
Detección de noticias falsas en aprendizaje automático [explicado con ejemplo de codificación]
Publicado: 2021-02-08Las noticias falsas son uno de los mayores problemas en la era actual de Internet y las redes sociales. Si bien es una bendición que las noticias fluyan de un rincón del mundo a otro en cuestión de horas, también es doloroso ver a muchas personas y grupos difundiendo noticias falsas.
Las técnicas de aprendizaje automático que utilizan el procesamiento del lenguaje natural y el aprendizaje profundo se pueden utilizar para abordar este problema hasta cierto punto. Construiremos un modelo de detección de noticias falsas utilizando Machine Learning en este tutorial.
Al final de este artículo, sabrá lo siguiente:
- Manejo de datos de texto
- Técnicas de procesamiento de PNL
- Contar vectorización y TF-IDF
- Hacer predicciones y clasificar textos de noticias
Únase al curso en línea AI & ML de las mejores universidades del mundo: maestrías, programas ejecutivos de posgrado y programa de certificado avanzado en ML & AI para acelerar su carrera.
Tabla de contenido
Datos y problema
Usaremos los datos del desafío Kaggle Fake News para hacer un clasificador. El conjunto de datos consta de 4 características y 1 objetivo binario. Las 4 características son las siguientes:
- id : identificación única para un artículo de noticias
- title : el título de un artículo de noticias
- autor : autor de la noticia
- text : el texto del artículo; podría estar incompleto
Y el objetivo es "etiqueta" que contiene valores binarios 0 y 1. Donde 0 significa que es una fuente confiable de noticias, o en otras palabras, No Fake. 1 significa que es una noticia potencialmente falsa y no confiable. El conjunto de datos que tenemos consiste en 20800 instancias. Vamos a sumergirnos.

Preprocesamiento y limpieza de datos
| importar pandas como pd df=pd.read_csv( 'noticias-falsas/tren.csv' ) df.cabeza() |
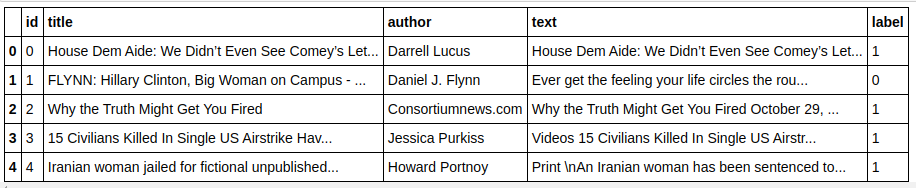
| X=df.drop( 'etiqueta' ,eje= 1 ) # Características y=df[ 'etiqueta' ] # Destino |
Necesitamos descartar instancias con datos faltantes ahora.
| df=df.dropna() |
![]()
Como podemos ver, eliminó todas las instancias con datos faltantes.
| mensajes=df.copia() mensajes.reset_index(inplace= True ) mensajes.head( 10 ) |
Echemos un vistazo a los datos una vez.
| mensajes['texto'][6] |

Como podemos ver, es necesario realizar los siguientes pasos:
- Eliminar palabras vacías: hay muchas palabras que no agregan valor a ningún texto sin importar los datos. Por ejemplo, "yo", "un", "soy", etc. Estas palabras no tienen valor informativo y, por lo tanto, pueden eliminarse para reducir el tamaño de nuestro corpus para que podamos centrarnos solo en palabras/tokens que tienen un valor real. .
- Stemming de las palabras: Stemming y Lematization son las técnicas para reducir las palabras a sus tallos o raíces. La principal ventaja de este paso es reducir el tamaño del vocabulario. Por ejemplo, palabras como Jugar, Jugando, Jugado se reducirán a "Jugar". Stemming simplemente trunca las palabras a la palabra más corta y no tiene en cuenta el aspecto gramatical del texto. La lematización, por otro lado, también tiene en cuenta la gramática y, por lo tanto, produce resultados mucho mejores. Sin embargo, la lematización suele ser más lenta que la lematización, ya que necesita consultar el diccionario y tener en cuenta el aspecto gramatical.
- Eliminar todo excepto los valores alfabéticos: los valores no alfabéticos no son muy útiles aquí, por lo que se pueden eliminar. Sin embargo, puede explorar más a fondo para ver si la presencia de datos numéricos o de otro tipo tiene algún impacto en el objetivo.
- Minúsculas las palabras: Minúsculas las palabras para reducir el vocabulario.
- Tokenizar las oraciones: Generar tokens a partir de oraciones.
| de sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer, HashingVectorizer de nltk.corpus importar palabras vacías de nltk.stem.porter importar PorterStemmer importar re ps = Porter Stemmer() corpus = [] for i in range(0, len(mensajes)): reseña = re.sub('[^a-zA-Z]', ' ', mensajes['texto'][i]) revisión = revisión.inferior() revisión = revisión.split() revisión = [ps.stem(palabra) para palabra en revisión si no palabra en stopwords.words('english')] revisión = ' '.join(revisión) corpus.append(revisión) |
Echemos un vistazo a nuestro corpus ahora.
| cuerpo[ 3 ] |
![]()
Como podemos ver, las palabras ahora se derivan de las palabras raíz.
