
Preprocesamiento de datos en aprendizaje automático: 7 sencillos pasos a seguir
Publicado: 2021-07-15El preprocesamiento de datos en Machine Learning es un paso crucial que ayuda a mejorar la calidad de los datos para promover la extracción de información significativa de los datos. El preprocesamiento de datos en Machine Learning se refiere a la técnica de preparar (limpiar y organizar) los datos sin procesar para que sean adecuados para la construcción y el entrenamiento de modelos de Machine Learning. En palabras simples, el preprocesamiento de datos en Machine Learning es una técnica de minería de datos que transforma los datos sin procesar en un formato comprensible y legible.
Tabla de contenido
¿Por qué el preprocesamiento de datos en el aprendizaje automático?
Cuando se trata de crear un modelo de Machine Learning, el preprocesamiento de datos es el primer paso que marca el inicio del proceso. Por lo general, los datos del mundo real son incompletos, inconsistentes, inexactos (contienen errores o valores atípicos) y, a menudo, carecen de valores/tendencias de atributos específicos. Aquí es donde el preprocesamiento de datos entra en escena: ayuda a limpiar, formatear y organizar los datos sin procesar, lo que los prepara para los modelos de aprendizaje automático. Exploremos varios pasos del preprocesamiento de datos en el aprendizaje automático.
Únase al curso de inteligencia artificial en línea de las mejores universidades del mundo: maestrías, programas ejecutivos de posgrado y programa de certificado avanzado en ML e IA para acelerar su carrera.
Pasos en el preprocesamiento de datos en aprendizaje automático
Hay siete pasos importantes en el preprocesamiento de datos en Machine Learning:
1. Adquirir el conjunto de datos
La adquisición del conjunto de datos es el primer paso en el preprocesamiento de datos en el aprendizaje automático. Para construir y desarrollar modelos de Machine Learning, primero debe adquirir el conjunto de datos relevante. Este conjunto de datos estará compuesto por datos recopilados de fuentes múltiples y dispares que luego se combinan en un formato adecuado para formar un conjunto de datos. Los formatos de conjuntos de datos difieren según los casos de uso. Por ejemplo, un conjunto de datos comerciales será completamente diferente de un conjunto de datos médicos. Mientras que un conjunto de datos comerciales contendrá datos comerciales y de la industria relevantes, un conjunto de datos médicos incluirá datos relacionados con la atención médica.
Hay varias fuentes en línea desde donde puede descargar conjuntos de datos como https://www.kaggle.com/uciml/datasets y https://archive.ics.uci.edu/ml/index.php . También puede crear un conjunto de datos mediante la recopilación de datos a través de diferentes API de Python. Una vez que el conjunto de datos esté listo, debe ponerlo en formato de archivo CSV, HTML o XLSX.

2. Importa todas las bibliotecas cruciales
Dado que Python es la biblioteca más utilizada y también la preferida por los científicos de datos de todo el mundo, le mostraremos cómo importar bibliotecas de Python para el preprocesamiento de datos en Machine Learning. Obtenga más información sobre las bibliotecas de Python para la ciencia de datos aquí. Las bibliotecas de Python predefinidas pueden realizar trabajos de preprocesamiento de datos específicos. La importación de todas las bibliotecas cruciales es el segundo paso en el preprocesamiento de datos en el aprendizaje automático. Las tres bibliotecas principales de Python utilizadas para este preprocesamiento de datos en Machine Learning son:
- NumPy : NumPy es el paquete fundamental para el cálculo científico en Python. Por lo tanto, se utiliza para insertar cualquier tipo de operación matemática en el código. Usando NumPy, también puede agregar matrices y arreglos multidimensionales grandes en su código.
- Pandas : Pandas es una excelente biblioteca Python de código abierto para la manipulación y el análisis de datos. Se utiliza ampliamente para importar y administrar los conjuntos de datos. Incluye estructuras de datos fáciles de usar y de alto rendimiento y herramientas de análisis de datos para Python.
- Matplotlib : Matplotlib es una biblioteca de trazado 2D de Python que se utiliza para trazar cualquier tipo de gráficos en Python. Puede entregar cifras con calidad de publicación en numerosos formatos impresos y entornos interactivos en todas las plataformas (conchas de IPython, notebook Jupyter, servidores de aplicaciones web, etc.).
