
Introducción a GraphQL: Por qué necesitamos un nuevo tipo de API (Parte 1)
Publicado: 2022-03-10En esta serie, quiero presentarles GraphQL. Al final, debe comprender no solo qué es, sino también sus orígenes, sus inconvenientes y los conceptos básicos de cómo trabajar con él. En este primer artículo, en lugar de saltar a la implementación, quiero repasar cómo y por qué llegamos a GraphQL (y herramientas similares) al observar las lecciones aprendidas de los últimos 60 años de desarrollo de API, desde RPC hasta ahora. Después de todo, como describió Mark Twain de manera colorida, no hay ideas nuevas.
"No existe tal cosa como una idea nueva. Es imposible. Simplemente tomamos muchas ideas viejas y las ponemos en una especie de caleidoscopio mental".
— Mark Twain en "La propia autobiografía de Mark Twain: los capítulos de The North American Review"
Pero primero, tengo que dirigirme al elefante en la habitación. Las cosas nuevas siempre son emocionantes, pero también pueden resultar agotadoras. Es posible que hayas oído hablar de GraphQL y simplemente hayas pensado: "¿Por qué...". Alternativamente, tal vez hayas pensado algo más como "¿Por qué me importa una nueva tendencia de diseño de API? DESCANSO está... bien. Estas son preguntas legítimas, así que déjame ayudarte a explicar por qué deberías prestar atención a esta.
Introducción
Los beneficios de traer nuevas herramientas a su equipo deben sopesarse frente a sus costos. Hay muchas cosas para medir. Está el tiempo que lleva aprender, el tiempo que la conversión le quita al desarrollo de características, la sobrecarga de mantener dos sistemas. Con costos tan altos, cualquier nueva tecnología tiene que ser mejor, más rápida o más productiva en gran medida. Las mejoras incrementales, aunque emocionantes, simplemente no valen la pena la inversión. Los tipos de API de los que quiero hablar, GraphQL en particular, son, en mi opinión, un gran paso adelante y ofrecen beneficios más que suficientes para justificar el costo.
En lugar de explorar primero las características, es útil ponerlas en contexto y comprender cómo llegaron a existir. Para hacer esto, voy a comenzar con un breve resumen de la historia de las API.
RPC
RPC fue, posiblemente, el primer patrón importante de API y sus orígenes se remontan a los inicios de la informática a mediados de los años 60. En ese momento, las computadoras todavía eran tan grandes y costosas que la noción de desarrollo de aplicaciones impulsadas por API, tal como lo concebimos, era principalmente teórica. Restricciones como ancho de banda/latencia, poder de cómputo, tiempo de cómputo compartido y proximidad física obligaron a los ingenieros a pensar en términos de sistemas distribuidos en lugar de servicios que exponen datos. Desde ARPANET en los años 60, hasta mediados de los 90 con cosas como CORBA y RMI de Java, la mayoría de las computadoras interactuaban entre sí usando llamadas de procedimiento remoto (RPC), que es un modelo de interacción cliente-servidor donde un cliente provoca un procedimiento (o método) para ejecutar en un servidor remoto.
Hay muchas cosas buenas sobre RPC. Su principio fundamental es permitir que un desarrollador trate el código en un entorno remoto como si estuviera en uno local, aunque mucho más lento y menos confiable, lo que crea continuidad en sistemas distintos y dispares. Como muchas cosas que surgieron de ARPANET, se adelantó a su tiempo ya que este tipo de continuidad es algo por lo que aún nos esforzamos cuando trabajamos con acciones no confiables y asincrónicas como el acceso a la base de datos y las llamadas a servicios externos.
A lo largo de las décadas, ha habido una enorme cantidad de investigación sobre cómo permitir que los desarrolladores integren un comportamiento asíncrono como este en el flujo típico de un programa; si hubiera cosas como Promises, Futures y ScheduledTasks disponibles en ese momento, es posible que nuestro panorama de API se vea diferente.
