
Construcción de un detector de habitaciones para dispositivos IoT en Mac OS
Publicado: 2022-03-10Saber en qué habitación se encuentra permite varias aplicaciones de IoT, desde encender la luz hasta cambiar los canales de televisión. Entonces, ¿cómo podemos detectar el momento en que usted y su teléfono están en la cocina, el dormitorio o la sala de estar? Con el hardware básico actual, hay una gran variedad de posibilidades:
Una solución es equipar cada habitación con un dispositivo bluetooth . Una vez que su teléfono esté dentro del alcance de un dispositivo bluetooth, su teléfono sabrá en qué habitación se encuentra, según el dispositivo bluetooth. Sin embargo, el mantenimiento de una serie de dispositivos Bluetooth es una sobrecarga significativa, desde reemplazar las baterías hasta reemplazar los dispositivos disfuncionales. Además, la proximidad al dispositivo Bluetooth no siempre es la respuesta: si estás en la sala de estar, junto a la pared compartida con la cocina, los electrodomésticos de tu cocina no deberían comenzar a producir comida en masa.
Otra solución, aunque poco práctica, es usar GPS . Sin embargo, tenga en cuenta que el GPS funciona mal en interiores en los que la multitud de paredes, otras señales y otros obstáculos causan estragos en la precisión del GPS.
En cambio, nuestro enfoque es aprovechar todas las redes WiFi dentro del alcance , incluso aquellas a las que su teléfono no está conectado. He aquí cómo: considere la fuerza de WiFi A en la cocina; digamos que es 5. Dado que hay una pared entre la cocina y el dormitorio, podemos esperar razonablemente que la potencia de WiFi A en el dormitorio difiera; digamos que es 2. Podemos aprovechar esta diferencia para predecir en qué habitación estamos. Es más: la red WiFi B de nuestro vecino solo se puede detectar desde la sala de estar, pero es invisible desde la cocina. Eso hace que la predicción sea aún más fácil. En resumen, la lista de todos los WiFi dentro del alcance nos brinda abundante información.
Este método tiene las claras ventajas de:
- no requiere más hardware;
- confiar en señales más estables como WiFi;
- funciona bien donde otras técnicas como el GPS son débiles.
Cuantas más paredes, mejor, ya que cuanto más dispares sean las intensidades de la red WiFi, más fácil será clasificar las habitaciones. Creará una aplicación de escritorio simple que recopila datos, aprende de los datos y predice en qué habitación se encuentra en un momento dado.
Lectura adicional en SmashingMag:
- El auge de la interfaz de usuario conversacional inteligente
- Aplicaciones de aprendizaje automático para diseñadores
- Cómo crear prototipos de experiencias de IoT: construir el hardware
- Diseñando para Internet de las cosas emocionales
requisitos previos
Para este tutorial, necesitará un Mac OSX. Mientras que el código puede aplicarse a cualquier plataforma, solo proporcionaremos instrucciones de instalación de dependencias para Mac.
- Mac OS X
- Homebrew, un administrador de paquetes para Mac OSX. Para instalar, copie y pegue el comando en brew.sh
- Instalación de NodeJS 10.8.0+ y npm
- Instalación de Python 3.6+ y pip. Consulte las primeras 3 secciones de "Cómo instalar virtualenv, Instalar con pip y Administrar paquetes"
Paso 0: configurar el entorno de trabajo
Su aplicación de escritorio se escribirá en NodeJS. Sin embargo, para aprovechar bibliotecas computacionales más eficientes como numpy , el código de entrenamiento y predicción se escribirá en Python. Para comenzar, configuraremos sus entornos e instalaremos las dependencias. Cree un nuevo directorio para albergar su proyecto.
mkdir ~/riotNavega al directorio.
cd ~/riotUse pip para instalar el administrador de entorno virtual predeterminado de Python.
sudo pip install virtualenv Cree un entorno virtual Python3.6 llamado riot .
virtualenv riot --python=python3.6Activar el entorno virtual.
source riot/bin/activate Su mensaje ahora está precedido por (riot) . Esto indica que hemos ingresado con éxito al entorno virtual. Instale los siguientes paquetes usando pip :
-
numpy: una biblioteca de álgebra lineal eficiente -
scipy: una biblioteca informática científica que implementa modelos populares de aprendizaje automático
pip install numpy==1.14.3 scipy ==1.1.0Con la configuración del directorio de trabajo, comenzaremos con una aplicación de escritorio que registra todas las redes WiFi dentro del alcance. Estas grabaciones constituirán datos de entrenamiento para su modelo de aprendizaje automático. Una vez que tengamos los datos a mano, escribirá un clasificador de mínimos cuadrados, entrenado en las señales WiFi recopiladas anteriormente. Finalmente, usaremos el modelo de mínimos cuadrados para predecir la habitación en la que se encuentra, en función de las redes WiFi dentro del alcance.
