de dos a tres viajes de ida y vuelta más rápido que TCP + TLS, pero veremos que en realidad es solo uno.
¿Sabías?
Como dijimos en la parte 1, una conexión generalmente realiza uno (TCP) o dos (TCP + TLS) protocolos de enlace antes de que se puedan intercambiar las solicitudes y respuestas HTTP. Estos apretones de manos intercambian parámetros iniciales que tanto el cliente como el servidor necesitan saber para, por ejemplo, cifrar los datos.
Como puede ver en la figura 2 a continuación, cada apretón de manos individual requiere al menos un viaje de ida y vuelta para completarse (TCP + TLS 1.3, (b)) y, a veces, dos (TLS 1.2 y anterior (a)). Esto es ineficiente, porque necesitamos al menos dos viajes de ida y vuelta del tiempo de espera del protocolo de enlace (sobrecarga) antes de que podamos enviar nuestra primera solicitud HTTP, lo que significa esperar al menos tres viajes de ida y vuelta para que lleguen los primeros datos de respuesta HTTP (la flecha roja que regresa). en. En redes lentas, esto puede significar una sobrecarga de 100 a 200 milisegundos.
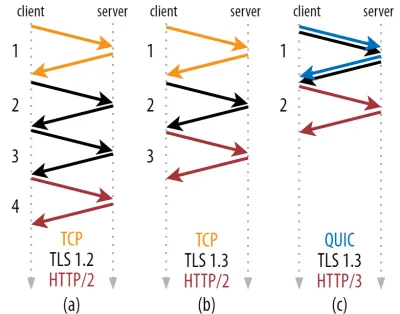
Tal vez se pregunte por qué el protocolo de enlace TCP + TLS no se puede combinar simplemente, en el mismo viaje de ida y vuelta. Si bien esto es conceptualmente posible (QUIC hace exactamente eso), las cosas inicialmente no se diseñaron así, porque necesitamos poder usar TCP con y sin TLS en la parte superior. Dicho de otra manera, TCP simplemente no admite el envío de cosas que no sean TCP durante el protocolo de enlace. Ha habido esfuerzos para agregar esto con la extensión TCP Fast Open; sin embargo, como se discutió en la parte 1, esto ha resultado ser difícil de implementar a escala.
Afortunadamente, QUIC se diseñó teniendo en cuenta TLS desde el principio y, como tal, combina los protocolos de enlace criptográficos y de transporte en un solo mecanismo. Esto significa que el protocolo de enlace QUIC tomará solo un viaje de ida y vuelta en total para completarse, que es un viaje de ida y vuelta menos que TCP + TLS 1.3 (consulte la figura 2c anterior).
Puede que esté confundido, porque probablemente haya leído que QUIC es dos o incluso tres viajes de ida y vuelta más rápido que TCP, no solo uno. Esto se debe a que la mayoría de los artículos solo consideran el peor de los casos (TCP + TLS 1.2, (a)), sin mencionar que el moderno TCP + TLS 1.3 también "solo" realiza dos viajes de ida y vuelta ((b) rara vez se muestra). Si bien un aumento de velocidad de un viaje de ida y vuelta es bueno, no es sorprendente. Especialmente en redes rápidas (digamos, menos de un RTT de 50 milisegundos), esto será apenas perceptible , aunque las redes lentas y las conexiones a servidores distantes se beneficiarían un poco más.
A continuación, es posible que se pregunte por qué tenemos que esperar al apretón de manos. ¿Por qué no podemos enviar una solicitud HTTP en el primer viaje de ida y vuelta? Esto se debe principalmente a que, si lo hiciéramos, esa primera solicitud se enviaría sin cifrar , y cualquier intruso podría leerla, lo que obviamente no es bueno para la privacidad y la seguridad. Como tal, debemos esperar a que se complete el protocolo de enlace criptográfico antes de enviar la primera solicitud HTTP. ¿O nosotros?
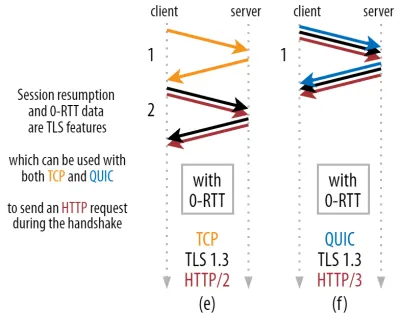
Aquí es donde se utiliza un truco inteligente en la práctica. Sabemos que los usuarios suelen volver a visitar las páginas web poco tiempo después de su primera visita. Como tal, podemos usar la conexión cifrada inicial para iniciar una segunda conexión en el futuro. En pocas palabras, en algún momento de su vida útil, la primera conexión se utiliza para comunicar de forma segura nuevos parámetros criptográficos entre el cliente y el servidor. Estos parámetros se pueden usar para cifrar la segunda conexión desde el principio, sin tener que esperar a que se complete el protocolo de enlace TLS completo. Este enfoque se denomina "reanudación de la sesión" .
Permite una potente optimización: ahora podemos enviar de forma segura nuestra primera solicitud HTTP junto con el protocolo de enlace QUIC/TLS, ¡ ahorrándonos otro viaje de ida y vuelta ! En cuanto a TLS 1.3, esto elimina efectivamente el tiempo de espera del protocolo de enlace TLS. Este método a menudo se llama 0-RTT (aunque, por supuesto, aún se necesita un viaje de ida y vuelta para que los datos de respuesta HTTP comiencen a llegar).
Tanto la reanudación de la sesión como 0-RTT son, nuevamente, cosas que a menudo he visto mal explicadas como características específicas de QUIC. En realidad, estas son características de TLS que ya estaban presentes de alguna forma en TLS 1.2 y ahora están completamente desarrolladas en TLS 1.3.
Dicho de otra manera, como puede ver en la figura 3 a continuación, ¡podemos obtener los beneficios de rendimiento de estas características sobre TCP (y por lo tanto también HTTP/2 e incluso HTTP/1.1) también! Vemos que incluso con 0-RTT, QUIC sigue siendo solo un viaje de ida y vuelta más rápido que una pila TCP + TLS 1.3 que funciona de manera óptima. La afirmación de que QUIC es tres viajes de ida y vuelta más rápido proviene de comparar la figura 2 (a) con la figura 3 (f), lo cual, como hemos visto, no es realmente justo.
La peor parte es que cuando se usa 0-RTT, QUIC ni siquiera puede usar ese viaje de ida y vuelta ganado tan bien debido a la seguridad. Para comprender esto, debemos comprender una de las razones por las que existe el protocolo de enlace TCP. Primero, le permite al cliente estar seguro de que el servidor está realmente disponible en la dirección IP dada antes de enviarle cualquier dato de capa superior.
En segundo lugar, y de manera crucial aquí, permite que el servidor se asegure de que el cliente que abre la conexión es realmente quién y dónde dice que está antes de enviarle datos. Si recuerda cómo definimos una conexión con la tupla de 4 en la parte 1, sabrá que el cliente se identifica principalmente por su dirección IP. Y este es el problema: ¡ las direcciones IP pueden ser falsificadas !
Suponga que un atacante solicita un archivo muy grande a través de HTTP sobre QUIC 0-RTT. Sin embargo, falsifican su dirección IP, haciendo que parezca que la solicitud 0-RTT proviene de la computadora de su víctima. Esto se muestra en la figura 4 a continuación. El servidor QUIC no tiene forma de detectar si la IP fue suplantada, porque este es el primer paquete que ve de ese cliente.

