
Desarrollo para la web semántica
Publicado: 2022-03-10En julio, la Fundación Wikimedia anunció la Wikipedia abstracta, un intento de marcar el conocimiento que es independiente del idioma. En muchos aspectos, esta es la culminación de décadas de construcción, durante las cuales el sueño de una Web Semántica nunca despegó del todo, pero tampoco desapareció del todo.
De hecho, la Web Semántica está creciendo y, a medida que renueva su misión, todos podemos beneficiarnos de la incorporación del marcado semántico en nuestros sitios web, ya sean blogs personales o gigantes de las redes sociales. Ya sea que le interesen las experiencias web sofisticadas, el SEO o defenderse de la tiranía de los monopolios web, la Web Semántica merece nuestra atención.
Los beneficios de desarrollar para la Web Semántica no siempre son inmediatos o visibles, pero cada sitio que lo hace fortalece los cimientos de una Internet abierta, transparente y descentralizada.
La Web Semántica
¿Qué es exactamente la Web Semántica? Es una web legible por máquina, que proporciona a través de los metadatos "un marco común que permite que los datos se compartan y reutilicen a través de los límites de la aplicación, la empresa y la comunidad".
La idea es tan antigua como la propia World Wide Web. Mayor, de hecho. Fue un punto focal de la propuesta de Tim Berners-Lee de 1989. Como señaló, no solo los documentos deberían formar redes, sino que los datos dentro de ellos también deberían:
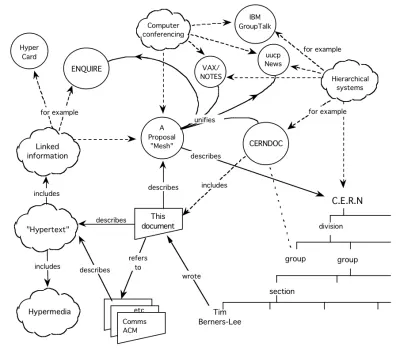
La Web Semántica ha recorrido un camino rocoso en las décadas posteriores. Desde el cambio de milenio, se ha transformado en múltiples conceptos (datos abiertos, gráficos de conocimiento), todos con el mismo significado: redes de datos.
Como resume el W3C, es "una extensión de la web actual en la que la información tiene un significado bien definido, lo que permite que las computadoras y las personas trabajen en cooperación".

La idea ha tenido una buena cantidad de defensores. El hacktivista de Internet Aaron Swartz escribió el manuscrito de un libro sobre la Web Semántica llamado A Programmable Web . En él escribió:
“Los documentos no se pueden fusionar, integrar y consultar realmente; sirven principalmente como instancias aisladas para ser vistas y revisadas. Pero los datos son cambiantes, capaces de adoptar la forma que mejor se adapte a sus necesidades”.
Por una variedad de razones, la Web Semántica no ha despegado de la misma manera que lo ha hecho la Web, aunque se está poniendo al día. Varios marcados han tratado de hacerse con el manto a lo largo de los años (RDFa, OWL y Schema, por nombrar algunos), aunque ninguno se ha convertido en estándar en la forma en que lo han hecho, por ejemplo, HTML o CSS. La barrera de entrada era demasiado alta.
Sin embargo, el sueño de la Web Semántica ha perdurado y, a medida que más y más sitios la incorporan en sus diseños, hay más razones para unirse a la fiesta. Cuantos más sitios se suman, más fuerte se vuelve la Web Semántica.
Otras lecturas
- Inteligencia de datos
- The Semantic Web, un artículo de 2001 de Tim Berners-Lee, James Hensley y Ora Lassila
- Grupo de comunidad web creíble en W3C
Conocimiento Sin Fronteras
Antes de meterse en la maleza de cómo diseñar para la Web Semántica, vale la pena profundizar un poco más en el por qué . ¿Qué importa si los datos están conectados? ¿No son suficientes los documentos conectados?
