
La guía para el raspado ético de sitios web dinámicos con Node.js y Puppeteer
Publicado: 2022-03-10Comencemos con una pequeña sección sobre lo que realmente significa web scraping. Todos usamos web scraping en nuestra vida cotidiana. Simplemente describe el proceso de extracción de información de un sitio web. Por lo tanto, si copia y pega una receta de su plato de fideos favorito de Internet en su cuaderno personal, está realizando un web scraping .
Cuando usamos este término en la industria del software, generalmente nos referimos a la automatización de esta tarea manual mediante el uso de una pieza de software. Siguiendo con nuestro ejemplo anterior de "plato de fideos", este proceso generalmente implica dos pasos:
- Obteniendo la página
Primero tenemos que descargar la página en su totalidad. Este paso es como abrir la página en su navegador web al raspar manualmente. - Analizando los datos
Ahora, tenemos que extraer la receta en el HTML del sitio web y convertirlo a un formato legible por máquina como JSON o XML.
En el pasado, trabajé para muchas empresas como consultor de datos. Me sorprendió ver cuántas tareas de extracción, agregación y enriquecimiento de datos todavía se realizan manualmente, aunque podrían automatizarse fácilmente con solo unas pocas líneas de código. De eso se trata exactamente el web scraping para mí: extraer y normalizar piezas valiosas de información de un sitio web para impulsar otro proceso empresarial generador de valor.
Durante este tiempo, vi que las empresas usaban web scraping para todo tipo de casos de uso. Las empresas de inversión se centraron principalmente en recopilar datos alternativos, como reseñas de productos , información de precios o publicaciones en redes sociales para respaldar sus inversiones financieras.
Aquí hay un ejemplo. Un cliente se acercó a mí para recopilar datos de revisión de productos para una lista extensa de productos de varios sitios web de comercio electrónico, incluida la calificación, la ubicación del revisor y el texto de revisión para cada revisión enviada. Los datos resultantes permitieron al cliente identificar tendencias sobre la popularidad del producto en diferentes mercados. Este es un excelente ejemplo de cómo una sola pieza de información aparentemente "inútil" puede volverse valiosa en comparación con una cantidad mayor.
Otras empresas aceleran su proceso de ventas mediante el uso de web scraping para la generación de clientes potenciales. Este proceso generalmente implica extraer información de contacto como el número de teléfono, la dirección de correo electrónico y el nombre de contacto para una lista determinada de sitios web. Automatizar esta tarea les da a los equipos de ventas más tiempo para acercarse a los prospectos. Por lo tanto, la eficiencia del proceso de ventas aumenta.
Apegarse a las reglas
En general, el web scraping de datos disponibles públicamente es legal, como lo confirma la jurisdicción del caso Linkedin vs. HiQ. Sin embargo, me he fijado un conjunto de reglas éticas a las que me gusta ceñirme cuando empiezo un nuevo proyecto de web scraping. Esto incluye:
- Comprobando el archivo robots.txt.
Por lo general, contiene información clara sobre a qué partes del sitio puede acceder el propietario de la página mediante robots y raspadores, y resalta las secciones a las que no se debe acceder. - Lectura de los términos y condiciones.
En comparación con robots.txt, esta información no está disponible con menos frecuencia, pero generalmente indica cómo tratan los raspadores de datos. - Raspado con velocidad moderada.
El raspado crea una carga de servidor en la infraestructura del sitio de destino. Dependiendo de lo que extraiga y del nivel de simultaneidad que esté operando su raspador, el tráfico puede causar problemas para la infraestructura del servidor del sitio de destino. Por supuesto, la capacidad del servidor juega un papel importante en esta ecuación. Por lo tanto, la velocidad de mi raspador es siempre un equilibrio entre la cantidad de datos que intento raspar y la popularidad del sitio de destino. Encontrar este equilibrio se puede lograr respondiendo a una sola pregunta: "¿La velocidad planificada va a cambiar significativamente el tráfico orgánico del sitio?". En los casos en los que no estoy seguro de la cantidad de tráfico natural de un sitio, utilizo herramientas como ahrefs para tener una idea aproximada.
