
Agregar capacidades de división de código a un sitio web de WordPress a través de PoP
Publicado: 2022-03-10La velocidad es una de las principales prioridades para cualquier sitio web hoy en día. Una forma de hacer que un sitio web se cargue más rápido es dividir el código: dividir una aplicación en fragmentos que se pueden cargar a pedido, cargando solo el JavaScript requerido que se necesita y nada más. Los sitios web basados en marcos de JavaScript pueden implementar inmediatamente la división de código a través de Webpack, el popular paquete de JavaScript. Sin embargo, para los sitios web de WordPress, no es tan fácil. Primero, Webpack no se creó intencionalmente para funcionar con WordPress, por lo que configurarlo requerirá algunas soluciones; en segundo lugar, no parece haber herramientas disponibles que proporcionen capacidades nativas de carga de activos bajo demanda para WordPress.
Dada la falta de una solución adecuada para WordPress, decidí implementar mi propia versión de división de código para PoP, un marco de código abierto para crear sitios web de WordPress que creé. Un sitio web de WordPress con PoP instalado tendrá capacidades de división de código de forma nativa, por lo que no necesitará depender de Webpack ni de ningún otro paquete. En este artículo, le mostraré cómo se hace, explicando qué decisiones se tomaron en función de los aspectos de la arquitectura del marco. Al final, analizaré el rendimiento de un sitio web con y sin división de código, y las ventajas y desventajas de usar una implementación personalizada en lugar de un paquete externo. ¡Espero que disfrutes el viaje!
Definición de la estrategia
La división de código se puede dividir en términos generales en estos dos pasos:
- Calcular qué activos deben cargarse para cada ruta,
- Cargando dinámicamente esos activos bajo demanda.
Para abordar el primer paso, necesitaremos producir un mapa de dependencia de activos, que incluya todos los activos en nuestra aplicación. Los activos se deben agregar recursivamente a este mapa; también se deben agregar dependencias de dependencias, hasta que no se necesiten más activos. Luego podemos calcular todas las dependencias requeridas para una ruta específica atravesando el mapa de dependencia de activos, comenzando desde el punto de entrada de la ruta (es decir, el archivo o fragmento de código desde el que comienza la ejecución) hasta el último nivel.
Para abordar el segundo paso, podríamos calcular qué activos se necesitan para la URL solicitada en el lado del servidor y luego enviar la lista de activos necesarios en la respuesta, en la que la aplicación debería cargarlos, o directamente HTTP/ 2 empujar los recursos junto con la respuesta.
Estas soluciones, sin embargo, no son óptimas. En el primer caso, la aplicación debe solicitar todos los activos después de que se devuelva la respuesta, por lo que habría una serie adicional de solicitudes de ida y vuelta para obtener los activos, y la vista no podría generarse antes de que se hayan cargado todos, lo que daría como resultado el usuario tiene que esperar (este problema se alivia al tener todos los activos precaché a través de los trabajadores del servicio, por lo que se reduce el tiempo de espera, pero no podemos evitar el análisis de los activos que ocurre solo después de que se recibe la respuesta). En el segundo caso, podríamos empujar los mismos activos repetidamente (a menos que agreguemos alguna lógica adicional, como para indicar qué recursos ya hemos cargado a través de cookies, pero esto de hecho agrega una complejidad no deseada y bloquea la respuesta para que no se almacene en caché), y nosotros no puede servir los activos desde un CDN.
Debido a esto, decidí manejar esta lógica en el lado del cliente. Se pone a disposición de la aplicación en el cliente una lista de los activos que se necesitan para cada ruta, de modo que ya sabe qué activos se necesitan para la URL solicitada. Esto resuelve los problemas mencionados anteriormente:
- Los activos se pueden cargar de inmediato, sin tener que esperar la respuesta del servidor. (Cuando combinamos eso con los trabajadores del servicio, podemos estar bastante seguros de que, cuando la respuesta regrese, todos los recursos se habrán cargado y analizado, por lo que no hay tiempo de espera adicional).
- La aplicación sabe qué activos ya se han cargado; por lo tanto, no solicitará todos los activos necesarios para esa ruta, sino solo aquellos activos que aún no se han cargado.
El aspecto negativo de entregar esta lista al front-end es que puede volverse pesada, según el tamaño del sitio web (como la cantidad de rutas disponibles). Necesitamos encontrar una manera de cargarlo sin aumentar el tiempo de carga percibido de la aplicación. Más sobre esto más adelante.
Habiendo tomado estas decisiones, podemos proceder a diseñar y luego implementar la división de código en la aplicación. Para facilitar la comprensión, el proceso se ha dividido en los siguientes pasos:
- Entender la arquitectura de la aplicación,
- Mapeo de dependencias de activos,
- Listado de todas las rutas de aplicación,
- Generar una lista que defina qué activos se requieren para cada ruta,
- Cargando activos dinámicamente,
- Aplicando optimizaciones.
¡Vamos a hacerlo!
0. Comprender la arquitectura de la aplicación
Tendremos que mapear la relación de todos los activos entre sí. Repasemos las particularidades de la arquitectura de PoP para diseñar la solución más adecuada para lograr este objetivo.
