
Pruebas escamosas: deshacerse de una pesadilla viviente en las pruebas
Publicado: 2022-03-10Hay una fábula en la que pienso mucho estos días. La fábula me la contaron de niño. Se llama “El niño que gritó lobo” de Esopo. Se trata de un niño que cuida las ovejas de su pueblo. Se aburre y finge que un lobo está atacando al rebaño, llamando a los aldeanos en busca de ayuda, solo para que ellos, decepcionados, se den cuenta de que es una falsa alarma y dejen al niño en paz. Luego, cuando aparece un lobo y el niño pide ayuda, los aldeanos creen que es otra falsa alarma y no acuden al rescate, y las ovejas terminan siendo devoradas por el lobo.
La moraleja de la historia la resume mejor el propio autor:
“Al mentiroso no se le creerá, ni aun cuando diga la verdad”.
Un lobo ataca a la oveja y el niño pide ayuda a gritos, pero después de numerosas mentiras, nadie le cree más. Esta moraleja se puede aplicar a las pruebas: la historia de Esopo es una buena alegoría de un patrón coincidente con el que me topé: pruebas escamosas que no brindan ningún valor.
Pruebas Front-End: ¿Por qué siquiera molestarse?
La mayor parte de mis días los paso en pruebas de front-end. Por lo tanto, no debería sorprenderle que los ejemplos de código en este artículo provengan principalmente de las pruebas de front-end que he encontrado en mi trabajo. Sin embargo, en la mayoría de los casos, pueden traducirse fácilmente a otros idiomas y aplicarse a otros marcos. Por lo tanto, espero que el artículo le sea útil, independientemente de la experiencia que pueda tener.
Vale la pena recordar lo que significa la prueba de front-end. En esencia, las pruebas front-end son un conjunto de prácticas para probar la interfaz de usuario de una aplicación web, incluida su funcionalidad.
Comencé como ingeniero de control de calidad y conozco el dolor de las interminables pruebas manuales de una lista de verificación justo antes de un lanzamiento. Entonces, además del objetivo de garantizar que una aplicación permanezca libre de errores durante las actualizaciones sucesivas, me esforcé por aliviar la carga de trabajo de las pruebas causadas por esas tareas rutinarias para las que en realidad no se necesita un humano. Ahora, como desarrollador, encuentro que el tema sigue siendo relevante, especialmente porque trato de ayudar directamente a los usuarios y compañeros de trabajo por igual. Y hay un problema con las pruebas en particular que nos ha dado pesadillas.
La ciencia de las pruebas escamosas
Una prueba escamosa es aquella que no produce el mismo resultado cada vez que se ejecuta el mismo análisis. La compilación fallará solo ocasionalmente: una vez pasará, otra vez fallará, la próxima vez pasará nuevamente, sin que se haya realizado ningún cambio en la compilación.
Cuando recuerdo mis pesadillas con las pruebas, me viene a la mente un caso en particular. Fue en una prueba de IU. Creamos un cuadro combinado de estilo personalizado (es decir, una lista seleccionable con campo de entrada):
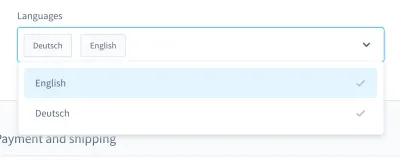
Con este cuadro combinado, puede buscar un producto y seleccionar uno o más de los resultados. Muchos días, esta prueba salió bien, pero en algún momento, las cosas cambiaron. En una de las aproximadamente diez compilaciones de nuestro sistema de integración continua (CI), falló la prueba para buscar y seleccionar un producto en este cuadro combinado.
La captura de pantalla de la falla muestra que la lista de resultados no se filtró, a pesar de que la búsqueda fue exitosa:
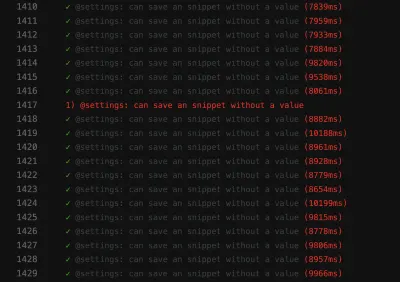
Una prueba inestable como esta puede bloquear la canalización de implementación continua , lo que hace que la entrega de funciones sea más lenta de lo necesario. Además, una prueba escamosa es problemática porque ya no es determinista, lo que la hace inútil. Después de todo, no confiarías en uno más de lo que confiarías en un mentiroso.