Hay varias razones por las que la Web Semántica sigue siendo impulsada por quienes se preocupan por una Internet libre y abierta. Comprender esas razones es esencial para el proceso de implementación. No debería ser un caso de 'come tus verduras, usa marcado semántico'. La Web Semántica es algo en lo que creer y ser parte.
Los beneficios de la Web Semántica incluyen:
- Experiencias web más ricas y sofisticadas
- Evitar los silos de contenido y los monopolios de Internet
- Mejora de la legibilidad y las clasificaciones de los motores de búsqueda
- Democratización de la información
La mayoría de estos se remontan a un principio básico de la Web Semántica: un lenguaje universal para datos. Aunque Internet ya ha hecho maravillas para la comunicación internacional, no se puede escapar del hecho de que algunos países lo tienen mucho mejor que otros. Tome los idiomas que se usan en la web frente a los idiomas que se usan en el mundo real, por ejemplo. Los ojos de águila entre ustedes pueden detectar un ligero desequilibrio en los datos a continuación...
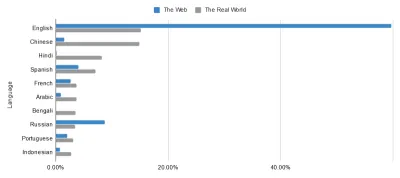
La utopía sin fronteras de la web no está tan cerca como podría parecer para aquellos de nosotros dentro de la burbuja de habla inglesa. ¿Es eso algo por lo que castigar a alguien? No necesariamente, pero es algo a lo que hay que enfrentarse. Hacerlo resalta la importancia del marcado que cierra esas brechas. Al enriquecer los datos de la web, eliminamos la tensión de sus idiomas.
Este es el quid de la Wikipedia abstracta recientemente anunciada, que intentará separar los artículos del idioma en el que están escritos. La directora ejecutiva de Wikimedia, Katherine Maher, escribe: “Usando código, los voluntarios podrán traducir estos 'artículos' abstractos a sus propios idiomas. Si tiene éxito, esto eventualmente podría permitir que todos lean sobre cualquier tema en Wikidata en su propio idioma”.
Resumen El creador de Wikipedia, Denny Vrandecic, ha sido un defensor de la Web Semántica durante años, reconociendo su potencial para desbloquear el potencial sin explotar en línea. Derribar las barreras nacionales es esencial para ese proceso.
“No importa en qué idioma publique su contenido, no podrá incluir a la gran mayoría de las personas en el mundo. La Web nos dio esta maravillosa oportunidad de tener un alcance global, pero al confiar en un solo idioma o en un pequeño conjunto de idiomas, estamos desperdiciando esta oportunidad. Si bien el objetivo más importante es crear un buen contenido en primer lugar, invita a más personas a participar en el desarrollo de un mejor contenido al ser independiente del idioma. Te ayuda a reducir las barreras de contribución y consumo, y permite que muchas más personas se beneficien de ese esfuerzo”.
— Denny Vrandecic, creador de Wikipedia abstracta
Un ejemplo oportuno de esto ha sido la visualización de datos durante la pandemia de COVID-19. El virus ha causado estragos indescriptibles en todo el mundo, pero también ha sido un momento brillante para las redes de datos abiertas, lo que permite que las aplicaciones web excelentes, los informes y más sean comunes en toda la web.
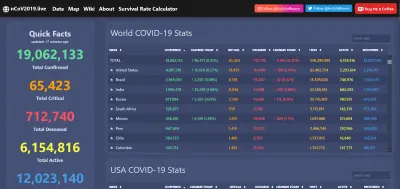
Y, por supuesto, cuando los datos son transparentes y de fácil acceso, es más fácil identificar anomalías... o engaños directos. El acceso público generalizado al tipo de información anterior sería impensable incluso hace 20 años. Ahora lo esperamos, y olemos una rata cuando se nos niega. Los datos son poderosos y, si queremos, se pueden utilizar para siempre.