Si el servidor simplemente comienza a enviar el archivo grande de regreso a la IP falsificada, podría terminar sobrecargando el ancho de banda de la red de la víctima (especialmente si el atacante hiciera muchas de estas solicitudes falsas en paralelo). Tenga en cuenta que la víctima eliminaría la respuesta QUIC, porque no espera datos entrantes, pero eso no importa: ¡su red aún necesita procesar los paquetes!
Esto se denomina ataque de reflexión o amplificación, y es una forma importante en que los piratas informáticos ejecutan ataques de denegación de servicio distribuido (DDoS). Tenga en cuenta que esto no sucede cuando se usa 0-RTT sobre TCP + TLS, precisamente porque el protocolo de enlace TCP debe completarse primero antes de que se envíe la solicitud 0-RTT junto con el protocolo de enlace TLS.
Como tal, QUIC debe ser conservador al responder a las solicitudes de 0-RTT, limitando la cantidad de datos que envía en respuesta hasta que se haya verificado que el cliente es un cliente real y no una víctima. Para QUIC, esta cantidad de datos se ha establecido en tres veces la cantidad recibida del cliente.
Dicho de otra manera, QUIC tiene un "factor de amplificación" máximo de tres, que se determinó como una compensación aceptable entre la utilidad del rendimiento y el riesgo de seguridad (especialmente en comparación con algunos incidentes que tenían un factor de amplificación de más de 51 000 veces). Debido a que el cliente generalmente envía primero solo uno o dos paquetes, la respuesta 0-RTT del servidor QUIC tendrá un límite de solo 4 a 6 KB (¡incluidos otros gastos generales de QUIC y TLS!), lo que es algo menos que impresionante.
Además, otros problemas de seguridad pueden dar lugar, por ejemplo, a “ataques de repetición”, que limitan el tipo de solicitud HTTP que puede realizar. Por ejemplo, Cloudflare solo permite solicitudes HTTP GET sin parámetros de consulta en 0-RTT. Estos limitan aún más la utilidad de 0-RTT.
Afortunadamente, QUIC tiene opciones para hacer esto un poco mejor. Por ejemplo, el servidor puede verificar si el 0-RTT proviene de una IP con la que ha tenido una conexión válida anteriormente. Sin embargo, eso solo funciona si el cliente permanece en la misma red (lo que limita un poco la función de migración de conexión de QUIC). E incluso si funciona, la respuesta de QUIC todavía está limitada por la lógica de inicio lento del controlador de congestión que discutimos anteriormente; por lo tanto, no hay un aumento de velocidad masivo adicional además del viaje de ida y vuelta guardado.
¿Sabías?
Es interesante notar que el límite de amplificación de tres veces de QUIC también cuenta para su proceso normal de protocolo de enlace sin RTT en la figura 2c. Esto puede ser un problema si, por ejemplo, el certificado TLS del servidor es demasiado grande para caber entre 4 y 6 KB. En ese caso, tendría que dividirse, y el segundo fragmento tendría que esperar a que se envíe el segundo viaje de ida y vuelta (después de que lleguen los reconocimientos de los primeros paquetes, lo que indica que la IP del cliente no fue falsificada). En este caso, el apretón de manos de QUIC aún podría terminar tomando dos viajes de ida y vuelta , ¡igual a TCP + TLS! Por eso, para QUIC, las técnicas como la compresión de certificados serán muy importantes.
¿Sabías?
Es posible que ciertas configuraciones avanzadas puedan mitigar estos problemas lo suficiente como para hacer que 0-RTT sea más útil. Por ejemplo, el servidor puede recordar cuánto ancho de banda tenía disponible un cliente la última vez que se vio, lo que lo hace menos limitado por el inicio lento del control de congestión para volver a conectar clientes (no falsificados). Esto ha sido investigado en la academia, e incluso hay una extensión propuesta en QUIC para hacer esto. Varias empresas ya hacen este tipo de cosas para acelerar TCP también.
Otra opción sería hacer que los clientes envíen más de uno o dos paquetes (por ejemplo, enviar 7 paquetes más con relleno), por lo que el límite de tres veces se traduce en una respuesta más interesante de 12 a 14 KB, incluso después de la migración de la conexión. He escrito sobre esto en uno de mis artículos.
Finalmente, los servidores QUIC (que se comportan mal) también podrían aumentar intencionalmente el límite de tres veces si creen que es seguro hacerlo o si no les importan los posibles problemas de seguridad (después de todo, no hay una policía de protocolo que lo impida).
Que significa todo esto?
La configuración de conexión más rápida de QUIC con 0-RTT es más una microoptimización que una nueva característica revolucionaria. En comparación con una configuración TCP + TLS 1.3 de última generación, ahorraría un máximo de un viaje de ida y vuelta. La cantidad de datos que realmente se pueden enviar en el primer viaje de ida y vuelta está limitada adicionalmente por una serie de consideraciones de seguridad.
Como tal, esta función brillará principalmente si sus usuarios están en redes con una latencia muy alta (por ejemplo, redes satelitales con RTT de más de 200 milisegundos) o si normalmente no envía muchos datos. Algunos ejemplos de estos últimos son sitios web con mucho almacenamiento en caché, así como aplicaciones de una sola página que periódicamente obtienen pequeñas actualizaciones a través de API y otros protocolos como DNS-over-QUIC. Una de las razones por las que Google vio muy buenos resultados de 0-RTT para QUIC fue que lo probó en su página de búsqueda ya altamente optimizada, donde las respuestas a las consultas son bastante pequeñas.
En otros casos, solo ganará unas pocas decenas de milisegundos en el mejor de los casos, incluso menos si ya está utilizando una CDN (¡lo que debería estar haciendo si le importa el rendimiento!).
Migración de conexión
Una tercera función de rendimiento hace que QUIC sea más rápido al transferir entre redes, al mantener intactas las conexiones existentes . Si bien esto funciona, este tipo de cambio de red no ocurre con tanta frecuencia y las conexiones aún necesitan restablecer sus velocidades de envío.
Como se explicó en la parte 1, los ID de conexión (CID) de QUIC le permiten realizar la migración de conexión al cambiar de red . Ilustramos esto con un cliente que se cambia de una red Wi-Fi a 4G mientras descarga un archivo grande. En TCP, es posible que se deba cancelar esa descarga, mientras que para QUIC podría continuar.
Primero, sin embargo, considere la frecuencia con la que realmente ocurre ese tipo de escenario. Puede pensar que esto también ocurre cuando se mueve entre puntos de acceso Wi-Fi dentro de un edificio o entre torres celulares mientras está en la carretera. Sin embargo, en esas configuraciones (si se realizan correctamente), su dispositivo normalmente mantendrá su IP intacta, porque la transición entre las estaciones base inalámbricas se realiza en una capa de protocolo más baja. Como tal, ocurre solo cuando te mueves entre redes completamente diferentes , lo que diría que no sucede con tanta frecuencia.
En segundo lugar, podemos preguntarnos si esto también funciona para otros casos de uso además de las descargas de archivos grandes y las videoconferencias y transmisiones en vivo. Si está cargando una página web en el momento exacto en que cambia de red, es posible que deba volver a solicitar algunos de los recursos (posteriores).
Sin embargo, la carga de una página suele tardar unos segundos, por lo que tampoco será muy común que coincida con un cambio de red. Además, para los casos de uso en los que se trata de una preocupación apremiante, normalmente ya existen otras mitigaciones . Por ejemplo, los servidores que ofrecen descargas de archivos grandes pueden admitir solicitudes de rango HTTP para permitir descargas reanudables.
