
Visualización de datos en Python: gráficos fundamentales explicados [con ilustración gráfica]
Publicado: 2021-02-08Tabla de contenido
Principios básicos de diseño
Para cualquier científico de datos aspirante o exitoso, ser capaz de explicar su investigación y análisis es una habilidad muy importante y útil que debe poseer. Aquí es donde la visualización de datos entra en escena. Es vital usar esta herramienta con honestidad, ya que la audiencia puede ser fácilmente desinformada o engañada por malas elecciones de diseño.
Como científicos de datos, todos tenemos ciertas obligaciones en cuanto a preservar lo que es verdadero.
La primera es que debemos ser completamente honestos con nosotros mismos al limpiar y resumir los datos. El preprocesamiento de datos es un paso muy importante para que funcione cualquier algoritmo de aprendizaje automático y, por lo tanto, cualquier deshonestidad en los datos conducirá a resultados drásticamente diferentes.
Otra obligación es hacia nuestro público objetivo. Hay varias técnicas en la visualización de datos que se utilizan para resaltar secciones específicas de datos y hacer que otras piezas de datos sean menos prominentes. Entonces, si no somos lo suficientemente cuidadosos, el lector no podrá explorar y juzgar el análisis adecuadamente, lo que puede generar dudas y desconfianza.
Cuestionarse siempre a uno mismo es una buena característica para los científicos de datos. Y siempre debemos pensar en cómo mostrar lo que realmente importa de una manera comprensible y estéticamente agradable, al mismo tiempo que recordamos que el contexto es importante.
Esto es exactamente lo que Alberto Cairo trata de plasmar en sus enseñanzas. Menciona las Cinco Cualidades de las Grandes Visualizaciones: bellas, esclarecedoras, funcionales, perspicaces y veraces, que vale la pena tener en cuenta.
Algunas tramas fundamentales
Ahora que tenemos una comprensión básica de los principios de diseño, profundicemos en algunas técnicas de visualización fundamentales utilizando la biblioteca matplotlib en python.
Todo el código a continuación se puede ejecutar en un cuaderno Jupyter.
Cuaderno %matplotlib
# esto proporciona un entorno interactivo y establece el back-end. ( También se puede usar %matplotlib inline , pero no es interactivo. Esto significa que cualquier llamada adicional a las funciones de trazado no actualizará automáticamente nuestra visualización original).
import matplotlib.pyplot as plt # importando el módulo de biblioteca requerido
Gráficos de puntos
La función matplotlib más simple para trazar un punto es plot() . Los argumentos representan las coordenadas X e Y, luego un valor de cadena que describe cómo se debe mostrar la salida de datos.
plt.figura()
plt.plot( 5, 6, '+' ) # el signo + actúa como marcador
Gráfico de dispersión
Un diagrama de dispersión es un diagrama de dos dimensiones. La función scatter() también toma el valor X como primer argumento y el valor Y como segundo. El diagrama a continuación es una línea diagonal y matplotlib ajusta automáticamente el tamaño de ambos ejes. Aquí, el gráfico de dispersión no trata los elementos como una serie. Entonces, también podemos dar una lista de colores deseados correspondientes a cada uno de los puntos.
importar numpy como np
x = np.matriz([1, 2, 3, 4, 5, 6, 7, 8])
y = x
plt.figura()
plt.dispersión( x, y )
Gráficos de línea
Un gráfico de líneas se crea con la función plot() y traza una serie diferente de puntos de datos como un gráfico de dispersión, pero conecta cada serie de puntos con una línea.
importar numpy como np
datos_lineales = np.matriz([1, 2, 3, 4, 5, 6, 7, 8])
datos_cuadrados = datos_lineales**2
plt.figura()
plt.plot(datos_lineales, '-o', datos_cuadrados, '-o')
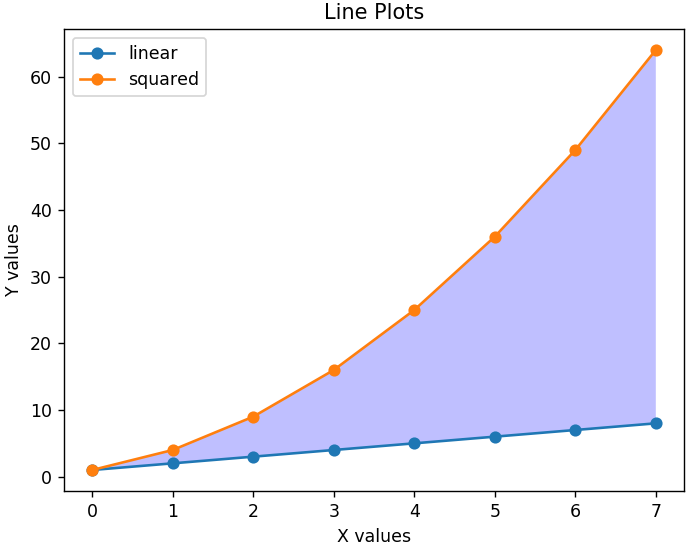
Para que el gráfico sea más legible, también podemos agregar una leyenda que nos diga qué representa cada línea. Es importante un título adecuado para el gráfico y para ambos ejes. Además, cualquier sección del gráfico se puede sombrear usando la función fill_ between() para resaltar las regiones relevantes.
