
Estructuras de datos en Python – Guía completa
Publicado: 2021-06-14Tabla de contenido
¿Qué es la estructura de datos?
La estructura de datos se refiere al almacenamiento computacional de datos para un uso eficiente. Almacena los datos de una manera que se puede modificar y acceder fácilmente. Se refiere colectivamente a los valores de los datos, la relación entre ellos y las operaciones que se pueden realizar en los datos. La importancia de la estructura de datos radica en su aplicación para el desarrollo de programas informáticos. Dado que los programas informáticos dependen en gran medida de los datos, la disposición adecuada de los datos para facilitar el acceso es de suma importancia para cualquier programa o software.
Las cuatro funciones principales de una estructura de datos son
- Para ingresar información
- Para procesar la información
- Para mantener la información
- Para recuperar la información
Tipos de estructuras de datos en Python
Python admite varias estructuras de datos para facilitar el acceso y el almacenamiento de datos. Los tipos de estructuras de datos de Python se pueden clasificar como tipos de datos primitivos y no primitivos. Los primeros tipos de datos incluyen enteros, flotantes, cadenas y booleanos, mientras que el último es la matriz, la lista, las tuplas, los diccionarios, los conjuntos y los archivos. Por lo tanto, las estructuras de datos en python son tanto estructuras de datos integradas como estructuras de datos definidas por el usuario. La estructura de datos integrada se denomina estructura de datos no primitiva.
Estructuras de datos incorporadas
Python tiene varias estructuras de datos que actúan como contenedores para el almacenamiento de otros datos. Estas estructuras de datos de Python son listas, diccionarios, tuplas y conjuntos.
Estructuras de datos definidas por el usuario
Estas estructuras de datos se pueden programar con la misma función que las estructuras de datos integradas en python . Las estructuras de datos definidas por el usuario son: lista enlazada, pila, cola, árbol, gráfico y mapa hash.
Lista de estructuras de datos integradas y explicación
1. Lista
Los datos almacenados en una lista están ordenados secuencialmente y son de diferentes tipos de datos. A cada dato se le asigna una dirección y se le conoce como índice. El valor del índice comienza con un 0 y continúa hasta el último elemento. Esto se llama un índice positivo. También existe un índice negativo si se accede a los elementos de forma inversa. Esto se llama indexación negativa.
Creación de listas
La lista se crea entre corchetes. A continuación, se pueden añadir elementos en consecuencia. Se puede agregar dentro de los corchetes para crear una lista. Si no se agregan elementos, se creará una lista vacía. De lo contrario, se crearán los elementos dentro de la lista.
| Aporte my_list = [] #crea una lista vacía imprimir (mi_lista) mi_lista = [1, 2, 3, 'ejemplo', 3.132] #creando lista con datos imprimir (mi_lista) | Producción [] [1, 2, 3, 'ejemplo', 3.132] |
Agregar elementos dentro de una lista
Se utilizan tres funciones para la adición de elementos dentro de una lista. Estas funciones son append(), extend() e insert().
- Todos los elementos se agregan como un solo elemento usando la función append().
- Para agregar elementos uno por uno en la lista, se usa la función extend().
- Para agregar elementos por su valor de índice, se usa la función insert().
| Aporte mi_lista = [1, 2, 3] imprimir (mi_lista) my_list.append([555, 12]) #añadir como elemento único imprimir (mi_lista) my_list.extend([234, 'more_example']) #añadir como elementos diferentes imprimir (mi_lista) my_list.insert(1, 'insertar_ejemplo') #agregar elemento i imprimir (mi_lista) | Producción: [1, 2, 3] [1, 2, 3, [555, 12]] [1, 2, 3, [555, 12], 234, 'más_ejemplo'] [1, 'insertar_ejemplo', 2, 3, [555, 12], 234, 'más_ejemplo'] |
Eliminación de elementos dentro de una lista
Una palabra clave incorporada "del" en python se usa para eliminar un elemento de la lista. Sin embargo, esta función no devuelve el elemento eliminado.
- Para devolver un elemento eliminado, se utiliza la función pop(). Utiliza el valor de índice del elemento a eliminar.
- La función remove() se usa para eliminar un elemento por su valor.
