
¿Cómo implementar la clasificación en el aprendizaje automático?
Publicado: 2021-03-12La aplicación de Machine Learning en varios campos ha aumentado a pasos agigantados en los últimos años, y continúa haciéndolo. Una de las tareas más populares del modelo de Machine Learning es reconocer objetos y separarlos en sus clases designadas.
Este es el método de clasificación que es una de las aplicaciones más populares de Machine Learning. La clasificación se utiliza para separar una gran cantidad de datos en un conjunto de valores discretos que pueden ser binarios, como 0/1, Sí/No, o multiclase, como animales, automóviles, pájaros, etc.
En el siguiente artículo, comprenderemos el concepto de clasificación en el aprendizaje automático, los tipos de datos involucrados y veremos algunos de los algoritmos de clasificación más populares utilizados en el aprendizaje automático para clasificar varios datos.
Tabla de contenido
¿Qué es el aprendizaje supervisado?
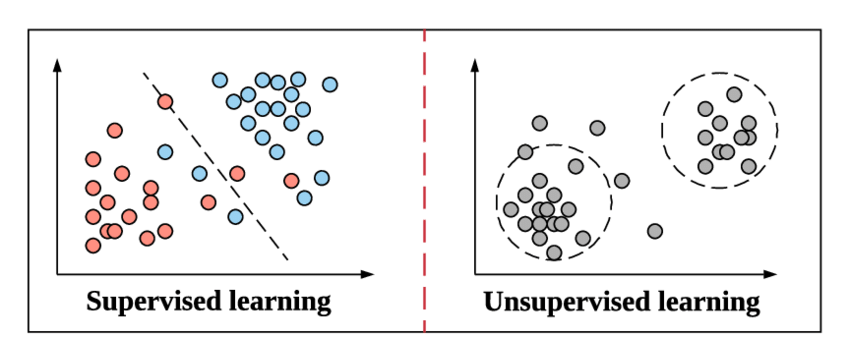
Mientras nos preparamos para sumergirnos en el concepto de clasificación y sus tipos, actualicemos rápidamente lo que significa aprendizaje supervisado y cómo se diferencia del otro método de aprendizaje no supervisado en el aprendizaje automático.
Entendamos esto tomando un ejemplo simple de nuestra clase de física en la escuela secundaria. Supongamos que hay un problema simple que involucra un nuevo método. Si se nos presenta una pregunta en la que tenemos que resolver usando el mismo método, ¿no deberíamos referirnos todos a un problema de ejemplo con el mismo método e intentar resolverlo? Una vez que estamos seguros con ese método, no necesitamos volver a consultarlo y continuar resolviéndolo.
Fuente

Esta es la misma forma en que funciona el aprendizaje supervisado en el aprendizaje automático. Se aprende con el ejemplo. Para mantenerlo aún más simple, en el aprendizaje supervisado, todos los datos se alimentan con sus etiquetas correspondientes y, por lo tanto, durante el proceso de capacitación, el modelo de aprendizaje automático compara su salida para un dato en particular con la salida real de esos mismos datos y trata de minimizar el error entre el valor de la etiqueta pronosticado y el real.
Los algoritmos de clasificación que analizaremos en este artículo siguen este método de aprendizaje supervisado, por ejemplo, detección de spam y reconocimiento de objetos.
El aprendizaje no supervisado es un paso anterior en el que los datos no se alimentan con sus etiquetas. Depende de la responsabilidad y la eficiencia del modelo de Machine Learning derivar patrones de los datos y dar el resultado. Los algoritmos de agrupamiento siguen este método de aprendizaje no supervisado.
¿Qué es la clasificación?
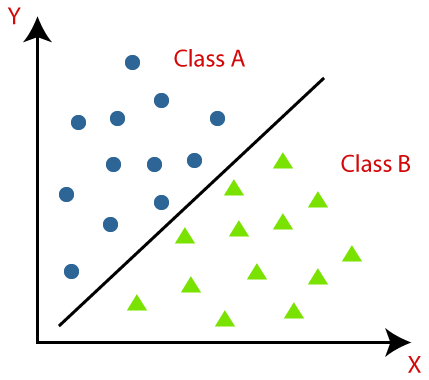
La clasificación se define como reconocer, comprender y agrupar los objetos o datos en clases preestablecidas. Al categorizar los datos antes del proceso de entrenamiento del modelo de Machine Learning, podemos usar varios algoritmos de clasificación para clasificar los datos en varias clases. A diferencia de la regresión, un problema de clasificación es cuando la variable de salida es una categoría, como "Sí" o "No" o "Enfermedad" o "Sin enfermedad".
