
Rendimiento front-end 2021: planificación y métricas
Publicado: 2022-03-10Esta guía ha sido amablemente respaldada por nuestros amigos de LogRocket, un servicio que combina la supervisión del rendimiento de frontend , la reproducción de sesiones y el análisis de productos para ayudarlo a crear mejores experiencias para los clientes. LogRocket rastrea métricas clave, incl. DOM completo, tiempo hasta el primer byte, primer retardo de entrada, CPU del cliente y uso de memoria. Obtenga una prueba gratuita de LogRocket hoy.

Tabla de contenido
- Preparándose: planificación y métricas
Cultura de rendimiento, Core Web Vitals, perfiles de rendimiento, CrUX, Lighthouse, FID, TTI, CLS, dispositivos. - Establecer metas realistas
Presupuestos de rendimiento, objetivos de rendimiento, marco RAIL, presupuestos de 170 KB/30 KB. - Definición del entorno
Elección de un marco, costo de rendimiento de referencia, paquete web, dependencias, CDN, arquitectura de front-end, CSR, SSR, CSR + SSR, renderizado estático, prerenderizado, patrón PRPL. - Optimizaciones de activos
Brotli, AVIF, WebP, imágenes receptivas, AV1, carga multimedia adaptable, compresión de video, fuentes web, fuentes de Google. - Optimizaciones de compilación
Módulos de JavaScript, patrón de módulo/no módulo, agitación de árboles, división de código, elevación de alcance, paquete web, servicio diferencial, trabajador web, WebAssembly, paquetes de JavaScript, React, SPA, hidratación parcial, importación en interacción, terceros, caché. - Optimizaciones de entrega
Carga diferida, observador de intersecciones, representación y decodificación diferidas, CSS crítico, transmisión, sugerencias de recursos, cambios de diseño, trabajador de servicio. - Redes, HTTP/2, HTTP/3
Grapado OCSP, certificados EV/DV, empaquetado, IPv6, QUIC, HTTP/3. - Pruebas y monitoreo
Flujo de trabajo de auditoría, navegadores proxy, página 404, avisos de consentimiento de cookies de GDPR, diagnóstico de rendimiento CSS, accesibilidad. - Triunfos rápidos
- Todo en una página
- Descargar la lista de verificación (PDF, Apple Pages, MS Word)
- Suscríbase a nuestro boletín de correo electrónico para no perderse las próximas guías.
Preparándose: planificación y métricas
Las microoptimizaciones son excelentes para mantener el rendimiento en el buen camino, pero es fundamental tener objetivos claramente definidos en mente: objetivos medibles que influirían en cualquier decisión que se tome a lo largo del proceso. Hay un par de modelos diferentes, y los que se analizan a continuación son bastante obstinados; solo asegúrese de establecer sus propias prioridades desde el principio.
- Establecer una cultura de rendimiento.
En muchas organizaciones, los desarrolladores front-end saben exactamente cuáles son los problemas subyacentes comunes y qué estrategias deben usarse para solucionarlos. Sin embargo, mientras no haya un respaldo establecido de la cultura del desempeño, cada decisión se convertirá en un campo de batalla de departamentos, dividiendo la organización en silos. Necesita la aceptación de las partes interesadas de la empresa y, para obtenerla, debe establecer un estudio de caso o una prueba de concepto sobre cómo la velocidad, especialmente Core Web Vitals , que trataremos en detalle más adelante, beneficia las métricas y los indicadores clave de rendimiento. ( KPI ) que les importan.Por ejemplo, para que el rendimiento sea más tangible, puede exponer el impacto en el rendimiento de los ingresos al mostrar la correlación entre la tasa de conversión y el tiempo de carga de la aplicación, así como el rendimiento de representación. O la tasa de rastreo del bot de búsqueda (PDF, páginas 27–50).
Sin una fuerte alineación entre los equipos de desarrollo/diseño y negocios/marketing, el rendimiento no se mantendrá a largo plazo. Estudie las quejas comunes que llegan al servicio de atención al cliente y al equipo de ventas, estudie los análisis de las altas tasas de rebote y las caídas de conversión. Explore cómo mejorar el rendimiento puede ayudar a aliviar algunos de estos problemas comunes. Ajuste el argumento según el grupo de partes interesadas con el que esté hablando.
Ejecute experimentos de rendimiento y mida los resultados, tanto en dispositivos móviles como en computadoras de escritorio (por ejemplo, con Google Analytics). Le ayudará a construir un caso de estudio personalizado para la empresa con datos reales. Además, el uso de datos de estudios de casos y experimentos publicados en WPO Stats ayudará a aumentar la sensibilidad de las empresas sobre por qué es importante el rendimiento y qué impacto tiene en la experiencia del usuario y las métricas comerciales. Sin embargo, afirmar que el rendimiento importa por sí solo no es suficiente: también debe establecer algunos objetivos medibles y rastreables y observarlos a lo largo del tiempo.
¿Cómo llegar allá? En su charla sobre Creación de rendimiento a largo plazo, Allison McKnight comparte un estudio de caso completo sobre cómo ayudó a establecer una cultura de rendimiento en Etsy (diapositivas). Más recientemente, Tammy Everts ha hablado sobre los hábitos de los equipos de desempeño altamente efectivos tanto en organizaciones pequeñas como grandes.
Al tener estas conversaciones en las organizaciones, es importante tener en cuenta que, al igual que UX es un espectro de experiencias, el rendimiento web es una distribución. Como señaló Karolina Szczur, "esperar que un solo número pueda proporcionar una calificación a la que aspirar es una suposición errónea". Por lo tanto, los objetivos de rendimiento deben ser granulares, rastreables y tangibles.
