
Introducción a GraphQL: la evolución del diseño de API (parte 2)
Publicado: 2022-03-10En la Parte 1, analizamos cómo han evolucionado las API en las últimas décadas y cómo cada una dio paso a la siguiente. También hablamos sobre algunos de los inconvenientes particulares de usar REST para el desarrollo de clientes móviles. En este artículo, quiero ver hacia dónde parece dirigirse el diseño de la API del cliente móvil, con un énfasis particular en GraphQL.
Hay, por supuesto, muchas personas, empresas y proyectos que han tratado de abordar las deficiencias de REST a lo largo de los años: HAL, Swagger/OpenAPI, OData JSON API y docenas de otros proyectos internos o más pequeños han buscado poner orden en el mundo sin especificaciones de REST. En lugar de tomar el mundo por lo que es y proponer mejoras incrementales, o tratar de ensamblar suficientes piezas dispares para convertir a REST en lo que necesito, me gustaría probar un experimento mental. Dada la comprensión de las técnicas que han funcionado y las que no han funcionado en el pasado, me gustaría aprovechar las limitaciones actuales y nuestros lenguajes inmensamente más expresivos para intentar esbozar la API que queremos. Trabajemos desde la experiencia del desarrollador hacia atrás en lugar de la implementación hacia adelante (te estoy mirando SQL).
Tráfico HTTP mínimo
Sabemos que el costo de cada solicitud de red (HTTP/1) es alto en varias medidas, desde la latencia hasta la duración de la batería. Idealmente, los clientes de nuestra nueva API necesitarán una forma de solicitar todos los datos que necesitan en el menor número posible de viajes de ida y vuelta.
Cargas útiles mínimas
También sabemos que el cliente promedio tiene recursos limitados en ancho de banda, CPU y memoria, por lo que nuestro objetivo debe ser enviar solo la información que nuestro cliente necesita. Para hacer esto, probablemente necesitaremos una forma para que el cliente solicite datos específicos.
Legible por humanos
Aprendimos de los días de SOAP que no es fácil interactuar con una API, la gente hará una mueca ante su mención. Los equipos de ingeniería quieren usar las mismas herramientas en las que hemos confiado durante años, como curl , wget y Charles y la pestaña de red de nuestros navegadores.
Herramientas ricas
Otra cosa que aprendimos de XML-RPC y SOAP es que los contratos cliente/servidor y los sistemas de tipos, en particular, son increíblemente útiles. Si es posible, cualquier nueva API tendría la ligereza de un formato como JSON o YAML con la capacidad de introspección de contratos más estructurados y con seguridad de tipos.
Preservación del Razonamiento Local
A lo largo de los años, hemos llegado a un acuerdo sobre algunos principios rectores sobre cómo organizar grandes bases de código, siendo el principal la "separación de preocupaciones". Desafortunadamente para la mayoría de los proyectos, esto tiende a fallar en forma de una capa de acceso a datos centralizada. Si es posible, las diferentes partes de una aplicación deberían tener la opción de administrar sus propias necesidades de datos junto con su otra funcionalidad.
Dado que estamos diseñando una API centrada en el cliente, comencemos con cómo sería obtener datos en una API como esta. Si sabemos que necesitamos hacer viajes de ida y vuelta mínimos y que necesitamos poder filtrar los campos que no queremos, necesitamos una forma de atravesar grandes conjuntos de datos y solicitar solo las partes que son útil para nosotros Parece que un lenguaje de consulta encajaría bien aquí.
No necesitamos hacer preguntas sobre nuestros datos de la misma manera que lo hace con una base de datos, por lo que un lenguaje imperativo como SQL parece la herramienta incorrecta. De hecho, nuestros objetivos principales son atravesar relaciones preexistentes y limitar campos que deberíamos poder hacer con algo relativamente simple y declarativo. La industria se ha decidido bastante por JSON para datos no binarios, así que comencemos con un lenguaje de consulta declarativo similar a JSON. Deberíamos poder describir los datos que necesitamos, y el servidor debería devolver JSON que contenga esos campos.

Un lenguaje de consulta declarativo cumple con el requisito de cargas útiles mínimas y tráfico HTTP mínimo, pero hay otro beneficio que nos ayudará con otro de nuestros objetivos de diseño. Muchos lenguajes declarativos, de consulta y otros, se pueden manipular de manera eficiente como si fueran datos. Si diseñamos con cuidado, nuestro lenguaje de consulta permitirá a los desarrolladores separar grandes solicitudes y recombinarlas de cualquier manera que tenga sentido para su proyecto. El uso de un lenguaje de consulta como este nos ayudaría a avanzar hacia nuestro objetivo final de Preservación del Razonamiento Local.