En la mayoría de los problemas de Machine Learning, una vez que el conjunto de datos se carga en el programa, antes del entrenamiento, divida el conjunto de datos en un conjunto de entrenamiento y un conjunto de prueba con una proporción fija (generalmente 70% conjunto de entrenamiento y 30% conjunto de prueba). Este proceso de división permite que el modelo realice una retropropagación en la que intenta corregir su error del valor predicho frente al valor real mediante varias aproximaciones matemáticas.
De manera similar, antes de comenzar la Clasificación, se crea el conjunto de datos de entrenamiento. El algoritmo de clasificación se entrena en él mientras se prueba en el conjunto de datos de prueba con cada iteración, lo que se conoce como época.
Fuente
Una de las aplicaciones de algoritmos de clasificación más comunes es filtrar los correos electrónicos para determinar si son "spam" o "no spam". En resumen, podemos definir la clasificación en el aprendizaje automático como una forma de "reconocimiento de patrones" en el que estos algoritmos que se aplican a los datos de entrenamiento se utilizan para extraer varios patrones de los datos (como palabras o secuencias de números similares, sentimientos, etc. .).
La clasificación es un proceso de categorizar un conjunto dado de datos en clases; se puede realizar tanto en datos estructurados como no estructurados. Comienza prediciendo la clase de los puntos de datos dados. Estas clases también se conocen como variables de salida, etiquetas de destino, etc. Varios algoritmos tienen funciones matemáticas incorporadas para aproximar la función de mapeo de las variables de puntos de datos de entrada a la clase de destino de salida. El objetivo principal de la clasificación es identificar en qué clase/categoría caerán los nuevos datos.
Tipos de algoritmos de clasificación en aprendizaje automático
Según el tipo de datos sobre los que se aplican los algoritmos de clasificación, existen dos grandes categorías de algoritmos, los modelos lineales y no lineales.
Modelos lineales
- Regresión logística
- Máquinas de vectores de soporte (SVM)
Modelos no lineales
- Clasificación K-vecinos más cercanos (KNN)
- Núcleo SVM
- Clasificación ingenua de Bayes
- Clasificación del árbol de decisión
- Clasificación aleatoria de bosques
En este artículo, repasaremos brevemente el concepto detrás de cada uno de los algoritmos que se mencionan anteriormente.
Evaluación de un Modelo de Clasificación en Machine Learning
Antes de saltar a los conceptos de estos algoritmos mencionados anteriormente, debemos comprender cómo podemos evaluar nuestro modelo de aprendizaje automático construido sobre estos algoritmos. Es esencial evaluar la precisión de nuestro modelo tanto en el conjunto de entrenamiento como en el conjunto de prueba.
Pérdida de entropía cruzada o pérdida de registro
Este es el primer tipo de función de pérdida que usaremos para evaluar el rendimiento de un clasificador cuya salida está entre 0 y 1. Esto se usa principalmente para modelos de clasificación binaria. La fórmula de Log Loss está dada por,
Pérdida de registro = -((1 – y) * log(1 – yhat) + y * log(yhat))
Donde ese es el valor predicho, y y es el valor real.
Matriz de confusión
Una matriz de confusión es una matriz NXN, donde N es el número de clases que se predicen. La matriz de confusión nos proporciona una matriz/tabla como resultado y describe el rendimiento del modelo. Consiste en el resultado de las predicciones en forma de matriz de la que podemos derivar varias métricas de rendimiento para evaluar el modelo de Clasificación. es de la forma,
| Positivo real | Negativo real | |
| Positivo pronosticado | Verdadero Positivo | Falso positivo |
| Negativo previsto | Falso negativo | verdadero negativo |
Algunas de las métricas de rendimiento que se pueden derivar de la tabla anterior se proporcionan a continuación.
