
Elección de una nueva tecnología de base de datos sin servidor en una agencia (estudio de caso)
Publicado: 2022-03-10Este artículo ha sido amablemente apoyado por nuestros queridos amigos de Fauna que hacen que trabajar con datos operativos sea productivo, escalable y seguro para cada equipo de desarrollo de software. ¡Gracias!

Adoptar una nueva tecnología es una de las decisiones más difíciles para un tecnólogo en un puesto de liderazgo. Esta es a menudo un área de riesgo grande e incómoda, ya sea que esté creando software para otra organización o dentro de la suya.
Durante los últimos doce años como ingeniero de software, me encontré en la posición de tener que evaluar una nueva tecnología con una frecuencia cada vez mayor. Este puede ser el próximo marco frontend, un nuevo lenguaje o incluso arquitecturas completamente nuevas como sin servidor.
La fase de experimentación suele ser divertida y emocionante. Es donde los ingenieros de software se sienten más cómodos, abrazando la novedad y la euforia de los momentos "ajá" mientras asimilan nuevos conceptos. Como ingenieros, nos gusta pensar y jugar, pero con suficiente experiencia, todo ingeniero aprende que incluso la tecnología más increíble tiene sus defectos. Simplemente no los has encontrado todavía.
Ahora, como cofundador de una agencia creativa, mi equipo y yo estamos a menudo en una posición única para usar nuevas tecnologías. Vemos muchos proyectos greenfield, que se convierten en la oportunidad perfecta para introducir algo nuevo. Estos proyectos también ven un nivel de aislamiento técnico de la organización más grande y, a menudo, están menos agobiados por decisiones anteriores.
Dicho esto, se confía a un buen líder de agencia que se ocupe de la gran idea de otra persona y la entregue al mundo. Tenemos que tratarlo con aún más cuidado del que tendríamos con nuestros propios proyectos. Cada vez que estoy a punto de tomar la decisión final sobre una nueva tecnología, a menudo reflexiono sobre esta sabiduría del cofundador de Stack Overflow, Joel Spolski:
“Tienes que sudar y sangrar con la cosa durante un año o dos antes de que realmente sepas que es lo suficientemente bueno o te des cuenta de que no importa cuánto lo intentes, no puedes…”
Este es el miedo, este es el lugar en el que ningún líder tecnológico quiere encontrarse. Elegir una nueva tecnología para un proyecto del mundo real es bastante difícil, pero como agencia, debe tomar estas decisiones con el proyecto de otra persona, alguien el sueño de otro, el dinero de otro. En una agencia, lo último que quieres es encontrar uno de esos defectos cerca de la fecha límite de un proyecto. Los cronogramas y presupuestos ajustados hacen que sea casi imposible revertir el rumbo después de cruzar un cierto umbral, por lo que descubrir que una tecnología no puede hacer algo crítico o no es confiable demasiado tarde en un proyecto puede ser catastrófico.
A lo largo de mi carrera como ingeniero de software, he trabajado en empresas SaaS y agencias creativas. Cuando se trata de adoptar una nueva tecnología para un proyecto, estos dos entornos tienen criterios muy diferentes. Hay superposición de criterios, pero en general, el entorno de la agencia tiene que trabajar con presupuestos rígidos y limitaciones de tiempo rigurosas . Si bien queremos que los productos que construimos envejezcan bien con el tiempo, a menudo es más difícil invertir en algo menos probado o adoptar tecnología con curvas de aprendizaje más pronunciadas y bordes ásperos.
Dicho esto, las agencias también tienen algunas limitaciones únicas que una sola organización puede no tener. Tenemos que sesgar la eficiencia y la estabilidad. La hora facturable suele ser la unidad de medida final cuando se completa un proyecto. He estado en empresas de SaaS en las que pasar uno o dos días en la configuración o en una canalización de compilación no es gran cosa.
En una agencia, este tipo de costo de tiempo ejerce presión sobre las relaciones, ya que los equipos de finanzas ven márgenes de ganancia reducidos para resultados poco visibles. También tenemos que considerar el mantenimiento a largo plazo de un proyecto y, a la inversa, qué sucede si es necesario devolver un proyecto al cliente. Por lo tanto, debemos sesgar la eficiencia, la curva de aprendizaje y la estabilidad en la tecnología que elegimos.
