
Descenso de gradiente en regresión logística [Explicado para principiantes]
Publicado: 2021-01-08En este artículo, discutiremos el muy popular Algoritmo de Descenso de Gradiente en Regresión Logística. Veremos qué es la regresión logística, luego avanzaremos gradualmente hacia la ecuación para la regresión logística, su función de costo y, finalmente, el algoritmo de descenso de gradiente.
Tabla de contenido
¿Qué es la regresión logística?
La regresión logística es simplemente un algoritmo de clasificación que se usa para predecir categorías discretas, como predecir si un correo es 'spam' o 'no spam'; predecir si un dígito dado es un '9' o 'no 9', etc. Ahora, al mirar el nombre, debe pensar, ¿por qué se llama Regresión?
La razón es que la idea de la regresión logística se desarrolló ajustando algunos elementos del algoritmo de regresión lineal básico que se usa en los problemas de regresión.
La regresión logística también se puede aplicar a problemas de clasificación de clases múltiples (más de dos clases). Aunque, se recomienda usar este algoritmo solo para problemas de clasificación binaria.
función sigmoidea
Los problemas de clasificación no son problemas de función lineal. La salida está limitada a ciertos valores discretos, por ejemplo, 0 y 1 para un problema de clasificación binaria. No tiene sentido que una función lineal prediga nuestros valores de salida como mayores que 1 o menores que 0. Por lo tanto, necesitamos una función adecuada para representar nuestros valores de salida.
La función sigmoidea resuelve nuestro problema. También conocida como función logística, es una función en forma de S que asigna cualquier número de valor real al intervalo (0,1), lo que la hace muy útil para transformar cualquier función aleatoria en una función basada en clasificación. Una función sigmoidea se ve así:

función sigmoidea
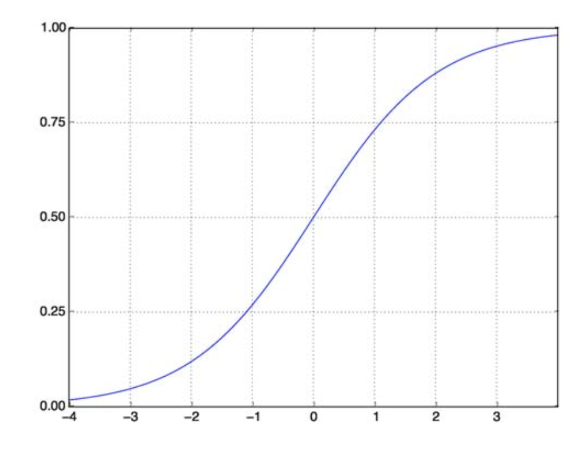
fuente
Ahora, la forma matemática de la función sigmoidea para el vector parametrizado y el vector de entrada X es:
(z) = 11+exp(-z) donde z = TX
(z) nos dará la probabilidad de que la salida sea 1. Como todos sabemos, el valor de probabilidad varía de 0 a 1. Ahora, esta no es la salida que queremos para nuestro problema de clasificación basado en discretos (solo 0 y 1). . Así que ahora podemos comparar la probabilidad predicha con 0,5. Si probabilidad > 0,5, tenemos y=1. De manera similar, si la probabilidad es < 0.5, tenemos y=0.
función de costo
Ahora que tenemos nuestras predicciones discretas, es hora de verificar si nuestras predicciones son correctas o no. Para hacer eso, tenemos una Función de Costo. La función de costo es simplemente la suma de todos los errores cometidos en las predicciones en todo el conjunto de datos. Por supuesto, no podemos usar la función de costo utilizada en la regresión lineal. Entonces, la nueva función de costo para la regresión logística es:
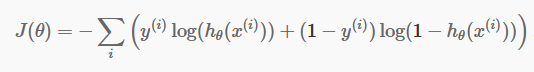 fuente
fuente
No tengas miedo de la ecuación. Es muy simple. Para cada iteración i , está calculando el error que hemos cometido en nuestra predicción y luego sumando todos los errores para definir nuestra función de costo J().
Los dos términos dentro del corchete son en realidad para los dos casos: y=0 y y=1. Cuando y=0, el primer término desaparece y nos queda solo el segundo término. De manera similar, cuando y=1, el segundo término desaparece y nos queda solo el primer término.
Algoritmo de descenso de gradiente
Hemos calculado con éxito nuestra Función de Costo. Pero necesitamos minimizar la pérdida para hacer un buen algoritmo de predicción. Para hacer eso, tenemos el Algoritmo de Descenso de Gradiente.
