
Cómo elegir un método de selección de funciones para el aprendizaje automático
Publicado: 2021-06-22Tabla de contenido
Selección de características Introducción
Un modelo de aprendizaje automático utiliza muchas funciones, de las cuales solo algunas son importantes. Hay una precisión reducida del modelo si se utilizan funciones innecesarias para entrenar un modelo de datos. Además, hay un aumento en la complejidad del modelo y una disminución en la capacidad de generalización que da como resultado un modelo sesgado. El dicho "a veces menos es mejor" va bien con el concepto de aprendizaje automático. Muchos usuarios se han enfrentado al problema en el que les resulta difícil identificar el conjunto de características relevantes de sus datos e ignorar todos los conjuntos de características irrelevantes. Las características menos importantes se denominan porque no contribuyen a la variable de destino.
Por lo tanto, uno de los procesos importantes es la selección de características en el aprendizaje automático . El objetivo es seleccionar el mejor conjunto posible de funciones para el desarrollo de un modelo de aprendizaje automático. Hay un gran impacto en el rendimiento del modelo por la selección de características. Junto con la limpieza de datos, la selección de funciones debe ser el primer paso en el diseño de un modelo.
La selección de características en Machine Learning se puede resumir como
- Selección automática o manual de aquellas características que más contribuyen a la variable de predicción o al resultado.
- La presencia de características irrelevantes podría conducir a una menor precisión del modelo, ya que aprenderá de las características irrelevantes.
Beneficios de la selección de características
- Reduce el sobreajuste de datos: una menor cantidad de datos conduce a una menor redundancia. Por lo tanto, hay menos posibilidades de tomar decisiones sobre el ruido.
- Mejora la precisión del modelo: con menos posibilidades de datos engañosos, aumenta la precisión del modelo.
- Se reduce el tiempo de entrenamiento: la eliminación de características irrelevantes reduce la complejidad del algoritmo ya que solo hay menos puntos de datos presentes. Por lo tanto, los algoritmos se entrenan más rápido.
- La complejidad del modelo se reduce con una mejor interpretación de los datos.
Métodos supervisados y no supervisados de selección de funciones
El principal objetivo de los algoritmos de selección de características es seleccionar un conjunto de las mejores características para el desarrollo del modelo. Los métodos de selección de características en el aprendizaje automático se pueden clasificar en métodos supervisados y no supervisados.
- Método supervisado: el método supervisado se utiliza para la selección de características a partir de datos etiquetados y también para la clasificación de las características relevantes. Por lo tanto, hay una mayor eficiencia de los modelos que se construyen.
- Método no supervisado : este método de selección de características se utiliza para los datos no etiquetados.
Lista de métodos bajo métodos supervisados
Los métodos supervisados de selección de características en el aprendizaje automático se pueden clasificar en

1. Métodos de envoltura
Este tipo de algoritmo de selección de funciones evalúa el proceso de rendimiento de las funciones en función de los resultados del algoritmo. También conocido como el algoritmo codicioso, entrena el algoritmo utilizando un subconjunto de funciones de forma iterativa. Los criterios de detención generalmente los define la persona que entrena el algoritmo. La adición y eliminación de funciones en el modelo se lleva a cabo en función del entrenamiento previo del modelo. En esta estrategia de búsqueda se puede aplicar cualquier tipo de algoritmo de aprendizaje. Los modelos son más precisos en comparación con los métodos de filtrado.
Las técnicas utilizadas en los métodos Wrapper son:
- Selección hacia adelante: el proceso de selección hacia adelante es un proceso iterativo en el que se agregan nuevas características que mejoran el modelo después de cada iteración. Comienza con un conjunto vacío de características. La iteración continúa y se detiene hasta que se agrega una característica que no mejora más el rendimiento del modelo.
- Selección/eliminación hacia atrás: el proceso es un proceso iterativo que comienza con todas las funciones. Después de cada iteración, las características con menor importancia se eliminan del conjunto de características iniciales. El criterio de detención de la iteración es cuando el rendimiento del modelo no mejora más con la eliminación de la característica. Estos algoritmos se implementan en el paquete mlxtend.
- Eliminación bidireccional : ambos métodos de selección hacia adelante y la técnica de eliminación hacia atrás se aplican simultáneamente en el método de eliminación bidireccional para llegar a una solución única.
