
La última hoja de trucos de ciencia de datos que todo científico de datos debería tener
Publicado: 2021-01-29Para todos aquellos profesionales en ciernes y novatos que están pensando en sumergirse en el floreciente mundo de la ciencia de datos, hemos compilado una hoja de trucos rápida para que se familiaricen con los conceptos básicos y las metodologías que subrayan este campo.
Tabla de contenido
Ciencia de datos: conceptos básicos
Los datos que se generan en nuestro mundo están sin procesar, es decir, números, códigos, palabras, oraciones, etc. La ciencia de datos toma estos datos sin procesar para procesarlos utilizando métodos científicos para transformarlos en formas significativas para obtener conocimiento e ideas. .
Datos
Antes de sumergirnos en los principios de la ciencia de datos, hablemos un poco sobre los datos, sus tipos y el procesamiento de datos.
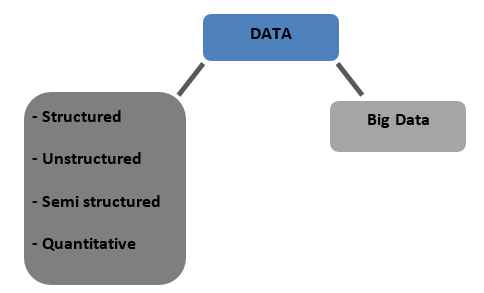
Tipos de datos
Estructurado : datos que se almacenan en un formato tabulado en bases de datos. Puede ser numérico o de texto.
No estructurados : los datos que no se pueden tabular con ninguna estructura definitiva para hablar se denominan datos no estructurados.
Semiestructurado : datos mixtos con rasgos de datos estructurados y no estructurados
Cuantitativo : datos con valores numéricos definidos que se pueden cuantificar
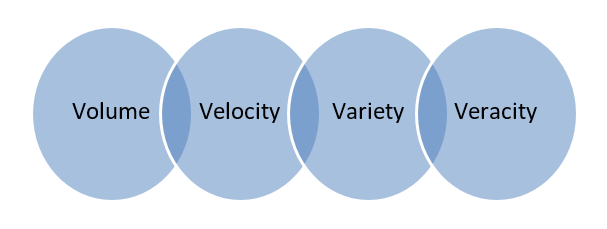
Big Data : los datos almacenados en enormes bases de datos que abarcan varias computadoras o granjas de servidores se denominan Big Data. Los datos biométricos, datos de redes sociales, etc. se consideran Big Data. Big data se caracteriza por 4 V
Preprocesamiento de datos
Clasificación de datos : es el proceso de categorizar o etiquetar datos en clases como numérico, textual o imagen, texto, video, etc.
Limpieza de datos : consiste en eliminar datos faltantes/inconsistentes/incompatibles o reemplazar datos utilizando uno de los siguientes métodos.
- Interpolación
- Heurístico
- Asignación aleatoria
- El vecino mas cercano
Enmascaramiento de datos : ocultar o enmascarar datos confidenciales para mantener la privacidad de la información confidencial sin dejar de procesarla.
¿De qué está hecha la ciencia de datos?
