
¿Qué es el análisis exploratorio de datos en Python? Aprende desde cero
Publicado: 2021-03-04El Análisis Exploratorio de Datos o EDA, en definitiva, comprende casi el 70% de Data Science Project. EDA es el proceso de explorar los datos mediante el uso de varias herramientas de análisis para obtener las estadísticas inferenciales de los datos. Estas exploraciones se realizan ya sea viendo números simples o trazando gráficos y tablas de diferentes tipos.
Cada gráfico o tabla representa una historia diferente y un ángulo de los mismos datos. Para la mayor parte de la parte de análisis y limpieza de datos, Pandas es la herramienta más utilizada. Para las visualizaciones y el trazado de gráficos/tablas, se utilizan bibliotecas de trazado como Matplotlib, Seaborn y Plotly.
EDA es extremadamente necesario para llevarse a cabo ya que hace que los datos le confiesen. Un científico de datos que hace un muy buen EDA sabe mucho sobre los datos y, por lo tanto, el modelo que construirá será automáticamente mejor que el científico de datos que no hace un buen EDA.
Al final de este tutorial, sabrá lo siguiente:
- Comprobación de la descripción general básica de los datos
- Comprobación de las estadísticas descriptivas de los datos
- Manipulación de nombres de columnas y tipos de datos
- Manejo de valores perdidos y filas duplicadas
- Análisis bivariado
Tabla de contenido
Resumen básico de datos
Usaremos Cars Dataset para este tutorial que se puede descargar desde Kaggle. El primer paso para casi cualquier conjunto de datos es importarlo y verificar su descripción general básica: su forma, columnas, tipos de columnas, las 5 filas principales, etc. Este paso le brinda una idea general rápida de los datos con los que trabajará. Veamos cómo hacer esto en Python.
| # Importando las bibliotecas requeridas importar pandas como pd importar numpy como np importar seaborn como sns # visualización importar matplotlib.pyplot como plt # visualización % matplotlib en línea sns.set(color_codes= True ) |
Cabeza y cola de datos
| datos = pd.read_csv ( "ruta/conjunto de datos.csv" ) # Verifique las 5 filas superiores del marco de datos datos.head() |
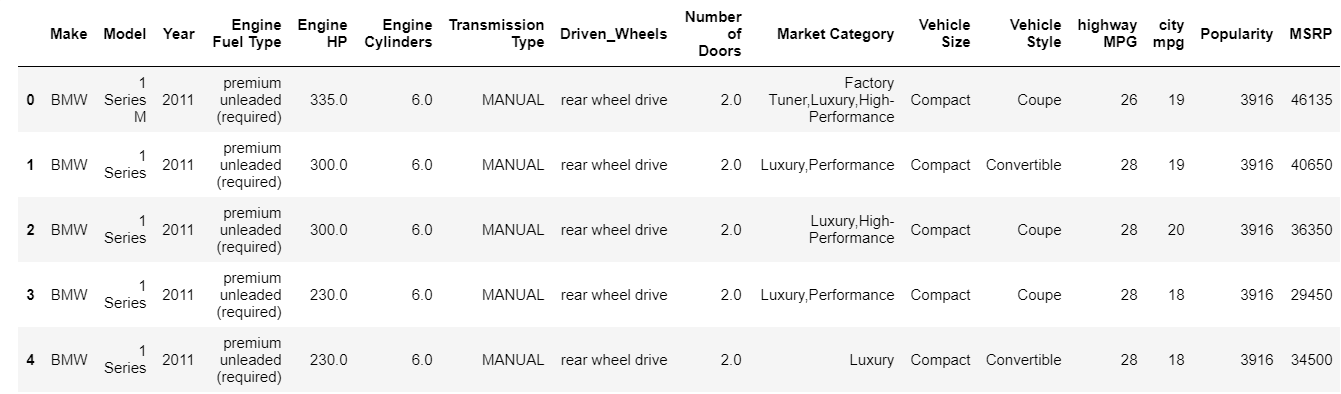
La función head imprime los 5 índices principales del marco de datos de forma predeterminada. También puede especificar cuántos índices principales necesita ver pasando ese valor al encabezado. Imprimir el cabezal al instante nos da una idea rápida de qué tipo de datos tenemos, qué tipo de características están presentes y qué valores contienen. Por supuesto, esto no cuenta toda la historia sobre los datos, pero le da un vistazo rápido a los datos. De manera similar, puede imprimir la parte inferior del marco de datos utilizando la función de cola.