Al evaluar una nueva pieza de tecnología, observo tres áreas generales:
- La tecnología
- La experiencia del desarrollador
- El negocio
Cada una de estas áreas tiene un conjunto de criterios que me gusta cumplir antes de comenzar a sumergirme realmente en el código y experimentar. En este artículo, analizaremos estos criterios y usaremos el ejemplo de considerar una nueva base de datos para un proyecto y revisarla a alto nivel bajo cada lente. Tomar una decisión tangible como esta ayudará a demostrar cómo podemos aplicar este marco en el mundo real.
La tecnología
Lo primero que hay que tener en cuenta al evaluar una nueva tecnología es si esa solución puede resolver los problemas que pretende resolver. Antes de sumergirse en cómo una tecnología puede ayudar a nuestro proceso y operaciones comerciales, es importante establecer primero que cumple con nuestros requisitos funcionales . Aquí también es donde me gusta echar un vistazo a las soluciones existentes que estamos usando y cómo esta nueva se compara con ellas.
Me haré preguntas como:
- ¿Resuelve como mínimo el problema que resuelve mi solución existente?
- ¿De qué manera es mejor esta solución?
- ¿De qué manera es peor?
- Para las áreas que es peor, ¿qué se necesita para superar esas deficiencias?
- ¿Ocupará el lugar de varias herramientas?
- ¿Qué tan estable es la tecnología?
Nuestro ¿Por qué?
En este punto, también quiero revisar por qué estamos buscando otra solución. Una respuesta simple es que nos encontramos con un problema que las soluciones existentes no resuelven . Sin embargo, esto es a menudo raramente el caso. Hemos resuelto muchos problemas de software a lo largo de los años con toda la tecnología que tenemos hoy. Lo que suele suceder es que nos cambiamos a una nueva tecnología que hace que algo que estamos haciendo actualmente sea más fácil, más estable, más rápido o más barato.
Tomemos React como ejemplo. ¿Por qué decidimos adoptar React cuando jQuery o Vanilla JavaScript estaban haciendo el trabajo? En este caso, el uso del marco destacó cómo esta era una forma mucho mejor de manejar las interfaces con estado. Se volvió más rápido para nosotros crear cosas como funciones de filtrado y clasificación al trabajar con estructuras de datos en lugar de la manipulación directa de DOM. Esto supuso un ahorro de tiempo y una mayor estabilidad de nuestras soluciones.
Typescript es otro ejemplo en el que decidimos adoptarlo porque encontramos aumentos en la estabilidad de nuestro código y la capacidad de mantenimiento. Con la adopción de nuevas tecnologías, a menudo no hay un problema claro que buscamos resolver, sino que simplemente buscamos mantenernos actualizados y luego descubrir soluciones más eficientes y estables que las que estamos usando actualmente.
En el caso de una base de datos, estábamos considerando específicamente pasar a una opción sin servidor . Habíamos tenido mucho éxito con aplicaciones e implementaciones sin servidor que reducían nuestros gastos generales como organización. Un área en la que sentimos que esto faltaba era nuestra capa de datos. Vimos servicios como Amazon Aurora, Fauna, Cosmos y Firebase que estaban aplicando principios sin servidor a las bases de datos y queríamos ver si era hora de dar el salto nosotros mismos. En este caso, buscábamos reducir nuestros gastos generales operativos y aumentar nuestra velocidad y eficiencia de desarrollo.
En este nivel, es importante entender por qué antes de comenzar a sumergirse en nuevas ofertas. Esto puede deberse a que está resolviendo un problema nuevo, pero con mucha más frecuencia está buscando mejorar su capacidad para resolver un tipo de problema que ya está resolviendo. En ese caso, debe hacer un inventario de dónde ha estado para descubrir qué proporcionaría una mejora significativa para su flujo de trabajo. Sobre la base de nuestro ejemplo de mirar bases de datos sin servidor, tendremos que echar un vistazo a cómo estamos resolviendo problemas actualmente y dónde se quedan cortas esas soluciones.
Donde hemos estado...