Selección de la tecnología adecuada
De hecho, raspar con un navegador sin cabeza es una de las tecnologías de menor rendimiento que puede usar, ya que afecta en gran medida a su infraestructura. Un núcleo del procesador de su máquina puede manejar aproximadamente una instancia de Chrome.
Hagamos un cálculo de ejemplo rápido para ver qué significa esto para un proyecto de web scraping del mundo real.
Guión
- Desea raspar 20,000 URL.
- El tiempo medio de respuesta del sitio de destino es de 6 segundos.
- Su servidor tiene 2 núcleos de CPU.
El proyecto tardará 16 horas en completarse.
Por lo tanto, siempre trato de evitar el uso de un navegador cuando realizo una prueba de viabilidad de raspado para un sitio web dinámico.
Aquí hay una pequeña lista de verificación que siempre reviso:
- ¿Puedo forzar el estado de la página requerida a través de parámetros GET en la URL? En caso afirmativo, simplemente podemos ejecutar una solicitud HTTP con los parámetros adjuntos.
- ¿La información dinámica es parte de la fuente de la página y está disponible a través de un objeto JavaScript en algún lugar del DOM? En caso afirmativo, podemos volver a utilizar una solicitud HTTP normal y analizar los datos del objeto en cadena.
- ¿Se obtienen los datos a través de una solicitud XHR? Si es así, ¿puedo acceder directamente al punto final con un cliente HTTP? En caso afirmativo, podemos enviar una solicitud HTTP directamente al punto final. Muchas veces, la respuesta incluso está formateada en JSON, lo que nos facilita mucho la vida.
Si todas las preguntas se responden con un rotundo "No", oficialmente nos quedamos sin opciones factibles para usar un cliente HTTP. Por supuesto, podría haber más ajustes específicos del sitio que podríamos probar, pero por lo general, el tiempo requerido para resolverlos es demasiado alto, en comparación con el rendimiento más lento de un navegador sin cabeza. La belleza de raspar con un navegador es que puede raspar cualquier cosa que esté sujeta a la siguiente regla básica:
Si puede acceder a él con un navegador, puede rasparlo.
Tomemos el siguiente sitio como ejemplo para nuestro raspador: https://quotes.toscrape.com/search.aspx. Presenta citas de una lista de autores dados para una lista de temas. Todos los datos se obtienen a través de XHR.
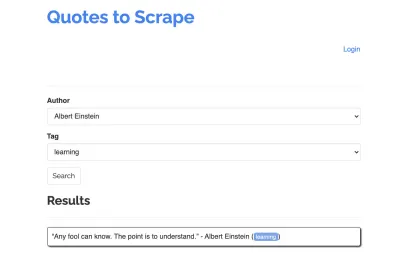
Quien analizó de cerca el funcionamiento del sitio y revisó la lista de verificación anterior probablemente se dio cuenta de que las cotizaciones en realidad podrían rasparse usando un cliente HTTP, ya que pueden recuperarse haciendo una solicitud POST en el punto final de cotizaciones directamente. Pero dado que se supone que este tutorial cubre cómo raspar un sitio web usando Puppeteer, haremos como si esto fuera imposible.
Instalación de requisitos previos
Ya que vamos a construir todo usando Node.js, primero vamos a crear y abrir una nueva carpeta y crear un nuevo proyecto de Nodo dentro, ejecutando el siguiente comando:
mkdir js-webscraper cd js-webscraper npm initAsegúrese de haber instalado npm. El instalador nos hará algunas preguntas sobre la metainformación de este proyecto, que todos podemos omitir, presionando Enter .