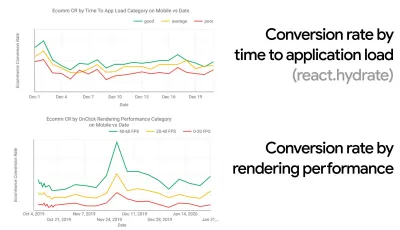
- Objetivo: ser al menos un 20 % más rápido que su competidor más rápido.
Según la investigación psicológica, si desea que los usuarios sientan que su sitio web es más rápido que el sitio web de su competidor, debe ser al menos un 20% más rápido. Estudie a sus principales competidores, recopile métricas sobre cómo se desempeñan en dispositivos móviles y de escritorio y establezca umbrales que lo ayuden a superarlos. Sin embargo, para obtener resultados y objetivos precisos, primero asegúrese de obtener una imagen completa de la experiencia de sus usuarios mediante el estudio de sus análisis. A continuación, puede imitar la experiencia del percentil 90 para la prueba.Para obtener una buena primera impresión de cómo se desempeñan sus competidores, puede usar Chrome UX Report ( CrUX , un conjunto de datos de RUM listo para usar, una introducción en video de Ilya Grigorik y una guía detallada de Rick Viscomi) o Treo, una herramienta de monitoreo de RUM que funciona con Chrome UX Report. Los datos se recopilan de los usuarios del navegador Chrome, por lo que los informes serán específicos de Chrome, pero le brindarán una distribución bastante completa del rendimiento, lo que es más importante, las puntuaciones de Core Web Vitals, en una amplia gama de sus visitantes. Tenga en cuenta que los nuevos conjuntos de datos de CrUX se publican el segundo martes de cada mes .
Alternativamente, también puede usar:
- Herramienta de comparación de informes Chrome UX de Addy Osmani,
- Speed Scorecard (también proporciona un estimador de impacto en los ingresos),
- Comparación de prueba de experiencia de usuario real o
- SiteSpeed CI (basado en pruebas sintéticas).
Nota : si usa Page Speed Insights o la API de Page Speed Insights (¡no, no está en desuso!), puede obtener datos de rendimiento de CrUX para páginas específicas en lugar de solo los agregados. Estos datos pueden ser mucho más útiles para establecer objetivos de rendimiento para activos como "página de destino" o "lista de productos". Y si está utilizando CI para probar los presupuestos, debe asegurarse de que su entorno probado coincida con CrUX si usó CrUX para establecer el objetivo ( ¡gracias Patrick Meenan! ).
Si necesita ayuda para mostrar el razonamiento detrás de la priorización de la velocidad, o si desea visualizar la disminución de la tasa de conversión o el aumento de la tasa de rebote con un rendimiento más lento, o tal vez necesite abogar por una solución RUM en su organización, Sergey Chernyshev ha creado una calculadora de velocidad UX, una herramienta de código abierto que lo ayuda a simular datos y visualizarlos para transmitir su punto.
CrUX genera una descripción general de las distribuciones de rendimiento a lo largo del tiempo, con el tráfico recopilado de los usuarios de Google Chrome. Puedes crear el tuyo propio en Chrome UX Dashboard. (Vista previa grande) 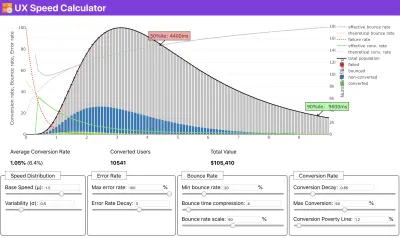
Justo cuando necesita defender el rendimiento para transmitir su punto: la Calculadora de velocidad de UX visualiza el impacto del rendimiento en las tasas de rebote, la conversión y los ingresos totales, según datos reales. (Vista previa grande) A veces, es posible que desee profundizar un poco más, combinando los datos provenientes de CrUX con cualquier otro dato que ya tenga para determinar rápidamente dónde se encuentran las ralentizaciones, los puntos ciegos y las ineficiencias, para sus competidores o para su proyecto. En su trabajo, Harry Roberts ha estado utilizando una hoja de cálculo de topografía de la velocidad del sitio que utiliza para desglosar el rendimiento por tipos de página clave y realizar un seguimiento de las diferentes métricas clave entre ellos. Puede descargar la hoja de cálculo como Hojas de cálculo de Google, Excel, documento de OpenOffice o CSV.
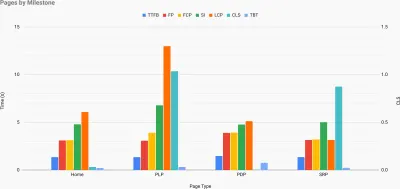
Topografía de velocidad del sitio, con métricas clave representadas para páginas clave en el sitio. (Vista previa grande) Y si quiere llegar hasta el final, puede ejecutar una auditoría de rendimiento de Lighthouse en cada página de un sitio (a través de Lightouse Parade), con una salida guardada como CSV. Eso lo ayudará a identificar qué páginas específicas (o tipos de páginas) de sus competidores funcionan peor o mejor, y en qué es posible que desee centrar sus esfuerzos. (¡Sin embargo, para su propio sitio, probablemente sea mejor enviar datos a un punto final de análisis!).

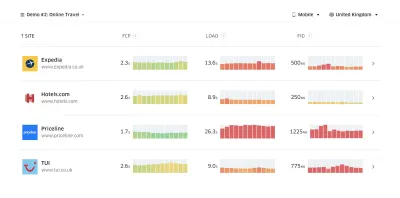
Con Lighthouse Parade, puede ejecutar una auditoría de rendimiento de Lighthouse en cada página de un sitio, con una salida guardada como CSV. (Vista previa grande) Recopile datos, configure una hoja de cálculo, reduzca el 20% y configure sus objetivos ( presupuestos de rendimiento ) de esta manera. Ahora tienes algo medible contra lo que probar. Si tiene en cuenta el presupuesto y trata de enviar solo la carga útil mínima para obtener un tiempo interactivo rápido, entonces está en un camino razonable.