Paso 1: aplicación de escritorio inicial
En este paso, crearemos una nueva aplicación de escritorio utilizando Electron JS. Para comenzar, usaremos en su lugar el administrador de paquetes Node npm y una utilidad de descarga wget .
brew install npm wgetPara comenzar, crearemos un nuevo proyecto Node.
npm init Esto le solicita el nombre del paquete y luego el número de versión. Presiona ENTER para aceptar el nombre predeterminado de riot y la versión predeterminada de 1.0.0 .
package name: (riot) version: (1.0.0) Esto le pedirá una descripción del proyecto. Agregue cualquier descripción que no esté vacía que desee. A continuación, la descripción es room detector
description: room detector Esto le solicita el punto de entrada o el archivo principal desde el que ejecutar el proyecto. Ingresa app.js
entry point: (index.js) app.js Esto le solicita el test command y el git repository . Presiona ENTER para omitir estos campos por ahora.
test command: git repository: Esto le pedirá keywords y author . Rellene los valores que desee. A continuación, usamos iot , wifi para palabras clave y usamos John Doe para el autor.
keywords: iot,wifi author: John Doe Esto le solicita la licencia. Pulse ENTER para aceptar el valor predeterminado de ISC .
license: (ISC) En este punto, npm le mostrará un resumen de la información hasta el momento. Su salida debe ser similar a la siguiente.
{ "name": "riot", "version": "1.0.0", "description": "room detector", "main": "app.js", "scripts": { "test": "echo \"Error: no test specified\" && exit 1" }, "keywords": [ "iot", "wifi" ], "author": "John Doe", "license": "ISC" } Pulse ENTER para aceptar. npm luego produce un package.json . Enumere todos los archivos para verificar dos veces.
lsEsto generará el único archivo en este directorio, junto con la carpeta del entorno virtual.
package.json riotInstale las dependencias de NodeJS para nuestro proyecto.
npm install electron --global # makes electron binary accessible globally npm install node-wifi --save Comience con main.js de Electron Quick Start, descargando el archivo, usando lo siguiente. El siguiente argumento -O cambia el nombre de main.js a app.js .
wget https://raw.githubusercontent.com/electron/electron-quick-start/master/main.js -O app.js Abra app.js en nano o su editor de texto favorito.
nano app.js En la línea 12, cambie index.html a static/index.html , ya que crearemos un directorio static para contener todas las plantillas HTML.
function createWindow () { // Create the browser window. win = new BrowserWindow({width: 1200, height: 800}) // and load the index.html of the app. win.loadFile('static/index.html') // Open the DevTools. Guarde sus cambios y salga del editor. Su archivo debe coincidir con el código fuente del archivo app.js Ahora cree un nuevo directorio para albergar nuestras plantillas HTML.
mkdir staticDescargue una hoja de estilo creada para este proyecto.
wget https://raw.githubusercontent.com/alvinwan/riot/master/static/style.css?token=AB-ObfDtD46ANlqrObDanckTQJ2Q1Pyuks5bf79PwA%3D%3D -O static/style.css Abra static/index.html en nano o en su editor de texto favorito. Comience con la estructura HTML estándar.
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>Riot | Room Detector</title> </head> <body> <main> </main> </body> </html>Justo después del título, vincula la fuente Montserrat vinculada por Google Fonts y la hoja de estilo.
<title>Riot | Room Detector</title> <!-- start new code --> <link href="https://fonts.googleapis.com/css?family=Montserrat:400,700" rel="stylesheet"> <link href="style.css" rel="stylesheet"> <!-- end new code --> </head> Entre las etiquetas main , agregue un espacio para el nombre previsto de la habitación.
