
Descenso de gradiente en el aprendizaje automático: ¿cómo funciona?
Publicado: 2021-01-28Tabla de contenido
Introducción
Una de las partes más cruciales de Machine Learning es la optimización de sus algoritmos. Casi todos los algoritmos en Machine Learning tienen un algoritmo de optimización en su base que actúa como el núcleo del algoritmo. Como todos sabemos, la optimización es el objetivo final de cualquier algoritmo, incluso con eventos de la vida real o cuando se trata de un producto basado en tecnología en el mercado.
Actualmente hay una gran cantidad de algoritmos de optimización que se utilizan en varias aplicaciones, como el reconocimiento facial, los automóviles autónomos, el análisis basado en el mercado, etc. De manera similar, en el aprendizaje automático, estos algoritmos de optimización juegan un papel importante. Uno de esos algoritmos de optimización ampliamente utilizados es el algoritmo de descenso de gradiente que analizaremos en este artículo.
¿Qué es el descenso de gradiente?
En Machine Learning, el algoritmo Gradient Descent es uno de los algoritmos más utilizados y, sin embargo, deja estupefactos a la mayoría de los recién llegados. Matemáticamente, Gradient Descent es un algoritmo de optimización iterativo de primer orden que se utiliza para encontrar el mínimo local de una función diferenciable. En términos simples, este algoritmo de descenso de gradiente se usa para encontrar los valores de los parámetros (o coeficientes) de una función que se usan para minimizar una función de costo lo más bajo posible. La función de costo se utiliza para cuantificar el error entre los valores predichos y los valores reales de un modelo de Machine Learning construido.
Intuición de descenso de gradiente
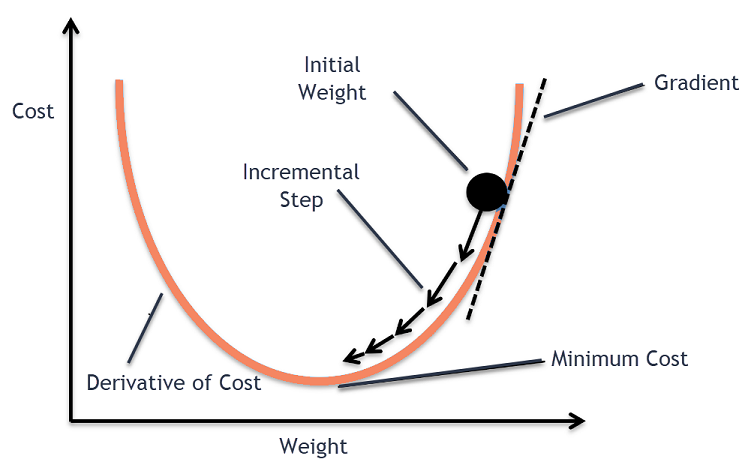
Considere un tazón grande con el que normalmente guardaría frutas o comería cereales. Este cuenco será la función de coste (f).
Ahora, una coordenada aleatoria en cualquier parte de la superficie del recipiente serán los valores actuales de los coeficientes de la función de costo. El fondo del recipiente es el mejor conjunto de coeficientes y es el mínimo de la función.
Aquí, el objetivo es calcular los diferentes valores de los coeficientes con cada iteración, evaluar el costo y elegir los coeficientes que tienen un mejor valor de función de costo (menor valor). En iteraciones múltiples, se encontraría que el fondo del recipiente tiene los mejores coeficientes para minimizar la función de costo.

De esta forma, el algoritmo de descenso de gradiente funciona para generar un costo mínimo.
Únase al curso de aprendizaje automático en línea de las mejores universidades del mundo: maestrías, programas ejecutivos de posgrado y programa de certificado avanzado en ML e IA para acelerar su carrera.
Procedimiento de descenso de gradiente
Este proceso de descenso de gradiente comienza asignando valores inicialmente a los coeficientes de la función de costo. Esto podría ser un valor cercano a 0 o un pequeño valor aleatorio.
coeficiente = 0.0
A continuación, se obtiene el coste de los coeficientes aplicándolo a la función de coste y calculando el coste.
costo = f(coeficiente)
Luego, se calcula la derivada de la función de costo. Esta derivada de la función de costo se obtiene mediante el concepto matemático de cálculo diferencial. Nos da la pendiente de la función en el punto dado donde se calcula su derivada. Esta pendiente es necesaria para saber en qué dirección se moverá el coeficiente en la próxima iteración para obtener un valor de costo más bajo. Esto se hace observando el signo de la derivada calculada.
delta = derivada (costo)
Una vez que sabemos qué dirección es cuesta abajo a partir de la derivada calculada, necesitamos actualizar los valores de los coeficientes. Para ello se utiliza un parámetro conocido como parámetro de aprendizaje, alfa (α). Esto se usa para controlar hasta qué punto los coeficientes pueden cambiar con cada actualización.
coeficiente = coeficiente – (alfa * delta)
Fuente
De esta forma, este proceso se repite hasta que el coste de los coeficientes sea igual a 0,0 o lo suficientemente cercano a cero. Este es el procedimiento para el algoritmo de descenso de gradiente.