¿Necesita recursos para empezar?
- Addy Osmani ha escrito un artículo muy detallado sobre cómo empezar a presupuestar el rendimiento, cómo cuantificar el impacto de las nuevas funciones y por dónde empezar cuando supera el presupuesto.
- La guía de Lara Hogan sobre cómo abordar los diseños con un presupuesto de rendimiento puede proporcionar consejos útiles para los diseñadores.
- Harry Roberts ha publicado una guía sobre cómo configurar una hoja de cálculo de Google para mostrar el impacto de los scripts de terceros en el rendimiento, utilizando Request Map,
- Performance Budget Calculator de Jonathan Fielding, perf-budget-calculator de Katie Hempenius y Browser Calories pueden ayudar a crear presupuestos (gracias a Karolina Szczur por los avisos).
- En muchas empresas, los presupuestos de desempeño no deben ser aspiracionales, sino más bien pragmáticos, sirviendo como una señal de advertencia para evitar pasar de cierto punto. En ese caso, podría elegir su peor punto de datos en las últimas dos semanas como umbral y continuar desde allí. Presupuestos de desempeño, pragmáticamente le muestra una estrategia para lograrlo.
- Además, haga que tanto el presupuesto de rendimiento como el rendimiento actual sean visibles configurando paneles con gráficos que informen los tamaños de compilación. Hay muchas herramientas que le permiten lograrlo: el panel de SiteSpeed.io (código abierto), SpeedCurve y Calibre son solo algunas de ellas, y puede encontrar más herramientas en perf.rocks.

Las calorías del navegador lo ayudan a establecer un presupuesto de rendimiento y medir si una página supera estos números o no. (Vista previa grande) Una vez que tenga un presupuesto establecido, incorpórelo a su proceso de creación con Webpack Performance Hints y Bundlesize, Lighthouse CI, PWMetrics o Sitespeed CI para hacer cumplir los presupuestos en las solicitudes de extracción y proporcionar un historial de puntuación en los comentarios de relaciones públicas.
Para exponer los presupuestos de rendimiento a todo el equipo, integre los presupuestos de rendimiento en Lighthouse a través de Lightwallet o use LHCI Action para una integración rápida de Github Actions. Y si necesita algo personalizado, puede usar webpagetest-charts-api, una API de puntos finales para crear gráficos a partir de los resultados de WebPagetest.
Sin embargo, la conciencia del rendimiento no debería provenir únicamente de los presupuestos de rendimiento. Al igual que Pinterest, puede crear una regla eslint personalizada que no permita la importación desde archivos y directorios que se sabe que tienen muchas dependencias y que inflarían el paquete. Configure una lista de paquetes "seguros" que se puedan compartir con todo el equipo.
Además, piense en las tareas críticas del cliente que son más beneficiosas para su negocio. Estudie, discuta y defina umbrales de tiempo aceptables para acciones críticas y establezca marcas de tiempo de usuario "Listo para UX" que toda la organización haya aprobado. En muchos casos, los viajes de los usuarios tocarán el trabajo de muchos departamentos diferentes, por lo que la alineación en términos de tiempos aceptables ayudará a respaldar o evitar las discusiones sobre el desempeño en el futuro. Asegúrese de que los costos adicionales de los recursos y características adicionales sean visibles y comprensibles.
Alinear los esfuerzos de rendimiento con otras iniciativas tecnológicas, que van desde nuevas características del producto que se está construyendo hasta la refactorización para llegar a nuevas audiencias globales. Entonces, cada vez que ocurre una conversación sobre un mayor desarrollo, el rendimiento también es parte de esa conversación. Es mucho más fácil alcanzar los objetivos de rendimiento cuando el código base es nuevo o se está refactorizando.
Además, como sugirió Patrick Meenan, vale la pena planificar una secuencia de carga y compensaciones durante el proceso de diseño. Si prioriza desde el principio qué partes son más críticas y define el orden en el que deben aparecer, también sabrá qué se puede retrasar. Idealmente, ese orden también reflejará la secuencia de sus importaciones de CSS y JavaScript, por lo que será más fácil manejarlas durante el proceso de compilación. Además, considere cuál debería ser la experiencia visual en estados "intermedios", mientras se carga la página (por ejemplo, cuando las fuentes web aún no se cargan).
Una vez que haya establecido una sólida cultura de desempeño en su organización, intente ser un 20 % más rápido que antes para mantener las prioridades intactas a medida que pasa el tiempo ( ¡gracias, Guy Podjarny! ). Pero tenga en cuenta los diferentes tipos y comportamientos de uso de sus clientes (que Tobias Baldauf llamó cadencia y cohortes), junto con el tráfico de bots y los efectos de la estacionalidad.
Planificación, planificación, planificación. Puede ser tentador entrar en algunas optimizaciones rápidas de "frutos al alcance de la mano" desde el principio, y podría ser una buena estrategia para ganancias rápidas, pero será muy difícil mantener el rendimiento como una prioridad sin planificar y establecer una empresa realista. -Objetivos de rendimiento personalizados.
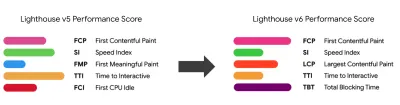
- Elija las métricas correctas.
