
CNN vs RNN: diferencia entre CNN y RNN
Publicado: 2021-02-25Tabla de contenido
Introducción
En el campo de la inteligencia artificial, las redes neuronales inspiradas en el cerebro humano se utilizan ampliamente para extraer y procesar información compleja de varios datos y el uso de redes neuronales convolucionales (CNN) y redes neuronales recurrentes (RNN) en tales aplicaciones. están demostrando ser útiles.
En este artículo, comprenderemos los conceptos detrás de las redes neuronales convolucionales y las redes neuronales recurrentes, veremos sus aplicaciones y distinguiremos las diferencias entre los dos tipos populares de redes neuronales.
Obtenga capacitación en aprendizaje automático de las mejores universidades del mundo. Obtenga programas de maestría, PGP ejecutivo o certificado avanzado para acelerar su carrera.
Redes Neuronales y Aprendizaje Profundo
Antes de entrar en los conceptos de redes neuronales convolucionales y redes neuronales recurrentes, comprendamos los conceptos detrás de las redes neuronales y cómo se vinculan con el aprendizaje profundo.
En los últimos tiempos, Deep Learning es un concepto que se usa ampliamente en muchos campos y, por lo tanto, es un tema candente en estos días. Pero, ¿cuál es la razón por la que se habla tanto de él? Para responder a esta pregunta, aprenderemos sobre el concepto de Redes Neuronales.
En definitiva, las Redes Neuronales son la columna vertebral del Deep Learning. Son un número determinado de capas que consisten en elementos altamente interconectados conocidos como neuronas que realizan una serie de transformaciones en los datos que generan su propia comprensión de esos datos a los que nos referimos con el término características.

¿Qué son las Redes Neuronales?
El primer concepto que tenemos que abordar es el de Redes Neuronales. Sabemos que el cerebro humano es una de las estructuras complejas que se han estudiado. Debido a su complejidad, ha habido una gran dificultad para desentrañar su funcionamiento interno, pero en la actualidad, se están realizando varios tipos de investigación para revelar sus secretos. Este cerebro humano sirve como inspiración detrás de los modelos de redes neuronales.
Por definición, las redes neuronales son las unidades funcionales de Deep Learning que utilizan estas redes neuronales para imitar la actividad cerebral y resolver problemas complejos. Cuando los datos de entrada se alimentan a la red neuronal, se procesan a través de las capas de perceptrón y finalmente dan la salida.
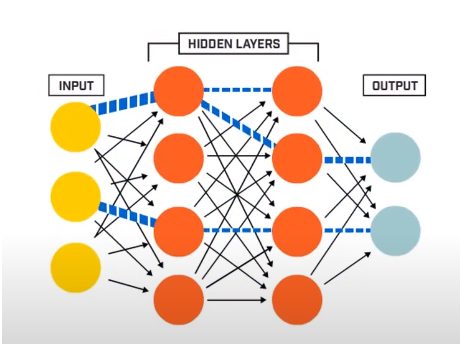
Una red neuronal consta básicamente de 3 capas:
- Capa de entrada
- Capas ocultas
- Capa de salida
La capa de entrada lee los datos de entrada que se introducen en el sistema de red neuronal para su posterior preprocesamiento por parte de las capas posteriores de neuronas artificiales. Todas las capas que existen entre la capa de entrada y la capa de salida se denominan capas ocultas.
Es en estas Capas Ocultas donde las neuronas presentes en ellas hacen uso de entradas y sesgos ponderados y producen una salida utilizando las funciones de activación. La capa de salida es la última capa de neuronas que nos da la salida para el programa dado.
Fuente
¿Cómo funcionan las redes neuronales?
Ahora que tenemos una idea de la estructura básica de las redes neuronales, avanzaremos y comprenderemos cómo funcionan. Para comprender su funcionamiento, primero debemos aprender sobre una de las estructuras básicas de las redes neuronales, conocida como Perceptron.