- Selección exhaustiva de funciones: también se conoce como enfoque de fuerza bruta para la evaluación de subconjuntos de funciones. Se crea un conjunto de posibles subconjuntos y se construye un algoritmo de aprendizaje para cada subconjunto. Se elige aquel subconjunto cuyo modelo ofrece el mejor rendimiento.
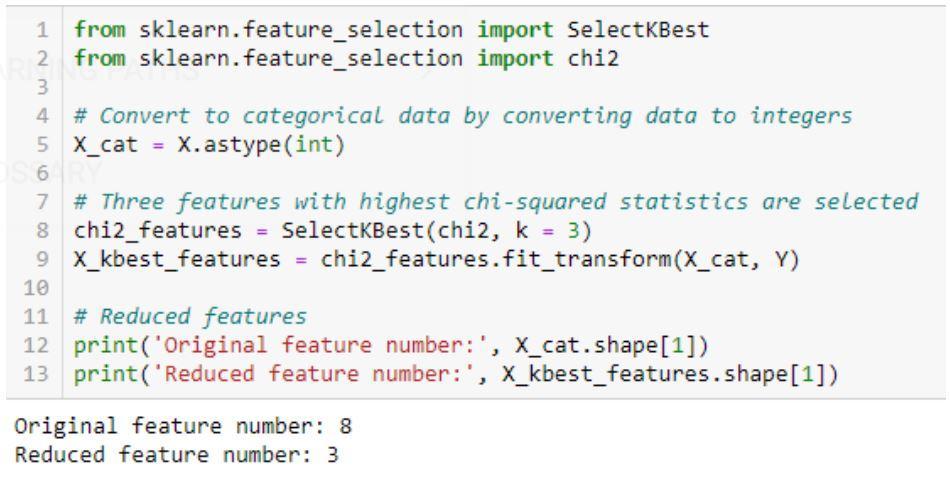
- Eliminación recursiva de características (RFE): el método se denomina codicioso ya que selecciona características al considerar recursivamente el conjunto de características cada vez más pequeño. Se utiliza un conjunto inicial de características para entrenar al estimador y su importancia se obtiene usando atributo_importancia_característica. Luego se sigue con la eliminación de las características menos importantes, dejando solo el número requerido de características. Los algoritmos se implementan en el paquete scikit-learn.
Figura 4: Un ejemplo de código que muestra la técnica recursiva de eliminación de características
2. Métodos integrados
Los métodos integrados de selección de funciones en el aprendizaje automático tienen una cierta ventaja sobre los métodos de filtro y envoltura al incluir la interacción de funciones y también mantener un costo computacional razonable. Las técnicas utilizadas en los métodos integrados son:
- Regularización: el modelo evita el sobreajuste de los datos añadiendo una penalización a los parámetros del modelo. Los coeficientes se suman con la penalización que resulta en que algunos coeficientes sean cero. Por lo tanto, aquellas características que tienen un coeficiente cero se eliminan del conjunto de características. El enfoque de selección de características utiliza Lasso (regularización L1) y redes elásticas (regularización L1 y L2).
- SMLR (Sparse Multinomial Logistic Regression): El algoritmo implementa una regularización escasa por ARD previa (determinación automática de relevancia) para la regresión logística multinacional clásica. Esta regularización estima la importancia de cada característica y poda las dimensiones que no son útiles para la predicción. La implementación del algoritmo se realiza en SMLR.
- ARD (regresión de determinación de relevancia automática): el algoritmo desplazará los pesos de los coeficientes hacia cero y se basa en una regresión de cresta bayesiana. El algoritmo se puede implementar en scikit-learn.
- Importancia aleatoria del bosque: este algoritmo de selección de características es una agregación de un número específico de árboles. Las estrategias basadas en árboles en este algoritmo se clasifican según el aumento de la impureza de un nodo o la disminución de la impureza (impureza de Gini). El final de los árboles consta de los nodos con la menor disminución de impurezas y el inicio de los árboles consta de los nodos con la mayor disminución de impurezas. Por lo tanto, las características importantes se pueden seleccionar mediante la poda del árbol debajo de un nodo en particular.
3. Métodos de filtrado
Los métodos se aplican durante los pasos de preprocesamiento. Los métodos son bastante rápidos y económicos y funcionan mejor en la eliminación de características duplicadas, correlacionadas y redundantes. En lugar de aplicar cualquier método de aprendizaje supervisado, la importancia de las características se evalúa en función de sus características inherentes. El costo computacional del algoritmo es menor en comparación con los métodos de envoltura de selección de características. Sin embargo, si no hay suficientes datos para derivar la correlación estadística entre las características, los resultados pueden ser peores que los métodos de envoltura. Por lo tanto, los algoritmos se utilizan sobre datos de alta dimensión, lo que conduciría a un mayor costo computacional si se aplicaran métodos de envoltura.