Como agencia, hemos utilizado anteriormente una amplia gama de bases de datos, incluidas, entre otras, MySQL, PostgreSQL, MongoDB, DynamoDB, BigQuery y Firebase Cloud Storage. Sin embargo, la gran mayoría de nuestro trabajo se centró en tres bases de datos principales: PostgreSQL, MongoDB y Firebase Realtime Database. De hecho, cada uno de estos tiene ofertas semi-sin servidor, pero algunas características clave de las ofertas más nuevas nos hicieron reevaluar nuestras suposiciones anteriores. Echemos un vistazo a nuestra experiencia histórica con cada uno de estos primeros y por qué nos quedamos considerando alternativas en primer lugar.
Por lo general, elegimos PostgreSQL para proyectos más grandes a largo plazo, ya que este es el estándar de oro probado en batalla para casi todo. Admite transacciones clásicas, datos normalizados y cumple con ACID. Hay una gran cantidad de herramientas y ORM disponibles en casi todos los idiomas e incluso se puede usar como una base de datos NoSQL ad-hoc con su soporte de columna JSON. Se integra bien con muchos marcos, bibliotecas y lenguajes de programación existentes, lo que lo convierte en un verdadero caballo de batalla para ir a cualquier parte. También es de código abierto y, por lo tanto, no nos limita a ningún proveedor. Como dicen, nadie fue despedido por elegir Postgres.
Dicho esto, gradualmente nos encontramos usando PostgreSQL cada vez menos a medida que nos convertimos en una tienda más orientada a nodos. Descubrimos que los ORM para Node son mediocres y requieren más consultas personalizadas (aunque ahora esto se ha vuelto menos problemático) y NoSQL se sintió más natural cuando se trabaja en un tiempo de ejecución de JavaScript o TypeScript. Dicho esto, a menudo teníamos proyectos que se podían hacer con bastante rapidez con el modelado relacional clásico, como los flujos de trabajo de comercio electrónico. Sin embargo, lidiar con la configuración local de la base de datos, unificar el flujo de pruebas entre los equipos y lidiar con las migraciones locales eran cosas que no nos gustaban y nos alegramos de dejar atrás a medida que las bases de datos NoSQL basadas en la nube se hicieron más populares.
MongoDB se convirtió cada vez más en nuestra base de datos de acceso, ya que adoptamos Node.js como nuestro back-end preferido. Trabajar con MongoDB Atlas facilitó el desarrollo rápido y las bases de datos de prueba que nuestro equipo podía usar. Durante un tiempo, MongoDB no era compatible con ACID, no admitía transacciones y desaconsejaba demasiadas operaciones internas similares a las de unión, por lo que para las aplicaciones de comercio electrónico todavía usábamos Postgres con mayor frecuencia. Dicho esto, hay una gran cantidad de bibliotecas que lo acompañan y el lenguaje de consulta de Mongo y el soporte JSON de primera clase nos brindaron una velocidad y eficiencia que no habíamos experimentado con las bases de datos relacionales. MongoDB agregó soporte para transacciones ACID recientemente, pero durante mucho tiempo, esta fue la razón principal por la que optaríamos por Postgres.
MongoDB también nos presentó un nuevo nivel de flexibilidad. En medio de un proyecto de agencia, los requisitos están obligados a cambiar. No importa cuánto te defiendas, siempre hay un requerimiento de datos de última hora . Con las bases de datos NoSQL, en general, la flexibilidad de la estructura de datos hizo que esos tipos de cambios fueran menos duros. No terminamos con una carpeta llena de archivos de migración para administrar las columnas agregadas, eliminadas y agregadas nuevamente antes de que un proyecto viera la luz del día.
Como servicio, Mongo Atlas también estaba bastante cerca de lo que deseábamos en un servicio de base de datos en la nube. Me gusta pensar en Atlas como una oferta semi -sin servidor, ya que todavía tiene algunos gastos generales operativos para administrarlo. Debe aprovisionar una base de datos de cierto tamaño y seleccionar una cantidad de memoria por adelantado. Estas cosas no se escalarán automáticamente, por lo que deberá monitorearlas para cuando sea el momento de proporcionar más espacio o memoria. En una base de datos verdaderamente sin servidor, todo esto sucedería automáticamente y bajo demanda.
También utilizamos Firebase Realtime Database para algunos proyectos. De hecho, se trataba de una oferta sin servidor en la que la base de datos aumentaba y disminuía según la demanda, y con precios de pago por uso, tenía sentido para aplicaciones en las que la escala no se conocía por adelantado y el presupuesto era limitado. Usamos esto en lugar de MongoDB para proyectos de corta duración que tenían requisitos de datos simples.
