
Lista de verificación de rendimiento de front-end 2021 (PDF, Apple Pages, MS Word)
Publicado: 2022-03-10Esta guía ha sido amablemente respaldada por nuestros amigos de LogRocket, un servicio que combina la supervisión del rendimiento de frontend , la reproducción de sesiones y el análisis de productos para ayudarlo a crear mejores experiencias para los clientes. LogRocket rastrea métricas clave, incl. DOM completo, tiempo hasta el primer byte, primer retardo de entrada, CPU del cliente y uso de memoria. Obtenga una prueba gratuita de LogRocket hoy.

El rendimiento web es una bestia engañosa, ¿no es así? ¿Cómo sabemos realmente cuál es nuestra posición en términos de rendimiento y cuáles son exactamente los cuellos de botella de nuestro rendimiento? ¿Es JavaScript costoso, entrega lenta de fuentes web, imágenes pesadas o renderizado lento? ¿Hemos optimizado lo suficiente con la sacudida del árbol, la elevación del alcance, la división de código y todos los patrones de carga sofisticados con el observador de intersecciones, la hidratación progresiva, las sugerencias de los clientes, HTTP/3, los trabajadores de servicio y, por Dios, los trabajadores de borde? Y, lo que es más importante, ¿dónde comenzamos a mejorar el desempeño y cómo establecemos una cultura de desempeño a largo plazo?
En el pasado, el rendimiento a menudo era una mera ocurrencia tardía . A menudo pospuesto hasta el final del proyecto, se reduciría a minificación, concatenación, optimización de activos y, potencialmente, algunos ajustes finos en el archivo de config del servidor. Mirando hacia atrás ahora, las cosas parecen haber cambiado bastante significativamente.
El rendimiento no es solo una preocupación técnica: afecta todo, desde la accesibilidad hasta la usabilidad y la optimización del motor de búsqueda, y cuando se integra en el flujo de trabajo, las decisiones de diseño deben basarse en sus implicaciones de rendimiento. El rendimiento debe medirse, monitorearse y refinarse continuamente , y la creciente complejidad de la web plantea nuevos desafíos que dificultan el seguimiento de las métricas, ya que los datos variarán significativamente según el dispositivo, el navegador, el protocolo, el tipo de red y la latencia ( CDN, ISP, cachés, proxies, firewalls, balanceadores de carga y servidores, todos juegan un papel en el rendimiento).
Entonces, si creamos una descripción general de todas las cosas que debemos tener en cuenta al mejorar el rendimiento, desde el comienzo del proyecto hasta el lanzamiento final del sitio web, ¿cómo sería eso? A continuación, encontrará una lista de verificación de rendimiento de front-end (con suerte imparcial y objetiva) para 2021 : una descripción general actualizada de los problemas que podría necesitar considerar para garantizar que sus tiempos de respuesta sean rápidos, la interacción del usuario sea fluida y sus sitios no agotar el ancho de banda del usuario.
Tabla de contenido
- Todo en páginas separadas
- Preparándose: planificación y métricas
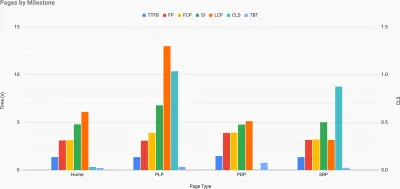
Cultura de rendimiento, Core Web Vitals, perfiles de rendimiento, CrUX, Lighthouse, FID, TTI, CLS, dispositivos. - Establecer metas realistas
Presupuestos de rendimiento, objetivos de rendimiento, marco RAIL, presupuestos de 170 KB/30 KB. - Definición del entorno
Elección de un marco, costo de rendimiento de referencia, paquete web, dependencias, CDN, arquitectura de front-end, CSR, SSR, CSR + SSR, renderizado estático, prerenderizado, patrón PRPL. - Optimizaciones de activos
Brotli, AVIF, WebP, imágenes receptivas, AV1, carga multimedia adaptable, compresión de video, fuentes web, fuentes de Google. - Optimizaciones de compilación
Módulos de JavaScript, patrón de módulo/no módulo, agitación de árboles, división de código, elevación de alcance, paquete web, servicio diferencial, trabajador web, WebAssembly, paquetes de JavaScript, React, SPA, hidratación parcial, importación en interacción, terceros, caché. - Optimizaciones de entrega
Carga diferida, observador de intersecciones, representación y decodificación diferidas, CSS crítico, transmisión, sugerencias de recursos, cambios de diseño, trabajador de servicio. - Redes, HTTP/2, HTTP/3
Grapado OCSP, certificados EV/DV, empaquetado, IPv6, QUIC, HTTP/3. - Pruebas y monitoreo
Flujo de trabajo de auditoría, navegadores proxy, página 404, avisos de consentimiento de cookies de GDPR, diagnóstico de rendimiento CSS, accesibilidad. - Triunfos rápidos
- Descargar la lista de verificación (PDF, Apple Pages, MS Word)
- ¡Nos vamos!
(También puede descargar el PDF de la lista de verificación (166 KB) o descargar el archivo editable de Apple Pages (275 KB) o el archivo .docx (151 KB). ¡Feliz optimización a todos!)
Preparándose: planificación y métricas
Las microoptimizaciones son excelentes para mantener el rendimiento en el buen camino, pero es fundamental tener objetivos claramente definidos en mente: objetivos medibles que influirían en cualquier decisión que se tome a lo largo del proceso. Hay un par de modelos diferentes, y los que se analizan a continuación son bastante obstinados; solo asegúrese de establecer sus propias prioridades desde el principio.
- Establecer una cultura de rendimiento.
En muchas organizaciones, los desarrolladores front-end saben exactamente cuáles son los problemas subyacentes comunes y qué estrategias deben usarse para solucionarlos. Sin embargo, mientras no haya un respaldo establecido de la cultura del desempeño, cada decisión se convertirá en un campo de batalla de departamentos, dividiendo la organización en silos. Necesita la aceptación de las partes interesadas de la empresa y, para obtenerla, debe establecer un estudio de caso o una prueba de concepto sobre cómo la velocidad, especialmente Core Web Vitals , que trataremos en detalle más adelante, beneficia las métricas y los indicadores clave de rendimiento. ( KPI ) que les importan.Por ejemplo, para que el rendimiento sea más tangible, puede exponer el impacto en el rendimiento de los ingresos al mostrar la correlación entre la tasa de conversión y el tiempo de carga de la aplicación, así como el rendimiento de representación. O la tasa de rastreo del bot de búsqueda (PDF, páginas 27–50).
Sin una fuerte alineación entre los equipos de desarrollo/diseño y negocios/marketing, el rendimiento no se mantendrá a largo plazo. Estudie las quejas comunes que llegan al servicio de atención al cliente y al equipo de ventas, estudie los análisis de las altas tasas de rebote y las caídas de conversión. Explore cómo mejorar el rendimiento puede ayudar a aliviar algunos de estos problemas comunes. Ajuste el argumento según el grupo de partes interesadas con el que esté hablando.
Ejecute experimentos de rendimiento y mida los resultados, tanto en dispositivos móviles como en computadoras de escritorio (por ejemplo, con Google Analytics). Le ayudará a construir un caso de estudio personalizado para la empresa con datos reales. Además, el uso de datos de estudios de casos y experimentos publicados en WPO Stats ayudará a aumentar la sensibilidad de las empresas sobre por qué es importante el rendimiento y qué impacto tiene en la experiencia del usuario y las métricas comerciales. Sin embargo, afirmar que el rendimiento importa por sí solo no es suficiente: también debe establecer algunos objetivos medibles y rastreables y observarlos a lo largo del tiempo.
¿Cómo llegar allá? En su charla sobre Creación de rendimiento a largo plazo, Allison McKnight comparte un estudio de caso completo sobre cómo ayudó a establecer una cultura de rendimiento en Etsy (diapositivas). Más recientemente, Tammy Everts ha hablado sobre los hábitos de los equipos de desempeño altamente efectivos tanto en organizaciones pequeñas como grandes.
Al tener estas conversaciones en las organizaciones, es importante tener en cuenta que, al igual que UX es un espectro de experiencias, el rendimiento web es una distribución. Como señaló Karolina Szczur, "esperar que un solo número pueda proporcionar una calificación a la que aspirar es una suposición errónea". Por lo tanto, los objetivos de rendimiento deben ser granulares, rastreables y tangibles.
- Objetivo: ser al menos un 20 % más rápido que su competidor más rápido.
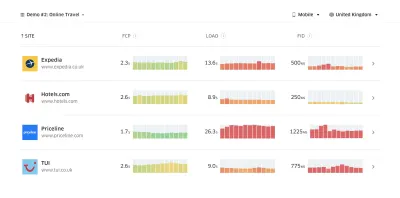
Según la investigación psicológica, si desea que los usuarios sientan que su sitio web es más rápido que el sitio web de su competidor, debe ser al menos un 20% más rápido. Estudie a sus principales competidores, recopile métricas sobre cómo se desempeñan en dispositivos móviles y de escritorio y establezca umbrales que lo ayuden a superarlos. Sin embargo, para obtener resultados y objetivos precisos, primero asegúrese de obtener una imagen completa de la experiencia de sus usuarios mediante el estudio de sus análisis. A continuación, puede imitar la experiencia del percentil 90 para la prueba.Para obtener una buena primera impresión de cómo se desempeñan sus competidores, puede usar Chrome UX Report ( CrUX , un conjunto de datos de RUM listo para usar, una introducción en video de Ilya Grigorik y una guía detallada de Rick Viscomi) o Treo, una herramienta de monitoreo de RUM que funciona con Chrome UX Report. Los datos se recopilan de los usuarios del navegador Chrome, por lo que los informes serán específicos de Chrome, pero le brindarán una distribución bastante completa del rendimiento, lo que es más importante, las puntuaciones de Core Web Vitals, en una amplia gama de sus visitantes. Tenga en cuenta que los nuevos conjuntos de datos de CrUX se publican el segundo martes de cada mes .
Alternativamente, también puede usar:
- Herramienta de comparación de informes Chrome UX de Addy Osmani,
- Speed Scorecard (también proporciona un estimador de impacto en los ingresos),
- Comparación de prueba de experiencia de usuario real o
- SiteSpeed CI (basado en pruebas sintéticas).
Nota : si usa Page Speed Insights o la API de Page Speed Insights (¡no, no está en desuso!), puede obtener datos de rendimiento de CrUX para páginas específicas en lugar de solo los agregados. Estos datos pueden ser mucho más útiles para establecer objetivos de rendimiento para activos como "página de destino" o "lista de productos". Y si está utilizando CI para probar los presupuestos, debe asegurarse de que su entorno probado coincida con CrUX si usó CrUX para establecer el objetivo ( ¡gracias Patrick Meenan! ).
Si necesita ayuda para mostrar el razonamiento detrás de la priorización de la velocidad, o si desea visualizar la disminución de la tasa de conversión o el aumento de la tasa de rebote con un rendimiento más lento, o tal vez necesite abogar por una solución RUM en su organización, Sergey Chernyshev ha creado una calculadora de velocidad UX, una herramienta de código abierto que lo ayuda a simular datos y visualizarlos para transmitir su punto.
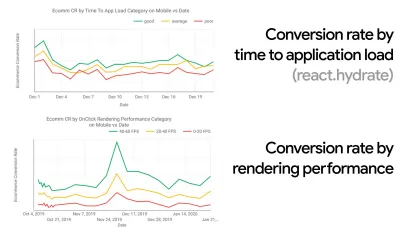
CrUX genera una descripción general de las distribuciones de rendimiento a lo largo del tiempo, con el tráfico recopilado de los usuarios de Google Chrome. Puedes crear el tuyo propio en Chrome UX Dashboard. (Vista previa grande) 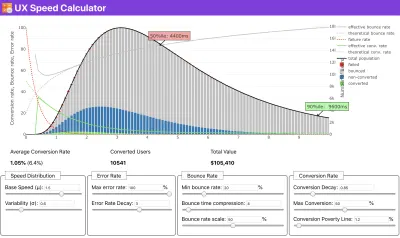
Justo cuando necesita defender el rendimiento para transmitir su punto: la Calculadora de velocidad de UX visualiza el impacto del rendimiento en las tasas de rebote, la conversión y los ingresos totales, según datos reales. (Vista previa grande) A veces, es posible que desee profundizar un poco más, combinando los datos provenientes de CrUX con cualquier otro dato que ya tenga para determinar rápidamente dónde se encuentran las ralentizaciones, los puntos ciegos y las ineficiencias, para sus competidores o para su proyecto. En su trabajo, Harry Roberts ha estado utilizando una hoja de cálculo de topografía de la velocidad del sitio que utiliza para desglosar el rendimiento por tipos de página clave y realizar un seguimiento de las diferentes métricas clave entre ellos. Puede descargar la hoja de cálculo como Hojas de cálculo de Google, Excel, documento de OpenOffice o CSV.
Topografía de velocidad del sitio, con métricas clave representadas para páginas clave en el sitio. (Vista previa grande) Y si quiere llegar hasta el final, puede ejecutar una auditoría de rendimiento de Lighthouse en cada página de un sitio (a través de Lightouse Parade), con una salida guardada como CSV. Eso lo ayudará a identificar qué páginas específicas (o tipos de páginas) de sus competidores funcionan peor o mejor, y en qué es posible que desee centrar sus esfuerzos. (¡Sin embargo, para su propio sitio, probablemente sea mejor enviar datos a un punto final de análisis!).

Con Lighthouse Parade, puede ejecutar una auditoría de rendimiento de Lighthouse en cada página de un sitio, con una salida guardada como CSV. (Vista previa grande) Recopile datos, configure una hoja de cálculo, reduzca el 20% y configure sus objetivos ( presupuestos de rendimiento ) de esta manera. Ahora tienes algo medible contra lo que probar. Si tiene en cuenta el presupuesto y trata de enviar solo la carga útil mínima para obtener un tiempo interactivo rápido, entonces está en un camino razonable.
¿Necesita recursos para empezar?
- Addy Osmani ha escrito un artículo muy detallado sobre cómo empezar a presupuestar el rendimiento, cómo cuantificar el impacto de las nuevas funciones y por dónde empezar cuando supera el presupuesto.
- La guía de Lara Hogan sobre cómo abordar los diseños con un presupuesto de rendimiento puede proporcionar consejos útiles para los diseñadores.
- Harry Roberts ha publicado una guía sobre cómo configurar una hoja de cálculo de Google para mostrar el impacto de los scripts de terceros en el rendimiento, utilizando Request Map,
- Performance Budget Calculator de Jonathan Fielding, perf-budget-calculator de Katie Hempenius y Browser Calories pueden ayudar a crear presupuestos (gracias a Karolina Szczur por los avisos).
- En muchas empresas, los presupuestos de desempeño no deben ser aspiracionales, sino más bien pragmáticos, sirviendo como una señal de advertencia para evitar pasar de cierto punto. En ese caso, podría elegir su peor punto de datos en las últimas dos semanas como umbral y continuar desde allí. Presupuestos de desempeño, pragmáticamente le muestra una estrategia para lograrlo.
- Además, haga que tanto el presupuesto de rendimiento como el rendimiento actual sean visibles configurando paneles con gráficos que informen los tamaños de compilación. Hay muchas herramientas que le permiten lograrlo: el panel de SiteSpeed.io (código abierto), SpeedCurve y Calibre son solo algunas de ellas, y puede encontrar más herramientas en perf.rocks.

Las calorías del navegador lo ayudan a establecer un presupuesto de rendimiento y medir si una página supera estos números o no. (Vista previa grande) Una vez que tenga un presupuesto establecido, incorpórelo a su proceso de creación con Webpack Performance Hints y Bundlesize, Lighthouse CI, PWMetrics o Sitespeed CI para hacer cumplir los presupuestos en las solicitudes de extracción y proporcionar un historial de puntuación en los comentarios de relaciones públicas.
Para exponer los presupuestos de rendimiento a todo el equipo, integre los presupuestos de rendimiento en Lighthouse a través de Lightwallet o use LHCI Action para una integración rápida de Github Actions. Y si necesita algo personalizado, puede usar webpagetest-charts-api, una API de puntos finales para crear gráficos a partir de los resultados de WebPagetest.
Sin embargo, la conciencia del rendimiento no debería provenir únicamente de los presupuestos de rendimiento. Al igual que Pinterest, puede crear una regla eslint personalizada que no permita la importación desde archivos y directorios que se sabe que tienen muchas dependencias y que inflarían el paquete. Configure una lista de paquetes "seguros" que se puedan compartir con todo el equipo.
Además, piense en las tareas críticas del cliente que son más beneficiosas para su negocio. Estudie, discuta y defina umbrales de tiempo aceptables para acciones críticas y establezca marcas de tiempo de usuario "Listo para UX" que toda la organización haya aprobado. En muchos casos, los viajes de los usuarios tocarán el trabajo de muchos departamentos diferentes, por lo que la alineación en términos de tiempos aceptables ayudará a respaldar o evitar las discusiones sobre el desempeño en el futuro. Asegúrese de que los costos adicionales de los recursos y características adicionales sean visibles y comprensibles.
Alinear los esfuerzos de rendimiento con otras iniciativas tecnológicas, que van desde nuevas características del producto que se está construyendo hasta la refactorización para llegar a nuevas audiencias globales. Entonces, cada vez que ocurre una conversación sobre un mayor desarrollo, el rendimiento también es parte de esa conversación. Es mucho más fácil alcanzar los objetivos de rendimiento cuando el código base es nuevo o se está refactorizando.
Además, como sugirió Patrick Meenan, vale la pena planificar una secuencia de carga y compensaciones durante el proceso de diseño. Si prioriza desde el principio qué partes son más críticas y define el orden en el que deben aparecer, también sabrá qué se puede retrasar. Idealmente, ese orden también reflejará la secuencia de sus importaciones de CSS y JavaScript, por lo que será más fácil manejarlas durante el proceso de compilación. Además, considere cuál debería ser la experiencia visual en estados "intermedios", mientras se carga la página (por ejemplo, cuando las fuentes web aún no se cargan).
Una vez que haya establecido una sólida cultura de desempeño en su organización, intente ser un 20 % más rápido que antes para mantener las prioridades intactas a medida que pasa el tiempo ( ¡gracias, Guy Podjarny! ). Pero tenga en cuenta los diferentes tipos y comportamientos de uso de sus clientes (que Tobias Baldauf llamó cadencia y cohortes), junto con el tráfico de bots y los efectos de la estacionalidad.
Planificación, planificación, planificación. Puede ser tentador entrar en algunas optimizaciones rápidas de "frutos al alcance de la mano" desde el principio, y podría ser una buena estrategia para ganancias rápidas, pero será muy difícil mantener el rendimiento como una prioridad sin planificar y establecer una empresa realista. -Objetivos de rendimiento personalizados.
- Elija las métricas correctas.
No todas las métricas son igualmente importantes. Estudie qué métricas son más importantes para su aplicación: por lo general, se definirá por la rapidez con la que puede comenzar a renderizar los píxeles más importantes de su interfaz y la rapidez con la que puede proporcionar la capacidad de respuesta de entrada para estos píxeles renderizados. Este conocimiento le dará el mejor objetivo de optimización para los esfuerzos en curso. Al final, no son los eventos de carga o los tiempos de respuesta del servidor los que definen la experiencia, sino la percepción de cuán ágil se siente la interfaz.¿Qué significa? En lugar de centrarse en el tiempo de carga de la página completa (a través de los tiempos de onLoad y DOMContentLoaded , por ejemplo), priorice la carga de la página tal como la perciben sus clientes. Eso significa centrarse en un conjunto de métricas ligeramente diferente. De hecho, elegir la métrica correcta es un proceso sin ganadores obvios.
Según la investigación de Tim Kadlec y las notas de Marcos Iglesias en su charla, las métricas tradicionales podrían agruparse en unos pocos conjuntos. Por lo general, los necesitaremos todos para obtener una imagen completa del rendimiento y, en su caso particular, algunos de ellos serán más importantes que otros.
- Las métricas basadas en la cantidad miden el número de solicitudes, el peso y la puntuación de rendimiento. Bueno para generar alarmas y monitorear cambios a lo largo del tiempo, no tan bueno para comprender la experiencia del usuario.
- Las métricas de hitos utilizan estados durante el tiempo de vida del proceso de carga, por ejemplo, Tiempo hasta el primer byte y Tiempo hasta interactivo . Bueno para describir la experiencia del usuario y el monitoreo, no tan bueno para saber qué sucede entre los hitos.
- Las métricas de procesamiento proporcionan una estimación de la rapidez con la que se procesa el contenido (p. ej., tiempo de inicio de procesamiento , índice de velocidad ). Bueno para medir y ajustar el rendimiento de representación, pero no tan bueno para medir cuándo aparece contenido importante y se puede interactuar con él.
- Las métricas personalizadas miden un evento personalizado en particular para el usuario, por ejemplo, el Tiempo hasta el primer tweet de Twitter y el Tiempo de espera de Pinner de Pinterest. Bueno para describir la experiencia del usuario con precisión, no tan bueno para escalar las métricas y compararlas con la competencia.
Para completar el panorama, generalmente buscamos métricas útiles entre todos estos grupos. Por lo general, los más específicos y relevantes son:
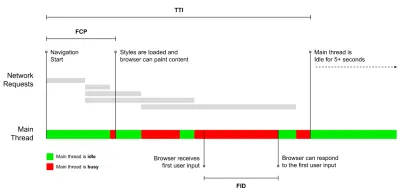
- Tiempo para Interactivo (TTI)
El punto en el que el diseño se ha estabilizado , las fuentes web clave son visibles y el hilo principal está lo suficientemente disponible para manejar la entrada del usuario, básicamente la marca de tiempo cuando un usuario puede interactuar con la interfaz de usuario. Las métricas clave para comprender cuánto tiempo de espera debe experimentar un usuario para usar el sitio sin demoras. Boris Schapira ha escrito una publicación detallada sobre cómo medir TTI de manera confiable. - Primera demora de entrada (FID) o capacidad de respuesta de entrada
El tiempo desde que un usuario interactúa por primera vez con su sitio hasta el momento en que el navegador puede responder a esa interacción. Complementa muy bien a TTI, ya que describe la parte faltante de la imagen: lo que sucede cuando un usuario realmente interactúa con el sitio. Diseñado como una métrica RUM únicamente. Hay una biblioteca de JavaScript para medir FID en el navegador. - Pintura con contenido más grande (LCP)
Marca el punto en la línea de tiempo de carga de la página cuando es probable que se haya cargado el contenido importante de la página. La suposición es que el elemento más importante de la página es el más grande visible en la ventana gráfica del usuario. Si los elementos se representan tanto por encima como por debajo del pliegue, solo la parte visible se considera relevante. - Tiempo total de bloqueo ( TBT )
Una métrica que ayuda a cuantificar la gravedad de cuán no interactiva es una página antes de que se vuelva confiablemente interactiva (es decir, el subproceso principal ha estado libre de tareas que se ejecutan durante más de 50 ms ( tareas largas ) durante al menos 5 s). La métrica mide la cantidad total de tiempo entre la primera pintura y el Tiempo de interacción (TTI), donde el subproceso principal se bloqueó durante el tiempo suficiente para evitar la capacidad de respuesta de entrada. No es de extrañar, entonces, que un TBT bajo sea un buen indicador de un buen desempeño. (gracias, Artem, Phil) - Cambio de diseño acumulativo ( CLS )
La métrica destaca la frecuencia con la que los usuarios experimentan cambios de diseño inesperados ( reflujos ) al acceder al sitio. Examina los elementos inestables y su impacto en la experiencia general. Cuanto menor sea la puntuación, mejor. - Índice de velocidad
Mide la rapidez con la que se rellenan visualmente los contenidos de la página; cuanto menor sea la puntuación, mejor. La puntuación del índice de velocidad se calcula en función de la velocidad del progreso visual , pero es simplemente un valor calculado. También es sensible al tamaño de la ventana gráfica, por lo que debe definir un rango de configuraciones de prueba que coincidan con su público objetivo. Tenga en cuenta que se está volviendo menos importante con LCP convirtiéndose en una métrica más relevante ( ¡gracias, Boris, Artem! ). - tiempo de CPU dedicado
Una métrica que muestra con qué frecuencia y durante cuánto tiempo se bloquea el subproceso principal, trabajando en pintar, renderizar, generar secuencias de comandos y cargar. El tiempo de CPU alto es un claro indicador de una experiencia de janky , es decir, cuando el usuario experimenta un retraso notable entre su acción y una respuesta. Con WebPageTest, puede seleccionar "Capturar línea de tiempo de herramientas de desarrollo" en la pestaña "Chrome" para exponer el desglose del hilo principal a medida que se ejecuta en cualquier dispositivo que use WebPageTest. - Costos de CPU a nivel de componente
Al igual que con el tiempo dedicado a la CPU , esta métrica, propuesta por Stoyan Stefanov, explora el impacto de JavaScript en la CPU . La idea es utilizar el recuento de instrucciones de CPU por componente para comprender su impacto en la experiencia general, de forma aislada. Podría implementarse usando Puppeteer y Chrome. - índice de frustración
Si bien muchas de las métricas presentadas anteriormente explican cuándo ocurre un evento en particular, FrustrationIndex de Tim Vereecke analiza las brechas entre las métricas en lugar de mirarlas individualmente. Examina los hitos clave percibidos por el usuario final, como el título es visible, el primer contenido es visible, visualmente listo y la página parece lista y calcula una puntuación que indica el nivel de frustración al cargar una página. Cuanto mayor sea la brecha, mayor será la posibilidad de que un usuario se sienta frustrado. Potencialmente un buen KPI para la experiencia del usuario. Tim ha publicado una publicación detallada sobre FrustrationIndex y cómo funciona. - Impacto del peso del anuncio
Si su sitio depende de los ingresos generados por la publicidad, es útil realizar un seguimiento del peso del código relacionado con la publicidad. El script de Paddy Ganti construye dos URL (una normal y otra que bloquea los anuncios), solicita la generación de una comparación de video a través de WebPageTest e informa un delta. - Métricas de desviación
Como señalaron los ingenieros de Wikipedia, los datos de cuánta variación existe en sus resultados podrían informarle cuán confiables son sus instrumentos y cuánta atención debe prestar a las desviaciones y los valores atípicos. Una gran variación es un indicador de los ajustes necesarios en la configuración. También ayuda a comprender si ciertas páginas son más difíciles de medir de manera confiable, por ejemplo, debido a scripts de terceros que causan una variación significativa. También podría ser una buena idea realizar un seguimiento de la versión del navegador para comprender los cambios en el rendimiento cuando se implementa una nueva versión del navegador. - Métricas personalizadas
Las métricas personalizadas se definen según las necesidades de su negocio y la experiencia del cliente. Requiere que identifique píxeles importantes , scripts críticos , CSS necesario y activos relevantes y mida la rapidez con que se entregan al usuario. Para eso, puede monitorear Hero Rendering Times o usar Performance API, marcando marcas de tiempo particulares para eventos que son importantes para su negocio. Además, puede recopilar métricas personalizadas con WebPagetest ejecutando JavaScript arbitrario al final de una prueba.
Tenga en cuenta que la primera pintura significativa (FMP) no aparece en la descripción general anterior. Solía proporcionar una idea de la rapidez con la que el servidor genera cualquier dato. FMP largo generalmente indicaba que JavaScript bloqueaba el hilo principal, pero también podría estar relacionado con problemas de back-end/servidor. Sin embargo, la métrica ha quedado obsoleta recientemente, ya que parece no ser precisa en aproximadamente el 20 % de los casos. Fue reemplazado efectivamente por LCP, que es más confiable y más fácil de razonar. Ya no se admite en Lighthouse. Vuelva a verificar las últimas métricas y recomendaciones de rendimiento centradas en el usuario solo para asegurarse de que está en la página segura ( gracias, Patrick Meenan ).
Steve Souders tiene una explicación detallada de muchas de estas métricas. Es importante tener en cuenta que, si bien el tiempo de interacción se mide mediante la ejecución de auditorías automatizadas en el llamado entorno de laboratorio , el retraso de la primera entrada representa la experiencia real del usuario, y los usuarios reales experimentan un retraso notable. En general, probablemente sea una buena idea medir y rastrear siempre ambos.
Según el contexto de su aplicación, las métricas preferidas pueden diferir: por ejemplo, para la interfaz de usuario de TV de Netflix, la capacidad de respuesta de entrada clave, el uso de memoria y TTI son más importantes, y para Wikipedia, las métricas de primeros/últimos cambios visuales y tiempo de CPU son más importantes.
Nota : tanto FID como TTI no tienen en cuenta el comportamiento de desplazamiento; el desplazamiento puede ocurrir de forma independiente ya que está fuera del hilo principal, por lo que para muchos sitios de consumo de contenido, estas métricas pueden ser mucho menos importantes ( ¡gracias, Patrick! ).
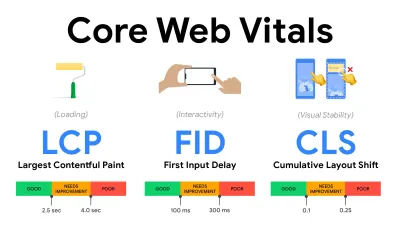
- Mida y optimice los Core Web Vitals .
Durante mucho tiempo, las métricas de rendimiento fueron bastante técnicas, centrándose en la vista de ingeniería de qué tan rápido responden los servidores y qué tan rápido se cargan los navegadores. Las métricas han cambiado a lo largo de los años, tratando de encontrar una manera de capturar la experiencia real del usuario, en lugar de los tiempos del servidor. En mayo de 2020, Google anunció Core Web Vitals, un conjunto de nuevas métricas de rendimiento centradas en el usuario, cada una de las cuales representa una faceta distinta de la experiencia del usuario.Para cada uno de ellos, Google recomienda un rango de objetivos de velocidad aceptables. Al menos el 75 % de todas las visitas a la página deben superar el rango bueno para aprobar esta evaluación. Estas métricas ganaron terreno rápidamente, y con Core Web Vitals convirtiéndose en señales de clasificación para la Búsqueda de Google en mayo de 2021 ( actualización del algoritmo de clasificación de Page Experience ), muchas empresas han centrado su atención en sus puntuaciones de rendimiento.
Analicemos cada uno de los Core Web Vitals, uno por uno, junto con técnicas y herramientas útiles para optimizar sus experiencias con estas métricas en mente. (Vale la pena señalar que obtendrá mejores puntajes de Core Web Vitals si sigue los consejos generales de este artículo).
- Pintura con contenido más grande ( LCP ) < 2,5 seg.
Mide la carga de una página e informa el tiempo de procesamiento de la imagen o bloque de texto más grande que está visible dentro de la ventana gráfica. Por lo tanto, LCP se ve afectado por todo lo que está aplazando la representación de información importante, ya sean tiempos de respuesta lentos del servidor, bloqueo de CSS, JavaScript en tránsito (de origen o de terceros), carga de fuentes web, operaciones costosas de representación o pintura, perezosos -imágenes cargadas, pantallas de esqueleto o renderizado del lado del cliente.
Para una buena experiencia, LCP debe ocurrir dentro de los 2,5 segundos desde que la página comienza a cargarse por primera vez. Eso significa que debemos renderizar la primera parte visible de la página lo antes posible. Eso requerirá CSS crítico personalizado para cada plantilla, organizando el orden<head>y precargando activos críticos (los cubriremos más adelante).La razón principal de una puntuación LCP baja suelen ser las imágenes. Entregar un LCP en <2,5 s en Fast 3G, alojado en un servidor bien optimizado, todo estático sin representación del lado del cliente y con una imagen que proviene de una CDN de imagen dedicada, significa que el tamaño de imagen teórico máximo es de solo alrededor de 144 KB . Es por eso que las imágenes receptivas son importantes, así como la precarga temprana de imágenes críticas (con
preload).Sugerencia rápida : para descubrir qué se considera LCP en una página, en DevTools puede pasar el cursor sobre la insignia LCP en "Tiempos" en el Panel de rendimiento (¡ gracias, Tim Kadlec !).
- Retardo de la primera entrada ( FID ) < 100 ms.
Mide la capacidad de respuesta de la interfaz de usuario, es decir, cuánto tiempo estuvo ocupado el navegador con otras tareas antes de que pudiera reaccionar a un evento de entrada de usuario discreto como un toque o un clic. Está diseñado para capturar los retrasos que resultan de que el subproceso principal esté ocupado, especialmente durante la carga de la página.
El objetivo es permanecer entre 50 y 100 ms por cada interacción. Para llegar allí, necesitamos identificar tareas largas (bloquea el hilo principal durante > 50 ms) y dividirlas, codificar un paquete dividido en varios fragmentos, reducir el tiempo de ejecución de JavaScript, optimizar la obtención de datos, diferir la ejecución de scripts de terceros. , mueva JavaScript al subproceso de fondo con los trabajadores web y use la hidratación progresiva para reducir los costos de rehidratación en los SPA.Consejo rápido : en general, una estrategia confiable para obtener una mejor puntuación FID es minimizar el trabajo en el subproceso principal dividiendo los paquetes más grandes en paquetes más pequeños y sirviendo lo que el usuario necesita cuando lo necesita, para que las interacciones del usuario no se retrasen. . Cubriremos más sobre eso en detalle a continuación.
- Cambio de diseño acumulativo ( CLS ) < 0.1.
Mide la estabilidad visual de la interfaz de usuario para garantizar interacciones fluidas y naturales, es decir, la suma total de todos los puntajes de cambio de diseño individuales para cada cambio de diseño inesperado que ocurre durante la vida útil de la página. Un cambio de diseño individual ocurre cada vez que un elemento que ya estaba visible cambia su posición en la página. Se puntúa según el tamaño del contenido y la distancia que se movió.
Por lo tanto, cada vez que aparece un cambio, por ejemplo, cuando las fuentes alternativas y las fuentes web tienen métricas de fuente diferentes, o anuncios, incrustaciones o iframes que llegan tarde, o las dimensiones de imagen/video no están reservadas, o CSS tardío obliga a repintar, o los cambios son inyectados por JavaScript tardío: tiene un impacto en la puntuación CLS. El valor recomendado para una buena experiencia es un CLS < 0,1.
Vale la pena señalar que se supone que Core Web Vitals evoluciona con el tiempo, con un ciclo anual predecible . Para la actualización del primer año, es posible que esperemos que First Contentful Paint se promueva a Core Web Vitals, un umbral de FID reducido y un mejor soporte para aplicaciones de una sola página. We might also see the responding to user inputs after load gaining more weight, along with security, privacy and accessibility (!) considerations.
Related to Core Web Vitals, there are plenty of useful resources and articles that are worth looking into:
- Web Vitals Leaderboard allows you to compare your scores against competition on mobile, tablet, desktop, and on 3G and 4G.
- Core SERP Vitals, a Chrome extension that shows the Core Web Vitals from CrUX in the Google Search Results.
- Layout Shift GIF Generator that visualizes CLS with a simple GIF (also available from the command line).
- web-vitals library can collect and send Core Web Vitals to Google Analytics, Google Tag Manager or any other analytics endpoint.
- Analyzing Web Vitals with WebPageTest, in which Patrick Meenan explores how WebPageTest exposes data about Core Web Vitals.
- Optimizing with Core Web Vitals, a 50-min video with Addy Osmani, in which he highlights how to improve Core Web Vitals in an eCommerce case-study.
- Cumulative Layout Shift in Practice and Cumulative Layout Shift in the Real World are comprehensive articles by Nic Jansma, which cover pretty much everything about CLS and how it correlates with key metrics such as Bounce Rate, Session Time or Rage Clicks.
- What Forces Reflow, with an overview of properties or methods, when requested/called in JavaScript, that will trigger the browser to synchronously calculate the style and layout.
- CSS Triggers shows which CSS properties trigger Layout, Paint and Composite.
- Fixing Layout Instability is a walkthrough of using WebPageTest to identify and fix layout instability issues.
- Cumulative Layout Shift, The Layout Instability Metric, another very detailed guide by Boris Schapira on CLS, how it's calcualted, how to measure and how to optimize for it.
- How To Improve Core Web Vitals, a detailed guide by Simon Hearne on each of the metrics (including other Web Vitals, such as FCP, TTI, TBT), when they occur and how they are measured.
So, are Core Web Vitals the ultimate metrics to follow ? No exactamente. They are indeed exposed in most RUM solutions and platforms already, including Cloudflare, Treo, SpeedCurve, Calibre, WebPageTest (in the filmstrip view already), Newrelic, Shopify, Next.js, all Google tools (PageSpeed Insights, Lighthouse + CI, Search Console etc.) and many others.
However, as Katie Sylor-Miller explains, some of the main problems with Core Web Vitals are the lack of cross-browser support, we don't really measure the full lifecycle of a user's experience, plus it's difficult to correlate changes in FID and CLS with business outcomes.
As we should be expecting Core Web Vitals to evolve, it seems only reasonable to always combine Web Vitals with your custom-tailored metrics to get a better understanding of where you stand in terms of performance.
- Pintura con contenido más grande ( LCP ) < 2,5 seg.
- Gather data on a device representative of your audience.
To gather accurate data, we need to thoroughly choose devices to test on. In most companies, that means looking into analytics and creating user profiles based on most common device types. Yet often, analytics alone doesn't provide a complete picture. A significant portion of the target audience might be abandoning the site (and not returning back) just because their experience is too slow, and their devices are unlikely to show up as the most popular devices in analytics for that reason. So, additionally conducting research on common devices in your target group might be a good idea.Globally in 2020, according to the IDC, 84.8% of all shipped mobile phones are Android devices. An average consumer upgrades their phone every 2 years, and in the US phone replacement cycle is 33 months. Average bestselling phones around the world will cost under $200.
A representative device, then, is an Android device that is at least 24 months old , costing $200 or less, running on slow 3G, 400ms RTT and 400kbps transfer, just to be slightly more pessimistic. This might be very different for your company, of course, but that's a close enough approximation of a majority of customers out there. In fact, it might be a good idea to look into current Amazon Best Sellers for your target market. ( Thanks to Tim Kadlec, Henri Helvetica and Alex Russell for the pointers! ).
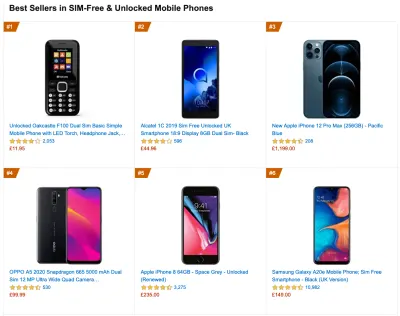
When building a new site or app, always check current Amazon Best Sellers for your target market first. (Vista previa grande) What test devices to choose then? The ones that fit well with the profile outlined above. It's a good option to choose a slightly older Moto G4/G5 Plus, a mid-range Samsung device (Galaxy A50, S8), a good middle-of-the-road device like a Nexus 5X, Xiaomi Mi A3 or Xiaomi Redmi Note 7 and a slow device like Alcatel 1X or Cubot X19, perhaps in an open device lab. For testing on slower thermal-throttled devices, you could also get a Nexus 4, which costs just around $100.
Also, check the chipsets used in each device and do not over-represent one chipset : a few generations of Snapdragon and Apple as well as low-end Rockchip, Mediatek would be enough (thanks, Patrick!) .
If you don't have a device at hand, emulate mobile experience on desktop by testing on a throttled 3G network (eg 300ms RTT, 1.6 Mbps down, 0.8 Mbps up) with a throttled CPU (5× slowdown). Eventually switch over to regular 3G, slow 4G (eg 170ms RTT, 9 Mbps down, 9Mbps up), and Wi-Fi. To make the performance impact more visible, you could even introduce 2G Tuesdays or set up a throttled 3G/4G network in your office for faster testing.
Keep in mind that on a mobile device, we should be expecting a 4×–5× slowdown compared to desktop machines. Mobile devices have different GPUs, CPU, memory and different battery characteristics. That's why it's important to have a good profile of an average device and always test on such a device.
- Synthetic testing tools collect lab data in a reproducible environment with predefined device and network settings (eg Lighthouse , Calibre , WebPageTest ) and
- Real User Monitoring ( RUM ) tools evaluate user interactions continuously and collect field data (eg SpeedCurve , New Relic — the tools provide synthetic testing, too).
- use Lighthouse CI to track Lighthouse scores over time (it's quite impressive),
- run Lighthouse in GitHub Actions to get a Lighthouse report alongside every PR,
- run a Lighthouse performance audit on every page of a site (via Lightouse Parade), with an output saved as CSV,
- use Lighthouse Scores Calculator and Lighthouse metric weights if you need to dive into more detail.
- Lighthouse is available for Firefox as well, but under the hood it uses the PageSpeed Insights API and generates a report based on a headless Chrome 79 User-Agent.