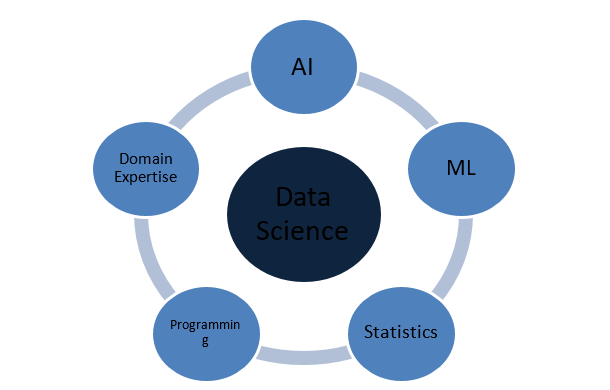
Conceptos de Estadística
Regresión
Regresión lineal
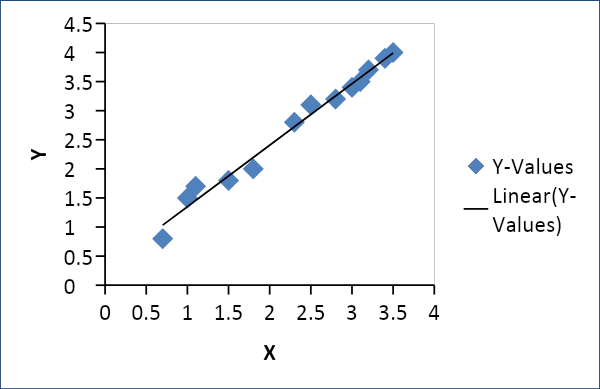
La regresión lineal se utiliza para establecer una relación entre dos variables, como la oferta y la demanda, el precio y el consumo, etc. Relaciona una variable x como una función lineal de otra variable y de la siguiente manera
Y = f(x) o Y =mx + c, donde m = coeficiente
Regresión logística
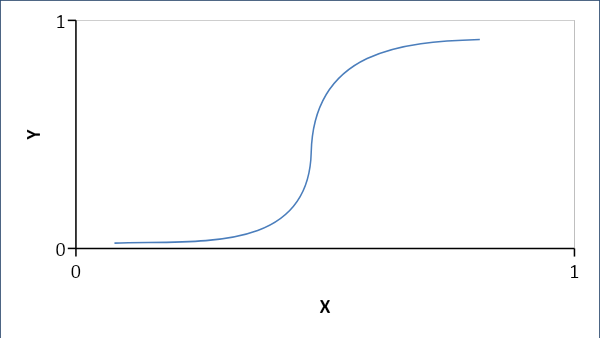
La regresión logística establece una relación probabilística en lugar de lineal entre las variables. La respuesta resultante es 0 o 1 y buscamos probabilidades y la curva tiene forma de S.
Si p < 0.5, entonces es 0 sino 1
Fórmula:
Y = e^ (b0 + b1x) / (1 + e^ (b0 +b1x))
donde b0 = sesgo y b1 = coeficiente
Probabilidad
La probabilidad ayuda a predecir la posibilidad de que ocurra un evento. Algunas terminologías:
Muestra: el conjunto de resultados probables
Evento: Es un subconjunto del espacio muestral
Variable aleatoria: las variables aleatorias ayudan a mapear o cuantificar resultados probables a números o una línea en un espacio de muestra
Distribuciones de probabilidad
Distribuciones discretas: da la probabilidad como un conjunto de valores discretos (entero)
P[X=x] = p(x)
 Fuente de imagen
Fuente de imagen
Distribuciones continuas: da la probabilidad sobre un número de puntos o intervalos continuos en lugar de valores discretos. Fórmula:
P[a ≤ x ≤ b] = a∫bf(x) dx, donde a, b son los puntos
Fuente de imagen
Correlación y Covarianza
Desviación estándar: la variación o desviación de un conjunto de datos dado de su valor medio
σ = √ {(Σi=1N ( xi – x ) ) / (N -1)}
covarianza
Define el grado de desviación de las variables aleatorias X e Y con la media del conjunto de datos.
Cov(X,Y) = σ2XY = E[(X−μX)(Y−μY)] = E[XY]−μXμY
Correlación
La correlación define el alcance de una relación lineal entre variables junto con su dirección, +ve o -ve
ρXY= σ2XY/ σX * *σY
Inteligencia artificial
La capacidad de las máquinas para adquirir conocimiento y tomar decisiones basadas en entradas se llama Inteligencia Artificial o simplemente IA.
Tipos
- Máquinas reactivas: la IA de la máquina reactiva funciona al aprender a reaccionar ante escenarios predefinidos al reducirse a las mejores y más rápidas opciones. Carecen de memoria y son mejores para tareas con un conjunto definido de parámetros. Altamente confiable y consistente.
- Memoria limitada: esta IA tiene algunos datos heredados y de observación del mundo real. Puede aprender y tomar decisiones basadas en los datos proporcionados, pero no puede adquirir nuevas experiencias.
- Teoría de la Mente: Es una IA interactiva que puede tomar decisiones basadas en el comportamiento de las entidades circundantes.