Debido a que suele haber cierto tiempo de superposición entre la caída de la red 1 y la disponibilidad de la red 2, las aplicaciones de video pueden abrir múltiples conexiones (1 por red), sincronizándolas antes de que la red anterior desaparezca por completo. El usuario aún notará el cambio, pero no eliminará la transmisión de video por completo.
En tercer lugar, no hay garantía de que la nueva red tenga tanto ancho de banda disponible como la antigua. Como tal, aunque la conexión conceptual se mantenga intacta, el servidor QUIC no puede seguir enviando datos a altas velocidades. En cambio, para evitar sobrecargar la nueva red, necesita restablecer (o al menos reducir) la velocidad de envío y comenzar de nuevo en la fase de inicio lento del controlador de congestión.
Debido a que esta tasa de envío inicial suele ser demasiado baja para admitir realmente cosas como la transmisión de video, verá alguna pérdida de calidad o contratiempos, incluso en QUIC. En cierto modo, la migración de la conexión se trata más de evitar la rotación y la sobrecarga del contexto de la conexión en el servidor que de mejorar el rendimiento.
¿Sabías?
Tenga en cuenta que, como se mencionó anteriormente para 0-RTT, podemos idear algunas técnicas avanzadas para mejorar la migración de la conexión. Por ejemplo, podemos, nuevamente, intentar recordar cuánto ancho de banda estaba disponible en una red determinada la última vez e intentar aumentar más rápido a ese nivel para una nueva migración. Además, podríamos imaginar no simplemente cambiar entre redes, sino usar ambas al mismo tiempo. Este concepto se llama multitrayecto y lo analizamos con más detalle a continuación.
Hasta ahora, hemos hablado principalmente sobre la migración de conexión activa, donde los usuarios se mueven entre diferentes redes. Sin embargo, también hay casos de migración de conexión pasiva, en los que una determinada red cambia los parámetros. Un buen ejemplo de esto es el reenlace de traducción de direcciones de red (NAT). Si bien una discusión completa de NAT está fuera del alcance de este artículo, principalmente significa que los números de puerto de la conexión pueden cambiar en cualquier momento, sin previo aviso. Esto también sucede mucho más a menudo para UDP que para TCP en la mayoría de los enrutadores.
Si esto ocurre, el QUIC CID no cambiará y la mayoría de las implementaciones supondrán que el usuario todavía está en la misma red física y, por lo tanto, no restablecerá la ventana de congestión u otros parámetros. QUIC también incluye algunas funciones como PING e indicadores de tiempo de espera para evitar que esto suceda, ya que esto suele ocurrir en conexiones inactivas prolongadas.
Discutimos en la parte 1 que QUIC no solo usa un solo CID por razones de seguridad. En su lugar, cambia los CID cuando realiza una migración activa. En la práctica, es aún más complicado, porque tanto el cliente como el servidor tienen listas separadas de CID (llamados CID de origen y destino en QUIC RFC). Esto se ilustra en la figura 5 a continuación.
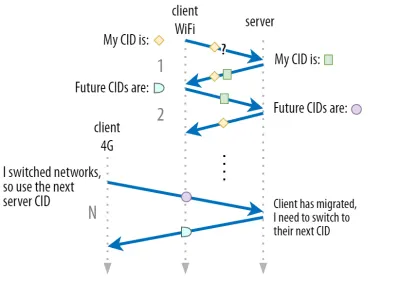
Esto se hace para permitir que cada punto final elija su propio formato y contenido de CID , lo que a su vez es crucial para permitir una lógica avanzada de enrutamiento y balanceo de carga. Con la migración de conexiones, los balanceadores de carga ya no pueden simplemente mirar la tupla de 4 para identificar una conexión y enviarla al servidor back-end correcto. Sin embargo, si todas las conexiones QUIC usaran CID aleatorios, esto aumentaría considerablemente los requisitos de memoria en el equilibrador de carga, ya que necesitaría almacenar asignaciones de CID a servidores back-end. Además, esto aún no funcionaría con la migración de conexión, ya que los CID cambian a nuevos valores aleatorios.
Como tal, es importante que los servidores back-end QUIC implementados detrás de un balanceador de carga tengan un formato predecible de sus CID, de modo que el balanceador de carga pueda derivar el servidor back-end correcto del CID, incluso después de la migración. Algunas opciones para hacer esto se describen en el documento propuesto por el IETF. Para que todo esto sea posible, los servidores deben poder elegir su propio CID, lo que no sería posible si el iniciador de la conexión (que, para QUIC, siempre es el cliente) eligiera el CID. Esta es la razón por la que hay una división entre los CID de cliente y servidor en QUIC.

Que significa todo esto?
Por lo tanto, la migración de conexiones es una característica situacional. Las pruebas iniciales de Google, por ejemplo, muestran mejoras de bajo porcentaje para sus casos de uso. Muchas implementaciones de QUIC aún no implementan esta función. Incluso aquellos que lo hacen normalmente lo limitarán a clientes y aplicaciones móviles y no a sus equivalentes de escritorio. Algunas personas incluso opinan que la función no es necesaria, porque abrir una nueva conexión con 0-RTT debería tener propiedades de rendimiento similares en la mayoría de los casos.
Aún así, dependiendo de su caso de uso o perfil de usuario, podría tener un gran impacto. Si su sitio web o aplicación se usa con mayor frecuencia mientras está en movimiento (por ejemplo, algo como Uber o Google Maps), entonces probablemente se beneficiaría más que si sus usuarios estuvieran sentados detrás de un escritorio. Similarly, if you're focusing on constant interaction (be it video chat, collaborative editing, or gaming), then your worst-case scenarios should improve more than if you have a news website.
Head-of-Line Blocking Removal
The fourth performance feature is intended to make QUIC faster on networks with a high amount of packet loss by mitigating the head-of-line (HoL) blocking problem. While this is true in theory, we will see that in practice this will probably only provide minor benefits for web-page loading performance.
To understand this, though, we first need to take a detour and talk about stream prioritization and multiplexing.
Stream Prioritization
As discussed in part 1, a single TCP packet loss can delay data for multiple in-transit resources because TCP's bytestream abstraction considers all data to be part of a single file. QUIC, on the other hand, is intimately aware that there are multiple concurrent bytestreams and can handle loss on a per-stream basis. However, as we've also seen, these streams are not truly transmitting data in parallel: Rather, the stream data is multiplexed onto a single connection. This multiplexing can happen in many different ways.
For example, for streams A, B, and C, we might see a packet sequence of ABCABCABCABCABCABCABCABC , where we change the active stream in each packet (let's call this round-robin). However, we might also see the opposite pattern of AAAAAAAABBBBBBBBCCCCCCCC , where each stream is completed in full before starting the next one (let's call this sequential). Of course, many other options are possible in between these extremes ( AAAABBCAAAAABBC… , AABBCCAABBCC… , ABABABCCCC… , etc.). The multiplexing scheme is dynamic and driven by an HTTP-level feature called stream prioritization (discussed later in this article).
As it turns out, which multiplexing scheme you choose can have a huge impact on website loading performance. You can see this in the video below, courtesy of Cloudflare, as every browser uses a different multiplexer. The reasons why are quite complex, and I've written several academic papers on the topic, as well as talked about it in a conference. Patrick Meenan, of Webpagetest fame, even has a three-hour tutorial on just this topic.
