
Los 10 principales comandos de Hadoop [con usos]
Publicado: 2021-01-29En esta era, con enormes cantidades de datos, se vuelve esencial tratar con ellos. Los datos que surgen de organizaciones con clientes en crecimiento son mucho más grandes de lo que puede almacenar cualquier herramienta tradicional de administración de datos. Nos deja con la cuestión de administrar conjuntos de datos más grandes, que pueden oscilar entre gigabytes y petabytes, sin usar una sola computadora grande o una herramienta tradicional de administración de datos.
Aquí es donde el marco Apache Hadoop llama la atención. Antes de profundizar en la implementación de comandos de Hadoop, comprendamos brevemente el marco de trabajo de Hadoop y su importancia.
Tabla de contenido
¿Qué es Hadoop?
Hadoop es comúnmente utilizado por las principales organizaciones comerciales para resolver varios problemas, desde almacenar grandes GB (Gigabytes) de datos todos los días hasta operaciones informáticas en los datos.
Definido tradicionalmente como un marco de software de código abierto utilizado para almacenar datos y procesar aplicaciones, Hadoop se destaca bastante de la mayoría de las herramientas tradicionales de administración de datos. Mejora la potencia informática y amplía el límite de almacenamiento de datos al agregar algunos nodos en el marco, lo que lo hace altamente escalable. Además, sus datos y procesos de aplicaciones están protegidos contra varias fallas de hardware.
Hadoop sigue una arquitectura maestro-esclavo para distribuir y almacenar datos usando MapReduce y HDFS. Como se muestra en la figura a continuación, la arquitectura se adapta de manera definida para realizar operaciones de administración de datos utilizando cuatro nodos principales, a saber, Nombre, Datos, Maestro y Esclavo. Los componentes centrales de Hadoop se construyen directamente sobre el marco. Otros componentes se integran directamente con los segmentos.
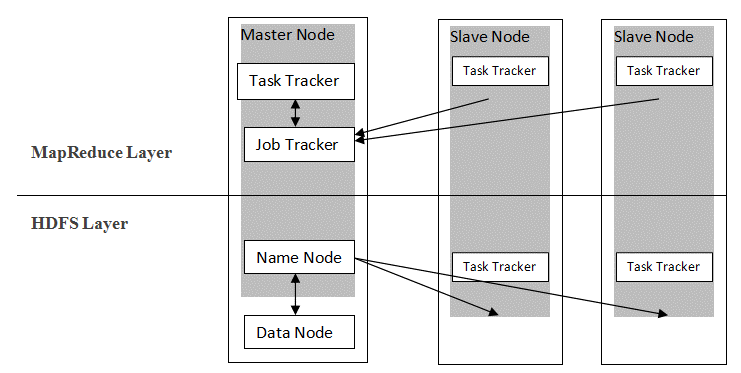 Fuente
Fuente

Comandos de Hadoop
Las características principales del marco de Hadoop muestran una naturaleza coherente y se vuelve más fácil de usar cuando se trata de administrar grandes datos con el aprendizaje de los comandos de Hadoop. A continuación, se muestran algunos comandos de Hadoop convenientes que permiten realizar varias operaciones, como la administración y el procesamiento de archivos de clústeres HDFS. Esta lista de comandos se requiere con frecuencia para lograr ciertos resultados del proceso.
1. Hadoop Touchz
hadoop fs -touchz /directorio/nombre de archivo
Este comando permite al usuario crear un nuevo archivo en el clúster HDFS. El "directorio" en el comando se refiere al nombre del directorio donde el usuario desea crear el nuevo archivo, y el "nombre de archivo" significa el nombre del nuevo archivo que se creará al completar el comando.
2. Comando de prueba de Hadoop
hadoop fs -test -[defsz] <ruta>
Este comando en particular cumple con el propósito de probar la existencia de un archivo en el clúster HDFS. Los caracteres de "[defsz]" en el comando deben modificarse según sea necesario. Aquí hay una breve descripción de estos personajes:
- d -> Comprueba si es un directorio o no
- e -> Comprueba si es un camino o no
- f -> Comprueba si es un archivo o no
- s -> Comprueba si es una ruta vacía o no
- r -> Comprueba la existencia de la ruta y el permiso de lectura
- w -> Comprueba la existencia de la ruta y el permiso de escritura
- z -> Comprueba el tamaño del archivo
3. Comando de texto de Hadoop
hadoop fs-text <src>
El comando de texto es particularmente útil para mostrar el archivo zip asignado en formato de texto. Funciona procesando archivos de origen y proporcionando su contenido en un formato de texto decodificado sin formato.