Leer : Ideas de proyectos de aprendizaje automático para principiantes
3. Importar el conjunto de datos
En este paso, debe importar los conjuntos de datos que ha recopilado para el proyecto ML en cuestión. Importar el conjunto de datos es uno de los pasos importantes en el preprocesamiento de datos en el aprendizaje automático. Sin embargo, antes de poder importar los conjuntos de datos, debe configurar el directorio actual como el directorio de trabajo. Puede configurar el directorio de trabajo en Spyder IDE en tres simples pasos:
- Guarde su archivo de Python en el directorio que contiene el conjunto de datos.
- Vaya a la opción Explorador de archivos en Spyder IDE y elija el directorio requerido.
- Ahora, haga clic en el botón F5 o en la opción Ejecutar para ejecutar el archivo.
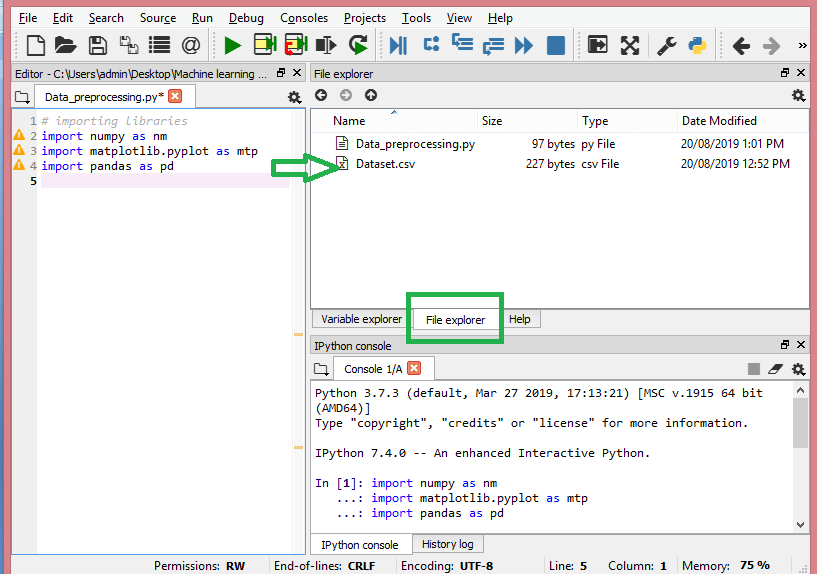
Fuente
Así es como debería verse el directorio de trabajo.
Una vez que haya configurado el directorio de trabajo que contiene el conjunto de datos relevante, puede importar el conjunto de datos utilizando la función "read_csv()" de la biblioteca de Pandas. Esta función puede leer un archivo CSV (ya sea localmente o a través de una URL) y también realizar varias operaciones en él. El read_csv() está escrito como:
data_set= pd.read_csv('Dataset.csv')
En esta línea de código, "conjunto_de_datos" denota el nombre de la variable en la que almacenó el conjunto de datos. La función también contiene el nombre del conjunto de datos. Una vez que ejecute este código, el conjunto de datos se importará con éxito.
Durante el proceso de importación de conjuntos de datos, hay otra cosa esencial que debe hacer: extraer variables dependientes e independientes. Para cada modelo de Machine Learning, es necesario separar las variables independientes (matriz de características) y las variables dependientes en un conjunto de datos.