Las técnicas utilizadas en los métodos de filtro son :
- Ganancia de información : la ganancia de información se refiere a la cantidad de información que se obtiene de las características para identificar el valor objetivo. Luego mide la reducción en los valores de entropía. La ganancia de información de cada atributo se calcula considerando los valores objetivo para la selección de características.
- Prueba Chi-cuadrado : El método Chi-cuadrado (X 2 ) se usa generalmente para probar la relación entre dos variables categóricas. La prueba se utiliza para identificar si existe una diferencia significativa entre los valores observados de diferentes atributos del conjunto de datos y su valor esperado. Una hipótesis nula establece que no existe asociación entre dos variables.
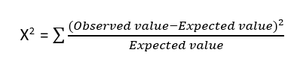
Fuente
La fórmula para la prueba de Chi-cuadrado
Implementación del algoritmo Chi-Cuadrado: sklearn, scipy
Un ejemplo de código para la prueba de Chi-cuadrado
Fuente
- CFS (selección de características basada en la correlación): el método sigue " Implementación de CFS (selección de funciones basada en correlación): scikit-feature
Únase a los cursos en línea de AI y ML de las mejores universidades del mundo: maestrías, programas ejecutivos de posgrado y programa de certificado avanzado en ML y AI para acelerar su carrera.
- FCBF (filtro rápido basado en correlación): en comparación con los métodos mencionados anteriormente de Relief y CFS, el método FCBF es más rápido y eficiente. Inicialmente, el cálculo de la Incertidumbre Simétrica se realiza para todas las características. Usando estos criterios, las funciones se ordenan y las funciones redundantes se eliminan.
Incertidumbre simétrica= la ganancia de información de x | y dividido por la suma de sus entropías. Implementación de FCBF: skfeature
- Puntuación de Fischer: la relación de Fischer (FIR) se define como la distancia entre las medias de la muestra para cada clase por característica dividida por sus varianzas. Cada característica se selecciona de forma independiente según sus puntuaciones según el criterio de Fisher. Esto conduce a un conjunto subóptimo de características. Una puntuación de Fisher más grande denota una característica mejor seleccionada.
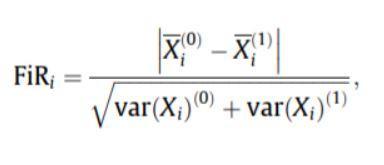
Fuente
La fórmula para la puntuación de Fischer
Implementación de la puntuación de Fisher: scikit-feature
La salida del código que muestra la técnica de puntuación de Fisher
Fuente
Coeficiente de Correlación de Pearson: Es una medida de cuantificación de la asociación entre dos variables continuas. Los valores del coeficiente de correlación oscilan entre -1 y 1, lo que define la dirección de la relación entre las variables.
- Umbral de varianza: se eliminan las características cuya varianza no alcanza el umbral específico. Las características que tienen varianza cero se eliminan mediante este método. La suposición considerada es que es probable que las características de mayor varianza contengan más información.
Figura 15: Un ejemplo de código que muestra la implementación del umbral de varianza
- Diferencia media absoluta (MAD): el método calcula la diferencia media absoluta
diferencia del valor medio.
