
Análisis exploratorio de datos en Python: ¿Qué necesita saber?
Publicado: 2021-03-12El análisis exploratorio de datos (EDA) es una práctica muy común e importante seguida por todos los científicos de datos. Es el proceso de mirar tablas y tablas de datos desde diferentes ángulos para poder entenderlo completamente. Obtener una buena comprensión de los datos nos ayuda a limpiarlos y resumirlos, lo que luego saca a la luz las ideas y las tendencias que de otro modo no estarían claras.
EDA no tiene un conjunto de reglas estrictas que deban seguirse como en el "análisis de datos", por ejemplo. Las personas que son nuevas en el campo siempre tienden a confundir los dos términos, que en su mayoría son similares pero diferentes en su propósito. A diferencia de EDA, el análisis de datos se inclina más hacia la implementación de probabilidades y métodos estadísticos para revelar hechos y relaciones entre diferentes variantes.
Volviendo, no hay una forma correcta o incorrecta de realizar EDA. Varía de persona a persona, sin embargo, existen algunas pautas importantes que se siguen comúnmente y que se enumeran a continuación.
- Manejo de valores faltantes: los valores nulos se pueden ver cuando es posible que no todos los datos hayan estado disponibles o registrados durante la recopilación.
- Eliminación de datos duplicados: es importante evitar cualquier sobreajuste o sesgo creado durante el entrenamiento del algoritmo de aprendizaje automático utilizando registros de datos repetidos.
- Manejo de valores atípicos: los valores atípicos son registros que difieren drásticamente del resto de los datos y no siguen la tendencia. Puede surgir debido a ciertas excepciones o inexactitudes durante la recopilación de datos.
- Escalado y normalización: Esto solo se hace para variables de datos numéricos. La mayoría de las veces, las variables difieren mucho en su rango y escala, lo que dificulta compararlas y encontrar correlaciones.
- Análisis univariado y bivariado: el análisis univariado generalmente se realiza al ver cómo una variable afecta a la variable objetivo. El análisis bivariado se lleva a cabo entre 2 variables cualesquiera, puede ser numérico o categórico o ambos.
Veremos cómo se implementan algunos de estos utilizando un conjunto de datos muy famoso de 'Riesgo de incumplimiento de crédito para el hogar' disponible en Kaggle aquí . Los datos contienen información sobre el solicitante del préstamo en el momento de solicitar el préstamo. Contiene dos tipos de escenarios:
- El cliente con dificultades de pago : tenía más de X días de retraso en el pago
en al menos una de las primeras Y cuotas del préstamo en nuestra muestra,
- Todos los demás casos : Todos los demás casos cuando el pago se paga a tiempo.
Solo trabajaremos en los archivos de datos de la aplicación por el bien de este artículo.
Relacionado: Ideas y temas de proyectos de Python para principiantes
Tabla de contenido
Mirando los datos
app_data = pd.read_csv( 'application_data.csv' )
app_data.info()
Después de leer los datos de la aplicación, usamos la función info() para obtener una breve descripción general de los datos con los que trabajaremos. El siguiente resultado nos informa que tenemos alrededor de 300000 registros de préstamos con 122 variables. De estas, hay 16 variables categóricas y el resto numéricas.
<clase 'pandas.core.frame.DataFrame'>
RangeIndex: 307511 entradas, 0 a 307510
Columnas: 122 entradas, SK_ID_CURR a AMT_REQ_CREDIT_BUREAU_YEAR
tipos: float64(65), int64(41), objeto(16)
uso de memoria: 286.2+ MB
Siempre es una buena práctica manejar y analizar datos numéricos y categóricos por separado.
categórico = app_data.select_dtypes(incluir = objeto).columnas
app_data[categórico].apply(pd.Series.nunique, eje = 0)
Mirando solo las características categóricas a continuación, vemos que la mayoría de ellas solo tienen unas pocas categorías que las hacen más fáciles de analizar usando gráficos simples.