Luckily, there are many great options that help you automate the collection of data and measure how your website performs over time according to these metrics. Keep in mind that a good performance picture covers a set of performance metrics, lab data and field data:
The former is particularly useful during development as it will help you identify, isolate and fix performance issues while working on the product. The latter is useful for long-term maintenance as it will help you understand your performance bottlenecks as they are happening live — when users actually access the site.
By tapping into built-in RUM APIs such as Navigation Timing, Resource Timing, Paint Timing, Long Tasks, etc., synthetic testing tools and RUM together provide a complete picture of performance in your application. You could use Calibre, Treo, SpeedCurve, mPulse and Boomerang, Sitespeed.io, which all are great options for performance monitoring. Furthermore, with Server Timing header, you could even monitor back-end and front-end performance all in one place.
Note : It's always a safer bet to choose network-level throttlers, external to the browser, as, for example, DevTools has issues interacting with HTTP/2 push, due to the way it's implemented ( thanks, Yoav, Patrick !). For Mac OS, we can use Network Link Conditioner, for Windows Windows Traffic Shaper, for Linux netem, and for FreeBSD dummynet.
As it's likely that you'll be testing in Lighthouse, keep in mind that you can:
- Set up "clean" and "customer" profiles for testing.
While running tests in passive monitoring tools, it's a common strategy to turn off anti-virus and background CPU tasks, remove background bandwidth transfers and test with a clean user profile without browser extensions to avoid skewed results (in Firefox, and in Chrome).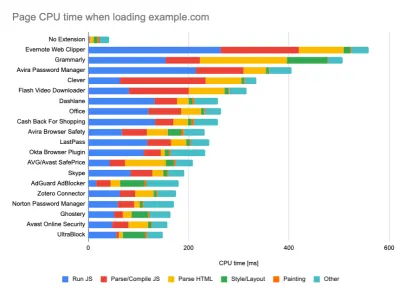
DebugBear's report highlights 20 slowest extensions, including password managers, ad-blockers and popular applications like Evernote and Grammarly. (Vista previa grande) However, it's also a good idea to study which browser extensions your customers use frequently, and test with dedicated "customer" profiles as well. In fact, some extensions might have a profound performance impact (2020 Chrome Extension Performance Report) on your application, and if your users use them a lot, you might want to account for it up front. Hence, "clean" profile results alone are overly optimistic and can be crushed in real-life scenarios.
- Comparta los objetivos de rendimiento con sus colegas.
Asegúrese de que los objetivos de rendimiento sean familiares para todos los miembros de su equipo para evitar malentendidos en el futuro. Cada decisión, ya sea de diseño, marketing o cualquier otra, tiene implicaciones en el rendimiento , y distribuir la responsabilidad y la propiedad entre todo el equipo agilizaría las decisiones centradas en el rendimiento más adelante. Mapee las decisiones de diseño contra el presupuesto de rendimiento y las prioridades definidas desde el principio.
Establecer metas realistas
- Tiempo de respuesta de 100 milisegundos, 60 fps.
Para que una interacción se sienta fluida, la interfaz tiene 100 ms para responder a la entrada del usuario. Más tiempo que eso, y el usuario percibe que la aplicación está retrasada. El RAIL, un modelo de rendimiento centrado en el usuario, le brinda objetivos saludables : para permitir una respuesta de <100 milisegundos, la página debe devolver el control al subproceso principal a más tardar cada <50 milisegundos. La latencia de entrada estimada nos dice si estamos alcanzando ese umbral e, idealmente, debería estar por debajo de los 50 ms. Para puntos de alta presión como la animación, es mejor no hacer nada más donde pueda y el mínimo absoluto donde no pueda.
RAIL, un modelo de rendimiento centrado en el usuario. Además, cada cuadro de animación debe completarse en menos de 16 milisegundos, logrando así 60 cuadros por segundo (1 segundo ÷ 60 = 16,6 milisegundos), preferiblemente menos de 10 milisegundos. Debido a que el navegador necesita tiempo para pintar el nuevo marco en la pantalla, su código debería terminar de ejecutarse antes de llegar a la marca de los 16,6 milisegundos. Estamos empezando a tener conversaciones sobre 120 fps (por ejemplo, las pantallas del iPad Pro funcionan a 120 Hz) y Surma ha cubierto algunas soluciones de rendimiento de renderizado para 120 fps, pero probablemente ese no sea un objetivo que estemos viendo todavía .
Sea pesimista en las expectativas de rendimiento, pero sea optimista en el diseño de la interfaz y use el tiempo de inactividad de manera inteligente (marque inactivo, inactivo hasta que sea urgente y reaccionar inactivo). Obviamente, estos objetivos se aplican al rendimiento del tiempo de ejecución, en lugar del rendimiento de carga.
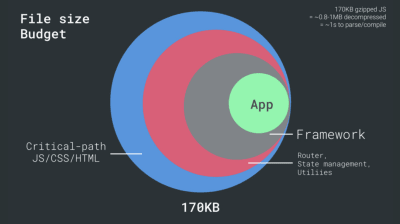
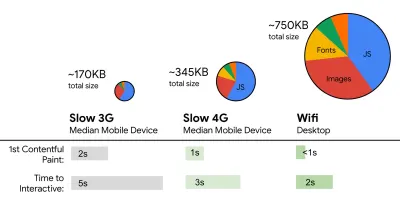
- FID < 100 ms, LCP < 2,5 s, TTI < 5 s en 3G, presupuesto de tamaño de archivo crítico < 170 KB (comprimido con gzip).
Aunque puede ser muy difícil de lograr, un buen objetivo final sería el tiempo para interactuar con menos de 5 años, y para las visitas repetidas, apuntar a menos de 2 años (alcanzable solo con un trabajador de servicio). Apunte a la pintura con contenido más grande de menos de 2,5 segundos y minimice el tiempo de bloqueo total y el cambio de diseño acumulativo . Un retardo de primera entrada aceptable es de menos de 100 ms a 70 ms. Como se mencionó anteriormente, estamos considerando que la línea base es un teléfono Android de $200 (por ejemplo, Moto G4) en una red 3G lenta, emulada a 400ms RTT y 400kbps de velocidad de transferencia.Tenemos dos restricciones principales que dan forma de manera efectiva a un objetivo razonable para la entrega rápida del contenido en la web. Por un lado, tenemos restricciones de entrega de red debido al inicio lento de TCP. Los primeros 14 KB del HTML (10 paquetes TCP, cada uno de 1460 bytes, que suman alrededor de 14,25 KB, aunque no debe tomarse literalmente) es el fragmento de carga útil más crítico y la única parte del presupuesto que se puede entregar en el primer viaje de ida y vuelta ( que es todo lo que obtienes en 1 segundo a 400 ms RTT debido a los tiempos de activación del móvil).

Con las conexiones TCP, comenzamos con una pequeña ventana de congestión y la duplicamos para cada viaje de ida y vuelta. En el primer viaje de ida y vuelta, caben 14 KB. De: Redes de navegador de alto rendimiento por Ilya Grigorik. (Vista previa grande) ( Nota : como TCP generalmente infrautiliza la conexión de red en una cantidad significativa, Google ha desarrollado TCP Bottleneck Bandwidth and RRT ( BBR ), un algoritmo de control de flujo TCP controlado por retardo. Diseñado para la web moderna, responde a la congestión real, en lugar de pérdida de paquetes como lo hace TCP, es significativamente más rápido, con mayor rendimiento y menor latencia, y el algoritmo funciona de manera diferente ( ¡gracias, Victor, Barry! )
Por otro lado, tenemos restricciones de hardware en la memoria y la CPU debido al análisis de JavaScript y los tiempos de ejecución (hablaremos de ello en detalle más adelante). Para lograr los objetivos establecidos en el primer párrafo, debemos considerar el presupuesto de tamaño de archivo crítico para JavaScript. Las opiniones varían sobre cuál debería ser ese presupuesto (y depende en gran medida de la naturaleza de su proyecto), pero un presupuesto de 170 KB de JavaScript ya comprimido tomaría hasta 1 segundo para analizar y compilar en un teléfono de gama media. Suponiendo que 170 KB se expanda a 3 veces ese tamaño cuando se descomprime (0,7 MB), eso ya podría ser la sentencia de muerte de una experiencia de usuario "decente" en un Moto G4/G5 Plus.
En el caso del sitio web de Wikipedia, en 2020, a nivel mundial, la ejecución del código se ha vuelto un 19 % más rápida para los usuarios de Wikipedia. Por lo tanto, si sus métricas de rendimiento web año tras año se mantienen estables, eso suele ser una señal de advertencia, ya que en realidad está retrocediendo a medida que el entorno sigue mejorando (detalles en una publicación de blog de Gilles Dubuc).
Si desea apuntar a mercados en crecimiento como el Sudeste Asiático, África o India, tendrá que considerar un conjunto muy diferente de limitaciones. Addy Osmani cubre las principales limitaciones de los teléfonos básicos, como pocos dispositivos de alta calidad y bajo costo, la falta de disponibilidad de redes de alta calidad y datos móviles costosos, junto con el presupuesto PRPL-30 y las pautas de desarrollo para estos entornos.
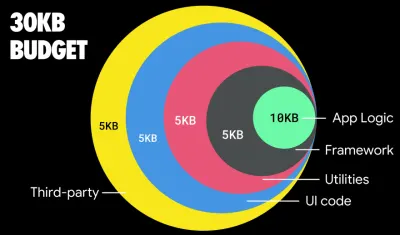
Según Addy Osmani, un tamaño recomendado para las rutas con carga diferida también es inferior a 35 KB. (Vista previa grande) 
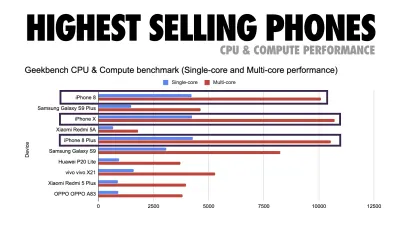
Addy Osmani sugiere un presupuesto de rendimiento PRPL-30 (30 KB comprimidos con gzip + paquete inicial minimizado) si se dirige a un teléfono con funciones. (Vista previa grande) De hecho, Alex Russell de Google recomienda apuntar a 130-170 KB comprimidos con gzip como un límite superior razonable. En escenarios del mundo real, la mayoría de los productos ni siquiera están cerca: el tamaño promedio de un paquete hoy en día es de alrededor de 452 KB, lo que representa un aumento del 53,6 % en comparación con principios de 2015. En un dispositivo móvil de clase media, eso representa entre 12 y 20 segundos para Time -A-Interactivo .
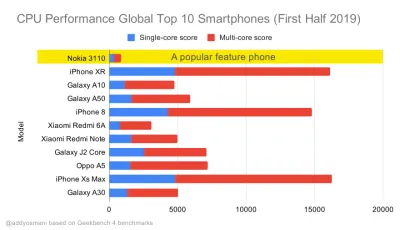
Puntos de referencia de rendimiento de CPU de Geekbench para los teléfonos inteligentes más vendidos a nivel mundial en 2019. JavaScript enfatiza el rendimiento de un solo núcleo (recuerde, es inherentemente más de un solo subproceso que el resto de la plataforma web) y está vinculado a la CPU. Del artículo de Addy "Carga rápida de páginas web en un teléfono con funciones de $20". (Vista previa grande) Sin embargo, también podríamos ir más allá del presupuesto del tamaño del paquete. Por ejemplo, podríamos establecer presupuestos de rendimiento en función de las actividades del subproceso principal del navegador, es decir, el tiempo de pintura antes de comenzar a renderizar o rastrear los acaparamientos de CPU de front-end. Herramientas como Calibre, SpeedCurve y Bundlesize pueden ayudarlo a mantener sus presupuestos bajo control y pueden integrarse en su proceso de creación.
Finalmente, un presupuesto de rendimiento probablemente no debería ser un valor fijo . Dependiendo de la conexión de red, los presupuestos de rendimiento deberían adaptarse, pero la carga útil en una conexión más lenta es mucho más "cara", independientemente de cómo se usen.
Nota : Puede sonar extraño establecer presupuestos tan rígidos en tiempos de HTTP/2 generalizado, 5G y HTTP/3 próximos, teléfonos móviles en rápida evolución y SPA florecientes. Sin embargo, suenan razonables cuando nos ocupamos de la naturaleza impredecible de la red y el hardware, que incluye todo, desde redes congestionadas hasta infraestructura de lento desarrollo, límites de datos, navegadores proxy, modo de ahorro de datos y cargos furtivos de roaming.
Definición del entorno
- Elija y configure sus herramientas de compilación.
No prestes demasiada atención a lo que supuestamente está de moda en estos días. Cíñete a tu entorno para construir, ya sea Grunt, Gulp, Webpack, Parcel o una combinación de herramientas. Mientras obtenga los resultados que necesita y no tenga problemas para mantener su proceso de compilación, lo estará haciendo bien.Entre las herramientas de compilación, Rollup sigue ganando terreno, al igual que Snowpack, pero Webpack parece ser la más establecida, con literalmente cientos de complementos disponibles para optimizar el tamaño de sus compilaciones. Esté atento a la hoja de ruta de Webpack 2021.
Una de las estrategias más notables que apareció recientemente es la fragmentación granular con Webpack en Next.js y Gatsby para minimizar el código duplicado. Por defecto, los módulos que no se comparten en todos los puntos de entrada se pueden solicitar para las rutas que no lo utilizan. Esto termina convirtiéndose en una sobrecarga ya que se descarga más código del necesario. Con la fragmentación granular en Next.js, podemos usar un archivo de manifiesto de compilación del lado del servidor para determinar qué fragmentos de salida utilizan los diferentes puntos de entrada.
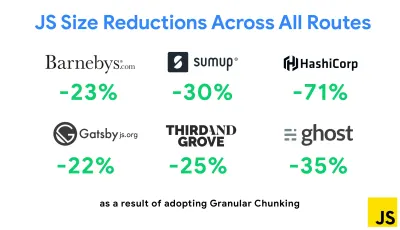
Para reducir el código duplicado en los proyectos de Webpack, podemos usar la fragmentación granular, habilitada en Next.js y Gatsby de manera predeterminada. Crédito de la imagen: Addy Osmani. (Vista previa grande) Con SplitChunksPlugin, se crean varios fragmentos divididos en función de una serie de condiciones para evitar obtener código duplicado en varias rutas. Esto mejora el tiempo de carga de la página y el almacenamiento en caché durante las navegaciones. Enviado en Next.js 9.2 y en Gatsby v2.20.7.
Sin embargo, comenzar con Webpack puede ser difícil. Entonces, si desea sumergirse en Webpack, existen algunos recursos excelentes:
- La documentación de Webpack, obviamente, es un buen punto de partida, al igual que Webpack: The Confusing Bits de Raja Rao y An Annotated Webpack Config de Andrew Welch.
- Sean Larkin tiene un curso gratuito sobre Webpack: The Core Concepts y Jeffrey Way ha lanzado un fantástico curso gratuito sobre Webpack para todos. Ambos son excelentes introducciones para sumergirse en Webpack.
- Webpack Fundamentals es un curso muy completo de 4 horas con Sean Larkin, publicado por FrontendMasters.
- Los ejemplos de Webpack tienen cientos de configuraciones de Webpack listas para usar, clasificadas por tema y propósito. Bonificación: también hay un configurador de configuración de Webpack que genera un archivo de configuración básico.
- awesome-webpack es una lista seleccionada de útiles recursos, bibliotecas y herramientas de Webpack, incluidos artículos, videos, cursos, libros y ejemplos para proyectos Angular, React y sin marco.
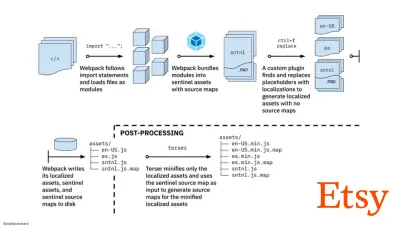
- El viaje hacia compilaciones de activos de producción rápida con Webpack es el estudio de caso de Etsy sobre cómo el equipo pasó de usar un sistema de compilación de JavaScript basado en RequireJS a usar Webpack y cómo optimizaron sus compilaciones, administrando más de 13 200 activos en 4 minutos en promedio.
- Los consejos de rendimiento de Webpack son una mina de oro de Ivan Akulov, que presenta muchos consejos centrados en el rendimiento, incluidos los que se centran específicamente en Webpack.
- impresionante-webpack-perf es un repositorio de GitHub de mina de oro con útiles herramientas y complementos de Webpack para el rendimiento. También mantenido por Ivan Akulov.
- Utilice la mejora progresiva como opción predeterminada.
Aun así, después de todos estos años, mantener la mejora progresiva como el principio rector de la implementación y la arquitectura de front-end es una apuesta segura. Primero diseñe y cree la experiencia central y luego mejore la experiencia con funciones avanzadas para navegadores compatibles, creando experiencias resilientes. Si su sitio web se ejecuta rápido en una máquina lenta con una pantalla deficiente en un navegador deficiente en una red subóptima, solo se ejecutará más rápido en una máquina rápida con un buen navegador en una red decente.De hecho, con el servicio de módulos adaptativos, parece que estamos llevando la mejora progresiva a otro nivel, brindando experiencias básicas "ligeras" a dispositivos de gama baja y mejorando con funciones más sofisticadas para dispositivos de gama alta. No es probable que la mejora progresiva desaparezca pronto.
- Elija una base de referencia de rendimiento sólida.
Con tantas incógnitas que afectan la carga: la red, el estrangulamiento térmico, el desalojo de caché, scripts de terceros, patrones de bloqueo del analizador, E/S de disco, latencia de IPC, extensiones instaladas, software antivirus y firewalls, tareas de CPU en segundo plano, restricciones de hardware y memoria, diferencias en el almacenamiento en caché L2/L3, RTTS: JavaScript tiene el costo más alto de la experiencia, junto con las fuentes web que bloquean el procesamiento de forma predeterminada y las imágenes que a menudo consumen demasiada memoria. Con los cuellos de botella de rendimiento alejándose del servidor al cliente, como desarrolladores, tenemos que considerar todas estas incógnitas con mucho más detalle.Con un presupuesto de 170 KB que ya contiene la ruta crítica HTML/CSS/JavaScript, el enrutador, la administración de estado, las utilidades, el marco y la lógica de la aplicación, tenemos que examinar minuciosamente el costo de transferencia de la red, el tiempo de análisis/compilación y el costo del tiempo de ejecución. del marco de nuestra elección. Afortunadamente, hemos visto una gran mejora en los últimos años en la rapidez con la que los navegadores pueden analizar y compilar scripts. Sin embargo, la ejecución de JavaScript sigue siendo el principal cuello de botella, por lo que prestar mucha atención al tiempo de ejecución del script y la red puede tener un impacto.
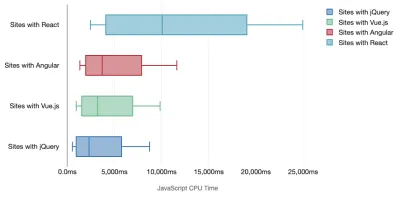
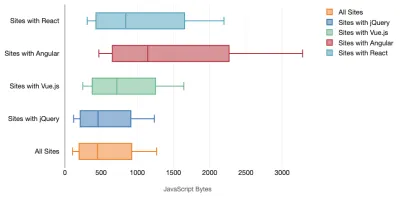
Tim Kadlec realizó una investigación fantástica sobre el rendimiento de los marcos modernos y los resumió en el artículo "Los marcos de JavaScript tienen un costo". A menudo hablamos sobre el impacto de los marcos independientes, pero como señala Tim, en la práctica, no es raro tener múltiples marcos en uso . Tal vez una versión anterior de jQuery que se está migrando lentamente a un marco moderno, junto con algunas aplicaciones heredadas que usan una versión anterior de Angular. Por lo tanto, es más razonable explorar el costo acumulativo de los bytes de JavaScript y el tiempo de ejecución de la CPU que pueden hacer que las experiencias de los usuarios sean apenas utilizables, incluso en dispositivos de gama alta.
En general, los marcos modernos no dan prioridad a los dispositivos menos potentes , por lo que las experiencias en un teléfono y en una computadora de escritorio a menudo serán dramáticamente diferentes en términos de rendimiento. Según la investigación, los sitios con React o Angular pasan más tiempo en la CPU que otros (lo que, por supuesto, no significa necesariamente que React sea más costoso en la CPU que Vue.js).
Según Tim, una cosa es obvia: "si está utilizando un marco para construir su sitio, está haciendo una compensación en términos de rendimiento inicial , incluso en el mejor de los escenarios".
- Evaluar marcos y dependencias.
Ahora, no todos los proyectos necesitan un marco y no todas las páginas de una aplicación de una sola página necesitan cargar un marco. En el caso de Netflix, "al eliminar React, varias bibliotecas y el código de la aplicación correspondiente del lado del cliente se redujo la cantidad total de JavaScript en más de 200 KB, lo que provocó una reducción de más del 50 % en el tiempo de interactividad de Netflix para la página de inicio sin sesión. ." Luego, el equipo utilizó el tiempo que los usuarios pasaban en la página de destino para precargar React para las páginas posteriores a las que los usuarios probablemente llegarían (siga leyendo para obtener más detalles).Entonces, ¿qué pasa si elimina por completo un marco existente en páginas críticas? Con Gatsby, puede verificar gatsby-plugin-no-javascript que elimina todos los archivos JavaScript creados por Gatsby de los archivos HTML estáticos. En Vercel, también puede permitir la desactivación de JavaScript en tiempo de ejecución en producción para ciertas páginas (experimental).
Una vez que se elige un marco, nos quedaremos con él durante al menos unos años, por lo que si necesitamos usar uno, debemos asegurarnos de que nuestra elección esté informada y bien considerada, y eso se aplica especialmente a las métricas de rendimiento clave que necesitamos. preocuparse.
Los datos muestran que, de forma predeterminada, los marcos son bastante caros: el 58,6 % de las páginas de React envían más de 1 MB de JavaScript, y el 36 % de las cargas de páginas de Vue.js tienen una primera pintura con contenido de <1,5 s. Según un estudio de Ankur Sethi, "su aplicación React nunca se cargará más rápido que aproximadamente 1,1 segundos en un teléfono promedio en la India, sin importar cuánto la optimice. Su aplicación Angular siempre tardará al menos 2,7 segundos en iniciarse. los usuarios de su aplicación Vue deberán esperar al menos 1 segundo antes de poder comenzar a usarla". Es posible que no tenga como objetivo la India como su mercado principal de todos modos, pero los usuarios que accedan a su sitio con condiciones de red subóptimas tendrán una experiencia comparable.
Por supuesto, es posible hacer que los SPA sean rápidos, pero no son rápidos desde el primer momento, por lo que debemos tener en cuenta el tiempo y el esfuerzo necesarios para hacerlos y mantenerlos rápidos. Probablemente será más fácil elegir un costo de rendimiento de referencia ligero desde el principio.
Entonces, ¿cómo elegimos un marco ? Es una buena idea considerar al menos el costo total del tamaño + los tiempos iniciales de ejecución antes de elegir una opción; las opciones ligeras como Preact, Inferno, Vue, Svelte, Alpine o Polymer pueden hacer el trabajo perfectamente. El tamaño de su línea base definirá las restricciones para el código de su aplicación.
Como señaló Seb Markbage, una buena manera de medir los costos iniciales de los marcos es primero renderizar una vista, luego eliminarla y luego volver a renderizar, ya que puede indicarle cómo se escala el marco. El primer renderizado tiende a calentar un montón de código compilado perezosamente, del cual un árbol más grande puede beneficiarse cuando escala. El segundo renderizado es básicamente una emulación de cómo la reutilización del código en una página afecta las características de rendimiento a medida que la página crece en complejidad.
Puede ir tan lejos como para evaluar a sus candidatos (o cualquier biblioteca de JavaScript en general) en el sistema de puntuación de escala de 12 puntos de Sacha Greif explorando características, accesibilidad, estabilidad, rendimiento, ecosistema de paquetes , comunidad, curva de aprendizaje, documentación, herramientas, historial , equipo, compatibilidad, seguridad por ejemplo.
Perf Track realiza un seguimiento del rendimiento del marco a escala. (Vista previa grande) También puede confiar en los datos recopilados en la web durante un período de tiempo más largo. Por ejemplo, Perf Track realiza un seguimiento del rendimiento del marco a escala, mostrando puntuaciones de Core Web Vitals agregadas por origen para sitios web creados en Angular, React, Vue, Polymer, Preact, Ember, Svelte y AMP. Incluso puede especificar y comparar sitios web creados con Gatsby, Next.js o Create React App, así como sitios web creados con Nuxt.js (Vue) o Sapper (Svelte).
Un buen punto de partida es elegir una buena pila predeterminada para su aplicación. Gatsby (React), Next.js (React), Vuepress (Vue), Preact CLI y PWA Starter Kit proporcionan valores predeterminados razonables para una carga rápida lista para usar en hardware móvil promedio. Además, eche un vistazo a la guía de rendimiento específica del marco web.dev para React y Angular ( ¡gracias, Phillip! ).
Y tal vez podría adoptar un enfoque un poco más refrescante para crear aplicaciones de una sola página: Turbolinks, una biblioteca de JavaScript de 15 KB que usa HTML en lugar de JSON para representar las vistas. Entonces, cuando sigue un enlace, Turbolinks busca automáticamente la página, intercambia su
<body>y fusiona su<head>, todo sin incurrir en el costo de una carga completa de la página. Puede consultar detalles rápidos y documentación completa sobre la pila (Hotwire).
- ¿Representación del lado del cliente o representación del lado del servidor? ¡Ambas cosas!
Esa es una conversación bastante acalorada. El enfoque final sería configurar algún tipo de arranque progresivo: use la representación del lado del servidor para obtener una primera pintura con contenido rápida, pero también incluya un mínimo de JavaScript necesario para mantener el tiempo de interacción cerca de la primera pintura con contenido. Si JavaScript llega demasiado tarde después del FCP, el navegador bloqueará el hilo principal mientras analiza, compila y ejecuta JavaScript descubierto tarde, por lo tanto, limita la interactividad del sitio o la aplicación.Para evitarlo, siempre divida la ejecución de funciones en tareas asíncronas separadas y, cuando sea posible, use
requestIdleCallback. Considere la carga diferida de partes de la interfaz de usuario utilizando el soporte deimport()de WebPack, evitando el costo de carga, análisis y compilación hasta que los usuarios realmente los necesiten ( ¡gracias Addy! ).Como se mencionó anteriormente, Time to Interactive (TTI) nos dice el tiempo entre la navegación y la interactividad. En detalle, la métrica se define mirando la primera ventana de cinco segundos después de que se representa el contenido inicial, en la que ninguna tarea de JavaScript tarda más de 50 ms ( Tareas largas ). Si se produce una tarea de más de 50 ms, la búsqueda de una ventana de cinco segundos comienza de nuevo. Como resultado, el navegador primero asumirá que llegó a Interactive , solo para cambiar a Frozen , solo para eventualmente volver a cambiar a Interactive .
Una vez que llegamos a Interactivo , podemos, ya sea a pedido o según lo permita el tiempo, iniciar partes no esenciales de la aplicación. Desafortunadamente, como notó Paul Lewis, los marcos generalmente no tienen un concepto simple de prioridad que se pueda mostrar a los desarrolladores y, por lo tanto, el arranque progresivo no es fácil de implementar con la mayoría de las bibliotecas y marcos.
Aún así, estamos llegando allí. En estos días hay un par de opciones que podemos explorar, y Houssein Djirdeh y Jason Miller brindan una excelente descripción general de estas opciones en su charla sobre Rendering on the Web y el artículo de Jason y Addy sobre Modern Front-End Architectures. La descripción general a continuación se basa en su trabajo estelar.
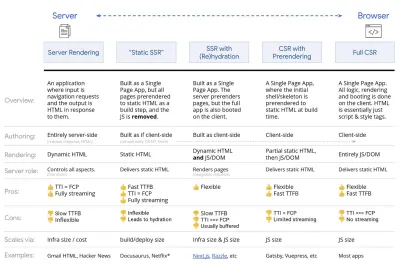
- Representación completa del lado del servidor (SSR)
En SSR clásico, como WordPress, todas las solicitudes se manejan completamente en el servidor. El contenido solicitado se devuelve como una página HTML terminada y los navegadores pueden procesarlo de inmediato. Por lo tanto, las aplicaciones SSR no pueden realmente hacer uso de las API DOM, por ejemplo. La brecha entre First Contentful Paint y Time to Interactive suele ser pequeña, y la página se puede representar de inmediato a medida que HTML se transmite al navegador.Esto evita viajes de ida y vuelta adicionales para obtener datos y crear plantillas en el cliente, ya que se maneja antes de que el navegador obtenga una respuesta. Sin embargo, terminamos con un tiempo de reflexión del servidor más largo y, en consecuencia, Tiempo hasta el primer byte y no hacemos uso de las características ricas y receptivas de las aplicaciones modernas.
- Representación estática
Creamos el producto como una aplicación de una sola página, pero todas las páginas se procesan previamente en HTML estático con JavaScript mínimo como paso de creación. Eso significa que con el renderizado estático, producimos archivos HTML individuales para cada URL posible con anticipación, algo que no muchas aplicaciones pueden permitirse. Pero debido a que el código HTML de una página no tiene que generarse sobre la marcha, podemos lograr un tiempo hasta el primer byte consistentemente rápido. Por lo tanto, podemos mostrar una página de destino rápidamente y luego precargar un marco SPA para las páginas posteriores. Netflix ha adoptado este enfoque para reducir la carga y el tiempo de interacción en un 50 %. - Renderización del lado del servidor con (re)hidratación (representación universal, SSR + CSR)
Podemos tratar de usar lo mejor de ambos mundos: los enfoques SSR y CSR. Con la hidratación en la mezcla, la página HTML devuelta por el servidor también contiene un script que carga una aplicación completa del lado del cliente. Idealmente, eso logra una primera pintura con contenido rápida (como SSR) y luego continúa renderizando con (re) hidratación. Desafortunadamente, ese es raramente el caso. Más a menudo, la página parece lista pero no puede responder a la entrada del usuario, lo que produce clics de rabia y abandonos.Con React, podemos usar el módulo
ReactDOMServeren un servidor Node como Express y luego llamar al métodorenderToStringpara representar los componentes de nivel superior como una cadena HTML estática.Con Vue.js, podemos usar vue-server-renderer para representar una instancia de Vue en HTML usando
renderToString. En Angular, podemos usar@nguniversalpara convertir las solicitudes de los clientes en páginas HTML totalmente procesadas por el servidor. También se puede lograr una experiencia completamente renderizada en el servidor desde el primer momento con Next.js (React) o Nuxt.js (Vue).El enfoque tiene sus desventajas. Como resultado, obtenemos una flexibilidad total de las aplicaciones del lado del cliente al mismo tiempo que brindamos una representación más rápida del lado del servidor, pero también terminamos con una brecha más larga entre la primera pintura con contenido y el tiempo para la interacción y un mayor retraso de la primera entrada. La rehidratación es muy costosa y, por lo general, esta estrategia por sí sola no será lo suficientemente buena, ya que retrasa mucho el tiempo de interacción.
- Streaming del lado del servidor con hidratación progresiva (SSR + CSR)
Para minimizar la brecha entre Time To Interactive y First Contentful Paint, procesamos varias solicitudes a la vez y enviamos contenido en fragmentos a medida que se generan. Por lo tanto, no tenemos que esperar la cadena completa de HTML antes de enviar contenido al navegador y, por lo tanto, mejorar el tiempo hasta el primer byte.En React, en lugar de
renderToString(), podemos usar renderToNodeStream() para canalizar la respuesta y enviar el HTML en fragmentos. En Vue, podemos usar renderToStream() que se puede canalizar y transmitir. Con React Suspense, también podríamos usar el renderizado asíncrono para ese propósito.En el lado del cliente, en lugar de iniciar toda la aplicación a la vez, iniciamos los componentes progresivamente . Las secciones de las aplicaciones se dividen primero en secuencias de comandos independientes con división de código y luego se hidratan gradualmente (en orden de nuestras prioridades). De hecho, podemos hidratar los componentes críticos primero, mientras que el resto podría hidratarse más tarde. La función de representación del lado del cliente y del lado del servidor se puede definir de manera diferente por componente. Luego, también podemos diferir la hidratación de algunos componentes hasta que estén a la vista, o sean necesarios para la interacción del usuario, o cuando el navegador esté inactivo.
Para Vue, Markus Oberlehner ha publicado una guía sobre cómo reducir el tiempo de interacción de las aplicaciones SSR utilizando la hidratación en la interacción del usuario, así como vue-lazy-hydration, un complemento de etapa inicial que permite la hidratación de los componentes en la visibilidad o la interacción específica del usuario. El equipo de Angular trabaja en la hidratación progresiva con Ivy Universal. También puede implementar la hidratación parcial con Preact y Next.js.
- Representación trisomórfica
Con los trabajadores del servicio en su lugar, podemos usar la representación del servidor de transmisión para navegaciones iniciales/no JS, y luego hacer que el trabajador del servicio asuma la representación de HTML para las navegaciones después de que se haya instalado. En ese caso, el trabajador del servicio renderiza previamente el contenido y habilita las navegaciones de estilo SPA para renderizar nuevas vistas en la misma sesión. Funciona bien cuando puede compartir la misma plantilla y código de enrutamiento entre el servidor, la página del cliente y el trabajador del servicio.
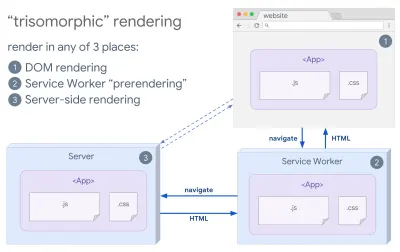
Representación trisomórfica, con la misma representación de código en 3 lugares cualquiera: en el servidor, en el DOM o en un trabajador de servicio. (Fuente de la imagen: Google Developers) (Vista previa grande) - CSR con representación previa
La renderización previa es similar a la renderización del lado del servidor, pero en lugar de renderizar páginas en el servidor dinámicamente, renderizamos la aplicación en HTML estático en el momento de la compilación. Si bien las páginas estáticas son completamente interactivas sin mucho JavaScript del lado del cliente, la representación previa funciona de manera diferente . Básicamente, captura el estado inicial de una aplicación del lado del cliente como HTML estático en el momento de la compilación, mientras que con la representación previa, la aplicación debe iniciarse en el cliente para que las páginas sean interactivas.Con Next.js, podemos usar la exportación de HTML estático prerenderizando una aplicación en HTML estático. En Gatsby, un generador de sitios estáticos de código abierto que usa React, usa el método
renderToStaticMarkupen lugar del métodorenderToStringdurante las compilaciones, con el fragmento JS principal precargado y las rutas futuras precargadas, sin atributos DOM que no son necesarios para páginas estáticas simples.Para Vue, podemos usar Vuepress para lograr el mismo objetivo. También puede usar prerender-loader con Webpack. Navi también proporciona renderizado estático.
El resultado es un mejor tiempo para el primer byte y la primera pintura con contenido, y reducimos la brecha entre el tiempo para la interacción y la primera pintura con contenido. No podemos usar el enfoque si se espera que el contenido cambie mucho. Además, todas las URL deben conocerse con anticipación para generar todas las páginas. Por lo tanto, algunos componentes pueden renderizarse mediante renderizado previo, pero si necesitamos algo dinámico, tenemos que confiar en la aplicación para obtener el contenido.
- Representación completa del lado del cliente (CSR)
Toda la lógica, el renderizado y el arranque se realizan en el cliente. El resultado suele ser una gran brecha entre Time To Interactive y First Contentful Paint. Como resultado, las aplicaciones a menudo se sienten lentas , ya que toda la aplicación debe iniciarse en el cliente para generar cualquier cosa.Como JavaScript tiene un costo de rendimiento, a medida que la cantidad de JavaScript crece con una aplicación, la división de código agresiva y el aplazamiento de JavaScript serán absolutamente necesarios para controlar el impacto de JavaScript. Para tales casos, una representación del lado del servidor generalmente será un mejor enfoque en caso de que no se requiera mucha interactividad. Si no es una opción, considere usar The App Shell Model.
En general, SSR es más rápido que CSR. Sin embargo, es una implementación bastante frecuente para muchas aplicaciones.
Entonces, ¿del lado del cliente o del lado del servidor? En general, es una buena idea limitar el uso de marcos completamente del lado del cliente a páginas que los requieran absolutamente. Para aplicaciones avanzadas, tampoco es una buena idea confiar solo en el renderizado del lado del servidor. Tanto la representación del servidor como la representación del cliente son un desastre si se hacen mal.
Ya sea que se incline por CSR o SSR, asegúrese de renderizar los píxeles importantes lo antes posible y minimice la brecha entre ese renderizado y el tiempo de interacción. Considere la posibilidad de renderizar previamente si sus páginas no cambian mucho, y posponga el inicio de los marcos si puede. Transmita HTML en fragmentos con renderizado del lado del servidor e implemente una hidratación progresiva para el renderizado del lado del cliente, e hidrátese en la visibilidad, la interacción o durante el tiempo de inactividad para obtener lo mejor de ambos mundos.
- Representación completa del lado del servidor (SSR)