Una cosa que no disfrutamos de Firebase fue que parecía estar más lejos del modelo relacional típico construido alrededor de datos normalizados a los que estábamos acostumbrados. Mantener las estructuras de datos planas significaba que a menudo teníamos más duplicaciones, lo que podía volverse un poco feo a medida que crece el proyecto. Termina teniendo que actualizar los mismos datos en varios lugares o tratando de unir diferentes referencias, lo que da como resultado múltiples consultas que pueden volverse difíciles de razonar en el código. Si bien nos gustó Firebase, nunca nos enamoramos del lenguaje de consulta y, a veces, la documentación nos pareció deslucida.
En general, tanto MongoDB como Firebase tenían un enfoque similar en los datos desnormalizados , y sin acceso a transacciones eficientes, a menudo encontramos muchos de los flujos de trabajo que eran fáciles de modelar en bases de datos relacionales, lo que llevó a un código más complejo en la capa de aplicación con su Contrapartes de NoSQL. Si pudiéramos obtener la flexibilidad y la facilidad de estas ofertas NoSQL con la solidez y el modelado relacional de una base de datos SQL tradicional, realmente habríamos encontrado una gran combinación. Sentimos que MongoDB tenía la mejor API y capacidades, pero Firebase tenía el modelo verdaderamente sin servidor desde el punto de vista operativo.
nuestro ideal
En este punto, podemos comenzar a ver qué nuevas opciones consideraremos. Hemos definido claramente nuestras soluciones anteriores y hemos identificado las cosas que es importante para nosotros tener como mínimo en nuestra nueva solución. No solo tenemos una línea de base o un conjunto mínimo de requisitos, sino que también tenemos un conjunto de problemas que nos gustaría que la nueva solución solucione. Estos son los requisitos técnicos que tenemos:
- Operacionalmente sin servidor con escala bajo demanda
- Modelado flexible (sin esquema)
- Sin dependencia de migraciones u ORM
- Transacciones compatibles con ACID
- Admite relaciones y datos normalizados
- Funciona con backends tradicionales y sin servidor
Entonces, ahora que tenemos una lista de elementos imprescindibles, podemos evaluar algunas opciones. Puede que no sea importante que la nueva solución cumpla todos los objetivos aquí. Puede ser que encuentre la combinación correcta de características donde las soluciones existentes no se superponen. Por ejemplo, si quería flexibilidad sin esquema , tenía que renunciar a las transacciones ACID. (Este fue el caso durante mucho tiempo con las bases de datos).
Un ejemplo de otro dominio es que si desea tener una validación mecanografiada en la representación de su plantilla, debe usar TSX y React. Si elige opciones como Svelte o Vue, puede tener esto, parcialmente pero no completamente, a través de la representación de la plantilla . Por lo tanto, una solución que le diera el tamaño reducido y la velocidad de Svelte con la verificación de tipo de nivel de plantilla de React y TypeScript podría ser suficiente para su adopción, incluso si faltara otra característica. El equilibrio de deseos y necesidades va a cambiar de un proyecto a otro. Depende de usted averiguar dónde estará el valor y decidir cómo marcar los puntos más importantes en su análisis.
Ahora podemos echar un vistazo a una solución y ver cómo se evalúa frente a nuestra solución deseada. Fauna es una solución de base de datos sin servidor que cuenta con una escala bajo demanda con distribución global. Es una base de datos sin esquema, que proporciona transacciones compatibles con ACID y admite consultas relacionales y datos normalizados como característica. Fauna se puede utilizar tanto en aplicaciones sin servidor como en backends más tradicionales y proporciona bibliotecas para trabajar con los lenguajes más populares. Además, Fauna proporciona flujos de trabajo para la autenticación, así como una tenencia múltiple fácil y eficiente. Estas son características adicionales sólidas a tener en cuenta porque podrían ser los factores determinantes cuando dos tecnologías están cara a cara en nuestra evaluación.
Ahora, después de ver todas estas fortalezas, tenemos que evaluar las debilidades . Uno de los cuales es Fauna no es de código abierto. Esto significa que existen riesgos de bloqueo de proveedores o cambios comerciales y de precios que están fuera de su control. El código abierto puede ser bueno porque a menudo puede subir y llevar la tecnología a otro proveedor si lo desea o puede contribuir al proyecto.