<main> <!-- start new code --> <p class="text">I believe you're in the</p> <h1 class="title">(I dunno)</h1> <!-- end new code --> </main>Su secuencia de comandos ahora debería coincidir exactamente con lo siguiente. Sal del editor.
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>Riot | Room Detector</title> <link href="https://fonts.googleapis.com/css?family=Montserrat:400,700" rel="stylesheet"> <link href="style.css" rel="stylesheet"> </head> <body> <main> <p class="text">I believe you're in the</p> <h1 class="title">(I dunno)</h1> </main> </body> </html>Ahora, modifique el archivo del paquete para que contenga un comando de inicio.
nano package.json Inmediatamente después de la línea 7, agregue un comando de start que tenga un alias de electron . . Asegúrese de agregar una coma al final de la línea anterior.
"scripts": { "test": "echo \"Error: no test specified\" && exit 1", "start": "electron ." }, Guardar y Salir. Ahora está listo para iniciar su aplicación de escritorio en Electron JS. Utilice npm para iniciar su aplicación.
npm startSu aplicación de escritorio debe coincidir con lo siguiente.

Esto completa su aplicación de escritorio inicial. Para salir, navegue de regreso a su terminal y presione CTRL+C. En el siguiente paso, registraremos las redes wifi y haremos que la utilidad de grabación sea accesible a través de la interfaz de usuario de la aplicación de escritorio.
Paso 2: Grabar redes WiFi
En este paso, escribirá un script de NodeJS que registre la fuerza y la frecuencia de todas las redes wifi dentro del alcance. Cree un directorio para sus scripts.
mkdir scripts Abra scripts/observe.js en nano o en su editor de texto favorito.
nano scripts/observe.jsImporte una utilidad wifi de NodeJS y el objeto del sistema de archivos.
var wifi = require('node-wifi'); var fs = require('fs'); Defina una función de record que acepte un controlador de finalización.
/** * Uses a recursive function for repeated scans, since scans are asynchronous. */ function record(n, completion, hook) { } Dentro de la nueva función, inicialice la utilidad wifi. Establezca iface en nulo para inicializar a una interfaz wifi aleatoria, ya que este valor actualmente es irrelevante.
function record(n, completion, hook) { wifi.init({ iface : null }); }Defina una matriz para contener sus muestras. Las muestras son datos de entrenamiento que usaremos para nuestro modelo. Los ejemplos en este tutorial en particular son listas de redes wifi dentro del alcance y sus fortalezas, frecuencias, nombres, etc. asociados.
function record(n, completion, hook) { ... samples = [] } Defina una función recursiva startScan , que iniciará de forma asincrónica escaneos wifi. Al finalizar, el escaneo wifi asíncrono invocará recursivamente startScan .
function record(n, completion, hook) { ... function startScan(i) { wifi.scan(function(err, networks) { }); } startScan(n); } En la devolución de llamada wifi.scan , verifique si hay errores o listas vacías de redes y reinicie el escaneo si es así.
wifi.scan(function(err, networks) { if (err || networks.length == 0) { startScan(i); return } });Agregue el caso base de la función recursiva, que invoca el controlador de finalización.
wifi.scan(function(err, networks) { ... if (i <= 0) { return completion({samples: samples}); } });Envíe una actualización de progreso, agregue a la lista de muestras y realice la llamada recursiva.
wifi.scan(function(err, networks) { ... hook(n-i+1, networks); samples.push(networks); startScan(i-1); }); Al final de su archivo, invoque la función de record con una devolución de llamada que guarda las muestras en un archivo en el disco.
function record(completion) { ... } function cli() { record(1, function(data) { fs.writeFile('samples.json', JSON.stringify(data), 'utf8', function() {}); }, function(i, networks) { console.log(" * [INFO] Collected sample " + (21-i) + " with " + networks.length + " networks"); }) } cli();Vuelva a verificar que su archivo coincida con lo siguiente:
var wifi = require('node-wifi'); var fs = require('fs'); /** * Uses a recursive function for repeated scans, since scans are asynchronous. */ function record(n, completion, hook) { wifi.init({ iface : null // network interface, choose a random wifi interface if set to null }); samples = [] function startScan(i) { wifi.scan(function(err, networks) { if (err || networks.length == 0) { startScan(i); return } if (i <= 0) { return completion({samples: samples}); } hook(n-i+1, networks); samples.push(networks); startScan(i-1); }); } startScan(n); } function cli() { record(1, function(data) { fs.writeFile('samples.json', JSON.stringify(data), 'utf8', function() {}); }, function(i, networks) { console.log(" * [INFO] Collected sample " + i + " with " + networks.length + " networks"); }) } cli();Guardar y Salir. Ejecute el script.
node scripts/observe.jsSu salida coincidirá con lo siguiente, con números variables de redes.