- ¿Cuánto podemos servir de forma estática?
Ya sea que esté trabajando en una aplicación grande o en un sitio pequeño, vale la pena considerar qué contenido podría servirse estáticamente desde un CDN (es decir, JAM Stack), en lugar de generarse dinámicamente sobre la marcha. Incluso si tiene miles de productos y cientos de filtros con muchas opciones de personalización, es posible que desee publicar sus páginas de destino críticas de forma estática y desvincular estas páginas del marco de su elección.Hay muchos generadores de sitios estáticos y las páginas que generan suelen ser muy rápidas. The more content we can pre-build ahead of time instead of generating page views on a server or client at request time, the better performance we will achieve.
In Building Partially Hydrated, Progressively Enhanced Static Websites, Markus Oberlehner shows how to build out websites with a static site generator and an SPA, while achieving progressive enhancement and a minimal JavaScript bundle size. Markus uses Eleventy and Preact as his tools, and shows how to set up the tools, add partial hydration, lazy hydration, client entry file, configure Babel for Preact and bundle Preact with Rollup — from start to finish.
With JAMStack used on large sites these days, a new performance consideration appeared: the build time . In fact, building out even thousands of pages with every new deploy can take minutes, so it's promising to see incremental builds in Gatsby which improve build times by 60 times , with an integration into popular CMS solutions like WordPress, Contentful, Drupal, Netlify CMS and others.
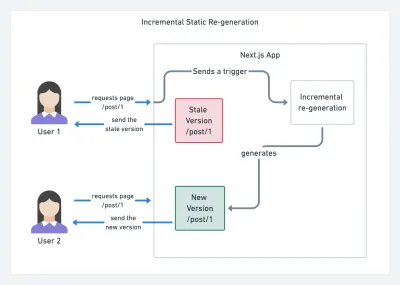
Incremental static regeneration with Next.js. (Image credit: Prisma.io) (Large preview) Also, Next.js announced ahead-of-time and incremental static generation, which allows us to add new static pages at runtime and update existing pages after they've been already built, by re-rendering them in the background as traffic comes in.
Need an even more lightweight approach? In his talk on Eleventy, Alpine and Tailwind: towards a lightweight Jamstack, Nicola Goutay explains the differences between CSR, SSR and everything-in-between, and shows how to use a more lightweight approach — along with a GitHub repo that shows the approach in practice.
- Consider using PRPL pattern and app shell architecture.
Different frameworks will have different effects on performance and will require different strategies of optimization, so you have to clearly understand all of the nuts and bolts of the framework you'll be relying on. When building a web app, look into the PRPL pattern and application shell architecture. The idea is quite straightforward: Push the minimal code needed to get interactive for the initial route to render quickly, then use service worker for caching and pre-caching resources and then lazy-load routes that you need, asynchronously.
- Have you optimized the performance of your APIs?
APIs are communication channels for an application to expose data to internal and third-party applications via endpoints . When designing and building an API, we need a reasonable protocol to enable the communication between the server and third-party requests. Representational State Transfer ( REST ) is a well-established, logical choice: it defines a set of constraints that developers follow to make content accessible in a performant, reliable and scalable fashion. Web services that conform to the REST constraints, are called RESTful web services .As with good ol' HTTP requests, when data is retrieved from an API, any delay in server response will propagate to the end user, hence delaying rendering . When a resource wants to retrieve some data from an API, it will need to request the data from the corresponding endpoint. A component that renders data from several resources, such as an article with comments and author photos in each comment, may need several roundtrips to the server to fetch all the data before it can be rendered. Furthermore, the amount of data returned through REST is often more than what is needed to render that component.
If many resources require data from an API, the API might become a performance bottleneck. GraphQL provides a performant solution to these issues. Per se, GraphQL is a query language for your API, and a server-side runtime for executing queries by using a type system you define for your data. Unlike REST, GraphQL can retrieve all data in a single request , and the response will be exactly what is required, without over or under -fetching data as it typically happens with REST.
In addition, because GraphQL is using schema (metadata that tells how the data is structured), it can already organize data into the preferred structure, so, for example, with GraphQL, we could remove JavaScript code used for dealing with state management, producing a cleaner application code that runs faster on the client.
If you want to get started with GraphQL or encounter performance issues, these articles might be quite helpful:
- A GraphQL Primer: Why We Need A New Kind Of API by Eric Baer,
- A GraphQL Primer: The Evolution Of API Design by Eric Baer,
- Designing a GraphQL server for optimal performance by Leonardo Losoviz,
- GraphQL performance explained by Wojciech Trocki.
- Will you be using AMP or Instant Articles?
Depending on the priorities and strategy of your organization, you might want to consider using Google's AMP or Facebook's Instant Articles or Apple's Apple News. You can achieve good performance without them, but AMP does provide a solid performance framework with a free content delivery network (CDN), while Instant Articles will boost your visibility and performance on Facebook.The seemingly obvious benefit of these technologies for users is guaranteed performance , so at times they might even prefer AMP-/Apple News/Instant Pages-links over "regular" and potentially bloated pages. For content-heavy websites that are dealing with a lot of third-party content, these options could potentially help speed up render times dramatically.
Unless they don't. According to Tim Kadlec, for example, "AMP documents tend to be faster than their counterparts, but they don't necessarily mean a page is performant. AMP is not what makes the biggest difference from a performance perspective."
A benefit for the website owner is obvious: discoverability of these formats on their respective platforms and increased visibility in search engines.
Well, at least that's how it used to be. As AMP is no longer a requirement for Top Stories , publishers might be moving away from AMP to a traditional stack instead ( thanks, Barry! ).
Still, you could build progressive web AMPs, too, by reusing AMPs as a data source for your PWA. Downside? Obviously, a presence in a walled garden places developers in a position to produce and maintain a separate version of their content, and in case of Instant Articles and Apple News without actual URLs (thanks Addy, Jeremy!) .
- Choose your CDN wisely.
As mentioned above, depending on how much dynamic data you have, you might be able to "outsource" some part of the content to a static site generator, pushing it to a CDN and serving a static version from it, thus avoiding requests to the server. In fact, some of those generators are actually website compilers with many automated optimizations provided out of the box. As compilers add optimizations over time, the compiled output gets smaller and faster over time.Notice that CDNs can serve (and offload) dynamic content as well. So, restricting your CDN to static assets is not necessary. Double-check whether your CDN performs compression and conversion (eg image optimization and resizing at the edge), whether they provide support for servers workers, A/B testing, as well as edge-side includes, which assemble static and dynamic parts of pages at the CDN's edge (ie the server closest to the user), and other tasks. Also, check if your CDN supports HTTP over QUIC (HTTP/3).
Katie Hempenius has written a fantastic guide to CDNs that provides insights on how to choose a good CDN , how to finetune it and all the little things to keep in mind when evaluating one. In general, it's a good idea to cache content as aggressively as possible and enable CDN performance features like Brotli, TLS 1.3, HTTP/2, and HTTP/3.
Note : based on research by Patrick Meenan and Andy Davies, HTTP/2 prioritization is effectively broken on many CDNs, so be careful when choosing a CDN. Patrick has more details in his talk on HTTP/2 Prioritization ( thanks, Barry! ).
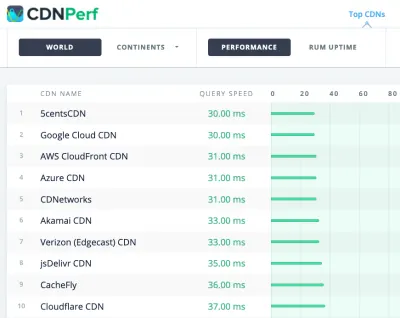
CDNPerf measures query speed for CDNs by gathering and analyzing 300 million tests every day. (Vista previa grande) When choosing a CDN, you can use these comparison sites with a detailed overview of their features:
- Comparación de CDN, una matriz de comparación de CDN para Cloudfront, Aazure, KeyCDN, Fastly, Verizon, Stackpach, Akamai y muchos otros.
- CDN Perf mide la velocidad de consulta de CDN recopilando y analizando 300 millones de pruebas todos los días, con todos los resultados basados en datos RUM de usuarios de todo el mundo. Consulte también la Comparación de rendimiento de DNS y la Comparación de rendimiento de la nube.
- CDN Planet Guides proporciona una descripción general de las CDN para temas específicos, como Servicio obsoleto, Purga, Escudo de origen, Prefetch y Compresión.
- Web Almanac: Adopción y uso de CDN brinda información sobre los principales proveedores de CDN, su administración de RTT y TLS, el tiempo de negociación de TLS, la adopción de HTTP/2 y otros. (Lamentablemente, los datos son solo de 2019).
Optimizaciones de activos
- Utilice Brotli para la compresión de texto sin formato.
En 2015, Google presentó Brotli, un nuevo formato de datos sin pérdidas de código abierto, que ahora es compatible con todos los navegadores modernos. La biblioteca Brotli de código abierto, que implementa un codificador y decodificador para Brotli, tiene 11 niveles de calidad predefinidos para el codificador, con un nivel de calidad más alto que exige más CPU a cambio de una mejor relación de compresión. Una compresión más lenta conducirá en última instancia a tasas de compresión más altas, pero aún así, Brotli se descomprime rápidamente. Sin embargo, vale la pena señalar que Brotli con el nivel de compresión 4 es más pequeño y se comprime más rápido que Gzip.En la práctica, Brotli parece ser mucho más efectivo que Gzip. Las opiniones y las experiencias difieren, pero si su sitio ya está optimizado con Gzip, es posible que espere mejoras de al menos un dígito y, en el mejor de los casos, mejoras de dos dígitos en la reducción de tamaño y los tiempos de FCP. También puede estimar los ahorros de compresión de Brotli para su sitio.
Los navegadores aceptarán Brotli solo si el usuario visita un sitio web a través de HTTPS. Brotli es ampliamente compatible y muchas CDN lo admiten (Akamai, Netlify Edge, AWS, KeyCDN, Fastly (actualmente solo como transferencia), Cloudflare, CDN77) y puede habilitar Brotli incluso en CDN que aún no lo admiten. (con un trabajador de servicio).
El problema es que debido a que comprimir todos los activos con Brotli a un alto nivel de compresión es costoso, muchos proveedores de alojamiento no pueden usarlo a gran escala solo por el enorme costo que genera. De hecho, en el nivel más alto de compresión, Brotli es tan lento que cualquier ganancia potencial en el tamaño del archivo podría verse anulada por la cantidad de tiempo que le toma al servidor comenzar a enviar la respuesta mientras espera para comprimir dinámicamente el activo. (Pero si tiene tiempo durante el tiempo de compilación con compresión estática, por supuesto, se prefieren configuraciones de compresión más altas).
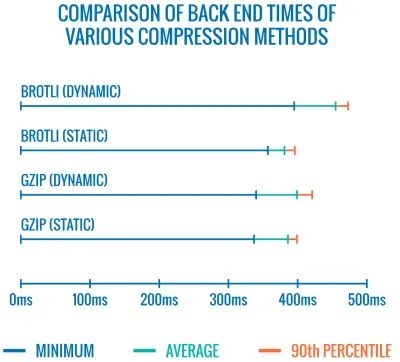
Comparación de los tiempos finales de varios métodos de compresión. Como era de esperar, Brotli es más lento que gzip (por ahora). (Vista previa grande) Aunque esto podría estar cambiando. El formato de archivo Brotli incluye un diccionario estático incorporado y, además de contener varias cadenas en varios idiomas, también admite la opción de aplicar múltiples transformaciones a esas palabras, lo que aumenta su versatilidad. En su investigación, Felix Hanau ha descubierto una manera de mejorar la compresión en los niveles 5 a 9 usando "un subconjunto más especializado del diccionario que el predeterminado" y confiando en el encabezado
Content-Typepara decirle al compresor si debe usar un diccionario para HTML, JavaScript o CSS. El resultado fue un "impacto insignificante en el rendimiento (1 % a 3 % más de CPU en comparación con el 12 % normal) al comprimir contenido web a altos niveles de compresión, utilizando un enfoque de uso de diccionario limitado".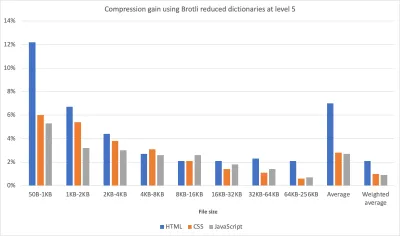
Con el enfoque de diccionario mejorado, podemos comprimir activos más rápido en niveles de compresión más altos, todo mientras usamos solo entre un 1 % y un 3 % más de CPU. Normalmente, el nivel de compresión 6 sobre 5 aumentaría el uso de la CPU hasta en un 12 %. (Vista previa grande) Además de eso, con la investigación de Elena Kirilenko, podemos lograr una recompresión de Brotli rápida y eficiente utilizando artefactos de compresión anteriores. Según Elena, "una vez que tenemos un activo comprimido a través de Brotli, y tratamos de comprimir contenido dinámico sobre la marcha, donde el contenido se parece al contenido disponible para nosotros con anticipación, podemos lograr mejoras significativas en los tiempos de compresión. "
¿Con qué frecuencia es el caso? Por ejemplo, con la entrega de subconjuntos de paquetes de JavaScript (por ejemplo, cuando partes del código ya están almacenadas en caché en el cliente o con paquetes dinámicos sirviendo con WebBundles). O con HTML dinámico basado en plantillas conocidas de antemano, o fuentes WOFF2 subdivididas dinámicamente . Según Elena, podemos obtener una mejora del 5,3 % en la compresión y una mejora del 39 % en la velocidad de compresión al eliminar el 10 % del contenido, y un 3,2 % de mejores tasas de compresión y una compresión un 26 % más rápida, al eliminar el 50 % del contenido.
La compresión de Brotli está mejorando, por lo que si puede evitar el costo de comprimir dinámicamente los activos estáticos, definitivamente vale la pena el esfuerzo. No hace falta decir que Brotli se puede usar para cualquier carga útil de texto sin formato: HTML, CSS, SVG, JavaScript, JSON, etc.
Nota : a principios de 2021, aproximadamente el 60 % de las respuestas HTTP se envían sin compresión basada en texto, con un 30,82 % comprimiendo con Gzip y un 9,1 % comprimiendo con Brotli (tanto en dispositivos móviles como en computadoras de escritorio). Por ejemplo, el 23,4 % de las páginas de Angular no están comprimidas (a través de gzip o Brotli). Sin embargo, a menudo activar la compresión es una de las victorias más fáciles para mejorar el rendimiento con solo presionar un interruptor.
¿La estrategia? Comprima previamente los activos estáticos con Brotli+Gzip en el nivel más alto y comprima HTML (dinámico) sobre la marcha con Brotli en el nivel 4–6. Asegúrese de que el servidor maneje la negociación de contenido para Brotli o Gzip correctamente.
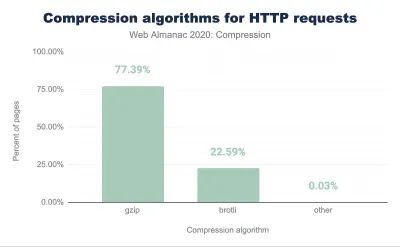
- ¿Utilizamos la carga de medios adaptativos y sugerencias de clientes?
Viene de la tierra de las noticias antiguas, pero siempre es un buen recordatorio para usar imágenes receptivas consrcset,sizesy el elemento<picture>. Especialmente para los sitios con una gran huella de medios, podemos ir un paso más allá con la carga de medios adaptativa (en este ejemplo, React + Next.js), brindando una experiencia liviana para redes lentas y dispositivos con poca memoria y una experiencia completa para redes rápidas y alta. -dispositivos de memoria. En el contexto de React, podemos lograrlo con sugerencias de clientes en el servidor y ganchos adaptativos de reacción en el cliente.El futuro de las imágenes receptivas podría cambiar drásticamente con la adopción más amplia de las sugerencias de los clientes. Las sugerencias del cliente son campos de encabezado de solicitud HTTP, por ejemplo,
DPR,Viewport-Width,Width,Save-Data,Accept(para especificar preferencias de formato de imagen) y otros. Se supone que deben informar al servidor sobre los detalles del navegador, la pantalla, la conexión, etc. del usuario.Como resultado, el servidor puede decidir cómo completar el diseño con imágenes del tamaño adecuado y servir solo estas imágenes en los formatos deseados. Con las sugerencias del cliente, movemos la selección de recursos del marcado HTML a la negociación de solicitud-respuesta entre el cliente y el servidor.
Servicio multimedia adaptable en uso. Enviamos un marcador de posición con texto a los usuarios que no están conectados, una imagen de baja resolución a los usuarios de 2G, una imagen de alta resolución a los usuarios de 3G y un video HD a los usuarios de 4G. A través de Cargar páginas web rápidamente en un teléfono con funciones de $20. (Vista previa grande) Como señaló Ilya Grigorik hace un tiempo, las sugerencias de los clientes completan la imagen: no son una alternativa a las imágenes receptivas. "El elemento
<picture>proporciona el control de dirección de arte necesario en el marcado HTML. Las sugerencias del cliente proporcionan anotaciones en las solicitudes de imágenes resultantes que permiten la automatización de la selección de recursos. Service Worker proporciona capacidades completas de gestión de solicitudes y respuestas en el cliente".Un trabajador de servicio podría, por ejemplo, agregar nuevos valores de encabezados de sugerencias de clientes a la solicitud, reescribir la URL y apuntar la solicitud de imagen a un CDN, adaptar la respuesta en función de la conectividad y las preferencias del usuario, etc. para casi todas las demás solicitudes también.
Para los clientes que admiten sugerencias de clientes, se podría medir un 42 % de ahorro de bytes en imágenes y 1 MB+ menos de bytes para el percentil 70+. En Smashing Magazine, también pudimos medir una mejora del 19 al 32 %. Las sugerencias de clientes son compatibles con los navegadores basados en Chromium, pero aún se están considerando en Firefox.
Sin embargo, si proporciona tanto el marcado de imágenes receptivas normales como la etiqueta
<meta>para Client Hints, entonces un navegador compatible evaluará el marcado de imágenes receptivas y solicitará la fuente de imagen adecuada utilizando los encabezados HTTP de Client Hints. - ¿Usamos imágenes receptivas para las imágenes de fondo?
¡Seguramente deberíamos! Conimage-set, ahora compatible con Safari 14 y con la mayoría de los navegadores modernos excepto Firefox, también podemos ofrecer imágenes de fondo receptivas:background-image: url("fallback.jpg"); background-image: image-set( "photo-small.jpg" 1x, "photo-large.jpg" 2x, "photo-print.jpg" 600dpi);Básicamente, podemos servir de forma condicional imágenes de fondo de baja resolución con un descriptor de
1xe imágenes de mayor resolución con un descriptor de2x, e incluso una imagen de calidad de impresión con un descriptor de600dpi. Sin embargo, tenga cuidado: los navegadores no brindan ninguna información especial sobre las imágenes de fondo para la tecnología de asistencia, por lo que, idealmente, estas fotos serían meramente decorativas. - ¿Usamos WebP?
La compresión de imágenes a menudo se considera una ganancia rápida, sin embargo, todavía está muy infrautilizada en la práctica. Por supuesto, las imágenes no bloquean el renderizado, pero contribuyen en gran medida a las bajas puntuaciones de LCP y, muy a menudo, son demasiado pesadas y demasiado grandes para el dispositivo en el que se consumen.Entonces, como mínimo, podríamos explorar el uso del formato WebP para nuestras imágenes. De hecho, la saga WebP estuvo llegando a su fin el año pasado cuando Apple agregó soporte para WebP en Safari 14. Entonces, después de muchos años de discusiones y debates, a partir de hoy, WebP es compatible con todos los navegadores modernos. Por lo tanto, podemos servir imágenes WebP con el elemento
<picture>y un respaldo JPEG si es necesario (consulte el fragmento de código de Andreas Bovens) o mediante la negociación de contenido (usando encabezados deAccept).Sin embargo, WebP no está exento de inconvenientes . Si bien los tamaños de archivo de imagen de WebP se comparan con Guetzli y Zopfli equivalentes, el formato no es compatible con la representación progresiva como JPEG, por lo que los usuarios pueden ver la imagen terminada más rápido con un buen JPEG, aunque las imágenes de WebP pueden ser más rápidas a través de la red. Con JPEG, podemos ofrecer una experiencia de usuario "decente" con la mitad o incluso la cuarta parte de los datos y cargar el resto más tarde, en lugar de tener una imagen medio vacía como en el caso de WebP.
Su decisión dependerá de lo que esté buscando: con WebP, reducirá la carga útil y con JPEG mejorará el rendimiento percibido. Puede obtener más información sobre WebP en WebP Rewind talk de Pascal Massimino de Google.
Para la conversión a WebP, puede usar WebP Converter, cwebp o libwebp. Ire Aderinokun también tiene un tutorial muy detallado sobre cómo convertir imágenes a WebP, al igual que Josh Comeau en su artículo sobre la adopción de formatos de imagen modernos.