| # Imprimir las últimas 10 filas del marco de datos datos.cola( 10 ) |
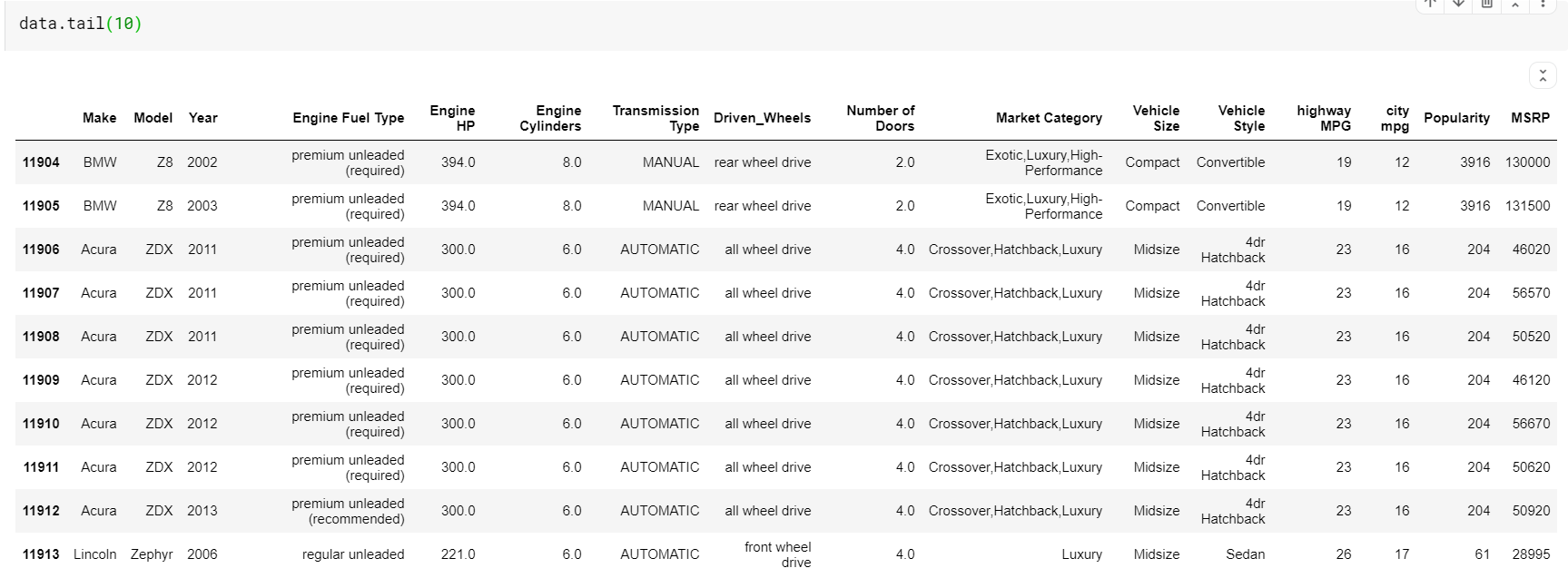
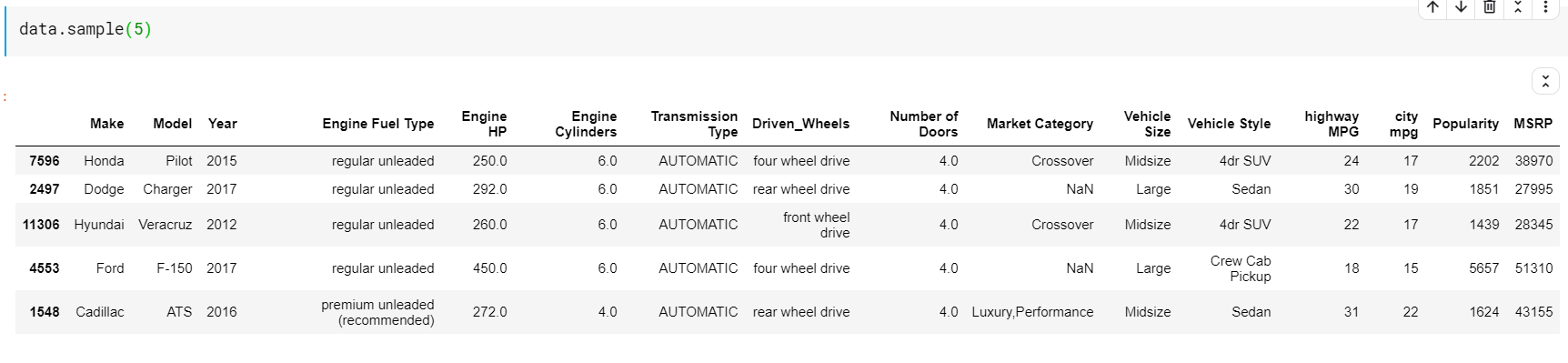
Una cosa a tener en cuenta aquí es que tanto la función cabeza como la cola nos dan los índices superior o inferior. Pero las filas superiores o inferiores no siempre son una buena vista previa de los datos. Por lo tanto, también puede imprimir cualquier número de filas muestreadas aleatoriamente del conjunto de datos utilizando la función sample().