No todas las métricas son igualmente importantes. Estudie qué métricas son más importantes para su aplicación: por lo general, se definirá por la rapidez con la que puede comenzar a renderizar los píxeles más importantes de su interfaz y la rapidez con la que puede proporcionar la capacidad de respuesta de entrada para estos píxeles renderizados. Este conocimiento le dará el mejor objetivo de optimización para los esfuerzos en curso. Al final, no son los eventos de carga o los tiempos de respuesta del servidor los que definen la experiencia, sino la percepción de cuán ágil se siente la interfaz.¿Qué significa? En lugar de centrarse en el tiempo de carga de la página completa (a través de los tiempos de onLoad y DOMContentLoaded , por ejemplo), priorice la carga de la página tal como la perciben sus clientes. Eso significa centrarse en un conjunto de métricas ligeramente diferente. De hecho, elegir la métrica correcta es un proceso sin ganadores obvios.
Según la investigación de Tim Kadlec y las notas de Marcos Iglesias en su charla, las métricas tradicionales podrían agruparse en unos pocos conjuntos. Por lo general, los necesitaremos todos para obtener una imagen completa del rendimiento y, en su caso particular, algunos de ellos serán más importantes que otros.
- Las métricas basadas en la cantidad miden el número de solicitudes, el peso y la puntuación de rendimiento. Bueno para generar alarmas y monitorear cambios a lo largo del tiempo, no tan bueno para comprender la experiencia del usuario.
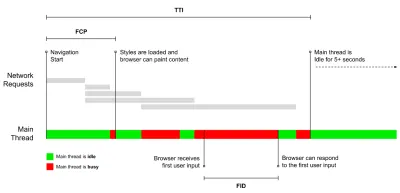
- Las métricas de hitos utilizan estados durante el tiempo de vida del proceso de carga, por ejemplo, Tiempo hasta el primer byte y Tiempo hasta interactivo . Bueno para describir la experiencia del usuario y el monitoreo, no tan bueno para saber qué sucede entre los hitos.
- Las métricas de procesamiento proporcionan una estimación de la rapidez con la que se procesa el contenido (p. ej., tiempo de inicio de procesamiento , índice de velocidad ). Bueno para medir y ajustar el rendimiento de representación, pero no tan bueno para medir cuándo aparece contenido importante y se puede interactuar con él.
- Las métricas personalizadas miden un evento personalizado en particular para el usuario, por ejemplo, el Tiempo hasta el primer tweet de Twitter y el Tiempo de espera de Pinner de Pinterest. Bueno para describir la experiencia del usuario con precisión, no tan bueno para escalar las métricas y compararlas con la competencia.
Para completar el panorama, generalmente buscamos métricas útiles entre todos estos grupos. Por lo general, los más específicos y relevantes son:
- Tiempo para Interactivo (TTI)
El punto en el que el diseño se ha estabilizado , las fuentes web clave son visibles y el hilo principal está lo suficientemente disponible para manejar la entrada del usuario, básicamente la marca de tiempo cuando un usuario puede interactuar con la interfaz de usuario. Las métricas clave para comprender cuánto tiempo de espera debe experimentar un usuario para usar el sitio sin demoras. Boris Schapira ha escrito una publicación detallada sobre cómo medir TTI de manera confiable. - Primera demora de entrada (FID) o capacidad de respuesta de entrada
El tiempo desde que un usuario interactúa por primera vez con su sitio hasta el momento en que el navegador puede responder a esa interacción. Complementa muy bien a TTI, ya que describe la parte faltante de la imagen: lo que sucede cuando un usuario realmente interactúa con el sitio. Diseñado como una métrica RUM únicamente. Hay una biblioteca de JavaScript para medir FID en el navegador. - Pintura con contenido más grande (LCP)
Marca el punto en la línea de tiempo de carga de la página cuando es probable que se haya cargado el contenido importante de la página. La suposición es que el elemento más importante de la página es el más grande visible en la ventana gráfica del usuario. Si los elementos se representan tanto por encima como por debajo del pliegue, solo la parte visible se considera relevante. - Tiempo total de bloqueo ( TBT )
Una métrica que ayuda a cuantificar la gravedad de cuán no interactiva es una página antes de que se vuelva confiablemente interactiva (es decir, el subproceso principal ha estado libre de tareas que se ejecutan durante más de 50 ms ( tareas largas ) durante al menos 5 s). La métrica mide la cantidad total de tiempo entre la primera pintura y el Tiempo de interacción (TTI), donde el subproceso principal se bloqueó durante el tiempo suficiente para evitar la capacidad de respuesta de entrada. No es de extrañar, entonces, que un TBT bajo sea un buen indicador de un buen desempeño. (gracias, Artem, Phil) - Cambio de diseño acumulativo ( CLS )
La métrica destaca la frecuencia con la que los usuarios experimentan cambios de diseño inesperados ( reflujos ) al acceder al sitio. Examina los elementos inestables y su impacto en la experiencia general. Cuanto menor sea la puntuación, mejor. - Índice de velocidad
Mide la rapidez con la que se rellenan visualmente los contenidos de la página; cuanto menor sea la puntuación, mejor. La puntuación del índice de velocidad se calcula en función de la velocidad del progreso visual , pero es simplemente un valor calculado. También es sensible al tamaño de la ventana gráfica, por lo que debe definir un rango de configuraciones de prueba que coincidan con su público objetivo. Tenga en cuenta que se está volviendo menos importante con LCP convirtiéndose en una métrica más relevante ( ¡gracias, Boris, Artem! ). - tiempo de CPU dedicado
Una métrica que muestra con qué frecuencia y durante cuánto tiempo se bloquea el subproceso principal, trabajando en pintar, renderizar, generar secuencias de comandos y cargar. El tiempo de CPU alto es un claro indicador de una experiencia de janky , es decir, cuando el usuario experimenta un retraso notable entre su acción y una respuesta. Con WebPageTest, puede seleccionar "Capturar línea de tiempo de herramientas de desarrollo" en la pestaña "Chrome" para exponer el desglose del hilo principal a medida que se ejecuta en cualquier dispositivo que use WebPageTest. - Costos de CPU a nivel de componente