En el mundo de las agencias, el bloqueo de proveedores es algo que debemos vigilar de cerca, no tanto por el precio, sino por la viabilidad del negocio subyacente. Tener que cambiar las bases de datos de un proyecto que está en pleno desarrollo o que tiene algunos años es desastroso para una agencia. A menudo, un cliente tendrá que pagar la cuenta por esto, lo cual no es una conversación agradable.
Otra debilidad que nos preocupaba es el enfoque en JAMstack . Si bien nos encanta JAMstack, nos encontramos construyendo una amplia variedad de aplicaciones web tradicionales con más frecuencia. Queremos estar seguros de que Fauna continúa apoyando esos casos de uso. Tuvimos una mala experiencia en el pasado con un proveedor de alojamiento que optó por JAMstack y terminamos teniendo que migrar una gran cantidad de sitios del servicio, por lo que queremos estar seguros de que todos los casos de uso se seguirán viendo. soporte sólido. En este momento, este parece ser el caso, y los flujos de trabajo sin servidor proporcionados por Fauna en realidad pueden complementar bastante bien una aplicación más tradicional.

En este punto, hemos realizado nuestra investigación funcional y la única forma de saber si esta solución es viable es bajar y escribir algo de código. En el entorno de una agencia, no podemos tomar semanas fuera del cronograma para que las personas evalúen múltiples soluciones. Esta es la naturaleza de trabajar en una agencia frente a un entorno SaaS . En este último, puede construir algunos prototipos para intentar llegar a la solución correcta. En una agencia, tendrá algunos días para experimentar, o tal vez la oportunidad de hacer un proyecto paralelo, pero en general, realmente tenemos que reducir esto a una o dos tecnologías en esta etapa y luego poner los dedos en el teclado.
La experiencia del desarrollador
Juzgar el lado de la experiencia de una nueva tecnología es quizás la más difícil de las tres áreas, ya que es subjetiva por naturaleza. También tendrá variabilidad de un equipo a otro. Por ejemplo, si le preguntas a un programador de Ruby, un programador de Python y un programador de Rust acerca de sus opiniones sobre las diferentes funciones del lenguaje, obtendrás una gran variedad de respuestas. Entonces, antes de comenzar a juzgar una experiencia, primero debe decidir qué características son más importantes para su equipo en general.

Para las agencias, creo que hay dos cuellos de botella principales que surgen con respecto a la experiencia del desarrollador:
- Tiempo de instalación y configuración
- Capacidad de aprendizaje
Ambos afectan la viabilidad a largo plazo de una nueva tecnología de diferentes maneras. Mantener sincronizados equipos transitorios de desarrolladores en una agencia puede ser un dolor de cabeza. Las herramientas que tienen muchos costos de instalación y configuraciones iniciales son notoriamente difíciles de usar para las agencias. El otro es la capacidad de aprendizaje y lo fácil que es para los desarrolladores hacer crecer la nueva tecnología. Veremos esto con más detalle y explicaremos por qué son mi base cuando empiezo a evaluar la experiencia del desarrollador.
Tiempo de instalación y configuración
Las agencias tienden a tener poca paciencia y tiempo para la configuración. A mí me encantan las herramientas afiladas, con diseños ergonómicos, que me permitan trabajar rápidamente en el problema comercial que tengo entre manos. Hace varios años, trabajé para una empresa de SaaS que tenía una configuración local compleja que involucraba muchas configuraciones y, a menudo, fallaba en puntos aleatorios del proceso de configuración. Una vez que estaba configurado, la sabiduría convencional era no tocar nada y esperar que no estuvo en la empresa el tiempo suficiente para tener que configurarlo nuevamente en otra máquina. Conocí a desarrolladores que disfrutaron mucho configurando cada pequeña parte de su configuración de emacs y no pensaron en perder algunas horas en un entorno local dañado.
En general, he encontrado que los ingenieros de agencias tienen un desdén por este tipo de cosas en su trabajo diario. Mientras están en casa, pueden jugar con este tipo de herramientas, pero cuando tienen una fecha límite, no hay nada como las herramientas que simplemente funcionan. En las agencias, normalmente preferimos aprender algunas cosas nuevas que funcionan bien, de manera consistente, en lugar de poder configurar cada pieza de tecnología según el gusto personal de cada individuo.