Instalación de titiritero
Hemos estado hablando de raspar con un navegador antes. Puppeteer es una API de Node.js que nos permite hablar con una instancia de Chrome sin cabeza mediante programación.
Instalémoslo usando npm:
npm install puppeteerConstruyendo nuestro raspador
Ahora, comencemos a construir nuestro raspador creando un nuevo archivo, llamado scraper.js .
Primero, importamos la librería previamente instalada, Puppeteer:
const puppeteer = require('puppeteer');Como siguiente paso, le decimos a Puppeteer que abra una nueva instancia de navegador dentro de una función asíncrona y autoejecutable:
(async function scrape() { const browser = await puppeteer.launch({ headless: false }); // scraping logic comes here… })();Nota : De forma predeterminada, el modo sin cabeza está desactivado, ya que esto aumenta el rendimiento. Sin embargo, cuando construyo un raspador nuevo, me gusta desactivar el modo sin cabeza. Esto nos permite seguir el proceso por el que pasa el navegador y ver todo el contenido renderizado. Esto nos ayudará a depurar nuestro script más adelante.
Dentro de nuestra instancia de navegador abierta, ahora abrimos una nueva página y nos dirigimos hacia nuestra URL de destino:
const page = await browser.newPage(); await page.goto('https://quotes.toscrape.com/search.aspx'); Como parte de la función asíncrona, usaremos la instrucción await para esperar a que se ejecute el siguiente comando antes de continuar con la siguiente línea de código.
Ahora que hemos abierto con éxito una ventana del navegador y navegado a la página, tenemos que crear el estado del sitio web , para que la información deseada se vuelva visible para el raspado.
Los temas disponibles se generan dinámicamente para un autor seleccionado. Por lo tanto, primero seleccionaremos 'Albert Einstein' y esperaremos la lista de temas generada. Una vez que la lista se ha generado por completo, seleccionamos 'aprendizaje' como tema y lo seleccionamos como segundo parámetro de formulario. Luego hacemos clic en enviar y extraemos las cotizaciones recuperadas del contenedor que contiene los resultados.

Como ahora convertiremos esto en lógica de JavaScript, primero hagamos una lista de todos los selectores de elementos de los que hemos hablado en el párrafo anterior:
| Campo de selección de autor | #author |
| Campo de selección de etiqueta | #tag |
| Botón de enviar | input[type="submit"] |
| Contenedor de cotización | .quote |
Antes de comenzar a interactuar con la página, nos aseguraremos de que todos los elementos a los que accederemos estén visibles, agregando las siguientes líneas a nuestro script:
await page.waitForSelector('#author'); await page.waitForSelector('#tag');A continuación, seleccionaremos valores para nuestros dos campos de selección:
await page.select('select#author', 'Albert Einstein'); await page.select('select#tag', 'learning');Ahora estamos listos para realizar nuestra búsqueda presionando el botón "Buscar" en la página y esperando que aparezcan las comillas:
await page.click('.btn'); await page.waitForSelector('.quote'); Dado que ahora vamos a acceder a la estructura DOM HTML de la página, estamos llamando a la función proporcionada page.evaluate() , seleccionando el contenedor que contiene las comillas (solo es uno en este caso). Luego construimos un objeto y definimos nulo como el valor alternativo para cada parámetro de object :
let quotes = await page.evaluate(() => { let quotesElement = document.body.querySelectorAll('.quote'); let quotes = Object.values(quotesElement).map(x => { return { author: x.querySelector('.author').textContent ?? null, quote: x.querySelector('.content').textContent ?? null, tag: x.querySelector('.tag').textContent ?? null, }; }); return quotes; });Podemos hacer que todos los resultados sean visibles en nuestra consola registrándolos:
console.log(quotes);Finalmente, cerremos nuestro navegador y agreguemos una instrucción catch:
await browser.close();El raspador completo tiene el siguiente aspecto:
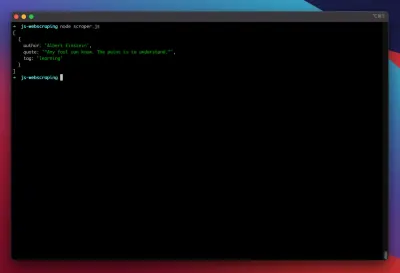
const puppeteer = require('puppeteer'); (async function scrape() { const browser = await puppeteer.launch({ headless: false }); const page = await browser.newPage(); await page.goto('https://quotes.toscrape.com/search.aspx'); await page.waitForSelector('#author'); await page.select('#author', 'Albert Einstein'); await page.waitForSelector('#tag'); await page.select('#tag', 'learning'); await page.click('.btn'); await page.waitForSelector('.quote'); // extracting information from code let quotes = await page.evaluate(() => { let quotesElement = document.body.querySelectorAll('.quote'); let quotes = Object.values(quotesElement).map(x => { return { author: x.querySelector('.author').textContent ?? null, quote: x.querySelector('.content').textContent ?? null, tag: x.querySelector('.tag').textContent ?? null, } }); return quotes; }); // logging results console.log(quotes); await browser.close(); })();Intentemos ejecutar nuestro raspador con:
node scraper.js¡Y allá vamos! El raspador devuelve nuestro objeto de cotización tal como se esperaba:
Optimizaciones Avanzadas
Nuestro raspador básico ya está funcionando. Agreguemos algunas mejoras para prepararlo para algunas tareas de raspado más serias.
Configuración de un agente de usuario
De forma predeterminada, Puppeteer usa un agente de usuario que contiene la cadena HeadlessChrome . Bastantes sitios web buscan este tipo de firma y bloquean las solicitudes entrantes con una firma como esa. Para evitar que eso sea una razón potencial para que el raspador falle, siempre configuro un agente de usuario personalizado agregando la siguiente línea a nuestro código:
await page.setUserAgent('Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4298.0 Safari/537.36');Esto podría mejorarse aún más eligiendo un agente de usuario aleatorio con cada solicitud de una matriz de los 5 agentes de usuario más comunes. Puede encontrar una lista de los agentes de usuario más comunes en un artículo sobre Agentes de usuario más comunes.
Implementando un proxy
Puppeteer hace que conectarse a un proxy sea muy fácil, ya que la dirección del proxy se puede pasar a Puppeteer en el lanzamiento, así:
const browser = await puppeteer.launch({ headless: false, args: [ '--proxy-server=<PROXY-ADDRESS>' ] });sslproxies proporciona una gran lista de proxies gratuitos que puede usar. Como alternativa, se pueden utilizar servicios de proxy rotativos. Como los proxies suelen compartirse entre muchos clientes (o usuarios gratuitos en este caso), la conexión se vuelve mucho menos fiable de lo que ya es en circunstancias normales. Este es el momento perfecto para hablar sobre el manejo de errores y la gestión de reintentos.
Gestión de errores y reintentos
Muchos factores pueden hacer que su raspador falle. Por lo tanto, es importante manejar los errores y decidir qué debe suceder en caso de falla. Dado que hemos conectado nuestro raspador a un proxy y esperamos que la conexión sea inestable (especialmente porque estamos usando proxies gratuitos), queremos volver a intentarlo cuatro veces antes de darnos por vencidos.
Además, no tiene sentido volver a intentar una solicitud con la misma dirección IP si ha fallado anteriormente. Por lo tanto, vamos a construir un pequeño sistema de rotación proxy .
En primer lugar, creamos dos nuevas variables:
let retry = 0; let maxRetries = 5; Cada vez que ejecutamos nuestra función scrape() , aumentaremos nuestra variable de reintento en 1. Luego envolvemos nuestra lógica de raspado completa con una declaración de prueba y captura para que podamos manejar los errores. La gestión de reintentos ocurre dentro de nuestra función catch :
La instancia de navegador anterior se cerrará, y si nuestra variable de reintento es más pequeña que nuestra variable maxRetries , la función de raspado se llama recursivamente.