Al igual que con el tiempo dedicado a la CPU , esta métrica, propuesta por Stoyan Stefanov, explora el impacto de JavaScript en la CPU . La idea es utilizar el recuento de instrucciones de CPU por componente para comprender su impacto en la experiencia general, de forma aislada. Podría implementarse usando Puppeteer y Chrome. - índice de frustración
Si bien muchas de las métricas presentadas anteriormente explican cuándo ocurre un evento en particular, FrustrationIndex de Tim Vereecke analiza las brechas entre las métricas en lugar de mirarlas individualmente. Examina los hitos clave percibidos por el usuario final, como el título es visible, el primer contenido es visible, visualmente listo y la página parece lista y calcula una puntuación que indica el nivel de frustración al cargar una página. Cuanto mayor sea la brecha, mayor será la posibilidad de que un usuario se sienta frustrado. Potencialmente un buen KPI para la experiencia del usuario. Tim ha publicado una publicación detallada sobre FrustrationIndex y cómo funciona. - Impacto del peso del anuncio
Si su sitio depende de los ingresos generados por la publicidad, es útil realizar un seguimiento del peso del código relacionado con la publicidad. El script de Paddy Ganti construye dos URL (una normal y otra que bloquea los anuncios), solicita la generación de una comparación de video a través de WebPageTest e informa un delta. - Métricas de desviación
Como señalaron los ingenieros de Wikipedia, los datos de cuánta variación existe en sus resultados podrían informarle cuán confiables son sus instrumentos y cuánta atención debe prestar a las desviaciones y los valores atípicos. Una gran variación es un indicador de los ajustes necesarios en la configuración. También ayuda a comprender si ciertas páginas son más difíciles de medir de manera confiable, por ejemplo, debido a scripts de terceros que causan una variación significativa. También podría ser una buena idea realizar un seguimiento de la versión del navegador para comprender los cambios en el rendimiento cuando se implementa una nueva versión del navegador. - Métricas personalizadas
Las métricas personalizadas se definen según las necesidades de su negocio y la experiencia del cliente. Requiere que identifique píxeles importantes , scripts críticos , CSS necesario y activos relevantes y mida la rapidez con que se entregan al usuario. Para eso, puede monitorear Hero Rendering Times o usar Performance API, marcando marcas de tiempo particulares para eventos que son importantes para su negocio. Además, puede recopilar métricas personalizadas con WebPagetest ejecutando JavaScript arbitrario al final de una prueba.
Tenga en cuenta que la primera pintura significativa (FMP) no aparece en la descripción general anterior. Solía proporcionar una idea de la rapidez con la que el servidor genera cualquier dato. FMP largo generalmente indicaba que JavaScript bloqueaba el hilo principal, pero también podría estar relacionado con problemas de back-end/servidor. Sin embargo, la métrica ha quedado obsoleta recientemente, ya que parece no ser precisa en aproximadamente el 20 % de los casos. Fue reemplazado efectivamente por LCP, que es más confiable y más fácil de razonar. Ya no se admite en Lighthouse. Vuelva a verificar las últimas métricas y recomendaciones de rendimiento centradas en el usuario solo para asegurarse de que está en la página segura ( gracias, Patrick Meenan ).

Steve Souders tiene una explicación detallada de muchas de estas métricas. Es importante tener en cuenta que, si bien el tiempo de interacción se mide mediante la ejecución de auditorías automatizadas en el llamado entorno de laboratorio , el retraso de la primera entrada representa la experiencia real del usuario, y los usuarios reales experimentan un retraso notable. En general, probablemente sea una buena idea medir y rastrear siempre ambos.
Según el contexto de su aplicación, las métricas preferidas pueden diferir: por ejemplo, para la interfaz de usuario de TV de Netflix, la capacidad de respuesta de entrada clave, el uso de memoria y TTI son más importantes, y para Wikipedia, las métricas de primeros/últimos cambios visuales y tiempo de CPU son más importantes.
Nota : tanto FID como TTI no tienen en cuenta el comportamiento de desplazamiento; el desplazamiento puede ocurrir de forma independiente ya que está fuera del hilo principal, por lo que para muchos sitios de consumo de contenido, estas métricas pueden ser mucho menos importantes ( ¡gracias, Patrick! ).
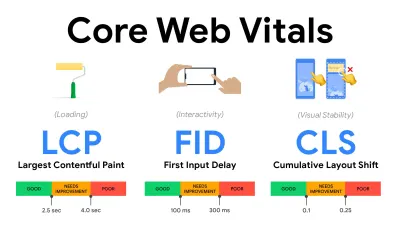
- Mida y optimice los Core Web Vitals .
Durante mucho tiempo, las métricas de rendimiento fueron bastante técnicas, centrándose en la vista de ingeniería de qué tan rápido responden los servidores y qué tan rápido se cargan los navegadores. Las métricas han cambiado a lo largo de los años, tratando de encontrar una manera de capturar la experiencia real del usuario, en lugar de los tiempos del servidor. En mayo de 2020, Google anunció Core Web Vitals, un conjunto de nuevas métricas de rendimiento centradas en el usuario, cada una de las cuales representa una faceta distinta de la experiencia del usuario.Para cada uno de ellos, Google recomienda un rango de objetivos de velocidad aceptables. Al menos el 75 % de todas las visitas a la página deben superar el rango bueno para aprobar esta evaluación. Estas métricas ganaron terreno rápidamente, y con Core Web Vitals convirtiéndose en señales de clasificación para la Búsqueda de Google en mayo de 2021 ( actualización del algoritmo de clasificación de Page Experience ), muchas empresas han centrado su atención en sus puntuaciones de rendimiento.
Analicemos cada uno de los Core Web Vitals, uno por uno, junto con técnicas y herramientas útiles para optimizar sus experiencias con estas métricas en mente. (Vale la pena señalar que obtendrá mejores puntajes de Core Web Vitals si sigue los consejos generales de este artículo).