NOMBRE_CONTRATO_TIPO 2
CÓDIGO_GENERO 3
FLAG_OWN_CAR 2
FLAG_OWN_REALTY 2
NOMBRE_TYPE_SUITE 7
NOMBRE_INCOME_TYPE 8
NOMBRE_EDUCACIÓN_TIPO 5
NOMBRE_FAMILIA_ESTADO 6
NOMBRE_VIVIENDA_TIPO 6
OCUPACIÓN_TIPO 18
WEEKDAY_APPR_PROCESS_START 7
ORGANIZACIÓN_TIPO 58
FONDKAPREMONT_MODO 4
TIPO DE CASA_MODO 3
WALLMATERIAL_MODE 7
ESTADO DE EMERGENCIA_MODO 2
tipo: int64
Ahora, para las características numéricas, el método describe() nos da las estadísticas de nuestros datos:
numer= app_data.describe()
numérico= numer.columnas
número
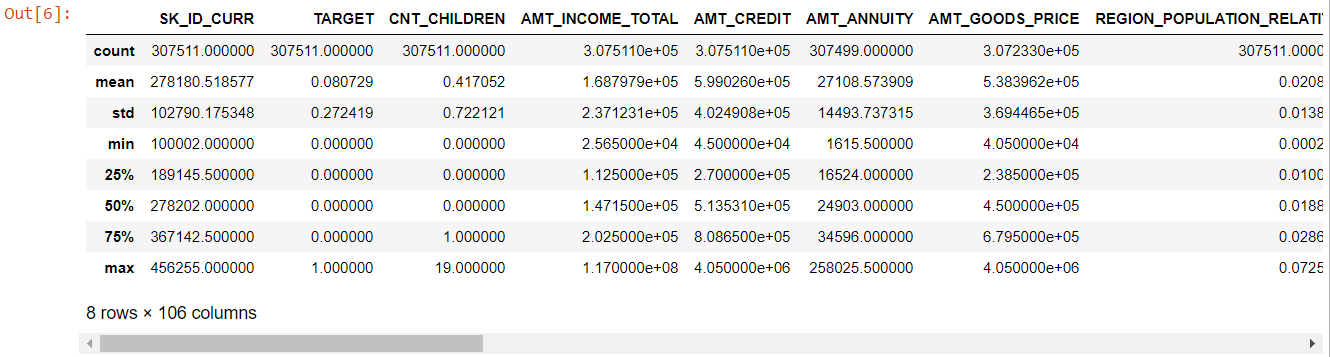
Mirando toda la tabla es evidente que:
- days_birth es negativo: la edad del solicitante (en días) en relación con el día de la solicitud
- days_emploed tiene valores atípicos (el valor máximo es de alrededor de 100 años) (635243)
- amt_annuity- significa mucho más pequeño que el valor máximo
Entonces ahora sabemos qué características deberán analizarse más a fondo.
Datos perdidos
Podemos hacer un gráfico de puntos de todas las características a las que les faltan valores trazando el % de datos faltantes a lo largo del eje Y.
perdido = pd.DataFrame( (app_data.isnull().sum()) * 100 / app_data.shape[0]).reset_index()
plt.figure(figsize = (16,5))
hacha = sns.pointplot('índice', 0, datos = faltantes)

plt.xticks(rotación = 90, tamaño de fuente = 7)
plt.title(“Porcentaje de valores faltantes”)
plt.ylabel(“PORCENTAJE”)
plt.mostrar()
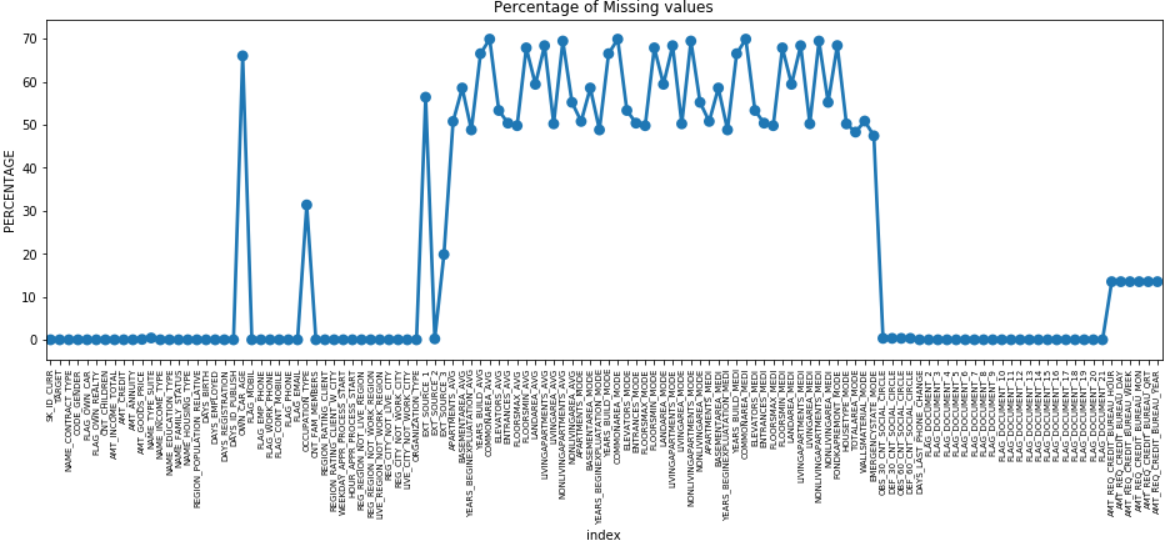
Muchas columnas tienen muchos datos faltantes (30-70%), algunas tienen pocos datos faltantes (13-19%) y muchas columnas tampoco tienen ningún dato faltante. No es realmente necesario modificar el conjunto de datos cuando solo tiene que realizar EDA. Sin embargo, siguiendo adelante con el preprocesamiento de datos, debemos saber cómo manejar los valores faltantes.
