
Creación de un flujo de trabajo de prueba de integración continua mediante acciones de GitHub
Publicado: 2022-03-10Al contribuir a proyectos en plataformas de control de versiones como GitHub y Bitbucket, la convención es que existe una rama principal que contiene el código base funcional. Luego, hay otras ramas en las que varios desarrolladores pueden trabajar en copias de la principal para agregar una nueva función, corregir un error, etc. Tiene mucho sentido porque se vuelve más fácil monitorear el tipo de efecto que tendrán los cambios entrantes en el código existente. Si hay algún error, se puede rastrear y corregir fácilmente antes de integrar los cambios en la rama principal. Puede llevar mucho tiempo revisar cada línea de código manualmente en busca de errores o fallas, incluso para un proyecto pequeño. Ahí es donde entra la integración continua.
¿Qué es la integración continua (CI)?
“La integración continua (CI) es la práctica de automatizar la integración de cambios de código de múltiples colaboradores en un solo proyecto de software”.
— Atlassian.com
La idea general detrás de la integración continua (CI) es garantizar que los cambios realizados en el proyecto no "rompan la compilación", es decir, arruinen la base de código existente. La implementación de la integración continua en su proyecto, dependiendo de cómo configure su flujo de trabajo, crearía una compilación cada vez que alguien realice cambios en el repositorio.
Entonces, ¿qué es una compilación?
Una compilación, en este contexto, es la compilación del código fuente en un formato ejecutable. Si tiene éxito, significa que los cambios entrantes no tendrán un impacto negativo en el código base, y están listos para comenzar. Sin embargo, si la compilación falla, los cambios deberán volver a evaluarse. Por eso es recomendable realizar cambios en un proyecto trabajando en una copia del proyecto en una rama diferente antes de incorporarlo al código base principal. De esta manera, si la compilación falla, sería más fácil averiguar de dónde proviene el error y tampoco afectará su código fuente principal.
“Cuanto antes detecte los defectos, más barato será repararlos”.
— David Farley, Entrega continua: Versiones de software confiables a través de la automatización de compilación, prueba e implementación
Hay varias herramientas disponibles para ayudar a crear una integración continua para su proyecto. Estos incluyen Jenkins, TravisCI, CircleCI, GitLab CI, GitHub Actions, etc. Para este tutorial, usaré GitHub Actions.
Acciones de GitHub para la integración continua
CI Actions es una característica bastante nueva en GitHub y permite la creación de flujos de trabajo que ejecutan automáticamente la compilación y las pruebas de su proyecto. Un flujo de trabajo contiene uno o más trabajos que se pueden activar cuando ocurre un evento. Este evento podría ser un envío a cualquiera de las sucursales en el repositorio o la creación de una solicitud de extracción. Explicaré estos términos en detalle a medida que avancemos.
¡Empecemos!
requisitos previos
Este es un tutorial para principiantes, por lo que hablaré principalmente sobre GitHub Actions CI en un nivel superficial. Los lectores ya deberían estar familiarizados con la creación de una API REST de Node JS utilizando la base de datos PostgreSQL, Sequelize ORM y la escritura de pruebas con Mocha y Chai.
También debe tener lo siguiente instalado en su máquina:
- NodoJS,
- postgresql,
- MNP,
- VSCode (o cualquier editor y terminal de su elección).
Usaré una API REST que ya creé llamada countries-info-api . Es una API simple sin autorizaciones basadas en roles (como en el momento de escribir este tutorial). Esto significa que cualquiera puede agregar, eliminar y/o actualizar los detalles de un país. Cada país tendrá una identificación (UUID autogenerado), nombre, capital y población. Para lograr esto, utilicé Node js, express js framework y Postgresql para la base de datos.
Explicaré brevemente cómo configuro el servidor, la base de datos antes de comenzar a escribir las pruebas para la cobertura de la prueba y el archivo de flujo de trabajo para la integración continua.
Puede clonar el repositorio de countries-info-api para seguir o crear su propia API.
Tecnología utilizada : Node Js, NPM (un administrador de paquetes para Javascript), base de datos Postgresql, Sequelize ORM, Babel.