1. Precisión: la proporción del número total de predicciones correctas.
2. Valor predictivo positivo o precisión: la proporción de casos positivos que se identificaron correctamente.
3. Valor predictivo negativo: la proporción de casos negativos que se identificaron correctamente.
4. Sensibilidad o recuperación: la proporción de casos positivos reales que se identifican correctamente.
5. Especificidad: la proporción de casos negativos reales que se identifican correctamente.
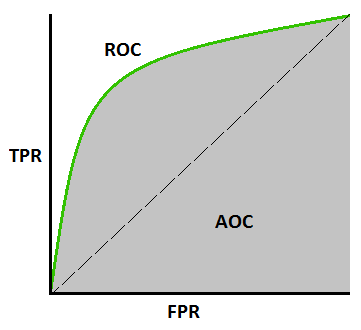
Curva AUC-ROC –
Esta es otra métrica de curva importante que evalúa cualquier modelo de Machine Learning. La curva ROC significa Curva de características operativas del receptor y AUC significa Área bajo la curva. La curva ROC se traza con TPR y FPR, donde TPR (tasa de verdaderos positivos) en el eje Y y FPR (tasa de falsos positivos) en el eje X. Muestra el rendimiento del modelo de clasificación en diferentes umbrales.
Fuente
1. Regresión logística
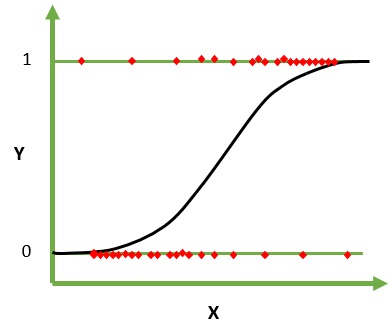
La regresión logística es un algoritmo de aprendizaje automático para la clasificación. En este algoritmo, las probabilidades que describen los posibles resultados de un solo ensayo se modelan mediante una función logística. Asume que las variables de entrada son numéricas y tienen una distribución gaussiana (curva de campana).
La función logística, también llamada función sigmoidea, fue utilizada inicialmente por los estadísticos para describir el crecimiento de la población en ecología. La función sigmoidea es una función matemática que se utiliza para representar los valores predichos en probabilidades. La regresión logística tiene una curva en forma de S y puede tomar valores entre 0 y 1 pero nunca exactamente en esos límites.

Fuente
La regresión logística se utiliza principalmente para predecir un resultado binario como Sí/No y Pasa/Falla. Las variables independientes pueden ser categóricas o numéricas, pero la variable dependiente siempre es categórica. La fórmula para la regresión logística está dada por,
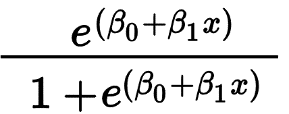
Donde e representa la curva en forma de S que tiene valores entre 0 y 1.
2. Máquinas de vectores de soporte
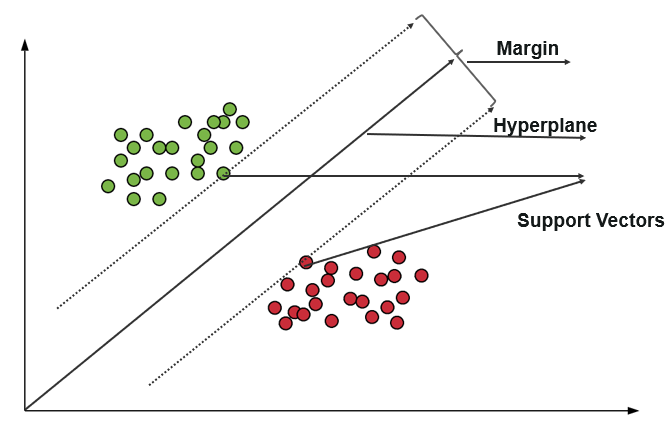
Una máquina de vectores de soporte (SVM) usa algoritmos para entrenar y clasificar datos dentro de grados de polaridad, llevándolos a un grado más allá de la predicción X/Y. En SVM, la línea que se usa para separar las clases se denomina Hiperplano. Los puntos de datos a ambos lados del hiperplano más cercanos al hiperplano se denominan vectores de soporte y se utilizan para trazar la línea de límite.
Esta máquina de vectores de soporte en clasificación representa los datos de entrenamiento como puntos de datos en un espacio en el que muchas categorías se separan en categorías de hiperplano. Cuando ingresa un nuevo punto, se clasifica prediciendo en qué categoría se encuentran y pertenecen a un espacio en particular.
Fuente
El objetivo principal de la máquina de vectores de soporte es maximizar el margen entre los dos vectores de soporte.
Únase al curso de ML en línea de las mejores universidades del mundo: maestrías, programas ejecutivos de posgrado y programa de certificado avanzado en ML e IA para acelerar su carrera.