Hay muchas cosas emocionantes que puede hacer una vez que sus consultas se convierten en "datos". Por ejemplo, podría interceptar todas las solicitudes y procesarlas por lotes de manera similar a como un DOM virtual procesa por lotes las actualizaciones de DOM, también podría usar un compilador para extraer las consultas pequeñas en el momento de la compilación para almacenar previamente en caché los datos o podría crear un sistema de caché sofisticado. como Apolo caché.
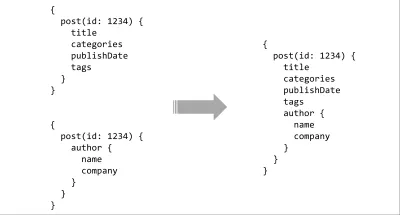
El elemento final en la lista de deseos de la API son las herramientas. Ya obtenemos algo de esto usando un lenguaje de consulta, pero el verdadero poder viene cuando lo combinas con un sistema de tipos. Con un esquema mecanografiado simple en el servidor, hay posibilidades casi infinitas para herramientas ricas. Las consultas se pueden analizar estáticamente y validar contra el contrato, las integraciones de IDE pueden proporcionar sugerencias o autocompletar, los compiladores pueden realizar optimizaciones de tiempo de compilación para las consultas, o se pueden unir varios esquemas para formar una superficie de API contigua.

Diseñar una API que combine un lenguaje de consulta y un sistema de tipos puede parecer una propuesta espectacular, pero la gente ha estado experimentando con esto, de diversas formas, durante años. XML-RPC impulsó las respuestas escritas a mediados de los 90 y su sucesor, SOAP, dominó durante años. Más recientemente, hay cosas como la abstracción MongoDB de Meteor, Horizon de RethinkDB (RIP), el increíble Falcor de Netflix que han estado usando para Netflix.com durante años y, por último, está GraphQL de Facebook. Para el resto de este ensayo, me centraré en GraphQL ya que, mientras que otros proyectos como Falcor están haciendo cosas similares, la mentalidad de la comunidad parece favorecerlo abrumadoramente.
¿Qué es GraphQL?
Primero, tengo que decir que mentí un poco. La API que construimos arriba fue GraphQL. GraphQL es solo un sistema de tipos para sus datos, un lenguaje de consulta para recorrerlos; el resto son solo detalles. En GraphQL, describe sus datos como un gráfico de interconexiones y su cliente solicita específicamente el subconjunto de datos que necesita. Se habla y se escribe mucho sobre todas las cosas increíbles que permite GraphQL, pero los conceptos básicos son muy manejables y sencillos.
Para hacer estos conceptos más concretos y ayudar a ilustrar cómo GraphQL intenta abordar algunos de los problemas de la Parte 1, el resto de esta publicación creará una API de GraphQL que puede impulsar el blog en la Parte 1 de esta serie. Antes de saltar al código, hay algunas cosas sobre GraphQL a tener en cuenta.
GraphQL es una especificación (no una implementación)
GraphQL es solo una especificación. Define un sistema de tipos junto con un lenguaje de consulta simple, y eso es todo. Lo primero que se desprende de esto es que GraphQL no está vinculado de ninguna manera a un idioma en particular. Hay más de dos docenas de implementaciones en todo, desde Haskell hasta C++, de las cuales JavaScript es solo una. Poco después de que se anunciara la especificación, Facebook lanzó una implementación de referencia en JavaScript pero, dado que no la usan internamente, las implementaciones en lenguajes como Go y Clojure pueden ser incluso mejores o más rápidas.
La especificación de GraphQL no menciona clientes ni datos
Si lees las especificaciones, notarás que dos cosas brillan por su ausencia. En primer lugar, más allá del lenguaje de consulta, no se mencionan las integraciones de clientes. Herramientas como Apollo, Relay, Loka y similares son posibles gracias al diseño de GraphQL, pero de ninguna manera son parte de él ni son necesarias para su uso. En segundo lugar, no se menciona ninguna capa de datos en particular. El mismo servidor GraphQL puede, y con frecuencia lo hace, obtener datos de un conjunto heterogéneo de fuentes. Puede solicitar datos almacenados en caché de Redis, realizar una búsqueda de direcciones desde la API de USPS y llamar a microservicios basados en protobuff y el cliente nunca notará la diferencia.