| # Imprime 5 filas al azar datos.muestra( 5 ) |
Estadísticas descriptivas
A continuación, veamos las estadísticas descriptivas del conjunto de datos. Las estadísticas descriptivas consisten en todo lo que "describe" el conjunto de datos. Verificamos la forma del marco de datos, qué columnas están presentes, qué características numéricas y categóricas están allí. También veremos cómo hacer todo esto en funciones simples.
Forma
| # Comprobando la forma del marco de datos (mxn) # m=número de filas # n=número de columnas data.shape |

Como vemos, este marco de datos contiene 11914 filas y 16 columnas.
columnas
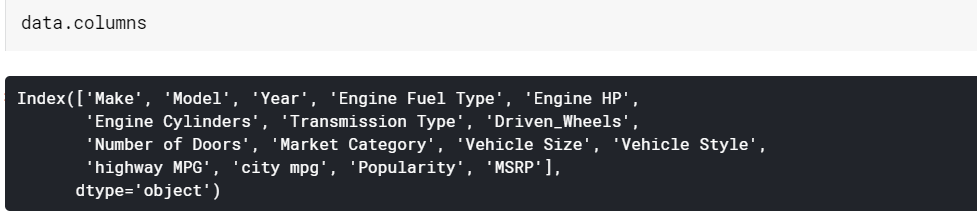
| # Imprimir los nombres de las columnas columnas.de.datos |
Información del marco de datos
| # Imprime los tipos de datos de la columna y la cantidad de valores que no faltan datos.info() |
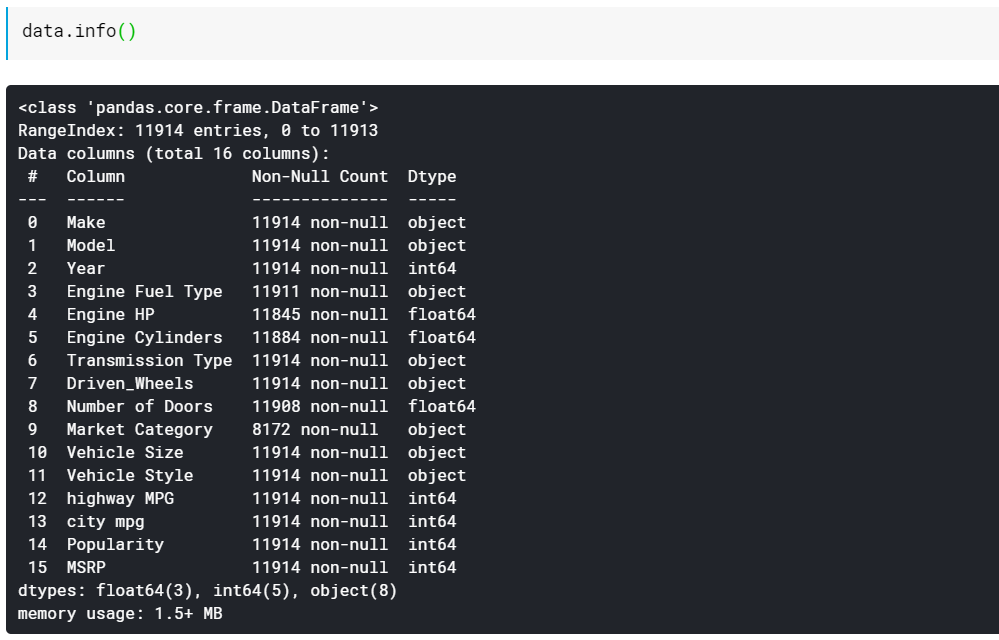
Como puede ver, la función info() nos brinda todas las columnas, cuántos valores no nulos o no faltantes hay en esas columnas y, por último, el tipo de datos de esas columnas. Esta es una buena forma rápida de ver qué características son numéricas y qué son categóricas/basadas en texto. Además, ahora tenemos información sobre qué valores faltan en todas las columnas. Veremos cómo trabajar con valores faltantes más adelante.