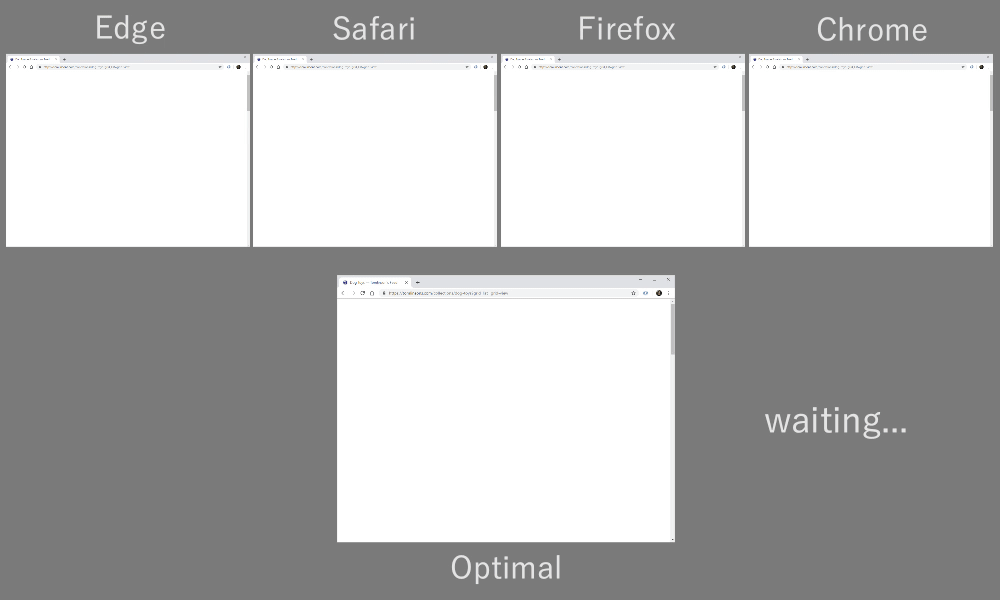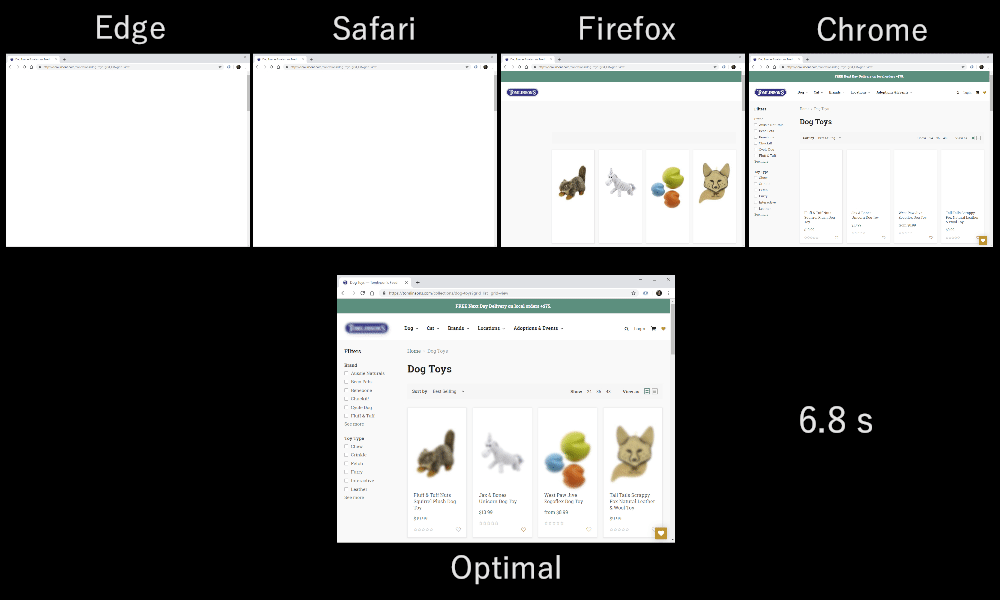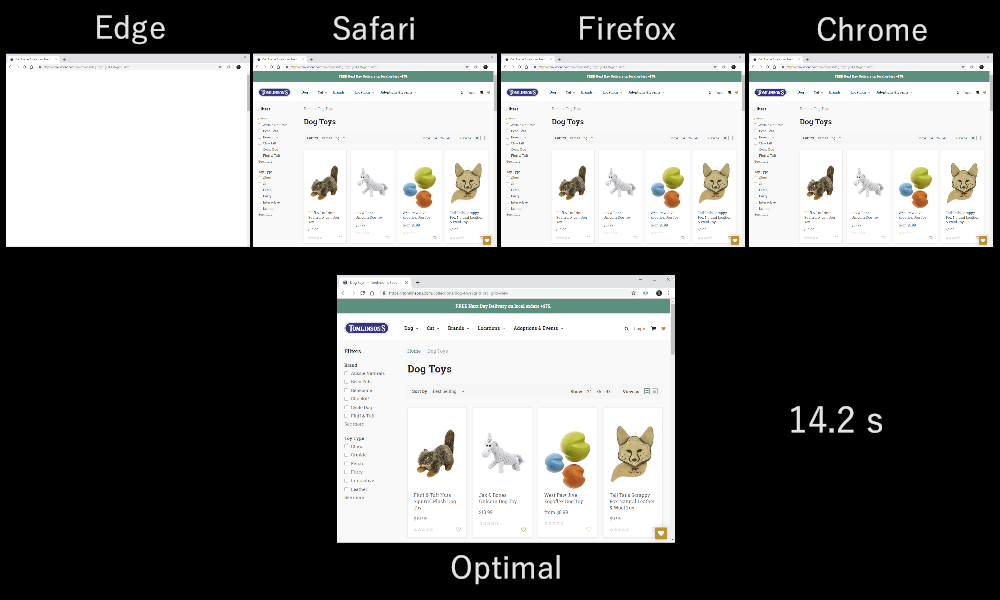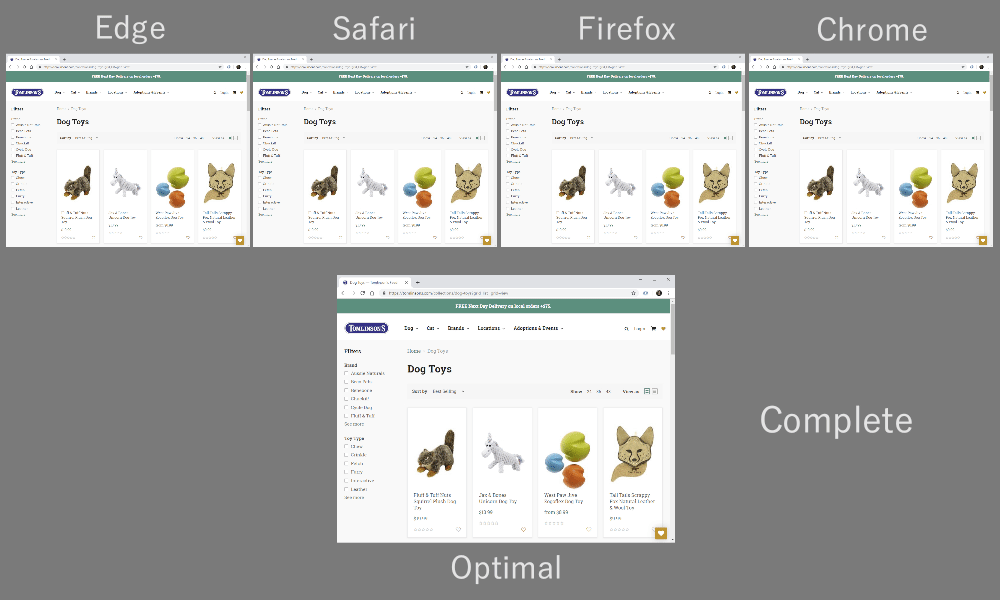
Luckily, we can explain the basics relatively easily. As you may know, some resources can be render blocking. This is the case for CSS files and for some JavaScript in the HTML head element. While these files are loading, the browser cannot paint the page (or, for example, execute new JavaScript).