* [INFO] Collected sample 1 with 39 networks Examine las muestras que se acaban de recolectar. Diríjase a json_pp para imprimir el JSON y diríjase a head para ver las primeras 16 líneas.
cat samples.json | json_pp | head -16El siguiente es un ejemplo de salida para una red de 2,4 GHz.
{ "samples": [ [ { "mac": "64:0f:28:79:9a:29", "bssid": "64:0f:28:79:9a:29", "ssid": "SMASHINGMAGAZINEROCKS", "channel": 4, "frequency": 2427, "signal_level": "-91", "security": "WPA WPA2", "security_flags": [ "(PSK/AES,TKIP/TKIP)", "(PSK/AES,TKIP/TKIP)" ] },Esto concluye su secuencia de comandos de escaneo wifi de NodeJS. Esto nos permite ver todas las redes WiFi dentro del alcance. En el siguiente paso, hará que este script sea accesible desde la aplicación de escritorio.
Paso 3: conecte el script de escaneo a la aplicación de escritorio
En este paso, primero agregará un botón a la aplicación de escritorio para activar el script. Luego, actualizará la interfaz de usuario de la aplicación de escritorio con el progreso del script.
Abra static/index.html .
nano static/index.htmlInserte el botón "Agregar", como se muestra a continuación.
<h1 class="title">(I dunno)</h1> <!-- start new code --> <div class="buttons"> <a href="add.html" class="button">Add new room</a> </div> <!-- end new code --> </main> Guardar y Salir. Abra static/add.html .
nano static/add.htmlPegue el siguiente contenido.
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>Riot | Add New Room</title> <link href="https://fonts.googleapis.com/css?family=Montserrat:400,700" rel="stylesheet"> <link href="style.css" rel="stylesheet"> </head> <body> <main> <h1 class="title">0</h1> <p class="subtitle">of <span>20</span> samples needed. Feel free to move around the room.</p> <input type="text" class="text-field" placeholder="(room name)"> <div class="buttons"> <a href="#" class="button">Start recording</a> <a href="index.html" class="button light">Cancel</a> </div> <p class="text"></p> </main> <script> require('../scripts/observe.js') </script> </body> </html> Guardar y Salir. Vuelva a abrir scripts/observe.js .
nano scripts/observe.js Debajo de la función cli , defina una nueva función ui .
function cli() { ... } // start new code function ui() { } // end new code cli();Actualice el estado de la aplicación de escritorio para indicar que la función ha comenzado a ejecutarse.
function ui() { var room_name = document.querySelector('#add-room-name').value; var status = document.querySelector('#add-status'); var number = document.querySelector('#add-title'); status.style.display = "block" status.innerHTML = "Listening for wifi..." }Divida los datos en conjuntos de datos de entrenamiento y validación.
function ui() { ... function completion(data) { train_data = {samples: data['samples'].slice(0, 15)} test_data = {samples: data['samples'].slice(15)} var train_json = JSON.stringify(train_data); var test_json = JSON.stringify(test_data); } } Todavía dentro de la devolución de llamada de completion , escriba ambos conjuntos de datos en el disco.
function ui() { ... function completion(data) { ... fs.writeFile('data/' + room_name + '_train.json', train_json, 'utf8', function() {}); fs.writeFile('data/' + room_name + '_test.json', test_json, 'utf8', function() {}); console.log(" * [INFO] Done") status.innerHTML = "Done." } } Invoque el record con las devoluciones de llamada apropiadas para grabar 20 muestras y guardar las muestras en el disco.
function ui() { ... function completion(data) { ... } record(20, completion, function(i, networks) { number.innerHTML = i console.log(" * [INFO] Collected sample " + i + " with " + networks.length + " networks") }) } Finalmente, invoque las funciones cli y ui cuando corresponda. Comience por eliminar el cli(); llamada en la parte inferior del archivo.
function ui() { ... } cli(); // remove me Compruebe si el objeto del documento es accesible globalmente. De lo contrario, el script se ejecuta desde la línea de comandos. En este caso, invoque la función cli . Si es así, el script se carga desde la aplicación de escritorio. En este caso, vincule el detector de clics a la función ui .
if (typeof document == 'undefined') { cli(); } else { document.querySelector('#start-recording').addEventListener('click', ui) }Guardar y Salir. Crear un directorio para almacenar nuestros datos.
mkdir dataInicie la aplicación de escritorio.
npm startVerá la siguiente página de inicio. Haga clic en "Agregar habitación".