Manipulación de nombres de columnas y tipos de datos
Verificar y manipular cuidadosamente cada columna es extremadamente crucial en EDA. Necesitamos ver qué tipo de contenido contiene una columna/característica y qué pandas ha leído su tipo de datos. Los tipos de datos numéricos son en su mayoría int64 o float64. A las características categóricas o basadas en texto se les asigna el tipo de datos 'objeto'.
Se asignan las funciones basadas en la fecha y la hora. Hay ocasiones en las que Pandas no comprende el tipo de datos de una función. En tales casos, simplemente le asigna perezosamente el tipo de datos 'objeto'. Podemos especificar los tipos de datos de columna explícitamente mientras leemos los datos con read_csv.
Selección de columnas categóricas y numéricas
| # Agregue todas las columnas categóricas y numéricas a listas separadas categórico = datos.select_dtypes( 'objeto' ).columnas numérico = datos.select_dtypes( 'número' ).columnas |


Aquí, el tipo que pasamos como 'número' selecciona todas las columnas con tipos de datos que tienen cualquier tipo de número, ya sea int64 o float64.
Cambiar el nombre de las columnas
| # Cambiar el nombre de las columnas data = data.rename(columns={ “HP del motor” : “HP” , “Cilindros del motor” : “Cilindros” , “Tipo de transmisión” : “Transmisión” , “Driven_Wheels” : “Modo de conducción” , “autopista MPG” : “MPG-H” , “MSRP” : “Precio” }) datos.head( 5 ) |

La función de renombrar solo toma un diccionario con los nombres de las columnas a renombrar y sus nuevos nombres.
Manejo de valores faltantes y filas duplicadas
Los valores faltantes son uno de los problemas/discrepancias más comunes en cualquier conjunto de datos de la vida real. El manejo de los valores faltantes es en sí mismo un tema muy amplio, ya que existen múltiples formas de hacerlo. Algunas formas son formas más genéricas y otras son más específicas para el conjunto de datos con el que se podría estar tratando.
Comprobación de valores faltantes
| # Comprobación de valores faltantes datos.isnull().sum() |
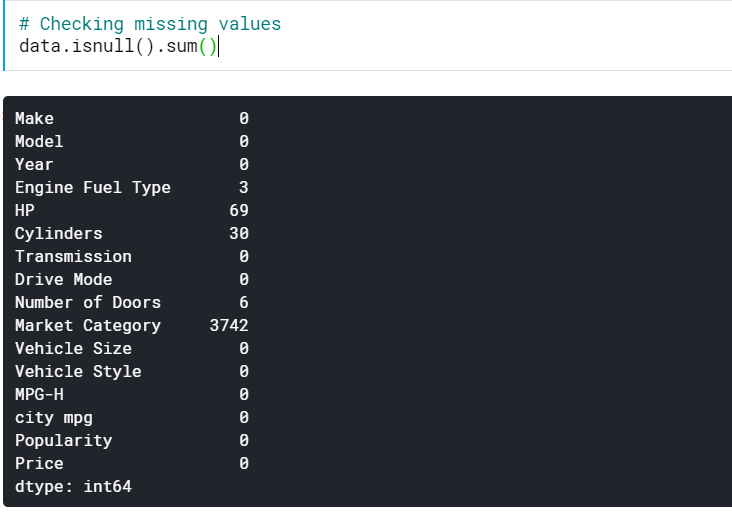
Esto nos da el número de valores que faltan en todas las columnas. También podemos ver el porcentaje de valores que faltan.