Producción:
[1, 2, 3, 'ejemplo', 3.132, 30]
[1, 2, 3, 3.132, 30]
Elemento reventado: 2 Lista restante: [1, 3, 3.132, 30]
[]
Evaluación de los elementos de una lista
- Evaluar el elemento en una lista es simple. Al imprimir la lista, se mostrarán directamente los elementos.
- Los elementos específicos se pueden evaluar pasando el valor del índice.
Producción:
1
2
3
ejemplo
3.132
10
30
[1, 2, 3, 'ejemplo', 3.132, 10, 30]
Ejemplo
[1, 2]
[30, 10, 3.132, 'ejemplo', 3, 2, 1]
Además de las operaciones mencionadas anteriormente, Python dispone de otras funciones integradas para trabajar con listas.
- len(): la función se usa para devolver la longitud de la lista.
- index(): esta función permite al usuario conocer el valor de índice de un valor pasado.
- La función count () se usa para encontrar el recuento del valor que se le pasó.
- sort() ordena el valor en una lista y modifica la lista.
- sorted() ordena el valor en una lista y devuelve la lista.
Producción
6
3
2
[1, 2, 3, 10, 10, 30]
[30, 10, 10, 3, 2, 1]
2. Diccionario
El diccionario es un tipo de estructura de datos donde se almacenan pares clave-valor en lugar de elementos individuales. Se puede explicar con el ejemplo de un directorio telefónico que tiene todos los números de personas junto con sus números de teléfono. El nombre y el número de teléfono aquí definen los valores constantes que son la "clave" y los números y nombres de todas las personas como los valores de esa clave. Evaluar una clave dará acceso a todos los valores almacenados dentro de esa clave. Esta estructura clave-valor definida en Python se conoce como diccionario.
Creación de un diccionario.
- Los corchetes florales inactivos, la función dict() se puede usar para crear un diccionario.
- Los pares clave-valor deben agregarse al crear un diccionario.
Modificación en pares clave-valor
Cualquier modificación en el diccionario se puede hacer solo a través de la clave. Por lo tanto, primero se debe acceder a las claves y luego realizar las modificaciones.
| Aporte my_dict = {'First': 'Python', 'Second': 'Java'} print(my_dict) my_dict['Second'] = 'C++' #elemento cambiante print(my_dict) my_dict['Tercero'] = 'Ruby' #agregar par clave-valor print(my_dict) | Producción: {'Primero': 'Python', 'Segundo': 'Java'} {'Primero': 'Python', 'Segundo': 'C++'} {'Primero': 'Python', 'Segundo': 'C++', 'Tercero': 'Ruby'} |
Eliminación de un diccionario
Se utiliza una función de borrado () para eliminar todo el diccionario. El diccionario se puede evaluar a través de las claves usando la función get() o pasando los valores clave.
| Aporte dict = {'Mes': 'Enero', 'Temporada': 'invierno'} imprimir(dict['Primero']) imprimir(dict.get('Segundo') | Producción enero Invierno |
Otras funciones asociadas con un diccionario son claves(), valores() y elementos().
3. tupla
Al igual que la lista, las tuplas son listas de almacenamiento de datos, pero la única diferencia es que los datos almacenados en una tupla no se pueden modificar. Si los datos dentro de una tupla son mutables, solo entonces es posible cambiar los datos.
- Las tuplas se pueden crear a través de la función tuple().
Aporte
nueva_tupla = (10, 20, 30, 40)
imprimir (nueva_tupla)
Producción
(10, 20, 30, 40)
- Los elementos de una tupla se pueden evaluar de la misma manera que se evalúan los elementos de una lista.
Aporte
new_tuple2 = (10, 20, 30, 'edad')
para x en new_tuple2:
imprimir (x)
imprimir (nueva_tupla2)
imprimir(nueva_tupla2[0])
Producción
10
20
30
Años
(10, 20, 30, 'edad')
10
- El operador '+' se usa para agregar otra tupla
Aporte
tupla = (1, 2, 3)
tupla = tupla + (4, 5, 6
imprimir (tupla)
Producción
(1, 2, 3, 4, 5, 6)
4. Establecer
La estructura de datos del conjunto es similar a los conjuntos aritméticos. Es básicamente la colección de elementos únicos. Si los datos siguen repitiéndose, los conjuntos consideran agregar ese elemento solo una vez.
- Se puede crear un conjunto simplemente pasándole los valores entre llaves florales.