Otra gran ventaja de RPC es que, dado que no está restringido por la estructura de los datos, se pueden escribir métodos altamente especializados para clientes que soliciten y recuperen exactamente la información necesaria, lo que puede resultar en una sobrecarga de red mínima y cargas útiles más pequeñas.
Sin embargo, hay cosas que dificultan el RPC. Primero, la continuidad requiere contexto . RPC, por diseño, crea bastante acoplamiento entre los sistemas locales y remotos: pierde los límites entre su código local y remoto. Para algunos dominios, esto está bien o incluso se prefiere como en los SDK de cliente, pero para las API donde el código del cliente no se entiende bien, puede ser considerablemente menos flexible que algo más orientado a datos.
Sin embargo, más importante es el potencial de proliferación de métodos API . En teoría, un servicio RPC expone una pequeña API reflexiva que puede manejar cualquier tarea. En la práctica, una gran cantidad de puntos finales externos pueden acumularse sin mucha estructura. Se necesita una enorme cantidad de disciplina para evitar la superposición de API y la duplicación a lo largo del tiempo a medida que los miembros del equipo van y vienen y los proyectos giran.
Es cierto que con las herramientas adecuadas y los cambios en la documentación, como los que mencioné, se pueden administrar, pero en mi tiempo escribiendo software me he encontrado con unos pocos servicios disciplinados y de documentación automática, por lo que, para mí, esto es un poco complicado. cortina de humo.
JABÓN
El siguiente tipo importante de API que apareció fue SOAP, que nació a finales de los 90 en Microsoft Research. SOAP (Simple O bject A ccess P rotocol) es una especificación de protocolo ambiciosa para la comunicación basada en XML entre aplicaciones. La ambición declarada de SOAP era abordar algunos de los inconvenientes prácticos de RPC, XML-RPC en particular, mediante la creación de una base bien estructurada para servicios web complejos. En efecto, esto solo significaba agregar un sistema de tipos de comportamiento a XML. Lamentablemente, creó más impedimentos de los que resolvió, como lo demuestra el hecho de que hoy en día se escriben muy pocos puntos finales SOAP nuevos.
"SOAP es lo que la mayoría de la gente consideraría un éxito moderado".
— Caja Don
SOAP tenía algunas cosas buenas a pesar de su verbosidad insoportable y nombres terribles. Los contratos exigibles en WSDL y WADL (pronunciados "wizdle" y "waddle") entre el cliente y el servidor garantizaban resultados predecibles y seguros, y el WSDL podía usarse para generar documentación o crear integraciones con IDE y otras herramientas.
La gran revelación de SOAP con respecto a la evolución de las API fue la introducción gradual y posiblemente no intencional de llamadas más orientadas a los recursos. Los puntos finales de SOAP le permiten solicitar datos con una estructura predeterminada en lugar de pensar en los métodos necesarios para generar los datos (suponiendo que esté escrito de esta manera).
La desventaja más significativa de SOAP es que es tan detallado; es casi imposible de usar sin muchas herramientas . Necesita herramientas para escribir pruebas, herramientas para inspeccionar las respuestas de un servidor y herramientas para analizar todos los datos. Muchos sistemas antiguos todavía usan SOAP, pero el requisito de las herramientas lo hace demasiado engorroso para la mayoría de los proyectos nuevos, y la cantidad de bytes necesarios para la estructura XML lo convierte en una mala elección para servir dispositivos móviles o sistemas distribuidos conversacionales.
Para obtener más información, vale la pena leer las especificaciones de SOAP, así como la historia sorprendentemente interesante de SOAP de Don Box, uno de los miembros originales del equipo.
DESCANSO
Finalmente, hemos llegado al patrón de diseño de API du jour: REST. REST, presentado en una disertación doctoral de Roy Fielding en 2000, osciló el péndulo en una dirección completamente diferente. REST es, en muchos sentidos, la antítesis de SOAP y mirarlos uno al lado del otro te hace sentir como si su disertación fuera un poco furiosa.