Vectorizador TF-IDF
Ahora necesitamos vectorizar las palabras a datos numéricos que también se llama vectorización. La forma más fácil de vectorizar es usar la Bolsa de palabras. Pero Bag of Words crea una matriz dispersa y, por lo tanto, se necesita mucha memoria de procesamiento. Además, BoW no tiene en cuenta la frecuencia de las palabras, lo que lo convierte en un mal algoritmo.
TF-IDF (Frecuencia de término - Frecuencia de documento inversa) es otra forma de vectorizar palabras que tiene en cuenta las frecuencias de palabras. Por ejemplo, palabras comunes como "nosotros", "nuestro", "el" están en cada documento/instancia, por lo que el valor de BoW será demasiado alto y, por lo tanto, engañoso. Esto conducirá a un mal modelo. TF-IDF es la multiplicación de la frecuencia de términos y la frecuencia de documentos inversa.
La frecuencia de términos tiene en cuenta la frecuencia de las palabras en un documento y la frecuencia inversa del documento tiene en cuenta las palabras que están presentes en todo el corpus. Las palabras que están presentes en todo el corpus tienen una importancia reducida ya que el valor de IDF es mucho más bajo. Las palabras que están presentes específicamente en un documento tienen un valor IDF alto, lo que hace que el valor total de TF-IDF sea alto.
| ## Vectorizador TFi df de sklearn.feature_extraction.text importar TfidfVectorizer tfidf_v = TfidfVectorizer(max_features= 5000 ,ngram_range=( 1 , 3 )) X=tfidf_v.fit_transform(corpus).toarray() y=mensajes[ 'etiqueta' ] |
En el código anterior, importamos el vectorizador TF-IDF del módulo de extracción de funciones de Sklearn. Hacemos su objeto pasando max_features como 5000 y ngram_range como (1,3). El parámetro max_features define el número máximo de vectores de características que queremos crear y el parámetro ngram_range define las combinaciones de ngram que queremos incluir. En nuestro caso, obtendremos 3 combinaciones de 1 palabra, 2 palabras y 3 palabras. Echemos un vistazo a algunas de las características creadas.

| tfidf_v.get_feature_names()[: 20 ] |

Como podemos ver, se forman múltiples tipos de combinaciones. Hay nombres de funciones con 1 token, 2 tokens y también con 3 tokens.
Hacer un marco de datos
| ## Dividir el conjunto de datos en Entrenar y Probar de sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size= 0.33 , random_state= 0 ) count_df = pd.DataFrame(X_train, column=tfidf_v.get_feature_names()) cuenta_df.cabeza() |
Dividimos el conjunto de datos en entrenar y probar para que podamos probar el rendimiento del modelo en datos no vistos. Luego creamos un nuevo marco de datos que contiene los nuevos vectores de características.
Modelado y Tuning
Algoritmo MultinomialNB
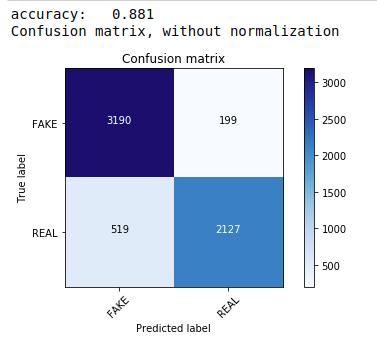
Primero, usamos el teorema Multinomial Naive Bayes, que es el algoritmo preferido más común y más fácil para la clasificación de datos de texto. Nos ajustamos a los datos de entrenamiento y predecimos a partir de los datos de prueba. Luego calculamos y trazamos la matriz de confusión y obtenemos una precisión del 88,1%.
| de sklearn.naive_bayes importar MultinomialNB de las métricas de importación de sklearn importar numpy como np importar itertools de sklearn.metrics importar plot_confusion_matrix clasificador=MultinomialNB() clasificador.fit(tren_X, tren_y) pred = clasificador.predecir(X_test) puntuación = metrics.accuracy_score(y_test, pred) imprimir ( "precisión:% 0.3f" % puntuación) cm = metrics.confusion_matrix(y_test, pred) plot_confusion_matrix(cm, clases=[ 'FALSO' , 'REAL' ]) |
Clasificador multinomial con ajuste de hiperparámetros
MultinomialNB tiene un parámetro alfa que se puede ajustar aún más. Por lo tanto, ejecutamos un ciclo para probar múltiples clasificadores MultinomialNB con diferentes valores alfa y verificar sus puntajes de precisión. Y verificamos si el puntaje actual es mayor que el puntaje anterior. Si es así, entonces establecemos el clasificador como el actual.
| puntuación_anterior= 0 para alfa en np.arange( 0 , 1 , 0.1 ): sub_classifier=MultinomialNB(alfa=alfa) sub_clasificador.fit(tren_X,tren_y) y_pred=sub_clasificador.predict(X_test) puntuación = metrics.accuracy_score(y_test, y_pred) si puntuación>puntuación_anterior: clasificador=sub_clasificador print( “Alfa: {}, Puntuación: {}” .format(alfa,puntuación)) |
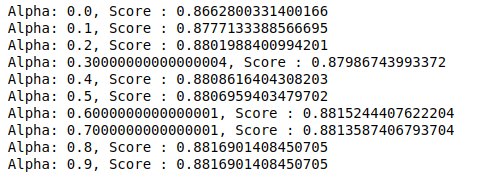
Por lo tanto, podemos ver que un valor alfa de 0,9 o 0,8 dio la puntuación de precisión más alta.