Además, las pruebas escamosas son costosas de reparar y, a menudo, requieren horas o incluso días para depurar. Aunque las pruebas de un extremo a otro son más propensas a ser inestables, las he experimentado en todo tipo de pruebas: pruebas unitarias, pruebas funcionales, pruebas de un extremo a otro y todo lo demás.
Otro problema importante con las pruebas escamosas es la actitud que nos imbuyen a los desarrolladores. Cuando comencé a trabajar en la automatización de pruebas, a menudo escuchaba a los desarrolladores decir esto en respuesta a una prueba fallida:
“Ahh, esa construcción. No importa, solo lánzalo de nuevo. Eventualmente pasará, en algún momento”.
Esta es una gran bandera roja para mí . Me muestra que el error en la compilación no se tomará en serio. Existe la suposición de que una prueba escamosa no es un error real, sino que es "simplemente" escamosa, sin necesidad de ser atendida o incluso depurada. La prueba volverá a pasar más tarde de todos modos, ¿verdad? ¡No! Si se fusiona una confirmación de este tipo, en el peor de los casos tendremos una nueva prueba inestable en el producto.
Las causas
Por lo tanto, las pruebas escamosas son problemáticas. ¿Qué debemos hacer con ellos? Bueno, si conocemos el problema, podemos diseñar una contraestrategia.
A menudo encuentro causas en la vida cotidiana. Se pueden encontrar dentro de las propias pruebas . Las pruebas pueden estar escritas de manera subóptima, contener suposiciones incorrectas o contener malas prácticas. Sin embargo, no solo eso. Las pruebas escamosas pueden ser una indicación de algo mucho peor.
En las siguientes secciones, repasaremos los más comunes que he encontrado.
1. Causas del lado de la prueba
En un mundo ideal, el estado inicial de su aplicación debería ser impecable y 100 % predecible. En realidad, nunca se sabe si la identificación que ha utilizado en su prueba será siempre la misma.
Inspeccionemos dos ejemplos de un solo error de mi parte. El error número uno fue usar una identificación en mis accesorios de prueba:
{ "id": "f1d2554b0ce847cd82f3ac9bd1c0dfca", "name": "Variant product", }El error número dos fue buscar un selector único para usar en una prueba de interfaz de usuario y pensar: “Vale, este ID parece único. Lo usaré.
<!-- This is a text field I took from a project I worked on --> <input type="text" />Sin embargo, si ejecutara la prueba en otra instalación o, más tarde, en varias compilaciones en CI, esas pruebas podrían fallar. Nuestra aplicación generaría los ID de nuevo, cambiándolos entre compilaciones. Entonces, la primera causa posible se encuentra en las identificaciones codificadas .
La segunda causa puede surgir de datos de demostración generados aleatoriamente (o de otro modo). Claro, podría estar pensando que este "defecto" está justificado, después de todo, la generación de datos es aleatoria, pero piense en depurar estos datos. Puede ser muy difícil ver si un error está en las pruebas mismas o en los datos de demostración.
El siguiente paso es una causa del lado de la prueba con la que he luchado varias veces: pruebas con dependencias cruzadas . Es posible que algunas pruebas no puedan ejecutarse de forma independiente o en un orden aleatorio, lo cual es problemático. Además, las pruebas anteriores podrían interferir con las posteriores. Estos escenarios pueden causar pruebas irregulares al introducir efectos secundarios.
Sin embargo, no olvide que las pruebas se basan en suposiciones desafiantes. ¿Qué sucede si sus suposiciones son erróneas para empezar? He experimentado esto a menudo, siendo mi favorito las suposiciones erróneas sobre el tiempo.
Un ejemplo es el uso de tiempos de espera inexactos, especialmente en las pruebas de interfaz de usuario, por ejemplo, mediante el uso de tiempos de espera fijos . La siguiente línea se toma de una prueba de Nightwatch.js.
// Please never do that unless you have a very good reason! // Waits for 1 second browser.pause(1000);Otra suposición errónea se relaciona con el tiempo mismo. Una vez descubrí que una prueba de PHPUnit escamosa fallaba solo en nuestras compilaciones nocturnas. Después de un poco de depuración, descubrí que el cambio de hora entre ayer y hoy era el culpable. Otro buen ejemplo son las fallas debido a las zonas horarias .