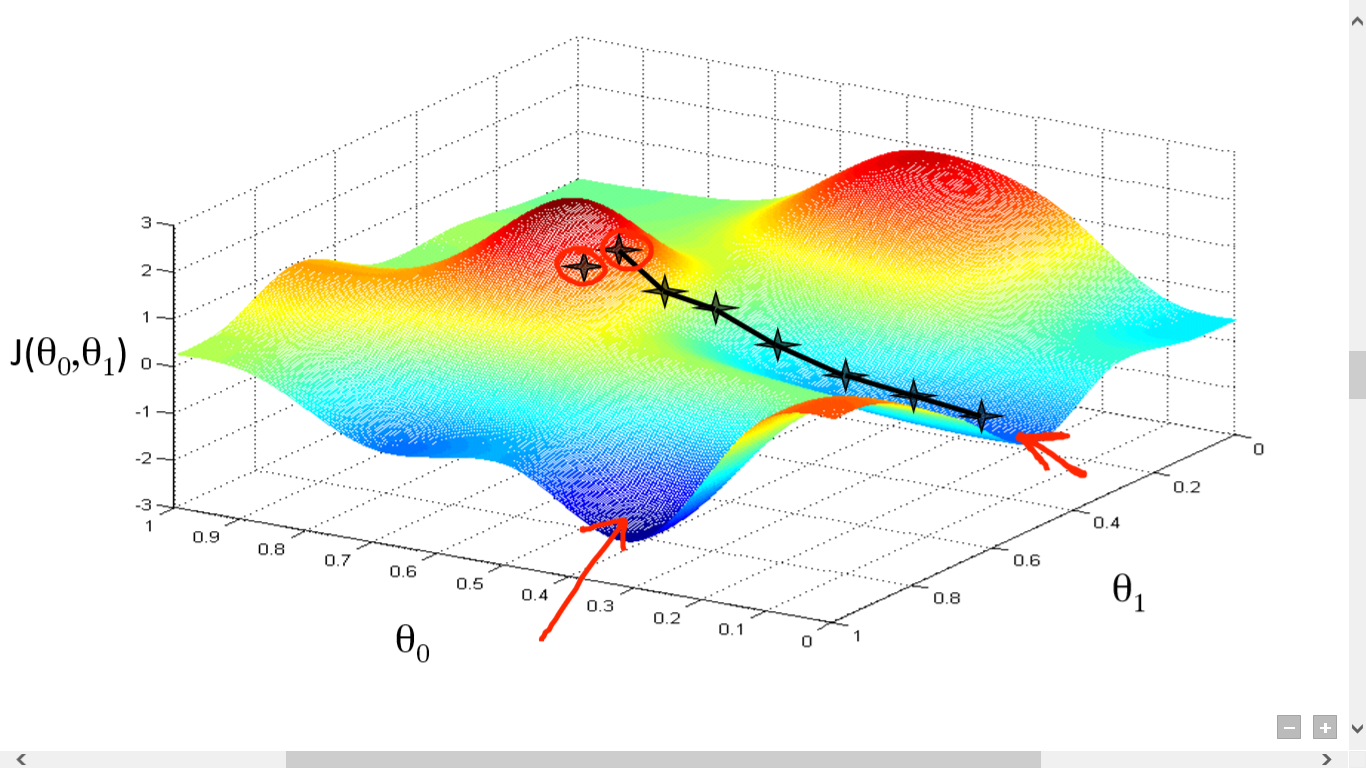 fuente
fuente
Aquí hemos trazado un gráfico entre J() y . Nuestro objetivo es encontrar el punto más profundo (mínimo global) de esta función. Ahora el punto más profundo es donde J() es mínimo.
Se requieren dos cosas para encontrar el punto más profundo:
- Derivada: para encontrar la dirección del siguiente paso.
- (Tasa de aprendizaje) - magnitud del siguiente paso
La idea es que primero seleccione cualquier punto aleatorio de la función. Luego necesitas calcular la derivada de J()wrt . Esto apuntará a la dirección del mínimo local. Ahora multiplique ese gradiente resultante con la tasa de aprendizaje. La tasa de aprendizaje no tiene un valor fijo y se decide en función de los problemas.
Ahora, debe restar el resultado de para obtener el nuevo .
Esta actualización de debe hacerse simultáneamente para cada (i) .
Realice estos pasos repetidamente hasta que alcance el mínimo local o global. Al alcanzar el mínimo global, ha logrado la pérdida más baja posible en su predicción.
Tomar derivadas es simple. Solo el cálculo básico que debes haber hecho en tu escuela secundaria es suficiente. El principal problema es con la tasa de aprendizaje ( ). Llevar un buen ritmo de aprendizaje es importante y muchas veces difícil.
Si toma una tasa de aprendizaje muy pequeña, cada paso será demasiado pequeño y, por lo tanto, necesitará mucho tiempo para alcanzar el mínimo local.

Ahora, si tiende a tomar un valor de tasa de aprendizaje enorme, sobrepasará el mínimo y nunca volverá a converger. No existe una regla específica para la tasa de aprendizaje perfecta.
Necesita ajustarlo para preparar el mejor modelo.
La ecuación para el descenso de gradiente es:
Repetir hasta la convergencia:
Entonces podemos resumir el Algoritmo de Descenso de Gradiente como:
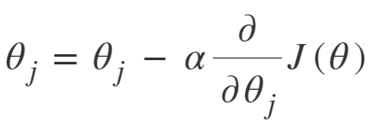
- Empezar con aleatorio
- Bucle hasta la convergencia:
- Calcular gradiente
- Actualizar
- Regreso
Algoritmo de descenso de gradiente estocástico
Ahora, el algoritmo de descenso de gradiente es un buen algoritmo para minimizar la función de costo, especialmente para datos pequeños y medianos. Pero cuando necesitamos lidiar con conjuntos de datos más grandes, el algoritmo de descenso de gradiente resulta ser lento en el cálculo. La razón es simple: necesita calcular el gradiente y actualizar los valores simultáneamente para cada parámetro, y eso también para cada ejemplo de entrenamiento.