Aporte
conjunto = {10, 20, 30, 40, 40, 40}
imprimir (establecer)
Producción
{10, 20, 30, 40}

- La función add() se puede usar para agregar elementos a un conjunto.
- Para combinar datos de dos conjuntos, se puede usar la función union().
- Para identificar los datos que están presentes en ambos conjuntos, se utiliza la función de intersección().
- La función difference() genera solo los datos que son exclusivos del conjunto, eliminando los datos comunes.
- La función symmetric_difference() genera los datos exclusivos de ambos conjuntos.
Lista de estructuras de datos definidas por el usuario y explicación
1. pilas
Una pila es una estructura lineal que es una estructura de último en entrar, primero en salir (LIFO) o primero en entrar, último en salir (FIFO). Existen dos operaciones principales en la pila, es decir, empujar y sacar. Push significa agregar un elemento en la parte superior de la lista, mientras que pop significa eliminar un elemento de la parte inferior de la pila. El proceso está bien descrito en la Figura 1.
Utilidad de la pila
- Los elementos anteriores pueden evaluarse mediante el rastreo hacia atrás.
- Emparejamiento de elementos recursivos.
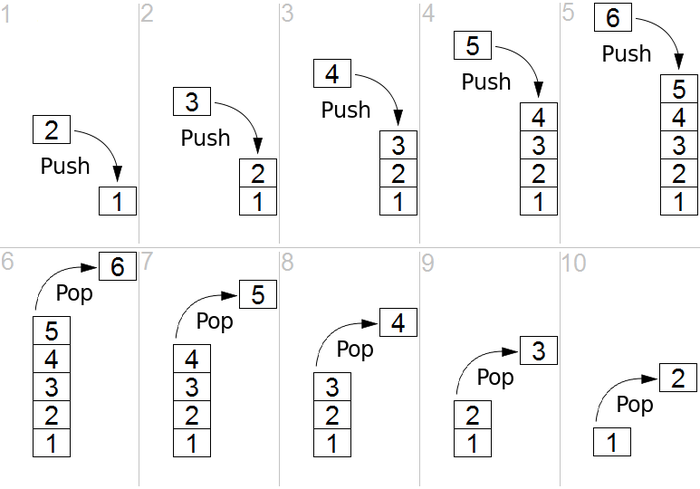
Fuente
Figura 1: Representación gráfica de Stack
Ejemplo

Producción
['primera segunda tercera']
['primero Segundo Tercero Cuarto Quinto']
quinto
['primero Segundo Tercero Cuarto']
2. Cola
Similar a las pilas, una cola es una estructura lineal que permite la inserción de un elemento en un extremo y la eliminación del otro extremo. Las dos operaciones se conocen como enqueue y dequeue. El elemento agregado recientemente se elimina primero como las pilas. En la Figura 2 se muestra una representación gráfica de la cola . Uno de los principales usos de una cola es el procesamiento de cosas tan pronto como ingresan.
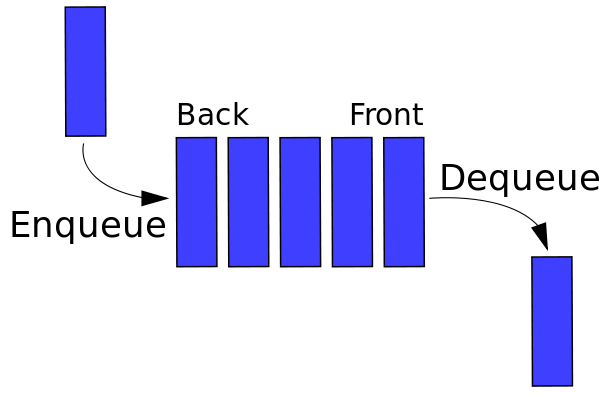
Fuente
Figura 2 : Representación gráfica de Colas
Ejemplo

Producción
['primera segunda tercera']
['primero Segundo Tercero Cuarto Quinto']
primero
quinto
['segundo', 'tercero', 'cuarto', 'quinto']
3. Árbol
Los árboles son estructuras de datos no lineales y jerárquicas que consisten en nodos vinculados a través de bordes. La estructura de datos del árbol de Python tiene un nodo raíz, un nodo principal y un nodo secundario. La raíz es el elemento superior de una estructura de datos. Un árbol binario es una estructura en la que los elementos no tienen más de dos nodos secundarios.