3. Clasificación K-vecinos más cercanos (KNN)
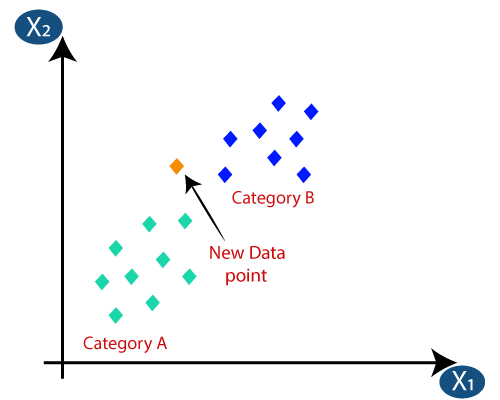
La clasificación KNN es uno de los algoritmos de clasificación más simples, pero se utiliza mucho debido a su alta eficiencia y facilidad de uso. En este método, todo el conjunto de datos se almacena inicialmente en la máquina. Luego, se elige un valor – k, que representa el número de vecinos. De esta manera, cuando se agrega un nuevo punto de datos al conjunto de datos, toma el voto mayoritario de la etiqueta de clase de los k vecinos más cercanos a ese nuevo punto de datos. Con este voto, el nuevo punto de datos se agrega a esa clase en particular con el voto más alto.
Fuente
4. Núcleo SVM
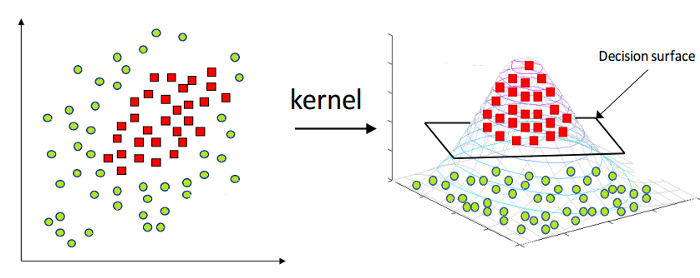
Como se mencionó anteriormente, la máquina de vectores de soporte lineal solo se puede aplicar a datos de naturaleza lineal. Sin embargo, todos los datos del mundo no son linealmente separables. Por lo tanto, necesitamos desarrollar una máquina de vectores de soporte para dar cuenta de los datos que también son separables de forma no lineal. Aquí viene el truco del Kernel, también conocido como Kernel Support Vector Machine o Kernel SVM.
En Kernel SVM, seleccionamos un kernel como el RBF o el Gaussian Kernel. Todos los puntos de datos se asignan a una dimensión superior, donde se vuelven linealmente separables. De esta manera, podemos crear un límite de decisión entre las diferentes clases del conjunto de datos.
Fuente
Por lo tanto, de esta manera, utilizando los conceptos básicos de Support Vector Machines, podemos diseñar un Kernel SVM para no lineal.
5. Clasificación Naive Bayes
La Clasificación Naive Bayes tiene sus raíces pertenecientes al Teorema de Bayes, asumiendo que todas las variables independientes (características) del conjunto de datos son independientes. Tienen la misma importancia en la predicción del resultado. Esta suposición del Teorema de Bayes le da el nombre de 'Ingenuo'. Se utiliza para diversas tareas, como el filtrado de spam y otras áreas de clasificación de texto. Naive Bayes calcula la posibilidad de que un punto de datos pertenezca o no a una determinada categoría.
La fórmula de la Clasificación Naive Bayes está dada por,
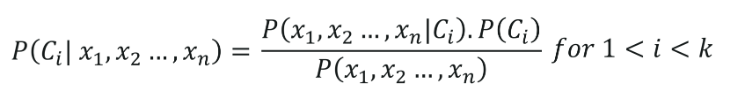
6. Clasificación del árbol de decisión
Un árbol de decisión es un algoritmo de aprendizaje supervisado que es perfecto para problemas de clasificación, ya que puede ordenar clases en un nivel preciso. Opera en forma de diagrama de flujo donde separa los puntos de datos en cada nivel. La estructura final parece un árbol con nudos y hojas.

Fuente
Un nodo de decisión tendrá dos o más ramas, y una hoja representa una clasificación o decisión. En el ejemplo anterior de un árbol de decisiones, al hacer varias preguntas, se crea un diagrama de flujo que nos ayuda a resolver el problema simple de predecir si ir al mercado o no.