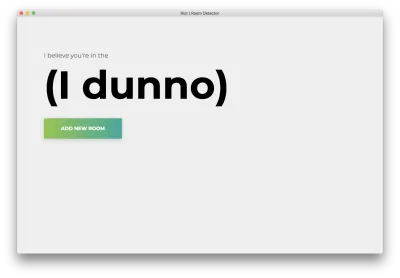
Verá el siguiente formulario. Escribe un nombre para la habitación. Recuerde este nombre, ya que lo usaremos más adelante. Nuestro ejemplo será bedroom .
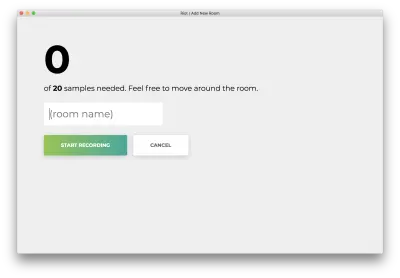
Haga clic en "Iniciar grabación" y verá el siguiente estado "Escuchando wifi...".
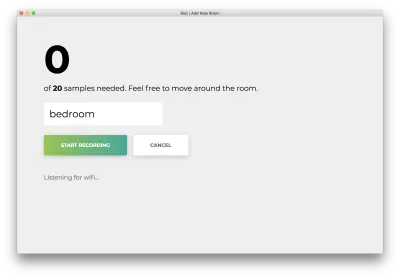
Una vez que se hayan registrado las 20 muestras, su aplicación coincidirá con lo siguiente. El estado será "Terminado".

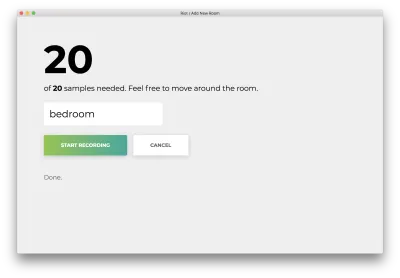
Haga clic en el mal llamado "Cancelar" para volver a la página de inicio, que coincide con la siguiente.
Ahora podemos escanear redes wifi desde la interfaz de usuario del escritorio, lo que guardará todas las muestras grabadas en archivos en el disco. A continuación, entrenaremos un algoritmo de aprendizaje automático listo para usar: mínimos cuadrados con los datos que ha recopilado.
Paso 4: Escriba el script de entrenamiento de Python
En este paso, escribiremos un script de entrenamiento en Python. Crea un directorio para tus utilidades de entrenamiento.
mkdir model Abrir model/train.py
nano model/train.py En la parte superior de su archivo, importe la biblioteca computacional numpy y scipy para su modelo de mínimos cuadrados.
import numpy as np from scipy.linalg import lstsq import json import sysLas siguientes tres utilidades manejarán la carga y configuración de datos de los archivos en el disco. Comience agregando una función de utilidad que aplana las listas anidadas. Usará esto para aplanar una lista de listas de muestras.
import sys def flatten(list_of_lists): """Flatten a list of lists to make a list. >>> flatten([[1], [2], [3, 4]]) [1, 2, 3, 4] """ return sum(list_of_lists, []) Agregue una segunda utilidad que cargue muestras de los archivos especificados. Este método abstrae el hecho de que las muestras se distribuyen en varios archivos y devuelve un único generador para todas las muestras. Para cada una de las muestras, la etiqueta es el índice del archivo. por ejemplo, si llama a get_all_samples('a.json', 'b.json') , todas las muestras en a.json tendrán la etiqueta 0 y todas las muestras en b.json tendrán la etiqueta 1.
def get_all_samples(paths): """Load all samples from JSON files.""" for label, path in enumerate(paths): with open(path) as f: for sample in json.load(f)['samples']: signal_levels = [ network['signal_level'].replace('RSSI', '') or 0 for network in sample] yield [network['mac'] for network in sample], signal_levels, labelA continuación, agregue una utilidad que codifique las muestras usando un modelo tipo bolsa de palabras. Aquí hay un ejemplo: supongamos que recolectamos dos muestras.