PoP es una capa que envuelve a WordPress, lo que nos permite usar WordPress como el CMS que impulsa la aplicación, y al mismo tiempo proporciona un marco JavaScript personalizado para representar contenido en el lado del cliente para crear sitios web dinámicos. Redefine los componentes de construcción de la página web: mientras que WordPress se basa actualmente en el concepto de plantillas jerárquicas que producen HTML (como single.php , home.php y archive.php ), PoP se basa en el concepto de “módulos, ” que son una funcionalidad atómica o una composición de otros módulos. Construir una aplicación PoP es similar a jugar con LEGO : apilar módulos uno encima del otro o envolverse entre sí, creando finalmente una estructura más compleja. También podría considerarse como una implementación del diseño atómico de Brad Frost, y se ve así:
Los módulos se pueden agrupar en entidades de orden superior, a saber: bloques, grupos de bloques, secciones de página y niveles superiores. Estas entidades también son módulos, solo que con propiedades y responsabilidades adicionales, y se contienen entre sí siguiendo una arquitectura estrictamente descendente en la que cada módulo puede ver y cambiar las propiedades de todos sus módulos internos. La relación entre módulos es así:
- 1 topLevel contiene N secciones de página,
- 1 sección de página contiene N bloques o grupos de bloques,
- 1 blockGroup contiene N bloques o grupos de bloques,
- 1 bloque contiene N módulos,
- 1 módulo contiene N módulos, ad infinitum.
Ejecutar código JavaScript en PoP
PoP crea HTML dinámicamente, comenzando en el nivel de sección de página, iterando a través de todos los módulos en la línea, renderizando cada uno de ellos a través de la plantilla de manubrios predefinida del módulo y, finalmente, agregando los elementos correspondientes recién creados del módulo en el DOM. Una vez hecho esto, ejecuta funciones de JavaScript sobre ellos, que están predefinidas módulo por módulo.
PoP se diferencia de los marcos de JavaScript (como React y AngularJS) en que el flujo de la aplicación no se origina en el cliente, pero todavía está configurado en el back-end, dentro de la configuración del módulo (que está codificado en un objeto PHP). Influenciado por los ganchos de acción de WordPress, PoP implementa un patrón de publicación-suscripción:
- Cada módulo define qué funciones de JavaScript deben ejecutarse en sus correspondientes elementos DOM recién creados, sin saber necesariamente de antemano qué ejecutará este código o de dónde provendrá.
- Los objetos de JavaScript deben registrar qué funciones de JavaScript implementan.
- Finalmente, en tiempo de ejecución, PoP calcula qué objetos de JavaScript deben ejecutar qué funciones de JavaScript y los invoca de manera apropiada.
Por ejemplo, a través de su objeto PHP correspondiente, un módulo de calendario indica que necesita que la función de calendar se ejecute en sus elementos DOM de esta manera:
class CalendarModule { function get_jsmethods() { $methods = parent::get_jsmethods(); $this->add_jsmethod($methods, 'calendar'); return $methods; } ... } Luego, un objeto de JavaScript, en este caso, popFullCalendar , anuncia que implementó la función de calendar . Esto se hace llamando a popJSLibraryManager.register :
window.popFullCalendar = { calendar : function(elements) { ... } }; popJSLibraryManager.register(popFullCalendar, ['calendar', ...]); Finalmente, popJSLibraryManager hace coincidir qué ejecuta qué código. Permite que los objetos de JavaScript registren qué funciones implementan y proporciona un método para ejecutar una función particular de todos los objetos de JavaScript suscritos:
window.popJSLibraryManager = { libraries: [], methods: {}, register : function(library, methods) { this.libraries.push(library); for (var i = 0; i < methods.length; i++) { var method = methods[i]; this.methods[method] = this.methods[method] || []; this.methods[method].push(library); } }, execute : function(method, elements) { var libraries = this.methods[method] || []; for (var i = 0; i < libraries.length; i++) { var library = libraries[i]; library[method](elements); } } } Después de agregar un nuevo elemento de calendario al DOM, que tiene una ID de calendar-293 , PoP simplemente ejecutará la siguiente función:
popJSLibraryManager.execute("calendar", document.getElementById("calendar-293"));Punto de entrada
Para PoP, el punto de entrada para ejecutar código JavaScript es esta línea al final de la salida HTML:
<script type="text/javascript">popManager.init();</script> popManager.init() primero inicializa el marco frontal y luego ejecuta las funciones de JavaScript definidas por todos los módulos representados, como se explicó anteriormente. A continuación se muestra una forma muy simplificada de esta función (el código original está en GitHub). Al invocar popJSLibraryManager.execute('pageSectionInitialized', pageSection) y popJSLibraryManager.execute('documentInitialized') , todos los objetos de JavaScript que implementan esas funciones ( pageSectionInitialized y documentInitialized ) las ejecutarán.
(function($){ window.popManager = { // The configuration for all the modules (including pageSections and blocks) in the application configuration : {...}, init : function() { var that = this; $.each(this.configuration, function(pageSectionId, configuration) { // Obtain the pageSection element in the DOM from the ID var pageSection = $('#'+pageSectionId); // Run all required JavaScript methods on it this.runJSMethods(pageSection, configuration); // Trigger an event marking the block as initialized popJSLibraryManager.execute('pageSectionInitialized', pageSection); }); // Trigger an event marking the document as initialized popJSLibraryManager.execute('documentInitialized'); }, ... }; })(jQuery); La función runJSMethods ejecuta los métodos de JavaScript definidos para todos y cada uno de los módulos, comenzando desde pageSection, que es el módulo más alto, y luego hacia abajo para todos sus bloques internos y sus módulos internos:
(function($){ window.popManager = { ... runJSMethods : function(pageSection, configuration) { // Initialize the heap with "modules", starting from the top one, and recursively iterate over its inner modules var heap = [pageSection.data('module')], i; while (heap.length > 0) { // Get the first element of the heap var module = heap.pop(); // The configuration for that module contains which JavaScript methods to execute, and which are the module's inner modules var moduleConfiguration = configuration[module]; // The list of all JavaScript functions that must be executed on the module's newly created DOM elements var jsMethods = moduleConfiguration['js-methods']; // Get all of the elements added to the DOM for that module, which have been stored in JavaScript object `popJSRuntimeManager` upon creation var elements = popJSRuntimeManager.getDOMElements(module); // Iterate through all of the JavaScript methods and execute them, passing the elements as argument for (i = 0; i < jsMethods.length; i++) { popJSLibraryManager.execute(jsMethods[i], elements); } // Finally, add the inner-modules to the heap heap = heap.concat(moduleConfiguration['inner-modules']); } }, }; })(jQuery);En resumen, la ejecución de JavaScript en PoP está débilmente acoplada: en lugar de tener dependencias fijas, ejecutamos funciones de JavaScript a través de ganchos a los que cualquier objeto de JavaScript puede suscribirse.