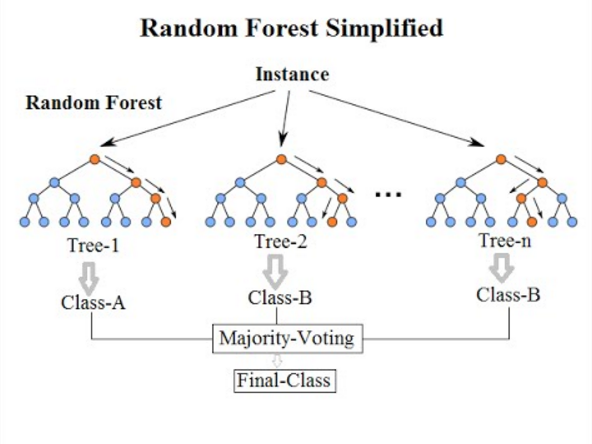
7. Clasificación aleatoria de bosques
Llegando al último algoritmo de clasificación de esta lista, The Random Forest es solo una extensión del algoritmo del árbol de decisión. Un bosque aleatorio es un método de aprendizaje conjunto con múltiples árboles de decisión. Funciona de la misma manera que los árboles de decisión.
Fuente
El Algoritmo de Bosque Aleatorio es un avance del Algoritmo de Árbol de Decisión existente, que adolece de un problema importante de " sobreajuste ". También se considera más rápido y preciso en comparación con el algoritmo del árbol de decisiones.
Lea también: Ideas y temas de proyectos de aprendizaje automático
Conclusión
Así, en este artículo sobre Métodos de Aprendizaje Automático para Clasificación, hemos entendido los conceptos básicos de Clasificación y Aprendizaje Supervisado, Tipos y Métricas de Evaluación de modelos de Clasificación y, por último, un resumen de todos los modelos de Clasificación de Aprendizaje Automático más utilizados.
Si está interesado en obtener más información sobre el aprendizaje automático, consulte el Programa PG Ejecutivo en Aprendizaje Automático e IA de IIIT-B y upGrad, que está diseñado para profesionales que trabajan y ofrece más de 450 horas de capacitación rigurosa, más de 30 estudios de casos y asignaciones, IIIT -Estado de exalumno B, más de 5 proyectos prácticos finales prácticos y asistencia laboral con las mejores empresas.
Q1. ¿Qué algoritmos son los más utilizados en el aprendizaje automático?
El aprendizaje automático emplea muchos algoritmos diferentes, que se pueden clasificar en términos generales en tres tipos principales: algoritmos de aprendizaje supervisado, algoritmos de aprendizaje no supervisado y algoritmos de aprendizaje por refuerzo. Ahora, para acotar y nombrar algunos de los algoritmos más utilizados, los que deben mencionarse son la regresión lineal, la regresión logística, SVM, árboles de decisión, algoritmo de bosque aleatorio, kNN, teoría Naive Bayes, K-Means, reducción de dimensionalidad, y algoritmos de aumento de gradiente. Los algoritmos XGBoost, GBM, LightGBM y CatBoost merecen una mención especial en los algoritmos de aumento de gradiente. Estos algoritmos se pueden aplicar para resolver casi cualquier tipo de problema de datos.
Q2. ¿Qué es la clasificación y la regresión en el aprendizaje automático?
Tanto los algoritmos de clasificación como los de regresión se utilizan ampliamente en el aprendizaje automático. Sin embargo, existen muchas diferencias entre ellos, que en definitiva determinan su uso o finalidad. La principal diferencia es que mientras que los algoritmos de clasificación se usan para clasificar o predecir valores discretos como hombre-mujer o verdadero-falso, los algoritmos de regresión se usan para pronosticar valores continuos no discretos como salario, edad, precio, etc. Árboles de decisión, Random Forest, Kernel SVM y la regresión logística son algunos de los algoritmos de clasificación más comunes, mientras que la regresión lineal simple y múltiple, la regresión de vectores de soporte, la regresión polinomial y la regresión de árboles de decisión son algunos de los algoritmos de regresión más populares utilizados en el aprendizaje automático.
Q3. ¿Cuáles son los requisitos previos para aprender el aprendizaje automático?
Para comenzar con el aprendizaje automático, no necesita ser un matemático competente o un programador experto. Sin embargo, dada la inmensidad del campo, puede resultar intimidante cuando está a punto de comenzar su viaje de aprendizaje automático. En tales casos, conocer los requisitos previos puede ayudarlo a comenzar sin problemas. Los requisitos previos son esencialmente las habilidades básicas que necesita adquirir para comprender los conceptos de aprendizaje automático. Entonces, ante todo, asegúrese de aprender a codificar usando Python. Luego, una comprensión básica de estadística y matemáticas, especialmente álgebra lineal y cálculo multivariable, será una ventaja adicional.