Divulgación progresiva de la complejidad
GraphQL, para muchas personas, ha llegado a una rara intersección de poder y simplicidad. Hace un trabajo fantástico al hacer que las cosas simples sean simples y las difíciles posibles. Hacer que un servidor se ejecute y proporcione datos escritos a través de HTTP puede ser solo unas pocas líneas de código en casi cualquier idioma que pueda imaginar.
Por ejemplo, un servidor GraphQL puede empaquetar una API REST existente y sus clientes pueden obtener datos con solicitudes GET regulares tal como lo haría con otros servicios. Puedes ver una demostración aquí. O, si el proyecto necesita un conjunto de herramientas más sofisticado, es posible usar GraphQL para hacer cosas como autenticación de nivel de campo, suscripciones de publicación/suscripción o consultas precompiladas/almacenadas en caché.
Una aplicación de ejemplo
El objetivo de este ejemplo es demostrar el poder y la simplicidad de GraphQL en ~70 líneas de JavaScript, no escribir un extenso tutorial. No entraré en demasiados detalles sobre la sintaxis y la semántica, pero todo el código aquí se puede ejecutar y hay un enlace a una versión descargable del proyecto al final del artículo. Si después de pasar por esto, desea profundizar un poco más, tengo una colección de recursos en mi blog que lo ayudarán a crear servicios más grandes y sólidos.
Para la demostración, usaré JavaScript, pero los pasos son muy similares en cualquier idioma. Comencemos con algunos datos de muestra utilizando el increíble Mocky.io.
Autores
{ 9: { id: 9, name: "Eric Baer", company: "Formidable" }, ... }Publicaciones
[ { id: 17, author: "author/7", categories: [ "software engineering" ], publishdate: "2016/03/27 14:00", summary: "...", tags: [ "http/2", "interlock" ], title: "http/2 server push" }, ... ] El primer paso es crear un nuevo proyecto con express y el middleware express-graphql .

bash npm init -y && npm install --save graphql express express-graphql Y para crear un archivo index.js con un servidor express.
const app = require("express")(); const PORT = 5000; app.listen(PORT, () => { console.log(`Server running at https://localhost:${PORT}`); }); Para comenzar a trabajar con GraphQL, podemos comenzar modelando los datos en la API REST. En un nuevo archivo llamado schema.js agregue lo siguiente:
const { GraphQLInt, GraphQLList, GraphQLObjectType, GraphQLSchema, GraphQLString } = require("graphql"); const Author = new GraphQLObjectType({ name: "Author", fields: { id: { type: GraphQLInt }, name: { type: GraphQLString }, company: { type: GraphQLString }, } }); const Post = new GraphQLObjectType({ name: "Post", fields: { id: { type: GraphQLInt }, author: { type: Author }, categories: { type: new GraphQLList(GraphQLString) }, publishDate: { type: GraphQLString }, summary: { type: GraphQLString }, tags: { type: new GraphQLList(GraphQLString) }, title: { type: GraphQLString } } }); const Blog = new GraphQLObjectType({ name: "Blog", fields: { posts: { type: new GraphQLList(Post) } } }); module.exports = new GraphQLSchema({ query: Blog }); El código anterior asigna los tipos en las respuestas JSON de nuestra API a los tipos de GraphQL. Un GraphQLObjectType corresponde a un Object de JavaScript, un GraphQLString corresponde a una String de JavaScript y así sucesivamente. El único tipo especial al que hay que prestar atención es el GraphQLSchema en las últimas líneas. El GraphQLSchema es la exportación de nivel raíz de un GraphQL: el punto de partida para que las consultas atraviesen el gráfico. En este ejemplo básico, solo estamos definiendo la query ; aquí es donde definiría mutaciones (escrituras) y suscripciones.
A continuación, agregaremos el esquema a nuestro servidor express en el archivo index.js . Para hacer esto, agregaremos el middleware express-graphql y le pasaremos el esquema.
const graphqlHttp = require("express-graphql"); const schema = require("./schema.js"); const app = require("express")(); const PORT = 5000; app.use(graphqlHttp({ schema, // Pretty Print the JSON response pretty: true, // Enable the GraphiQL dev tool graphiql: true })); app.listen(PORT, () => { console.log(`Server running at https://localhost:${PORT}`); }); En este punto, aunque no devolvemos ningún dato, tenemos un servidor GraphQL en funcionamiento que proporciona su esquema a los clientes. Para facilitar el inicio de la aplicación, también agregaremos un script de inicio al package.json .