| # Porcentaje de valores faltantes datos.isnull().mean()* 100 |
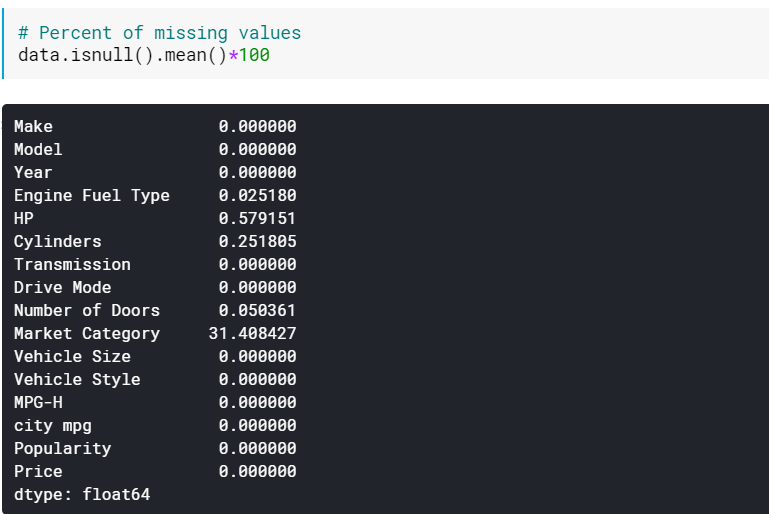
Verificar los porcentajes puede ser útil cuando hay muchas columnas a las que les faltan valores. En tales casos, las columnas con muchos valores perdidos (por ejemplo, >60 % perdidos) pueden descartarse.
Imputación de valores faltantes
| #Imputación de valores faltantes de columnas numéricas por media datos[numéricos] = datos[numéricos].fillna(datos[numéricos].media().iloc[ 0 ]) #Imputación de valores faltantes de columnas categóricas por modo datos[categóricos] = datos[categóricos].fillna(datos[categóricos].modo().iloc[ 0 ]) |
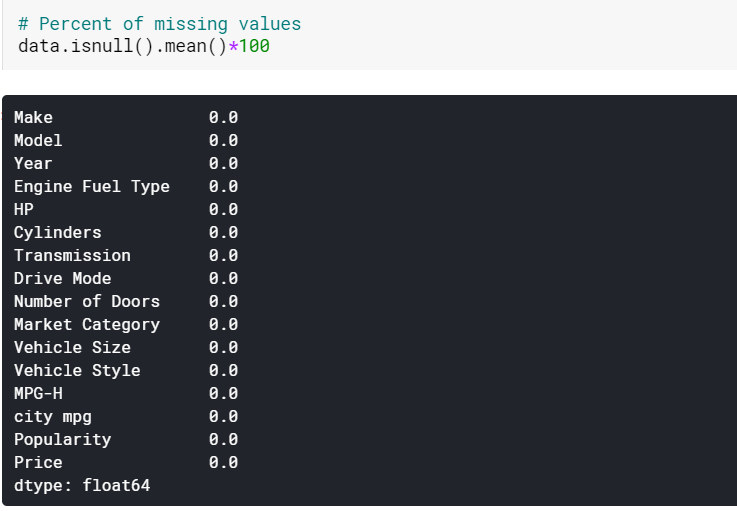
Aquí simplemente imputamos los valores faltantes en las columnas numéricas por sus respectivas medias y los de las columnas categóricas por sus modas. Y como podemos ver, ahora no faltan valores.
Tenga en cuenta que esta es la forma más primitiva de imputar los valores y no funciona en casos de la vida real donde se desarrollan formas más sofisticadas, por ejemplo, interpolación, KNN, etc.
Manejo de filas duplicadas
| # Soltar filas duplicadas datos.drop_duplicates(inplace= True ) |
Esto simplemente elimina las filas duplicadas.
Pago: ideas y temas de proyectos de Python
Análisis bivariado
Ahora veamos cómo obtener más información mediante un análisis bivariado. Bivariado significa un análisis que consta de 2 variables o características. Hay diferentes tipos de gráficos disponibles para diferentes tipos de características.