Las suposiciones falsas no se detienen ahí. También podemos tener suposiciones erróneas sobre el orden de los datos . Imagine una cuadrícula o lista que contenga varias entradas con información, como una lista de monedas:
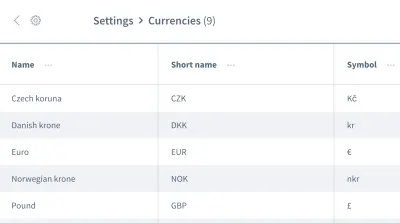
Queremos trabajar con la información de la primera entrada, la moneda “Corona checa”. ¿Puede estar seguro de que su aplicación siempre colocará este dato como la primera entrada cada vez que se ejecute la prueba? ¿Será que el “Euro” u otra moneda será la primera entrada en algunas ocasiones?
No asuma que sus datos vendrán en el orden en que los necesita. De manera similar a las identificaciones codificadas, un orden puede cambiar entre compilaciones, según el diseño de la aplicación.
2. Causas del lado del medio ambiente
La siguiente categoría de causas se relaciona con todo lo que está fuera de sus pruebas. Específicamente, estamos hablando del entorno en el que se ejecutan las pruebas, las dependencias relacionadas con CI y Docker fuera de sus pruebas; todas esas cosas en las que apenas puede influir, al menos en su rol de probador.
Una causa común del lado del entorno son las fugas de recursos : a menudo, se trata de una aplicación bajo carga, lo que provoca tiempos de carga variables o un comportamiento inesperado. Las pruebas grandes pueden causar fugas fácilmente, consumiendo mucha memoria. Otro problema común es la falta de limpieza .
La incompatibilidad entre dependencias me da pesadillas en particular. Ocurrió una pesadilla cuando estaba trabajando con Nightwatch.js para las pruebas de interfaz de usuario. Nightwatch.js usa WebDriver, que por supuesto depende de Chrome. Cuando Chrome aceleró con una actualización, hubo un problema con la compatibilidad: Chrome, WebDriver y Nightwatch.js ya no funcionaban juntos, lo que provocó que nuestras compilaciones fallaran de vez en cuando.
Hablando de dependencias : una mención de honor va para cualquier problema de npm, como la falta de permisos o la caída de npm. Experimenté todo esto al observar a CI.
Cuando se trata de errores en las pruebas de IU debido a problemas ambientales, tenga en cuenta que necesita toda la pila de aplicaciones para que se ejecuten. Cuantas más cosas estén involucradas, mayor será el potencial de error . Las pruebas de JavaScript son, por tanto, las pruebas más difíciles de estabilizar en el desarrollo web, porque abarcan una gran cantidad de código.
3. Causas del lado del producto
Por último, pero no menos importante, debemos tener mucho cuidado con esta tercera área, un área con errores reales. Estoy hablando de las causas de la descamación del lado del producto. Uno de los ejemplos más conocidos son las condiciones de carrera en una aplicación. Cuando esto sucede, el error debe corregirse en el producto, ¡no en la prueba! Intentar arreglar la prueba o el entorno no servirá de nada en este caso.
Formas de combatir la descamación
Hemos identificado tres causas de la descamación. ¡Podemos construir nuestra contraestrategia sobre esto! Por supuesto, ya habrá ganado mucho al tener en cuenta las tres causas cuando se encuentre con pruebas escamosas. Ya sabrás qué buscar y cómo mejorar las pruebas. Sin embargo, además de esto, hay algunas estrategias que nos ayudarán a diseñar, escribir y depurar pruebas, y las veremos juntas en las siguientes secciones.
Concéntrese en su equipo
Podría decirse que su equipo es el factor más importante . Como primer paso, admita que tiene un problema con las pruebas escamosas. ¡Conseguir el compromiso de todo el equipo es crucial! Luego, como equipo, deben decidir cómo lidiar con las pruebas irregulares.
Durante los años que trabajé en tecnología, me encontré con cuatro estrategias utilizadas por los equipos para contrarrestar la descamación:

- No haga nada y acepte el resultado de la prueba escamosa.
Por supuesto, esta estrategia no es una solución en absoluto. La prueba no arrojará ningún valor porque ya no puede confiar en ella, incluso si acepta la descamación. Entonces podemos saltarnos este bastante rápido. - Vuelva a intentar la prueba hasta que pase.