"scripts": { "start": "nodemon index.js" }, Ejecutar el proyecto e ir a https://localhost:5000/ debería mostrar un explorador de datos llamado GraphiQL. GraphiQL se cargará de forma predeterminada siempre que el encabezado de Accept HTTP no esté configurado en application/json . Llamar a esta misma URL con fetch o cURL usando application/json devolverá un resultado JSON. Siéntase libre de jugar con la documentación integrada y escribir una consulta.

Lo único que queda por hacer para completar el servidor es conectar los datos subyacentes al esquema. Para hacer esto, necesitamos definir funciones de resolve . En GraphQL, una consulta se ejecuta de arriba hacia abajo llamando a una función de resolve a medida que atraviesa el árbol. Por ejemplo, para la siguiente consulta:
query homepage { posts { title } } GraphQL llamará primero a posts.resolve(parentData) y luego posts.title.resolve(parentData) . Comencemos definiendo el resolver en nuestra lista de publicaciones de blog.
const Blog = new GraphQLObjectType({ name: "Blog", fields: { posts: { type: new GraphQLList(Post), resolve: () => { return fetch('https://www.mocky.io/v2/594a3ac810000053021aa3a7') .then((response) => response.json()) } } } }); Estoy usando el paquete isomorphic-fetch aquí para hacer una solicitud HTTP, ya que demuestra muy bien cómo devolver una Promesa desde un resolutor, pero puede usar lo que quiera. Esta función devolverá una matriz de Publicaciones al tipo Blog. La función de resolución predeterminada para la implementación de JavaScript de GraphQL es parentData.<fieldName> . Por ejemplo, la resolución predeterminada para el campo Nombre del autor sería:
rawAuthorObject => rawAuthorObject.nameEsta resolución de anulación única debe proporcionar los datos para todo el objeto de publicación. Todavía tenemos que definir el resolver para Autor, pero si ejecuta una consulta para obtener los datos necesarios para la página de inicio, debería verlo funcionando.
Dado que el atributo de autor en nuestra API de publicaciones es solo la ID del autor, cuando GraphQL busca un objeto que define el nombre y la empresa y encuentra una cadena, simplemente devolverá null . Para conectar el autor, necesitamos cambiar nuestro esquema de publicación para que se vea como el siguiente:
const Post = new GraphQLObjectType({ name: "Post", fields: { id: { type: GraphQLInt }, author: { type: Author, resolve: (subTree) => { // Get the AuthorId from the post data const authorId = subTree.author.split("/")[1]; return fetch('https://www.mocky.io/v2/594a3bd21000006d021aa3ac') .then((response) => response.json()) .then(authors => authors[authorId]); } }, ... } });Ahora, tenemos un servidor GraphQL completamente funcional que envuelve una API REST. El código fuente completo puede descargarse desde este enlace de Github o ejecutarse desde esta plataforma de lanzamiento de GraphQL.
Es posible que se esté preguntando acerca de las herramientas que necesitará usar para consumir un punto final de GraphQL como este. Hay muchas opciones como Relay y Apollo, pero para empezar, creo que el enfoque simple es el mejor. Si jugó mucho con GraphiQL, es posible que haya notado que tiene una URL larga. Esta URL es solo una versión codificada de URI de su consulta. Para crear una consulta GraphQL en JavaScript, puede hacer algo como esto:
const homepageQuery = ` posts { title author { name } } `; const uriEncodedQuery = encodeURIComponent(homepageQuery); fetch(`https://localhost:5000/?query=${uriEncodedQuery}`);O, si lo desea, puede copiar y pegar la URL directamente desde GraphiQL de esta manera:
https://localhost:5000/?query=query%20homepage%20%7B%0A%20%20posts%20%7B%0A%20%20%20%20title%0A%20%20%20%20author%20%7B%0A%20%20%20%20%20%20name%0A%20%20%20%20%7D%0A%20%20%7D%0A%7D&operationName=homepageDado que tenemos un punto final de GraphQL y una forma de usarlo, podemos compararlo con nuestra API RESTish. El código que necesitábamos escribir para obtener nuestros datos usando una API RESTish se veía así:
Usando una API RESTish
const getPosts = () => fetch(`${API_ROOT}/posts`); const getPost = postId => fetch(`${API_ROOT}/post/${postId}`); const getAuthor = authorId => fetch(`${API_ROOT}/author/${postId}`); const getPostWithAuthor = post => { return getAuthor(post.author) .then(author => { return Object.assign({}, post, { author }) }) }; const getHomePageData = () => { return getPosts() .then(posts => { const postDetails = posts.map(getPostWithAuthor); return Promise.all(postDetails); }) };Usando una API de GraphQL
const homepageQuery = ` posts { title author { name } } `; const uriEncodedQuery = encodeURIComponent(homepageQuery); fetch(`https://localhost:5000/?query=${uriEncodedQuery}`);En resumen, hemos usado GraphQL para:
- Reducir nueve solicitudes (lista de publicaciones, cuatro publicaciones de blog y el autor de cada publicación).