- Pintura con contenido más grande ( LCP ) < 2,5 seg.
Mide la carga de una página e informa el tiempo de procesamiento de la imagen o bloque de texto más grande que está visible dentro de la ventana gráfica. Por lo tanto, LCP se ve afectado por todo lo que está aplazando la representación de información importante, ya sean tiempos de respuesta lentos del servidor, bloqueo de CSS, JavaScript en tránsito (de origen o de terceros), carga de fuentes web, operaciones costosas de representación o pintura, perezosos -imágenes cargadas, pantallas de esqueleto o renderizado del lado del cliente.
Para una buena experiencia, LCP debe ocurrir dentro de los 2,5 segundos desde que la página comienza a cargarse por primera vez. Eso significa que debemos renderizar la primera parte visible de la página lo antes posible. Eso requerirá CSS crítico personalizado para cada plantilla, organizando el orden<head>y precargando activos críticos (los cubriremos más adelante).La razón principal de una puntuación LCP baja suelen ser las imágenes. Entregar un LCP en <2,5 s en Fast 3G, alojado en un servidor bien optimizado, todo estático sin representación del lado del cliente y con una imagen que proviene de una CDN de imagen dedicada, significa que el tamaño de imagen teórico máximo es de solo alrededor de 144 KB . Es por eso que las imágenes receptivas son importantes, así como la precarga temprana de imágenes críticas (con
preload).Sugerencia rápida : para descubrir qué se considera LCP en una página, en DevTools puede pasar el cursor sobre la insignia LCP en "Tiempos" en el Panel de rendimiento (¡ gracias, Tim Kadlec !).
- Retardo de la primera entrada ( FID ) < 100 ms.
Mide la capacidad de respuesta de la interfaz de usuario, es decir, cuánto tiempo estuvo ocupado el navegador con otras tareas antes de que pudiera reaccionar a un evento de entrada de usuario discreto como un toque o un clic. Está diseñado para capturar los retrasos que resultan de que el subproceso principal esté ocupado, especialmente durante la carga de la página.
El objetivo es permanecer entre 50 y 100 ms por cada interacción. Para llegar allí, necesitamos identificar tareas largas (bloquea el hilo principal durante > 50 ms) y dividirlas, codificar un paquete dividido en varios fragmentos, reducir el tiempo de ejecución de JavaScript, optimizar la obtención de datos, diferir la ejecución de scripts de terceros. , mueva JavaScript al subproceso de fondo con los trabajadores web y use la hidratación progresiva para reducir los costos de rehidratación en los SPA.Consejo rápido : en general, una estrategia confiable para obtener una mejor puntuación FID es minimizar el trabajo en el subproceso principal dividiendo los paquetes más grandes en paquetes más pequeños y sirviendo lo que el usuario necesita cuando lo necesita, para que las interacciones del usuario no se retrasen. . Cubriremos más sobre eso en detalle a continuación.
- Cambio de diseño acumulativo ( CLS ) < 0.1.
Mide la estabilidad visual de la interfaz de usuario para garantizar interacciones fluidas y naturales, es decir, la suma total de todos los puntajes de cambio de diseño individuales para cada cambio de diseño inesperado que ocurre durante la vida útil de la página. Un cambio de diseño individual ocurre cada vez que un elemento que ya estaba visible cambia su posición en la página. Se puntúa según el tamaño del contenido y la distancia que se movió.
Por lo tanto, cada vez que aparece un cambio, por ejemplo, cuando las fuentes alternativas y las fuentes web tienen métricas de fuente diferentes, o anuncios, incrustaciones o iframes que llegan tarde, o las dimensiones de imagen/video no están reservadas, o CSS tardío obliga a repintar, o los cambios son inyectados por JavaScript tardío: tiene un impacto en la puntuación CLS. El valor recomendado para una buena experiencia es un CLS < 0,1.
Vale la pena señalar que se supone que Core Web Vitals evoluciona con el tiempo, con un ciclo anual predecible . Para la actualización del primer año, es posible que esperemos que First Contentful Paint se promueva a Core Web Vitals, un umbral de FID reducido y un mejor soporte para aplicaciones de una sola página. También podríamos ver que la respuesta a las entradas del usuario después de la carga gana más peso, junto con las consideraciones de seguridad, privacidad y accesibilidad (!).
En relación con Core Web Vitals, hay muchos recursos y artículos útiles que vale la pena consultar:
- La tabla de clasificación de Web Vitals le permite comparar sus puntajes con los de la competencia en dispositivos móviles, tabletas, computadoras de escritorio y en 3G y 4G.
- Core SERP Vitals, una extensión de Chrome que muestra Core Web Vitals de CrUX en los resultados de búsqueda de Google.
- Layout Shift GIF Generator que visualiza CLS con un simple GIF (también disponible desde la línea de comando).
- La biblioteca web-vitals puede recopilar y enviar Core Web Vitals a Google Analytics, Google Tag Manager o cualquier otro punto final de análisis.
- Análisis de Web Vitals con WebPageTest, en el que Patrick Meenan explora cómo WebPageTest expone datos sobre Core Web Vitals.
- Optimización con Core Web Vitals, un video de 50 minutos con Addy Osmani, en el que destaca cómo mejorar Core Web Vitals en un estudio de caso de comercio electrónico.
- El cambio de diseño acumulativo en la práctica y el cambio de diseño acumulativo en el mundo real son artículos completos de Nic Jansma, que cubren prácticamente todo sobre CLS y cómo se correlaciona con métricas clave como la tasa de rebote, el tiempo de sesión o los clics de rabia.
- What Forces Reflow, con una descripción general de las propiedades o los métodos, cuando se solicita/llama en JavaScript, activará el navegador para calcular sincrónicamente el estilo y el diseño.