Configuración del servidor
Antes de configurar el servidor, instalé algunas dependencias de npm.
npm install express dotenv cors npm install --save-dev @babel/core @babel/cli @babel/preset-env nodemonEstoy usando Express Framework y escribiendo en formato ES6, por lo que necesitaré Babeljs para compilar mi código. Puedes leer la documentación oficial para saber más sobre cómo funciona y cómo configurarlo para tu proyecto. Nodemon detectará cualquier cambio realizado en el código y reiniciará automáticamente el servidor.
Nota : los paquetes Npm instalados con el --save-dev solo son necesarios durante las etapas de desarrollo y se ven en devDependencies en el archivo package.json .
Agregué lo siguiente a mi archivo index.js :
import express from "express"; import bodyParser from "body-parser"; import cors from "cors"; import "dotenv/config"; const app = express(); const port = process.env.PORT; app.use(bodyParser.json()); app.use(bodyParser.urlencoded({ extended: true })); app.use(cors()); app.get("/", (req, res) => { res.send({message: "Welcome to the homepage!"}) }) app.listen(port, () => { console.log(`Server is running on ${port}...`) }) Esto configura nuestra API para que se ejecute en lo que esté asignado a la variable PORT en el archivo .env . Aquí también es donde declararemos variables a las que no queremos que otros tengan acceso fácilmente. El paquete dotenv npm carga nuestras variables de entorno desde .env .
Ahora, cuando ejecuto npm run start en mi terminal, obtengo esto:
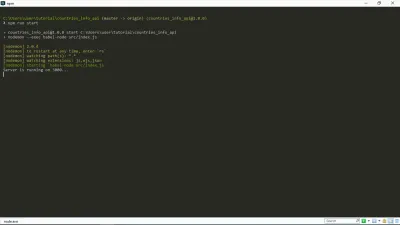
Como puede ver, nuestro servidor está en funcionamiento. ¡Hurra!
Este enlace https://127.0.0.1:your_port_number/ en su navegador web debería devolver el mensaje de bienvenida. Es decir, mientras el servidor esté funcionando.
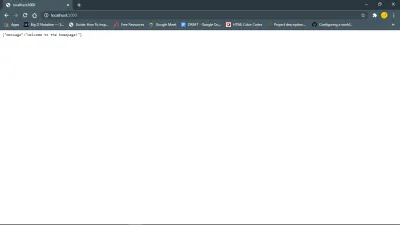
A continuación, Base de datos y modelos.
Creé el modelo de país usando Sequelize y me conecté a mi base de datos de Postgres. Sequelize es un ORM para Nodejs. Una gran ventaja es que nos ahorra el tiempo de escribir consultas SQL sin formato.
Dado que estamos usando Postgresql, la base de datos se puede crear a través de la línea de comando psql usando el comando CREATE DATABASE database_name nombre_base_de_datos. Esto también se puede hacer en su terminal, pero prefiero PSQL Shell.
En el archivo env, configuraremos la cadena de conexión de nuestra base de datos, siguiendo este formato a continuación.
TEST_DATABASE_URL = postgres://<db_username>:<db_password>@127.0.0.1:5432/<database_name>Para mi modelo, seguí este tutorial de secuela. Es fácil de seguir y explica todo sobre la configuración de Sequelize.
A continuación, escribiré pruebas para el modelo que acabo de crear y configuraré la cobertura en Coverall.
Redacción de exámenes y cobertura de informes
¿Por qué escribir pruebas? Personalmente, creo que escribir pruebas lo ayuda como desarrollador a comprender mejor cómo se espera que su software funcione en manos de su usuario porque es un proceso de intercambio de ideas. También te ayuda a descubrir errores a tiempo.
Pruebas:
Existen diferentes métodos de prueba de software, sin embargo, para este tutorial, utilicé pruebas unitarias y de extremo a extremo.
Escribí mis pruebas utilizando el marco de pruebas de Mocha y la biblioteca de aserciones de Chai. También instalé sequelize-test-helpers para ayudar a probar el modelo que creé usando sequelize.define .
Cobertura de prueba:
Es recomendable verificar la cobertura de su prueba porque el resultado muestra si nuestros casos de prueba realmente cubren el código y también cuánto código se usa cuando ejecutamos nuestros casos de prueba.

Usé Istanbul (una herramienta de cobertura de prueba), nyc (cliente CLI de Instabul) y Coveralls.