What's more, CSS and JavaScript files need to be downloaded in full in order to be used (although they can often be incrementally parsed and compiled). As such, these resources need to be loaded as soon as possible, with the highest priority. Let's contemplate what would happen if A, B, and C were all render-blocking resources.
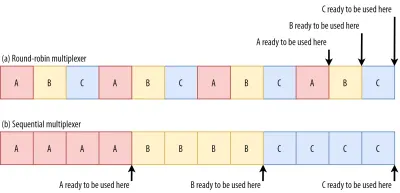
If we use a round-robin multiplexer (the top row in figure 6), we would actually delay each resource's total completion time, because they all need to share bandwidth with the others. Since we can only use them after they are fully loaded, this incurs a significant delay. However, if we multiplex them sequentially (the bottom row in figure 6), we would see that A and B complete much earlier (and can be used by the browser), while not actually delaying C's completion time.
However, that doesn't mean that sequential multiplexing is always the best, because some (mostly non-render-blocking) resources (such as HTML and progressive JPEGs) can actually be processed and used incrementally . In those (and some other) cases, it makes sense to use the first option (or at least something in between).
Still, for most web-page resources, it turns out that sequential multiplexing performs best . This is, for example, what Google Chrome is doing in the video above, while Internet Explorer is using the worst-case round-robin multiplexer.
Packet Loss Resilience
Now that we know that all streams aren't always active at the same time and that they can be multiplexed in different ways, we can consider what happens if we have packet loss. As explained in part 1, if one QUIC stream experiences packet loss, then other active streams can still be used (whereas, in TCP, all would be paused).
However, as we've just seen, having many concurrent active streams is typically not optimal for web performance, because it can delay some critical (render-blocking) resources, even without packet loss! We'd rather have just one or two active at the same time, using a sequential multiplexer. However, this reduces the impact of QUIC's HoL blocking removal.
Imagine, for example, that the sender could transmit 12 packets at a given time (see figure 7 below) — remember that this is limited by the congestion controller). If we fill all 12 of those packets with data for stream A (because it's high priority and render-blocking — think main.js ), then we would have only one active stream in that 12-packet window.
If one of those packets were to be lost, then QUIC would still end up fully HoL blocked because there would simply be no other streams it could process besides A : All of the data is for A , and so everything would still have to wait (we don't have B or C data to process), similar to TCP.

We see that we have a kind of contradiction: Sequential multiplexing ( AAAABBBBCCCC ) is typically better for web performance, but it doesn't allow us to take much advantage of QUIC's HoL blocking removal. Round-robin multiplexing ( ABCABCABCABC ) would be better against HoL blocking, but worse for web performance. As such, one best practice or optimization can end up undoing another .
And it gets worse. Up until now, we've sort of assumed that individual packets get lost one at a time. However, this isn't always true, because packet loss on the Internet is often “bursty”, meaning that multiple packets often get lost at the same time .
As discussed above, an important reason for packet loss is that a network is overloaded with too much data, having to drop excess packets. This is why the congestion controller starts sending slowly. However, it then keeps growing its send rate until… there is packet loss!
Put differently, the mechanism that's intended to prevent overloading the network actually overloads the network (albeit in a controlled fashion). On most networks, that occurs after quite a while, when the send rate has increased to hundreds of packets per round trip. When those reach the limit of the network, several of them are typically dropped together, leading to the bursty loss patterns.
Did You Know?
This is one of the reasons why we wanted to move to using a single (TCP) connection with HTTP/2, rather than the 6 to 30 connections with HTTP/1.1. Because each individual connection ramps up its send rate in pretty much the same way, HTTP/1.1 could get a good speed-up at the start, but the connections could actually start causing massive packet loss for each other as they caused the network to become overloaded.
At the time, Chromium developers speculated that this behaviour caused most of the packet loss seen on the Internet. This is also one of the reasons why BBR has become an often used congestion-control algorithm, because it uses fluctuations in observed RTTs, rather than packet loss, to assess available bandwidth.
Did You Know?
Other causes of packet loss can lead to fewer or individual packets becoming lost (or unusable), especially on wireless networks. There, however, the losses are often detected at lower protocol layers and solved between two local entities (say, the smartphone and the 4G cellular tower), rather than by retransmissions between the client and the server. These usually don't lead to real end-to-end packet loss, but rather show up as variations in packet latency (or “jitter”) and reordered packet arrivals.
So, let's say we are using a per-packet round-robin multiplexer ( ABCABCABCABCABCABCABCABC… ) to get the most out of HoL blocking removal, and we get a bursty loss of just 4 packets. We see that this will always impact all 3 streams (see figure 8, middle row)! In this case, QUIC's HoL blocking removal provides no benefits, because all streams have to wait for their own retransmissions .
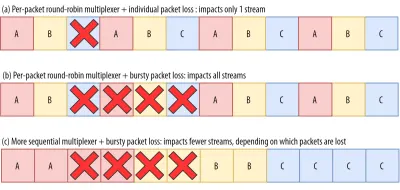
To lower the risk of multiple streams being affected by a lossy burst, we need to concatenate more data for each stream. For example, AABBCCAABBCCAABBCCAABBCC… is a small improvement, and AAAABBBBCCCCAAAABBBBCCCC… (see bottom row in figure 8 above) is even better. You can again see that a more sequential approach is better, even though that reduces the chances that we have multiple concurrent active streams.
In the end, predicting the actual impact of QUIC's HoL blocking removal is difficult, because it depends on the number of streams, the size and frequency of the loss bursts, how the stream data is actually used, etc. However, most results at this time indicate it will not help much for the use case of web-page loading, because there we typically want fewer concurrent streams.
If you want even more detail on this topic or just some concrete examples, please check out my in-depth article on HTTP HoL blocking.
Did You Know?
As with the previous sections, some advanced techniques can help us here. For example, modern congestion controllers use packet pacing. This means that they don't send, for example, 100 packets in a single burst, but rather spread them out over an entire RTT. This conceptually lowers the chances of overloading the network, and the QUIC Recovery RFC strongly recommends using it. Complementarily, some congestion-control algorithms such as BBR don't keep increasing their send rate until they cause packet loss, but rather back off before that (by looking at, for example, RTT fluctuations, because RTTs also rise when a network is becoming overloaded).
While these approaches lower the overall chances of packet loss, they don't necessarily lower its burstiness.
Que significa todo esto?
While QUIC's HoL blocking removal means, in theory, that it (and HTTP/3) should perform better on lossy networks, in practice this depends on a lot of factors. Because the use case of web-page loading typically favours a more sequential multiplexing set-up, and because packet loss is unpredictable, this feature would, again, likely affect mainly the slowest 1% of users . However, this is still a very active area of research, and only time will tell.