- red wifi A con fuerza 10 y red wifi B con fuerza 15
- red wifi B con fuerza 20 y red wifi C con fuerza 25.
Esta función producirá una lista de tres números para cada una de las muestras: el primer valor es la potencia de la red wifi A, el segundo para la red B y el tercero para C. En efecto, el formato es [A, B, C ].
- [10, 15, 0]
- [0, 20, 25]
def bag_of_words(all_networks, all_strengths, ordering): """Apply bag-of-words encoding to categorical variables. >>> samples = bag_of_words( ... [['a', 'b'], ['b', 'c'], ['a', 'c']], ... [[1, 2], [2, 3], [1, 3]], ... ['a', 'b', 'c']) >>> next(samples) [1, 2, 0] >>> next(samples) [0, 2, 3] """ for networks, strengths in zip(all_networks, all_strengths): yield [strengths[networks.index(network)] if network in networks else 0 for network in ordering] Usando las tres utilidades anteriores, sintetizamos una colección de muestras y sus etiquetas. Reúna todas las muestras y etiquetas usando get_all_samples . Defina un ordering de formato consistente para codificar one-hot todas las muestras, luego aplique la codificación one_hot a las muestras. Finalmente, construya las matrices de datos y etiquetas X e Y respectivamente.
def create_dataset(classpaths, ordering=None): """Create dataset from a list of paths to JSON files.""" networks, strengths, labels = zip(*get_all_samples(classpaths)) if ordering is None: ordering = list(sorted(set(flatten(networks)))) X = np.array(list(bag_of_words(networks, strengths, ordering))).astype(np.float64) Y = np.array(list(labels)).astype(np.int) return X, Y, orderingEstas funciones completan la canalización de datos. A continuación, abstraemos la predicción y evaluación del modelo. Comience por definir el método de predicción. La primera función normaliza los resultados de nuestro modelo, de modo que la suma de todos los valores sume 1 y todos los valores no sean negativos; esto asegura que la salida sea una distribución de probabilidad válida. El segundo evalúa el modelo.
def softmax(x): """Convert one-hotted outputs into probability distribution""" x = np.exp(x) return x / np.sum(x) def predict(X, w): """Predict using model parameters""" return np.argmax(softmax(X.dot(w)), axis=1)A continuación, evalúe la precisión del modelo. La primera línea ejecuta la predicción utilizando el modelo. El segundo cuenta el número de veces que concuerdan tanto los valores predichos como los verdaderos, luego se normaliza por el número total de muestras.
def evaluate(X, Y, w): """Evaluate model w on samples X and labels Y.""" Y_pred = predict(X, w) accuracy = (Y == Y_pred).sum() / X.shape[0] return accuracy Esto concluye nuestras utilidades de predicción y evaluación. Después de estas utilidades, defina una función main que recopilará el conjunto de datos, entrenará y evaluará. Comience leyendo la lista de argumentos de la línea de comando sys.argv ; estas son las salas a incluir en el entrenamiento. Luego, cree un gran conjunto de datos de todas las habitaciones especificadas.
def main(): classes = sys.argv[1:] train_paths = sorted(['data/{}_train.json'.format(name) for name in classes]) test_paths = sorted(['data/{}_test.json'.format(name) for name in classes]) X_train, Y_train, ordering = create_dataset(train_paths) X_test, Y_test, _ = create_dataset(test_paths, ordering=ordering)Aplicar codificación one-hot a las etiquetas. Una codificación one-hot es similar al modelo anterior de bolsa de palabras; usamos esta codificación para manejar variables categóricas. Digamos que tenemos 3 etiquetas posibles. En lugar de etiquetar 1, 2 o 3, etiquetamos los datos con [1, 0, 0], [0, 1, 0] o [0, 0, 1]. Para este tutorial, nos ahorraremos la explicación de por qué es importante la codificación one-hot. Entrene el modelo y evalúe tanto en el tren como en los conjuntos de validación.