¡Así que piensa en todos esos cálculos! Es enorme y, por lo tanto, era necesario un algoritmo de descenso de gradiente ligeramente modificado, a saber, el algoritmo de descenso de gradiente estocástico (SGD).
La única diferencia que tiene SGD con Normal Gradient Descent es que, en SGD, no tratamos con toda la instancia de entrenamiento en un solo momento. En SGD, calculamos el gradiente de la función de costo para un solo ejemplo aleatorio en cada iteración.
Ahora, hacerlo reduce el tiempo necesario para los cálculos por un margen enorme, especialmente para grandes conjuntos de datos. El camino tomado por SGD es muy desordenado y ruidoso (aunque un camino ruidoso puede darnos la oportunidad de alcanzar mínimos globales).
Pero eso está bien, ya que no tenemos que preocuparnos por el camino tomado.
Solo necesitamos alcanzar una pérdida mínima en un tiempo más rápido.
Entonces podemos resumir el Algoritmo de Descenso de Gradiente como:
- Bucle hasta la convergencia:
- Elija el punto de datos único ' i'
- Calcular gradiente sobre ese único punto
- Actualizar
- Regreso
Algoritmo de descenso de gradiente de mini lotes
El descenso de gradiente de mini lotes es otra ligera modificación del algoritmo de descenso de gradiente. Está algo entre el Descenso de Gradiente Normal y el Descenso de Gradiente Estocástico.
El descenso de gradiente de minilotes solo toma un lote más pequeño de todo el conjunto de datos y luego minimiza la pérdida en él.
Este proceso es más eficiente que los dos algoritmos de descenso de gradiente anteriores. Ahora, el tamaño del lote puede ser, por supuesto, el que desee.
Pero los investigadores han demostrado que es mejor si se mantiene entre 1 y 100, siendo 32 el mejor tamaño de lote.
Por lo tanto, el tamaño de lote = 32 se mantiene predeterminado en la mayoría de los marcos.
- Bucle hasta la convergencia:
- Elija un lote de puntos de datos ' b '
- Calcular gradiente sobre ese lote
- Actualizar
- Regreso
Conclusión
Ahora tiene la comprensión teórica de la regresión logística. Has aprendido a representar matemáticamente funciones logísticas. Sabe cómo medir el error pronosticado usando la función de costo.
También sabe cómo puede minimizar esta pérdida utilizando el algoritmo de descenso de gradiente.
Finalmente, sabe qué variación del algoritmo de descenso de gradiente debe elegir para su problema. upGrad ofrece un Diploma PG en Aprendizaje Automático e IA y una Maestría en Ciencias en Aprendizaje Automático e IA que pueden guiarlo hacia la construcción de una carrera. Estos cursos explicarán la necesidad del aprendizaje automático y los pasos adicionales para recopilar conocimientos en este dominio que cubren conceptos variados que van desde algoritmos de descenso de gradiente hasta redes neuronales.
¿Qué es un algoritmo de descenso de gradiente?
El descenso de gradiente es un algoritmo de optimización para encontrar el mínimo de una función. Supón que quieres encontrar el mínimo de una función f(x) entre dos puntos (a, b) y (c, d) en la gráfica de y = f(x). Luego, el descenso del gradiente implica tres pasos: (1) elegir un punto en el medio entre dos puntos extremos, (2) calcular el gradiente ∇f(x) (3) moverse en dirección opuesta al gradiente, es decir, desde (c, d) hasta (a, b). La forma de pensar en esto es que el algoritmo encuentra la pendiente de la función en un punto y luego se mueve en la dirección opuesta a la pendiente.
¿Qué es la función sigmoidea?
La función sigmoidea, o curva sigmoidea, es un tipo de función matemática que no es lineal y tiene una forma muy similar a la letra S (de ahí el nombre). Se utiliza en investigación de operaciones, estadísticas y otras disciplinas para modelar ciertas formas de crecimiento de valor real. También se utiliza en una amplia gama de aplicaciones en informática e ingeniería, especialmente en áreas relacionadas con las redes neuronales y la inteligencia artificial. Las funciones sigmoideas se utilizan como parte de las entradas de los algoritmos de aprendizaje por refuerzo, que se basan en redes neuronales artificiales.
¿Qué es el algoritmo de descenso de gradiente estocástico?
El descenso de gradiente estocástico es una de las variaciones populares del algoritmo clásico de descenso de gradiente para encontrar los mínimos locales de la función. El algoritmo elige aleatoriamente la dirección en la que irá la función a continuación para minimizar el valor y la dirección se repite hasta que se alcanza un mínimo local. El objetivo es que al repetir continuamente este proceso, el algoritmo converja al mínimo global o local de la función.