Para características con menos valores perdidos, podemos usar la regresión para predecir los valores perdidos o completar con la media de los valores presentes, dependiendo de la característica. Y para las funciones con una cantidad muy alta de valores faltantes, es mejor descartar esas columnas, ya que brindan menos información sobre el análisis.
Desequilibrio de datos
En este conjunto de datos, los morosos se identifican mediante la variable binaria 'OBJETIVO'.
100 * app_data['TARGET'].value_counts() / len(app_data['TARGET'])
0 91.927118
1 8.072882
Nombre: OBJETIVO, tipo de d: float64
Vemos que los datos están muy desequilibrados con una proporción de 92:8. La mayoría de los préstamos se pagaron a tiempo (objetivo = 0). Por lo tanto, siempre que exista un desequilibrio tan grande, es mejor tomar características y compararlas con la variable objetivo (análisis específico) para determinar qué categorías en esas características tienden a incumplir los préstamos más que otras.
A continuación se muestran solo algunos ejemplos de gráficos que se pueden crear utilizando la biblioteca Seaborn de Python y funciones sencillas definidas por el usuario.
Género
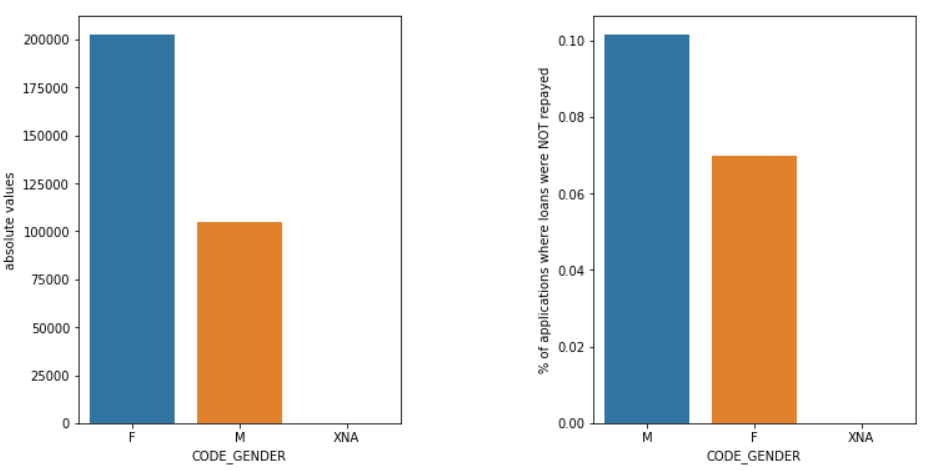
Los hombres (M) tienen una mayor probabilidad de incumplimiento en comparación con las mujeres (F), a pesar de que el número de mujeres solicitantes es casi el doble. Por lo tanto, las mujeres son más confiables que los hombres para pagar sus préstamos.