Considere este conjunto de datos:
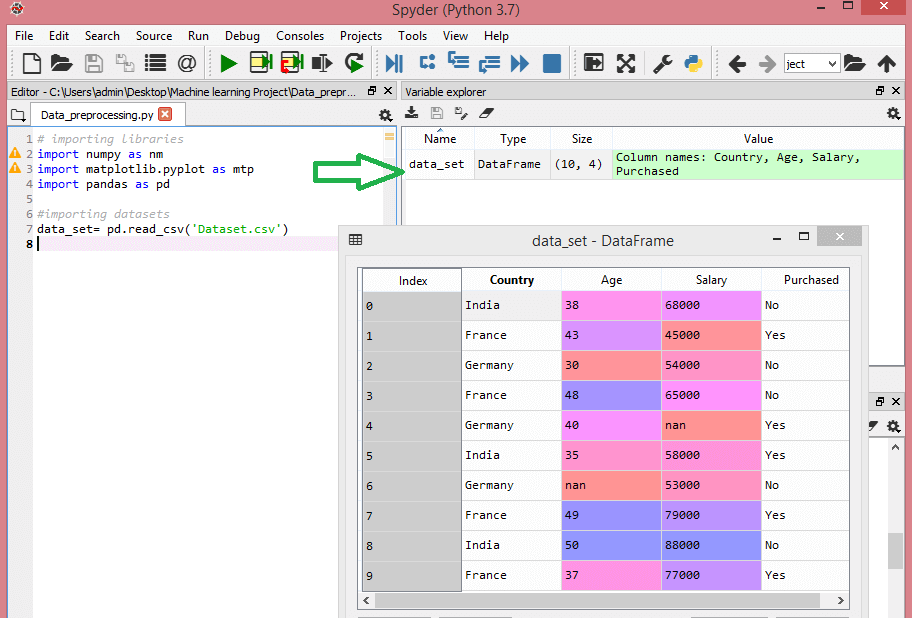
Fuente
Este conjunto de datos contiene tres variables independientes: país, edad y salario, y una variable dependiente: compra.
¿Cómo extraer las variables independientes?
Para extraer las variables independientes, puede utilizar la función “iloc[ ]” de la biblioteca de Pandas. Esta función puede extraer filas y columnas seleccionadas del conjunto de datos.
x= conjunto_datos.iloc[:,:-1].valores
En la línea de código anterior, los primeros dos puntos (:) consideran todas las filas y los segundos dos puntos (:) consideran todas las columnas. El código contiene ":-1" ya que debe omitir la última columna que contiene la variable dependiente. Al ejecutar este código, obtendrá la matriz de funciones, como esta:
[['India' 38.0 68000.0]
['Francia' 43.0 45000.0]
['Alemania' 30.0 54000.0]
['Francia' 48.0 65000.0]
['Alemania' 40.0 nan]
['India' 35.0 58000.0]
['Alemania' nan 53000.0]
['Francia' 49.0 79000.0]
['India' 50.0 88000.0]
['Francia' 37.0 77000.0]]
¿Cómo extraer la variable dependiente?
También puede usar la función "iloc[ ]" para extraer la variable dependiente. Así es como lo escribes:
y= conjunto_datos.iloc[:,3].valores
Esta línea de código considera todas las filas con la última columna solamente. Al ejecutar el código anterior, obtendrá la matriz de variables dependientes, así:
array(['No', 'Sí', 'No', 'No', 'Sí', 'Sí', 'No', 'Sí', 'No', 'Sí'],
dtipo=objeto)
4. Identificar y manejar los valores perdidos
En el preprocesamiento de datos, es fundamental identificar y manejar correctamente los valores faltantes; si no lo hace, podría sacar conclusiones e inferencias inexactas y defectuosas a partir de los datos. No hace falta decir que esto obstaculizará su proyecto ML.
Básicamente, hay dos formas de manejar los datos faltantes:
- Eliminar una fila en particular : en este método, elimina una fila específica que tiene un valor nulo para una función o una columna en particular donde falta más del 75% de los valores. Sin embargo, este método no es 100 % eficiente y se recomienda usarlo solo cuando el conjunto de datos tenga muestras adecuadas. Debe asegurarse de que después de eliminar los datos, no quede ninguna adición de sesgo.
- Cálculo de la media : este método es útil para funciones que tienen datos numéricos como edad, salario, año, etc. Aquí, puede calcular la media, la mediana o la moda de una función, columna o fila en particular que contiene un valor faltante y reemplazar el resultado del valor faltante. Este método puede agregar variación al conjunto de datos, y cualquier pérdida de datos puede ser negada de manera eficiente. Por lo tanto, arroja mejores resultados en comparación con el primer método (omisión de filas/columnas). Otra forma de aproximación es a través de la desviación de los valores vecinos. Sin embargo, esto funciona mejor para datos lineales.