Del mismo modo, salir de los silos de contenido, un sello distintivo de la experiencia web moderna, quita poder a los monopolios web como Google, Facebook y Twitter. Estamos tan acostumbrados a que las plataformas de terceros descifren y presenten información que olvidamos que no son estrictamente necesarios.
“Si tuviéramos formatos compartidos, protocolos compartidos, aún podríamos terminar con ciertos proveedores que juegan un papel importante en ciertos mercados (piense en Gmail para el correo electrónico), pero todos son libres de cambiarse a otro proveedor y el mercado sigue siendo competitivo”.
— Denny Vrandecic, creador de Wikipedia abstracta
La Web Semántica no tiene silos; es gratuito, abierto y abstracto, lo que permite la comunicación entre diferentes lenguajes y plataformas que de otro modo sería mucho más difícil.
Contenido en línea de data-fying
El diseño para la Web Semántica se reduce a la recopilación de datos de contenido en línea: mirar su contenido y ver qué puede (y debe) abstraerse. ¿Qué significa esto en términos prácticos, más allá de aceptar vagamente que vale la pena hacerlo? Depende:
- Si comienza un proyecto desde cero, incorpore consideraciones de Web Semántica en lo que hace. A medida que un sitio web toma forma, entreteja el marcado semántico en su ADN.
- Si está actualizando o reconstruyendo un proyecto, evalúe lo que podría estar entretejido en la Web Semántica que actualmente no está y luego impleméntelo.
Ambos casos básicamente equivalen a contenido de datos falsos. En esta sección, veremos algunos ejemplos de abstracción de datos y cómo puede hacer que el contenido sea mejor, más inteligente y más accesible.
Información de abstracción
Diseñar y desarrollar para la Web Semántica significa mirar el contenido en línea con el sombrero puesto. La mayoría de nosotros experimentamos la web como una serie de documentos o páginas que se conectan; lo que quieres hacer con la Web Semántica es conectar información. Esto significa evaluar su contenido en busca de puntos de datos y luego ajustar el diseño en función de lo que encuentre.
El defensor de la Web Semántica, James Hendler, describe este proceso particularmente bien con su espíritu DIVE. ( SUMÉRGETE en los datos, ¿eh? ¿Eh?). Se desglosa de la siguiente manera:
- Descubrir
Encuentre conjuntos de datos y/o contenido (incluso fuera de su propia organización). - Integrar
Vincule las relaciones usando etiquetas significativas. - Validar
Proporcionar insumos para los sistemas de modelado y simulación. - Explorar
Desarrollar enfoques para convertir los datos en conocimiento procesable.
Desarrollar para la Web Semántica se trata en gran medida de tener esa vista de pájaro de las cosas que haces y cómo se alimenta potencialmente de experiencias web infinitamente más ricas. Como dice Hendler, el conocimiento procesable es el objetivo.
Esto realmente se puede aplicar a casi cualquier tipo de contenido web, pero comencemos con un ejemplo común: recetas . Digamos que tienes un blog de cocina, con nuevas recetas todos los jueves. Si eres francés y publicas una receta de suflé sensacional en tu blog personal en texto sin formato, solo es útil para aquellos que pueden leer francés.
Sin embargo, al implementar el marcado semántico, el blog se puede transformar en un conjunto de datos de recetas legibles por máquina. Existe sintaxis para abstraer los términos de cocina. Schema, por ejemplo, que puede funcionar junto con Microdata, RDFa o JSON-LD, tiene marcas que incluyen:
- prepTime
- hora de cocinar
- recetaRendimiento
- recetaIngrediente
- costo estimado
- nutrición, desglosada en calorías y contenido de grasa
- adecuadoParaDieta.
Podría seguir. La gama completa de opciones, con ejemplos, se puede leer en Schema.org. Al agregarlos al formato de publicación, el formato de la receta no necesita cambiar en absoluto: simplemente está poniendo la información en términos que las computadoras puedan entender.