- CSS Triggers muestra qué propiedades CSS activan Layout, Paint y Composite.
- Reparar la inestabilidad del diseño es un tutorial sobre el uso de WebPageTest para identificar y solucionar problemas de inestabilidad del diseño.
- Cambio de diseño acumulativo, la métrica de inestabilidad de diseño, otra guía muy detallada de Boris Schapira sobre CLS, cómo se calcula, cómo medir y cómo optimizar.
- Cómo mejorar Core Web Vitals, una guía detallada de Simon Hearne sobre cada una de las métricas (incluidas otras Web Vitals, como FCP, TTI, TBT), cuándo ocurren y cómo se miden.
Entonces, ¿son Core Web Vitals las métricas definitivas a seguir ? No exactamente. De hecho, ya están expuestos en la mayoría de las soluciones y plataformas RUM, incluidos Cloudflare, Treo, SpeedCurve, Calibre, WebPageTest (ya en la vista de tira de película), Newrelic, Shopify, Next.js, todas las herramientas de Google (PageSpeed Insights, Lighthouse + CI, Search Consola, etc.) y muchos otros.
Sin embargo, como explica Katie Sylor-Miller, algunos de los principales problemas con Core Web Vitals son la falta de compatibilidad entre navegadores, en realidad no medimos el ciclo de vida completo de la experiencia de un usuario, además es difícil correlacionar los cambios en FID y CLS con resultados de negocio.
Como deberíamos esperar que Core Web Vitals evolucione, parece razonable combinar siempre Web Vitals con sus métricas personalizadas para obtener una mejor comprensión de su posición en términos de rendimiento.
- Pintura con contenido más grande ( LCP ) < 2,5 seg.
- Recopile datos en un dispositivo representativo de su audiencia.
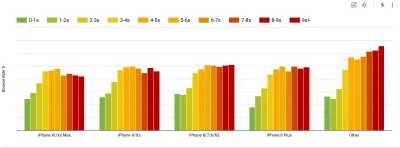
Para recopilar datos precisos, debemos elegir minuciosamente los dispositivos en los que realizar las pruebas. En la mayoría de las empresas, eso significa buscar análisis y crear perfiles de usuario basados en los tipos de dispositivos más comunes. Sin embargo, a menudo, el análisis por sí solo no proporciona una imagen completa. Una parte significativa de la audiencia objetivo podría estar abandonando el sitio (y no regresando) solo porque su experiencia es demasiado lenta y es poco probable que sus dispositivos aparezcan como los dispositivos más populares en análisis por ese motivo. Por lo tanto, realizar una investigación adicional sobre dispositivos comunes en su grupo objetivo podría ser una buena idea.A nivel mundial en 2020, según IDC, el 84,8% de todos los teléfonos móviles enviados son dispositivos Android. Un consumidor promedio actualiza su teléfono cada 2 años, y en el ciclo de reemplazo de teléfonos de EE. UU. es de 33 meses. Los teléfonos promedio más vendidos en todo el mundo costarán menos de $ 200.
Un dispositivo representativo, entonces, es un dispositivo Android que tiene al menos 24 meses de antigüedad , cuesta $200 o menos, funciona con 3G lento, RTT de 400 ms y transferencia de 400 kbps, solo para ser un poco más pesimista. Esto puede ser muy diferente para su empresa, por supuesto, pero es una aproximación lo suficientemente cercana a la mayoría de los clientes. De hecho, podría ser una buena idea buscar en los Best Sellers actuales de Amazon para su mercado objetivo. ( ¡Gracias a Tim Kadlec, Henri Helvetica y Alex Russell por los consejos! ).
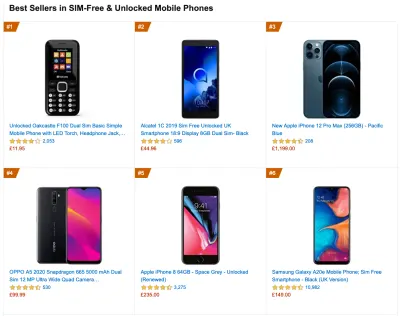
Al crear un nuevo sitio o aplicación, siempre consulte primero los Best Sellers actuales de Amazon para su mercado objetivo. (Vista previa grande) ¿Qué dispositivos de prueba elegir entonces? Las que encajen bien con el perfil descrito anteriormente. Es una buena opción elegir un Moto G4/G5 Plus un poco más antiguo, un dispositivo Samsung de gama media (Galaxy A50, S8), un buen dispositivo intermedio como un Nexus 5X, Xiaomi Mi A3 o Xiaomi Redmi Note. 7 y un dispositivo lento como Alcatel 1X o Cubot X19, quizás en un laboratorio de dispositivos abiertos. Para realizar pruebas en dispositivos de aceleración térmica más lentos, también puede obtener un Nexus 4, que cuesta alrededor de $ 100.
Además, verifique los conjuntos de chips utilizados en cada dispositivo y no represente demasiado un conjunto de chips : unas pocas generaciones de Snapdragon y Apple, así como Rockchip de gama baja, Mediatek serían suficientes (¡gracias, Patrick!) .
Si no tiene un dispositivo a mano, emule la experiencia móvil en el escritorio probando en una red 3G acelerada (p. ej., 300 ms RTT, 1,6 Mbps de bajada, 0,8 Mbps de subida) con una CPU acelerada (5 veces más lenta). Con el tiempo, cambie a 3G normal, 4G lento (p. ej., 170 ms RTT, 9 Mbps de bajada, 9 Mbps de subida) y Wi-Fi. Para que el impacto en el rendimiento sea más visible, incluso podría introducir 2G Tuesdays o configurar una red 3G/4G acelerada en su oficina para realizar pruebas más rápidas.