Leer: Aplicaciones de aplicaciones de aprendizaje automático usando la nube
5. Codificación de los datos categóricos
Los datos categóricos se refieren a la información que tiene categorías específicas dentro del conjunto de datos. En el conjunto de datos citado anteriormente, hay dos variables categóricas: país y compra.
Los modelos de aprendizaje automático se basan principalmente en ecuaciones matemáticas. Por lo tanto, puede comprender intuitivamente que mantener los datos categóricos en la ecuación causará ciertos problemas, ya que solo necesitaría números en las ecuaciones.
¿Cómo codificar la variable país?
Como se ve en nuestro ejemplo de conjunto de datos, la columna de país causará problemas, por lo que debe convertirla en valores numéricos. Para hacerlo, puede usar la clase LabelEncoder() de la biblioteca de aprendizaje de sci-kit. El código será el siguiente:
#Datos categóricos
#para variable de país
de sklearn.preprocessing importar LabelEncoder
label_encoder_x= Codificador de etiquetas()
x[:, 0]= codificador_etiqueta_x.fit_transform(x[:, 0])
Y la salida será –
Fuera[15]:
matriz ([[2, 38.0, 68000.0],
[0, 43.0, 45000.0],
[1, 30.0, 54000.0],
[0, 48.0, 65000.0],
[1, 40.0, 65222.22222222222],
[2, 35.0, 58000.0],
[1, 41.111111111111114, 53000.0],
[0, 49.0, 79000.0],
[2, 50.0, 88000.0],
[0, 37.0, 77000.0]], dtype=objeto)
Aquí podemos ver que la clase LabelEncoder ha codificado con éxito las variables en dígitos. Sin embargo, hay variables de país que están codificadas como 0, 1 y 2 en el resultado que se muestra arriba. Entonces, el modelo ML puede suponer que existe cierta correlación entre las tres variables, lo que produce una salida defectuosa. Para eliminar este problema, ahora usaremos codificación ficticia.
Las variables ficticias son aquellas que toman los valores 0 o 1 para indicar la ausencia o presencia de un efecto categórico específico que puede cambiar el resultado. En este caso, el valor 1 indica la presencia de esa variable en una determinada columna mientras que las otras variables pasan a tener el valor 0. En la codificación ficticia, el número de columnas es igual al número de categorías.
Dado que nuestro conjunto de datos tiene tres categorías, producirá tres columnas con los valores 0 y 1. Para la codificación ficticia, usaremos la clase OneHotEncoder de la biblioteca scikit-learn. El código de entrada será el siguiente:
#para variable de país
de sklearn.preprocessing import LabelEncoder, OneHotEncoder
label_encoder_x= Codificador de etiquetas()

x[:, 0]= codificador_etiqueta_x.fit_transform(x[:, 0])
#Codificación para variables ficticias
onehot_encoder= OneHotEncoder(categorical_features= [0])
x = un codificador_caliente.fit_transform(x).toarray()
Al ejecutar este código, obtendrá el siguiente resultado:
matriz([[0.00000000e+00, 0.00000000e+00, 1.00000000e+00, 3.80000000e+01,
6.80000000e+04],
[1.00000000e+00, 0.00000000e+00, 0.00000000e+00, 4.30000000e+01,
4.50000000e+04],
[0.00000000e+00, 1.00000000e+00, 0.00000000e+00, 3.00000000e+01,
5.40000000e+04],
[1,00000000e+00, 0,00000000e+00, 0,00000000e+00, 4,80000000e+01,
6.50000000e+04],
[0.00000000e+00, 1.00000000e+00, 0.00000000e+00, 4.00000000e+01,
6.52222222e+04],
[0.00000000e+00, 0.00000000e+00, 1.00000000e+00, 3.50000000e+01,
5.80000000e+04],
[0.00000000e+00, 1.00000000e+00, 0.00000000e+00, 4.11111111e+01,
5.30000000e+04],
[1,00000000e+00, 0,00000000e+00, 0,00000000e+00, 4,90000000e+01,
7.90000000e+04],
[0.00000000e+00, 0.00000000e+00, 1.00000000e+00, 5.00000000e+01,
8.80000000e+04],
[1.00000000e+00, 0.00000000e+00, 0.00000000e+00, 3.70000000e+01,
7.70000000e+04]])
En el resultado que se muestra arriba, todas las variables se dividen en tres columnas y se codifican en los valores 0 y 1.