Una charla completa sobre WebP: WebP Rewind de Pascal Massimino. (Vista previa grande) Sketch es compatible de forma nativa con WebP, y las imágenes de WebP se pueden exportar desde Photoshop utilizando un complemento de WebP para Photoshop. Pero también hay otras opciones disponibles.
Si está utilizando WordPress o Joomla, existen extensiones para ayudarlo a implementar fácilmente la compatibilidad con WebP, como Optimus y Cache Enabler para WordPress y la propia extensión compatible de Joomla (a través de Cody Arsenault). También puede abstraer el elemento
<picture>con React, componentes con estilo o gatsby-image.¡Ah, enchufe desvergonzado! — Jeremy Wagner incluso publicó un libro Smashing sobre WebP que tal vez desee consultar si está interesado en todo lo relacionado con WebP.
- ¿Utilizamos AVIF?
Es posible que haya escuchado la gran noticia: AVIF ha aterrizado. Es un nuevo formato de imagen derivado de los fotogramas clave del video AV1. Es un formato abierto y libre de regalías que admite compresión con pérdida y sin pérdida, animación, canal alfa con pérdida y puede manejar líneas nítidas y colores sólidos (que era un problema con JPEG), al tiempo que proporciona mejores resultados en ambos.De hecho, en comparación con WebP y JPEG, AVIF funciona significativamente mejor , lo que genera un ahorro de tamaño de archivo promedio de hasta un 50 % con el mismo DSSIM ((des)similitud entre dos o más imágenes usando un algoritmo que se aproxima a la visión humana). De hecho, en su publicación completa sobre la optimización de la carga de imágenes, Malte Ubl señala que AVIF "supera consistentemente a JPEG de una manera muy significativa. Esto es diferente de WebP, que no siempre produce imágenes más pequeñas que JPEG y en realidad puede ser una red. pérdida por falta de apoyo para la carga progresiva".

Podemos usar AVIF como una mejora progresiva, entregando WebP o JPEG o PNG a navegadores más antiguos. (Vista previa grande). Consulte la vista de texto sin formato a continuación. Irónicamente, AVIF puede funcionar incluso mejor que los SVG grandes, aunque, por supuesto, no debe verse como un reemplazo de los SVG. También es uno de los primeros formatos de imagen que admite soporte de color HDR; ofreciendo mayor brillo, profundidad de bits de color y gamas de colores. El único inconveniente es que actualmente AVIF no admite la decodificación progresiva de imágenes (¿todavía?) y, de manera similar a Brotli, una codificación de alta tasa de compresión actualmente es bastante lenta, aunque la decodificación es rápida.
Actualmente, AVIF es compatible con Chrome, Firefox y Opera, y se espera que pronto sea compatible con Safari (ya que Apple es miembro del grupo que creó AV1).
Entonces, ¿cuál es la mejor manera de publicar imágenes en estos días ? Para ilustraciones e imágenes vectoriales, SVG (comprimido) es sin duda la mejor opción. Para las fotos, usamos métodos de negociación de contenido con el elemento de
picture. Si se admite AVIF, enviamos una imagen AVIF; si no es el caso, primero recurrimos a WebP, y si WebP tampoco es compatible, cambiamos a JPEG o PNG como respaldo (aplicando las condiciones de@mediasi es necesario):<picture> <source type="image/avif"> <source type="image/webp"> <img src="image.jpg" alt="Photo" width="450" height="350"> </picture>Francamente, es más probable que usemos algunas condiciones dentro del elemento de
picture:<picture> <source type="image/avif" /> <source type="image/webp" /> <source type="image/jpeg" /> <img src="fallback-image.jpg" alt="Photo" width="450" height="350"> </picture><picture> <source type="image/avif" /> <source type="image/webp" /> <source type="image/jpeg" /> <img src="fallback-image.jpg" alt="Photo" width="450" height="350"> </picture>Puede ir aún más lejos intercambiando imágenes animadas con imágenes estáticas para los clientes que optan por menos movimiento con movimiento
prefers-reduced-motion:<picture> <source media="(prefers-reduced-motion: reduce)" type="image/avif"></source> <source media="(prefers-reduced-motion: reduce)" type="image/jpeg"></source> <source type="image/avif"></source> <img src="motion.jpg" alt="Animated AVIF"> </picture><picture> <source media="(prefers-reduced-motion: reduce)" type="image/avif"></source> <source media="(prefers-reduced-motion: reduce)" type="image/jpeg"></source> <source type="image/avif"></source> <img src="motion.jpg" alt="Animated AVIF"> </picture>Durante el par de meses, AVIF ha ganado bastante tracción:
- Podemos probar los respaldos de WebP/AVIF en el panel Rendering en DevTools.
- Podemos usar Squoosh, AVIF.io y libavif para codificar, decodificar, comprimir y convertir archivos AVIF.
- Podemos usar el componente AVIF Preact de Jake Archibald que decodifica un archivo AVIF en un trabajador y muestra el resultado en un lienzo,
- Para entregar AVIF solo a navegadores compatibles, podemos usar un complemento PostCSS junto con un script 315B para usar AVIF en sus declaraciones CSS.
- Podemos entregar progresivamente nuevos formatos de imagen con CSS y Cloudlare Workers para modificar dinámicamente el documento HTML devuelto, deducir información del encabezado de
accepty luego agregar laswebp/avif, etc., según corresponda. - AVIF ya está disponible en Cloudinary (con límites de uso), Cloudflare admite AVIF en el cambio de tamaño de imagen y puede habilitar AVIF con encabezados AVIF personalizados en Netlify.
- Cuando se trata de animación, AVIF funciona tan bien como
<img src=mp4>de Safari, superando a GIF y WebP en general, pero MP4 aún funciona mejor. - En general, para animaciones, AVC1 (h264) > HVC1 > WebP > AVIF > GIF, suponiendo que los navegadores basados en Chromium alguna vez admitirán
<img src=mp4>. - Puede encontrar más detalles sobre AVIF en AVIF para la charla de codificación de imágenes de próxima generación de Aditya Mavlankar de Netflix, y la charla de The AVIF Image Format de Kornel Lesinski de Cloudflare.
- Una gran referencia para todo lo relacionado con AVIF: ha llegado la publicación completa de Jake Archibald sobre AVIF.
¿Entonces es el futuro AVIF ? Jon Sneyers no está de acuerdo: AVIF funciona un 60 % peor que JPEG XL, otro formato gratuito y abierto desarrollado por Google y Cloudinary. De hecho, JPEG XL parece estar funcionando mucho mejor en todos los ámbitos. Sin embargo, JPEG XL aún se encuentra en las etapas finales de estandarización y aún no funciona en ningún navegador. (No se mezcle con el JPEG-XR de Microsoft que viene del buen Internet Explorer 9 veces).
- ¿Están JPEG/PNG/SVG correctamente optimizados?
Cuando esté trabajando en una página de destino en la que es fundamental que una imagen destacada se cargue ultrarrápidamente, asegúrese de que los archivos JPEG sean progresivos y estén comprimidos con mozJPEG (que mejora el tiempo de inicio de procesamiento al manipular los niveles de escaneo) o Guetzli, el código abierto de Google. codificador centrado en el rendimiento perceptivo y utilizando aprendizajes de Zopfli y WebP. El único inconveniente: tiempos de procesamiento lentos (un minuto de CPU por megapíxel).Para PNG, podemos usar Pingo y para SVG, podemos usar SVGO o SVGOMG. Y si necesita obtener una vista previa y copiar o descargar rápidamente todos los activos SVG de un sitio web, svg-grabber también puede hacerlo por usted.
Cada artículo de optimización de imágenes lo indicaría, pero siempre vale la pena mencionar mantener los activos vectoriales limpios y ajustados. Asegúrese de limpiar los activos no utilizados, elimine los metadatos innecesarios y reduzca la cantidad de puntos de ruta en las ilustraciones (y, por lo tanto, en el código SVG). ( ¡Gracias, Jeremy! )
Sin embargo, también hay herramientas útiles en línea disponibles:
- Use Squoosh para comprimir, cambiar el tamaño y manipular imágenes en los niveles de compresión óptimos (con pérdida o sin pérdida),
- Use Guetzli.it para comprimir y optimizar imágenes JPEG con Guetzli, que funciona bien para imágenes con bordes nítidos y colores sólidos (pero puede ser un poco más lento).
- Utilice el Generador de puntos de interrupción de imágenes sensibles o un servicio como Cloudinary o Imgix para automatizar la optimización de imágenes. Además, en muchos casos, el uso exclusivo de
srcsetysizesgenerará beneficios significativos. - Para verificar la eficiencia de su marcado receptivo, puede usar el montón de imágenes, una herramienta de línea de comandos que mide la eficiencia en los tamaños de ventana gráfica y las proporciones de píxeles del dispositivo.
- Puede agregar compresión automática de imágenes a sus flujos de trabajo de GitHub, de modo que ninguna imagen llegue a la producción sin comprimir. La acción usa mozjpeg y libvips que funcionan con PNG y JPG.
- Para optimizar el almacenamiento de forma interna, puede usar el nuevo formato Lepton de Dropbox para comprimir archivos JPEG sin pérdidas en un promedio del 22 %.
- Use BlurHash si desea mostrar una imagen de marcador de posición antes. BlurHash toma una imagen y le da una cadena corta (¡solo 20-30 caracteres!) que representa el marcador de posición para esta imagen. La cadena es lo suficientemente corta como para que se pueda agregar fácilmente como un campo en un objeto JSON.
BlurHash es una representación pequeña y compacta de un marcador de posición para una imagen. (Vista previa grande) A veces, la optimización de imágenes por sí sola no es suficiente. Para mejorar el tiempo necesario para iniciar la renderización de una imagen crítica, cargue de forma diferida las imágenes menos importantes y posponga la carga de cualquier script después de que las imágenes críticas ya se hayan renderizado. La forma más segura es la carga diferida híbrida, cuando utilizamos carga diferida nativa y carga diferida, una biblioteca que detecta cualquier cambio de visibilidad desencadenado a través de la interacción del usuario (con IntersectionObserver, que exploraremos más adelante). Adicionalmente:
- Considere precargar imágenes críticas, para que un navegador no las descubra demasiado tarde. Para las imágenes de fondo, si desea ser aún más agresivo que eso, puede agregar la imagen como una imagen normal con
<img src>y luego ocultarla de la pantalla. - Considere intercambiar imágenes con el atributo de tamaños especificando diferentes dimensiones de visualización de imágenes según las consultas de medios, por ejemplo, para manipular
sizespara intercambiar fuentes en un componente de lupa. - Revise las inconsistencias en la descarga de imágenes para evitar descargas inesperadas de imágenes de primer plano y de fondo. Tenga cuidado con las imágenes que se cargan de forma predeterminada, pero es posible que nunca se muestren, por ejemplo, en carruseles, acordeones y galerías de imágenes.
- Asegúrese de establecer siempre el
widthy elheighten las imágenes. Tenga cuidado con la propiedadaspect-ratioen CSS y el atributo de tamañointrinsicsizeque nos permitirá establecer relaciones de aspecto y dimensiones para las imágenes, de modo que el navegador pueda reservar un espacio de diseño predefinido con anticipación para evitar saltos de diseño durante la carga de la página.
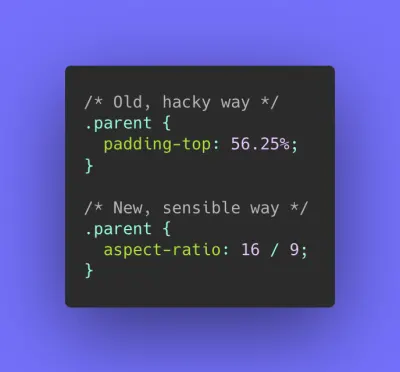
Debería ser solo cuestión de semanas o meses ahora, con la relación de aspecto aterrizando en los navegadores. En Safari Technical Preview 118 ya. Actualmente detrás de la bandera en Firefox y Chrome. (Vista previa grande) Si se siente aventurero, puede cortar y reorganizar las transmisiones HTTP/2 utilizando trabajadores de Edge, básicamente un filtro en tiempo real que vive en la CDN, para enviar imágenes más rápido a través de la red. Los trabajadores de borde usan flujos de JavaScript que usan fragmentos que puede controlar (básicamente, son JavaScript que se ejecuta en el borde de CDN que puede modificar las respuestas de transmisión), por lo que puede controlar la entrega de imágenes.
Con un trabajador de servicio, es demasiado tarde ya que no puede controlar lo que está en el cable, pero funciona con los trabajadores de Edge. Por lo tanto, puede usarlos sobre archivos JPEG estáticos guardados progresivamente para una página de destino en particular.
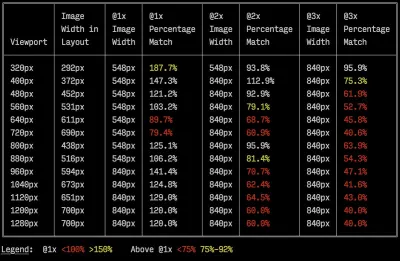
Un resultado de muestra de Imaging-Heap, una herramienta de línea de comandos que mide la eficiencia en los tamaños de ventana gráfica y las proporciones de píxeles del dispositivo. (Fuente de la imagen) (Vista previa grande) ¿No es suficiente? Bueno, también puede mejorar el rendimiento percibido de las imágenes con la técnica de múltiples imágenes de fondo. Tenga en cuenta que jugar con el contraste y difuminar detalles innecesarios (o eliminar colores) también puede reducir el tamaño del archivo. Ah, ¿necesitas ampliar una foto pequeña sin perder calidad? Considere usar Letsenhance.io.
Estas optimizaciones hasta ahora cubren solo lo básico. Addy Osmani ha publicado una guía muy detallada sobre la optimización esencial de imágenes que profundiza en los detalles de la compresión de imágenes y la gestión del color. Por ejemplo, podría desenfocar partes innecesarias de la imagen (aplicándoles un filtro de desenfoque gaussiano) para reducir el tamaño del archivo y, eventualmente, incluso podría comenzar a eliminar colores o convertir la imagen en blanco y negro para reducir aún más el tamaño. . Para las imágenes de fondo, exportar fotos de Photoshop con una calidad del 0 al 10 % también puede ser absolutamente aceptable.
En Smashing Magazine, usamos el sufijo
-optpara nombres de imágenes, por ejemplo,brotli-compression-opt.png; cada vez que una imagen contiene ese sufijo, todos en el equipo saben que la imagen ya ha sido optimizada.Ah, y no use JPEG-XR en la web: "el procesamiento de decodificación de JPEG-XR del lado del software en la CPU anula e incluso supera el impacto potencialmente positivo del ahorro de tamaño de bytes, especialmente en el contexto de SPA" (no mezclarse con Cloudinary/Google's JPEG XL).

- ¿Los videos están correctamente optimizados?
Cubrimos las imágenes hasta ahora, pero hemos evitado una conversación sobre buenos GIF. A pesar de nuestro amor por los GIF, es realmente el momento de abandonarlos para siempre (al menos en nuestros sitios web y aplicaciones). En lugar de cargar GIF animados pesados que afectan tanto el rendimiento de la representación como el ancho de banda, es una buena idea cambiar a WebP animado (con GIF como alternativa) o reemplazarlos con videos HTML5 en bucle.A diferencia de las imágenes, los navegadores no precargan el contenido de
<video>, pero los videos HTML5 tienden a ser mucho más livianos y pequeños que los GIF. ¿No es una opción? Bueno, al menos podemos agregar compresión con pérdida a los GIF con Lossy GIF, gifsicle o giflossy.Las pruebas realizadas por Colin Bendell muestran que los videos en línea dentro de las etiquetas
imgen Safari Technology Preview se muestran al menos 20 veces más rápido y se decodifican 7 veces más rápido que el equivalente GIF, además de tener una fracción del tamaño del archivo. Sin embargo, no es compatible con otros navegadores.En la tierra de las buenas noticias, los formatos de video han avanzado enormemente a lo largo de los años. Durante mucho tiempo, esperábamos que WebM se convirtiera en el formato para gobernarlos a todos, y WebP (que es básicamente una imagen fija dentro del contenedor de video WebM) se convertirá en un reemplazo para los formatos de imagen fechados. De hecho, Safari ahora es compatible con WebP, pero a pesar de que WebP y WebM obtuvieron soporte en estos días, el avance realmente no sucedió.
Aún así, podríamos usar WebM para la mayoría de los navegadores modernos:
<!-- By Houssein Djirdeh. https://web.dev/replace-gifs-with-videos/ --> <!-- A common scenartio: MP4 with a WEBM fallback. --> <video autoplay loop muted playsinline> <source src="my-animation.webm" type="video/webm"> <source src="my-animation.mp4" type="video/mp4"> </video>Pero tal vez podríamos revisarlo por completo. En 2018, Alliance of Open Media lanzó un nuevo formato de video prometedor llamado AV1 . AV1 tiene una compresión similar al códec H.265 (la evolución de H.264) pero a diferencia de este último, AV1 es gratuito. El precio de la licencia H.265 empujó a los proveedores de navegadores a adoptar un AV1 con un rendimiento comparable: AV1 (al igual que H.265) se comprime el doble de bien que WebM .

AV1 tiene buenas posibilidades de convertirse en el último estándar para video en la web. (Crédito de la imagen: Wikimedia.org) (Vista previa grande) De hecho, Apple actualmente usa el formato HEIF y HEVC (H.265), y todas las fotos y videos en el último iOS se guardan en estos formatos, no en JPEG. Si bien HEIF y HEVC (H.265) no están correctamente expuestos a la web (¿todavía?), AV1 sí lo está, y está ganando compatibilidad con los navegadores. Por lo tanto, agregar la fuente
AV1en su etiqueta<video>es razonable, ya que todos los proveedores de navegadores parecen estar de acuerdo.Por ahora, la codificación más utilizada y admitida es H.264, proporcionada por archivos MP4, por lo tanto, antes de entregar el archivo, asegúrese de que sus MP4 se procesen con una codificación multipaso, borrosa con el efecto frei0r iirblur (si corresponde) y Los metadatos de moov atom se mueven al encabezado del archivo, mientras que su servidor acepta el servicio de bytes. Boris Schapira proporciona instrucciones exactas para que FFmpeg optimice los videos al máximo. Por supuesto, proporcionar el formato WebM como alternativa también ayudaría.
¿Necesita comenzar a renderizar videos más rápido pero los archivos de video aún son demasiado grandes ? Por ejemplo, ¿siempre que tenga un video de fondo grande en una página de destino? Una técnica común que se usa es mostrar el primer cuadro primero como una imagen fija, o mostrar un segmento de bucle corto muy optimizado que podría interpretarse como parte del video y luego, cuando el video esté lo suficientemente almacenado en el búfer, comience a reproducirse. el vídeo real. Doug Sillars tiene una guía escrita detallada para el rendimiento de video de fondo que podría ser útil en ese caso. ( ¡Gracias, Guy Podjarny! ).
Para el escenario anterior, es posible que desee proporcionar imágenes de póster receptivas . De forma predeterminada, los elementos de
videosolo permiten una imagen como póster, lo que no es necesariamente óptimo. Podemos usar Responsive Video Poster, una biblioteca de JavaScript que le permite usar diferentes imágenes de póster para diferentes pantallas, al tiempo que agrega una superposición de transición y un control de estilo completo de los marcadores de posición de video.La investigación muestra que la calidad de la transmisión de video afecta el comportamiento del espectador. De hecho, los espectadores comienzan a abandonar el video si el retraso en el inicio supera los 2 segundos. Más allá de ese punto, un aumento de 1 segundo en la demora da como resultado un aumento de aproximadamente el 5,8 % en la tasa de abandono. Por lo tanto, no sorprende que la mediana del tiempo de inicio del video sea de 12,8 s, con un 40 % de videos que tienen al menos 1 detención y un 20 % de al menos 2 s de reproducción de video detenida. De hecho, las paradas de video son inevitables en 3G ya que los videos se reproducen más rápido de lo que la red puede proporcionar contenido.
Entonces, ¿cuál es la solución? Por lo general, los dispositivos de pantalla pequeña no pueden manejar los 720p y 1080p que estamos sirviendo en el escritorio. Según Doug Sillars, podemos crear versiones más pequeñas de nuestros videos y usar Javascript para detectar la fuente en pantallas más pequeñas para garantizar una reproducción rápida y fluida en estos dispositivos. Alternativamente, podemos usar la transmisión de video. Las transmisiones de video HLS entregarán un video de tamaño adecuado al dispositivo, lo que elimina la necesidad de crear diferentes videos para diferentes pantallas. También negociará la velocidad de la red y adaptará la tasa de bits del video a la velocidad de la red que está utilizando.
Para evitar el desperdicio de ancho de banda, solo podríamos agregar la fuente de video para dispositivos que realmente puedan reproducir bien el video. Alternativamente, podemos eliminar el atributo de
autoplayde la etiqueta devideopor completo y usar JavaScript para insertarautoplaypara pantallas más grandes. Además, debemos agregarpreload="none"en elvideopara decirle al navegador que no descargue ninguno de los archivos de video hasta que realmente necesite el archivo:<!-- Based on Doug Sillars's post. https://dougsillars.com/2020/01/06/hiding-videos-on-the-mbile-web/ --> <video preload="none" playsinline muted loop width="1920" height="1080" poster="poster.jpg"> <source src="video.webm" type="video/webm"> <source src="video.mp4" type="video/mp4"> </video>Entonces podemos apuntar específicamente a los navegadores que realmente son compatibles con AV1:
<!-- Based on Doug Sillars's post. https://dougsillars.com/2020/01/06/hiding-videos-on-the-mbile-web/ --> <video preload="none" playsinline muted loop width="1920" height="1080" poster="poster.jpg"> <source src="video.av1.mp4" type="video/mp4; codecs=av01.0.05M.08"> <source src="video.hevc.mp4" type="video/mp4; codecs=hevc"> <source src="video.webm" type="video/webm"> <source src="video.mp4" type="video/mp4"> </video>Entonces podríamos volver a agregar la
autoplaysobre un cierto umbral (por ejemplo, 1000px):/* By Doug Sillars. https://dougsillars.com/2020/01/06/hiding-videos-on-the-mbile-web/ */ <script> window.onload = addAutoplay(); var videoLocation = document.getElementById("hero-video"); function addAutoplay() { if(window.innerWidth > 1000){ videoLocation.setAttribute("autoplay",""); }; } </script>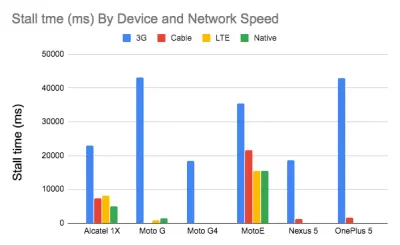
Número de puestos por dispositivo y velocidad de red. Los dispositivos más rápidos en redes más rápidas prácticamente no tienen paradas. Según la investigación de Doug Sillars. (Vista previa grande) El rendimiento de la reproducción de video es una historia en sí misma, y si desea profundizar en ella en detalle, eche un vistazo a otra serie de Doug Sillars sobre el estado actual del video y las mejores prácticas de entrega de video que incluyen detalles sobre las métricas de entrega de video. , precarga de video, compresión y transmisión. Finalmente, puede verificar qué tan lenta o rápida será su transmisión de video con Stream or Not.
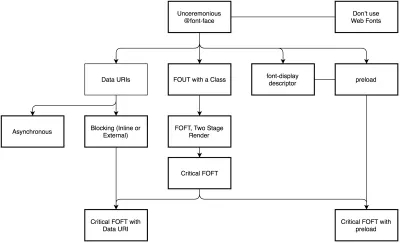
- ¿Está optimizada la entrega de fuentes web?
The first question that's worth asking is if we can get away with using UI system fonts in the first place — we just need to make sure to double check that they appear correctly on various platforms. If it's not the case, chances are high that the web fonts we are serving include glyphs and extra features and weights that aren't being used. We can ask our type foundry to subset web fonts or if we are using open-source fonts, subset them on our own with Glyphhanger or Fontsquirrel. We can even automate our entire workflow with Peter Muller's subfont, a command line tool that statically analyses your page in order to generate the most optimal web font subsets, and then inject them into our pages.WOFF2 support is great, and we can use WOFF as fallback for browsers that don't support it — or perhaps legacy browsers could be served system fonts. There are many, many, many options for web font loading, and we can choose one of the strategies from Zach Leatherman's "Comprehensive Guide to Font-Loading Strategies," (code snippets also available as Web font loading recipes).
Probably the better options to consider today are Critical FOFT with
preloadand "The Compromise" method. Both of them use a two-stage render for delivering web fonts in steps — first a small supersubset required to render the page fast and accurately with the web font, and then load the rest of the family async. The difference is that "The Compromise" technique loads polyfill asynchronously only if font load events are not supported, so you don't need to load the polyfill by default. Need a quick win? Zach Leatherman has a quick 23-min tutorial and case study to get your fonts in order.In general, it might be a good idea to use the
preloadresource hint to preload fonts, but in your markup include the hints after the link to critical CSS and JavaScript. Withpreload, there is a puzzle of priorities, so consider injectingrel="preload"elements into the DOM just before the external blocking scripts. According to Andy Davies, "resources injected using a script are hidden from the browser until the script executes, and we can use this behaviour to delay when the browser discovers thepreloadhint." Otherwise, font loading will cost you in the first render time.
When everything is critical, nothing is critical. preload only one or a maximum of two fonts of each family. (Image credit: Zach Leatherman – slide 93) (Large preview) It's a good idea to be selective and choose files that matter most, eg the ones that are critical for rendering or that would help you avoiding visible and disruptive text reflows. In general, Zach advises to preload one or two fonts of each family — it also makes sense to delay some font loading if they are less critical.
It has become quite common to use
local()value (which refers to a local font by name) when defining afont-familyin the@font-facerule:/* Warning! Not a good idea! */ @font-face { font-family: Open Sans; src: local('Open Sans Regular'), local('OpenSans-Regular'), url('opensans.woff2') format ('woff2'), url('opensans.woff') format('woff'); }The idea is reasonable: some popular open-source fonts such as Open Sans are coming pre-installed with some drivers or apps, so if the font is available locally, the browser doesn't need to download the web font and can display the local font immediately. As Bram Stein noted, "though a local font matches the name of a web font, it most likely isn't the same font . Many web fonts differ from their "desktop" version. The text might be rendered differently, some characters may fall back to other fonts, OpenType features can be missing entirely, or the line height may be different."
Also, as typefaces evolve over time, the locally installed version might be very different from the web font, with characters looking very different. So, according to Bram, it's better to never mix locally installed fonts and web fonts in
@font-facerules. Google Fonts has followed suit by disablinglocal()on the CSS results for all users, other than Android requests for Roboto.Nobody likes waiting for the content to be displayed. With the
font-displayCSS descriptor, we can control the font loading behavior and enable content to be readable immediately (withfont-display: optional) or almost immediately (with a timeout of 3s, as long as the font gets successfully downloaded — withfont-display: swap). (Well, it's a bit more complicated than that.)However, if you want to minimize the impact of text reflows, we could use the Font Loading API (supported in all modern browsers). Specifically that means for every font, we'd creata a
FontFaceobject, then try to fetch them all, and only then apply them to the page. This way, we group all repaints by loading all fonts asynchronously, and then switch from fallback fonts to the web font exactly once. Take a look at Zach's explanation, starting at 32:15, and the code snippet):/* Load two web fonts using JavaScript */ /* Zach Leatherman: https://noti.st/zachleat/KNaZEg/the-five-whys-of-web-font-loading-performance#sWkN4u4 */ // Remove existing @font-face blocks // Create two let font = new FontFace("Noto Serif", /* ... */); let fontBold = new FontFace("Noto Serif, /* ... */); // Load two fonts let fonts = await Promise.all([ font.load(), fontBold.load() ]) // Group repaints and render both fonts at the same time! fonts.forEach(font => documents.fonts.add(font));/* Load two web fonts using JavaScript */ /* Zach Leatherman: https://noti.st/zachleat/KNaZEg/the-five-whys-of-web-font-loading-performance#sWkN4u4 */ // Remove existing @font-face blocks // Create two let font = new FontFace("Noto Serif", /* ... */); let fontBold = new FontFace("Noto Serif, /* ... */); // Load two fonts let fonts = await Promise.all([ font.load(), fontBold.load() ]) // Group repaints and render both fonts at the same time! fonts.forEach(font => documents.fonts.add(font));To initiate a very early fetch of the fonts with Font Loading API in use, Adrian Bece suggests to add a non-breaking space
nbsp;at the top of thebody, and hide it visually witharia-visibility: hiddenand a.hiddenclass:<body class="no-js"> <!-- ... Website content ... --> <div aria-visibility="hidden" class="hidden"> <!-- There is a non-breaking space here --> </div> <script> document.getElementsByTagName("body")[0].classList.remove("no-js"); </script> </body><body class="no-js"> <!-- ... Website content ... --> <div aria-visibility="hidden" class="hidden"> <!-- There is a non-breaking space here --> </div> <script> document.getElementsByTagName("body")[0].classList.remove("no-js"); </script> </body>This goes along with CSS that has different font families declared for different states of loading, with the change triggered by Font Loading API once the fonts have successfully loaded:
body:not(.wf-merriweather--loaded):not(.no-js) { font-family: [fallback-system-font]; /* Fallback font styles */ } .wf-merriweather--loaded, .no-js { font-family: "[web-font-name]"; /* Webfont styles */ } /* Accessible hiding */ .hidden { position: absolute; overflow: hidden; clip: rect(0 0 0 0); height: 1px; width: 1px; margin: -1px; padding: 0; border: 0; }body:not(.wf-merriweather--loaded):not(.no-js) { font-family: [fallback-system-font]; /* Fallback font styles */ } .wf-merriweather--loaded, .no-js { font-family: "[web-font-name]"; /* Webfont styles */ } /* Accessible hiding */ .hidden { position: absolute; overflow: hidden; clip: rect(0 0 0 0); height: 1px; width: 1px; margin: -1px; padding: 0; border: 0; }If you ever wondered why despite all your optimizations, Lighthouse still suggests to eliminate render-blocking resources (fonts), in the same article Adrian Bece provides a few techniques to make Lighthouse happy, along with a Gatsby Omni Font Loader, a performant asynchronous font loading and Flash Of Unstyled Text (FOUT) handling plugin for Gatsby.