Still, there are situations that might see more improvements. These are mostly outside of the typical use case of the first full page load — for example, when resources are not render blocking, when they can be processed incrementally, when streams are completely independent, or when less data is sent at the same time.
Examples include repeat visits on well-cached pages and background downloads and API calls in single-page apps. For example, Facebook has seen some benefits from HoL blocking removal when using HTTP/3 to load data in its native app.
Rendimiento UDP y TLS
Un quinto aspecto del rendimiento de QUIC y HTTP/3 se refiere a la eficacia y el rendimiento con los que pueden crear y enviar paquetes en la red. Veremos que el uso de QUIC de UDP y el cifrado pesado pueden hacerlo un poco más lento que TCP (pero las cosas están mejorando).
En primer lugar, ya hemos comentado que el uso de UDP por parte de QUIC tenía más que ver con la flexibilidad y la capacidad de implementación que con el rendimiento. Esto se evidencia aún más por el hecho de que, hasta hace poco, el envío de paquetes QUIC sobre UDP solía ser mucho más lento que el envío de paquetes TCP. Esto se debe en parte a dónde y cómo se implementan normalmente estos protocolos (consulte la figura 9 a continuación).
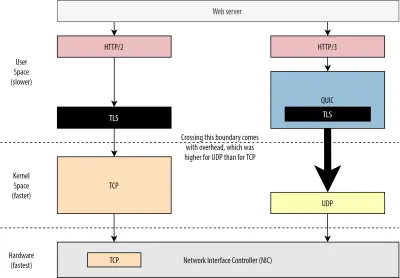
Como se discutió anteriormente, TCP y UDP generalmente se implementan directamente en el kernel rápido del sistema operativo. Por el contrario, las implementaciones de TLS y QUIC se encuentran principalmente en un espacio de usuario más lento (tenga en cuenta que esto no es realmente necesario para QUIC; se realiza principalmente porque es mucho más flexible). Esto hace que QUIC ya sea un poco más lento que TCP.
Además, cuando enviamos datos desde nuestro software de espacio de usuario (por ejemplo, navegadores y servidores web), necesitamos pasar estos datos al kernel del sistema operativo , que luego usa TCP o UDP para ponerlos realmente en la red. La transferencia de estos datos se realiza mediante las API del kernel (llamadas al sistema), lo que implica una cierta cantidad de gastos generales por llamada a la API. Para TCP, estos gastos generales fueron mucho más bajos que para UDP.
Esto se debe principalmente a que, históricamente, TCP se ha utilizado mucho más que UDP. Como tal, con el tiempo, se agregaron muchas optimizaciones a las implementaciones de TCP y las API del kernel para reducir al mínimo los gastos generales de envío y recepción de paquetes. Muchos controladores de interfaz de red (NIC) incluso tienen funciones integradas de descarga de hardware para TCP. UDP, sin embargo, no tuvo tanta suerte, porque su uso más limitado no justificaba la inversión en optimizaciones adicionales. En los últimos cinco años, esto ha cambiado afortunadamente y, desde entonces, la mayoría de los sistemas operativos también han agregado opciones optimizadas para UDP .
En segundo lugar, QUIC tiene muchos gastos generales porque encripta cada paquete individualmente . Esto es más lento que usar TLS sobre TCP, porque allí puede cifrar paquetes en fragmentos (hasta aproximadamente 16 KB u 11 paquetes a la vez), lo cual es más eficiente. Esta fue una compensación consciente realizada en QUIC, porque el cifrado masivo puede conducir a sus propias formas de bloqueo de HoL.
A diferencia del primer punto, donde podríamos agregar API adicionales para hacer que UDP (y, por lo tanto, QUIC) sea más rápido, aquí, QUIC siempre tendrá una desventaja inherente a TCP + TLS. Sin embargo, esto también es bastante manejable en la práctica con, por ejemplo, bibliotecas de cifrado optimizadas y métodos inteligentes que permiten cifrar los encabezados de los paquetes QUIC de forma masiva.
Como resultado, aunque las primeras versiones de QUIC de Google seguían siendo el doble de lentas que TCP + TLS, las cosas ciertamente han mejorado desde entonces. Por ejemplo, en pruebas recientes, la pila QUIC altamente optimizada de Microsoft pudo obtener 7,85 Gbps, en comparación con 11,85 Gbps para TCP + TLS en el mismo sistema (así que aquí, QUIC es aproximadamente un 66 % más rápido que TCP + TLS).
Esto es con las actualizaciones recientes de Windows, que hicieron que UDP fuera más rápido (para una comparación completa, el rendimiento de UDP en ese sistema fue de 19,5 Gbps). La versión más optimizada de la pila QUIC de Google es actualmente un 20 % más lenta que TCP + TLS. Las pruebas anteriores realizadas por Fastly en un sistema menos avanzado y con algunos trucos incluso afirman un rendimiento igual (alrededor de 450 Mbps), lo que demuestra que, según el caso de uso, QUIC definitivamente puede competir con TCP.
Sin embargo, incluso si QUIC fuera el doble de lento que TCP + TLS, no es tan malo. En primer lugar, el procesamiento QUIC y TCP + TLS normalmente no es lo más pesado que sucede en un servidor, porque también es necesario ejecutar otra lógica (por ejemplo, HTTP, almacenamiento en caché, proxy, etc.). Como tal, en realidad no necesitará el doble de servidores para ejecutar QUIC (sin embargo, no está claro cuánto impacto tendrá en un centro de datos real, porque ninguna de las grandes empresas ha publicado datos sobre esto).
En segundo lugar, todavía hay muchas oportunidades para optimizar las implementaciones de QUIC en el futuro. Por ejemplo, con el tiempo, algunas implementaciones de QUIC se moverán (parcialmente) al kernel del sistema operativo (al igual que TCP) o lo omitirán (algunas ya lo hacen, como MsQuic y Quant). También podemos esperar que el hardware específico de QUIC esté disponible.
Aún así, es probable que haya algunos casos de uso en los que TCP + TLS seguirá siendo la opción preferida. Por ejemplo, Netflix ha indicado que probablemente no pasará a QUIC en el corto plazo, ya que ha invertido mucho en configuraciones personalizadas de FreeBSD para transmitir sus videos a través de TCP + TLS.
De manera similar, Facebook ha dicho que QUIC probablemente se usará principalmente entre los usuarios finales y el borde de la CDN , pero no entre los centros de datos o entre los nodos del borde y los servidores de origen, debido a su mayor sobrecarga. En general, los escenarios de ancho de banda muy alto probablemente seguirán favoreciendo a TCP + TLS, especialmente en los próximos años.
¿Sabías?
La optimización de las pilas de red es un agujero de conejo profundo y técnico del cual lo anterior simplemente araña la superficie (y pierde muchos matices). Si eres lo suficientemente valiente o si quieres saber qué significan términos comoGRO/GSO,SO_TXTIME, kernel bypass ysendmmsg()yrecvmmsg(), también puedo recomendarte algunos artículos excelentes sobre la optimización de QUIC por Cloudflare y Fastly. como un extenso tutorial de código de Microsoft y una charla detallada de Cisco. Finalmente, un ingeniero de Google dio un discurso de apertura muy interesante sobre cómo optimizar su implementación de QUIC con el tiempo.
Que significa todo esto?
Históricamente, el uso particular de QUIC de los protocolos UDP y TLS lo ha hecho mucho más lento que TCP + TLS. Sin embargo, con el tiempo, se han realizado varias mejoras (y se seguirán implementando) que han cerrado la brecha de alguna manera. Sin embargo, probablemente no notará estas discrepancias en los casos de uso típicos de la carga de páginas web, pero pueden causarle dolores de cabeza si mantiene grandes granjas de servidores.