- Reducir la cantidad de datos enviados en un porcentaje significativo.
- Utilice increíbles herramientas de desarrollo para crear nuestras consultas.
- Escriba un código mucho más limpio en nuestro cliente.
Fallas en GraphQL
Si bien creo que la exageración está justificada, no hay una bala de plata y, por muy bueno que sea GraphQL, no está exento de fallas.
Integridad de los datos
GraphQL a veces parece una herramienta diseñada específicamente para obtener buenos datos. A menudo funciona mejor como una especie de puerta de enlace, uniendo servicios dispares o tablas altamente normalizadas. Si los datos que regresan de los servicios que consume son desordenados y no están estructurados, agregar una canalización de transformación de datos debajo de GraphQL puede ser un verdadero desafío. El alcance de una función de resolución de GraphQL es solo sus propios datos y los de sus hijos. Si una tarea de orquestación necesita acceso a datos en un hermano o principal en el árbol, puede ser especialmente desafiante.
Manejo de errores complejos
Una solicitud de GraphQL puede ejecutar una cantidad arbitraria de consultas, y cada consulta puede alcanzar una cantidad arbitraria de servicios. Si falla alguna parte de la solicitud, en lugar de fallar toda la solicitud, GraphQL, de forma predeterminada, devuelve datos parciales. Es probable que los datos parciales sean técnicamente la opción correcta, y pueden ser increíblemente útiles y eficientes. El inconveniente es que el manejo de errores ya no es tan simple como verificar el código de estado HTTP. Este comportamiento se puede desactivar, pero la mayoría de las veces, los clientes terminan con casos de error más sofisticados.
almacenamiento en caché
Aunque a menudo es una buena idea usar consultas GraphQL estáticas, para organizaciones como Github que permiten consultas arbitrarias, el almacenamiento en caché de red con herramientas estándar como Varnish o Fastly ya no será posible.
Alto costo de CPU
Analizar, validar y verificar el tipo de una consulta es un proceso vinculado a la CPU que puede generar problemas de rendimiento en lenguajes de subproceso único como JavaScript.
Esto es solo un problema para la evaluación de consultas en tiempo de ejecución.
Pensamientos finales
Las características de GraphQL no son una revolución; algunas de ellas existen desde hace casi 30 años. Lo que hace que GraphQL sea poderoso es que el nivel de pulido, integración y facilidad de uso lo hacen más que la suma de sus partes.
Muchas de las cosas que logra GraphQL se pueden lograr, con esfuerzo y disciplina, usando REST o RPC, pero GraphQL brinda API de última generación a la enorme cantidad de proyectos que pueden no tener el tiempo, los recursos o las herramientas para hacerlo por sí mismos. También es cierto que GraphQL no es una bala de plata, pero sus fallas tienden a ser menores y bien comprendidas. Como alguien que ha creado un servidor GraphQL razonablemente complicado, puedo decir fácilmente que los beneficios superan fácilmente el costo.
Este ensayo se centra casi por completo en por qué existe GraphQL y los problemas que resuelve. Si esto ha despertado su interés en aprender más sobre su semántica y cómo usarla, lo animo a que aprenda de la manera que mejor le funcione, ya sea en blogs, youtube o simplemente leyendo la fuente (How To GraphQL es particularmente bueno).
Si disfrutaste este artículo (o si lo odiaste) y quieres darme tu opinión, encuéntrame en Twitter como @ebaerbaerbaer o LinkedIn en ericjbaer.