Páginas web y API
Un sitio web PoP es una API autoconsumida. En PoP, no hay distinción entre una página web y una API: cada URL devuelve la página web de forma predeterminada y, con solo agregar el parámetro output=json , devuelve su API en su lugar (por ejemplo, getpop.org/en/ es una página web, y getpop.org/en/?output=json es su API). La API se usa para renderizar dinámicamente contenido en PoP; por lo tanto, al hacer clic en un enlace a otra página, lo que se solicita es la API, porque para entonces el marco del sitio web se habrá cargado (como la navegación superior y lateral), entonces el conjunto de recursos necesarios para el modo API ser un subconjunto de eso de la página web. Tendremos que tener esto en cuenta al calcular las dependencias de una ruta: cargar la ruta cuando se carga el sitio web por primera vez o cargarla dinámicamente al hacer clic en algún enlace producirá diferentes conjuntos de activos necesarios.
Estos son los aspectos más importantes de PoP que definirán el diseño y la implementación de la división de código. Sigamos con el siguiente paso.
1. Mapeo de dependencias de activos
Podríamos agregar un archivo de configuración para cada archivo JavaScript, detallando sus dependencias explícitas. Sin embargo, esto duplicaría el código y sería difícil mantener la coherencia. Una solución más limpia sería mantener los archivos JavaScript como la única fuente de verdad, extrayendo el código de ellos y luego analizándolo para recrear las dependencias.
Los metadatos que buscamos en los archivos fuente de JavaScript, para poder recrear el mapeo, son los siguientes:
- llamadas a métodos internos, como
this.runJSMethods(...); - llamadas a métodos externos, como
popJSRuntimeManager.getDOMElements(...); - todas las apariciones de
popJSLibraryManager.execute(...), que ejecuta una función de JavaScript en todos los objetos que la implementan; - todas las apariciones de
popJSLibraryManager.register(...), para obtener qué objetos de JavaScript implementan qué métodos de JavaScript.
Usaremos jParser y jTokenizer para tokenizar nuestros archivos fuente de JavaScript en PHP y extraer los metadatos, de la siguiente manera:
- Las llamadas a métodos internos (como
this.runJSMethods) se deducen al encontrar la siguiente secuencia: tokenthisorthat+.+ algún otro token, que es el nombre del método interno (runJSMethods). - Las llamadas a métodos externos (como
popJSRuntimeManager.getDOMElements) se deducen al encontrar la siguiente secuencia: un token incluido en la lista de todos los objetos de JavaScript en nuestra aplicación (necesitaremos esta lista de antemano; en este caso, contendrá el objetopopJSRuntimeManager) +.+ algún otro token, que es el nombre del método externo (getDOMElements). - Cada vez que encontramos
popJSLibraryManager.execute("someFunctionName"), deducimos que el método Javascript essomeFunctionName. - Cada vez que encontramos
popJSLibraryManager.register(someJSObject, ["someFunctionName1", "someFunctionName2"])deducimos el objeto JavascriptsomeJSObjectpara implementar métodossomeFunctionName1,someFunctionName2.
He implementado el script pero no lo describiré aquí. (Es demasiado largo no agrega mucho valor, pero se puede encontrar en el repositorio de PoP). El script, que se ejecuta al solicitar una página interna en el servidor de desarrollo del sitio web (sobre cuya metodología he escrito en un artículo anterior sobre los trabajadores del servicio), generará el archivo de mapeo y lo almacenará en el servidor. He preparado un ejemplo del archivo de mapeo generado. Es un archivo JSON simple que contiene los siguientes atributos:
-
internalMethodCalls
Para cada objeto de JavaScript, enumere las dependencias de las funciones internas entre sí. -
externalMethodCalls
Para cada objeto de JavaScript, enumere las dependencias de funciones internas a funciones de otros objetos de JavaScript. -
publicMethods
Enumere todos los métodos registrados y, para cada método, qué objetos de JavaScript lo implementan. -
methodExecutions
Para cada objeto de JavaScript y cada función interna, enumere todos los métodos ejecutados a travéspopJSLibraryManager.execute('someMethodName').
Tenga en cuenta que el resultado aún no es un mapa de dependencia de activos, sino un mapa de dependencia de objetos de JavaScript. A partir de este mapa, podemos establecer, siempre que se ejecute una función de algún objeto, qué otros objetos también serán requeridos. Todavía necesitamos configurar qué objetos de JavaScript están contenidos en cada activo, para todos los activos (en el script jTokenizer, los objetos de JavaScript son los tokens que estamos buscando para identificar las llamadas a métodos externos, por lo que esta información es una entrada para el script y puede no se puede obtener de los propios archivos de origen). Esto se hace a través de objetos PHP ResourceLoaderProcessor , como resourceloader-processor.php.