Esta estrategia era común al comienzo de mi carrera, lo que resultó en la respuesta que mencioné anteriormente. Hubo cierta aceptación con volver a intentar las pruebas hasta que pasaron. Esta estrategia no requiere depuración, pero es perezosa. Además de ocultar los síntomas del problema, ralentizará aún más su conjunto de pruebas, lo que hace que la solución no sea viable. Sin embargo, puede haber algunas excepciones a esta regla, que explicaré más adelante. - Eliminar y olvidarse de la prueba.
Este se explica por sí mismo: simplemente elimine la prueba escamosa, para que ya no moleste a su conjunto de pruebas. Claro, le ahorrará dinero porque ya no necesitará depurar y corregir la prueba. Pero se produce a expensas de perder un poco de cobertura de prueba y perder posibles correcciones de errores. ¡La prueba existe por una razón! No dispares al mensajero eliminando la prueba. - Cuarentena y arreglo.
Tuve el mayor éxito con esta estrategia. En este caso, omitiríamos la prueba temporalmente y el conjunto de pruebas nos recordaría constantemente que se ha omitido una prueba. Para asegurarnos de que la solución no se pase por alto, programaríamos un ticket para el próximo sprint. Los recordatorios de bots también funcionan bien. Una vez que se haya solucionado el problema que causa la descamación, integraremos (es decir, anularemos) la prueba nuevamente. Lamentablemente, perderemos la cobertura temporalmente, pero volverá con una solución, por lo que no tardará mucho.
Estas estrategias nos ayudan a lidiar con problemas de prueba a nivel de flujo de trabajo, y no soy el único que los ha encontrado. En su artículo, Sam Saffron llega a una conclusión similar. Pero en nuestro trabajo diario, nos ayudan de forma limitada. Entonces, ¿cómo procedemos cuando se nos presenta una tarea así?
Mantenga las pruebas aisladas
Cuando planifique sus casos de prueba y su estructura, mantenga siempre sus pruebas aisladas de otras pruebas, para que puedan ejecutarse en un orden independiente o aleatorio. El paso más importante es restaurar una instalación limpia entre pruebas . Además, solo pruebe el flujo de trabajo que desea probar y cree datos simulados solo para la prueba en sí. Otra ventaja de este atajo es que mejorará el rendimiento de la prueba . Si sigue estos puntos, no se interpondrán efectos secundarios de otras pruebas o datos sobrantes.
El siguiente ejemplo está tomado de las pruebas de interfaz de usuario de una plataforma de comercio electrónico y se trata del inicio de sesión del cliente en el escaparate de la tienda. (La prueba está escrita en JavaScript, utilizando el marco Cypress).
// File: customer-login.spec.js let customer = {}; beforeEach(() => { // Set application to clean state cy.setInitialState() .then(() => { // Create test data for the test specifically return cy.setFixture('customer'); }) }): El primer paso es restablecer la aplicación a una instalación limpia. Se realiza como el primer paso en el enlace del ciclo de vida beforeEach para asegurarse de que el restablecimiento se ejecute en cada ocasión. Posteriormente, los datos de prueba se crean específicamente para la prueba; para este caso de prueba, se crearía un cliente a través de un comando personalizado. Posteriormente, podemos comenzar con el único flujo de trabajo que queremos probar: el inicio de sesión del cliente.
Optimizar aún más la estructura de prueba
Podemos hacer algunos otros pequeños ajustes para que nuestra estructura de prueba sea más estable. La primera es bastante simple: Comience con pruebas más pequeñas. Como se dijo antes, cuanto más haces en una prueba, más cosas pueden salir mal. Mantenga las pruebas lo más simples posible y evite mucha lógica en cada una.
Cuando se trata de no asumir un orden de datos (por ejemplo, cuando se trata del orden de las entradas en una lista en las pruebas de interfaz de usuario), podemos diseñar una prueba para que funcione independientemente de cualquier orden. Para recuperar el ejemplo de la cuadrícula con información, no usaríamos pseudo-selectores u otro CSS que tenga una fuerte dependencia en el orden. En lugar del selector nth-child(3) , podríamos usar texto u otras cosas para las que el orden no importa. Por ejemplo, podríamos usar una afirmación como "Encuéntrame el elemento con esta cadena de texto en esta tabla".