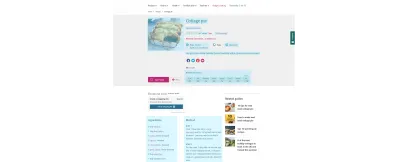
Por ejemplo, todo lo resaltado en azul en la receta de la BBC anterior también recibió un marcado semántico, desde el tiempo de cocción hasta el contenido nutricional. Puede ver lo que sucede debajo del capó ingresando la URL de la receta en la Prueba de resultados enriquecidos de Google. Tenga en cuenta la funcionalidad 'Agregar a la lista de compras', un ejemplo de conexión posible gracias a la implementación de la Web Semántica. El buen contenido se convierte en datos utilizables.
La mayoría de nosotros nos hemos cruzado con este tipo de sofisticación a través de los resultados de búsqueda, pero las aplicaciones son mucho más amplias que eso. El marcado semántico de las recetas facilita que los asistentes domésticos encuentren y utilicen los sitios web. Los ingredientes enumerados se pueden pedir en el supermercado local. Las recetas se pueden filtrar de muchas maneras: por dietas, alergias, religión, costo, lo que sea. O digamos que tenía un número limitado de ingredientes en la casa. Con una base de datos, puede ingresar esos ingredientes y ver qué recetas se ajustan a la factura.
La gama de posibilidades realmente bordea lo ilimitado. Como dijo Swartz, los datos son cambiantes. Una vez que lo tienes, puedes usarlo en todo tipo de formas extrañas y maravillosas. Esta pieza no se trata tanto de esas formas extrañas y maravillosas como de hacerlas posibles. Diseñar para la Web Semántica enriquece infinitamente el diseño posterior.
Aquí hay un ejemplo más personal para mostrar lo que quiero decir. Un par de amigos y yo tenemos un pequeño webzine de música como pasatiempo. Aunque publicamos algún que otro artículo o entrevista, el "evento principal" son nuestras reseñas semanales de álbumes, en las que los tres asignamos una puntuación, elegimos pistas favoritas y escribimos resúmenes. Llevamos más de cinco años, lo que significa que tenemos cerca de 250 revisiones, lo que significa una gran cantidad de datos potenciales. No nos dimos cuenta de cuánto hasta que comenzamos a rediseñar el sitio.
Mencioné esto en un artículo sobre la incorporación de datos estructurados en el proceso de diseño. Al diseccionar nuestras reseñas, nos dimos cuenta de que estaban repletas de información a la que se le podía dar un marcado semántico. Artistas, nombres de álbumes, ilustraciones, fecha de lanzamiento, puntajes individuales, puntajes generales, tipo de lanzamiento y más. Además, y aquí es donde se pone realmente emocionante, nos dimos cuenta de que podíamos conectarnos a una base de datos existente: MusicBrainz.
Este enfoque bidireccional es el quid de la Web Semántica. Cuando nuestro sitio web de música se vuelva a lanzar, será su propia fuente de datos abiertos con miles de puntos de datos únicos. Conectarse a una base de datos de música existente le dará a nuestros propios datos más contexto y potencial. Miles de puntos de datos se convierten en decenas de miles de puntos de datos, tal vez más.
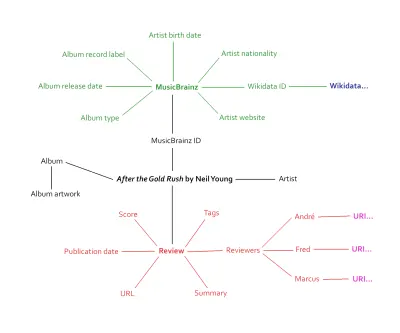
El gráfico anterior solo araña la superficie de la cantidad de información que se conectará a las páginas de reseñas. El contenido es el mismo que antes, solo que ahora está conectado a un ecosistema de metadatos: el gráfico global gigante, como lo llamó una vez Berners-Lee.
Desarrollar para la Web Semántica significa identificar sus propios datos, marcarlos y luego descubrir cómo se conectan con otros datos. Porque lo hace. siempre lo hace Y ese proceso es como esto...