Finalmente, al combinar el mapa y la configuración, podremos calcular todos los activos necesarios para cada ruta en la aplicación.
2. Listado de todas las rutas de aplicación
Necesitamos identificar todas las rutas disponibles en nuestra aplicación. Para un sitio web de WordPress, esta lista comenzará con la URL de cada una de las jerarquías de plantillas. Los implementados para PoP son estos:
- página de inicio: https://getpop.org/en/
- autor: https://getpop.org/en/u/leo/
- sencillo: https://getpop.org/en/blog/new-feature-code-splitting/
- etiqueta: https://getpop.org/en/tags/internet/
- página: https://getpop.org/en/philosophy/
- categoría: https://getpop.org/en/blog/ (la categoría en realidad se implementa como una página, para eliminar
category/de la ruta URL) - 404: https://getpop.org/es/esta-pagina-no-existe/
Para cada una de estas jerarquías, debemos obtener todas las rutas que producen una configuración única (es decir, que requerirán un conjunto único de activos). En el caso de PoP, tenemos lo siguiente:
- la página de inicio y el 404 son únicos.
- Las páginas de etiquetas siempre tienen la misma configuración para cualquier etiqueta. Por lo tanto, una sola URL para cualquier etiqueta será suficiente.
- La publicación individual depende de la combinación del tipo de publicación (como "evento" o "publicación") y la categoría principal de la publicación (como "blog" o "artículo"). Luego, necesitamos una URL para cada una de estas combinaciones.
- La configuración de una página de categoría depende de la categoría. Entonces, necesitaremos la URL de cada categoría de publicación.
- Una página de autor depende del rol del autor ("individuo", "organización" o "comunidad"). Entonces, necesitaremos URL para tres autores, cada uno de ellos con uno de estos roles.
- Cada página puede tener su propia configuración (“iniciar sesión”, “contáctenos”, “nuestra misión”, etc.). Por lo tanto, todas las URL de la página deben agregarse a la lista.
Como vemos, la lista ya es bastante larga. Además, nuestra aplicación puede agregar parámetros a la URL que cambien la configuración, y posiblemente también cambien los activos que se requieren. PoP, por ejemplo, ofrece agregar los siguientes parámetros de URL:
- tab (
?tab=…), para mostrar información relacionada: https://getpop.org/en/blog/new-feature-code-splitting/?tab=authors; - format (
?format=…), para cambiar la forma en que se muestran los datos: https://getpop.org/en/blog/?format=list; - target (
?target=…), para abrir la página en una sección de página diferente: https://getpop.org/en/add-post/?target=addons.
Algunas de las rutas iniciales pueden tener uno, dos o incluso tres de los parámetros anteriores, creando una amplia gama de combinaciones:
- publicación única: https://getpop.org/en/blog/new-feature-code-splitting/
- autores de publicaciones individuales: https://getpop.org/en/blog/new-feature-code-splitting/?tab=authors
- autores de publicaciones individuales como una lista: https://getpop.org/en/blog/new-feature-code-splitting/?tab=authors&format=list
- autores de publicaciones individuales como una lista en una ventana modal: https://getpop.org/en/blog/new-feature-code-splitting/?tab=authors&format=list&target=modals
En resumen, para PoP, todas las rutas posibles son una combinación de los siguientes elementos:
- todas las rutas de jerarquía de plantillas iniciales;
- todos los diferentes valores para los cuales la jerarquía producirá una configuración diferente;
- todas las pestañas posibles para cada jerarquía (diferentes jerarquías pueden tener diferentes valores de pestaña: una sola publicación puede tener las pestañas "autores" y "respuestas", mientras que un autor puede tener las pestañas "publicaciones" y "seguidores");
- todos los formatos posibles para cada pestaña (a diferentes pestañas se les pueden aplicar diferentes formatos: la pestaña "autores" puede tener el formato "mapa", pero la pestaña "respuestas" puede no tenerlo);
- todos los objetivos posibles que indican las secciones de la página donde se puede mostrar cada ruta (mientras que se puede crear una publicación en la sección principal o en una ventana flotante, la página "Compartir con tus amigos" se puede configurar para que se abra en una ventana modal).
Por lo tanto, para una aplicación un poco compleja, la producción de la lista con todas las rutas no se puede hacer manualmente. Entonces, debemos crear un script para extraer esta información de la base de datos, manipularla y, finalmente, generarla en el formato que se necesita. Este script obtendrá todas las categorías de publicaciones, a partir de las cuales podemos producir la lista de todas las diferentes URL de páginas de categoría y luego, para cada categoría, consultar la base de datos para cualquier publicación debajo de la misma, lo que producirá la URL para una sola publicar en cada categoría, y así sucesivamente. La secuencia de comandos completa está disponible, a partir de function get_resources() , que expone los ganchos que implementará cada uno de los casos de jerarquía.
3. Generación de la lista que define qué activos se requieren para cada ruta
Por ahora, tenemos el mapa de dependencia de activos y la lista de todas las rutas en la aplicación. Ahora es el momento de combinar estos dos y producir una lista que indique, para cada ruta, qué activos se requieren.
Para crear esta lista, aplicamos el siguiente procedimiento:
- Genere una lista que contenga todos los métodos de JavaScript que se ejecutarán para cada ruta:
Calcule los módulos de la ruta, luego obtenga la configuración para cada módulo, luego extraiga de la configuración qué funciones de JavaScript necesita ejecutar el módulo y agréguelas todas juntas. - A continuación, recorra el mapa de dependencia de activos para cada función de JavaScript, recopile la lista de todas sus dependencias requeridas y agréguelas todas juntas.