La utilidad de un árbol.
- Muestra las relaciones estructurales de los elementos de datos.
- Atravesar cada nodo de manera eficiente
- Los usuarios pueden insertar, buscar, recuperar y eliminar los datos.
- Estructuras de datos flexibles
Figura 3: Representación gráfica de un árbol
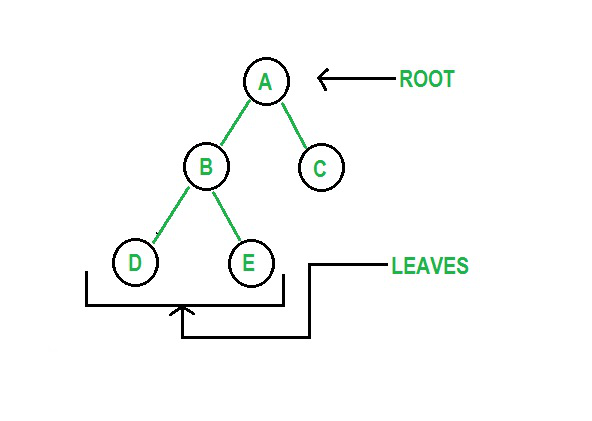
Fuente
Ejemplo:

Producción
Primero
Segundo
Tercera
4. Gráfico
Otra estructura de datos no lineal en python es el gráfico que consta de nodos y bordes. Gráficamente muestra un conjunto de objetos, con algunos objetos conectados a través de enlaces. Los vértices son objetos interconectados, mientras que los enlaces se denominan aristas. La representación de un gráfico se puede hacer a través de la estructura de datos del diccionario de python, donde la clave representa los vértices y los valores representan los bordes.
Operaciones básicas que se pueden realizar en gráficos
- Mostrar vértices y bordes de gráficos.
- Adición de un vértice.
- Adición de un borde.
- Creación de un gráfico
La utilidad de un gráfico
- La representación de un gráfico es fácil de entender y seguir.
- Es una gran estructura para representar relaciones vinculadas, es decir, amigos de Facebook.
Figura 4: Representación gráfica de un gráfico
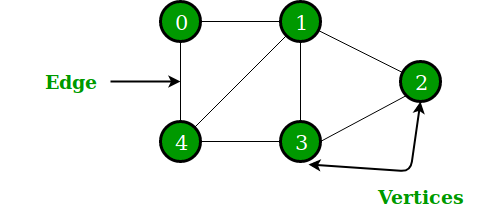
Fuente
Ejemplo

g = gráfica(4)
g.borde(0, 2)
g.borde(1, 3)
g.borde(3, 2)
g.borde(0, 3)
g.__repr__()
Producción
Lista de adyacencia del vértice 0
cabeza -> 3 -> 2
Lista de adyacencia del vértice 1
cabeza -> 3
Lista de adyacencia del vértice 2
cabeza -> 3 -> 0
Lista de adyacencia del vértice 3
cabeza -> 0 -> 2 -> 1
5. mapa hash
Los mapas hash son estructuras de datos de Python indexadas útiles para el almacenamiento de pares clave-valor. Los datos almacenados en hashmaps se recuperan a través de las claves que se calculan con la ayuda de una función hash. Estos tipos de estructuras de datos son útiles para el almacenamiento de datos de estudiantes, detalles de clientes, etc. Los diccionarios en python son un ejemplo de hashmaps.
Ejemplo

Producción
0 -> primero
1 -> segundo
2 -> tercero
0 -> primero
1 -> segundo
2 -> tercero
3 -> cuarto
0 -> primero
1 -> segundo
2 -> tercero
Utilidad
- Es el método más flexible y confiable para recuperar información que otras estructuras de datos.
6. Lista enlazada
Es un tipo de estructura de datos lineal. Básicamente, es una serie de elementos de datos unidos a través de enlaces en python. Los elementos de una lista enlazada se conectan mediante punteros. El primer nodo de esta estructura de datos se denomina encabezado y el último nodo se denomina cola. Por lo tanto, una lista enlazada consta de nodos que tienen valores, y cada nodo consta de un puntero vinculado a otro nodo.
La utilidad de las listas enlazadas
- En comparación con una matriz que es fija, una lista enlazada es una forma dinámica de entrada de datos. La memoria se guarda a medida que asigna la memoria de los nodos. Mientras está en una matriz, el tamaño debe estar predefinido, lo que genera un desperdicio de memoria.