SOAP usa HTTP como un transporte tonto y construye su estructura en el cuerpo de solicitud y respuesta. REST, por otro lado, elimina los contratos cliente-servidor, las herramientas, XML y los encabezados personalizados, reemplazándolos con la semántica de HTTP, ya que es una estructura que elige en su lugar usar verbos HTTP que interactúan con datos y URI que hacen referencia a un recurso en alguna jerarquía de datos.
| JABÓN | DESCANSO | |
|---|---|---|
| Verbos HTTP | OBTENER, PONER, PUBLICAR, PARCHE, ELIMINAR | |
| Formato de datos | XML | Lo que quieras |
| Contratos Cliente/Servidor | ¡Todo el día, todos los días! | Quien necesita esos |
| Sistema de tipo | JavaScript tiene corto sin firmar, ¿verdad? | |
| URL | Describir operaciones | Recursos con nombre |
REST cambia completa y explícitamente el diseño de la API desde el modelado de interacciones hasta el simple modelado de los datos de un dominio. Al estar completamente orientado a los recursos cuando trabaja con una API REST, ya no necesita saber, o preocuparse, lo que se necesita para recuperar una determinada pieza de datos; ni es necesario que sepa nada sobre la implementación de los servicios de back-end.

La simplicidad no solo fue una gran ayuda para los desarrolladores, sino que, dado que las URL representan información estable, es fácilmente almacenable en caché, su apatridia hace que sea fácil de escalar horizontalmente y, dado que modela los datos en lugar de anticipar las necesidades de los consumidores, puede reducir drásticamente el área de superficie de las API. .
REST es excelente y su ubicuidad es un éxito asombroso, pero, como todas las soluciones anteriores, REST no carece de fallas. Para hablar concretamente de algunas de sus carencias vamos a repasar un ejemplo básico. Supongamos que tenemos que construir la página de inicio de un blog que muestra una lista de publicaciones de blog y el nombre de su autor.
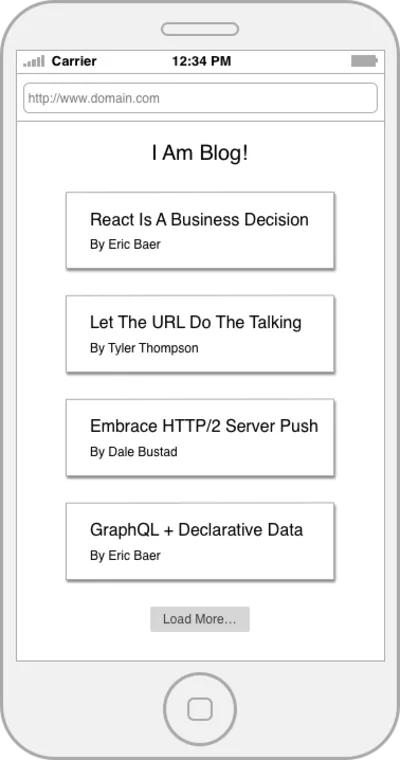
Escribamos el código que puede recuperar los datos de la página de inicio desde una API REST simple. Comenzaremos con algunas funciones que envuelven nuestros recursos.
const getPosts = () => fetch(`${API_ROOT}/posts`); const getPost = postId => fetch(`${API_ROOT}/posts/${postId}`); const getAuthor = authorId => fetch(`${API_ROOT}/authors/${authorId}`);¡Ahora, orquestemos!
const getPostWithAuthor = postId => { return getPost(postId) .then(post => getAuthor(post.author)) .then(author => { return Object.assign({}, post, { author }) }) }; const getHomePageData = () => { return getPosts() .then(postIds => { const postDetails = postIds.map(getPostWithAuthor); return Promise.all(postDetails); }) };Entonces nuestro código hará lo siguiente:
- Obtener todas las publicaciones;
- Obtén los detalles de cada publicación;
- Obtener recurso de autor para cada publicación.