Características HTTP/3
Hasta ahora, hemos hablado principalmente sobre las nuevas funciones de rendimiento en QUIC frente a TCP. Sin embargo, ¿qué pasa con HTTP/3 frente a HTTP/2? Como se discutió en la parte 1, HTTP/3 es realmente HTTP/2-over-QUIC y, como tal, no se introdujeron nuevas características reales en la nueva versión. Esto es diferente al cambio de HTTP/1.1 a HTTP/2, que era mucho más grande e introdujo nuevas funciones como la compresión de encabezado, la priorización de secuencias y la inserción del servidor. Todas estas funciones todavía están en HTTP/3, pero existen algunas diferencias importantes en la forma en que se implementan bajo el capó.
Esto se debe principalmente a cómo funciona la eliminación del bloqueo de HoL por parte de QUIC. Como hemos discutido, una pérdida en el flujo B ya no implica que los flujos A y C tendrán que esperar las retransmisiones de B, como lo hicieron a través de TCP. Como tal, si A, B y C enviaron cada uno un paquete QUIC en ese orden, ¡sus datos bien podrían ser entregados (y procesados por) el navegador como A, C, B! Dicho de otra manera, a diferencia de TCP, ¡QUIC ya no está completamente ordenado en diferentes flujos!
Este es un problema para HTTP/2, que realmente se basó en el orden estricto de TCP en el diseño de muchas de sus funciones, que utilizan mensajes de control especiales intercalados con fragmentos de datos. En QUIC, estos mensajes de control pueden llegar (y aplicarse) en cualquier orden, ¡incluso haciendo que las funciones hagan lo contrario de lo que se pretendía! Los detalles técnicos son, nuevamente, innecesarios para este artículo, pero la primera mitad de este documento debería darle una idea de cuán estúpidamente complejo puede llegar a ser esto.
Como tal, la mecánica interna y las implementaciones de las funciones tuvieron que cambiar para HTTP/3. Un ejemplo concreto es la compresión de encabezados HTTP , que reduce la sobrecarga de encabezados HTTP grandes repetidos (por ejemplo, cookies y cadenas de agentes de usuario). En HTTP/2, esto se hizo usando la configuración HPACK, mientras que para HTTP/3 esto se modificó a QPACK más complejo. Ambos sistemas ofrecen la misma función (es decir, compresión de encabezado) pero de formas bastante diferentes. Se pueden encontrar diagramas y discusiones técnicas detalladas excelentes sobre este tema en el blog de Litespeed.
Algo similar es cierto para la función de priorización que impulsa la lógica de multiplexación de flujo y que hemos discutido brevemente anteriormente. En HTTP/2, esto se implementó utilizando una configuración compleja de "árbol de dependencia", que intentaba modelar explícitamente todos los recursos de la página y sus interrelaciones (más información en la charla "La guía definitiva para la priorización de recursos HTTP"). El uso de este sistema directamente sobre QUIC conduciría a algunos diseños de árbol potencialmente muy incorrectos, porque agregar cada recurso al árbol sería un mensaje de control separado.
Además, este enfoque resultó ser innecesariamente complejo, lo que generó muchos errores e ineficiencias en la implementación y un rendimiento mediocre en muchos servidores. Ambos problemas han llevado a rediseñar el sistema de priorización para HTTP/3 de una forma mucho más sencilla. Esta configuración más sencilla hace que algunos escenarios avanzados sean difíciles o imposibles de aplicar (por ejemplo, el tráfico de proxy de varios clientes en una sola conexión), pero aún permite una amplia gama de opciones para la optimización de la carga de páginas web.
Si bien, de nuevo, los dos enfoques ofrecen la misma característica básica (multiplexación de flujo de guía), la esperanza es que la configuración más sencilla de HTTP/3 produzca menos errores de implementación.
Por último, está el empuje del servidor . Esta función permite que el servidor envíe respuestas HTTP sin esperar primero una solicitud explícita. En teoría, esto podría generar excelentes ganancias de rendimiento. En la práctica, sin embargo, resultó ser difícil de usar correctamente y se implementó de manera inconsistente. Como resultado, es probable que incluso se elimine de Google Chrome.
A pesar de todo esto, todavía se define como una función en HTTP/3 (aunque pocas implementaciones lo admiten). Si bien su funcionamiento interno no ha cambiado tanto como las dos funciones anteriores, también se ha adaptado para funcionar alrededor del ordenamiento no determinista de QUIC. Lamentablemente, sin embargo, esto hará poco para resolver algunos de sus problemas de larga data.
Que significa todo esto?
Como dijimos antes, la mayor parte del potencial de HTTP/3 proviene del QUIC subyacente, no de HTTP/3 en sí. Si bien la implementación interna del protocolo es muy diferente de la de HTTP/2, sus características de rendimiento de alto nivel y cómo pueden y deben usarse siguen siendo las mismas.
Desarrollos futuros a tener en cuenta
En esta serie, he destacado regularmente que una evolución más rápida y una mayor flexibilidad son aspectos centrales de QUIC (y, por extensión, HTTP/3). Como tal, no debería sorprender que la gente ya esté trabajando en nuevas extensiones y aplicaciones de los protocolos. A continuación se enumeran los principales que probablemente encontrará en algún momento:
Corrección de errores de reenvío
El propósito de esta técnica es, nuevamente, mejorar la resistencia de QUIC a la pérdida de paquetes . Lo hace enviando copias redundantes de los datos (aunque inteligentemente codificadas y comprimidas para que no sean tan grandes). Entonces, si se pierde un paquete pero llegan datos redundantes, ya no es necesaria una retransmisión.
Originalmente, esto era parte de Google QUIC (y una de las razones por las que la gente dice que QUIC es bueno contra la pérdida de paquetes), pero no está incluido en la versión 1 de QUIC estandarizado porque su impacto en el rendimiento aún no se ha probado. Sin embargo, los investigadores ahora están realizando experimentos activos con él, y usted puede ayudarlos utilizando la aplicación Experimentos de descarga de PQUIC-FEC.Multitrayecto QUIC
Anteriormente discutimos la migración de la conexión y cómo puede ayudar al pasar, por ejemplo, de Wi-Fi a celular. Sin embargo, ¿eso no implica que podríamos usar Wi-Fi y celular al mismo tiempo ? ¡El uso simultáneo de ambas redes nos daría más ancho de banda disponible y una mayor robustez! Ese es el concepto principal detrás de multipath.
Esto es, nuevamente, algo con lo que Google experimentó pero que no llegó a la versión 1 de QUIC debido a su complejidad inherente. Sin embargo, desde entonces los investigadores han demostrado su alto potencial, y podría convertirse en la versión 2 de QUIC. Tenga en cuenta que también existe TCP multipath, pero ha tardado casi una década en volverse prácticamente utilizable.Datos poco fiables sobre QUIC y HTTP/3
Como hemos visto, QUIC es un protocolo completamente confiable. Sin embargo, debido a que se ejecuta sobre UDP, que no es confiable, podemos agregar una función a QUIC para enviar también datos no confiables. Esto se describe en la extensión de datagrama propuesta. Por supuesto, no querrá usar esto para enviar recursos de páginas web, pero podría ser útil para cosas como juegos y transmisión de video en vivo. De esta forma, los usuarios obtendrían todos los beneficios de UDP pero con cifrado de nivel QUIC y control de congestión (opcional).WebTransporte
Los navegadores no exponen TCP o UDP a JavaScript directamente, principalmente debido a problemas de seguridad. En cambio, tenemos que confiar en las API de nivel HTTP como Fetch y los protocolos WebSocket y WebRTC algo más flexibles. La más nueva de esta serie de opciones se llama WebTransport, que principalmente te permite usar HTTP/3 (y, por extensión, QUIC) de una forma más baja (aunque también puede recurrir a TCP y HTTP/2 si es necesario). ).