Tipo de Educación
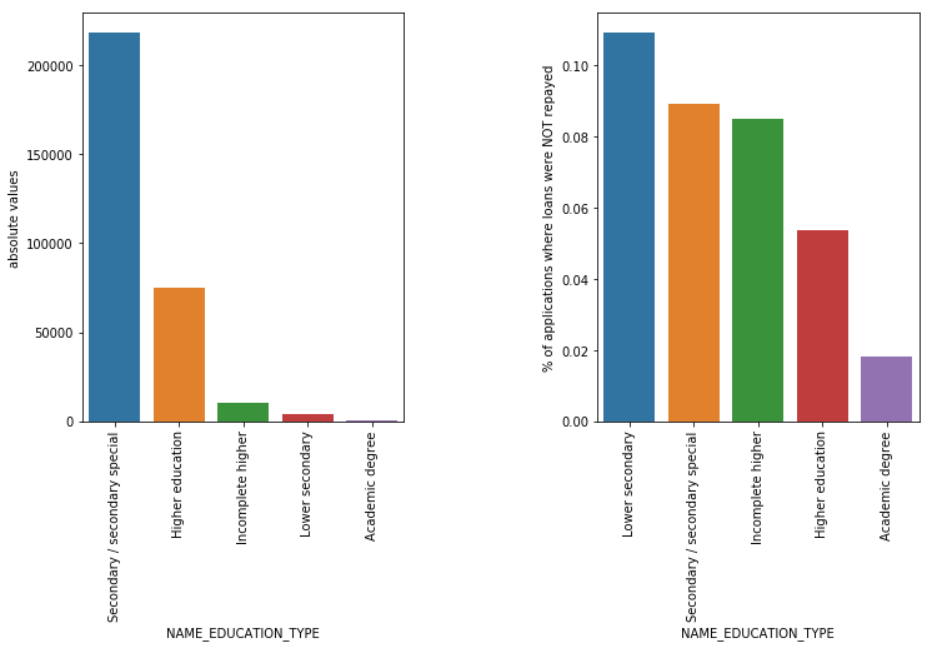
Aunque la mayoría de los préstamos para estudiantes son para su educación secundaria o superior, son los préstamos para la educación secundaria inferior los más riesgosos para la empresa, seguidos por la secundaria.
Lea también: Carrera en ciencia de datos
Conclusión
Este tipo de análisis visto anteriormente se realiza ampliamente en análisis de riesgo en servicios bancarios y financieros. De esta forma, los archivos de datos se pueden utilizar para minimizar el riesgo de perder dinero al prestar a los clientes. El alcance de EDA en todos los demás sectores es infinito y debe usarse ampliamente.
Si tiene curiosidad por aprender sobre ciencia de datos, consulte IIIT-B & upGrad's Executive PG in Data Science, creado para profesionales que trabajan y ofrece más de 10 estudios de casos y proyectos, talleres prácticos, tutoría con expertos de la industria, 1- on-1 con mentores de la industria, más de 400 horas de aprendizaje y asistencia laboral con las mejores empresas.
El análisis exploratorio de datos se considera el nivel inicial cuando comienza a modelar sus datos. Esta es una técnica bastante perspicaz para analizar las mejores prácticas para modelar sus datos. Podrá extraer diagramas visuales, gráficos e informes de los datos para obtener una comprensión completa de ellos. Los valores atípicos se refieren a las anomalías o ligeras variaciones en sus datos. Puede ocurrir durante la recopilación de datos. Hay 4 formas en las que podemos detectar un valor atípico en el conjunto de datos. Estos métodos son los siguientes: A diferencia del análisis de datos, no hay reglas y regulaciones estrictas y rápidas que deban seguirse para EDA. No se puede decir que este es el método correcto o que es el método incorrecto para realizar EDA. Los principiantes a menudo son malinterpretados y se confunden entre EDA y análisis de datos.¿Por qué es necesario el análisis exploratorio de datos (EDA)?
El EDA implica ciertos pasos para analizar completamente los datos, incluida la obtención de resultados estadísticos, la búsqueda de valores de datos faltantes, el manejo de las entradas de datos defectuosas y, finalmente, la deducción de varios diagramas y gráficos.
El objetivo principal de este análisis es garantizar que el conjunto de datos que está utilizando sea adecuado para comenzar a aplicar algoritmos de modelado. Esa es la razón por la que este es el primer paso que debe realizar en sus datos antes de pasar a la etapa de modelado. ¿Qué son los valores atípicos y cómo manejarlos?
1. Diagrama de caja: el diagrama de caja es un método para detectar un valor atípico donde segregamos los datos a través de sus cuartiles.
2. Diagrama de dispersión: un diagrama de dispersión muestra los datos de 2 variables en forma de una colección de puntos marcados en el plano cartesiano. El valor de una variable representa el eje horizontal (x-ais) y el valor de la otra variable representa el eje vertical (eje y).
3. Puntuación Z: al calcular la puntuación Z, buscamos los puntos que están lejos del centro y los consideramos como valores atípicos.
4. Rango intercuartil (IQR): el rango intercuartil o IQR es la diferencia entre los cuartiles superior e inferior o el cuartil 75 y 25, a menudo denominado dispersión estadística. ¿Cuáles son las pautas para realizar EDA?
Sin embargo, hay algunas pautas que se practican comúnmente:
1. Manejo de valores faltantes
2. Eliminar datos duplicados
3. Manejo de valores atípicos
4. Escalado y normalización
5. Análisis univariado y bivariado