- Finalmente, agregue las plantillas Handlebars necesarias para representar cada módulo dentro de esa ruta.
Además, como se indicó anteriormente, cada URL tiene modos de página web y API, por lo que debemos ejecutar el procedimiento anterior dos veces, una vez para cada modo (es decir, agregar una vez el parámetro output=json a la URL, que representa la ruta para el modo API, y una vez manteniendo la URL sin cambios para el modo de página web). A continuación, produciremos dos listas, que tendrán diferentes usos:

- La lista de modos de página web se utilizará cuando se cargue inicialmente el sitio web, de modo que los scripts correspondientes para esa ruta se incluyan en la respuesta HTML inicial. Esta lista se almacenará en el servidor.
- La lista de modos API se utilizará cuando se cargue dinámicamente una página en el sitio web. Esta lista se cargará en el cliente para permitir que la aplicación calcule qué activos adicionales se deben cargar, a pedido, cuando se hace clic en un enlace.
La mayor parte de la lógica se ha implementado a partir de function add_resources_from_settingsprocessors($fetching_json, ...) , (puede encontrarla en el repositorio). El parámetro $fetching_json diferencia entre los modos de página web ( false ) y API ( true ).
Cuando se ejecuta el script para el modo de página web, generará resourceloader-bundle-mapping.json, que es un objeto JSON con las siguientes propiedades:
-
bundle-ids
Esta es una colección de hasta cuatro recursos (sus nombres han sido modificados para el entorno de producción:eq=>handlebars,er=>handlebars-helpers, etc.), agrupados bajo una ID de paquete. -
bundlegroup-ids
Esta es una colección debundle-ids. Cada bundleGroup representa un conjunto único de recursos. -
key-ids
Este es el mapeo entre rutas (representadas por su hash, que identifica el conjunto de todos los atributos que hacen que una ruta sea única) y su grupo de paquetes correspondiente.
Como se puede observar, el mapeo entre una ruta y sus recursos no es recto. En lugar de asignar key-ids a una lista de recursos, los asigna a un bundleGroup único, que es en sí mismo una lista de bundles , y solo cada paquete es una lista de resources (de hasta cuatro elementos cada paquete). ¿Por qué se hizo así? Esto tiene dos propósitos:
- Nos permite identificar todos los recursos bajo un único bundleGroup. Por lo tanto, en lugar de incluir todos los recursos en la respuesta HTML, podemos incluir un activo de JavaScript único, que es el archivo bundleGroup correspondiente, que se agrupa dentro de todos los recursos correspondientes. Esto es útil cuando se sirven dispositivos que aún no son compatibles con HTTP/2, y también aumentará el tiempo de carga, ya que comprimir con Gzip un solo archivo incluido es más efectivo que comprimir los archivos que lo componen por sí solos y luego sumarlos. Alternativamente, también podríamos cargar una serie de paquetes en lugar de un grupo de paquetes único, que es un compromiso entre los recursos y los grupos de paquetes (la carga de paquetes es más lenta que la de los grupos de paquetes debido a Gzip, pero es más eficaz si la invalidación ocurre con frecuencia, de modo que descargaría solo el paquete actualizado y no todo el grupo de paquetes). Los scripts para agrupar todos los recursos en paquetes y grupos de paquetes se encuentran en filegenerator-bundles.php y filegenerator-bundlegroups.php.
- Dividir los conjuntos de recursos en paquetes nos permite identificar patrones comunes (por ejemplo, identificar conjuntos de cuatro recursos que se comparten entre muchas rutas), lo que permite que diferentes rutas se vinculen al mismo paquete. Como resultado, la lista generada tendrá un tamaño más pequeño. Puede que esto no sea de gran utilidad para la lista de páginas web, que vive en el servidor, pero es excelente para la lista de API, que se cargará en el cliente, como veremos más adelante.
Cuando se ejecuta el script para el modo API, generará el archivo resources.js, con las siguientes propiedades:
- los
bundlesybundle-groupspaquetes tienen el mismo propósito que el establecido para el modo de página web - Las
keystambién tienen el mismo propósito que los identificadores dekey-idspara el modo de página web. Sin embargo, en lugar de tener un hash como clave para representar la ruta, es una concatenación de todos esos atributos que hacen que una ruta sea única; en nuestro caso, formato (f), tabulación (t) y destino (r). -
sourceses el archivo de origen de cada recurso. -
typeses el CSS o JavaScript para cada recurso (aunque, en aras de la simplicidad, no hemos cubierto en este artículo que los recursos de JavaScript también pueden establecer recursos de CSS como dependencias, y los módulos pueden cargar sus propios activos de CSS, implementando la estrategia de carga progresiva de CSS ). -
resourcescaptura qué grupos de paquetes deben cargarse para cada jerarquía. -
ordered-load-resourcescontiene qué recursos se deben cargar en orden, para evitar que los scripts se carguen antes que los scripts de los que dependen (de manera predeterminada, son asíncronos).
Exploraremos cómo usar este archivo en la siguiente sección.
4. Carga dinámica de los activos
Como se indicó, la lista de API se cargará en el cliente, de modo que podamos comenzar a cargar los activos necesarios para una ruta inmediatamente después de que el usuario haga clic en un enlace.