Lo bueno es que esto es bastante fácil de razonar, está bien organizado y los límites conceptuales de cada recurso están bien trazados. Lo malo aquí es que acabamos de hacer ocho solicitudes de red, muchas de las cuales suceden en serie.
GET /posts GET /posts/234 GET /posts/456 GET /posts/17 GET /posts/156 GET /author/9 GET /author/4 GET /author/7 GET /author/2 Sí, podría criticar este ejemplo sugiriendo que la API podría tener un punto final paginado /posts pero eso es dividir los pelos. El hecho es que a menudo tiene una colección de llamadas API para que dependan unas de otras para representar una aplicación o página completa.
Desarrollar clientes y servidores REST es ciertamente mejor que lo que vino antes, o al menos más a prueba de idiotas, pero muchas cosas han cambiado en las dos décadas desde el artículo de Fielding. En ese momento, todas las computadoras eran de plástico beige; ahora son de aluminio! Hablando en serio, el año 2000 estuvo cerca del pico de la explosión de la informática personal. Cada año, los procesadores duplicaban su velocidad y las redes se aceleraban a un ritmo increíble. La penetración de mercado de Internet fue de alrededor del 45% y no tenía a dónde ir sino hacia arriba.
Luego, alrededor de 2008, la informática móvil se generalizó. Con los dispositivos móviles, efectivamente retrocedimos una década en términos de velocidad/rendimiento de la noche a la mañana. En 2017, tenemos casi un 80 % de penetración nacional y más del 50 % global de teléfonos inteligentes, y es el momento de repensar algunas de nuestras suposiciones sobre el diseño de API.
Debilidades de REST
La siguiente es una mirada crítica a REST desde la perspectiva de un desarrollador de aplicaciones cliente, particularmente uno que trabaja en dispositivos móviles. Las API de estilo GraphQL y GraphQL no son nuevas y no resuelven problemas que están fuera del alcance de los desarrolladores de REST. La contribución más significativa de GraphQL es su capacidad para resolver estos problemas de manera sistemática y con un nivel de integración que no está disponible en ningún otro lugar. En otras palabras, es una solución “baterías incluidas”.
Los autores principales de REST, incluido Fielding, publicaron un artículo a fines de 2017 (Reflexiones sobre el estilo arquitectónico REST y "Diseño basado en principios de la arquitectura web moderna") que reflexiona sobre dos décadas de REST y los muchos patrones que ha inspirado. Es breve y vale la pena leerlo para cualquier persona interesada en el diseño de API.
Con algo de contexto histórico y una aplicación de referencia, veamos las tres debilidades principales de REST.
REST es hablador
Los servicios REST tienden a ser al menos algo "habladores", ya que se necesitan varios viajes de ida y vuelta entre el cliente y el servidor para obtener suficientes datos para representar una aplicación. Esta cascada de solicitudes tiene un impacto devastador en el rendimiento, especialmente en dispositivos móviles. Volviendo al ejemplo del blog, incluso en el mejor de los casos con un teléfono nuevo y una red confiable con una conexión 4G, ha gastado casi 0,5 segundos solo en sobrecarga de latencia antes de que se descargue el primer byte de datos.
Latencia 4G de 55 ms * 8 solicitudes = sobrecarga de 440 ms
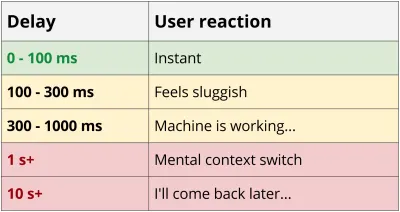
Otro problema con los servicios de chatty es que, en muchos casos, lleva menos tiempo descargar una solicitud grande que muchas pequeñas. El rendimiento reducido de las solicitudes pequeñas es cierto por muchas razones, incluido el inicio lento de TCP, la falta de compresión de encabezado y la eficiencia de gzip y, si tiene curiosidad al respecto, le recomiendo leer Redes de navegador de alto rendimiento de Ilya Grigorik. El blog de MaxCDN también tiene una excelente descripción general.