¡Esperar! ¿Los reintentos de prueba son a veces correctos?
Volver a intentar las pruebas es un tema controvertido, y con razón. Todavía lo considero un antipatrón si la prueba se vuelve a intentar a ciegas hasta que tenga éxito. Sin embargo, hay una excepción importante: cuando no puede controlar los errores, volver a intentarlo puede ser el último recurso (por ejemplo, para excluir errores de dependencias externas). En este caso, no podemos influir en la fuente del error. Sin embargo, tenga mucho cuidado al hacer esto: no se vuelva ciego a la descamación cuando vuelva a intentar una prueba, y use notificaciones para recordarle cuándo se salta una prueba.
El siguiente ejemplo es uno que usé en nuestro CI con GitLab. Otros entornos pueden tener una sintaxis diferente para lograr reintentos, pero esto debería darle una idea:
test: script: rspec retry: max: 2 when: runner_system_failureEn este ejemplo, estamos configurando cuántos reintentos se deben realizar si el trabajo falla. Lo interesante es la posibilidad de volver a intentarlo si hay un error en el sistema del corredor (por ejemplo, la configuración del trabajo falló). Elegimos volver a intentar nuestro trabajo solo si falla algo en la configuración de la ventana acoplable.
Tenga en cuenta que esto volverá a intentar todo el trabajo cuando se active. Si desea volver a intentar solo la prueba defectuosa, deberá buscar una función en su marco de prueba para respaldar esto. A continuación, se muestra un ejemplo de Cypress, que admite el reintento de una sola prueba desde la versión 5:
{ "retries": { // Configure retry attempts for 'cypress run` "runMode": 2, // Configure retry attempts for 'cypress open` "openMode": 2, } } Puede activar los reintentos de prueba en el archivo de configuración de Cypress, cypress.json . Allí, puede definir los intentos de reintento en el corredor de prueba y el modo sin cabeza.
Uso de tiempos de espera dinámicos
Este punto es importante para todo tipo de pruebas, pero especialmente para las pruebas de interfaz de usuario. No puedo enfatizar esto lo suficiente: nunca use tiempos de espera fijos , al menos no sin una muy buena razón. Si lo hace, considere los posibles resultados. En el mejor de los casos, elegirá tiempos de espera demasiado largos, lo que hará que el conjunto de pruebas sea más lento de lo necesario. En el peor de los casos, no esperará lo suficiente, por lo que la prueba no continuará porque la aplicación aún no está lista, lo que provocará que la prueba falle de manera irregular. En mi experiencia, esta es la causa más común de pruebas escamosas.
En su lugar, utilice tiempos de espera dinámicos. Hay muchas formas de hacerlo, pero Cypress las maneja particularmente bien.
Todos los comandos de Cypress poseen un método de espera implícito: ya verifican si el elemento al que se aplica el comando existe en el DOM durante el tiempo especificado, lo que apunta a la capacidad de reintento de Cypress. Sin embargo, solo verifica la existencia y nada más. Por lo tanto, recomiendo ir un paso más allá: esperar cualquier cambio en su sitio web o en la interfaz de usuario de la aplicación que un usuario real también vería, como cambios en la propia interfaz de usuario o en la animación.
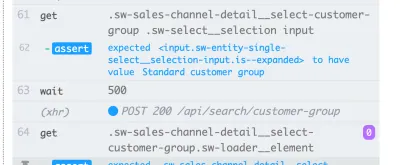
Este ejemplo utiliza un tiempo de espera explícito en el elemento con el selector .offcanvas . La prueba solo continuaría si el elemento es visible hasta el tiempo de espera especificado, que puede configurar:
// Wait for changes in UI (until element is visible) cy.get(#element).should('be.visible'); Otra clara posibilidad en Cypress para la espera dinámica son sus funciones de red. Sí, podemos esperar a que se produzcan las solicitudes y los resultados de sus respuestas. Utilizo este tipo de espera especialmente a menudo. En el siguiente ejemplo, definimos la solicitud a wait , usamos un comando de espera para esperar la respuesta y afirmamos su código de estado:
// File: checkout-info.spec.js // Define request to wait for cy.intercept({ url: '/widgets/customer/info', method: 'GET' }).as('checkoutAvailable'); // Imagine other test steps here... // Assert the response's status code of the request cy.wait('@checkoutAvailable').its('response.statusCode') .should('equal', 200);De esta manera, podemos esperar exactamente el tiempo que necesita nuestra aplicación, lo que hace que las pruebas sean más estables y menos propensas a fallas debido a fugas de recursos u otros problemas ambientales.