Para Numérico – Numérico
- Gráfico de dispersión
- Trazado de líneas
- Mapa de calor para correlaciones
Para Categórico-Numérico
- Gráfico de barras
- Trama de violín
- trama de enjambre
Para Categórico-Categórico
- Gráfico de barras
- Gráfico de puntos
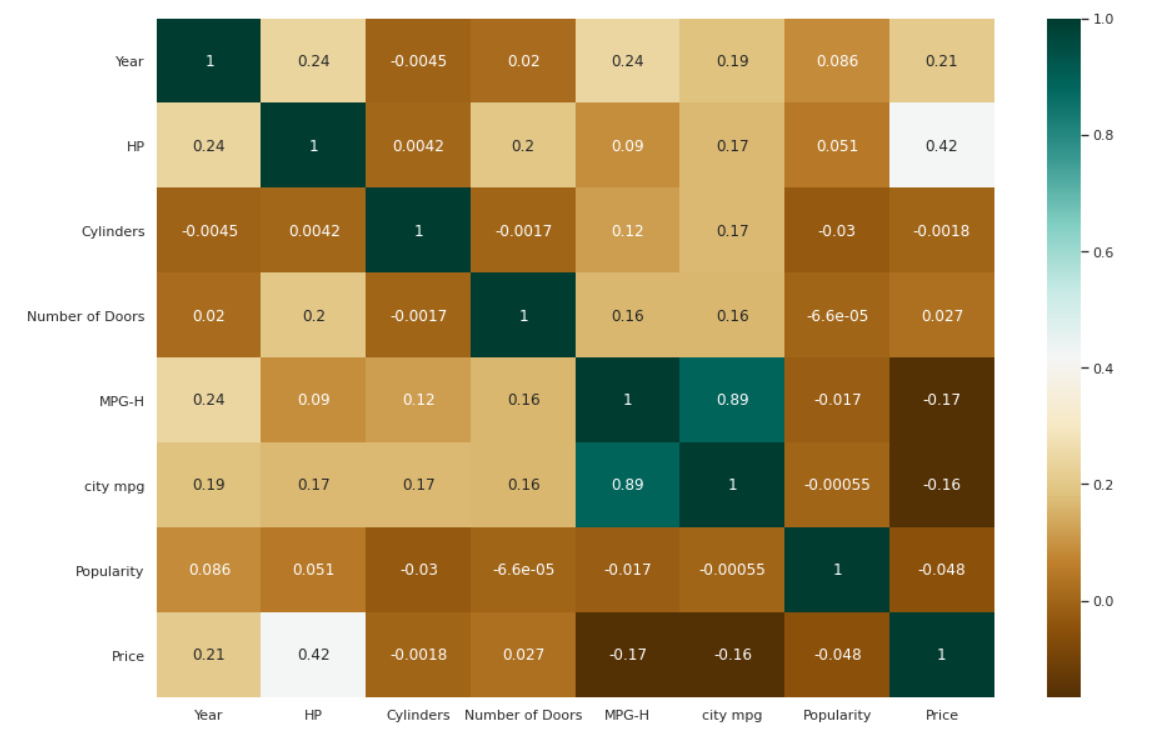
Mapa de calor para correlaciones
| # Comprobación de las correlaciones entre las variables. plt.figura(tamañofig=( 15 , 10 )) c= datos.corr() sns.heatmap(c,cmap= “BrBG” , annot= True ) |
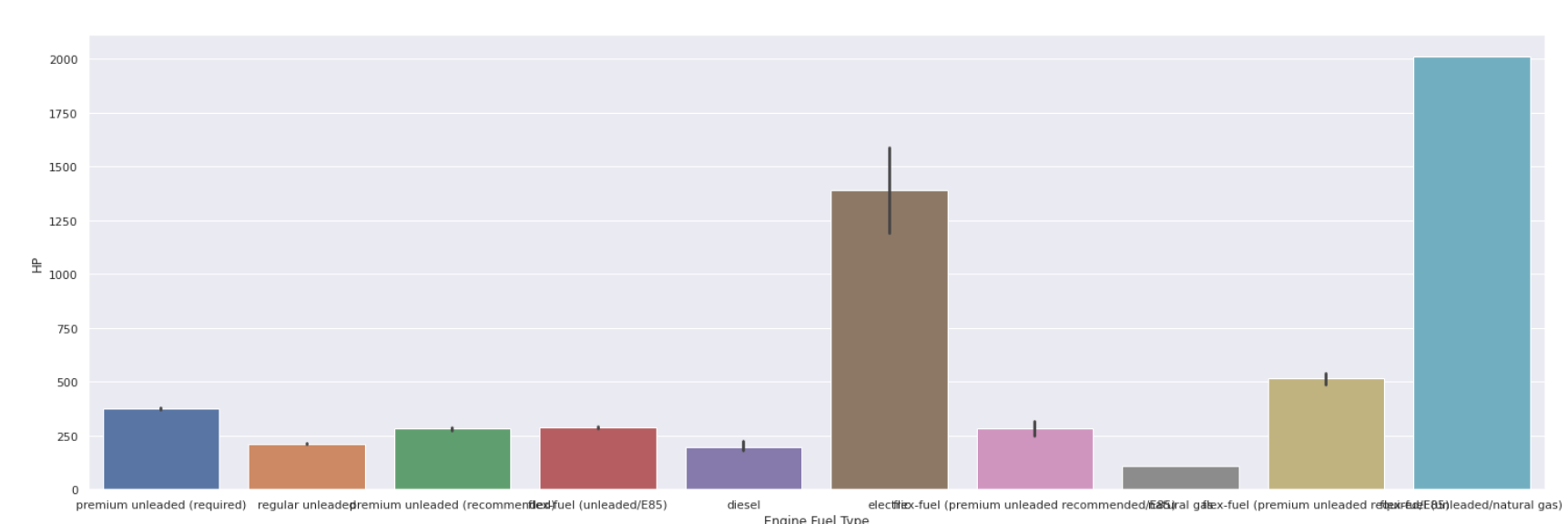
Parcela de barra
| sns.barplot(datos[ 'Tipo de combustible del motor' ], datos[ 'HP' ]) |
Obtenga la certificación de ciencia de datos de las mejores universidades del mundo. Aprenda los programas Executive PG, los programas de certificación avanzada o los programas de maestría para acelerar su carrera.
Conclusión
Como vimos, hay muchos pasos que se deben cubrir al explorar un conjunto de datos. Solo cubrimos un puñado de aspectos en este tutorial, pero esto le dará más que un conocimiento básico de un buen EDA.
Si tiene curiosidad por aprender sobre Python, todo sobre ciencia de datos, consulte el Diploma PG en ciencia de datos de IIIT-B y upGrad, creado para profesionales que trabajan y ofrece más de 10 estudios de casos y proyectos, talleres prácticos prácticos, tutoría con la industria. expertos, 1 a 1 con mentores de la industria, más de 400 horas de aprendizaje y asistencia laboral con las mejores empresas.
¿Cuáles son los pasos en el análisis exploratorio de datos?
Los pasos principales que debe realizar para realizar un análisis exploratorio de datos son:
Deben identificarse las variables y los tipos de datos.
Analizando las métricas fundamentales
Análisis no gráfico univariante
Análisis gráfico univariado
Análisis de datos bivariados
Transformaciones que son variables
Tratamiento por valor faltante