De acuerdo con los documentos, Istanbul instrumenta su código JavaScript ES5 y ES2015+ con contadores de línea, para que pueda rastrear qué tan bien sus pruebas unitarias ejercitan su base de código.
En mi archivo package.json , el script de prueba ejecuta las pruebas y genera un informe.
{ "scripts": { "test": "nyc --reporter=lcov --reporter=text mocha -r @babel/register ./src/test/index.js" } } En el proceso, creará una carpeta .nyc_output que contiene la información de cobertura sin procesar y una carpeta de coverage que contiene los archivos del informe de cobertura. Ambos archivos no son necesarios en mi repositorio, así que los coloqué en el archivo .gitignore .
Ahora que hemos generado un informe, tenemos que enviarlo a Coveralls. Una cosa interesante sobre Overoles (y otras herramientas de cobertura, supongo) es cómo informa la cobertura de su prueba. La cobertura se desglosa archivo por archivo y puede ver la cobertura relevante, las líneas cubiertas y perdidas, y qué cambió en la cobertura construida.
Para comenzar, instale el paquete overol npm. También debe iniciar sesión en overoles y agregarle el repositorio.
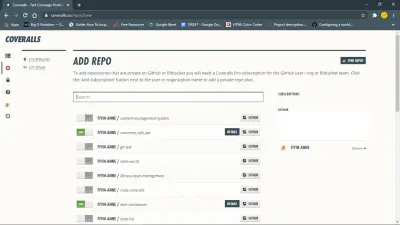
Luego configure overoles para su proyecto javascript creando un archivo coveralls.yml en su directorio raíz. Este archivo contendrá su repo-token obtenido de la sección de configuración para su repositorio en overoles.
Otro script necesario en el archivo package.json son los scripts de cobertura. Este script será útil cuando estemos creando una compilación a través de Acciones.
{ "scripts": { "coverage": "nyc npm run test && nyc report --reporter=text-lcov --reporter=lcov | node ./node_modules/coveralls/bin/coveralls.js --verbose" } }Básicamente, ejecutará las pruebas, obtendrá el informe y lo enviará a overoles para su análisis.
Ahora al punto principal de este tutorial.
Crear archivo de flujo de trabajo de Node JS
En este punto, hemos configurado los trabajos necesarios que ejecutaremos en nuestra acción de GitHub. (¿Se pregunta qué significan los "trabajos"? Siga leyendo).
GitHub ha facilitado la creación del archivo de flujo de trabajo al proporcionar una plantilla de inicio. Como se ve en la página Acciones, hay varias plantillas de flujo de trabajo que sirven para diferentes propósitos. Para este tutorial, usaremos el flujo de trabajo de Node.js (que GitHub ya sugirió amablemente).
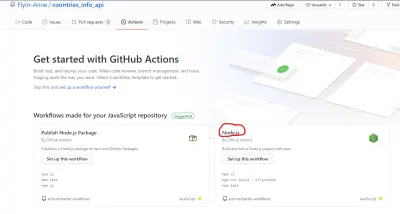
Puede editar el archivo directamente en GitHub, pero yo crearé manualmente el archivo en mi repositorio local. La carpeta .github/workflows que contiene el archivo node.js.yml estará en el directorio raíz.
Este archivo ya contiene algunos comandos básicos y el primer comentario explica lo que hacen.
# This workflow will do a clean install of node dependencies, build the source code and run tests across different versions of nodeLe haré algunos cambios para que, además del comentario anterior, también tenga cobertura.
Mi archivo .node.js.yml :
name: NodeJS CI on: ["push"] jobs: build: name: Build runs-on: windows-latest strategy: matrix: node-version: [12.x, 14.x] steps: - uses: actions/checkout@v2 - name: Use Node.js ${{ matrix.node-version }} uses: actions/setup-node@v1 with: node-version: ${{ matrix.node-version }} - run: npm install - run: npm run build --if-present - run: npm run coverage - name: Coveralls uses: coverallsapp/github-action@master env: COVERALLS_REPO_TOKEN: ${{ secrets.COVERALLS_REPO_TOKEN }} COVERALLS_GIT_BRANCH: ${{ github.ref }} with: github-token: ${{ secrets.GITHUB_TOKEN }}¿Qué significa esto?
Vamos a desglosarlo.