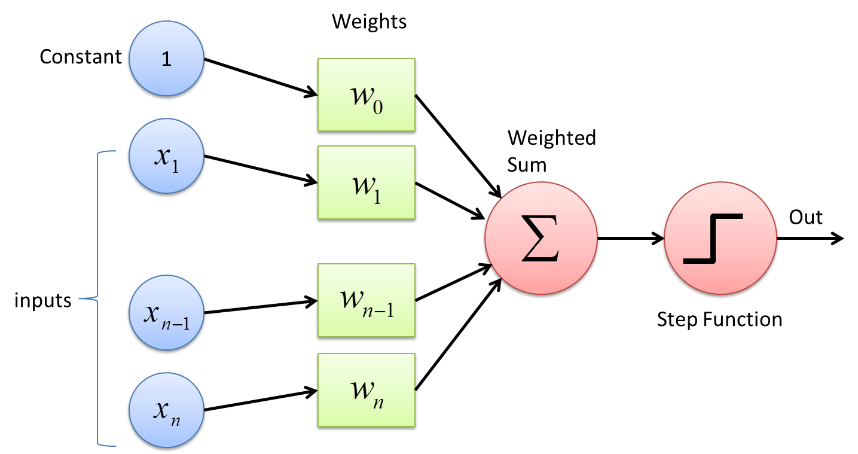
Perceptron es un tipo de red neuronal que tiene la forma más básica. Es una simple red neuronal artificial de alimentación hacia adelante con una sola capa oculta. En la red Perceptron, cada neurona está conectada con todas las demás neuronas en la dirección de avance.
Las conexiones entre estas neuronas se ponderan por lo que la información que se transfiere entre las dos neuronas se fortalece o atenúa mediante estos pesos. En el proceso de entrenamiento de las Redes Neuronales, son estos pesos los que se ajustan para obtener el valor correcto.
El Perceptron utiliza una función clasificadora binaria en la que asigna un vector de variables que son de naturaleza binaria a una única salida binaria. Esto también se puede utilizar en el aprendizaje supervisado. Los pasos en el algoritmo de aprendizaje de Perceptron son:
- Multiplique todas las entradas con sus pesos w, donde w son números reales que pueden ser inicialmente fijos o aleatorios.
- Sume el producto para obtener la suma ponderada, ∑ wj xj
- Una vez que se obtiene la suma ponderada de entradas, se aplica la función de activación para determinar si la suma ponderada es mayor que un valor de umbral particular o no, dependiendo de la función de activación aplicada. La salida se asigna como 1 o 0 dependiendo de la condición de umbral. Aquí el valor “-umbral” también se refiere al término sesgo, b.
De esta forma, el algoritmo Perceptron Learning se puede utilizar para encender (valor = 1) las neuronas presentes en las Redes Neuronales que se diseñan y desarrollan en la actualidad. Otra representación del algoritmo de aprendizaje de perceptrón es:
f(x) = 1, si ∑ wj xj + b ≥ 0
0, si ∑ wj xj + b < 0
Aunque los perceptrones no se usan mucho en la actualidad, siguen siendo uno de los conceptos centrales de las redes neuronales. En investigaciones posteriores, se entendió que pequeños cambios en los pesos o el sesgo en incluso un perceptrón podrían cambiar enormemente la salida de 1 a 0 o viceversa. Esta fue una de las principales desventajas del Perceptron. Por lo tanto, se desarrollaron funciones de activación más complejas como ReLU, funciones sigmoideas que introducen solo cambios moderados en los pesos y sesgos de las neuronas artificiales.
Fuente
Redes neuronales convolucionales
Una red neuronal convolucional es un algoritmo de aprendizaje profundo que toma una imagen como entrada, asigna varios pesos y sesgos a varias partes de la imagen para que sean diferenciables entre sí. Una vez que se vuelven diferenciables, utilizando varias funciones de activación, el modelo de red neuronal convolucional puede realizar varias tareas en el dominio de procesamiento de imágenes, incluido el reconocimiento de imágenes, la clasificación de imágenes, la detección de objetos y rostros, etc.
El fundamento de un modelo de red neuronal convolucional es que recibe una imagen de entrada. La imagen de entrada puede estar etiquetada (como gato, perro, león, etc.) o no etiquetada. Dependiendo de esto, los algoritmos de aprendizaje profundo se clasifican en dos tipos, a saber, los algoritmos supervisados donde las imágenes están etiquetadas y los algoritmos no supervisados donde las imágenes no reciben ninguna etiqueta en particular.