4. Comando de búsqueda de Hadoop
hadoop fs -find <ruta> … <expresión>
Este comando generalmente se usa para buscar archivos en el clúster HDFS. Escanea la expresión dada en el comando con todos los archivos en el clúster y muestra los archivos que coinciden con la expresión definida.
Leer: Principales herramientas de Hadoop
5. Comando Getmerge de Hadoop
hadoop fs -getmerge <src> <localdest>
El comando Getmerge permite fusionar uno o varios archivos en un directorio designado en el clúster del sistema de archivos HDFS. Acumula los archivos en un solo archivo ubicado en el sistema de archivos local. El "src" y "localdest" representan el significado de origen-destino y destino local.
6. Comando de conteo de Hadoop
hadoop fs -count [opciones] <ruta>
Tan obvio como su nombre, el comando de cuenta de Hadoop cuenta la cantidad de archivos y bytes en un directorio determinado. Hay varias opciones disponibles que modifican la salida según el requisito. Estos son los siguientes:
- q -> cuota muestra el límite en el número total de nombres y el uso del espacio
- u -> muestra solo la cuota y el uso
- h -> da el tamaño de un archivo
- v -> muestra el encabezado
7. Comando AppendToFile de Hadoop
hadoop fs -appendToFile <localsrc> <destino>
Permite al usuario agregar el contenido de uno o varios archivos en un solo archivo en el archivo de destino especificado en el clúster del sistema de archivos HDFS. Al ejecutar este comando, los archivos de origen dados se agregan al origen de destino según el nombre de archivo dado en el comando.
8. Comando Hadoop ls
hadoop fs -ls /ruta
El comando ls en Hadoop muestra la lista de archivos/contenidos en un directorio específico, es decir, la ruta. Al agregar "R" antes de /ruta, la salida mostrará detalles del contenido, como nombres, tamaño, propietario, etc. para cada archivo especificado en el directorio dado.
9. Comando mkdir de Hadoop
hadoop fs -mkdir /ruta/nombre_directorio
La característica única de este comando es la creación de un directorio en el clúster del sistema de archivos HDFS si el directorio no existe. Además, si el directorio especificado está presente, el mensaje de salida mostrará un error que indica la existencia del directorio.
10. Comando Hadoop chmod
hadoop fs -chmod [-R] <modo> <ruta>
Este comando se usa cuando es necesario cambiar los permisos para acceder a un archivo en particular. Al dar el comando chmod, se cambia el permiso del archivo especificado. Sin embargo, es importante recordar que el permiso se modificará cuando el propietario del archivo ejecute este comando.
Lea también: Tutorial de Impala Hadoop
Conclusión
Comenzando con el importante problema del almacenamiento de datos que enfrentan las principales organizaciones en el mundo actual, este artículo analiza la solución para el almacenamiento limitado de datos mediante la introducción de Hadoop y su impacto en la realización de operaciones de administración de datos mediante el uso de comandos de Hadoop. Para principiantes en Hadoop, se describe una descripción general del marco junto con sus componentes y arquitectura.

Después de leer este artículo, uno puede confiar fácilmente en su conocimiento en el aspecto del marco Hadoop y sus comandos aplicados. Certificación PG exclusiva de upGrad en Big Data: upGrad ofrece un programa de 7,5 meses específico de la industria para la certificación PG en Big Data en el que organizará, analizará e interpretará Big Data con IIIT-Bangalore.
Diseñado cuidadosamente para profesionales que trabajan, ayudará a los estudiantes a adquirir conocimientos prácticos y fomentará su entrada en roles de Big Data.
Puntos destacados del programa:
- Aprender lenguajes y herramientas relevantes
- Aprender conceptos avanzados de Programación Distribuida, Plataformas de Big Data, Base de Datos, Algoritmos y Minería Web
- Un certificado acreditado de IIIT Bangalore
- Asistencia de colocación para ser absorbido en las principales multinacionales
- Tutoría 1: 1 para seguir su progreso y ayudarlo en cada punto
- Trabajando en proyectos y asignaciones en vivo
Elegibilidad : Matemáticas/Ingeniería de software/Estadística/Antecedentes analíticos
Consulte nuestros otros cursos de ingeniería de software en upGrad.