Tipos de algoritmos de descenso de gradiente
En los tiempos modernos, existen tres tipos básicos de descenso de gradiente que se utilizan en los algoritmos modernos de aprendizaje automático y aprendizaje profundo. La principal diferencia entre cada uno de estos 3 tipos es su costo computacional y eficiencia. Según la cantidad de datos utilizados, la complejidad del tiempo y la precisión, los siguientes son los tres tipos.
- Descenso de gradiente por lotes
- Descenso de gradiente estocástico
- Descenso de gradiente de mini lotes
Descenso de gradiente por lotes
Esta es la primera y básica versión de los algoritmos de Descenso de Gradiente en la que se utiliza todo el conjunto de datos a la vez para calcular la función de costo y su gradiente. Como todo el conjunto de datos se usa de una sola vez para una sola actualización, el cálculo del gradiente en este tipo puede ser muy lento y no es posible con aquellos conjuntos de datos que están fuera de la capacidad de memoria del dispositivo.
Por lo tanto, este algoritmo de descenso de gradiente por lotes se usa solo para conjuntos de datos más pequeños y cuando la cantidad de ejemplos de entrenamiento es grande, no se prefiere el descenso de gradiente por lotes. En su lugar, se utilizan los algoritmos Stochastic y Mini Batch Gradient Descent.
Descenso de gradiente estocástico
Este es otro tipo de algoritmo de descenso de gradiente en el que solo se procesa un ejemplo de entrenamiento por iteración. En esto, el primer paso es aleatorizar todo el conjunto de datos de entrenamiento. Entonces, solo se usa un ejemplo de entrenamiento para actualizar los coeficientes. Esto contrasta con el Descenso de gradiente por lotes en el que los parámetros (coeficientes) se actualizan solo cuando se evalúan todos los ejemplos de entrenamiento.

Stochastic Gradient Descent (SGD) tiene la ventaja de que este tipo de actualización frecuente brinda una tasa de mejora detallada. Sin embargo, en ciertos casos, esto puede resultar costoso desde el punto de vista computacional, ya que procesa solo un ejemplo en cada iteración, lo que puede causar que el número de iteraciones sea muy grande.
Descenso de gradiente de mini lotes
Este es un algoritmo desarrollado recientemente que es más rápido que los algoritmos Batch y Stochastic Gradient Descent. Se prefiere principalmente ya que es una combinación de los dos algoritmos mencionados anteriormente. En esto, separa el conjunto de entrenamiento en varios mini lotes y realiza una actualización para cada uno de estos lotes después de calcular el gradiente de ese lote (como en SGD).
Comúnmente, el tamaño del lote varía entre 30 y 500 pero no hay un tamaño fijo ya que varían para diferentes aplicaciones. Por lo tanto, incluso si hay un gran conjunto de datos de entrenamiento, este algoritmo lo procesa en minilotes 'b'. Por lo tanto, es adecuado para grandes conjuntos de datos con un menor número de iteraciones.
Si 'm' es el número de ejemplos de entrenamiento, entonces si b==m, el descenso de gradiente de mini lotes será similar al algoritmo de descenso de gradiente de lotes.
Variantes de descenso de gradiente en aprendizaje automático
Con esta base para Gradient Descent, ha habido varios otros algoritmos que se han desarrollado a partir de esto. Algunos de ellos se resumen a continuación.