Para la computadora, la imagen de entrada se ve como un conjunto de píxeles, más a menudo en forma de matriz. Las imágenes son en su mayoría de la forma hxwxd (Donde h = Altura, w = Ancho, d = Dimensión). Por ejemplo, una imagen de matriz de tamaño 16 x 16 x 3 denota una imagen RGB (3 representa los valores RGB). Por otro lado, una imagen de matriz de 14 x 14 x 1 representa una imagen en escala de grises.
Fuente
Capas de red neuronal convolucional
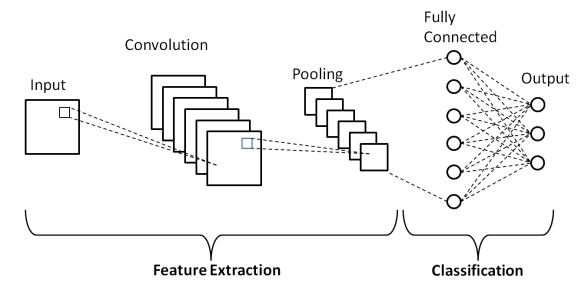
Como se muestra en la arquitectura básica anterior de una red neuronal convolucional, un modelo CNN consta de varias capas a través de las cuales las imágenes de entrada se someten a un procesamiento previo para obtener la salida. Básicamente, estas capas se diferencian en dos partes:
- Las primeras tres capas incluyen la capa de entrada, la capa de convolución y la capa de agrupación, que actúa como la herramienta de extracción de características para derivar las características de nivel base de las imágenes alimentadas en el modelo.
- La capa final totalmente conectada y la capa de salida utilizan la salida de las capas de extracción de características y predicen una clase para la imagen según las características extraídas.
La primera capa es la capa de entrada donde la imagen se introduce en el modelo de red neuronal convolucional en forma de una matriz de matriz, es decir, 32 x 32 x 3, donde 3 indica que la imagen es una imagen RGB con la misma altura y anchura. de 32 píxeles. Luego, estas imágenes de entrada pasan a través de la Capa Convolucional donde se realiza la operación matemática de Convolución.

La imagen de entrada se convoluciona con otra matriz cuadrada conocida como núcleo o filtro. Al deslizar el kernel uno por uno sobre los píxeles de la imagen de entrada, obtenemos la imagen de salida conocida como mapa de características que proporciona información sobre las características de nivel básico de la imagen, como bordes y líneas.
A la capa convolucional le sigue la capa de agrupación, cuyo objetivo es reducir el tamaño del mapa de características para reducir el costo computacional. Esto se hace mediante varios tipos de agrupación, como la agrupación máxima, la agrupación promedio y la agrupación suma.
La capa totalmente conectada (FC) es la penúltima capa del modelo de red neuronal convolucional donde las capas se aplanan y alimentan a la capa FC. Aquí, mediante el uso de funciones de activación como las funciones Sigmoid, ReLU y tanH, la predicción de la etiqueta tiene lugar y se entrega en la capa de salida final .
Donde las CNN se quedan cortas
Con tantas aplicaciones útiles de la red neuronal convolucional en datos de imágenes visuales, las CNN tienen una pequeña desventaja, ya que no funcionan bien con una secuencia de imágenes (videos) y fallan al interpretar la información temporal y los bloques de texto.
Para manejar datos temporales o secuenciales como las oraciones, necesitamos algoritmos que aprendan de los datos pasados y también de los datos futuros en la secuencia. Afortunadamente, las redes neuronales recurrentes hacen exactamente eso.