- Conciencia de sí mismo: esta IA es consciente de su existencia y funcionamiento independientemente del entorno. Puede desarrollar habilidades cognitivas y comprender y evaluar los impactos de sus propias acciones en el entorno.
términos de IA
Redes neuronales
Las redes neuronales son un grupo o red de nodos interconectados que transmiten datos e información en un sistema. Los NN están modelados para imitar las neuronas en nuestros cerebros y pueden tomar decisiones aprendiendo y prediciendo.
Heurística
La heurística es la capacidad de predecir en función de aproximaciones y estimaciones rápidamente utilizando la experiencia previa en situaciones en las que la información disponible es irregular. Es rápido pero no exacto ni preciso.
Razonamiento basado en casos
La capacidad de aprender de casos anteriores de resolución de problemas y aplicarlos en situaciones actuales para llegar a una solución aceptable.
Procesamiento natural del lenguaje
Es simplemente la capacidad de una máquina para comprender e interactuar directamente en el habla o texto humano. Por ejemplo, comandos de voz en un automóvil
Aprendizaje automático
Machine Learning es simplemente una aplicación de IA que utiliza varios modelos y algoritmos para predecir y resolver problemas.

Tipos
supervisado
Este método se basa en datos de entrada que se asocian con los datos de salida. La máquina está provista de un conjunto de variables objetivo Y y tiene que llegar a la variable objetivo a través de un conjunto de variables de entrada X bajo la supervisión de un algoritmo de optimización. Ejemplos de aprendizaje supervisado son Redes Neuronales, Random Forest, Deep Learning, Support Vector Machines, etc.
sin supervisión
En este método, las variables de entrada no tienen etiquetas ni asociaciones, y los algoritmos funcionan para encontrar patrones y grupos que dan como resultado nuevos conocimientos e ideas.
Reforzado
El aprendizaje reforzado se centra en técnicas de improvisación para afinar o pulir el comportamiento de aprendizaje. Es un método basado en recompensas en el que la máquina mejora gradualmente sus técnicas para ganar una recompensa objetivo.
Métodos de modelado
Regresión
Los modelos de regresión siempre dan números como salida a través de la interpolación o extrapolación de datos continuos.
Clasificación
Los modelos de clasificación generan salidas como una clase o etiqueta y son mejores para predecir resultados discretos como "de qué tipo".
Tanto la regresión como la clasificación son modelos supervisados.
Agrupación
La agrupación en clústeres es un modelo no supervisado que identifica grupos en función de rasgos, atributos, características, etc.
Algoritmos de aprendizaje automático
Árboles de decisión
Los árboles de decisión utilizan un enfoque binario para llegar a una solución basada en preguntas sucesivas en cada etapa, de modo que el resultado sea cualquiera de los dos posibles, como 'Sí' o 'No'. Los árboles de decisión son fáciles de implementar e interpretar.
Bosque aleatorio o embolsado
Random Forest es un algoritmo avanzado de árboles de decisión. Utiliza una gran cantidad de árboles de decisión que hacen que la estructura sea densa y compleja como un bosque. Genera múltiples resultados y, por lo tanto, conduce a resultados y rendimiento más precisos.
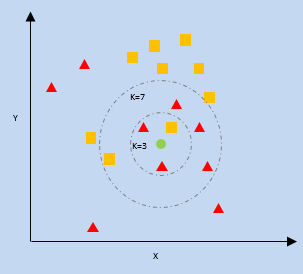
K- Vecino más cercano (KNN)
kNN utiliza la proximidad de los puntos de datos más cercanos en un gráfico en relación con un nuevo punto de datos para predecir en qué categoría se encuentra. El nuevo punto de datos se asigna a la categoría con un mayor número de vecinos.
k = número de vecinos más cercanos
bayesiana ingenua
Naive Bayes trabaja sobre dos pilares, primero que cada característica de los puntos de datos son independientes, sin relación entre sí, es decir, únicos, y segundo sobre el teorema de Bayes que predice resultados basados en una condición o hipótesis.