… con el tiempo se convierte en esto…
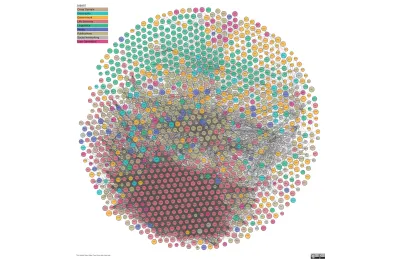
La segunda imagen es The Linked Open Data Cloud, una visualización en constante actualización de los datos conectados de la web. Esa colmena roja de conexiones son las ciencias; el resto tiene camino por recorrer. Ahí es donde entramos.
Recursos útiles de la Web Semántica
- RDF en w3schools.com
- Validador RDF de W3C
- “La web semántica simplificada” por W3C
- “¿Qué pasó con la Web Semántica?” por historia de dos bits
- Generador JSON-LD
- Asistente de marcado de datos estructurados de Google
Conectándose
El ideal de la Web Semántica es la conexión. Hacer datos, compartir datos, exigir datos. Ser parte de un ecosistema de información. Cuando estás creando datos originales, genial. Compártelo. Cuando los datos ya existen y le gustaría usarlos, introdúzcalos.
Estos son solo algunos de los recursos de datos disponibles:
- DPpedia
- MusicBrainz
- mundocat
- ISBNdb
De hecho, donde existen bases de datos como estas, iría tan lejos como para decir que lo correcto sería actualizarlas donde les falta información. ¿Por qué guardártelo para ti? Conviértase en un colaborador, un defensor de la Web Semántica.
Implementación
En lo que respecta a la construcción de Web Semántica en sus sitios, ciertamente no estoy abogando por el marcado manual, doc-by-doc. ¿Quién tiene tiempo para eso? La mayoría de las veces, la solución es un caso de estandarización de un formato y plantillas para él.
Las plantillas son la gran oportunidad aquí. ¿Cuántas personas realmente tienen tiempo para marcar toda esa información manualmente? Sin embargo, si tiene entradas personalizadas, obtiene lo mejor de ambos mundos. El contenido se puede llenar con información amigable para las personas y la información existe como datos listos para servir cualquier propósito que se le ocurra.
Tomemos, por ejemplo, un generador de sitios estáticos como Eleventy, que últimamente ha estado disfrutando un poco del amor de la comunidad de desarrolladores. Escribes una publicación, la ejecutas a través de una plantilla y estás listo. Entonces, ¿por qué no incorporar el marcado semántico en la plantilla misma?
Al igual que Eleventy, la nueva versión de nuestro sitio web de música utiliza Markdown para sus publicaciones. Si bien tenemos las mismas publicaciones de texto antiguas que siempre teníamos, cada revisión ahora también incluye las siguientes entradas de metadatos, que luego se incorporan a la plantilla:
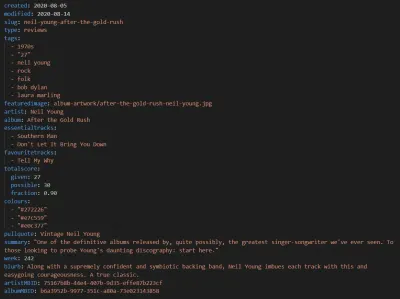
Junto con los detalles del autor en el cuerpo de la publicación y alguna información genérica del sitio web, esto se traduce en el siguiente marcado semántico:
<script type="application/ld+json"> { "@context": "https://schema.org/", "@type": "Review", "reviewBody": "One of the definitive albums released by, quite possibly, the greatest singer-songwriter we've ever seen. To those looking to probe Young's daunting discography: start here.", "datePublished": "2020-08-14", "author": [{ "@type": "Person", "name": "Andre Dack" }, { "@type": "Person", "name": "Frederick O'Brien" }, { "@type": "Person", "name": "Marcus Lawrence" }], "itemReviewed": { "@type": "MusicAlbum", "name": "After the Gold Rush", "@id": "https://musicbrainz.org/release-group/b6a3952b-9977-351c-a80a-73e023143858", "image": "https://audioxide.com/images/album-artwork/after-the-gold-rush-neil-young.jpg", "albumProductionType": "https://schema.org/StudioAlbum", "albumReleaseType": "https://schema.org/AlbumRelease", "byArtist": { "@type": "MusicGroup", "name": "Neil