Una cosa buena de trabajar con una plataforma en la nube que no es de código abierto es que son dueños de la instalación y la configuración por completo. Si bien una desventaja de esto es el bloqueo del proveedor, la ventaja es que este tipo de herramientas a menudo hacen bien las cosas para las que están configuradas. No hay que modificar los entornos, no hay configuraciones locales ni canalizaciones de implementación. También tenemos menos decisiones que tomar.
Este es inherentemente el atractivo de serverless . Serverless en general tiene una mayor dependencia de servicios y herramientas propietarios. Intercambiamos la flexibilidad del alojamiento y el código fuente para que podamos ganar una mayor estabilidad y centrarnos en los problemas del dominio comercial que estamos tratando de resolver. También señalaré que cuando estoy evaluando una tecnología y tengo la sensación de que podría ser necesario migrar fuera de una plataforma, esto suele ser una mala señal desde el principio.
En el caso de las bases de datos, la configuración de configurarlo y olvidarlo es ideal cuando se trabaja con clientes donde las necesidades de la base de datos pueden ser ambiguas. Hemos tenido clientes que no estaban seguros de cuán popular sería un programa o una aplicación. Hemos tenido clientes a los que técnicamente no estábamos contratados para brindar soporte de esta manera, pero sin embargo nos llamaron en estado de pánico cuando nos necesitaban para escalar su base de datos o aplicación.
En el pasado, siempre teníamos que tener en cuenta cosas como la redundancia, la replicación de datos y la fragmentación para escalar cuando creamos nuestras SOW. Tratar de cubrir cada escenario y al mismo tiempo estar preparado para mover un libro completo de negocios en caso de que una base de datos no se escalara es una situación para la que es imposible prepararse. Al final, una base de datos sin servidor facilita estas cosas.
Nunca pierde datos , no tiene que preocuparse por replicar datos a través de una red, ni aprovisionar una base de datos y una máquina más grandes para ejecutarlos: todo simplemente funciona. Solo nos enfocamos en el problema comercial en cuestión, la arquitectura técnica y la escala siempre se administrarán. Para nuestro equipo de desarrollo, esta es una gran victoria; tenemos menos simulacros de incendio, monitoreo y cambio de contexto.
Capacidad de aprendizaje
Existe una medida clásica de la experiencia del usuario, que creo que es aplicable a la experiencia del desarrollador, que es la capacidad de aprendizaje . Cuando diseñamos para una determinada experiencia de usuario, no solo nos fijamos en si algo es evidente o fácil en el primer intento. La tecnología tiene más complejidad que eso la mayor parte del tiempo. Lo importante es la facilidad con la que un nuevo usuario puede aprender y dominar el sistema.
Cuando se trata de herramientas técnicas, especialmente de las más potentes, sería mucho pedir que la curva de aprendizaje fuera cero . Por lo general, lo que buscamos es que haya una excelente documentación para los casos de uso más comunes y que ese conocimiento se desarrolle de manera fácil y rápida en un proyecto. Está bien perder un poco de tiempo para aprender en el primer proyecto con una tecnología. Después de eso, deberíamos ver que la eficiencia mejora con cada proyecto sucesivo.
Lo que busco específicamente aquí es cómo podemos aprovechar el conocimiento y los patrones que ya conocemos para ayudar a acortar la curva de aprendizaje. Por ejemplo, con las bases de datos sin servidor, la curva de aprendizaje será prácticamente nula para configurarlas en la nube e implementarlas. Cuando se trata de usar la base de datos, una de las cosas que me gusta es poder aprovechar todos los años de dominio de las bases de datos relacionales y aplicar esos aprendizajes a nuestra nueva configuración. En este caso, estamos aprendiendo a usar una nueva herramienta, pero no nos obliga a repensar nuestro modelado de datos desde cero.

Como ejemplo de esto, cuando usamos Firebase, MongoDB y DynamoDB, descubrimos que fomentaba la desnormalización de los datos en lugar de tratar de unir diferentes documentos. Esto creó mucha fricción cognitiva al modelar nuestros datos, ya que necesitábamos pensar en términos de patrones de acceso en lugar de entidades comerciales. Por otro lado, Fauna nos permitió aprovechar nuestros años de conocimiento relacional, así como nuestra preferencia por los datos normalizados cuando se trataba de modelar datos.
