
¿Qué son las estructuras de datos en C y cómo usarlas?
Publicado: 2021-02-26Tabla de contenido
Introducción
Para empezar, una estructura de datos es una colección de elementos de datos que se mantienen juntos bajo un nombre o encabezado y es una forma específica de almacenar y ensamblar los datos para que los datos se puedan usar de manera eficiente.
Tipos
Las estructuras de datos prevalecen y se utilizan en casi todos los sistemas de software. Algunos de los ejemplos más comunes de estructuras de datos son matrices, colas, pilas, listas vinculadas y árboles.
Aplicaciones
En el diseño de compiladores, sistemas operativos, creación de bases de datos, aplicaciones de Inteligencia Artificial y muchos más.
Clasificación
Las estructuras de datos se clasifican en dos categorías: estructuras de datos primitivas y estructuras de datos no primitivas.
1. Primitivos: Son los tipos de datos básicos que soporta un lenguaje de programación. Un ejemplo común de esta clasificación son los números enteros, los caracteres y los valores booleanos.
2. No primitivas: estas categorías de estructuras de datos se crean utilizando estructuras de datos primitivas. Los ejemplos incluyen pilas vinculadas, listas vinculadas, gráficos y árboles.

arreglos
Una matriz es una colección simple de elementos de datos que tienen el mismo tipo de datos. Eso significa que una matriz de enteros de tipo solo puede almacenar valores enteros. Una matriz de tipo de datos flotante puede almacenar valores que corresponden al tipo de datos flotante y nada más.
Los elementos almacenados en una matriz son accesibles linealmente y están presentes en bloques de memoria contiguos a los que se puede hacer referencia mediante un índice.
Declarar una matriz
En C, una matriz se puede declarar como:
nombre del tipo de datos [longitud];
Por ejemplo,
pedidos int[10];
La línea de código anterior crea una matriz de 10 bloques de memoria en los que se puede almacenar un valor entero. En C, el valor del índice de la matriz comienza desde 0. Por lo tanto, los valores del índice oscilarán entre 0 y 9. Si queremos acceder a algún valor en particular en esa matriz, simplemente tenemos que escribir:
printf(orden[número_índice]);
Otra forma de declarar una matriz es la siguiente:
data_type array_name[size]={lista de valores};
Por ejemplo,
int marcas[5]={9, 8, 7, 9, 8};
La línea de comando anterior crea una matriz que tiene 5 bloques de memoria con valores fijos en cada uno de los bloques. En un compilador de 32 bits, la memoria de 32 bits ocupada por el tipo de datos int es de 4 bytes. Entonces, 5 bloques de memoria ocuparían 20 bytes de memoria.
Otra forma legítima de inicializar matrices es:
int marcas [5] = {9, 45};
Este comando creará una matriz de 5 bloques, con los últimos 3 bloques teniendo 0 como valor.
Otra forma legítima es:
int marcas [] = {9, 5, 2, 1, 3,4};
El compilador de C entiende que solo se requieren 5 bloques para colocar estos datos en una matriz. Por lo tanto, inicializará una matriz de marcas de nombre de tamaño 5.
De manera similar, una matriz 2-D se puede inicializar de la siguiente manera
int marcas[2][3]={{9,7,7},{6, 2, 1}};
El comando anterior creará una matriz 2D con 2 filas y 3 columnas.
Leer: Ideas y temas de proyectos de estructura de datos
Operaciones
Hay algunas operaciones que se pueden realizar en matrices. Por ejemplo:
- atravesando una matriz
- Insertar un elemento en la matriz
- Buscando un elemento particular en la matriz
- Eliminar un elemento particular de la matriz
- Fusionando las dos matrices y,
- Clasificación de la matriz: en orden ascendente o descendente.
Desventajas
La memoria asignada a la matriz es fija. Esto en realidad es un problema. Digamos que creamos una matriz de tamaño 50 y solo accedimos a 30 bloques de memoria. Los 20 bloques restantes ocupan memoria sin ningún uso. Por lo tanto, para abordar este problema, tenemos una lista enlazada.
Lista enlazada
Lista enlazada, muy parecida a las matrices que almacenan datos en serie. La principal diferencia es que no almacena todo a la vez. En su lugar, almacena los datos o hace que un bloque de memoria esté disponible cuando sea necesario. En una lista enlazada, los bloques se dividen en dos partes. La primera parte contiene los datos reales.