Un ejemplo de código y su salida que muestra la implementación de la diferencia media absoluta (MAD)
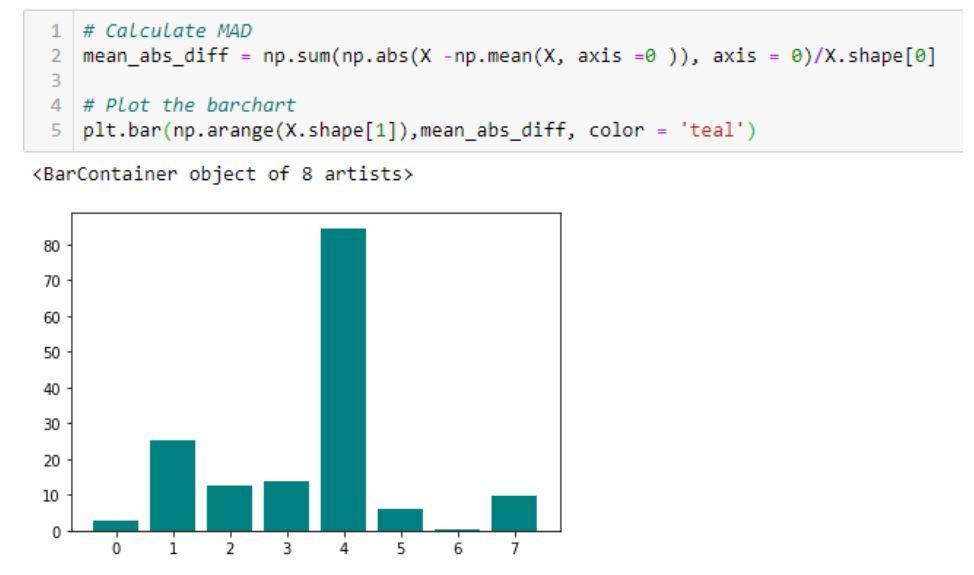
Fuente
- Relación de dispersión: la relación de dispersión se define como la relación entre la media aritmética (AM) y la media geométrica (GM) para una característica determinada. Su valor oscila entre +1 y ∞ cuando AM ≥ GM para una determinada característica.
Una relación de dispersión más alta implica un valor más alto de Ri y, por lo tanto, una característica más relevante. Por el contrario, cuando Ri está cerca de 1, indica una característica de baja relevancia.
- Dependencia Mutua: El método se utiliza para medir la dependencia mutua entre dos variables. La información obtenida de una variable puede usarse para obtener información de la otra variable.
- Puntuación laplaciana: los datos de la misma clase a menudo están cerca unos de otros. La importancia de una característica puede evaluarse por su poder de preservación de la localidad. Se calcula la puntuación laplaciana para cada característica. Los valores más pequeños determinan dimensiones importantes. Implementación de la partitura laplaciana: scikit-feature.
Conclusión
La selección de funciones en el proceso de aprendizaje automático se puede resumir como uno de los pasos importantes hacia el desarrollo de cualquier modelo de aprendizaje automático. El proceso del algoritmo de selección de características conduce a la reducción de la dimensionalidad de los datos con la eliminación de características que no son relevantes o importantes para el modelo en consideración. Las características relevantes podrían acelerar el tiempo de entrenamiento de los modelos, lo que resultaría en un alto rendimiento.
Si está interesado en obtener más información sobre el aprendizaje automático, consulte el Programa PG Ejecutivo en Aprendizaje Automático e IA de IIIT-B y upGrad, que está diseñado para profesionales que trabajan y ofrece más de 450 horas de capacitación rigurosa, más de 30 estudios de casos y asignaciones, IIIT -Estado de exalumno B, más de 5 proyectos prácticos finales prácticos y asistencia laboral con las mejores empresas.
¿En qué se diferencia el método de filtro del método de envoltura?
El método de envoltura ayuda a medir qué tan útiles son las características en función del rendimiento del clasificador. El método de filtro, por otro lado, evalúa las cualidades intrínsecas de las características utilizando estadísticas univariadas en lugar del rendimiento de validación cruzada, lo que implica que juzgan la relevancia de las características. Como resultado, el método de envoltura es más efectivo ya que optimiza el rendimiento del clasificador. Sin embargo, debido a los procesos de aprendizaje repetidos y la validación cruzada, la técnica de envoltura es computacionalmente más costosa que el método de filtro.
¿Qué es la selección directa secuencial en el aprendizaje automático?
Es una especie de selección secuencial de funciones, aunque es mucho más costosa que la selección de filtros. Es una técnica de búsqueda codiciosa que selecciona iterativamente características en función del rendimiento del clasificador para descubrir el subconjunto de características ideal. Comienza con un subconjunto de funciones vacío y continúa agregando una función en cada ronda. Esta característica se elige de un grupo de todas las características que no están en nuestro subconjunto de características, y es la que da como resultado el mejor rendimiento del clasificador cuando se combina con las demás.
¿Cuáles son las limitaciones de usar el método de filtro para la selección de características?
El enfoque de filtro es menos costoso desde el punto de vista computacional que los métodos de selección de características incrustadas y contenedor, pero tiene algunos inconvenientes. En el caso de los enfoques univariados, esta estrategia frecuentemente ignora la interdependencia de las características mientras selecciona características y evalúa cada característica de forma independiente. En comparación con los otros dos métodos de selección de funciones, esto a veces puede resultar en un rendimiento informático deficiente.