Now, many of us might be using a CDN or a third-party host to load web fonts from. In general, it's always better to self-host all your static assets if you can, so consider using google-webfonts-helper, a hassle-free way to self-host Google Fonts. And if it's not possible, you can perhaps proxy the Google Font files through the page origin.
It's worth noting though that Google is doing quite a bit of work out of the box, so a server might need a bit of tweaking to avoid delays ( thanks, Barry! )
This is quite important especially as since Chrome v86 (released October 2020), cross-site resources like fonts can't be shared on the same CDN anymore — due to the partitioned browser cache. This behavior was a default in Safari for years.
But if it's not possible at all, there is a way to get to the fastest possible Google Fonts with Harry Roberts' snippet:
<!-- By Harry Roberts. https://csswizardry.com/2020/05/the-fastest-google-fonts/ - 1. Preemptively warm up the fonts' origin. - 2. Initiate a high-priority, asynchronous fetch for the CSS file. Works in - most modern browsers. - 3. Initiate a low-priority, asynchronous fetch that gets applied to the page - only after it's arrived. Works in all browsers with JavaScript enabled. - 4. In the unlikely event that a visitor has intentionally disabled - JavaScript, fall back to the original method. The good news is that, - although this is a render-blocking request, it can still make use of the - preconnect which makes it marginally faster than the default. --> <!-- [1] --> <link rel="preconnect" href="https://fonts.gstatic.com" crossorigin /> <!-- [2] --> <link rel="preload" as="style" href="$CSS&display=swap" /> <!-- [3] --> <link rel="stylesheet" href="$CSS&display=swap" media="print" onload="this.media='all'" /> <!-- [4] --> <noscript> <link rel="stylesheet" href="$CSS&display=swap" /> </noscript>Harry's strategy is to pre-emptively warm up the fonts' origin first. Then we initiate a high-priority, asynchronous fetch for the CSS file. Afterwards, we initiate a low-priority, asynchronous fetch that gets applied to the page only after it's arrived (with a print stylesheet trick). Finally, if JavaScript isn't supported, we fall back to the original method.
Ah, talking about Google Fonts: you can shave up to 90% of the size of Google Fonts requests by declaring only characters you need with
&text. Plus, the support for font-display was added recently to Google Fonts as well, so we can use it out of the box.Sin embargo, una breve advertencia. Si usa
font-display: optional, podría ser subóptimo usar también lapreload, ya que activará esa solicitud de fuente web antes (causando congestión en la red si tiene otros recursos de ruta crítica que deben recuperarse). Utilice lapreconnectpara solicitudes de fuentes de origen cruzado más rápidas, pero tenga cuidado con lapreload, ya que la precarga de fuentes de un origen diferente provocará conflictos en la red. Todas estas técnicas están cubiertas en las recetas de carga de fuentes web de Zach.Por otro lado, podría ser una buena idea excluirse de las fuentes web (o al menos el renderizado de segunda etapa) si el usuario ha habilitado Reducir movimiento en las preferencias de accesibilidad o ha optado por el Modo de ahorro de datos (consulte el encabezado
Save-Data) , o cuando el usuario tiene una conectividad lenta (a través de la API de información de red).También podemos usar la consulta de medios CSS
prefers-reduced-datapara no definir declaraciones de fuente si el usuario ha optado por el modo de ahorro de datos (también hay otros casos de uso). La consulta de medios básicamente expondría si el encabezado de la solicitudSave-Datade la extensión HTTP Client Hint está activado/desactivado para permitir el uso con CSS. Actualmente solo se admite en Chrome y Edge detrás de una bandera.¿Métrica? Para medir el rendimiento de carga de la fuente web, considere la métrica Todo el texto visible (el momento en que todas las fuentes se han cargado y todo el contenido se muestra en las fuentes web), el Tiempo para la cursiva real y el Conteo de flujo de fuente web después del primer renderizado. Obviamente, cuanto más bajas sean ambas métricas, mejor será el rendimiento.
¿Qué pasa con las fuentes variables , podrías preguntar? Es importante tener en cuenta que las fuentes variables pueden requerir una consideración de rendimiento significativa. Nos brindan un espacio de diseño mucho más amplio para las opciones tipográficas, pero tiene el costo de una sola solicitud en serie en lugar de varias solicitudes de archivos individuales.
Si bien las fuentes variables reducen drásticamente el tamaño de archivo combinado general de los archivos de fuentes, esa única solicitud puede ser lenta y bloquear la representación de todo el contenido de una página. Por lo tanto, subdividir y dividir la fuente en conjuntos de caracteres sigue siendo importante. Sin embargo, en el lado bueno, con una fuente variable en su lugar, obtendremos exactamente un reflujo por defecto, por lo que no se requerirá JavaScript para agrupar repintados.
Ahora, ¿qué haría entonces una estrategia de carga de fuentes web a prueba de balas ? Crea subconjuntos de fuentes y prepáralas para el renderizado en 2 etapas, decláralas con un descriptor
font-display, usa la API de carga de fuentes para agrupar repintados y almacenar fuentes en la memoria caché de un trabajador de servicio persistente. En la primera visita, inyecte la precarga de scripts justo antes de los scripts externos de bloqueo. Si es necesario, puede recurrir al Font Face Observer de Bram Stein. Y si está interesado en medir el rendimiento de la carga de fuentes, Andreas Marschke explora el seguimiento del rendimiento con Font API y UserTiming API.Por último, no se olvide de incluir
unicode-rangepara dividir una fuente grande en fuentes más pequeñas específicas del idioma, y use el comparador de estilo de fuente de Monica Dinculescu para minimizar un cambio discordante en el diseño, debido a las discrepancias de tamaño entre el respaldo y el fuentes webAlternativamente, para emular una fuente web para una fuente alternativa, podemos usar los descriptores @font-face para anular las métricas de fuente (demostración, habilitado en Chrome 87). (Tenga en cuenta que los ajustes son complicados con pilas de fuentes complicadas).
¿El futuro parece brillante? Con el enriquecimiento progresivo de la fuente, eventualmente podríamos "descargar solo la parte requerida de la fuente en cualquier página dada, y para las solicitudes posteriores de esa fuente para 'parchar' dinámicamente la descarga original con conjuntos adicionales de glifos según sea necesario en la página sucesiva". puntos de vista", como explica Jason Pamental. La demostración de transferencia incremental ya está disponible y está en proceso.
Optimizaciones de compilación
- ¿Hemos definido nuestras prioridades?
Es una buena idea saber con qué estás tratando primero. Ejecute un inventario de todos sus activos (JavaScript, imágenes, fuentes, scripts de terceros y módulos "caros" en la página, como carruseles, infografías complejas y contenido multimedia), y divídalos en grupos.Configura una hoja de cálculo . Defina la experiencia central básica para navegadores heredados (es decir, contenido central completamente accesible), la experiencia mejorada para navegadores capaces (es decir, una experiencia completa y enriquecida) y los extras (activos que no son absolutamente necesarios y pueden cargarse de forma diferida, como fuentes web, estilos innecesarios, scripts de carrusel, reproductores de video, widgets de redes sociales, imágenes grandes). Hace años, publicamos un artículo sobre "Mejorar el rendimiento de la revista Smashing", que describe este enfoque en detalle.
Al optimizar el rendimiento, debemos reflejar nuestras prioridades. Cargue la experiencia principal de inmediato, luego las mejoras y luego los extras .
- ¿Utiliza módulos JavaScript nativos en producción?
¿Recuerda la buena técnica clásica para enviar la experiencia principal a los navegadores heredados y una experiencia mejorada a los navegadores modernos? Una variante actualizada de la técnica podría usar ES2017+<script type="module">, también conocido como patrón de módulo/no módulo (también presentado por Jeremy Wagner como servicio diferencial ).La idea es compilar y servir dos paquetes de JavaScript separados : la compilación "normal", la que tiene transformaciones de Babel y rellenos polivalentes y servirlos solo a los navegadores heredados que realmente los necesitan, y otro paquete (la misma funcionalidad) que no tiene transformaciones o polirellenos.
Como resultado, ayudamos a reducir el bloqueo del hilo principal al reducir la cantidad de secuencias de comandos que el navegador necesita procesar. Jeremy Wagner ha publicado un artículo completo sobre el servicio diferencial y cómo configurarlo en su canal de compilación, desde la configuración de Babel hasta los ajustes que deberá realizar en Webpack, además de los beneficios de hacer todo este trabajo.
Las secuencias de comandos del módulo de JavaScript nativo se difieren de forma predeterminada, por lo que mientras se realiza el análisis de HTML, el navegador descargará el módulo principal.

Los módulos JavaScript nativos se difieren de forma predeterminada. Casi todo sobre los módulos nativos de JavaScript. (Vista previa grande) Sin embargo, una nota de advertencia: el patrón de módulo/no módulo puede fracasar en algunos clientes, por lo que es posible que desee considerar una solución alternativa: el patrón de servicio diferencial menos riesgoso de Jeremy que, sin embargo, elude el escáner de precarga, lo que podría afectar el rendimiento de maneras que uno no podría prever. ( ¡gracias, Jeremy! )
De hecho, Rollup admite módulos como formato de salida, por lo que podemos empaquetar código e implementar módulos en producción. Parcel tiene soporte para módulos en Parcel 2. Para Webpack, module-nomodule-plugin automatiza la generación de scripts de módulo/nomodule.
Nota : vale la pena señalar que la detección de funciones por sí sola no es suficiente para tomar una decisión informada sobre la carga útil que se enviará a ese navegador. Por sí solo, no podemos deducir la capacidad del dispositivo de la versión del navegador. Por ejemplo, los teléfonos Android baratos en los países en desarrollo en su mayoría ejecutan Chrome y cortarán la mostaza a pesar de sus capacidades limitadas de memoria y CPU.
Eventualmente, usando el encabezado de sugerencias de cliente de memoria del dispositivo, podremos apuntar a dispositivos de gama baja de manera más confiable. Al momento de escribir, el encabezado solo se admite en Blink (se aplica a las sugerencias del cliente en general). Dado que Device Memory también tiene una API de JavaScript que está disponible en Chrome, una opción podría ser la función de detección basada en la API y recurrir al patrón de módulo/sin módulo si no es compatible ( ¡gracias, Yoav! ).
- ¿Está utilizando la sacudida de árboles, el levantamiento de alcance y la división de códigos?
Tree-shaking es una forma de limpiar su proceso de compilación al incluir solo el código que realmente se usa en producción y eliminar las importaciones no utilizadas en Webpack. Con Webpack y Rollup, también tenemos elevación de alcance que permite que ambas herramientas detecten dónde se puede aplanar el encadenamiento deimporty convertirlo en una función en línea sin comprometer el código. Con Webpack, también podemos usar JSON Tree Shaking.La división de código es otra característica de Webpack que divide su base de código en "trozos" que se cargan a pedido. No es necesario descargar, analizar y compilar todo el JavaScript de inmediato. Una vez que defina los puntos de división en su código, Webpack puede encargarse de las dependencias y los archivos de salida. Le permite mantener pequeña la descarga inicial y solicitar código a pedido cuando lo solicite la aplicación. Alexander Kondrov tiene una fantástica introducción a la división de código con Webpack y React.
Considere usar preload-webpack-plugin que toma las rutas que divide en código y luego solicita al navegador que las cargue previamente usando
<link rel="preload">o<link rel="prefetch">. Las directivas en línea de Webpack también brindan cierto control sobre lapreload/prefetch. (Sin embargo, tenga cuidado con los problemas de priorización).¿Dónde definir los puntos de división? Mediante el seguimiento de qué fragmentos de CSS/JavaScript se utilizan y cuáles no. Umar Hansa explica cómo puede usar Code Coverage de Devtools para lograrlo.
Cuando se trata de aplicaciones de una sola página, necesitamos algo de tiempo para inicializar la aplicación antes de poder renderizar la página. Su configuración requerirá su solución personalizada, pero puede estar atento a los módulos y técnicas para acelerar el tiempo de renderizado inicial. Por ejemplo, aquí se explica cómo depurar el rendimiento de React y eliminar problemas comunes de rendimiento de React, y aquí se explica cómo mejorar el rendimiento en Angular. En general, la mayoría de los problemas de rendimiento provienen de la primera vez que se inicia la aplicación.
Entonces, ¿cuál es la mejor manera de dividir el código de manera agresiva, pero no demasiado agresiva? Según Phil Walton, "además de la división de código a través de importaciones dinámicas, [podríamos] también usar la división de código a nivel de paquete , donde cada módulo de nodo importado se coloca en un fragmento según el nombre de su paquete". Phil proporciona un tutorial sobre cómo construirlo también.
- ¿Podemos mejorar la salida de Webpack?
Como Webpack a menudo se considera misterioso, hay muchos complementos de Webpack que pueden ser útiles para reducir aún más la salida de Webpack. A continuación se muestran algunos de los más oscuros que podrían necesitar un poco más de atención.Uno de los interesantes proviene del hilo de Ivan Akulov. Imagine que tiene una función a la que llama una vez, almacena su resultado en una variable y luego no usa esa variable. Tree-shaking eliminará la variable, pero no la función, porque podría usarse de otra manera. Sin embargo, si la función no se usa en ninguna parte, es posible que desee eliminarla. Para hacerlo, anteponga a la llamada de función
/*#__PURE__*/que es compatible con Uglify y Terser, ¡listo!
Para eliminar una función de este tipo cuando no se usa su resultado, anteponga la llamada a la función con /*#__PURE__*/. A través de Ivan Akulov. (Vista previa grande)Estas son algunas de las otras herramientas que Ivan recomienda:
- purgecss-webpack-plugin elimina las clases no utilizadas, especialmente cuando usa Bootstrap o Tailwind.
- Habilite
optimization.splitChunks: 'all'con split-chunks-plugin. Esto haría que webpack dividiera automáticamente en código sus paquetes de entrada para un mejor almacenamiento en caché. - Establezca la
optimization.runtimeChunk: true. Esto movería el tiempo de ejecución de webpack a un fragmento separado y también mejoraría el almacenamiento en caché. - google-fonts-webpack-plugin descarga archivos de fuentes, para que pueda servirlos desde su servidor.
- workbox-webpack-plugin le permite generar un service worker con una configuración de precaching para todos sus activos de webpack. Además, consulte Service Worker Packages, una guía completa de módulos que se pueden aplicar de inmediato. O use preload-webpack-plugin para generar
preload/prefetchpara todos los fragmentos de JavaScript. - speed-measure-webpack-plugin mide la velocidad de compilación de su paquete web y brinda información sobre qué pasos del proceso de compilación consumen más tiempo.
- duplicate-package-checker-webpack-plugin advierte cuando su paquete contiene varias versiones del mismo paquete.
- Utilice el aislamiento del ámbito y acorte los nombres de las clases de CSS de forma dinámica en el momento de la compilación.
- ¿Se puede descargar JavaScript en un Web Worker?
Para reducir el impacto negativo en el tiempo de interacción, podría ser una buena idea descargar JavaScript pesado en un Web Worker.A medida que la base de código siga creciendo, aparecerán cuellos de botella en el rendimiento de la interfaz de usuario, lo que ralentizará la experiencia del usuario. Eso es porque las operaciones DOM se ejecutan junto con su JavaScript en el hilo principal. Con los trabajadores web, podemos mover estas costosas operaciones a un proceso en segundo plano que se ejecuta en un subproceso diferente. Los casos de uso típicos para los trabajadores web son la obtención previa de datos y las aplicaciones web progresivas para cargar y almacenar algunos datos por adelantado para que pueda usarlos más tarde cuando sea necesario. Y podría usar Comlink para agilizar la comunicación entre la página principal y el trabajador. Todavía queda trabajo por hacer, pero estamos llegando allí.
Hay algunos estudios de casos interesantes sobre los trabajadores web que muestran diferentes enfoques para mover el marco y la lógica de la aplicación a los trabajadores web. La conclusión: en general, todavía hay algunos desafíos, pero ya hay algunos buenos casos de uso ( ¡gracias, Ivan Akulov! ).
A partir de Chrome 80, se envió un nuevo modo para trabajadores web con beneficios de rendimiento de los módulos de JavaScript, llamados trabajadores de módulos. Podemos cambiar la carga y ejecución del script para que coincida con
script type="module", además, también podemos usar importaciones dinámicas para el código de carga diferida sin bloquear la ejecución del trabajador.¿Cómo empezar? Aquí hay algunos recursos que vale la pena investigar:
- Surma ha publicado una excelente guía sobre cómo ejecutar JavaScript fuera del hilo principal del navegador y también ¿Cuándo debería usar Web Workers?
- Además, consulte la charla de Surma sobre la arquitectura del subproceso principal.
- A Quest to Guarantee Responsiveness de Shubhie Panicker y Jason Miller proporciona información detallada sobre cómo utilizar los trabajadores web y cuándo evitarlos.
- Salir del camino de los usuarios: Menos Jank With Web Workers destaca patrones útiles para trabajar con Web Workers, formas efectivas de comunicarse entre trabajadores, manejar el procesamiento de datos complejos fuera del hilo principal y probarlos y depurarlos.
- Workerize le permite mover un módulo a un Web Worker, reflejando automáticamente las funciones exportadas como proxies asíncronos.
- Si está usando Webpack, podría usar workerize-loader. Alternativamente, también podría usar el complemento de trabajador.