Cargando el Script de Mapeo
El archivo JavaScript generado con la lista de recursos para todas las rutas en la aplicación no es liviano; en este caso, llegó a 85 KB (que en sí mismo está optimizado, ya que modificó los nombres de los recursos y produjo paquetes para identificar patrones comunes en todas las rutas) . El tiempo de análisis no debería ser un gran cuello de botella, porque analizar JSON es 10 veces más rápido que analizar JavaScript para obtener los mismos datos. Sin embargo, el tamaño es un problema de la transferencia de red, por lo que debemos cargar este script de una manera que no afecte el tiempo de carga percibido de la aplicación o que el usuario espere.
La solución que implementé es precachear este archivo usando trabajadores de servicio, cargarlo usando defer para que no bloquee el hilo principal mientras ejecuta los métodos críticos de JavaScript y luego mostrar un mensaje de notificación si el usuario hace clic en un enlace. antes de que se haya cargado el script: "El sitio web aún se está cargando, espere unos momentos para hacer clic en los enlaces". Esto se logra agregando un div fijo con una clase de pantalla de loadingscreen colocada encima de todo mientras se cargan los scripts, luego agregando el mensaje de notificación, con una clase de notificationmsg , dentro del div, y estas pocas líneas de CSS:
.loadingscreen > .notificationmsg { display: none; } .loadingscreen:focus > .notificationmsg, .loadingscreen:active > .notificationmsg { display: block; }Otra solución es dividir este archivo en varios y cargarlos progresivamente según sea necesario (una estrategia que ya he codificado). Además, el archivo de 85 KB incluye todas las rutas posibles en la aplicación, incluidas rutas como "los anuncios del autor, que se muestran en miniaturas, que se muestran en la ventana modal", a las que se puede acceder una vez cada luna azul, en todo caso. Las rutas a las que se accede en su mayoría son apenas unas pocas (página de inicio, única, autor, etiqueta y todas las páginas, todas ellas sin atributos adicionales), lo que debería producir un archivo mucho más pequeño, en torno a los 30 KB.
Obtención de la ruta desde la URL solicitada
Debemos poder identificar la ruta a partir de la URL solicitada. Por ejemplo:
-
https://getpop.org/en/u/leo/mapas a la ruta "autor", -
https://getpop.org/en/u/leo/?tab=followersmapea la ruta “seguidores del autor”, -
https://getpop.org/en/tags/internet/mapas a la ruta "etiqueta", -
https://getpop.org/en/tags/mapea a la ruta “page/tags/”, - y así.
Para ello, tendremos que evaluar la URL, y deducir de ella los elementos que hacen que una ruta sea única: la jerarquía y todos los atributos (formato, pestaña y destino). Identificar los atributos no es problema, porque esos son parámetros en la URL. El único desafío es inferir la jerarquía (inicio, autor, sencillo, página o etiqueta) a partir de la URL, haciendo coincidir la URL con varios patrones. Por ejemplo,
- Cualquier cosa que comience con
https://getpop.org/en/u/es un autor. - Cualquier cosa que comience con pero no sea exactamente
https://getpop.org/en/tags/es una etiqueta. Si es exactamentehttps://getpop.org/en/tags/, entonces es una página. - Y así.
La función a continuación, implementada a partir de la línea 321 de resourceloader.js, debe alimentarse con una configuración con los patrones para todas estas jerarquías. Primero verifica si no hay una subruta en la URL, en cuyo caso, es "inicio". Luego, verifica una por una para hacer coincidir las jerarquías de "autor", "etiqueta" y "único". Si no tiene éxito con ninguno de ellos, entonces es el caso predeterminado, que es "página":
window.popResourceLoader = { // The config will be populated externally, using a config.js file, generated by a script config : {}, getPath : function(url) { var parser = document.createElement('a'); parser.href = url; return parser.pathname; }, getHierarchy : function(url) { var path = this.getPath(url); if (!path) { return 'home'; } var config = this.config; if (path.startsWith(config.paths.author) && path != config.paths.author) { return 'author'; } if (path.startsWith(config.paths.tag) && path != config.paths.tag) { return 'tag'; } // We must also check that this path is, itself, not a potential page (https://getpop.org/en/posts/articles/ is "page", but https://getpop.org/en/posts/this-is-a-post/ is "single") if (config.paths.single.indexOf(path) === -1 && config.paths.single.some(function(single_path) { return path.startsWith(single_path) && path != single_path;})) { return 'single'; } return 'page'; }, ... };Debido a que todos los datos requeridos ya están en la base de datos (todas las categorías, todos los slugs de página, etc.), ejecutaremos un script para crear este archivo de configuración automáticamente en un entorno de desarrollo o ensayo. The implemented script is resourceloader-config.php, which produces config.js with the URL patterns for the hierarchies “author”, “tag” and “single”, under the key “paths”:
popResourceLoader.config = { "paths": { "author": "u/", "tag": "tags/", "single": ["posts/articles/", "posts/announcements/", ...] }, ... };Loading Resources for the Route
Once we have identified the route, we can obtain the required assets from the generated JavaScript file under the key “resources”, which looks like this:
config.resources = { "home": { "1": [1, 110, ...], "2": [2, 111, ...], ... }, "author": { "7": [6, 114, ...], "8": [7, 114, ...], ... }, "tag": { "119": [66, 127, ...], "120": [66, 127, ...], ... }, "single": { "posts/": { "7": [190, 142, ...], "3": [190, 142, ...], ... }, "events/": { "7": [213, 389, ...], "3": [213, 389, ...], ... }, ... }, "page": { "log-in/": { "3": [233, 115, ...] }, "log-out/": { "3": [234, 115, ...] }, "add-post/": { "3": [239, 398, ...] }, "posts/": { "120": [268, 127, ...], "122": [268, 127, ...], ... }, ... } };At the first level, we have the hierarchy (home, author, tag, single or page). Hierarchies are divided into two groups: those that have only one set of resources (home, author and tag), and those that have a specific subpath (page permalink for the pages, custom post type or category for the single). Finally, at the last level, for each key ID (which represents a unique combination of the possible values of “format”, “tab” and “target”, stored under “keys”), we have an array of two elements: [JS bundleGroup ID, CSS bundleGroup ID], plus additional bundleGroup IDs if executing progressive booting (JS bundleGroups to be loaded as "async" or "defer" are bundled separately; this will be explained in the optimizations section below).