La parte a la que tuvimos que acostumbrarnos fue usar índices y un nuevo lenguaje de consulta para unir esas piezas. En general, descubrí que preservar los conceptos que forman parte de paradigmas de diseño de software más amplios hace que sea más fácil para el equipo de desarrollo en términos de capacidad de aprendizaje y adopción.
¿Cómo sabemos que un equipo está adoptando y amando una nueva tecnología? Creo que la mejor señal es cuando nos preguntamos si esa herramienta se integra con dicha nueva tecnología. Cuando una nueva tecnología llega a un nivel de conveniencia y placer en el que el equipo está buscando formas de incorporarla en más proyectos, es una buena señal de que tiene un ganador.
El negocio
En esta sección, tenemos que ver cómo una nueva tecnología satisface nuestras necesidades comerciales . Estos incluyen preguntas como:
- ¿Con qué facilidad se puede cotizar e integrar en nuestros planes de soporte?
- ¿Podemos hacer la transición a los clientes fácilmente?
- ¿Pueden los clientes incorporarse a esta herramienta si es necesario?
- ¿Cuánto tiempo ahorra realmente esta herramienta, si es que lo hace?
El surgimiento de serverless como paradigma se adapta bien a las agencias. Cuando hablamos de bases de datos y DevOps, la necesidad de especialistas en estas áreas en las agencias es limitada. A menudo entregamos un proyecto cuando terminamos o lo apoyamos con una capacidad limitada a largo plazo. Tendemos a inclinarnos hacia los ingenieros de pila completa, ya que estas necesidades superan en número a las necesidades de DevOps por un amplio margen. Si contratáramos a un ingeniero de DevOps, probablemente pasaría algunas horas implementando un proyecto y muchas más horas esperando un incendio.
En este sentido, siempre tenemos algunos contratistas de DevOps listos, pero no contamos con personal para estos puestos a tiempo completo. Esto significa que no podemos confiar en que un ingeniero de DevOps esté listo para responder a un problema inesperado. Para nosotros, sabemos que podemos obtener mejores tarifas de hospedaje yendo a AWS directamente, pero también sabemos que al usar Heroku podemos confiar en nuestro personal existente para solucionar la mayoría de los problemas. A menos que tengamos un cliente que necesitemos brindar soporte a largo plazo con necesidades específicas de back-end, nos gusta usar de forma predeterminada las plataformas administradas como un servicio.
Las bases de datos no son una excepción. Nos encanta apoyarnos en servicios como Mongo Atlas o Heroku Postgres para que este proceso sea lo más fácil posible. A medida que comenzamos a ver más y más de nuestra pila de herramientas sin servidor como Vercel, Netlify o AWS Lambda, nuestras necesidades de base de datos tuvieron que evolucionar con eso. Las bases de datos sin servidor como Firebase, DynamoDB y Fauna son excelentes porque se integran bien con las aplicaciones sin servidor, pero también liberan completamente a nuestra empresa del aprovisionamiento y el escalado.
Estas soluciones también funcionan bien para aplicaciones más tradicionales, donde no tenemos una aplicación sin servidor pero aún podemos aprovechar las eficiencias sin servidor a nivel de base de datos. Como empresa, es más productivo para nosotros aprender una sola base de datos que pueda aplicarse a ambos mundos que cambiar de contexto. Esto es similar a nuestra decisión de adoptar Node y JavaScript isomorfo (y TypeScript).
Una de las desventajas que hemos encontrado con serverless ha sido la fijación de precios para los clientes para los que administramos estos servicios. En una arquitectura más tradicional, los niveles de tarifa plana hacen que sea muy fácil convertirlos en una tarifa para clientes con circunstancias predecibles para incurrir en aumentos y excedentes. Cuando se trata de serverless, esto puede ser ambiguo. A la gente de finanzas normalmente no le gusta escuchar cosas como que cobramos 1/10 de centavo por cada lectura más allá de 1 millón, y así sucesivamente.
Esto es difícil de traducir a un número fijo, incluso para los ingenieros, ya que a menudo estamos creando aplicaciones de las que no estamos seguros de cuál será el uso . A menudo tenemos que crear niveles nosotros mismos, pero las muchas variables que intervienen en el cálculo del costo de una lambda pueden ser difíciles de comprender. En última instancia, para un producto SaaS, estos modelos de precios de pago por uso son excelentes, pero para las agencias, a los contadores les gustan los números más concretos y predecibles.