La segunda parte es un puntero que apunta al siguiente bloque en una lista enlazada. El puntero almacena la dirección del siguiente bloque que contiene los datos. Hay un puntero más conocido como puntero principal. head apunta al primer bloque de memoria en la lista enlazada. A continuación se muestra la representación de la lista enlazada. Estos bloques también se denominan "nodos".
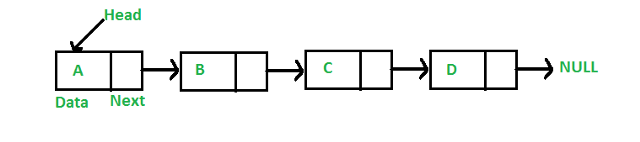
fuente
Inicializar listas enlazadas
Para inicializar la lista de enlaces, creamos un nodo de nombres de estructura. La estructura tiene dos cosas. 1. Los datos que contiene y 2. El puntero que apunta al siguiente nodo. El tipo de datos del puntero será el de la estructura, ya que apunta al nodo de la estructura.

nodo de estructura
{
datos int;
nodo de estructura *siguiente;
};
En una lista enlazada, el puntero del último nodo no apuntará a nada, o simplemente apuntará a nulo.
Lea también: Gráficos en la estructura de datos
Recorrido de lista enlazada
En una lista enlazada, el puntero del último nodo no apuntará a nada, o simplemente apuntará a nulo. Entonces, para recorrer una lista enlazada completa, creamos un puntero ficticio que inicialmente apunta a la cabeza. Y, durante la longitud de la lista vinculada, el puntero continúa avanzando hasta que apunta a nulo o llega al último nodo de la lista vinculada.
Agregar un nodo
El algoritmo para agregar un nodo antes de un nodo específico sería el siguiente:
- establezca dos punteros ficticios (ptr y preptr) que apunten a la cabeza inicialmente
- mueva el ptr hasta que ptr.data sea igual a los datos antes de que tengamos la intención de insertar el nodo. preptr estará 1 nodo detrás de ptr.
- Crear un nodo
- El nodo al que apuntaba el preptr ficticio, el siguiente de ese nodo apuntará a este nuevo nodo
- El siguiente del nuevo nodo apuntará al ptr.
El algoritmo para agregar un nodo después de un dato en particular se haría de manera similar.
Ventajas de la lista enlazada
- Tamaño dinámico a diferencia de una matriz
- Realizar inserción y eliminación es más fácil en la lista enlazada que en una matriz.
Cola
La cola sigue un tipo de sistema Primero en entrar, primero en salir o FIFO. En una implementación de matriz, tendremos dos punteros para demostrar el caso de uso de Queue.
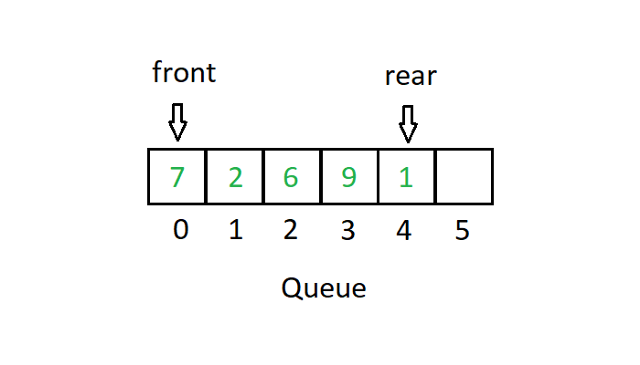
Fuente
FIFO básicamente significa que el valor que ingresa primero a la pila, sale primero de la matriz. En el diagrama de cola anterior, el puntero del frente apunta al valor 7. Si eliminamos el primer bloque (dequeue), el frente ahora apuntará al valor 2. De manera similar, si ingresamos un número (enqueue), digamos, 3 en posición 5. Luego, el indicador trasero apuntará a la posición 5.
Condiciones de desbordamiento y subdesbordamiento
Sin embargo, antes de ingresar un valor de datos en la cola, debemos verificar las condiciones de desbordamiento. Se producirá un desbordamiento cuando se intente insertar un elemento en una cola que ya está llena. Una cola se llenará cuando rear = max_size–1.