Please note: For the single hierarchy, we have different configurations depending on the custom post type. This can be reflected in the subpath indicated above (for example, events and posts ) because this information is in the URL (for example, https://getpop.org/en/posts/the-winners-of-climate-change-techno-fixes/ and https://getpop.org/en/events/debate-post-fork/ ), so that, when clicking on a link, we will know the corresponding post type and can thus infer the corresponding route. However, this is not the case with the author hierarchy. As indicated earlier, an author may have three different configurations, depending on the user role ( individual , organization or community ); however, in this file, we've defined only one configuration for the author hierarchy, not three. That is because we are not able to tell from the URL what is the role of the author: user leo (under https://getpop.org/en/u/leo/ ) is an individual, whereas user pop (under https://getpop.org/en/u/pop/ ) is a community; however, their URLs have the same pattern. If we could instead have the URLs https://getpop.org/en/u/individuals/leo/ and https://getpop.org/en/u/communities/pop/ , then we could add a configuration for each user role. However, I've found no way to achieve this in WordPress. As a consequence, only for the API mode, we must merge the three routes (individuals, organizations and communities) into one, which will have all of the resources for the three cases; and clicking on the link for user leo will also load the resources for organizations and communities, even if we don't need them.
Finally, when a URL is requested, we obtain its route, from which we obtain the bundleGroup IDs (for both JavaScript and CSS assets). From each bundleGroup, we find the corresponding bundles under bundlegroups . Then, for each bundle, we obtain all resources under the key bundles . Finally, we identify which assets have not yet been loaded, and we load them by getting their source, which is stored under the key sources . The whole logic is coded starting from line 472 in resourceloader.js.
And with that, we have implemented code-splitting for our application! From now on, we can get better loading times by applying optimizations. Let's tackle that next.
5. Applying Optimizations
The objective is to load as little code as possible, as delayed as possible, and to cache as much of it as possible. Let's explore how to do this.
Splitting Up the Code Into Smaller Units
A single JavaScript asset may implement several functions (by calling popJSLibraryManager.register ), yet maybe only one of those functions is actually needed by the route. Thus, it makes sense to split up the asset into several subassets, implementing a single function on each of them, and extracting all common code from all of the functions into yet another asset, depended upon by all of them.
For instance, in the past, there was a unique file, waypoints.js , that implemented the functions waypointsFetchMore , waypointsTheater and a few more. However, in most cases, only the function waypointsFetchMore was needed, so I was loading the code for the function waypointsTheater unnecessarily. Then, I split up waypoints.js into the following assets:
- waypoints.js, with all common code and implementing no public functions;
- waypoints-fetchmore.js, which implements just the public function
waypointsFetchMore; - waypoints-theater.js, which implements just the public function
waypointsTheater.
Evaluating how to split the files is a manual job. Luckily, there is a tool that greatly eases the task: Chrome Developer Tools' “Coverage” tab, which displays in red those portions of JavaScript code that have not been invoked:
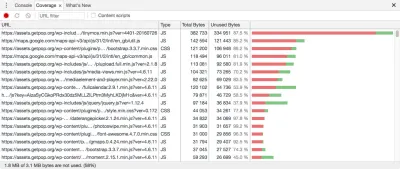
By using this tool, we can better understand how to split our JavaScript files into more granular units, thus reducing the amount of unneeded code that is loaded.
Integration With Service Workers
By precaching all of the resources using service workers, we can be pretty sure that, by the time the response is back from the server, all of the required assets will have been loaded and parsed. I wrote an article on Smashing Magazine on how to accomplish this.
Progressive Booting
PoP's architecture plays very nice with the concept of loading assets in different stages. When defining the JavaScript methods to execute on each module (by doing $this->add_jsmethod($methods, 'calendar') ), these can be set as either critical or non-critical . By default, all methods are set as non-critical, and critical methods must be explicitly defined by the developer, by adding an extra parameter: $this->add_jsmethod($methods, 'calendar', 'critical') . Then, we will be able to load scripts immediately for critical functions, and wait until the page is loaded to load non-critical functions, the JavaScript files of which are loaded using defer .
(function($){ window.popManager = { init : function() { var that = this; $.each(this.configuration, function(pageSectionId, configuration) { ... this.runJSMethods(pageSection, configuration, 'critical'); ... }); window.addEventListener('load', function() { $.each(this.configuration, function(pageSectionId, configuration) { ... this.runJSMethods(pageSection, configuration, 'non-critical'); ... }); }); ... }, ... }; })(jQuery);The gains from progressive booting are major: The JavaScript engine needs not spend time parsing non-critical JavaScript initially, when a quick response to the user is most important, and overall reduces the time to interactive.