Teorema de Bayes:
P(X|Y) = {P(Y|X) * P(X)} / P(Y)
Donde P(X|Y) = Probabilidad condicional de X dada la ocurrencia de Y
P(Y|X) = Probabilidad condicional de Y dada la ocurrencia de X
P(X), P(Y) = Probabilidad de X e Y individualmente
Máquinas de vectores de soporte
Este algoritmo intenta segregar datos en el espacio en función de los límites que pueden ser una línea o un plano. Este límite se denomina "hiperplano" y está definido por los puntos de datos más cercanos de cada clase que, a su vez, se denominan "vectores de soporte". La distancia máxima entre los vectores de apoyo de cada lado se llama margen.
Redes neuronales
perceptrón
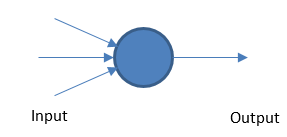
La red neuronal fundamental funciona tomando entradas y salidas ponderadas en función de un valor de umbral.
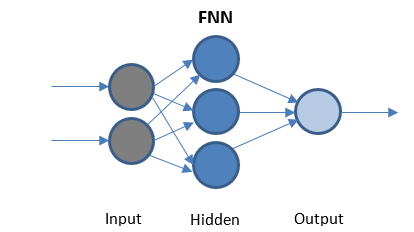
Red neuronal de avance
FFN es la red más simple que transmite datos en una sola dirección. Puede o no tener capas ocultas.
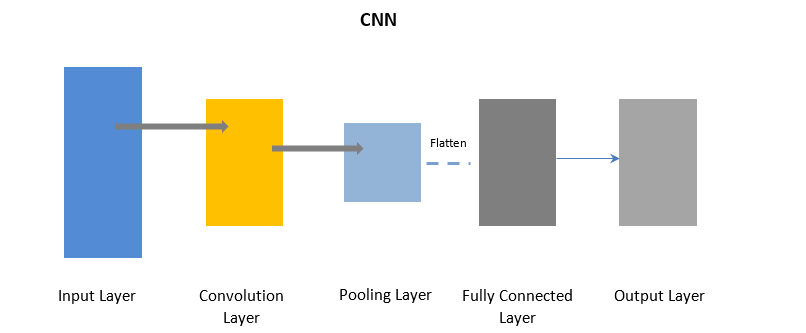
Redes neuronales convolucionales
CNN usa una capa de convolución para procesar ciertas partes de los datos de entrada en lotes seguidos de una capa de agrupación para completar la salida.
Redes neuronales recurrentes
RNN consta de unas pocas capas recurrentes entre las capas de E/S que pueden almacenar datos 'históricos'. El flujo de datos es bidireccional y se alimenta a las capas recurrentes para mejorar las predicciones.
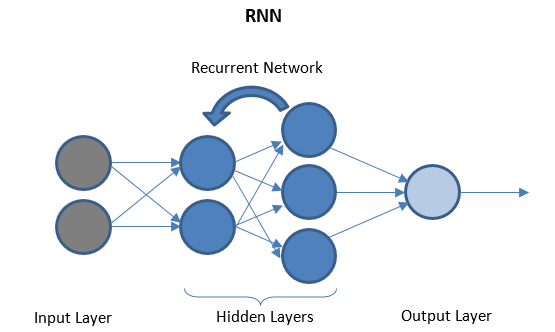
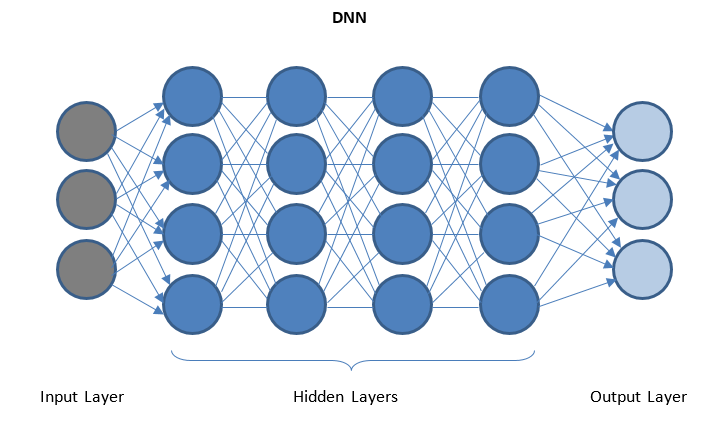
Redes neuronales profundas y aprendizaje profundo
DNN es una red con varias capas ocultas entre las capas de E/S. Las capas ocultas aplican transformaciones sucesivas a los datos antes de enviarlos a la capa de salida.