Del mismo modo, antes de eliminar datos de la cola, debemos verificar las condiciones de subdesbordamiento. Se producirá un desbordamiento cuando haya un intento de eliminar un elemento de una cola que ya está vacía, es decir, si front = null y rear = null, entonces la cola está vacía.
Apilar
Una pila es una estructura de datos en la que insertamos y eliminamos elementos solo en un extremo, también conocido como la parte superior de la pila. Por lo tanto, la implementación de la pila se denomina implementación de último en entrar, primero en salir (LIFO). A diferencia de la cola, para la pila, solo necesitamos un puntero superior.
Si queremos ingresar (empujar) elementos en una matriz, el puntero superior se mueve hacia arriba o aumenta en 1. Si queremos eliminar (abrir) un elemento, el puntero superior disminuye en 1 o baja en 1 unidad. Una pila admite tres operaciones básicas: empujar, abrir y mirar. La operación peep simplemente muestra el elemento superior en la pila.
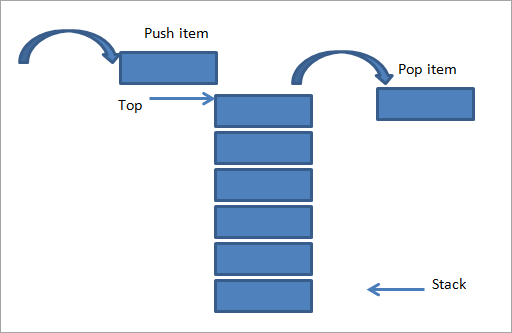
Fuente
Aprenda cursos de software en línea de las mejores universidades del mundo. Obtenga programas Executive PG, programas de certificados avanzados o programas de maestría para acelerar su carrera.
Conclusión
En este artículo, hemos hablado de 4 tipos de estructuras de datos, a saber, matrices, listas vinculadas, colas y pilas. Espero que les haya gustado este artículo y estén atentos para más lecturas interesantes. Hasta la proxima vez.
Si está interesado en obtener más información sobre Javascript, desarrollo de pila completa, consulte el programa Executive PG de upGrad & IIIT-B en desarrollo de software de pila completa, que está diseñado para profesionales que trabajan y ofrece más de 500 horas de capacitación rigurosa, más de 9 proyectos. , y asignaciones, estado de ex alumnos de IIIT-B, proyectos finales prácticos y asistencia laboral con las mejores empresas.
¿Qué son las estructuras de datos en programación?
Las estructuras de datos son la forma en que organizamos los datos en un programa. Las dos estructuras de datos más importantes son las matrices y las listas enlazadas. Las matrices son la estructura de datos más familiar y es la más fácil de entender. Las matrices son básicamente listas numeradas de elementos relacionados. Son simples de entender y usar, pero no son muy eficientes cuando se trabaja con grandes cantidades de datos. Las listas enlazadas son más complejas, pero pueden ser muy eficientes si se usan correctamente. Son buenas opciones cuando tendrá que agregar o eliminar elementos en medio de una lista grande, o cuando necesite buscar elementos en una lista grande.
¿Cuáles son las diferencias entre la lista enlazada y las matrices?
En las matrices, se utiliza un índice para acceder a un elemento. Los elementos de la matriz se organizan en orden secuencial, lo que facilita el acceso y la modificación de los elementos si se utiliza un índice. Array también tiene un tamaño fijo. Los elementos se asignan en el momento de su creación. En la lista enlazada, se utiliza un puntero para acceder a un elemento. Los elementos de una lista enlazada no se almacenan necesariamente en orden secuencial. Una lista enlazada tiene un tamaño desconocido porque puede contener nodos en el momento de su creación. Se utiliza un puntero para acceder a un elemento, por lo que la asignación de memoria es más fácil.
¿Qué es un puntero en C?
Un puntero es un tipo de dato en C que almacena la dirección de cualquier variable o función. Generalmente se usa como una referencia a otra ubicación de memoria. Un puntero puede contener una dirección de memoria de una matriz, estructura, función o cualquier otro tipo. C usa punteros para pasar valores y recibir valores de funciones. Los punteros se utilizan para asignar dinámicamente espacio de memoria.