Depuración de pruebas escamosas
Ahora sabemos cómo prevenir pruebas escamosas por diseño. Pero, ¿y si ya estás lidiando con una prueba escamosa? ¿Cómo puedes deshacerte de él?
Cuando estaba depurando, poner la prueba defectuosa en un ciclo me ayudó mucho a descubrir la descamación. Por ejemplo, si ejecuta una prueba 50 veces y pasa todas las veces, entonces puede estar más seguro de que la prueba es estable; tal vez su solución funcionó. Si no, al menos puede obtener más información sobre la prueba escamosa.
// Use in build Lodash to repeat the test 100 times Cypress._.times(100, (k) => { it(`typing hello ${k + 1} / 100`, () => { // Write your test steps in here }) }) Obtener más información sobre esta prueba escamosa es especialmente difícil en IC. Para obtener ayuda, vea si su marco de prueba puede obtener más información sobre su compilación. Cuando se trata de pruebas de front-end, generalmente puede utilizar un console.log en sus pruebas:
it('should be a Vue.JS component', () => { // Mock component by a method defined before const wrapper = createWrapper(); // Print out the component's html console.log(wrapper.html()); expect(wrapper.isVueInstance()).toBe(true); }) Este ejemplo está tomado de una prueba unitaria de Jest en la que uso un console.log para obtener el resultado del HTML del componente que se está probando. Si utiliza esta posibilidad de registro en el corredor de pruebas de Cypress, puede incluso inspeccionar el resultado en las herramientas de desarrollo que elija. Además, cuando se trata de Cypress en CI, puede inspeccionar esta salida en el registro de su CI mediante el uso de un complemento.
Mire siempre las características de su marco de prueba para obtener soporte con el registro. En las pruebas de interfaz de usuario, la mayoría de los marcos brindan funciones de captura de pantalla ; al menos en caso de falla, se tomará una captura de pantalla automáticamente. Algunos marcos incluso proporcionan grabación de video , lo que puede ser de gran ayuda para obtener información sobre lo que sucede en su prueba.
¡Lucha contra las pesadillas de la descamación!
Es importante buscar continuamente pruebas irregulares, ya sea previniéndolas en primer lugar o depurándolas y corrigiéndolas tan pronto como ocurran. Necesitamos tomarlos en serio, porque pueden indicar problemas en su aplicación.
Detectando las banderas rojas
Por supuesto, lo mejor es prevenir las pruebas escamosas en primer lugar. Para recapitular rápidamente, aquí hay algunas señales de alerta:
- La prueba es grande y contiene mucha lógica.
- La prueba cubre una gran cantidad de código (por ejemplo, en pruebas de interfaz de usuario).
- La prueba hace uso de tiempos de espera fijos.
- La prueba depende de pruebas previas.
- La prueba afirma datos que no son 100% predecibles, como el uso de ID, tiempos o datos de demostración, especialmente los generados aleatoriamente.
Si tiene en cuenta los consejos y las estrategias de este artículo, puede evitar las pruebas irregulares antes de que sucedan. Y si vienen, sabrá cómo depurarlos y corregirlos.
Estos pasos realmente me han ayudado a recuperar la confianza en nuestro conjunto de pruebas. Nuestro conjunto de pruebas parece estar estable en este momento. Podría haber problemas en el futuro: nada es 100 % perfecto. Este conocimiento y estas estrategias me ayudarán a lidiar con ellos. Por lo tanto, aumentaré la confianza en mi capacidad para luchar contra esas pesadillas de prueba escamosas .
¡Espero haber podido aliviar al menos algo de su dolor y preocupaciones sobre la descamación!
Otras lecturas
Si desea obtener más información sobre este tema, aquí hay algunos recursos y artículos interesantes, que me ayudaron mucho:
- Artículos sobre "flake", Cypress.io
- "Volver a intentar sus pruebas es realmente algo bueno (si su enfoque es correcto)", Filip Hric, Cypress.io
- "Prueba de descamación: métodos para identificar y tratar las pruebas de descamación", Jason Palmer, Ingeniería de I+D de Spotify
- "Pruebas escamosas en Google y cómo las mitigamos", John Micco, Google Testing Blog