Testing And Analizying Performance Gains
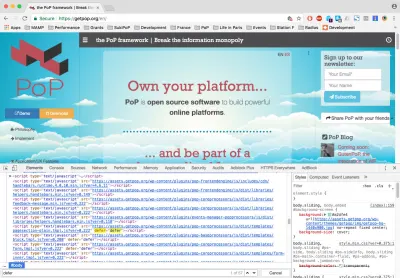
We can use https://getpop.org/en/, a PoP website, for testing purposes. When loading the home page, opening Chrome Developer Tools' “Elements” tab and searching for “defer”, it shows 4 occurrences. Thanks to progressive booting, that is 4 bundleGroup JavaScript files containing the contents of 57 Javascript files with non-critical methods that could wait until the website finished loading to be loaded:
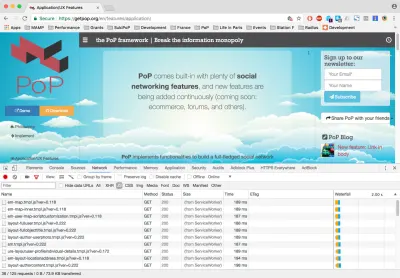
If we now switch to the “Network” tab and click on a link, we can see which assets get loaded. For instance, click on the link “Application/UX Features” on the left side. Filtering by JavaScript, we see it loaded 38 files, including JavaScript libraries and Handlebars templates. Filtering by CSS, we see it loaded 9 files. These 47 files have all been loaded on demand:
Let's check whether the loading time got boosted. We can use WebPagetest to measure the application with and without code-splitting, and calculate the difference.
- Without code-splitting: testing URL, WebPagetest results

- With code-splitting, loading resources: testing URL, WebPagetest Results

- With code-splitting, loading a bundleGroup: testing URL, WebPagetest Results

We can see that when loading the app bundle with all resources or when doing code-splitting and loading resources, there is not so much gain. However, when doing code-splitting and loading a bundleGroup, the gains are significant: 1.7 seconds in loading time, 500 milliseconds to the first meaningful paint, and 1 second to interactive.
Conclusion: Is It Worth It?
You might be thinking, Is it worth it all this trouble? Let's analyze the advantages and disadvantages of implementing our own code-splitting features.
Desventajas
- Debemos mantenerlo.
Si solo usáramos Webpack, podríamos confiar en su comunidad para mantener el software actualizado y podríamos beneficiarnos de su ecosistema de complementos. - Los scripts tardan en ejecutarse.
El sitio web de PoP Agenda Urbana tiene 304 rutas diferentes, de las cuales produce 422 conjuntos de recursos únicos. Para este sitio web, ejecutar el script que genera el mapa de dependencia de activos, usando una MacBook Pro de 2012, toma alrededor de 8 minutos, y ejecutar el script que genera las listas con todos los recursos y crea los archivos bundle y bundleGroup toma 15 minutos . ¡Es tiempo más que suficiente para ir a tomar un café! - Requiere un entorno de ensayo.
Si necesitamos esperar alrededor de 25 minutos para ejecutar los scripts, entonces no podemos ejecutarlos en producción. Necesitaríamos tener un entorno de prueba con exactamente la misma configuración que el sistema de producción. - Se agrega un código adicional al sitio web, solo para administración.
Los 85 KB de código no son funcionales por sí mismos, sino simplemente un código para administrar otro código. - Se agrega complejidad.
Esto es inevitable en cualquier caso si queremos dividir nuestros activos en unidades más pequeñas. Webpack también agregaría complejidad a la aplicación.
Ventajas
- Funciona con WordPress.
Webpack no funciona con WordPress desde el primer momento, y para que funcione necesita algunas soluciones. Esta solución funciona desde el primer momento para WordPress (siempre que PoP esté instalado). - Es escalable y extensible.
El tamaño y la complejidad de la aplicación pueden crecer sin límites, porque los archivos JavaScript se cargan a pedido. - Es compatible con Gutenberg (también conocido como WordPress del mañana).
Debido a que nos permite cargar marcos de JavaScript a pedido, admitirá los bloques de Gutenberg (llamados Gutenblocks), que se espera que estén codificados en el marco elegido por el desarrollador, con el resultado potencial de que se necesiten diferentes marcos para la misma aplicación. - Es conveniente.
La herramienta de compilación se encarga de generar los archivos de configuración. Aparte de esperar, no se necesita ningún esfuerzo adicional de nuestra parte. - Facilita la optimización.
Actualmente, si un complemento de WordPress quiere cargar activos de JavaScript de forma selectiva, utilizará muchos condicionales para verificar si la ID de la página es la correcta. Con esta herramienta, no hay necesidad de eso; el proceso es automático. - La aplicación se cargará más rápido.
Esta fue toda la razón por la que codificamos esta herramienta. - Requiere un entorno de ensayo.
Un efecto secundario positivo es una mayor confiabilidad: no ejecutaremos los scripts en producción, por lo que no romperemos nada allí; el proceso de implementación no fallará por un comportamiento inesperado; y el desarrollador se verá obligado a probar la aplicación utilizando la misma configuración que en producción. - Está personalizado para nuestra aplicación.
No hay gastos generales ni soluciones alternativas. Lo que obtenemos es exactamente lo que necesitamos, según la arquitectura con la que estamos trabajando.
En conclusión: sí, vale la pena, porque ahora podemos aplicar activos de carga bajo demanda en nuestro sitio web de WordPress y hacer que se cargue más rápido.
Más recursos
- Webpack, incluida la guía "División de código"
- "Mejores compilaciones de paquetes web" (video), K. Adam White
Integración de Webpack con WordPress - “Gutenberg y el WordPress del mañana”, Morten Rand-Hendriksen, WP Tavern
- “WordPress explora un enfoque agnóstico del marco de JavaScript para crear bloques de Gutenberg”, Sarah Gooding, WP Tavern