Utilice trabajadores web cuando el código se bloquee durante mucho tiempo, pero evítelos cuando confíe en el DOM, maneje la respuesta de entrada y necesite un retraso mínimo. (a través de Addy Osmani) (Vista previa grande) Tenga en cuenta que los Web Workers no tienen acceso al DOM porque el DOM no es "seguro para subprocesos" y el código que ejecutan debe estar contenido en un archivo separado.
- ¿Puede descargar "rutas activas" a WebAssembly?
Podríamos descargar tareas computacionalmente pesadas a WebAssembly ( WASM ), un formato de instrucción binaria, diseñado como un objetivo portátil para la compilación de lenguajes de alto nivel como C/C++/Rust. Su soporte de navegador es notable, y recientemente se ha vuelto viable a medida que las llamadas de funciones entre JavaScript y WASM son cada vez más rápidas. Además, incluso es compatible con la nube perimetral de Fastly.Por supuesto, no se supone que WebAssembly reemplace a JavaScript, pero puede complementarlo en los casos en que observe un consumo excesivo de CPU. Para la mayoría de las aplicaciones web, JavaScript se adapta mejor, y WebAssembly se usa mejor para aplicaciones web de computación intensiva , como los juegos.
Si desea obtener más información sobre WebAssembly:
- Lin Clark ha escrito una serie exhaustiva sobre WebAssembly y Milica Mihajlija ofrece una descripción general de cómo ejecutar código nativo en el navegador, por qué es posible que desee hacerlo y qué significa para JavaScript y el futuro del desarrollo web.
- Cómo usamos WebAssembly para acelerar nuestra aplicación web en 20X (estudio de caso) destaca un estudio de caso de cómo los cálculos lentos de JavaScript se reemplazaron con WebAssembly compilado y aportaron mejoras de rendimiento significativas.
- Patrick Hamann ha estado hablando sobre el papel cada vez mayor de WebAssembly y está desacreditando algunos mitos sobre WebAssembly, explora sus desafíos y podemos usarlo prácticamente en las aplicaciones de hoy.
- Google Codelabs ofrece una Introducción a WebAssembly, un curso de 60 minutos en el que aprenderá cómo tomar código nativo en C y compilarlo en WebAssembly, y luego llamarlo directamente desde JavaScript.
- Alex Danilo ha explicado WebAssembly y cómo funciona en su charla de Google I/O. Además, Benedek Gagyi compartió un caso de estudio práctico sobre WebAssembly, específicamente cómo el equipo lo usa como formato de salida para su base de código C++ para iOS, Android y el sitio web.
¿ Aún no está seguro de cuándo usar Web Workers, Web Assembly, streams o quizás la API JavaScript de WebGL para acceder a la GPU? Acelerar JavaScript es una guía breve pero útil que explica cuándo usar qué y por qué, también con un práctico diagrama de flujo y muchos recursos útiles.
- ¿Servimos código heredado solo para navegadores heredados?
Dado que ES2017 es notablemente compatible con los navegadores modernos, podemos usarbabelEsmPluginpara transpilar solo las funciones de ES2017+ que no son compatibles con los navegadores modernos a los que se dirige.Houssein Djirdeh y Jason Miller publicaron recientemente una guía completa sobre cómo transpilar y servir JavaScript moderno y heredado, y detallan cómo hacerlo funcionar con Webpack y Rollup, y las herramientas necesarias. También puede estimar cuánto JavaScript puede eliminar en su sitio o paquetes de aplicaciones.
Los módulos de JavaScript son compatibles con todos los navegadores principales, así que use
script type="module"para permitir que los navegadores con compatibilidad con el módulo ES carguen el archivo, mientras que los navegadores más antiguos podrían cargar compilaciones heredadas conscript nomodule.En estos días podemos escribir JavaScript basado en módulos que se ejecuta de forma nativa en el navegador, sin transpiladores ni empaquetadores. El encabezado
<link rel="modulepreload">proporciona una forma de iniciar la carga temprana (y de alta prioridad) de los scripts de módulos. Básicamente, es una forma ingeniosa de ayudar a maximizar el uso del ancho de banda, diciéndole al navegador lo que necesita buscar para que no tenga nada que hacer durante esos largos viajes de ida y vuelta. Además, Jake Archibald ha publicado un artículo detallado con trampas y cosas a tener en cuenta con los módulos ES que vale la pena leer.
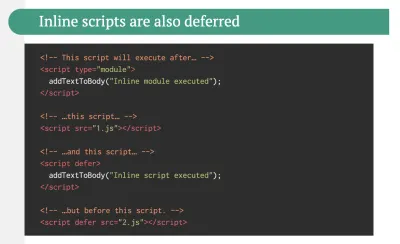
- Identifique y reescriba el código heredado con desacoplamiento incremental .
Los proyectos de larga duración tienden a acumular polvo y código obsoleto. Revise sus dependencias y evalúe cuánto tiempo se necesitaría para refactorizar o reescribir el código heredado que ha estado causando problemas últimamente. Por supuesto, siempre es una gran empresa, pero una vez que conoce el impacto del código heredado, puede comenzar con el desacoplamiento incremental.Primero, configure métricas que rastreen si la proporción de llamadas de código heredado se mantiene constante o disminuye, no aumenta. Desaliente públicamente al equipo de usar la biblioteca y asegúrese de que su CI alerte a los desarrolladores si se usa en solicitudes de incorporación de cambios. Los polyfills podrían ayudar en la transición del código heredado a una base de código reescrita que utiliza funciones de navegador estándar.
- Identifique y elimine CSS/JS no utilizados .
La cobertura de código CSS y JavaScript en Chrome le permite saber qué código se ha ejecutado/aplicado y cuál no. Puede comenzar a registrar la cobertura, realizar acciones en una página y luego explorar los resultados de la cobertura del código. Una vez que haya detectado el código no utilizado, busque esos módulos y realice la carga diferida conimport()(vea el hilo completo). Luego repita el perfil de cobertura y valide que ahora envía menos código en la carga inicial.Puede usar Titiritero para recopilar cobertura de código mediante programación. Chrome también le permite exportar resultados de cobertura de código. Como señaló Andy Davies, es posible que desee recopilar cobertura de código para navegadores tanto modernos como heredados.
Hay muchos otros casos de uso y herramientas para Puppetter que podrían necesitar un poco más de exposición:
- Casos de uso para Puppeteer, como, por ejemplo, diferenciación visual automática o monitoreo de CSS no utilizado con cada compilación,
- Recetas de rendimiento web con Puppeteer,
- Herramientas útiles para grabar y generar guiones de Pupeeteer y Playwright,
- Además, incluso puede grabar pruebas directamente en DevTools,
- Resumen completo de Titiritero por Nitay Neeman, con ejemplos y casos de uso.
Podemos usar Puppeteer Recorder y Puppeteer Sandbox para registrar la interacción del navegador y generar guiones de Puppeteer y Playwright. (Vista previa grande) Además, purgecss, UnCSS y Helium pueden ayudarlo a eliminar estilos no utilizados de CSS. Y si no está seguro de si se usa un código sospechoso en alguna parte, puede seguir el consejo de Harry Roberts: cree un GIF transparente de 1 × 1 px para una clase en particular y colóquelo en un directorio
dead/, por ejemplo,/assets/img/dead/comments.gif.Después de eso, configura esa imagen específica como fondo en el selector correspondiente en su CSS, siéntese y espere unos meses si el archivo aparecerá en sus registros. Si no hay entradas, nadie tenía ese componente heredado representado en su pantalla: probablemente pueda continuar y eliminarlo todo.
Para el departamento I-feel-adventurous , incluso podría automatizar la recopilación de CSS no utilizado a través de un conjunto de páginas al monitorear DevTools usando DevTools.
- Recorta el tamaño de tus paquetes de JavaScript.
Como señaló Addy Osmani, existe una alta probabilidad de que esté enviando bibliotecas de JavaScript completas cuando solo necesita una fracción, junto con polyfills fechados para navegadores que no los necesitan, o simplemente código duplicado. Para evitar la sobrecarga, considere usar webpack-libs-optimizations que elimine métodos no utilizados y polyfills durante el proceso de compilación.Verifique y revise los polyfills que está enviando a los navegadores heredados y a los navegadores modernos, y sea más estratégico al respecto. Eche un vistazo a polyfill.io, que es un servicio que acepta una solicitud de un conjunto de características del navegador y devuelve solo los polyfills que necesita el navegador solicitante.
Agregue también la auditoría de paquetes a su flujo de trabajo habitual. Puede haber algunas alternativas ligeras a las bibliotecas pesadas que agregó hace años, por ejemplo, Moment.js (ahora descontinuado) podría reemplazarse con:
- API de internacionalización nativa,
- Day.js con una API y patrones conocidos de Moment.js,
- fecha-fns o
- Luxón.
- También puede usar Skypack Discover, que combina recomendaciones de paquetes revisadas por personas con una búsqueda centrada en la calidad.
La investigación de Benedikt Rotsch mostró que un cambio de Moment.js a date-fns podría ahorrar alrededor de 300 ms para First paint en 3G y un teléfono móvil de gama baja.
Para la auditoría de paquetes, Bundlephobia podría ayudar a encontrar el costo de agregar un paquete npm a su paquete. size-limit amplía la comprobación básica del tamaño del paquete con detalles sobre el tiempo de ejecución de JavaScript. Incluso puede integrar estos costos con una auditoría personalizada de Lighthouse. Esto también se aplica a los marcos. Al quitar o recortar el adaptador Vue MDC (Componentes de material para Vue), los estilos bajan de 194 KB a 10 KB.
Hay muchas herramientas adicionales para ayudarlo a tomar una decisión informada sobre el impacto de sus dependencias y alternativas viables:
- analizador de paquete webpack
- Explorador de mapas de origen
- Amigo del paquete
- Paquetefobia
- El análisis del paquete web muestra por qué se incluye un módulo específico en el paquete.
- bundle-wizard también crea un mapa de dependencias para toda la página.
- Complemento de tamaño de paquete web
- Costo de importación para código visual
Alternativamente a enviar todo el marco, puede recortar su marco y compilarlo en un paquete de JavaScript sin formato que no requiere código adicional. Svelte lo hace, al igual que el complemento Rawact Babel, que transfiere los componentes de React.js a operaciones DOM nativas en el momento de la compilación. ¿Por qué? Bueno, como explican los mantenedores, "react-dom incluye código para cada posible componente/HTMLElement que se puede renderizar, incluido código para renderizado incremental, programación, manejo de eventos, etc. Pero hay aplicaciones que no necesitan todas estas características (al principio carga de la página). Para tales aplicaciones, podría tener sentido usar operaciones DOM nativas para construir la interfaz de usuario interactiva".
- ¿Usamos hidratación parcial?
Con la cantidad de JavaScript que se usa en las aplicaciones, debemos encontrar formas de enviar la menor cantidad posible al cliente. Una forma de hacerlo, y ya lo cubrimos brevemente, es con una hidratación parcial. La idea es bastante simple: en lugar de hacer SSR y luego enviar la aplicación completa al cliente, solo se enviarían al cliente pequeñas partes del JavaScript de la aplicación y luego se hidratarían. Podemos pensar en ello como múltiples aplicaciones React diminutas con múltiples raíces de renderizado en un sitio web estático.En el artículo "El caso de la hidratación parcial (con Next y Preact)", Lukas Bombach explica cómo el equipo detrás de Welt.de, uno de los medios de comunicación de Alemania, ha logrado un mejor rendimiento con la hidratación parcial. También puede consultar el repositorio de GitHub de próximo rendimiento superior con explicaciones y fragmentos de código.
También podría considerar opciones alternativas:
- hidratación parcial con Preact y Eleventy,
- hidratación progresiva en React GitHub repo,
- hidratación perezosa en Vue.js (repo de GitHub),
- Importe en el patrón de interacción para cargar de forma diferida los recursos no críticos (por ejemplo, componentes, incrustaciones) cuando un usuario interactúa con la interfaz de usuario que lo necesita.
Jason Miller ha publicado demostraciones de trabajo sobre cómo se podría implementar la hidratación progresiva con React, para que pueda usarlas de inmediato: demostración 1, demostración 2, demostración 3 (también disponible en GitHub). Además, puede buscar en la biblioteca de componentes prerenderizados de reacción.
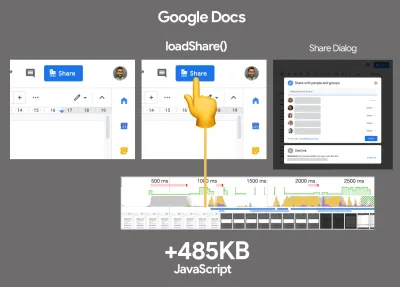
La importación en la interacción para el código de origen solo debe realizarse si no puede obtener recursos antes de la interacción. (Vista previa grande) - ¿Hemos optimizado la estrategia para React/SPA?
¿Tiene problemas con el rendimiento de su aplicación de una sola página? Jeremy Wagner ha explorado el impacto del rendimiento del marco del lado del cliente en una variedad de dispositivos, destacando algunas de las implicaciones y pautas que deberíamos tener en cuenta al usar uno.Como resultado, aquí hay una estrategia de SPA que Jeremy sugiere usar para el marco React (pero no debería cambiar significativamente para otros marcos):
- Refactorice los componentes con estado como componentes sin estado siempre que sea posible.
- Preprocesar componentes sin estado cuando sea posible para minimizar el tiempo de respuesta del servidor. Renderizar solo en el servidor.
- Para los componentes con estado con interactividad simple, considere la representación previa o la representación del servidor de ese componente, y reemplace su interactividad con detectores de eventos independientes del marco .
- Si debe hidratar componentes con estado en el cliente, utilice la hidratación perezosa en visibilidad o interacción.
- Para los componentes hidratados de forma diferida, programe su hidratación durante el tiempo de inactividad del subproceso principal con
requestIdleCallback.
Hay algunas otras estrategias que quizás desee seguir o revisar:
- Consideraciones de rendimiento para CSS-in-JS en aplicaciones React
- Reduzca el tamaño del paquete Next.js cargando polyfills solo cuando sea necesario, usando importaciones dinámicas e hidratación lenta.
- Secretos de JavaScript: Una historia de React, Performance Optimization and Multi-threading, una extensa serie de 7 partes sobre cómo mejorar los desafíos de la interfaz de usuario con React,
- Cómo medir el rendimiento de React y Cómo perfilar las aplicaciones de React.
- Creación de animaciones web para dispositivos móviles en React, una charla fantástica de Alex Holachek, junto con diapositivas y un repositorio de GitHub ( ¡gracias por el consejo, Addy! ).
- webpack-libs-optimizations es un fantástico repositorio de GitHub con muchas optimizaciones útiles relacionadas con el rendimiento específicas de Webpack. Mantenido por Ivan Akulov.
- Mejoras en el rendimiento de React en Notion, una guía de Ivan Akulov sobre cómo mejorar el rendimiento en React, con muchos consejos útiles para hacer que la aplicación sea un 30 % más rápida.
- El complemento React Refresh Webpack (experimental) permite la recarga en caliente que conserva el estado de los componentes y admite ganchos y componentes de funciones.
- Tenga cuidado con los componentes de servidor React de tamaño de paquete cero, un nuevo tipo de componentes propuesto que no tendrá impacto en el tamaño del paquete. El proyecto está actualmente en desarrollo, pero cualquier comentario de la comunidad es muy apreciado (excelente explicación de Sophie Alpert).
- ¿Está utilizando la captación previa predictiva para fragmentos de JavaScript?
Podríamos usar la heurística para decidir cuándo precargar fragmentos de JavaScript. Guess.js es un conjunto de herramientas y bibliotecas que utilizan datos de Google Analytics para determinar qué página es más probable que un usuario visite a continuación desde una página determinada. En función de los patrones de navegación de los usuarios recopilados de Google Analytics u otras fuentes, Guess.js crea un modelo de aprendizaje automático para predecir y obtener previamente el JavaScript que se requerirá en cada página posterior.Por lo tanto, cada elemento interactivo recibe una puntuación de probabilidad de participación y, en función de esa puntuación, un script del lado del cliente decide obtener un recurso con anticipación. Puede integrar la técnica a su aplicación Next.js, Angular y React, y hay un complemento Webpack que también automatiza el proceso de configuración.
Obviamente, es posible que esté solicitando al navegador que consuma datos innecesarios y precarga páginas no deseadas, por lo que es una buena idea ser bastante conservador en la cantidad de solicitudes precargadas. Un buen caso de uso sería obtener previamente los scripts de validación requeridos en el proceso de pago o la obtención previa especulativa cuando una llamada a la acción crítica entra en la ventana gráfica.
¿Necesita algo menos sofisticado? DNStradamus realiza una búsqueda previa de DNS para los enlaces salientes tal como aparecen en la ventana gráfica. Quicklink, InstantClick e Instant.page son pequeñas bibliotecas que automáticamente obtienen enlaces en la ventana gráfica durante el tiempo de inactividad en un intento de hacer que las navegaciones de la página siguiente se carguen más rápido. Quicklink permite precargar rutas de React Router y Javascript; además, tiene en cuenta los datos, por lo que no realiza una búsqueda previa en 2G o si
Data-Saverestá activado. También lo es Instant.page si el modo está configurado para usar la captación previa de ventana gráfica (que es un valor predeterminado).Si desea analizar la ciencia de la captación previa predictiva con todo detalle, Divya Tagtachian tiene una gran charla sobre El arte de la captación previa predictiva, que cubre todas las opciones de principio a fin.
- Aproveche las optimizaciones para su motor de JavaScript de destino.
Estudie qué motores de JavaScript dominan en su base de usuarios, luego explore formas de optimizarlos. Por ejemplo, al optimizar para V8 que se utiliza en los navegadores Blink, el tiempo de ejecución de Node.js y Electron, utilice la transmisión de secuencias de comandos para secuencias de comandos monolíticas.La transmisión de secuencias de comandos permite que las secuencias de comandos
asyncodefer scriptsse analicen en un subproceso de fondo separado una vez que comienza la descarga, lo que en algunos casos mejora los tiempos de carga de la página hasta en un 10%. Practically, use<script defer>in the<head>, so that the browsers can discover the resource early and then parse it on the background thread.Caveat : Opera Mini doesn't support script deferment, so if you are developing for India or Africa,
deferwill be ignored, resulting in blocking rendering until the script has been evaluated (thanks Jeremy!) .You could also hook into V8's code caching as well, by splitting out libraries from code using them, or the other way around, merge libraries and their uses into a single script, group small files together and avoid inline scripts. Or perhaps even use v8-compile-cache.
When it comes to JavaScript in general, there are also some practices that are worth keeping in mind:
- Clean Code concepts for JavaScript, a large collection of patterns for writing readable, reusable, and refactorable code.
- You can Compress data from JavaScript with the CompressionStream API, eg to gzip before uploading data (Chrome 80+).
- Detached window memory leaks and Fixing memory leaks in web apps are detailed guides on how to find and fix tricky JavaScript memory leaks. Plus, you can use queryObjects(SomeConstructor) from the DevTools Console ( thanks, Mathias! ).
- Reexports are bad for loading and runtime performance, and avoiding them can help reduce the bundle size significantly.
- We can improve scroll performance with passive event listeners by setting a flag in the
optionsparameter. So browsers can scroll the page immediately, rather than after the listener has finished. (via Kayce Basques). - If you have any
scrollortouch*listeners, passpassive: trueto addEventListener. This tells the browser you're not planning to callevent.preventDefault()inside, so it can optimize the way it handles these events. (via Ivan Akulov) - We can achieve better JavaScript scheduling with isInputPending(), a new API that attempts to bridge the gap between loading and responsiveness with the concepts of interrupts for user inputs on the web, and allows for JavaScript to be able to check for input without yielding to the browser.
- You can also automatically remove an event listener after it has executed.
- Firefox's recently released Warp, a significant update to SpiderMonkey (shipped in Firefox 83), Baseline Interpreter and there are a few JIT Optimization Strategies available as well.
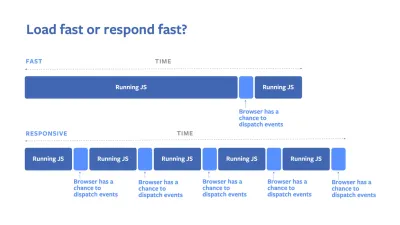
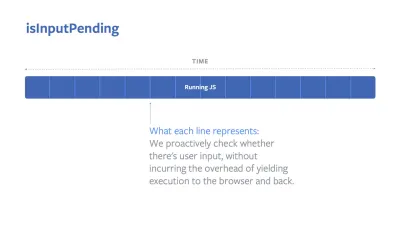
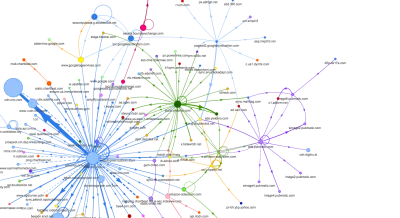
- Always prefer to self-host third-party assets.
Yet again, self-host your static assets by default. It's common to assume that if many sites use the same public CDN and the same version of a JavaScript library or a web font, then the visitors would land on our site with the scripts and fonts already cached in their browser, speeding up their experience considerably. However, it's very unlikely to happen.For security reasons, to avoid fingerprinting, browsers have been implementing partitioned caching that was introduced in Safari back in 2013, and in Chrome last year. So if two sites point to the exact same third-party resource URL, the code is downloaded once per domain , and the cache is "sandboxed" to that domain due to privacy implications ( thanks, David Calhoun! ). Hence, using a public CDN will not automatically lead to better performance.
Furthermore, it's worth noting that resources don't live in the browser's cache as long as we might expect, and first-party assets are more likely to stay in the cache than third-party assets. Therefore, self-hosting is usually more reliable and secure, and better for performance, too.
- Constrain the impact of third-party scripts.
With all performance optimizations in place, often we can't control third-party scripts coming from business requirements. Third-party-scripts metrics aren't influenced by end-user experience, so too often one single script ends up calling a long tail of obnoxious third-party scripts, hence ruining a dedicated performance effort. To contain and mitigate performance penalties that these scripts bring along, it's not enough to just defer their loading and execution and warm up connections via resource hints, iedns-prefetchorpreconnect.Currently 57% of all JavaScript code excution time is spent on third-party code. The median mobile site accesses 12 third-party domains , with a median of 37 different requests (or about 3 requests made to each third party).
Furthermore, these third-parties often invite fourth-party scripts to join in, ending up with a huge performance bottleneck, sometimes going as far as to the eigth-party scripts on a page. So regularly auditing your dependencies and tag managers can bring along costly surprises.
Another problem, as Yoav Weiss explained in his talk on third-party scripts, is that in many cases these scripts download resources that are dynamic. The resources change between page loads, so we don't necessarily know which hosts the resources will be downloaded from and what resources they would be.
Deferring, as shown above, might be just a start though as third-party scripts also steal bandwidth and CPU time from your app. We could be a bit more aggressive and load them only when our app has initialized.
/* Before */ const App = () => { return <div> <script> window.dataLayer = window.dataLayer || []; function gtag(){...} gtg('js', new Date()); </script> </div> } /* After */ const App = () => { const[isRendered, setRendered] = useState(false); useEffect(() => setRendered(true)); return <div> {isRendered ? <script> window.dataLayer = window.dataLayer || []; function gtag(){...} gtg('js', new Date()); </script> : null} </div> }In a fantastic post on "Reducing the Site-Speed Impact of Third-Party Tags", Andy Davies explores a strategy of minimizing the footprint of third-parties — from identifying their costs towards reducing their impact.
According to Andy, there are two ways tags impact site-speed — they compete for network bandwidth and processing time on visitors' devices, and depending on how they're implemented, they can delay HTML parsing as well. So the first step is to identify the impact that third-parties have, by testing the site with and without scripts using WebPageTest. With Simon Hearne's Request Map, we can also visualize third-parties on a page along with details on their size, type and what triggered their load.
Preferably self-host and use a single hostname, but also use a request map to exposes fourth-party calls and detect when the scripts change. You can use Harry Roberts' approach for auditing third parties and produce spreadsheets like this one (also check Harry's auditing workflow).
Afterwards, we can explore lightweight alternatives to existing scripts and slowly replace duplicates and main culprits with lighter options. Perhaps some of the scripts could be replaced with their fallback tracking pixel instead of the full tag.

Loading YouTube with facades, eg lite-youtube-embed that's significantly smaller than an actual YouTube player. (Fuente de la imagen) (Vista previa grande) If it's not viable, we can at least lazy load third-party resources with facades, ie a static element which looks similar to the actual embedded third-party, but is not functional and therefore much less taxing on the page load. The trick, then, is to load the actual embed only on interaction .
For example, we can use:
- lite-vimeo-embed for the Vimeo player,
- lite-vimeo for the Vimeo player,
- lite-youtube-embed for the YouTube player,
- react-live-chat-loader for a live chat (case study, and another case-study),
- lazyframe for iframes.
One of the reasons why tag managers are usually large in size is because of the many simultaneous experiments that are running at the same time, along with many user segments, page URLs, sites etc., so according to Andy, reducing them can reduce both the download size and the time it takes to execute the script in the browser.
And then there are anti-flicker snippets. Third-parties such as Google Optimize, Visual Web Optimizer (VWO) and others are unanimous in using them. These snippets are usually injected along with running A/B tests : to avoid flickering between the different test scenarios, they hide the
bodyof the document withopacity: 0, then adds a function that gets called after a few seconds to bring theopacityback. This often results in massive delays in rendering due to massive client-side execution costs.
With A/B testing in use, customers would often see flickering like this one. Anti-Flicker snippets prevent that, but they also cost in performance. Via Andy Davies. (Vista previa grande) Therefore keep track how often the anti-flicker timeout is triggered and reduce the timeout. Default blocks display of your page by up to 4s which will ruin conversion rates. According to Tim Kadlec, "Friends don't let friends do client side A/B testing". Server-side A/B testing on CDNs (eg Edge Computing, or Edge Slice Rerendering) is always a more performant option.
If you have to deal with almighty Google Tag Manager , Barry Pollard provides some guidelines to contain the impact of Google Tag Manager. Also, Christian Schaefer explores strategies for loading ads.
Cuidado: algunos widgets de terceros se ocultan de las herramientas de auditoría, por lo que pueden ser más difíciles de detectar y medir. Para realizar pruebas de estrés de terceros, examine los resúmenes de abajo hacia arriba en la página de perfil de rendimiento en DevTools, pruebe qué sucede si una solicitud está bloqueada o se agotó el tiempo de espera; para esto último, puede usar el servidor Blackhole de WebPageTest
blackhole.webpagetest.orgque puede señalar dominios específicos en su archivo dehosts.¿Qué opciones tenemos entonces? Considere el uso de trabajadores de servicio acelerando la descarga del recurso con un tiempo de espera y, si el recurso no ha respondido dentro de un cierto tiempo de espera, devuelva una respuesta vacía para indicarle al navegador que continúe con el análisis de la página. También puede registrar o bloquear solicitudes de terceros que no tengan éxito o no cumplan ciertos criterios. Si puede, cargue el script de terceros desde su propio servidor en lugar de hacerlo desde el servidor del proveedor y cárguelos de forma diferida.
Otra opción es establecer una Política de seguridad de contenido (CSP) para restringir el impacto de los scripts de terceros, por ejemplo, no permitir la descarga de audio o video. La mejor opción es incrustar secuencias de comandos a través de
<iframe>para que las secuencias de comandos se ejecuten en el contexto del iframe y, por lo tanto, no tengan acceso al DOM de la página y no puedan ejecutar código arbitrario en su dominio. Los iframes se pueden restringir aún más utilizando el atributosandbox, por lo que puede deshabilitar cualquier funcionalidad que iframe pueda hacer, por ejemplo, evitar que se ejecuten scripts, evitar alertas, envío de formularios, complementos, acceso a la navegación superior, etc.También puede controlar a los terceros a través de la alineación del rendimiento en el navegador con políticas de funciones, una función relativamente nueva que le permite
activar o desactivar ciertas funciones del navegador en su sitio. (Como nota al margen, también podría usarse para evitar imágenes de gran tamaño y sin optimizar, medios sin tamaño, secuencias de comandos de sincronización y otros). Actualmente compatible con navegadores basados en Blink. /* Via Tim Kadlec. https://timkadlec.com/remembers/2020-02-20-in-browser-performance-linting-with-feature-policies/ */ /* Block the use of the Geolocation API with a Feature-Policy header. */ Feature-Policy: geolocation 'none'/* Via Tim Kadlec. https://timkadlec.com/remembers/2020-02-20-in-browser-performance-linting-with-feature-policies/ */ /* Block the use of the Geolocation API with a Feature-Policy header. */ Feature-Policy: geolocation 'none'Dado que muchos scripts de terceros se ejecutan en iframes, es probable que deba ser minucioso al restringir sus asignaciones. Los iframes en espacio aislado siempre son una buena idea, y cada una de las limitaciones se puede eliminar a través de una serie de valores
allowen elsandboxde espacio aislado. Sandboxing es compatible en casi todas partes, por lo tanto, restrinja los scripts de terceros al mínimo de lo que se les debe permitir hacer.
ThirdPartyWeb.Today agrupa todos los scripts de terceros por categoría (análisis, redes sociales, publicidad, alojamiento, administrador de etiquetas, etc.) y visualiza cuánto tiempo tardan en ejecutarse los scripts de la entidad (en promedio). (Vista previa grande) Considere usar un Intersection Observer; eso permitiría que los anuncios se iframed mientras se envían eventos u obtienen la información que necesitan del DOM (por ejemplo, visibilidad de anuncios). Tenga cuidado con las nuevas políticas, como la política de funciones, los límites de tamaño de recursos y la prioridad de CPU/ancho de banda para limitar las funciones web dañinas y los scripts que ralentizarían el navegador, por ejemplo, scripts sincrónicos, solicitudes XHR sincrónicas, document.write e implementaciones obsoletas.
Finalmente, al elegir un servicio de terceros, considere consultar ThirdPartyWeb.Today de Patrick Hulce, un servicio que agrupa todos los scripts de terceros por categoría (análisis, redes sociales, publicidad, alojamiento, administrador de etiquetas, etc.) y visualiza cuánto duran los scripts de la entidad. tardan en ejecutarse (en promedio). Obviamente, las entidades más grandes tienen el peor impacto en el rendimiento de las páginas en las que se encuentran. Simplemente hojeando la página, obtendrá una idea de la huella de rendimiento que debería esperar.
Ah, y no se olvide de los sospechosos habituales: en lugar de widgets de terceros para compartir, podemos usar botones estáticos para compartir en redes sociales (como SSBG) y enlaces estáticos a mapas interactivos en lugar de mapas interactivos.
- Configure los encabezados de caché HTTP correctamente.
El almacenamiento en caché parece ser algo tan obvio que hacer, pero puede ser bastante difícil hacerlo bien. Necesitamos verificar queexpires,max-age,cache-controly otros encabezados de caché HTTP se hayan configurado correctamente. Sin los encabezados de caché HTTP adecuados, los navegadores los configurarán automáticamente al 10% del tiempo transcurrido desdelast-modified, lo que terminará con un posible almacenamiento insuficiente y excesivo de caché.En general, los recursos deben poder almacenarse en caché durante un tiempo muy corto (si es probable que cambien) o indefinidamente (si son estáticos); solo puede cambiar su versión en la URL cuando sea necesario. Puede llamarlo una estrategia Cache-Forever, en la que podríamos transmitir los encabezados
Cache-ControlyExpiresal navegador para permitir que los activos caduquen solo en un año. Por lo tanto, el navegador ni siquiera solicitaría el activo si lo tiene en el caché.La excepción son las respuestas de la API (por ejemplo
/api/user). Para evitar el almacenamiento en caché, podemos usarprivate, no storey nomax-age=0, no-store:Cache-Control: private, no-storeUse
Cache-control: immutablepara evitar la revalidación de tiempos de vida de caché explícitos prolongados cuando los usuarios presionan el botón de recarga. Para el caso de recarga,immutableguarda las solicitudes HTTP y mejora el tiempo de carga del HTML dinámico, ya que ya no compiten con la multitud de respuestas 304.Un ejemplo típico en el que queremos usar
immutableson los activos CSS/JavaScript con un hash en su nombre. Para ellos, probablemente queramos almacenar en caché el mayor tiempo posible y asegurarnos de que nunca se vuelvan a validar:Cache-Control: max-age: 31556952, immutableSegún la investigación de Colin Bendell,
immutablereduce los redireccionamientos 304 en alrededor de un 50 %, ya que incluso conmax-ageen uso, los clientes siguen revalidando y bloqueando al actualizar. Es compatible con Firefox, Edge y Safari y Chrome todavía está debatiendo el problema.Según Web Almanac, "su uso ha crecido hasta un 3,5 % y se utiliza mucho en las respuestas de terceros de Facebook y Google".

Cache-Control: Immutable reduce los 304 en alrededor de un 50 %, según la investigación de Colin Bendell en Cloudinary. (Vista previa grande) ¿Recuerdas el buen viejo mientras se revalida? Cuando especificamos el tiempo de almacenamiento en caché con el encabezado de respuesta
Cache-Control(p. ej.Cache-Control: max-age=604800), después de que expiremax-age, el navegador volverá a buscar el contenido solicitado, lo que hará que la página se cargue más lentamente. Esta ralentización se puede evitar constale-while-revalidate; básicamente define una ventana de tiempo adicional durante la cual un caché puede usar un activo obsoleto siempre que lo revalide de forma asíncrona en segundo plano. Por lo tanto, "oculta" la latencia (tanto en la red como en el servidor) de los clientes.En junio-julio de 2019, Chrome y Firefox lanzaron la compatibilidad con
stale-while-revalidateen el encabezado HTTP Cache-Control, por lo que, como resultado, debería mejorar las latencias de carga de páginas posteriores, ya que los activos obsoletos ya no se encuentran en la ruta crítica. Resultado: cero RTT para vistas repetidas.Tenga cuidado con el encabezado de variación, especialmente en relación con las CDN, y tenga cuidado con las variantes de representación HTTP que ayudan a evitar un viaje de ida y vuelta adicional para la validación cada vez que una nueva solicitud difiere levemente (pero no significativamente) de las solicitudes anteriores ( gracias, Guy y Mark ! ).
Además, verifique que no esté enviando encabezados innecesarios (por ejemplo
x-powered-by,pragma,x-ua-compatible,expires,X-XSS-Protectiony otros) y que incluya encabezados útiles de seguridad y rendimiento (como comoContent-Security-Policy,X-Content-Type-Optionsy otros). Finalmente, tenga en cuenta el costo de rendimiento de las solicitudes CORS en aplicaciones de una sola página.Nota : a menudo asumimos que los activos almacenados en caché se recuperan instantáneamente, pero la investigación muestra que recuperar un objeto del caché puede llevar cientos de milisegundos. De hecho, según Simon Hearne, "a veces, la red puede ser más rápida que el caché, y la recuperación de activos del caché puede ser costosa con una gran cantidad de activos almacenados en caché (no el tamaño del archivo) y los dispositivos del usuario. Por ejemplo: recuperación de caché promedio de Chrome OS se duplica desde ~50ms con 5 recursos en caché hasta ~100ms con 25 recursos".
Además, a menudo asumimos que el tamaño del paquete no es un gran problema y que los usuarios lo descargarán una vez y luego usarán la versión en caché. Al mismo tiempo, con CI/CD empujamos el código a producción varias veces al día, el caché se invalida cada vez, por lo que es importante ser estratégico con respecto al almacenamiento en caché.
Cuando se trata de almacenamiento en caché, hay muchos recursos que vale la pena leer:
- Cache-Control for Civilians, una inmersión profunda en todo el almacenamiento en caché con Harry Roberts.
- Manual básico de Heroku sobre encabezados de almacenamiento en caché HTTP,
- Mejores prácticas de almacenamiento en caché por Jake Archibald,
- Introducción al almacenamiento en caché de HTTP por Ilya Grigorik,
- Manteniendo las cosas frescas con obsoleto mientras se revalida por Jeff Posnick.
- CS Visualized: CORS de Lydia Hallie es una gran explicación sobre CORS, cómo funciona y cómo darle sentido.
- Hablando de CORS, aquí hay un pequeño repaso sobre la política del mismo origen de Eric Portis.
Optimizaciones de entrega
- ¿
deferpara cargar JavaScript crítico de forma asíncrona?
Cuando el usuario solicita una página, el navegador obtiene el HTML y construye el DOM, luego obtiene el CSS y construye el CSSOM, y luego genera un árbol de representación haciendo coincidir el DOM y el CSSOM. Si es necesario resolver algún JavaScript, el navegador no comenzará a mostrar la página hasta que se resuelva, lo que retrasará el procesamiento. Como desarrolladores, tenemos que decirle explícitamente al navegador que no espere y que comience a mostrar la página. La forma de hacer esto para los scripts es con los atributosdeferyasyncen HTML.En la práctica, resulta que es mejor usar
deferen lugar deasync. Ah, ¿cuál es la diferencia de nuevo? Según Steve Souders, una vez que llegan los scriptsasync, se ejecutan inmediatamente, tan pronto como el script está listo. Si eso sucede muy rápido, por ejemplo, cuando el script ya está en caché, en realidad puede bloquear el analizador HTML. Condefer, el navegador no ejecuta scripts hasta que se analiza HTML. Entonces, a menos que necesite ejecutar JavaScript antes de comenzar a renderizar, es mejor usardefer. Además, varios archivos asíncronos se ejecutarán en un orden no determinista.Vale la pena señalar que existen algunos conceptos erróneos sobre
asyncydefer. Lo que es más importante,asyncno significa que el código se ejecutará siempre que el script esté listo; significa que se ejecutará siempre que los scripts estén listos y todo el trabajo de sincronización anterior haya finalizado. En palabras de Harry Roberts: "Si coloca una secuencia de comandosasyncdespués de las secuencias de comandos de sincronización, su secuencia de comandosasyncserá tan rápida como la secuencia de comandos de sincronización más lenta".Además, no se recomienda usar tanto
asynccomodefer. Los navegadores modernos son compatibles con ambos, pero siempre que se usen ambos atributos,asyncsiempre ganará.Si desea profundizar en más detalles, Milica Mihajlija ha escrito una guía muy detallada sobre cómo construir el DOM más rápido, entrando en los detalles del análisis especulativo, asíncrono y diferido.
- Componentes caros de carga diferida con IntersectionObserver y sugerencias de prioridad.
En general, se recomienda cargar de forma diferida todos los componentes costosos, como JavaScript pesado, videos, iframes, widgets y potencialmente imágenes. La carga diferida nativa ya está disponible para imágenes e iframes con el atributo deloading(solo Chromium). Bajo el capó, este atributo difiere la carga del recurso hasta que alcanza una distancia calculada desde la ventana gráfica.<!-- Lazy loading for images, iframes, scripts. Probably for images outside of the viewport. --> <img loading="lazy" ... /> <iframe loading="lazy" ... /> <!-- Prompt an early download of an asset. For critical images, eg hero images. --> <img loading="eager" ... /> <iframe loading="eager" ... />Ese umbral depende de algunas cosas, desde el tipo de recurso de imagen que se obtiene hasta el tipo de conexión efectiva. Pero los experimentos realizados con Chrome en Android sugieren que en 4G, el 97,5 % de las imágenes de la parte inferior de la página que se cargan de forma diferida se cargaron por completo dentro de los 10 ms de volverse visibles, por lo que debería ser seguro.
También podemos usar el atributo de
importance(higholow) en un elemento<script>,<img>o<link>(solo parpadeo). De hecho, es una excelente manera de quitarle prioridad a las imágenes en los carruseles, así como a volver a priorizar las secuencias de comandos. Sin embargo, a veces es posible que necesitemos un poco más de control granular.<!-- When the browser assigns "High" priority to an image, but we don't actually want that. --> <img src="less-important-image.svg" importance="low" ... /> <!-- We want to initiate an early fetch for a resource, but also deprioritize it. --> <link rel="preload" importance="low" href="/script.js" as="script" />La forma más eficaz de realizar una carga diferida un poco más sofisticada es usar la API Intersection Observer, que proporciona una forma de observar de forma asincrónica los cambios en la intersección de un elemento de destino con un elemento antepasado o con la ventana gráfica de un documento de nivel superior. Básicamente, debe crear un nuevo objeto
IntersectionObserver, que recibe una función de devolución de llamada y un conjunto de opciones. Luego agregamos un objetivo para observar.La función de devolución de llamada se ejecuta cuando el objetivo se vuelve visible o invisible, por lo que cuando intercepta la ventana gráfica, puede comenzar a realizar algunas acciones antes de que el elemento se vuelva visible. De hecho, tenemos un control granular sobre cuándo se debe invocar la devolución de llamada del observador, con
rootMargin(margen alrededor de la raíz) ythreshold(un solo número o una matriz de números que indican a qué porcentaje de la visibilidad del objetivo estamos apuntando).Alejandro García Anglada ha publicado un práctico tutorial sobre cómo implementarlo realmente, Rahul Nanwani escribió una publicación detallada sobre la carga diferida de imágenes de primer plano y de fondo, y Google Fundamentals también proporciona un tutorial detallado sobre la carga diferida de imágenes y videos con Intersection Observer.
¿Recuerdas las lecturas largas de narración dirigida por el arte con objetos en movimiento y pegajosos? También puede implementar una narración de desplazamientos eficaz con Intersection Observer.
Comprueba de nuevo qué más podrías cargar de forma diferida. Incluso las cadenas de traducción de carga diferida y los emoji podrían ayudar. Al hacerlo, Mobile Twitter logró lograr una ejecución de JavaScript un 80 % más rápida a partir de la nueva canalización de internacionalización.
Sin embargo, una advertencia rápida: vale la pena señalar que la carga diferida debería ser una excepción y no la regla. Probablemente no sea razonable cargar de forma diferida cualquier cosa que realmente desee que la gente vea rápidamente, por ejemplo, imágenes de la página del producto, imágenes destacadas o un script necesario para que la navegación principal se vuelva interactiva.