¿Cómo codificar la variable comprada?
Para la segunda variable categórica, es decir, comprada, puede utilizar el objeto “labelencoder” de la clase LableEncoder. No estamos usando la clase OneHotEncoder ya que la variable comprada solo tiene dos categorías, sí o no, las cuales están codificadas en 0 y 1.
El código de entrada para esta variable será:
labelencoder_y= LabelEncoder()
y= codificador_etiqueta_y.fit_transform(y)
La salida será –
Salida[17]: matriz([0, 1, 0, 0, 1, 1, 0, 1, 0, 1])
6. Dividir el conjunto de datos
Dividir el conjunto de datos es el siguiente paso en el preprocesamiento de datos en el aprendizaje automático. Cada conjunto de datos para el modelo de Machine Learning debe dividirse en dos conjuntos separados: conjunto de entrenamiento y conjunto de prueba.
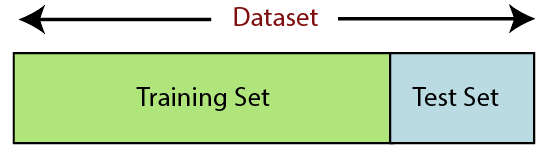
Fuente
Conjunto de entrenamiento denota el subconjunto de un conjunto de datos que se utiliza para entrenar el modelo de aprendizaje automático. Aquí, ya está al tanto de la salida. Un conjunto de prueba, por otro lado, es el subconjunto del conjunto de datos que se utiliza para probar el modelo de aprendizaje automático. El modelo ML usa el conjunto de prueba para predecir los resultados.
Por lo general, el conjunto de datos se divide en una proporción de 70:30 o una proporción de 80:20. Esto significa que toma el 70 % o el 80 % de los datos para entrenar el modelo y omite el 30 % o el 20 % restante. El proceso de división varía según la forma y el tamaño del conjunto de datos en cuestión.
Para dividir el conjunto de datos, debe escribir la siguiente línea de código:
de sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test= train_test_split(x, y, test_size= 0.2, random_state=0)
Aquí, la primera línea divide las matrices del conjunto de datos en subconjuntos aleatorios de prueba y tren. La segunda línea de código incluye cuatro variables:
- x_train: funciones para los datos de entrenamiento
- x_test: funciones para los datos de prueba
- y_train – variables dependientes para datos de entrenamiento
- y_test – variable independiente para probar datos
Por lo tanto, la función train_test_split() incluye cuatro parámetros, los dos primeros de los cuales son para matrices de datos. La función test_size especifica el tamaño del conjunto de prueba. El test_size puede ser .5, .3 o .2; esto especifica la relación de división entre los conjuntos de entrenamiento y prueba. El último parámetro, "random_state", establece la semilla para un generador aleatorio para que la salida sea siempre la misma.
7. Escalado de características
El escalado de características marca el final del preprocesamiento de datos en Machine Learning. Es un método para estandarizar las variables independientes de un conjunto de datos dentro de un rango específico. En otras palabras, el escalado de características limita el rango de variables para que pueda compararlas en términos comunes.
Considere este conjunto de datos, por ejemplo:
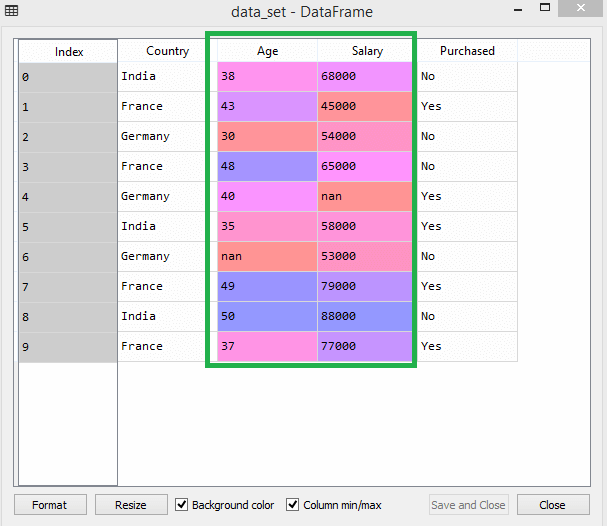
Fuente
En el conjunto de datos, puede notar que las columnas de edad y salario no tienen la misma escala. En tal escenario, si calcula dos valores cualquiera de las columnas de edad y salario, los valores de salario dominarán los valores de edad y generarán resultados incorrectos. Por lo tanto, debe eliminar este problema mediante el escalado de características para el aprendizaje automático.