Interpretación de los resultados
Ahora veamos qué significan estos valores de coeficiente clasificador. Primero guardaremos todos los nombres de características en otra variable.
| ## Obtener nombres de características nombres_de_características = cv.get_nombres_de_características() |
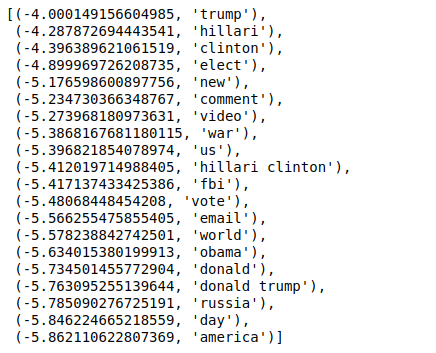
Ahora, cuando ordenamos los valores en orden inverso, obtenemos valores con un valor mínimo de -4. Estos denotan las palabras que son más reales o menos falsas.
| ### M á s real sorted(zip(classifier.coef_[ 0 ], feature_names), reverse= True )[: 20 ] |
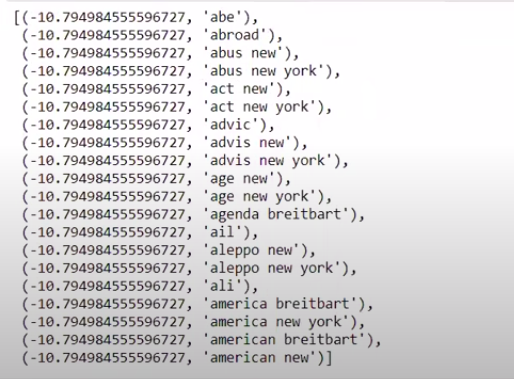
Cuando ordenamos los valores en orden no inverso, obtenemos valores con un valor mínimo de -10. Estos denotan las palabras que son menos reales o más falsas.
| ### M á s real sorted(zip(classifier.coef_[ 0 ], feature_names))[: 20 ] |
Conclusión
En este tutorial, solo usamos algoritmos ML, pero también usa otros métodos de redes neuronales. Además, para vectorizar los datos de texto, utilizamos el vectorizador TF-IDF. También hay más vectorizadores como Count Vectorizer, Hashing Vectorizer, etc., que pueden ser mejores para hacer el trabajo. Pruebe y experimente con otros algoritmos y técnicas para ver si puede producir mejores resultados o no.
Si está interesado en obtener más información sobre el aprendizaje automático, consulte el Programa PG Ejecutivo en Aprendizaje Automático e IA de IIIT-B y upGrad, que está diseñado para profesionales que trabajan y ofrece más de 450 horas de capacitación rigurosa, más de 30 estudios de casos y asignaciones, IIIT -Estado de exalumno B, más de 5 proyectos prácticos finales prácticos y asistencia laboral con las mejores empresas.
¿Por qué es necesario detectar noticias falsas?
En su condición actual, las plataformas de redes sociales son muy poderosas y valiosas, ya que permiten a los usuarios discutir e intercambiar ideas, así como debatir temas como la democracia, la educación y la salud. Sin embargo, ciertas entidades hacen un mal uso de dichas plataformas, para obtener ganancias monetarias en algunas circunstancias y para producir puntos de vista prejuiciosos, alterar mentalidades y diseminar sátiras o ridiculeces en otras. Fake news es el término para este fenómeno. La proliferación de publicaciones en línea que no se ajustan a la realidad ha dado lugar a una gran cantidad de problemas en la política, los deportes, la salud, la ciencia y otros campos.
¿Qué empresas hacen mayor uso de la detección de noticias falsas?
La detección de noticias falsas se utiliza en plataformas como redes sociales y sitios web de noticias. Los gigantes de las redes sociales como Facebook, Instagram y Twitter son vulnerables a las noticias falsas, ya que la mayoría de sus usuarios confían en ellas como fuentes de noticias diarias para obtener la información más actualizada. Las empresas de medios también utilizan técnicas de detección falsas para determinar la autenticidad de la información que tienen. El correo electrónico es otro medio a través del cual los individuos pueden recibir noticias, lo que dificulta su identificación y verificación de su veracidad. Los engaños, el spam y el correo no deseado son bien conocidos por transmitirse por correo electrónico. Como resultado, la mayoría de las plataformas de correo electrónico emplean la detección de noticias falsas para identificar el spam y el correo no deseado.