Redes neuronales recurrentes
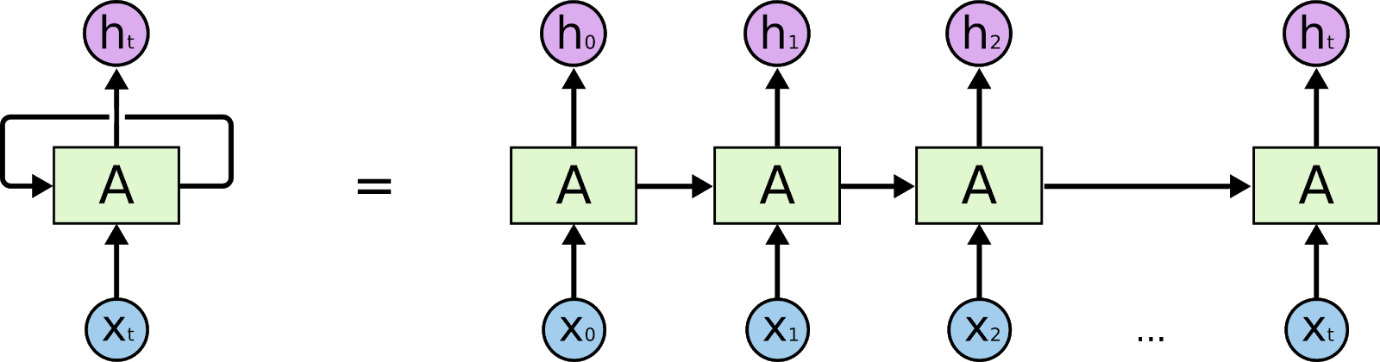
Las redes neuronales recurrentes son redes diseñadas para interpretar información temporal o secuencial. Los RNN usan otros puntos de datos en una secuencia para hacer mejores predicciones. Lo hacen tomando entradas y reutilizando las activaciones de nodos anteriores o nodos posteriores en la secuencia para influir en la salida.
Fuente
Como resultado de su memoria interna, las redes neuronales recurrentes pueden recordar detalles vitales, como la entrada que recibieron, lo que las hace ser muy precisas al predecir lo que sucederá a continuación. Por lo tanto, son el algoritmo preferido para datos secuenciales como series de tiempo, voz, texto, audio, video y muchos más. Las redes neuronales recurrentes pueden formar una comprensión mucho más profunda de una secuencia y su contexto en comparación con otros algoritmos.
¿Cómo funcionan las redes neuronales recurrentes?
La base para comprender el funcionamiento de las redes neuronales recurrentes es la misma que para las redes neuronales convolucionales, las redes neuronales simples de avance, también conocidas como perceptrones. Además, en las redes neuronales recurrentes, la salida del paso anterior se alimenta como entrada al paso actual. En la mayoría de las Redes Neuronales, la salida suele ser independiente de las entradas y viceversa, esta es la diferencia básica entre la RNN y otras Redes Neuronales.
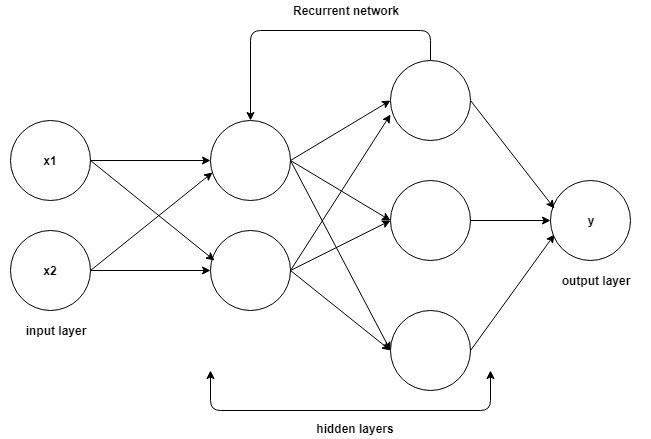
Fuente
Por tanto, una RNN tiene dos entradas: el presente y el pasado reciente. Esto es importante porque la secuencia de datos contiene información crucial sobre lo que viene a continuación, razón por la cual un RNN puede hacer cosas que otros algoritmos no pueden. La característica principal y más importante de las redes neuronales recurrentes es el estado oculto, que recuerda alguna información sobre una secuencia.
Las Redes Neuronales Recurrentes tienen una memoria que almacena toda la información sobre lo que se ha calculado. Al usar los mismos parámetros para cada entrada y realizar la misma tarea en todas las entradas o capas ocultas, se reduce la complejidad de los parámetros.