La mayoría de los modelos de ML se basan en la distancia euclidiana, que se representa como:
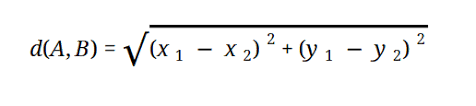
Fuente
Puede realizar el escalado de características en Machine Learning de dos maneras:
Estandarización
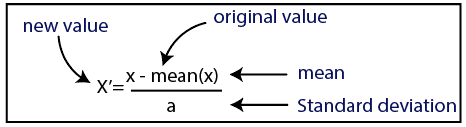
Fuente
Normalización
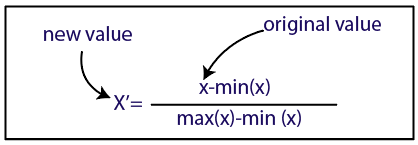
Fuente
Para nuestro conjunto de datos, utilizaremos el método de estandarización. Para hacerlo, importaremos la clase StandardScaler de la biblioteca sci-kit-learn usando la siguiente línea de código:
de sklearn.preprocessing importar StandardScaler
El siguiente paso será crear el objeto de la clase StandardScaler para variables independientes. Después de esto, puede ajustar y transformar el conjunto de datos de entrenamiento usando el siguiente código:
st_x= Escalador estándar()
tren_x= st_x.fit_transform(tren_x)
Para el conjunto de datos de prueba, puede aplicar directamente la función transform() (no necesita usar la función fit_transform() porque ya está hecha en el conjunto de entrenamiento). El código será el siguiente:
x_test= st_x.transform(x_test)
La salida para el conjunto de datos de prueba mostrará los valores escalados para x_train y x_test como:
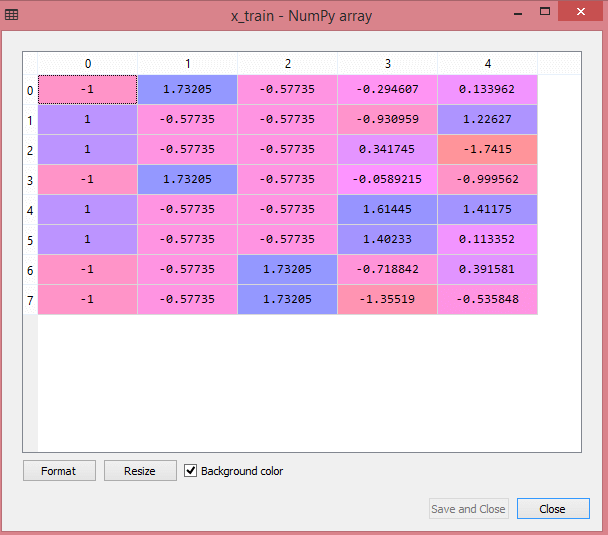
Fuente
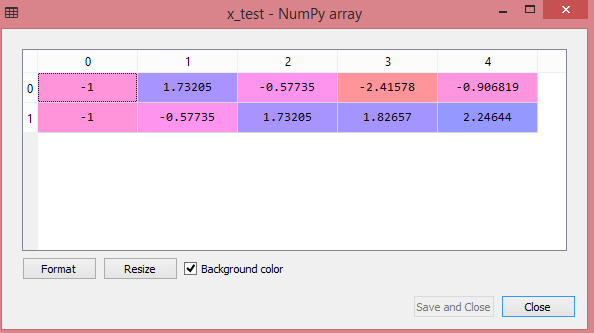
Fuente
Todas las variables en la salida están escaladas entre los valores -1 y 1.