Fundamentalmente, incluirá la capacidad de usar datos no confiables a través de HTTP/3 (consulte el punto anterior), lo que debería hacer que cosas como los juegos sean un poco más fáciles de implementar en el navegador. Para las llamadas normales a la API (JSON), por supuesto, seguirá usando Fetch, que también empleará automáticamente HTTP/3 cuando sea posible. WebTransport todavía está bajo fuerte discusión en este momento, por lo que aún no está claro cómo se verá eventualmente. De los navegadores, solo Chromium está trabajando actualmente en una implementación de prueba de concepto pública.Transmisión de video DASH y HLS
Para videos que no son en vivo (piense en YouTube y Netflix), los navegadores generalmente utilizan los protocolos de transmisión dinámica adaptativa sobre HTTP (DASH) o HTTP Live Streaming (HLS). Básicamente, ambos significan que codificas tus videos en fragmentos más pequeños (de 2 a 10 segundos) y diferentes niveles de calidad (720p, 1080p, 4K, etc.).
En tiempo de ejecución, el navegador estima la calidad más alta que su red puede manejar (o la más óptima para un caso de uso dado) y solicita los archivos relevantes del servidor a través de HTTP. Debido a que el navegador no tiene acceso directo a la pila TCP (ya que normalmente se implementa en el kernel), ocasionalmente comete algunos errores en estas estimaciones, o tarda un tiempo en reaccionar a las condiciones cambiantes de la red (lo que provoca bloqueos de video) .
Debido a que QUIC se implementa como parte del navegador, esto podría mejorarse bastante, dando a los estimadores de transmisión acceso a información de protocolo de bajo nivel (como tasas de pérdida, estimaciones de ancho de banda, etc.). Otros investigadores también han estado experimentando con la mezcla de datos confiables y no confiables para la transmisión de video, con algunos resultados prometedores.Protocolos distintos de HTTP/3
Dado que QUIC es un protocolo de transporte de propósito general, podemos esperar que muchos protocolos de capa de aplicación que ahora se ejecutan sobre TCP también se ejecuten sobre QUIC. Algunos trabajos en curso incluyen DNS sobre QUIC, SMB sobre QUIC e incluso SSH sobre QUIC. Debido a que estos protocolos suelen tener requisitos muy diferentes a HTTP y la carga de páginas web, las mejoras de rendimiento de QUIC que hemos discutido podrían funcionar mucho mejor para estos protocolos.
Que significa todo esto?
La versión 1 de QUIC es solo el comienzo . Muchas funciones avanzadas orientadas al rendimiento con las que Google había experimentado anteriormente no llegaron a esta primera iteración. Sin embargo, el objetivo es hacer evolucionar rápidamente el protocolo, introduciendo nuevas extensiones y características con alta frecuencia. Como tal, con el tiempo, QUIC (y HTTP/3) deberían ser claramente más rápidos y flexibles que TCP (y HTTP/2).
Conclusión
En esta segunda parte de la serie, hemos discutido las diferentes funciones y aspectos de rendimiento de HTTP/3 y especialmente QUIC. Hemos visto que, si bien la mayoría de estas funciones parecen muy impactantes, en la práctica es posible que no hagan mucho por el usuario promedio en el caso de uso de la carga de páginas web que hemos estado considerando.
Por ejemplo, hemos visto que el uso de UDP por parte de QUIC no significa que de repente pueda usar más ancho de banda que TCP, ni que pueda descargar sus recursos más rápidamente. La característica 0-RTT, a menudo elogiada, es realmente una microoptimización que le ahorra un viaje de ida y vuelta, en el que puede enviar alrededor de 5 KB (en el peor de los casos).
La eliminación de bloqueo de HoL no funciona bien si hay una pérdida de paquetes en ráfagas o cuando está cargando recursos de bloqueo de procesamiento. La migración de la conexión depende en gran medida de la situación, y HTTP/3 no tiene ninguna característica nueva importante que pueda hacerlo más rápido que HTTP/2.
Como tal, puede esperar que le recomiende que simplemente omita HTTP/3 y QUIC. ¿Por qué molestarse, verdad? Sin embargo, ¡definitivamente no haré tal cosa! Aunque es posible que estos nuevos protocolos no ayuden mucho a los usuarios en redes rápidas (urbanas), las nuevas funciones ciertamente tienen el potencial de tener un gran impacto para los usuarios con mucha movilidad y las personas en redes lentas.
Incluso en mercados occidentales como el mío, Bélgica, donde generalmente tenemos dispositivos rápidos y acceso a redes celulares de alta velocidad, estas situaciones pueden afectar al 1 % o incluso al 10 % de su base de usuarios, dependiendo de su producto. Un ejemplo es alguien en un tren que intenta desesperadamente buscar información crítica en su sitio web, pero tiene que esperar 45 segundos para que se cargue. Ciertamente sé que he estado en esa situación, deseando que alguien hubiera implementado QUIC para sacarme de ella.
Sin embargo, hay otros países y regiones donde las cosas son mucho peores aún. Allí, el usuario promedio podría parecerse mucho más al 10 % más lento de Bélgica, y es posible que el 1 % más lento nunca llegue a ver una página cargada. En muchas partes del mundo, el rendimiento web es un problema de accesibilidad e inclusión.
Esta es la razón por la que nunca deberíamos simplemente probar nuestras páginas en nuestro propio hardware (sino también usar un servicio como Webpagetest) y también por la que definitivamente debería implementar QUIC y HTTP/3 . Especialmente si sus usuarios están a menudo en movimiento o es poco probable que tengan acceso a redes celulares rápidas, estos nuevos protocolos pueden marcar una gran diferencia, incluso si no nota mucho en su MacBook Pro con cable. Para obtener más detalles, recomiendo encarecidamente la publicación de Fastly sobre el tema.
Si eso no le convence del todo, considere que QUIC y HTTP/3 seguirán evolucionando y serán más rápidos en los próximos años. Obtener algo de experiencia temprana con los protocolos valdrá la pena en el futuro, lo que le permitirá aprovechar los beneficios de las nuevas funciones lo antes posible. Además, QUIC aplica las mejores prácticas de seguridad y privacidad en segundo plano, lo que beneficia a todos los usuarios en todas partes.
¿Finalmente convencido? Luego continúe con la parte 3 de la serie para leer sobre cómo puede usar los nuevos protocolos en la práctica.
- Parte 1: Historia de HTTP/3 y conceptos básicos
Este artículo está dirigido a personas nuevas en HTTP/3 y protocolos en general, y trata principalmente los conceptos básicos. - Parte 2: Funciones de rendimiento de HTTP/3
Este es más profundo y técnico. Las personas que ya conocen los conceptos básicos pueden comenzar aquí. - Parte 3: Opciones prácticas de implementación de HTTP/3
Este tercer artículo de la serie explica los desafíos que implica implementar y probar HTTP/3 usted mismo. También detalla cómo y si debe cambiar sus páginas web y recursos.