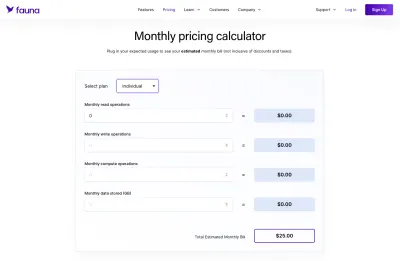
Cuando se trataba de Fauna, esto era definitivamente más ambiguo de entender que, por ejemplo, una base de datos MySQL estándar que tenía alojamiento de tarifa plana para una cantidad determinada de espacio. La ventaja fue que Fauna proporciona una buena calculadora que pudimos usar para armar nuestros propios esquemas de precios.
Otro aspecto difícil de serverless puede ser que muchos de estos proveedores no permiten un desglose fácil de cada aplicación alojada. Por ejemplo, la plataforma Heroku lo hace bastante fácil al crear nuevos canales y equipos. Incluso podemos ingresar la tarjeta de crédito de un cliente por ellos en caso de que no quieran usar nuestros planes de alojamiento. Todo esto también se puede hacer dentro del mismo tablero, por lo que no necesitamos crear múltiples inicios de sesión.
Cuando se trataba de otras herramientas sin servidor, esto era mucho más difícil. Al evaluar bases de datos sin servidor, Firebase admite la división de pagos por proyecto . En el caso de Fauna o DynamoDB, esto no es posible, por lo que tenemos que hacer algo de trabajo para monitorear el uso en su tablero, y si el cliente quiere dejar nuestro servicio, tendríamos que transferir la base de datos a su propia cuenta.
En última instancia, las herramientas sin servidor brindan grandes oportunidades comerciales en términos de ahorro de costos, administración y eficiencia de procesos. Sin embargo, a menudo resultan desafiantes para las agencias cuando se trata de precios y administración de cuentas. Esta es un área en la que hemos tenido que aprovechar las calculadoras de costos para crear nuestros propios niveles de precios predecibles o configurar clientes con sus propias cuentas para que puedan realizar los pagos directamente.
Conclusión
Puede ser una tarea difícil adoptar una nueva tecnología como agencia. Si bien estamos en una posición única para trabajar con nuevos proyectos totalmente nuevos que tienen oportunidades para nuevas tecnologías, también debemos considerar la inversión a largo plazo de estos. ¿Cómo se desempeñarán? ¿Nuestra gente será productiva y disfrutará usándolos? Can we incorporate them into our business offering?
You need to have a firm grasp of where you have been before you figure out where you want to go technologically. When evaluating a new tool or platform it's important to think of what you have tried in the past and figure out what is most important to you and your team. We took a look at the concept of a serverless database and passed it through our three lenses – the technology, the experience, and the business. We were left with some pros and cons and had to strike the right balance.
After we evaluated serverless databases, we decided to adopt Fauna over the alternatives. We felt the technology was robust and ticked all of our boxes for our technology filter. When it came to the experience, virtually zero configuration and being able to leverage our existing knowledge of relational data modeling made this a winner with the development team. On the business side serverless provides clear wins to efficiency and productivity , however on the pricing side and account management there are still some difficulties. We decided the benefits in the other areas outweighed the pricing difficulties.
Overall, we highly recommend giving Fauna a shot on one of your next projects. It has become one of our favorite tools and our go-to database of choice for smaller serverless projects and even more traditional large backend applications. The community is very helpful, the learning curve is gentle, and we believe you'll find levels of productivity you hadn't realized before with existing databases.
When we first use a new technology on a project, we start with something either internal or on the smaller side. We try to mitigate the risk by wading into the water rather than leaping into the deep end by trying it on a large and complex project. As the team builds understanding of the technology, we start using it for larger projects but only after we feel comfortable that it has handled similar use cases well for us in the past.
In general, it can take up to a year for a technology to become a ubiquitous part of most projects so it is important to be patient. Agencies have a lot of flexibility but also are required to ensure stability in the products they produce, we don't get a second chance. Always be experimenting and pushing your agency to adopt new technologies, but do so carefully and you will reap the benefits.
Otras lecturas
- Serverless Database Wishlist - What's Missing Today
- Relational NoSQL: Yes, that is an option
- Concerning toolkits - A great piece about the merits of zero configuration on developer experience