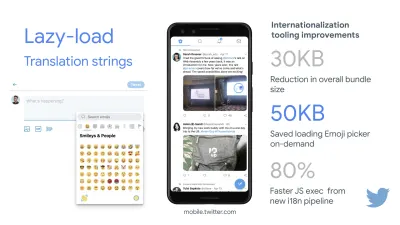
- Carga imágenes progresivamente.
Incluso podría llevar la carga diferida al siguiente nivel agregando la carga progresiva de imágenes a sus páginas. De manera similar a Facebook, Pinterest, Medium y Wolt, primero puede cargar imágenes de baja calidad o incluso borrosas, y luego, a medida que la página continúa cargando, reemplazarlas con las versiones de calidad completa utilizando la técnica BlurHash o LQIP (marcadores de posición de imagen de baja calidad) técnica.Las opiniones difieren si estas técnicas mejoran la experiencia del usuario o no, pero definitivamente mejora el tiempo de First Contentful Paint. Incluso podemos automatizarlo usando SQIP que crea una versión de baja calidad de una imagen como un marcador de posición SVG, o marcadores de posición de imagen degradada con degradados lineales CSS.
Estos marcadores de posición se pueden incrustar en HTML, ya que naturalmente se comprimen bien con los métodos de compresión de texto. En su artículo, Dean Hume ha descrito cómo se puede implementar esta técnica usando Intersection Observer.
¿Retroceder? Si el navegador no es compatible con el observador de intersecciones, aún podemos cargar un polyfill de forma diferida o cargar las imágenes de inmediato. E incluso hay una biblioteca para ello.
¿Quieres ir más elegante? Puede rastrear sus imágenes y usar formas y bordes primitivos para crear un marcador de posición SVG liviano, cargarlo primero y luego pasar de la imagen vectorial del marcador de posición a la imagen de mapa de bits (cargada).
- ¿Aplaza el renderizado con
content-visibility?
Para un diseño complejo con muchos bloques de contenido, imágenes y videos, la decodificación de datos y la representación de píxeles puede ser una operación bastante costosa, especialmente en dispositivos de gama baja. Concontent-visibility: auto, podemos indicarle al navegador que omita el diseño de los niños mientras el contenedor está fuera de la ventana gráfica.Por ejemplo, puede omitir la representación del pie de página y las últimas secciones en la carga inicial:
footer { content-visibility: auto; contain-intrinsic-size: 1000px; /* 1000px is an estimated height for sections that are not rendered yet. */ }Tenga en cuenta que content-visibility: auto; se comporta como desbordamiento: oculto; , pero puede solucionarlo aplicando
padding-leftypadding-righten lugar delmargin-left: auto;,margin-right: auto;y un ancho declarado. El relleno básicamente permite que los elementos se desborden del cuadro de contenido y entren en el cuadro de relleno sin dejar el modelo de cuadro como un todo y cortarlo.Además, tenga en cuenta que podría introducir algunos CLS cuando finalmente se renderice el contenido nuevo, por lo que es una buena idea utilizar
contain-intrinsic-sizecon un marcador de posición del tamaño adecuado ( ¡gracias, Una! ).Thijs Terluin tiene muchos más detalles sobre ambas propiedades y cómo el navegador calcula el
contain-intrinsic-size, Malte Ubl muestra cómo puede calcularlo y un breve video explicativo de Jake y Surma explica cómo funciona todo.Y si necesita obtener un poco más de granularidad, con CSS Containment, puede omitir manualmente el trabajo de diseño, estilo y pintura para los descendientes de un nodo DOM si solo necesita tamaño, alineación o estilos calculados en otros elementos, o si el elemento está actualmente fuera del lienzo.


content-visibility: auto a áreas de contenido fragmentado brinda un aumento de rendimiento de representación de 7 veces en la carga inicial. (Vista previa grande)- ¿Aplazas la decodificación con
decoding="async"?
A veces, el contenido aparece fuera de la pantalla, pero queremos asegurarnos de que esté disponible cuando los clientes lo necesiten; idealmente, sin bloquear nada en la ruta crítica, pero decodificando y renderizando de forma asíncrona. Podemos usardecoding="async"para otorgar al navegador permiso para decodificar la imagen del hilo principal, evitando el impacto del usuario en el tiempo de CPU utilizado para decodificar la imagen (a través de Malte Ubl):<img decoding="async" … />De forma alternativa, para las imágenes fuera de pantalla, podemos mostrar primero un marcador de posición y, cuando la imagen esté dentro de la ventana gráfica, mediante IntersectionObserver, active una llamada de red para que la imagen se descargue en segundo plano. Además, podemos diferir el procesamiento hasta la decodificación con img.decode() o descargar la imagen si la API de decodificación de imágenes no está disponible.
Al renderizar la imagen, podemos usar animaciones de aparición gradual, por ejemplo. Katie Hempenius y Addy Osmani comparten más información en su charla Speed at Scale: Web Performance Tips and Tricks from the Trenches.
- ¿Genera y sirve CSS crítico?
Para asegurarse de que los navegadores comiencen a mostrar su página lo más rápido posible, se ha convertido en una práctica común recopilar todo el CSS necesario para comenzar a mostrar la primera parte visible de la página (conocida como "CSS crítico" o "CSS en la mitad superior de la página"). ") e incluirlo en línea en el<head>de la página, reduciendo así los viajes de ida y vuelta. Debido al tamaño limitado de los paquetes intercambiados durante la fase de inicio lento, su presupuesto para CSS crítico es de alrededor de 14 KB.Si va más allá de eso, el navegador necesitará viajes de ida y vuelta adicionales para obtener más estilos. CriticalCSS y Critical le permiten generar CSS crítico para cada plantilla que esté utilizando. Sin embargo, en nuestra experiencia, ningún sistema automático fue mejor que la recopilación manual de CSS crítico para cada plantilla y, de hecho, ese es el enfoque al que hemos regresado recientemente.
A continuación, puede incluir CSS crítico en línea y cargar el resto de forma diferida con el complemento Webpack de critters. Si es posible, considere usar el enfoque de inserción condicional utilizado por Filament Group, o convierta el código en línea en activos estáticos sobre la marcha.
Si actualmente carga su CSS completo de forma asíncrona con bibliotecas como loadCSS, no es realmente necesario. Con
media="print", puede engañar al navegador para que obtenga el CSS de forma asíncrona pero se aplique al entorno de la pantalla una vez que se carga. ( ¡gracias Scott! )<!-- Via Scott Jehl. https://www.filamentgroup.com/lab/load-css-simpler/ --> <!-- Load CSS asynchronously, with low priority --> <link rel="stylesheet" href="full.css" media="print" onload="this.media='all'" />Al recopilar todo el CSS crítico para cada plantilla, es común explorar solo el área "en la mitad superior de la página". Sin embargo, para diseños complejos, podría ser una buena idea incluir la base del diseño también para evitar costos masivos de recálculo y repintado, lo que perjudicaría su puntuación de Core Web Vitals como resultado.
¿Qué sucede si un usuario obtiene una URL que se vincula directamente al medio de la página pero el CSS aún no se ha descargado? En ese caso, se ha vuelto común ocultar contenido no crítico, por ejemplo, con
opacity: 0;en CSS integrado yopacity: 1en el archivo CSS completo y mostrarlo cuando CSS esté disponible. Sin embargo, tiene una desventaja importante , ya que es posible que los usuarios con conexiones lentas nunca puedan leer el contenido de la página. Por eso es mejor mantener siempre visible el contenido, aunque no tenga el estilo adecuado.Poner CSS crítico (y otros activos importantes) en un archivo separado en el dominio raíz tiene beneficios, a veces incluso más que en línea, debido al almacenamiento en caché. Chrome abre especulativamente una segunda conexión HTTP al dominio raíz cuando solicita la página, lo que elimina la necesidad de una conexión TCP para obtener este CSS. Eso significa que puede crear un conjunto de archivos CSS críticos (p. ej., Critical- Homepage.css , Critical-Product-Page.css, etc.) y servirlos desde su raíz, sin tener que alinearlos. ( ¡gracias, Felipe! )
Una palabra de precaución: con HTTP/2, el CSS crítico podría almacenarse en un archivo CSS separado y entregarse a través de un servidor push sin inflar el HTML. El problema es que la inserción del servidor era problemática con muchas trampas y condiciones de carrera en todos los navegadores. Nunca fue compatible de manera constante y tuvo algunos problemas de almacenamiento en caché (consulte la diapositiva 114 en adelante de la presentación de Hooman Beheshti).
De hecho, el efecto podría ser negativo e inflar los búferes de la red, evitando que se entreguen marcos genuinos en el documento. Por lo tanto, no fue muy sorprendente que, por el momento, Chrome esté planeando eliminar la compatibilidad con Server Push.
- Experimente reagrupando sus reglas CSS.
Nos hemos acostumbrado al CSS crítico, pero hay algunas optimizaciones que podrían ir más allá. Harry Roberts realizó una investigación notable con resultados bastante sorprendentes. Por ejemplo, podría ser una buena idea dividir el archivo CSS principal en sus consultas de medios individuales. De esa forma, el navegador recuperará CSS crítico con alta prioridad y todo lo demás con baja prioridad, completamente fuera de la ruta crítica.Además, evite colocar
<link rel="stylesheet" />antes de los fragmentosasync. Si las secuencias de comandos no dependen de las hojas de estilo, considere colocar las secuencias de comandos de bloqueo sobre los estilos de bloqueo. Si lo hacen, divide ese JavaScript en dos y cárgalo a cada lado de tu CSS.Scott Jehl resolvió otro problema interesante al almacenar en caché un archivo CSS en línea con un trabajador de servicio, un problema común familiar si está utilizando CSS crítico. Básicamente, agregamos un atributo de ID al elemento de
stylepara que sea fácil encontrarlo usando JavaScript, luego una pequeña parte de JavaScript encuentra ese CSS y usa la API de caché para almacenarlo en un caché de navegador local (con un tipo de contenido detext/css) para su uso en páginas posteriores. Para evitar la inserción en páginas posteriores y, en su lugar, hacer referencia externa a los activos almacenados en caché, configuramos una cookie en la primera visita a un sitio. ¡Voila!Vale la pena señalar que el estilo dinámico también puede ser costoso, pero generalmente solo en los casos en que confía en cientos de componentes compuestos renderizados simultáneamente. Entonces, si está usando CSS-in-JS, asegúrese de que su biblioteca CSS-in-JS optimice la ejecución cuando su CSS no tenga dependencias en el tema o los accesorios, y no sobre-componga componentes con estilo . Aggelos Arvanitakis comparte más información sobre los costos de rendimiento de CSS-in-JS.
- ¿Transmite respuestas?
A menudo olvidados y descuidados, los flujos proporcionan una interfaz para leer o escribir fragmentos de datos asincrónicos, de los cuales solo un subconjunto podría estar disponible en la memoria en un momento dado. Básicamente, permiten que la página que realizó la solicitud original comience a trabajar con la respuesta tan pronto como esté disponible la primera parte de los datos, y utilizan analizadores optimizados para transmisión para mostrar progresivamente el contenido.Podríamos crear una transmisión a partir de múltiples fuentes. Por ejemplo, en lugar de servir un shell de interfaz de usuario vacío y permitir que JavaScript lo complete, puede permitir que el trabajador del servicio construya una secuencia donde el shell proviene de un caché, pero el cuerpo proviene de la red. Como señaló Jeff Posnick, si su aplicación web funciona con un CMS que el servidor procesa HTML uniendo plantillas parciales, ese modelo se traduce directamente en el uso de respuestas de transmisión, con la lógica de plantillas replicada en el trabajador del servicio en lugar de su servidor. El artículo The Year of Web Streams de Jake Archibald destaca cómo se puede construir exactamente. El aumento de rendimiento es bastante notable.
Una ventaja importante de la transmisión de la respuesta HTML completa es que el HTML representado durante la solicitud de navegación inicial puede aprovechar al máximo el analizador HTML de transmisión del navegador. Los fragmentos de HTML que se insertan en un documento después de que se haya cargado la página (como es común con el contenido que se completa a través de JavaScript) no pueden aprovechar esta optimización.
¿Soporte de navegador? Todavía estoy llegando con soporte parcial en Chrome, Firefox, Safari y Edge que admiten la API y Service Workers que se admiten en todos los navegadores modernos. Y si vuelve a sentirse aventurero, puede consultar una implementación experimental de solicitudes de transmisión, que le permite comenzar a enviar la solicitud mientras sigue generando el cuerpo. Disponible en cromo 85.
- Considere hacer que sus componentes reconozcan la conexión.
Los datos pueden ser costosos y con una carga útil cada vez mayor, debemos respetar a los usuarios que optan por ahorrar datos mientras acceden a nuestros sitios o aplicaciones. El encabezado de solicitud de sugerencia del cliente Save-Data nos permite personalizar la aplicación y la carga útil para usuarios con restricciones de costo y rendimiento.De hecho, puede reescribir las solicitudes de imágenes de alto DPI a imágenes de bajo DPI, eliminar fuentes web, efectos de paralaje sofisticados, previsualizar miniaturas y desplazamiento infinito, desactivar la reproducción automática de video, empujar el servidor, reducir la cantidad de elementos mostrados y degradar la calidad de la imagen, o incluso cambiar la forma en que entrega el marcado. Tim Vereecke ha publicado un artículo muy detallado sobre estrategias de ahorro de datos que presenta muchas opciones para guardar datos.
¿Quién está usando
save-data?, te estarás preguntando. El 18% de los usuarios globales de Android Chrome tienen habilitado el Modo Lite (conSave-Dataactivado), y es probable que el número sea mayor. Según la investigación de Simon Hearne, la tasa de aceptación es más alta en los dispositivos más baratos, pero hay muchos valores atípicos. Por ejemplo: los usuarios de Canadá tienen una tasa de aceptación de más del 34 % (en comparación con el ~7 % en los EE. UU.) y los usuarios del último buque insignia de Samsung tienen una tasa de aceptación de casi el 18 % a nivel mundial.Con el modo
Save-Dataactivado, Chrome Mobile brindará una experiencia optimizada, es decir, una experiencia web con proxy con secuencias de comandos diferidas ,font-display: swapy carga diferida forzada. Simplemente es más sensato crear la experiencia por su cuenta en lugar de confiar en el navegador para realizar estas optimizaciones.Actualmente, el encabezado solo es compatible con Chromium, en la versión Android de Chrome o a través de la extensión Data Saver en un dispositivo de escritorio. Finalmente, también puede usar la API de información de red para entregar costosos módulos de JavaScript, imágenes y videos de alta resolución según el tipo de red. La API de información de red y, específicamente,
navigator.connection.effectiveTypeusan valores deRTT,downlinky deeffectiveType(y algunos otros) para proporcionar una representación de la conexión y los datos que los usuarios pueden manejar.En este contexto, Max Bock habla de componentes conscientes de la conexión y Addy Osmani habla de servicio de módulos adaptativos. Por ejemplo, con React, podríamos escribir un componente que se represente de manera diferente para diferentes tipos de conexión. Como sugirió Max, un componente
<Media />en un artículo de noticias podría generar:-
Offline: un marcador de posición con textoalt, - Modo
2G/save-data: una imagen de baja resolución, -
3Gen pantalla no Retina: una imagen de resolución media, -
3Gen pantallas Retina: imagen Retina de alta resolución, -
4G: un vídeo HD.
Dean Hume proporciona una implementación práctica de una lógica similar utilizando un trabajador de servicio. Para un video, podríamos mostrar un póster de video de manera predeterminada y luego mostrar el ícono "Reproducir", así como el shell del reproductor de video, los metadatos del video, etc. en mejores conexiones. Como alternativa para los navegadores que no son compatibles, podríamos escuchar el evento
canplaythroughy usarPromise.race()para agotar el tiempo de carga de la fuente si el eventocanplaythroughno se activa en 2 segundos.Si desea profundizar un poco más, aquí hay un par de recursos para comenzar:
- Addy Osmani muestra cómo implementar el servicio adaptable en React.
- React Adaptive Loading Hooks & Utilities proporciona fragmentos de código para React,
- Netanel Basel explora los componentes conscientes de la conexión en Angular,
- Theodore Vorilas comparte cómo funciona el servicio de componentes adaptables mediante la API de información de red en Vue.
- Umar Hansa muestra cómo descargar/ejecutar JavaScript costoso de forma selectiva.
-
- Considere hacer que su dispositivo de componentes reconozca la memoria.
Sin embargo, la conexión de red nos da solo una perspectiva en el contexto del usuario. Yendo más allá, también puede ajustar dinámicamente los recursos en función de la memoria disponible del dispositivo, con la API de memoria del dispositivo.navigator.deviceMemoryreturns how much RAM the device has in gigabytes, rounded down to the nearest power of two. The API also features a Client Hints Header,Device-Memory, that reports the same value.Bonus : Umar Hansa shows how to defer expensive scripts with dynamic imports to change the experience based on device memory, network connectivity and hardware concurrency.
- Warm up the connection to speed up delivery.
Use resource hints to save time ondns-prefetch(which performs a DNS lookup in the background),preconnect(which asks the browser to start the connection handshake (DNS, TCP, TLS) in the background),prefetch(which asks the browser to request a resource) andpreload(which prefetches resources without executing them, among other things). Well supported in modern browsers, with support coming to Firefox soon.Remember
prerender? The resource hint used to prompt browser to build out the entire page in the background for next navigation. The implementations issues were quite problematic, ranging from a huge memory footprint and bandwidth usage to multiple registered analytics hits and ad impressions.Unsurprinsingly, it was deprecated, but the Chrome team has brought it back as NoState Prefetch mechanism. In fact, Chrome treats the
prerenderhint as a NoState Prefetch instead, so we can still use it today. As Katie Hempenius explains in that article, "like prerendering, NoState Prefetch fetches resources in advance ; but unlike prerendering, it does not execute JavaScript or render any part of the page in advance."NoState Prefetch only uses ~45MiB of memory and subresources that are fetched will be fetched with an
IDLENet Priority. Since Chrome 69, NoState Prefetch adds the header Purpose: Prefetch to all requests in order to make them distinguishable from normal browsing.Also, watch out for prerendering alternatives and portals, a new effort toward privacy-conscious prerendering, which will provide the inset
previewof the content for seamless navigations.Using resource hints is probably the easiest way to boost performance , and it works well indeed. When to use what? As Addy Osmani has explained, it's reasonable to preload resources that we know are very likely to be used on the current page and for future navigations across multiple navigation boundaries, eg Webpack bundles needed for pages the user hasn't visited yet.
Addy's article on "Loading Priorities in Chrome" shows how exactly Chrome interprets resource hints, so once you've decided which assets are critical for rendering, you can assign high priority to them. To see how your requests are prioritized, you can enable a "priority" column in the Chrome DevTools network request table (as well as Safari).
Most of the time these days, we'll be using at least
preconnectanddns-prefetch, and we'll be cautious with usingprefetch,preloadandprerender. Note that even withpreconnectanddns-prefetch, the browser has a limit on the number of hosts it will look up/connect to in parallel, so it's a safe bet to order them based on priority ( thanks Philip Tellis! ).Since fonts usually are important assets on a page, sometimes it's a good idea to request the browser to download critical fonts with
preload. However, double check if it actually helps performance as there is a puzzle of priorities when preloading fonts: aspreloadis seen as high importance, it can leapfrog even more critical resources like critical CSS. ( thanks, Barry! )<!-- Loading two rendering-critical fonts, but not all their weights. --> <!-- crossorigin="anonymous" is required due to CORS. Without it, preloaded fonts will be ignored. https://github.com/w3c/preload/issues/32 via https://twitter.com/iamakulov/status/1275790151642423303 --> <link rel="preload" as="font" href="Elena-Regular.woff2" type="font/woff2" crossorigin="anonymous" media="only screen and (min-width: 48rem)" /> <link rel="preload" as="font" href="Mija-Bold.woff2" type="font/woff2" crossorigin="anonymous" media="only screen and (min-width: 48rem)" /><!-- Loading two rendering-critical fonts, but not all their weights. --> <!-- crossorigin="anonymous" is required due to CORS. Without it, preloaded fonts will be ignored. https://github.com/w3c/preload/issues/32 via https://twitter.com/iamakulov/status/1275790151642423303 --> <link rel="preload" as="font" href="Elena-Regular.woff2" type="font/woff2" crossorigin="anonymous" media="only screen and (min-width: 48rem)" /> <link rel="preload" as="font" href="Mija-Bold.woff2" type="font/woff2" crossorigin="anonymous" media="only screen and (min-width: 48rem)" />Since
<link rel="preload">accepts amediaattribute, you could choose to selectively download resources based on@mediaquery rules, as shown above.Furthermore, we can use
imagesrcsetandimagesizesattributes to preload late-discovered hero images faster, or any images that are loaded via JavaScript, eg movie posters:<!-- Addy Osmani. https://addyosmani.com/blog/preload-hero-images/ --> <link rel="preload" as="image" href="poster.jpg" image image><!-- Addy Osmani. https://addyosmani.com/blog/preload-hero-images/ --> <link rel="preload" as="image" href="poster.jpg" image image>We can also preload the JSON as fetch , so it's discovered before JavaScript gets to request it:
<!-- Addy Osmani. https://addyosmani.com/blog/preload-hero-images/ --> <link rel="preload" as="fetch" href="foo.com/api/movies.json" crossorigin>We could also load JavaScript dynamically, effectively for lazy execution of the script.
/* Adding a preload hint to the head */ var preload = document.createElement("link"); link.href = "myscript.js"; link.rel = "preload"; link.as = "script"; document.head.appendChild(link); /* Injecting a script when we want it to execute */ var script = document.createElement("script"); script.src = "myscript.js"; document.body.appendChild(script);A few gotchas to keep in mind:
preloadis good for moving the start download time of an asset closer to the initial request, but preloaded assets land in the memory cache which is tied to the page making the request.preloadplays well with the HTTP cache: a network request is never sent if the item is already there in the HTTP cache.Hence, it's useful for late-discovered resources, hero images loaded via
background-image, inlining critical CSS (or JavaScript) and pre-loading the rest of the CSS (or JavaScript).
Preload important images early; no need to wait on JavaScript to discover them. (Image credit: “Preload Late-Discovered Hero Images Faster” by Addy Osmani) (Large preview) A
preloadtag can initiate a preload only after the browser has received the HTML from the server and the lookahead parser has found thepreloadtag. Preloading via the HTTP header could be a bit faster since we don't to wait for the browser to parse the HTML to start the request (it's debated though).Early Hints will help even further, enabling preload to kick in even before the response headers for the HTML are sent (on the roadmap in Chromium, Firefox). Plus, Priority Hints will help us indicate loading priorities for scripts.
Beware : if you're using
preload,asmust be defined or nothing loads, plus preloaded fonts without thecrossoriginattribute will double fetch. If you're usingprefetch, beware of theAgeheader issues in Firefox.
- Use service workers for caching and network fallbacks.
No performance optimization over a network can be faster than a locally stored cache on a user's machine (there are exceptions though). If your website is running over HTTPS, we can cache static assets in a service worker cache and store offline fallbacks (or even offline pages) and retrieve them from the user's machine, rather than going to the network.As suggested by Phil Walton, with service workers, we can send smaller HTML payloads by programmatically generating our responses. A service worker can request just the bare minimum of data it needs from the server (eg an HTML content partial, a Markdown file, JSON data, etc.), and then it can programmatically transform that data into a full HTML document. So once a user visits a site and the service worker is installed, the user will never request a full HTML page again. The performance impact can be quite impressive.
Browser support? Service workers are widely supported and the fallback is the network anyway. Does it help boost performance ? Oh yes, it does. And it's getting better, eg with Background Fetch allowing background uploads/downloads via a service worker as well.
There are a number of use cases for a service worker. For example, you could implement "Save for offline" feature, handle broken images, introduce messaging between tabs or provide different caching strategies based on request types. In general, a common reliable strategy is to store the app shell in the service worker's cache along with a few critical pages, such as offline page, frontpage and anything else that might be important in your case.
There are a few gotchas to keep in mind though. With a service worker in place, we need to beware range requests in Safari (if you are using Workbox for a service worker it has a range request module). If you ever stumbled upon
DOMException: Quota exceeded.error in the browser console, then look into Gerardo's article When 7KB equals 7MB.Como escribe Gerardo: "Si está creando una aplicación web progresiva y está experimentando un almacenamiento de caché inflado cuando su trabajador de servicio almacena en caché activos estáticos servidos desde CDN, asegúrese de que exista el encabezado de respuesta CORS adecuado para recursos de origen cruzado, no almacene en caché respuestas opacas con su trabajador de servicio sin querer, opta por activos de imagen de origen cruzado en el modo
crossoriginagregando el atributo de origen cruzado a la etiqueta<img>".Hay muchos recursos excelentes para comenzar con los trabajadores de servicios:
- Mentalidad de trabajador de servicios, que lo ayuda a comprender cómo trabajan los trabajadores de servicios detrás de escena y las cosas que debe comprender al crear uno.
- Chris Ferdinandi proporciona una gran serie de artículos sobre trabajadores de servicios, que explican cómo crear aplicaciones sin conexión y cubren una variedad de escenarios, desde guardar páginas vistas recientemente sin conexión hasta establecer una fecha de caducidad para elementos en un caché de trabajadores de servicios.
- Dificultades y prácticas recomendadas de Service Worker, con algunos consejos sobre el alcance, retrasando el registro de un Service Worker y el almacenamiento en caché de Service Worker.
- Gran serie de Ire Aderinokun sobre "Offline First" con Service Worker, con una estrategia de almacenamiento previo en caché del shell de la aplicación.
- Service Worker: una introducción con consejos prácticos sobre cómo usar Service Worker para disfrutar de ricas experiencias fuera de línea, sincronizaciones periódicas en segundo plano y notificaciones automáticas.
- Siempre vale la pena consultar el libro de cocina fuera de línea de Jake Archibald con una serie de recetas sobre cómo hornear su propio trabajador de servicio.
- Workbox es un conjunto de bibliotecas de trabajadores de servicios creadas específicamente para crear aplicaciones web progresivas.
- ¿Está ejecutando trabajadores de servidores en CDN/Edge, por ejemplo, para pruebas A/B?
En este punto, estamos bastante acostumbrados a ejecutar trabajadores de servicio en el cliente, pero con CDN implementándolos en el servidor, también podríamos usarlos para modificar el rendimiento en el perímetro.Por ejemplo, en las pruebas A/B, cuando HTML necesita variar su contenido para diferentes usuarios, podríamos usar Service Workers en los servidores CDN para manejar la lógica. También podríamos transmitir la reescritura de HTML para acelerar los sitios que usan Google Fonts.
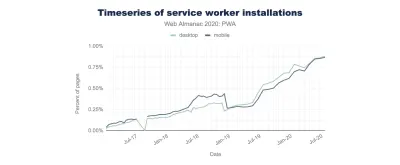
- Optimizar el rendimiento de renderizado.
Cada vez que la aplicación es lenta, se nota de inmediato. Por lo tanto, debemos asegurarnos de que no haya demoras al desplazarse por la página o cuando se anima un elemento, y que esté alcanzando constantemente los 60 cuadros por segundo. Si eso no es posible, al menos hacer que los cuadros por segundo sean consistentes es preferible a un rango mixto de 60 a 15. Use elwill-changede CSS para informar al navegador qué elementos y propiedades cambiarán.Siempre que esté experimentando, depure los repintados innecesarios en DevTools:
- Mida el rendimiento de representación en tiempo de ejecución. Consulte algunos consejos útiles sobre cómo darle sentido.
- Para comenzar, consulte el curso gratuito de Udacity de Paul Lewis sobre optimización de la representación del navegador y el artículo de Georgy Marchuk sobre pintura del navegador y consideraciones para el rendimiento web.
- Habilite Paint Flashing en "Más herramientas → Representación → Paint Flashing" en Firefox DevTools.
- En React DevTools, marque "Resaltar actualizaciones" y habilite "Registrar por qué se renderizó cada componente",
- También puede usar Why Did You Render, de modo que cuando se vuelva a renderizar un componente, un flash le notificará el cambio.
¿Está utilizando un diseño de mampostería? Tenga en cuenta que es posible que pueda crear un diseño de mampostería solo con la cuadrícula CSS, muy pronto.
Si desea profundizar en el tema, Nolan Lawson ha compartido trucos para medir con precisión el rendimiento del diseño en su artículo, y Jason Miller también sugirió técnicas alternativas. También tenemos un pequeño artículo de Sergey Chikuyonok sobre cómo obtener una animación GPU correcta.