Nuestro raspador ahora se verá así:
const browser = await puppeteer.launch({ headless: false, args: ['--proxy-server=' + proxy] }); try { const page = await browser.newPage(); … // our scraping logic } catch(e) { console.log(e); await browser.close(); if (retry < maxRetries) { scrape(); } };Ahora, agreguemos el rotador proxy mencionado anteriormente.
Primero creemos una matriz que contenga una lista de proxies:
let proxyList = [ '202.131.234.142:39330', '45.235.216.112:8080', '129.146.249.135:80', '148.251.20.79' ];Ahora, elija un valor aleatorio de la matriz:
var proxy = proxyList[Math.floor(Math.random() * proxyList.length)];Ahora podemos ejecutar el proxy generado dinámicamente junto con nuestra instancia de Titiritero:
const browser = await puppeteer.launch({ headless: false, args: ['--proxy-server=' + proxy] });Por supuesto, este rotador de proxy podría optimizarse aún más para marcar proxies inactivos, etc., pero esto definitivamente iría más allá del alcance de este tutorial.
Este es el código de nuestro scraper (incluyendo todas las mejoras):
const puppeteer = require('puppeteer'); // starting Puppeteer let retry = 0; let maxRetries = 5; (async function scrape() { retry++; let proxyList = [ '202.131.234.142:39330', '45.235.216.112:8080', '129.146.249.135:80', '148.251.20.79' ]; var proxy = proxyList[Math.floor(Math.random() * proxyList.length)]; console.log('proxy: ' + proxy); const browser = await puppeteer.launch({ headless: false, args: ['--proxy-server=' + proxy] }); try { const page = await browser.newPage(); await page.setUserAgent('Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4298.0 Safari/537.36'); await page.goto('https://quotes.toscrape.com/search.aspx'); await page.waitForSelector('select#author'); await page.select('select#author', 'Albert Einstein'); await page.waitForSelector('#tag'); await page.select('select#tag', 'learning'); await page.click('.btn'); await page.waitForSelector('.quote'); // extracting information from code let quotes = await page.evaluate(() => { let quotesElement = document.body.querySelectorAll('.quote'); let quotes = Object.values(quotesElement).map(x => { return { author: x.querySelector('.author').textContent ?? null, quote: x.querySelector('.content').textContent ?? null, tag: x.querySelector('.tag').textContent ?? null, } }); return quotes; }); console.log(quotes); await browser.close(); } catch (e) { await browser.close(); if (retry < maxRetries) { scrape(); } } })();¡Voila! Ejecutar nuestro raspador dentro de nuestra terminal devolverá las cotizaciones.
Dramaturgo como alternativa al titiritero
Titiritero fue desarrollado por Google. A principios de 2020, Microsoft lanzó una alternativa llamada Playwright. Microsoft contrató a muchos ingenieros del Titiritero-Team. Por lo tanto, Playwright fue desarrollado por muchos ingenieros que ya trabajaron en Puppeteer. Además de ser el chico nuevo en el blog, el mayor punto diferenciador de Playwright es la compatibilidad con varios navegadores, ya que es compatible con Chromium, Firefox y WebKit (Safari).
Las pruebas de rendimiento (como esta realizada por Checkly) muestran que Puppeteer generalmente ofrece un rendimiento un 30 % mejor en comparación con Playwright, lo que coincide con mi propia experiencia, al menos en el momento de escribir este artículo.
Otras diferencias, como el hecho de que puede ejecutar varios dispositivos con una instancia de navegador, no son realmente valiosas para el contexto del web scraping.
Recursos y enlaces adicionales
- Documentación del titiritero
- Aprendizaje de titiritero y dramaturgo
- Web Scraping con Javascript por Zenscrape
- Agentes de usuario más comunes
- Titiritero contra dramaturgo