El 'aprendizaje profundo' se facilita a través de DNN y puede manejar grandes cantidades de datos complejos y lograr una alta precisión debido a múltiples capas ocultas
Obtenga la certificación de ciencia de datos de las mejores universidades del mundo. Aprenda los programas Executive PG, los programas de certificación avanzada o los programas de maestría para acelerar su carrera.
Conclusión
La ciencia de datos es un vasto campo que atraviesa diferentes corrientes, pero se presenta como una revolución y una revelación para nosotros. La ciencia de datos está en auge y cambiará la forma en que funcionan y se sienten nuestros sistemas en el futuro.
Si tiene curiosidad por aprender sobre ciencia de datos, consulte el Diploma PG en ciencia de datos de IIIT-B y upGrad, creado para profesionales que trabajan y ofrece más de 10 estudios de casos y proyectos, talleres prácticos, tutoría con expertos de la industria, 1- on-1 con mentores de la industria, más de 400 horas de aprendizaje y asistencia laboral con las mejores empresas.
¿Qué lenguaje de programación es el más adecuado para la ciencia de datos y por qué?
Existen docenas de lenguajes de programación para la ciencia de datos, pero la mayoría de la comunidad de ciencia de datos cree que si desea sobresalir en la ciencia de datos, Python es la opción correcta. A continuación se presentan algunas de las razones que respaldan esta creencia:
1. Python tiene una amplia gama de módulos y bibliotecas como TensorFlow y PyTorch que facilita el manejo de conceptos de ciencia de datos.
2. Una gran comunidad de desarrolladores de Python ayuda constantemente a los novatos a pasar a la siguiente fase de su viaje de ciencia de datos.
3. Este lenguaje es, con mucho, uno de los más convenientes y fáciles de escribir con una sintaxis limpia que mejora su legibilidad.
¿Cuáles son los conceptos que completan la ciencia de datos?
Data Science es un vasto dominio que actúa como un paraguas para varios otros dominios cruciales. Los siguientes son los conceptos más destacados que constituyen la ciencia de datos:
Estadísticas
La estadística es un concepto importante en el que debe sobresalir para avanzar en la ciencia de datos. Además tiene algunos subtemas:
1. Regresión lineal
2. Probabilidad
3. Distribución de probabilidad
Inteligencia artificial
La ciencia que proporciona a las máquinas un cerebro y les permite tomar sus propias decisiones en función de las entradas se conoce como Inteligencia Artificial. Las máquinas reactivas, la memoria limitada, la teoría de la mente y la autoconciencia son algunos de los tipos de inteligencia artificial.
Aprendizaje automático
El aprendizaje automático es otro componente crucial de la ciencia de datos que se ocupa de enseñar a las máquinas a predecir resultados futuros en función de los datos proporcionados. El aprendizaje automático tiene tres métodos de modelado destacados: agrupación, regresión y clasificación.
¿Describa los tipos de aprendizaje automático?
Machine Learning o ML simple tiene tres tipos principales según sus métodos de trabajo. Estos tipos son los siguientes:
1. Aprendizaje supervisado
Este es el tipo más primitivo de ML donde se etiquetan los datos de entrada. La máquina cuenta con un conjunto más pequeño de datos que le da una idea del problema y se entrena sobre él.
2. Aprendizaje no supervisado
La mayor ventaja de este tipo es que los datos no están etiquetados aquí y el trabajo humano es casi insignificante. Esto abre la puerta para que se introduzcan conjuntos de datos mucho más grandes en el modelo.
3. Aprendizaje Reforzado Este es el tipo más avanzado de ML que se inspira en la vida de los seres humanos. Los resultados deseados se refuerzan mientras que los resultados inútiles se desalientan.