Tenga en cuenta que en un dispositivo móvil, deberíamos esperar una desaceleración de 4×–5× en comparación con las máquinas de escritorio. Los dispositivos móviles tienen diferentes GPU, CPU, memoria y diferentes características de batería. Por eso es importante tener un buen perfil de un dispositivo promedio y probar siempre en dicho dispositivo.
- Las herramientas de prueba sintéticas recopilan datos de laboratorio en un entorno reproducible con dispositivos predefinidos y configuraciones de red (por ejemplo, Lighthouse , Calibre , WebPageTest ) y
- Las herramientas Real User Monitoring ( RUM ) evalúan las interacciones de los usuarios de forma continua y recopilan datos de campo (p. ej., SpeedCurve , New Relic ; las herramientas también proporcionan pruebas sintéticas).
- use Lighthouse CI para rastrear las puntuaciones de Lighthouse a lo largo del tiempo (es bastante impresionante),
- ejecute Lighthouse en GitHub Actions para obtener un informe de Lighthouse junto con cada RP,
- ejecutar una auditoría de rendimiento de Lighthouse en cada página de un sitio (a través de Lightouse Parade), con una salida guardada como CSV,
- utilice la calculadora de puntuaciones de Lighthouse y los pesos métricos de Lighthouse si necesita profundizar en más detalles.
- Lighthouse también está disponible para Firefox, pero internamente utiliza la API de PageSpeed Insights y genera un informe basado en un agente de usuario de Chrome 79 sin cabeza.

Afortunadamente, existen muchas opciones excelentes que lo ayudan a automatizar la recopilación de datos y medir el rendimiento de su sitio web a lo largo del tiempo de acuerdo con estas métricas. Tenga en cuenta que una buena imagen de rendimiento cubre un conjunto de métricas de rendimiento, datos de laboratorio y datos de campo:
El primero es particularmente útil durante el desarrollo , ya que lo ayudará a identificar, aislar y solucionar problemas de rendimiento mientras trabaja en el producto. Este último es útil para el mantenimiento a largo plazo, ya que lo ayudará a comprender los cuellos de botella de su rendimiento a medida que ocurren en vivo, cuando los usuarios realmente acceden al sitio.
Al aprovechar las API de RUM integradas, como el tiempo de navegación, el tiempo de recursos, el tiempo de pintura, las tareas largas, etc., las herramientas de prueba sintéticas y el RUM juntos brindan una imagen completa del rendimiento en su aplicación. Puede usar Calibre, Treo, SpeedCurve, mPulse y Boomerang, Sitespeed.io, que son excelentes opciones para monitorear el rendimiento. Además, con el encabezado Server Timing, incluso podría monitorear el rendimiento de back-end y front-end en un solo lugar.
Nota : Siempre es una apuesta más segura elegir aceleradores de nivel de red, externos al navegador, ya que, por ejemplo, DevTools tiene problemas para interactuar con HTTP/2 push, debido a la forma en que está implementado (¡ gracias, Yoav, Patrick !). Para Mac OS, podemos usar Network Link Conditioner, para Windows Traffic Shaper, para Linux netem y para FreeBSD dummynet.
Como es probable que realice pruebas en Lighthouse, tenga en cuenta que puede:
- Configure perfiles "limpios" y "clientes" para realizar pruebas.
Al ejecutar pruebas en herramientas de monitoreo pasivo, es una estrategia común desactivar antivirus y tareas de CPU en segundo plano, eliminar transferencias de ancho de banda en segundo plano y probar con un perfil de usuario limpio sin extensiones de navegador para evitar resultados sesgados (en Firefox y en Chrome).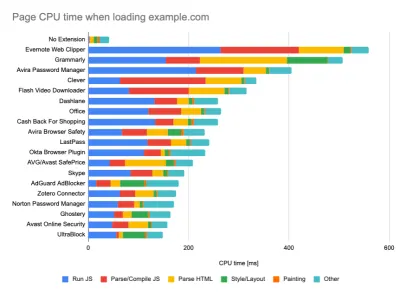
El informe de DebugBear destaca las 20 extensiones más lentas, incluidos administradores de contraseñas, bloqueadores de anuncios y aplicaciones populares como Evernote y Grammarly. (Vista previa grande) Sin embargo, también es una buena idea estudiar qué extensiones de navegador usan sus clientes con frecuencia y probar también con perfiles de "clientes" dedicados. De hecho, algunas extensiones pueden tener un impacto profundo en el rendimiento (Informe de rendimiento de extensiones de Chrome de 2020) en su aplicación, y si sus usuarios las usan mucho, es posible que desee tenerlo en cuenta por adelantado. Por lo tanto, los resultados del perfil "limpio" por sí solos son demasiado optimistas y pueden aplastarse en escenarios de la vida real.
- Comparta los objetivos de rendimiento con sus colegas.
Asegúrese de que los objetivos de rendimiento sean familiares para todos los miembros de su equipo para evitar malentendidos en el futuro. Cada decisión, ya sea de diseño, marketing o cualquier otra, tiene implicaciones en el rendimiento , y distribuir la responsabilidad y la propiedad entre todo el equipo agilizaría las decisiones centradas en el rendimiento más adelante. Mapee las decisiones de diseño contra el presupuesto de rendimiento y las prioridades definidas desde el principio.
Tabla de contenido
- Preparándose: planificación y métricas
- Establecer metas realistas
- Definición del entorno
- Optimizaciones de activos
- Optimizaciones de compilación
- Optimizaciones de entrega
- Redes, HTTP/2, HTTP/3
- Pruebas y monitoreo
- Triunfos rápidos
- Todo en una página
- Descargar la lista de verificación (PDF, Apple Pages, MS Word)
- Suscríbase a nuestro boletín de correo electrónico para no perderse las próximas guías.