Este problema no es técnicamente con REST sino con HTTP, específicamente HTTP/1. HTTP/2 casi resuelve el problema de la conversación independientemente del estilo de la API, y tiene un amplio soporte en clientes como navegadores y SDK nativos. Desafortunadamente, la implementación ha sido lenta en el lado de la API. Entre los 10.000 sitios web principales, la adopción es de alrededor del 20 % (y sigue aumentando) a fines de 2017. Incluso Node.js, para mi sorpresa, obtuvo compatibilidad con HTTP/2 en su versión 8.x. Si tiene la capacidad, ¡actualice su infraestructura! Mientras tanto, no nos detengamos ya que esta es solo una parte de la ecuación.
Aparte de HTTP, la pieza final de por qué es importante la charla, tiene que ver con cómo funcionan los dispositivos móviles, y específicamente sus radios. En resumidas cuentas, el funcionamiento de la radio es una de las partes de un teléfono que consume más batería, por lo que el sistema operativo lo apaga en cada oportunidad. Encender la radio no solo agota la batería, sino que agrega aún más gastos generales a cada solicitud.
TMI (sobrecarga)
El siguiente problema con los servicios de estilo REST es que envían más información de la necesaria. En nuestro ejemplo de blog, todo lo que necesitamos es el título de cada publicación y el nombre del autor, que es solo alrededor del 17% de lo que se devolvió. Esa es una pérdida de 6x para una carga útil muy simple. En una API del mundo real, ese tipo de sobrecarga puede ser enorme. Los sitios de comercio electrónico, por ejemplo, a menudo representan un solo producto como miles de líneas de JSON. Al igual que el problema de la conversación, los servicios REST pueden manejar este escenario hoy en día utilizando "conjuntos de campos dispersos" para incluir o excluir condicionalmente partes de los datos. Desafortunadamente, el soporte para esto es irregular, incompleto o problemático para el almacenamiento en caché de la red.
Herramientas e introspección
Lo último de lo que carecen las API REST son los mecanismos para la introspección. Sin ningún contrato con información sobre los tipos de devolución o la estructura de un punto final, no hay forma de generar documentación, crear herramientas o interactuar con los datos de manera confiable. Es posible trabajar dentro de REST para resolver este problema en diversos grados. Los proyectos que implementan completamente OpenAPI, OData o JSON API a menudo están limpios, bien especificados y, en mayor o menor medida, bien documentados, pero backends como este son raros. Incluso Hypermedia, una fruta al alcance de la mano relativamente baja, a pesar de haber sido promocionada en charlas de conferencias durante décadas, todavía no se hace bien con frecuencia, si es que se hace.
Conclusión
Cada uno de los tipos de API tiene fallas, pero todos los patrones lo tienen. Este escrito no es un juicio del fenomenal trabajo de base que han establecido los gigantes del software, solo pretende ser una evaluación sobria de cada uno de estos patrones, aplicados en su forma "pura" desde la perspectiva de un desarrollador cliente. Espero que, en lugar de alejarse de este pensamiento, se rompa un patrón como REST o RPC, que pueda alejarse pensando en cómo cada uno hizo compensaciones y las áreas en las que una organización de ingeniería podría centrar sus esfuerzos para mejorar sus propias API .
En el próximo artículo, exploraré GraphQL y cómo pretende abordar algunos de los problemas que mencioné anteriormente. La innovación en GraphQL y herramientas similares está en su nivel de integración y no en su implementación. Por favor, si usted o su equipo no está buscando una API de "baterías incluidas", ¡considere buscar algo como la nueva especificación OpenAPI que puede ayudar a construir una base más sólida hoy!
Si disfrutaste este artículo (o si lo odiaste) y quieres darme tu opinión, encuéntrame en Twitter como @ebaerbaerbaer o LinkedIn en ericjbaer.