Descenso de gradiente de vainilla
Esta es una de las formas más simples de la Técnica de Descenso de Gradiente. El nombre vainilla significa pura o sin adulteración. En esto, se dan pequeños pasos en la dirección de los mínimos calculando el gradiente de la función de costo. Similar al algoritmo mencionado anteriormente, la regla de actualización viene dada por,
coeficiente = coeficiente – (alfa * delta)
Descenso de gradiente con impulso
En este caso, el algoritmo es tal que conocemos los pasos anteriores antes de dar el siguiente paso. Esto se hace introduciendo un nuevo término que es el producto de la actualización anterior y una constante conocida como impulso. En esto, la regla de actualización del peso está dada por,
actualización = alfa * delta
velocidad = actualización_anterior * impulso
coeficiente = coeficiente + velocidad – actualización
ADAGRAD
El término ADAGRAD significa Algoritmo de Gradiente Adaptativo. Como su nombre lo dice, utiliza una técnica adaptativa para actualizar los pesos. Este algoritmo es más adecuado para datos dispersos. Esta optimización cambia sus tasas de aprendizaje en relación con la frecuencia de las actualizaciones de parámetros durante el entrenamiento. Por ejemplo, los parámetros que tienen gradientes más altos están hechos para tener una tasa de aprendizaje más lenta para que no terminemos sobrepasando el valor mínimo. Del mismo modo, los gradientes más bajos tienen una tasa de aprendizaje más rápida para capacitarse más rápidamente.
ADÁN
Otro algoritmo de optimización adaptativa que tiene sus raíces en el algoritmo de Descenso de Gradiente es el ADAM, que significa Estimación de Momento Adaptativo. Es una combinación de los algoritmos ADAGRAD y SGD con Momentum. Está construido a partir del algoritmo ADAGRAD y está construido más abajo. En términos simples, ADAM = ADAGRAD + Momentum.
De esta manera, hay varias otras variantes de algoritmos de descenso de gradiente que se han desarrollado y se están desarrollando en el mundo, como AMSGrad, ADAMax.
Conclusión
En este artículo, hemos visto el algoritmo detrás de uno de los algoritmos de optimización más utilizados en Machine Learning, los algoritmos de descenso de gradiente junto con sus tipos y variantes que se han desarrollado.
upGrad ofrece un Programa PG Ejecutivo en Aprendizaje Automático e IA y una Maestría en Ciencias en Aprendizaje Automático e IA que pueden guiarlo hacia la construcción de una carrera. Estos cursos explicarán la necesidad de Machine Learning y los pasos adicionales para recopilar conocimientos en este dominio que cubren conceptos variados que van desde Gradient Descent en Machine Learning.
¿Dónde puede contribuir al máximo el algoritmo de descenso de gradiente?
La optimización dentro de cualquier algoritmo de aprendizaje automático es incremental a la pureza del algoritmo. El algoritmo de descenso de gradiente ayuda a minimizar los errores de la función de costo y mejora los parámetros del algoritmo. Aunque el algoritmo de descenso de gradiente se usa ampliamente en aprendizaje automático y aprendizaje profundo, su efectividad puede determinarse por la cantidad de datos, la cantidad de iteraciones y la precisión preferida, y la cantidad de tiempo disponible. Para conjuntos de datos a pequeña escala, el Descenso de gradiente por lotes es óptimo. El descenso de gradiente estocástico (SGD) demuestra ser más eficiente para conjuntos de datos detallados y más extensos. Por el contrario, Mini Batch Gradient Descent se utiliza para una optimización más rápida.
¿Cuáles son los desafíos que se enfrentan en el descenso de gradiente?
Se prefiere Gradient Descent para optimizar los modelos de aprendizaje automático para reducir la función de costos. Sin embargo, también tiene sus defectos. Supongamos que el Gradiente disminuye debido a las funciones de salida mínimas de las capas del modelo. En ese caso, las iteraciones no serán tan efectivas ya que el modelo no se volverá a entrenar por completo, actualizando sus pesos y sesgos. A veces, un gradiente de error acumula muchos pesos y sesgos para mantener las iteraciones actualizadas. Sin embargo, este gradiente se vuelve demasiado grande para manejarlo y se denomina gradiente explosivo. Los requisitos de infraestructura, el equilibrio de la tasa de aprendizaje y el impulso deben abordarse.
¿El descenso de gradiente siempre converge?
La convergencia es cuando el algoritmo de descenso de gradiente minimiza con éxito su función de costo a un nivel óptimo. El algoritmo de descenso de gradiente intenta minimizar la función de costo a través de los parámetros del algoritmo. Sin embargo, puede aterrizar en cualquiera de los puntos óptimos y no necesariamente en el que tiene un punto óptimo global o local. Una razón para no tener una convergencia óptima es el tamaño del paso. Un tamaño de paso más significativo da como resultado más oscilaciones y puede desviarse del óptimo global. Por lo tanto, es posible que el descenso de gradiente no siempre converja en la mejor característica, pero aún aterriza en el punto de característica más cercano.