Tratamiento de valores atípicos
Análisis de Correlación
Reducción de Dimensionalidad
¿Cuál es el propósito del análisis exploratorio de datos?
El objetivo principal de EDA es ayudar en el análisis de datos antes de hacer suposiciones. Puede ayudar en la detección de errores evidentes, así como una mejor comprensión de los patrones de datos, la detección de valores atípicos o eventos inusuales y el descubrimiento de relaciones interesantes entre variables.
Los científicos de datos pueden utilizar el análisis exploratorio para garantizar que los resultados que crean sean precisos y apropiados para cualquier resultado y objetivo comercial objetivo. EDA también ayuda a las partes interesadas asegurándose de que estén abordando las preguntas apropiadas. Las desviaciones estándar, los datos categóricos y los intervalos de confianza se pueden responder con EDA. Tras la finalización de EDA y la extracción de información, sus funciones se pueden aplicar a análisis o modelado de datos más avanzados, incluido el aprendizaje automático.
¿Cuáles son los diferentes tipos de análisis exploratorio de datos?
Hay dos tipos de técnicas EDA: gráficas y cuantitativas (no gráficas). El enfoque cuantitativo, por otro lado, requiere la compilación de estadísticas resumidas, mientras que los métodos gráficos implican recopilar los datos de manera esquemática o visual. Los enfoques univariados y multivariados son subconjuntos de estos dos tipos de metodologías.
Para investigar las relaciones, los enfoques univariados analizan una variable (columna de datos) a la vez, mientras que los métodos multivariados analizan dos o más variables a la vez. Gráficos univariados y multivariados y no gráficos son las cuatro formas de EDA. Los procedimientos cuantitativos son más objetivos, mientras que los métodos pictóricos son más subjetivos.