plt.xlabel('Valores X')
plt.ylabel('Valores Y')
plt.title('Gráficos de líneas')

plt.leyenda( ['lineal', 'cuadrado'] )
plt.gca().fill_ between( range ( len ( linear_data ) ), linear_data, squared_data, facecolor = 'blue', alpha = 0.25)
Así es como se ve el gráfico modificado:
Gráfica de barras
Podemos trazar un gráfico de barras enviando argumentos para los valores X y la altura de cada barra a la función bar() . A continuación se muestra un diagrama de barras de la misma matriz de datos lineales que usamos anteriormente.
plt.figura()
x = rango (largo (datos_lineales))
plt.bar(x, datos_lineales)
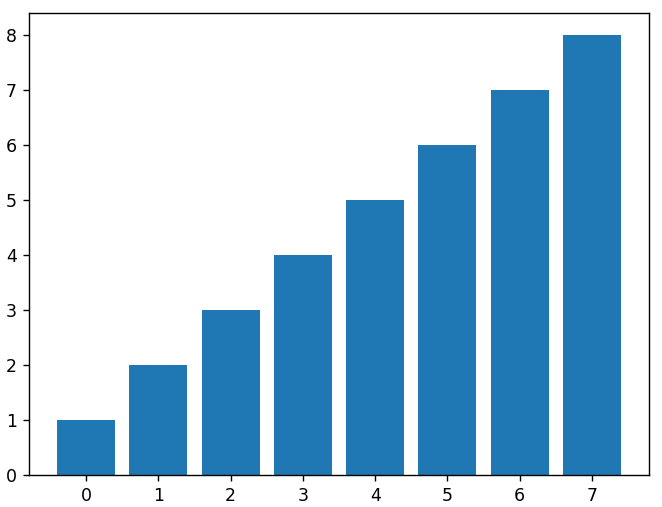
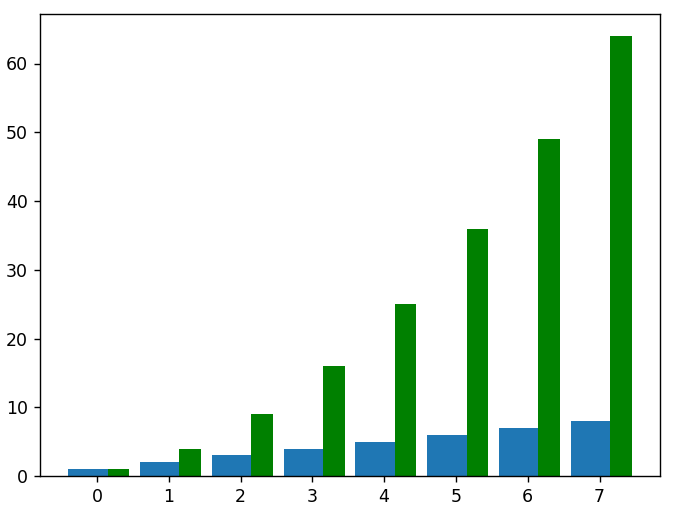
# para trazar los datos cuadrados como otro conjunto de barras en el mismo gráfico, tenemos que ajustar los nuevos valores de x para compensar el primer conjunto de barras
nuevo_x = []
para datos en x:
new_x.append(datos+0.3)
plt.bar(nueva_x, datos_cuadrados, ancho = 0.3, color = 'verde')
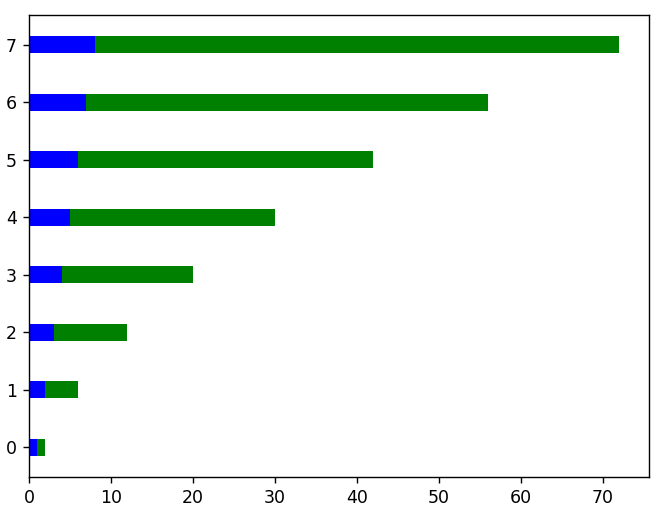
# Para gráficos con orientación horizontal usamos la función barh()
plt.figura()
x = rango (largo (datos_lineales))
plt.barh( x, datos_lineales, altura = 0.3, color = 'b')
plt.barh( x, datos_cuadrados, altura = 0.3, izquierda = datos_lineales, color = 'g')
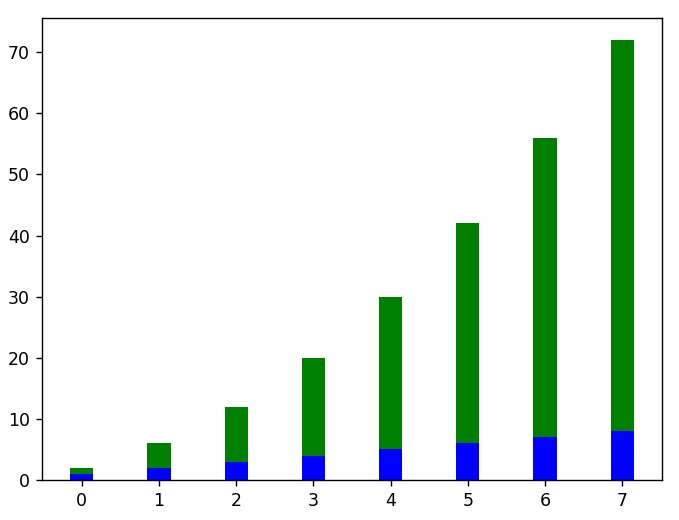
#aquí hay un ejemplo de gráficos de barras apiladas verticalmente
plt.figura()
x = rango (largo (datos_lineales))
plt.bar( x, datos_lineales, ancho = 0.3, color = 'b')
plt.bar( x, datos_cuadrados, ancho = 0.3, parte inferior = datos_lineales, color = 'g')
Aprenda cursos de ciencia de datos de las mejores universidades del mundo. Obtenga programas Executive PG, programas de certificados avanzados o programas de maestría para acelerar su carrera.
Conclusión
Los tipos de visualización no acaban aquí. Python también tiene una gran biblioteca llamada Seaborn que definitivamente vale la pena explorar. La correcta visualización de la información ayuda en gran medida a aumentar el valor de nuestros datos. La visualización de datos siempre será la mejor opción para obtener información e identificar varias tendencias y patrones en lugar de mirar tablas aburridas con millones de registros.
Si tiene curiosidad por aprender sobre ciencia de datos, consulte el Diploma PG en ciencia de datos de IIIT-B y upGrad, creado para profesionales que trabajan y ofrece más de 10 estudios de casos y proyectos, talleres prácticos, tutoría con expertos de la industria, 1- on-1 con mentores de la industria, más de 400 horas de aprendizaje y asistencia laboral con las mejores empresas.