Los navegadores pueden animar la transformación y la opacidad de forma económica. CSS Triggers es útil para verificar si CSS activa rediseños o reflujos. (Crédito de la imagen: Addy Osmani)(Vista previa grande) Nota : los cambios en las capas compuestas por GPU son los menos costosos, por lo que si puede activar solo la composición a través de la
opacityytransform, estará en el camino correcto. Anna Migas también brindó muchos consejos prácticos en su charla sobre la depuración del rendimiento de representación de la interfaz de usuario. Y para comprender cómo depurar el rendimiento de pintura en DevTools, consulte el video de auditoría de rendimiento de pintura de Umar. - ¿Ha optimizado para el rendimiento percibido?
Si bien la secuencia de cómo aparecen los componentes en la página y la estrategia de cómo entregamos los activos al navegador son importantes, no debemos subestimar también el papel del rendimiento percibido. El concepto trata los aspectos psicológicos de la espera, básicamente manteniendo a los clientes ocupados o comprometidos mientras sucede otra cosa. Ahí es donde entran en juego la gestión de la percepción, el inicio preventivo, la finalización anticipada y la gestión de la tolerancia.Que significa todo esto? Mientras cargamos activos, podemos tratar de estar siempre un paso por delante del cliente, para que la experiencia se sienta rápida mientras suceden muchas cosas en segundo plano. Para mantener al cliente comprometido, podemos probar pantallas esqueléticas (demostración de implementación) en lugar de cargar indicadores, agregar transiciones/animaciones y básicamente engañar a la UX cuando no hay nada más que optimizar.
En su estudio de caso sobre The Art of UI Skeletons, Kumar McMillan comparte algunas ideas y técnicas sobre cómo simular listas dinámicas, texto y la pantalla final, así como también cómo considerar el pensamiento de esqueleto con React.
Sin embargo, tenga cuidado: las pantallas de esqueleto deben probarse antes de implementarse, ya que algunas pruebas mostraron que las pantallas de esqueleto pueden funcionar peor según todas las métricas.
- ¿Evita cambios de diseño y repintados?
En el ámbito del rendimiento percibido, probablemente una de las experiencias más perturbadoras es el cambio de diseño , o reflujos , causados por imágenes y videos reescalados, fuentes web, anuncios inyectados o secuencias de comandos descubiertas tardíamente que llenan los componentes con contenido real. Como resultado, un cliente podría comenzar a leer un artículo solo para ser interrumpido por un salto de diseño sobre el área de lectura. La experiencia suele ser abrupta y bastante desorientadora: y eso es probablemente un caso de prioridades de carga que deben reconsiderarse.La comunidad ha desarrollado un par de técnicas y soluciones para evitar reflujos. En general, es una buena idea evitar insertar contenido nuevo sobre contenido existente , a menos que suceda en respuesta a una interacción del usuario. Establezca siempre los atributos de ancho y alto en las imágenes, para que los navegadores modernos asignen el cuadro y reserven el espacio de forma predeterminada (Firefox, Chrome).
Tanto para imágenes como para videos, podemos usar un marcador de posición SVG para reservar el cuadro de visualización en el que aparecerán los medios. Eso significa que el área se reservará correctamente cuando también necesite mantener su relación de aspecto. También podemos usar marcadores de posición o imágenes alternativas para anuncios y contenido dinámico, así como preasignar espacios de diseño.
En lugar de imágenes de carga diferida con secuencias de comandos externas, considere usar la carga diferida nativa o la carga diferida híbrida cuando cargamos una secuencia de comandos externa solo si la carga diferida nativa no es compatible.
Como se mencionó anteriormente, siempre agrupe los repintados de fuentes web y la transición de todas las fuentes alternativas a todas las fuentes web a la vez; solo asegúrese de que ese cambio no sea demasiado abrupto, ajustando la altura de línea y el espacio entre las fuentes con font-style-matcher .
Para anular las métricas de fuente para que una fuente alternativa emule una fuente web, podemos usar los descriptores @font-face para anular las métricas de fuente (demostración, habilitado en Chrome 87). (Tenga en cuenta que los ajustes son complicados con pilas de fuentes complicadas).
Para el CSS tardío, podemos asegurarnos de que el CSS crítico para el diseño esté integrado en el encabezado de cada plantilla. Incluso más allá de eso: para páginas largas, cuando se agrega la barra de desplazamiento vertical, desplaza el contenido principal 16px hacia la izquierda. Para mostrar una barra de desplazamiento antes, podemos agregar
overflow-y: scrollenhtmlpara aplicar una barra de desplazamiento en la primera pintura. Esto último ayuda porque las barras de desplazamiento pueden causar cambios de diseño no triviales debido a que el contenido de la parte superior del pliegue se redistribuye cuando cambia el ancho. Sin embargo, debería ocurrir principalmente en plataformas con barras de desplazamiento no superpuestas como Windows. Pero: rompe laposition: stickyporque esos elementos nunca se desplazarán fuera del contenedor.Si trabaja con encabezados que se vuelven fijos o fijos en la parte superior de la página al desplazarse, reserve espacio para el encabezado cuando se pinee, por ejemplo, con un elemento de marcador de posición o
margin-topen el contenido. Una excepción deberían ser los banners de consentimiento de cookies que no deberían tener impacto en CLS, pero a veces lo hacen: depende de la implementación. Hay algunas estrategias interesantes y conclusiones en este hilo de Twitter.Para un componente de pestaña que puede incluir varias cantidades de textos, puede evitar cambios de diseño con pilas de cuadrícula CSS. Al colocar el contenido de cada pestaña en la misma área de cuadrícula y ocultar una de ellas a la vez, podemos asegurarnos de que el contenedor siempre tome la altura del elemento más grande, por lo que no se producirán cambios de diseño.
Ah, y por supuesto, el desplazamiento infinito y "Cargar más" también pueden causar cambios de diseño si hay contenido debajo de la lista (por ejemplo, pie de página). Para mejorar CLS, reserve suficiente espacio para el contenido que se cargaría antes de que el usuario se desplace a esa parte de la página, elimine el pie de página o cualquier elemento DOM en la parte inferior de la página que pueda ser empujado hacia abajo por la carga del contenido. Además, precargar datos e imágenes para el contenido de la mitad inferior de la página, de modo que cuando un usuario se desplace hasta ese punto, ya esté allí. También puede usar bibliotecas de virtualización de listas como react-window para optimizar listas largas ( ¡gracias, Addy Osmani! ).
Para asegurarse de contener el impacto de los reflujos, mida la estabilidad del diseño con la API de inestabilidad del diseño. Con él, puede calcular el puntaje de Cambio de diseño acumulativo ( CLS ) e incluirlo como un requisito en sus pruebas, por lo que cada vez que aparece una regresión, puede rastrearla y corregirla.
Para calcular la puntuación de cambio de diseño, el navegador observa el tamaño de la ventana gráfica y el movimiento de elementos inestables en la ventana gráfica entre dos marcos renderizados. Idealmente, la puntuación sería cercana a
0. Hay una gran guía de Milica Mihajlija y Philip Walton sobre qué es CLS y cómo medirlo. Es un buen punto de partida para medir y mantener el rendimiento percibido y evitar interrupciones, especialmente para tareas críticas para el negocio.Sugerencia rápida : para descubrir qué causó un cambio de diseño en DevTools, puede explorar los cambios de diseño en "Experiencia" en el Panel de rendimiento.
Bonificación : si desea reducir los reflujos y los repintados, consulte la guía de Charis Theodoulou para Minimizar DOM Reflow/Layout Thrashing y la lista de Paul Irish de Qué fuerza el diseño/reflujo, así como CSSTriggers.com, una tabla de referencia sobre las propiedades de CSS que activan el diseño, la pintura y composición.
Redes y HTTP/2
- ¿Está habilitado el grapado OCSP?
Al habilitar el engrapado OCSP en su servidor, puede acelerar sus protocolos de enlace TLS. El Protocolo de estado de certificados en línea (OCSP) se creó como una alternativa al protocolo de Lista de revocación de certificados (CRL). Ambos protocolos se utilizan para comprobar si se ha revocado un certificado SSL.Sin embargo, el protocolo OCSP no requiere que el navegador dedique tiempo a descargar y luego buscar en una lista la información del certificado, lo que reduce el tiempo requerido para un apretón de manos.
- ¿Ha reducido el impacto de la revocación del certificado SSL?
En su artículo sobre "El costo de rendimiento de los certificados EV", Simon Hearne brinda una excelente descripción general de los certificados comunes y el impacto que puede tener la elección de un certificado en el rendimiento general.Como escribe Simon, en el mundo de HTTPS, existen algunos tipos de niveles de validación de certificados que se utilizan para proteger el tráfico:
- La validación de dominio (DV) valida que el solicitante del certificado es propietario del dominio,
- La validación de la organización (OV) valida que una organización es propietaria del dominio,
- Extended Validation (EV) valida que una organización es propietaria del dominio, con una validación rigurosa.
Es importante tener en cuenta que todos estos certificados son iguales en términos de tecnología; sólo difieren en la información y propiedades proporcionadas en dichos certificados.
Los certificados EV son costosos y consumen mucho tiempo, ya que requieren que una persona revise un certificado y garantice su validez. Los certificados DV, por otro lado, a menudo se proporcionan de forma gratuita, por ejemplo, Let's Encrypt, una autoridad de certificación abierta y automatizada que está bien integrada en muchos proveedores de alojamiento y CDN. De hecho, en el momento de escribir este artículo, funciona con más de 225 millones de sitios web (PDF), aunque solo representa el 2,69 % de las páginas (abiertas en Firefox).
Entonces, ¿cuál es el problema entonces? El problema es que los certificados EV no son totalmente compatibles con el grapado OCSP mencionado anteriormente. Si bien el grapado permite que el servidor verifique con la autoridad de certificación si el certificado ha sido revocado y luego agrega ("grapa") esta información al certificado, sin grapar, el cliente tiene que hacer todo el trabajo, lo que genera solicitudes innecesarias durante la negociación de TLS. . En conexiones deficientes, esto podría terminar con costos de rendimiento notables (más de 1000 ms).
Los certificados EV no son una buena opción para el rendimiento web y pueden causar un impacto mucho mayor en el rendimiento que los certificados DV. Para un rendimiento web óptimo, presente siempre un certificado DV grapado de OCSP. También son mucho más baratos que los certificados EV y menos complicados de adquirir. Bueno, al menos hasta que CRLite esté disponible.
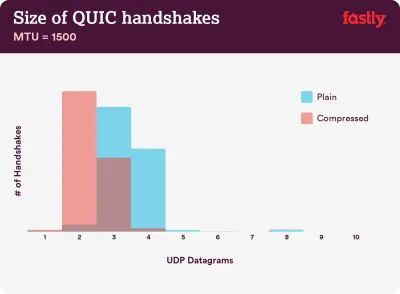
La compresión es importante: entre el 40 % y el 43 % de las cadenas de certificados sin comprimir son demasiado grandes para caber en un solo vuelo QUIC de 3 datagramas UDP. (Crédito de la imagen:) Fastly) (Vista previa grande) Nota : Con QUIC/HTTP/3 sobre nosotros, vale la pena señalar que la cadena de certificados TLS es el único contenido de tamaño variable que domina el conteo de bytes en QUIC Handshake. El tamaño varía entre unos cientos de byes y más de 10 KB.
Por lo tanto, mantener los certificados TLS pequeños importa mucho en QUIC/HTTP/3, ya que los certificados grandes provocarán múltiples protocolos de enlace. Además, debemos asegurarnos de que los certificados estén comprimidos, ya que, de lo contrario, las cadenas de certificados serían demasiado grandes para caber en un solo vuelo QUIC.
Puede encontrar muchos más detalles e indicaciones sobre el problema y las soluciones en:
- Los certificados EV hacen que la Web sea lenta y poco confiable por Aaron Peters,
- El impacto de la revocación del certificado SSL en el rendimiento web por Matt Hobbs,
- El costo de desempeño de los certificados EV por Simon Hearne,
- ¿El apretón de manos QUIC requiere compresión para ser rápido? por Patrick McManus.
- ¿Ya ha adoptado IPv6?
Debido a que nos estamos quedando sin espacio con IPv4 y las principales redes móviles están adoptando IPv6 rápidamente (EE. UU. casi ha alcanzado un umbral de adopción de IPv6 del 50 %), es una buena idea actualizar su DNS a IPv6 para mantenerse a prueba de balas en el futuro. Solo asegúrese de que se brinde soporte de doble pila en toda la red: permite que IPv6 e IPv4 se ejecuten simultáneamente uno al lado del otro. Después de todo, IPv6 no es compatible con versiones anteriores. Además, los estudios muestran que IPv6 hizo que esos sitios web fueran entre un 10 y un 15 % más rápidos debido al descubrimiento de vecinos (NDP) y la optimización de rutas. - Asegúrese de que todos los recursos se ejecuten a través de HTTP/2 (o HTTP/3).
Con Google empujando hacia una web HTTPS más segura en los últimos años, cambiar al entorno HTTP/2 es definitivamente una buena inversión. De hecho, según Web Almanac, el 64% de todas las solicitudes ya se ejecutan a través de HTTP/2.Es importante comprender que HTTP/2 no es perfecto y tiene problemas de priorización, pero se admite muy bien; y, en la mayoría de los casos, es mejor que lo hagas.
Una palabra de precaución: HTTP/2 Server Push se está eliminando de Chrome, por lo que si su implementación se basa en Server Push, es posible que deba volver a visitarlo. En su lugar, podríamos estar mirando Early Hints, que ya están integrados como experimento en Fastly.
Si aún utiliza HTTP, la tarea que más tiempo consumirá será migrar primero a HTTPS y luego ajustar su proceso de compilación para atender la multiplexación y paralelización de HTTP/2. Llevar HTTP/2 a Gov.uk es un estudio de caso fantástico sobre cómo hacer exactamente eso, encontrar una forma de hacerlo a través de CORS, SRI y WPT en el camino. Para el resto de este artículo, asumimos que está cambiando o ya ha cambiado a HTTP/2.
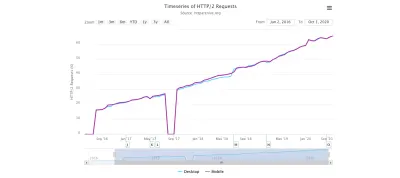
- Implemente correctamente HTTP/2.
Una vez más, la entrega de activos a través de HTTP/2 puede beneficiarse de una revisión parcial de cómo ha estado entregando los activos hasta ahora. Deberá encontrar un buen equilibrio entre empaquetar módulos y cargar muchos módulos pequeños en paralelo. Al final del día, la mejor solicitud sigue siendo no solicitar, sin embargo, el objetivo es encontrar un buen equilibrio entre la primera entrega rápida de activos y el almacenamiento en caché.Por un lado, es posible que desee evitar la concatenación de activos por completo, en lugar de dividir toda la interfaz en muchos módulos pequeños, comprimiéndolos como parte del proceso de compilación y cargándolos en paralelo. Un cambio en un archivo no requerirá que se vuelva a descargar toda la hoja de estilo o JavaScript. También minimiza el tiempo de análisis y mantiene bajas las cargas útiles de las páginas individuales.
Por otro lado, el embalaje sigue siendo importante. Al usar muchos scripts pequeños, la compresión general se verá afectada y aumentará el costo de recuperar objetos del caché. La compresión de un paquete grande se beneficiará de la reutilización del diccionario, mientras que los paquetes separados pequeños no lo harán. Hay trabajo estándar para abordar eso, pero está muy lejos por ahora. En segundo lugar, los navegadores aún no se han optimizado para tales flujos de trabajo. Por ejemplo, Chrome activará las comunicaciones entre procesos (IPC) lineales a la cantidad de recursos, por lo que incluir cientos de recursos tendrá costos de tiempo de ejecución del navegador.
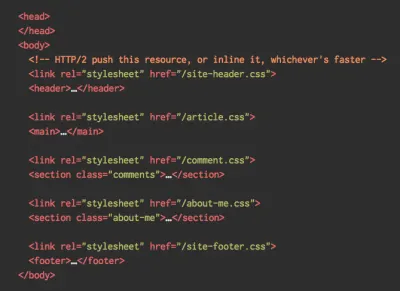
Para lograr los mejores resultados con HTTP/2, considere cargar CSS progresivamente, como lo sugiere Jake Archibald de Chrome. Aún así, puedes intentar cargar CSS progresivamente. De hecho, el CSS integrado ya no bloquea el renderizado para Chrome. Pero hay algunos problemas de priorización, por lo que no es tan sencillo, pero vale la pena experimentar con ellos.
Podría salirse con la suya con la fusión de conexiones HTTP/2, lo que le permite usar la fragmentación del dominio mientras se beneficia de HTTP/2, pero lograr esto en la práctica es difícil y, en general, no se considera una buena práctica. Además, HTTP/2 y la integridad de los subrecursos no siempre funcionan.
¿Qué hacer? Bueno, si utiliza HTTP/2, enviar alrededor de 6 a 10 paquetes parece un compromiso decente (y no es tan malo para los navegadores heredados). Experimente y mida para encontrar el equilibrio adecuado para su sitio web.
- ¿Enviamos todos los activos a través de una única conexión HTTP/2?
Una de las principales ventajas de HTTP/2 es que nos permite enviar activos por cable a través de una sola conexión. Sin embargo, a veces es posible que hayamos hecho algo mal, por ejemplo, tener un problema de CORS o configurar incorrectamente el atributocrossorigin, por lo que el navegador se vería obligado a abrir una nueva conexión.Para verificar si todas las solicitudes usan una única conexión HTTP/2 o si algo está mal configurado, habilite la columna "ID de conexión" en DevTools → Red. Por ejemplo, aquí, todas las solicitudes comparten la misma conexión (286), excepto manifest.json, que abre una separada (451).
- ¿Sus servidores y CDN son compatibles con HTTP/2?
Diferentes servidores y CDN (todavía) admiten HTTP/2 de manera diferente. Utilice la comparación de CDN para comprobar sus opciones o busque rápidamente el rendimiento de sus servidores y las funciones que puede esperar que sean compatibles.Consulte la increíble investigación de Pat Meenan sobre las prioridades de HTTP/2 (video) y pruebe la compatibilidad del servidor con la priorización de HTTP/2. Según Pat, se recomienda habilitar el control de congestión de BBR y establecer
tcp_notsent_lowaten 16 KB para que la priorización de HTTP/2 funcione de manera confiable en kernels de Linux 4.9 y posteriores ( ¡gracias, Yoav! ). Andy Davies realizó una investigación similar para la priorización de HTTP/2 en navegadores, CDN y servicios de alojamiento en la nube.Mientras está en él, verifique dos veces si su kernel admite TCP BBR y habilítelo si es posible. Actualmente se usa en Google Cloud Platform, Amazon Cloudfront, Linux (por ejemplo, Ubuntu).
- ¿Está en uso la compresión HPACK?
Si está utilizando HTTP/2, verifique que sus servidores implementen la compresión HPACK para los encabezados de respuesta HTTP para reducir la sobrecarga innecesaria. Es posible que algunos servidores HTTP/2 no admitan completamente la especificación, siendo HPACK un ejemplo. H2spec es una gran herramienta (aunque muy técnicamente detallada) para verificar eso. El algoritmo de compresión de HPACK es bastante impresionante y funciona. - Asegúrese de que la seguridad de su servidor sea infalible.
Todas las implementaciones de navegador de HTTP/2 se ejecutan sobre TLS, por lo que probablemente querrá evitar las advertencias de seguridad o que algunos elementos de su página no funcionen. Vuelva a verificar que sus encabezados de seguridad estén configurados correctamente, elimine las vulnerabilidades conocidas y verifique su configuración de HTTPS.Además, asegúrese de que todos los complementos externos y las secuencias de comandos de seguimiento se carguen a través de HTTPS, que las secuencias de comandos entre sitios no sean posibles y que tanto los encabezados de seguridad de transporte estricta de HTTP como los encabezados de política de seguridad de contenido estén configurados correctamente.
- ¿Sus servidores y CDN son compatibles con HTTP/3?
Si bien HTTP/2 ha aportado una serie de mejoras de rendimiento significativas a la web, también dejó bastante espacio para mejorar, especialmente el bloqueo de cabeza de línea en TCP, que se notó en una red lenta con una pérdida de paquetes significativa. HTTP/3 está resolviendo estos problemas para siempre (artículo).Para abordar los problemas de HTTP/2, IETF, junto con Google, Akamai y otros, han estado trabajando en un nuevo protocolo que recientemente se estandarizó como HTTP/3.
Robin Marx ha explicado HTTP/3 muy bien, y la siguiente explicación se basa en su explicación. En esencia, HTTP/3 es muy similar a HTTP/2 en términos de características, pero en el fondo funciona de manera muy diferente. HTTP/3 proporciona una serie de mejoras: apretones de manos más rápidos, mejor cifrado, flujos independientes más confiables, mejor cifrado y control de flujo. Una diferencia notable es que HTTP/3 utiliza QUIC como capa de transporte, con paquetes QUIC encapsulados sobre diagramas UDP, en lugar de TCP.
QUIC integra completamente TLS 1.3 en el protocolo, mientras que en TCP está superpuesto. En la pila TCP típica, tenemos algunos tiempos de sobrecarga de ida y vuelta porque TCP y TLS necesitan hacer sus propios protocolos de enlace por separado, pero con QUIC ambos pueden combinarse y completarse en un solo viaje de ida y vuelta . Dado que TLS 1.3 nos permite configurar claves de cifrado para una conexión consecuente, a partir de la segunda conexión ya podemos enviar y recibir datos de la capa de aplicación en el primer viaje de ida y vuelta, que se denomina "0-RTT".
Además, el algoritmo de compresión de encabezados de HTTP/2 se reescribió por completo, junto con su sistema de priorización. Además, QUIC admite la migración de conexión de Wi-Fi a red celular a través de ID de conexión en el encabezado de cada paquete QUIC. La mayoría de las implementaciones se realizan en el espacio del usuario, no en el espacio del kernel (como se hace con TCP), por lo que deberíamos esperar que el protocolo evolucione en el futuro.
¿Todo esto haría una gran diferencia? Probablemente sí, especialmente teniendo un impacto en los tiempos de carga en dispositivos móviles, pero también en cómo entregamos los activos a los usuarios finales. Mientras que en HTTP/2, varias solicitudes comparten una conexión, en HTTP/3 las solicitudes también comparten una conexión pero transmiten de forma independiente, por lo que un paquete descartado ya no afecta a todas las solicitudes, solo a una transmisión.
Eso significa que, mientras que con un gran paquete de JavaScript, el procesamiento de los activos se ralentizará cuando una transmisión se detenga, el impacto será menos significativo cuando se transmitan varios archivos en paralelo (HTTP/3). Así que el embalaje sigue siendo importante .
HTTP/3 todavía está en proceso. Chrome, Firefox y Safari ya tienen implementaciones. Algunas CDN ya son compatibles con QUIC y HTTP/3. A fines de 2020, Chrome comenzó a implementar HTTP/3 e IETF QUIC y, de hecho, todos los servicios de Google (Google Analytics, YouTube, etc.) ya se ejecutan en HTTP/3. LiteSpeed Web Server admite HTTP/3, pero ni Apache, nginx ni IIS lo admiten todavía, pero es probable que cambie rápidamente en 2021.
El resultado final : si tiene la opción de usar HTTP/3 en el servidor y en su CDN, probablemente sea una muy buena idea hacerlo. El principal beneficio provendrá de obtener múltiples objetos simultáneamente, especialmente en conexiones de alta latencia. Todavía no lo sabemos con certeza, ya que no se han realizado muchas investigaciones en ese espacio, pero los primeros resultados son muy prometedores.
Si desea profundizar más en los detalles y las ventajas del protocolo, aquí hay algunos buenos puntos de partida para verificar:
- Explicación de HTTP/3, un esfuerzo colaborativo para documentar los protocolos HTTP/3 y QUIC. Disponible en varios idiomas, también en PDF.
- Nivelación del rendimiento web con HTTP/3 con Daniel Stenberg.
- Una guía académica de QUIC con Robin Marx presenta los conceptos básicos de los protocolos QUIC y HTTP/3, explica cómo HTTP/3 maneja el bloqueo de cabeza de línea y la migración de conexiones, y cómo HTTP/3 está diseñado para ser perenne (gracias, Simon !).
- Puede verificar si su servidor se ejecuta en HTTP/3 en HTTP3Check.net.
Pruebas y monitoreo
- ¿Ha optimizado su flujo de trabajo de auditoría?
Puede que no suene como un gran problema, pero tener la configuración correcta al alcance de su mano puede ahorrarle bastante tiempo en las pruebas. Considere usar Alfred Workflow de Tim Kadlec para WebPageTest para enviar una prueba a la instancia pública de WebPageTest. De hecho, WebPageTest tiene muchas características oscuras, así que tómese el tiempo para aprender a leer un gráfico de vista en cascada de WebPageTest y cómo leer un gráfico de vista de conexión de WebPageTest para diagnosticar y resolver problemas de rendimiento más rápido.También puede ejecutar WebPageTest desde una hoja de cálculo de Google e incorporar puntajes de accesibilidad, rendimiento y SEO en su configuración de Travis con Lighthouse CI o directamente en Webpack.
Eche un vistazo a la recientemente lanzada AutoWebPerf, una herramienta modular que permite la recopilación automática de datos de rendimiento de múltiples fuentes. Por ejemplo, podríamos establecer una prueba diaria en sus páginas críticas para capturar los datos de campo de la API CrUX y los datos de laboratorio de un informe Lighthouse de PageSpeed Insights.
Y si necesita depurar algo rápidamente pero su proceso de compilación parece ser notablemente lento, tenga en cuenta que "la eliminación de espacios en blanco y la manipulación de símbolos representa el 95% de la reducción de tamaño en el código minificado para la mayoría de JavaScript, no las transformaciones de código elaboradas". simplemente deshabilite la compresión para acelerar las compilaciones de Uglify de 3 a 4 veces".
- ¿Has probado en navegadores proxy y navegadores heredados?
Probar en Chrome y Firefox no es suficiente. Mire cómo funciona su sitio web en navegadores proxy y navegadores heredados. UC Browser y Opera Mini, por ejemplo, tienen una cuota de mercado significativa en Asia (hasta un 35 % en Asia). Mida la velocidad promedio de Internet en sus países de interés para evitar grandes sorpresas en el futuro. Pruebe con limitación de red y emule un dispositivo de alto DPI. BrowserStack es fantástico para realizar pruebas en dispositivos reales remotos y complementarlo con al menos algunos dispositivos reales en su oficina también; vale la pena.
- ¿Has probado el rendimiento de tus 404 páginas?
Normalmente no lo pensamos dos veces cuando se trata de 404 páginas. Después de todo, cuando un cliente solicita una página que no existe en el servidor, el servidor responderá con un código de estado 404 y la página 404 asociada. No hay mucho de eso, ¿no?Un aspecto importante de las respuestas 404 es el tamaño real del cuerpo de la respuesta que se envía al navegador. Según la investigación de 404 páginas realizada por Matt Hobbs, la gran mayoría de las respuestas 404 provienen de favicons faltantes, solicitudes de carga de WordPress, solicitudes de JavaScript rotas, archivos de manifiesto, así como archivos CSS y de fuentes. Cada vez que un cliente solicita un activo que no existe, recibirá una respuesta 404 y, a menudo, esa respuesta es enorme.
Asegúrese de examinar y optimizar la estrategia de almacenamiento en caché para sus páginas 404. Nuestro objetivo es servir HTML al navegador solo cuando espera una respuesta HTML y devolver una pequeña carga útil de error para todas las demás respuestas. Según Matt, "si colocamos una CDN frente a nuestro origen, tenemos la posibilidad de almacenar en caché la respuesta de la página 404 en la CDN. Eso es útil porque sin ella, golpear una página 404 podría usarse como un vector de ataque DoS, al obligando al servidor de origen a responder a cada solicitud 404 en lugar de permitir que la CDN responda con una versión en caché".
Los errores 404 no solo pueden perjudicar su rendimiento, sino que también pueden costar tráfico, por lo que es una buena idea incluir una página de error 404 en su conjunto de pruebas de Lighthouse y realizar un seguimiento de su puntaje a lo largo del tiempo.
- ¿Ha probado el rendimiento de sus solicitudes de consentimiento de GDPR?
En tiempos de GDPR y CCPA, se ha vuelto común confiar en terceros para brindar opciones para que los clientes de la UE opten por participar o no en el seguimiento. Sin embargo, al igual que con cualquier otro script de terceros, su rendimiento puede tener un impacto bastante devastador en todo el esfuerzo de rendimiento.Por supuesto, es probable que el consentimiento real cambie el impacto de los scripts en el rendimiento general, por lo que, como señaló Boris Schapira, es posible que deseemos estudiar algunos perfiles de rendimiento web diferentes:
- El consentimiento fue completamente denegado,
- El consentimiento fue denegado parcialmente,
- El consentimiento se dio en su totalidad.
- El usuario no ha respondido a la solicitud de consentimiento (o la solicitud fue bloqueada por un bloqueador de contenido),
Normalmente, las solicitudes de consentimiento de cookies no deberían tener un impacto en CLS, pero a veces lo hacen, así que considere usar las opciones gratuitas y de código abierto Osano o cookie-consent-box.
En general, vale la pena analizar el rendimiento de la ventana emergente, ya que deberá determinar el desplazamiento horizontal o vertical del evento del mouse y colocar correctamente la ventana emergente en relación con el ancla. Noam Rosenthal comparte los aprendizajes del equipo de Wikimedia en el artículo Estudio de caso de rendimiento web: vistas previas de páginas de Wikipedia (también disponible como video y minutos).
- ¿Mantiene un CSS de diagnóstico de rendimiento?
Si bien podemos incluir todo tipo de controles para garantizar que se implemente el código que no funciona, a menudo es útil tener una idea rápida de algunas de las frutas más fáciles de resolver que podrían resolverse fácilmente. Para eso, podríamos usar el brillante CSS de diagnóstico de rendimiento de Tim Kadlec (inspirado en el fragmento de código de Harry Roberts que destaca imágenes con carga diferida, imágenes sin tamaño, imágenes de formato heredado y secuencias de comandos síncronas.Por ejemplo, es posible que desee asegurarse de que ninguna imagen de la parte superior de la página se cargue de forma diferida. Puede personalizar el fragmento según sus necesidades, por ejemplo, para resaltar fuentes web que no se utilizan o detectar fuentes de iconos. Una pequeña gran herramienta para garantizar que los errores sean visibles durante la depuración, o simplemente para auditar el proyecto actual muy rápidamente.
/* Performance Diagnostics CSS */ /* via Harry Roberts. https://twitter.com/csswizardry/status/1346477682544951296 */ img[loading=lazy] { outline: 10px solid red; }
- Have you tested the impact on accessibility?
When the browser starts to load a page, it builds a DOM, and if there is an assistive technology like a screen reader running, it also creates an accessibility tree. The screen reader then has to query the accessibility tree to retrieve the information and make it available to the user — sometimes by default, and sometimes on demand. And sometimes it takes time.When talking about fast Time to Interactive, usually we mean an indicator of how soon a user can interact with the page by clicking or tapping on links and buttons. The context is slightly different with screen readers. In that case, fast Time to Interactive means how much time passes by until the screen reader can announce navigation on a given page and a screen reader user can actually hit keyboard to interact.
Leonie Watson has given an eye-opening talk on accessibility performance and specifically the impact slow loading has on screen reader announcement delays. Screen readers are used to fast-paced announcements and quick navigation, and therefore might potentially be even less patient than sighted users.
Large pages and DOM manipulations with JavaScript will cause delays in screen reader announcements. A rather unexplored area that could use some attention and testing as screen readers are available on literally every platform (Jaws, NVDA, Voiceover, Narrator, Orca).
- Is continuous monitoring set up?
Having a private instance of WebPagetest is always beneficial for quick and unlimited tests. However, a continuous monitoring tool — like Sitespeed, Calibre and SpeedCurve — with automatic alerts will give you a more detailed picture of your performance. Set your own user-timing marks to measure and monitor business-specific metrics. Also, consider adding automated performance regression alerts to monitor changes over time.Look into using RUM-solutions to monitor changes in performance over time. For automated unit-test-alike load testing tools, you can use k6 with its scripting API. Also, look into SpeedTracker, Lighthouse and Calibre.
Triunfos rápidos
This list is quite comprehensive, and completing all of the optimizations might take quite a while. So, if you had just 1 hour to get significant improvements, what would you do? Let's boil it all down to 17 low-hanging fruits . Obviously, before you start and once you finish, measure results, including Largest Contentful Paint and Time To Interactive on a 3G and cable connection.
- Measure the real world experience and set appropriate goals. Aim to be at least 20% faster than your fastest competitor. Stay within Largest Contentful Paint < 2.5s, a First Input Delay < 100ms, Time to Interactive < 5s on slow 3G, for repeat visits, TTI < 2s. Optimize at least for First Contentful Paint and Time To Interactive.
- Optimize images with Squoosh, mozjpeg, guetzli, pingo and SVGOMG, and serve AVIF/WebP with an image CDN.
- Prepare critical CSS for your main templates, and inline them in the
<head>of each template. For CSS/JS, operate within a critical file size budget of max. 170KB gzipped (0.7MB decompressed). - Trim, optimize, defer and lazy-load scripts. Invest in the config of your bundler to remove redundancies and check lightweight alternatives.
- Always self-host your static assets and always prefer to self-host third-party assets. Limit the impact of third-party scripts. Use facades, load widgets on interaction and beware of anti-flicker snippets.
- Be selective when choosing a framework. For single-page-applications, identify critical pages and serve them statically, or at least prerender them, and use progressive hydration on component-level and import modules on interaction.
- Client-side rendering alone isn't a good choice for performance. Prerender if your pages don't change much, and defer the booting of frameworks if you can. If possible, use streaming server-side rendering.
- Serve legacy code only to legacy browsers with
<script type="module">and module/nomodule pattern. - Experiment with regrouping your CSS rules and test in-body CSS.
- Add resource hints to speed up delivery with faster
dns-lookup,preconnect,prefetch,preloadandprerender. - Subset web fonts and load them asynchronously, and utilize
font-displayin CSS for fast first rendering. - Check that HTTP cache headers and security headers are set properly.
- Enable Brotli compression on the server. (If that's not possible, at least make sure that Gzip compression is enabled.)
- Enable TCP BBR congestion as long as your server is running on the Linux kernel version 4.9+.
- Enable OCSP stapling and IPv6 if possible. Always serve an OCSP stapled DV certificate.
- Enable HPACK compression for HTTP/2 and move to HTTP/3 if it's available.
- Cache assets such as fonts, styles, JavaScript and images in a service worker cache.
Download The Checklist (PDF, Apple Pages)
With this checklist in mind, you should be prepared for any kind of front-end performance project. Feel free to download the print-ready PDF of the checklist as well as an editable Apple Pages document to customize the checklist for your needs:
- Download the checklist PDF (PDF, 166 KB)
- Download the checklist in Apple Pages (.pages, 275 KB)
- Download the checklist in MS Word (.docx, 151 KB)
If you need alternatives, you can also check the front-end checklist by Dan Rublic, the "Designer's Web Performance Checklist" by Jon Yablonski and the FrontendChecklist.
¡Nos vamos!
Some of the optimizations might be beyond the scope of your work or budget or might just be overkill given the legacy code you have to deal with. That's fine! Use this checklist as a general (and hopefully comprehensive) guide, and create your own list of issues that apply to your context. But most importantly, test and measure your own projects to identify issues before optimizing. Happy performance results in 2021, everyone!
A huge thanks to Guy Podjarny, Yoav Weiss, Addy Osmani, Artem Denysov, Denys Mishunov, Ilya Pukhalski, Jeremy Wagner, Colin Bendell, Mark Zeman, Patrick Meenan, Leonardo Losoviz, Andy Davies, Rachel Andrew, Anselm Hannemann, Barry Pollard, Patrick Hamann, Gideon Pyzer, Andy Davies, Maria Prosvernina, Tim Kadlec, Rey Bango, Matthias Ott, Peter Bowyer, Phil Walton, Mariana Peralta, Pepijn Senders, Mark Nottingham, Jean Pierre Vincent, Philipp Tellis, Ryan Townsend, Ingrid Bergman, Mohamed Hussain SH, Jacob Groß, Tim Swalling, Bob Visser, Kev Adamson, Adir Amsalem, Aleksey Kulikov and Rodney Rehm for reviewing this article, as well as our fantastic community which has shared techniques and lessons learned from its work in performance optimization for everybody to use. ¡Estás realmente destrozando!