-
name
Este sería el nombre de su flujo de trabajo (NodeJS CI) o trabajo (compilación) y GitHub lo mostrará en la página de acciones de su repositorio. -
on
Este es el evento que desencadena el flujo de trabajo. Esa línea en mi archivo básicamente le dice a GitHub que active el flujo de trabajo cada vez que se realiza un envío a mi repositorio. -
jobs
Un flujo de trabajo puede contener al menos uno o más trabajos y cada trabajo se ejecuta en un entorno especificado porruns-on. En el ejemplo de archivo anterior, solo hay un trabajo que ejecuta la compilación y también ejecuta la cobertura, y se ejecuta en un entorno de Windows. También puedo separarlo en dos trabajos diferentes como este:
Archivo Node.yml actualizado
name: NodeJS CI on: [push] jobs: build: name: Build runs-on: windows-latest strategy: matrix: node-version: [12.x, 14.x] steps: - uses: actions/checkout@v2 - name: Use Node.js ${{ matrix.node-version }} uses: actions/setup-node@v1 with: node-version: ${{ matrix.node-version }} - run: npm install - run: npm run build --if-present - run: npm run test coverage: name: Coveralls runs-on: windows-latest strategy: matrix: node-version: [12.x, 14.x] steps: - uses: coverallsapp/github-action@master env: COVERALLS_REPO_TOKEN: ${{ secrets.COVERALLS_REPO_TOKEN }} with: github-token: ${{ secrets.GITHUB_TOKEN }}-
env
Contiene las variables de entorno que están disponibles para todos o trabajos y pasos específicos en el flujo de trabajo. En el trabajo de cobertura, puede ver que las variables de entorno se han "ocultado". Se pueden encontrar en la página de secretos de su repositorio en la configuración. -
steps
Esto básicamente es una lista de los pasos a seguir cuando se ejecuta ese trabajo. - El trabajo de
buildhace varias cosas:- Utiliza una acción de pago (v2 significa la versión) que literalmente verifica su repositorio para que su flujo de trabajo pueda acceder a él;
- Utiliza una acción de configuración de nodo que configura el entorno de nodo que se utilizará;
- Ejecuta scripts de instalación, compilación y prueba que se encuentran en nuestro archivo package.json.
-
coverage
Esto utiliza una acción de coverallsapp que publica los datos de cobertura LCOV de su conjunto de pruebas en coveralls.io para su análisis.
Inicialmente presioné mi rama feat-add-controllers-and-route y olvidé agregar el repo_token de Coveralls a mi archivo .coveralls.yml , así que recibí el error que puede ver en la línea 132.
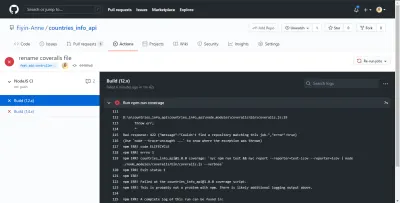
Bad response: 422 {"message":"Couldn't find a repository matching this job.","error":true} Una vez que agregué repo_token , mi compilación pudo ejecutarse correctamente. Sin este token, los overoles no podrían informar correctamente mi análisis de cobertura de prueba. Menos mal que nuestro GitHub Actions CI señaló el error antes de que se enviara a la rama principal.
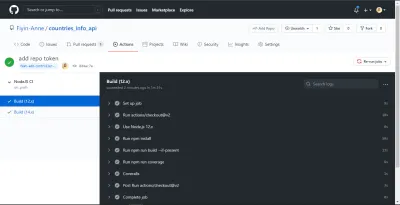
NB: Estos fueron tomados antes de separar el trabajo en dos trabajos. Además, pude ver el resumen de cobertura y el mensaje de error en mi terminal porque agregué el indicador --verbose al final de mi script de cobertura.
Conclusión
Podemos ver cómo configurar la integración continua para nuestros proyectos y también integrar la cobertura de prueba utilizando las Acciones disponibles por GitHub. Hay muchas otras formas en que esto se puede ajustar para adaptarse a las necesidades de su proyecto. Aunque el repositorio de muestra utilizado en este tutorial es un proyecto realmente menor, puede ver cuán esencial es la integración continua incluso en un proyecto más grande. Ahora que mis trabajos se ejecutaron correctamente, confío en fusionar la rama con mi rama principal. Aún así, le recomendaría que también lea los resultados de los pasos después de cada ejecución para ver que es completamente exitoso.