¿Cuáles son algunos paquetes útiles de Python para la visualización de datos?
Python tiene algunos paquetes sorprendentes y útiles para la visualización de datos. Algunos de estos paquetes se mencionan a continuación:
1. Matplotlib : Matplotlib es una biblioteca popular de Python utilizada para la visualización de datos en varias formas, como diagramas de dispersión, gráficos de barras, gráficos circulares y gráficos de líneas. Utiliza Numpy para sus operaciones matemáticas.
2. Seaborn : la biblioteca Seaborn se usa para representaciones estadísticas en Python. Está desarrollado sobre Matplotlib y está integrado con las estructuras de datos de Pandas.
3. Altair : Altair es otra biblioteca popular de Python para la visualización de datos. Es una biblioteca estadística declarativa que le permite crear imágenes con la codificación mínima posible.
4. Plotly : Plotly es una biblioteca de visualización de datos interactiva y de código abierto de Python. Las imágenes creadas por esta biblioteca basada en navegador son compatibles con muchas plataformas, como Jupyter Notebook y archivos HTML independientes.
¿Qué sabes sobre diagramas de puntos y diagramas de dispersión?
Los gráficos de puntos son los gráficos más básicos y simples para la visualización de datos. Un gráfico de puntos muestra los datos en forma de puntos en un plano cartesiano. El “+” muestra el aumento del valor mientras que “-” muestra la disminución del valor a lo largo del tiempo.
Un gráfico de dispersión, por otro lado, es un gráfico optimizado donde los datos se visualizan en un plano 2-D. Se define mediante la función scatter() que toma el valor del eje x como primer parámetro y el valor del eje y como segundo parámetro.
¿Cuáles son las ventajas de la visualización de datos?
Las siguientes ventajas muestran cómo las visualizaciones de datos pueden convertirse en el verdadero héroe para el crecimiento de una organización:
1. La visualización de datos facilita la interpretación de los datos sin procesar y su comprensión para un análisis posterior.
2. Después de investigar y analizar los datos, los resultados se pueden mostrar mediante visualizaciones significativas. Esto hace que sea más fácil conectarse con la audiencia y explicar los resultados.
3. Una de las aplicaciones más esenciales de esta técnica es analizar patrones y tendencias para deducir predicciones y áreas potenciales de crecimiento.
4. También le permite segregar los datos según las preferencias del cliente. También puede identificar las áreas que necesitan más atención.