Diferencia entre CNN y RNN
| Redes neuronales convolucionales | Redes neuronales recurrentes |
| En el aprendizaje profundo, una red neuronal convolucional (CNN o ConvNet) es una clase de redes neuronales profundas, que se aplica más comúnmente al análisis de imágenes visuales. | Una red neuronal recurrente (RNN) es una clase de redes neuronales artificiales donde las conexiones entre nodos forman un gráfico dirigido a lo largo de una secuencia temporal. |
| Es adecuado para datos espaciales como imágenes. | RNN se utiliza para datos temporales, también llamados datos secuenciales. |
| CNN es un tipo de red neuronal artificial de alimentación hacia adelante con variaciones de perceptrones multicapa diseñados para usar cantidades mínimas de preprocesamiento. | RNN, a diferencia de las redes neuronales de avance, puede usar su memoria interna para procesar secuencias arbitrarias de entradas. |
| Se considera que CNN es más poderosa que RNN. | RNN incluye menos compatibilidad de funciones en comparación con CNN. |
| Esta CNN toma entradas de tamaños fijos y genera salidas de tamaño fijo. | RNN puede manejar longitudes de entrada/salida arbitrarias. |
| Las CNN son ideales para el procesamiento de imágenes y videos. | Los RNN son ideales para el análisis de texto y voz. |
| Las aplicaciones incluyen reconocimiento de imágenes, clasificación de imágenes, análisis de imágenes médicas, detección de rostros y visión artificial. | Las aplicaciones incluyen traducción de textos, procesamiento de lenguaje natural, traducción de idiomas, análisis de sentimientos y análisis de voz. |
Conclusión
Por lo tanto, en este artículo sobre las diferencias entre los dos tipos más populares de redes neuronales, las redes neuronales convolucionales y las redes neuronales recurrentes, hemos aprendido la estructura básica de una red neuronal, junto con los fundamentos de CNN y RNN y finalmente resumimos un breve comparación entre los dos con sus aplicaciones en el mundo real.
Si está interesado en obtener más información sobre el aprendizaje automático, consulte el Programa PG Ejecutivo en Aprendizaje Automático e IA de IIIT-B y upGrad, que está diseñado para profesionales que trabajan y ofrece más de 450 horas de capacitación rigurosa, más de 30 estudios de casos y asignaciones, IIIT -Estado de exalumno B, más de 5 proyectos prácticos finales prácticos y asistencia laboral con las mejores empresas.
¿Por qué la CNN es más rápida que la RNN?
Las CNN son más rápidas que las RNN porque están diseñadas para manejar imágenes, mientras que las RNN están diseñadas para manejar texto. Si bien los RNN se pueden entrenar para manejar imágenes, todavía les resulta difícil separar las características contrastantes que están más juntas. Como, por ejemplo, si tiene una imagen de una cara con ojos, nariz y boca, los RNN tienen dificultades para determinar qué función mostrar primero. Las CNN usan una cuadrícula de puntos y, mediante el uso de un algoritmo, pueden entrenarse para reconocer formas y patrones. Las CNN son mejores que las RNN para clasificar imágenes; son más rápidos que los RNN porque son fáciles de calcular y son mejores para clasificar imágenes.
¿Para qué se utiliza RNN?
Las redes neuronales recurrentes (RNN) son una clase de redes neuronales artificiales donde las conexiones entre unidades forman un ciclo dirigido. La salida de una unidad se convierte en la entrada de otra unidad y así sucesivamente, al igual que la salida de una neurona se convierte en la entrada de otra. Los RNN se han utilizado con éxito para realizar tareas complejas, como el reconocimiento de voz y la traducción automática, que son difíciles de realizar con métodos estándar.
¿Qué es RNN y en qué se diferencia de Feedforward Neural Networks?
Las redes neuronales recurrentes (RNN) son un tipo de redes neuronales que se utilizan para procesar datos secuenciales. Una red neuronal recurrente consta de una capa de entrada, una o más capas ocultas y una capa de salida. Las capas ocultas están diseñadas para aprender representaciones internas de los datos de entrada, que luego se presentan a la capa de salida como una representación externa. El RNN se entrena con la ayuda de backpropagation. Las RNN a menudo se comparan con las redes neuronales feedforward (FNN). Si bien tanto los RNN como los FNN pueden aprender representaciones internas de datos, los RNN son capaces de aprender dependencias a largo plazo, de lo que los FNN no son capaces.