- Una lista enlazada se puede almacenar en cualquier lugar de la memoria. Un nodo de lista vinculada se puede actualizar y mover a una ubicación diferente.
Figura 6: Representación gráfica de una Lista Enlazada
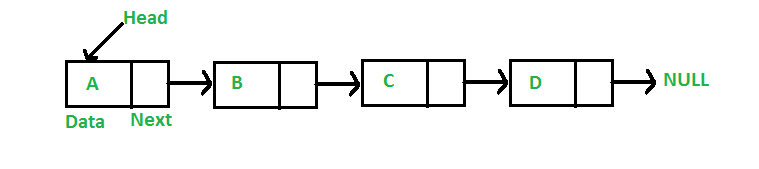
Fuente
Ejemplo

Producción:
['primera segunda tercera']
['primero', 'segundo', 'tercero', 'sexto', 'cuarto', 'quinto']
['primero', 'tercero', 'sexto', 'cuarto', 'quinto']
Conclusión
Se han explorado los diversos tipos de estructuras de datos en python . Ya sea un novato o un experto, las estructuras de datos y los algoritmos no se pueden ignorar. Al realizar cualquier forma de operaciones en los datos, los conceptos de estructuras de datos juegan un papel vital. Las estructuras de datos ayudan a almacenar la información de manera organizada, mientras que los algoritmos ayudan a guiar el análisis de datos. Por lo tanto, tanto las estructuras de datos como los algoritmos de Python ayudan al científico informático o a cualquier usuario a procesar sus datos.
Si tiene curiosidad por aprender sobre estructuras de datos, consulte el Programa PG Ejecutivo en Ciencia de Datos de IIIT-B y upGrad, creado para profesionales que trabajan y ofrece más de 10 estudios de casos y proyectos, talleres prácticos, tutoría con expertos de la industria, 1 -on-1 con mentores de la industria, más de 400 horas de aprendizaje y asistencia laboral con las mejores empresas.
¿Qué estructura de datos es más rápida en Python?
En los diccionarios, las búsquedas son más rápidas porque Python usa tablas hash para implementarlas. Si usamos los conceptos de Big O para ilustrar la distinción, los diccionarios poseen una complejidad de tiempo constante, O(1), mientras que las listas tienen una complejidad de tiempo lineal, O(n).
En Python, los diccionarios son la forma más rápida de buscar datos con miles de entradas con frecuencia. Los diccionarios están altamente optimizados porque son el tipo de mapeo incorporado en Python. En diccionarios y listas, sin embargo, existe una compensación común de espacio-tiempo. Indica que si bien podemos reducir el tiempo requerido para nuestro enfoque, necesitaremos usar más espacio de memoria.
En las listas, para obtener lo que desea, debe pasar por la lista completa. Un diccionario, por otro lado, devolverá el valor que está buscando sin revisar todas las claves.
¿Cuál es más rápido en la lista o matriz de Python?
En general, las listas de Python son increíblemente flexibles y pueden contener datos completamente heterogéneos y aleatorios, además de agregarse rápidamente y en un tiempo constante aproximado. Son el camino a seguir si necesita reducir y ampliar su lista de forma rápida y sencilla. Sin embargo, ocupan mucho más espacio que las matrices, en parte porque cada elemento de la lista requiere la creación de un objeto Python separado.
Por otro lado, el tipo array.array es esencialmente un envoltorio delgado alrededor de las matrices C. Solo puede transportar datos homogéneos (es decir, datos del mismo tipo), por lo tanto, la memoria está limitada al tamaño de (un objeto) * bytes de longitud.
¿Cuál es la diferencia entre la matriz y la lista NumPy?
Numpy es el paquete central de computación científica de Python. Utiliza un gran objeto de matriz multidimensional, así como utilidades para manipularlos. Una matriz numpy es una cuadrícula de valores de tipo idéntico indexados por una tupla de enteros no negativos.
Las listas se incluyeron en la biblioteca central de Python. Una lista es similar a una matriz en Python, pero se puede cambiar el tamaño y contener elementos de varios tipos. ¿Cuál es la verdadera diferencia aquí? El rendimiento es la respuesta. Las estructuras de datos Numpy son más eficientes en términos de tamaño, rendimiento y funcionalidad.