Young", "@id": "https://musicbrainz.org/artist/75167b8b-44e4-407b-9d35-effe87b223cf" } }, "reviewRating": { "@type": "Rating", "ratingValue": 27, "worstRating": 0, "bestRating": 30 }, "publisher": { "@type": "Organization", "name": "Audioxide", "description": "Independent music webzine founded in 2015. Publishes reviews, articles, interviews, and other oddities.", "url": "https://audioxide.com", "logo": "https://audioxide.com/logo-location.jpg", "sameAs" : [ "https://facebook.com/audioxide", "https://twitter.com/audioxide", "https://instagram.com/audioxidecom" ] } } </script>Donde antes solo había texto, en cada página de revisión ahora también habrá versiones legibles por máquina de lo que los lectores ven cuando visitan el sitio. Las palabras todavía están allí, el contenido apenas ha cambiado en absoluto, solo ha sido data-fyed. Desde resultados de búsqueda enriquecidos hasta páginas de estadísticas de revisión interactivas, esto aumenta enormemente lo que es posible. El camino por delante es ancho y abierto. También nos da una participación en el futuro de MusicBrainz. Al conectar sus datos con nuestros propios datos, a su vez queremos que funcione bien y haremos nuestra parte para asegurarnos de que así sea.
El marcado semántico apropiado depende de la naturaleza de un sitio web, pero es probable que exista. Comience con las entradas obvias (fecha, autor, tipo de contenido, etc.) y avance hacia la maleza del contenido. El primer paso podría ser tan simple como una hCard (una especie de tarjeta de identificación digital) para su sitio web personal. Imprima capturas de pantalla de las páginas y comience a anotar. Se sorprenderá de la cantidad de contenido que se puede incluir en los datos.
Más allá de la imaginación
Diseñar y desarrollar para la Web Semántica es una práctica que se remonta a los ideales fundacionales de Internet. Ya sea que valore la visualización de datos hermosos e informativos, desee resultados de búsqueda más sofisticados, desee eliminar el poder de los monopolios web o simplemente crea en la información libre y abierta, la Web Semántica es su aliada.
Aaron Swartz cerró su manuscrito con un llamado a la esperanza:
“La Web Semántica se basa en una apuesta, una apuesta de que dar al mundo herramientas para colaborar y comunicarse fácilmente dará lugar a posibilidades tan maravillosas que apenas podemos imaginarlas en este momento”.
Resumen Wikipedia Denny Vrandecic se hace eco de esos sentimientos hoy, diciendo:
"Existe la necesidad de una infraestructura web que facilite la interoperabilidad entre los servicios, lo que requiere un conjunto común de estándares para representar datos y protocolos comunes entre los proveedores".
La Web Semántica ha progresado lo suficiente como para que quede claro que es poco probable que aparezca un lenguaje milagroso, pero ahora coexisten pacíficamente suficientes para que el sueño fundacional de Berners-Lee sea una realidad para la mayor parte de la Web. Cada uno de nosotros podemos ser defensores en nuestros propios vecindarios.
Sea mejor, exija mejor
Como ha dicho Tim Berners-Lee, la Web Semántica es tanto una cultura como un obstáculo técnico. En una charla TED de 2009, lo resumió muy bien: haga datos vinculados, exija datos vinculados . Eso es más cierto ahora que nunca. La World Wide Web es tan abierta, conectada y buena como la obligamos a ser. Cada vez que haga algo en línea, pregúntese: "¿Cómo puede esto conectarse a la Web Semántica?" Las respuestas agregarán nuevas dimensiones a las cosas que creamos y crearán nuevas posibilidades inimaginablemente maravillosas en los años venideros.