Ahora, para combinar todos los pasos que hemos realizado hasta ahora, obtienes:
# importando bibliotecas
importar numpy como nm
importar matplotlib.pyplot como mtp
importar pandas como pd
#importación de conjuntos de datos
data_set= pd.read_csv('Dataset.csv')
#Extracción de variable independiente
x= conjunto_datos.iloc[:, :-1].valores
#Extracción de la variable dependiente
y= conjunto_datos.iloc[:, 3].valores
#manejar los datos que faltan (reemplazar los datos que faltan con el valor medio)
desde sklearn.preprocessing import Imputer
imputer= Imputer(missing_values ='NaN', estrategia='media', eje = 0)
#Ajustando objeto imputador a las variables independientes x.
imputerimputer= imputer.fit(x[:, 1:3])
#Reemplazando los datos que faltan con el valor medio calculado
x[:, 1:3]= imputador.transformar(x[:, 1:3])
#para variable de país
de sklearn.preprocessing import LabelEncoder, OneHotEncoder
label_encoder_x= Codificador de etiquetas()
x[:, 0]= codificador_etiqueta_x.fit_transform(x[:, 0])
#Codificación para variables ficticias
onehot_encoder= OneHotEncoder(categorical_features= [0])
x = un codificador_caliente.fit_transform(x).toarray()
#codificación para la variable comprada
labelencoder_y= LabelEncoder()
y= codificador_etiqueta_y.fit_transform(y)
# Dividir el conjunto de datos en conjunto de entrenamiento y prueba.
de sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test= train_test_split(x, y, test_size= 0.2, random_state=0)
#Feature Escalado de conjuntos de datos
de sklearn.preprocessing importar StandardScaler
st_x= Escalador estándar()
tren_x= st_x.fit_transform(tren_x)
x_test= st_x.transform(x_test)
Entonces, ¡eso es procesamiento de datos en Machine Learning en pocas palabras!
Puede consultar el Programa Executive PG de IIT Delhi en Machine Learning & AI en asociación con upGrad . IIT Delhi es una de las instituciones más prestigiosas de la India. Con más de 500+ profesores internos que son los mejores en las materias.
¿Cuál es la importancia del preprocesamiento de datos?
Debido a que los errores, las redundancias, los valores faltantes y las incoherencias ponen en peligro la integridad del conjunto de datos, debe abordarlos todos para obtener un resultado más preciso. Suponga que está utilizando un conjunto de datos defectuoso para entrenar un sistema de aprendizaje automático para gestionar las compras de sus clientes. Es probable que el sistema genere sesgos y desviaciones, lo que resultará en una mala experiencia de usuario. Como resultado, antes de usar esos datos para el propósito previsto, deben estar tan organizados y "limpios" como sea posible. Dependiendo del tipo de dificultad con la que te enfrentes, existen numerosas opciones.
¿Qué es la limpieza de datos?
Es casi seguro que habrá datos perdidos y ruidosos en sus conjuntos de datos. Debido a que el procedimiento de recopilación de datos no es ideal, tendrá mucha información inútil y faltante. La limpieza de datos es la forma que debe emplear para lidiar con este problema. Esto se puede dividir en dos categorías. El primero analiza cómo lidiar con los datos faltantes. Puede optar por ignorar los valores que faltan en esta sección de la recopilación de datos (llamada tupla). El segundo método de limpieza de datos es para datos con ruido. Es fundamental deshacerse de los datos inútiles que los sistemas no pueden leer si desea que todo el proceso funcione sin problemas.
¿Qué quiere decir con transformación y reducción de datos?
El preprocesamiento de datos pasa a la etapa de transformación después de abordar las inquietudes. Lo usa para convertir datos en conformaciones relevantes para el análisis. La normalización, la selección de atributos, la discretización y la generación de jerarquías de conceptos son algunos de los enfoques que se pueden utilizar para lograr esto. Incluso para los métodos automatizados, examinar grandes conjuntos de datos puede llevar mucho tiempo. Es por eso que la etapa de reducción de datos es tan crucial: reduce el tamaño de los conjuntos de datos al limitarlos a la información más importante, aumentando la eficiencia del almacenamiento y reduciendo los gastos financieros y de tiempo de trabajar con ellos.