def main(): ... X_test, Y_test, _ = create_dataset(test_paths, ordering=ordering) Y_train_oh = np.eye(len(classes))[Y_train] w, _, _, _ = lstsq(X_train, Y_train_oh) train_accuracy = evaluate(X_train, Y_train, w) test_accuracy = evaluate(X_test, Y_test, w)Imprima ambas precisiones y guarde el modelo en el disco.
def main(): ... print('Train accuracy ({}%), Validation accuracy ({}%)'.format(train_accuracy*100, test_accuracy*100)) np.save('w.npy', w) np.save('ordering.npy', np.array(ordering)) sys.stdout.flush() Al final del archivo, ejecute la función main .
if __name__ == '__main__': main()Guardar y Salir. Vuelva a verificar que su archivo coincida con lo siguiente:
import numpy as np from scipy.linalg import lstsq import json import sys def flatten(list_of_lists): """Flatten a list of lists to make a list. >>> flatten([[1], [2], [3, 4]]) [1, 2, 3, 4] """ return sum(list_of_lists, []) def get_all_samples(paths): """Load all samples from JSON files.""" for label, path in enumerate(paths): with open(path) as f: for sample in json.load(f)['samples']: signal_levels = [ network['signal_level'].replace('RSSI', '') or 0 for network in sample] yield [network['mac'] for network in sample], signal_levels, label def bag_of_words(all_networks, all_strengths, ordering): """Apply bag-of-words encoding to categorical variables. >>> samples = bag_of_words( ... [['a', 'b'], ['b', 'c'], ['a', 'c']], ... [[1, 2], [2, 3], [1, 3]], ... ['a', 'b', 'c']) >>> next(samples) [1, 2, 0] >>> next(samples) [0, 2, 3] """ for networks, strengths in zip(all_networks, all_strengths): yield [int(strengths[networks.index(network)]) if network in networks else 0 for network in ordering] def create_dataset(classpaths, ordering=None): """Create dataset from a list of paths to JSON files.""" networks, strengths, labels = zip(*get_all_samples(classpaths)) if ordering is None: ordering = list(sorted(set(flatten(networks)))) X = np.array(list(bag_of_words(networks, strengths, ordering))).astype(np.float64) Y = np.array(list(labels)).astype(np.int) return X, Y, ordering def softmax(x): """Convert one-hotted outputs into probability distribution""" x = np.exp(x) return x / np.sum(x) def predict(X, w): """Predict using model parameters""" return np.argmax(softmax(X.dot(w)), axis=1) def evaluate(X, Y, w): """Evaluate model w on samples X and labels Y.""" Y_pred = predict(X, w) accuracy = (Y == Y_pred).sum() / X.shape[0] return accuracy def main(): classes = sys.argv[1:] train_paths = sorted(['data/{}_train.json'.format(name) for name in classes]) test_paths = sorted(['data/{}_test.json'.format(name) for name in classes]) X_train, Y_train, ordering = create_dataset(train_paths) X_test, Y_test, _ = create_dataset(test_paths, ordering=ordering) Y_train_oh = np.eye(len(classes))[Y_train] w, _, _, _ = lstsq(X_train, Y_train_oh) train_accuracy = evaluate(X_train, Y_train, w) validation_accuracy = evaluate(X_test, Y_test, w) print('Train accuracy ({}%), Validation accuracy ({}%)'.format(train_accuracy*100, validation_accuracy*100)) np.save('w.npy', w) np.save('ordering.npy', np.array(ordering)) sys.stdout.flush() if __name__ == '__main__': main() Guardar y Salir. Recuerde el nombre de la sala que se usó anteriormente al grabar las 20 muestras. Use ese nombre en lugar de bedroom a continuación. Nuestro ejemplo es bedroom . Usamos -W ignore para ignorar las advertencias de un error LAPACK.
python -W ignore model/train.py bedroomDado que solo hemos recopilado muestras de capacitación para una sala, debería ver una precisión de capacitación y validación del 100 %.
Train accuracy (100.0%), Validation accuracy (100.0%)A continuación, vincularemos este script de capacitación a la aplicación de escritorio.
Paso 5: secuencia de comandos de enlace de tren
En este paso, volveremos a entrenar automáticamente el modelo cada vez que el usuario recopile un nuevo lote de muestras. Abra scripts/observe.js .
nano scripts/observe.js Inmediatamente después de la importación de fs , importe el generador de procesos secundarios y las utilidades.
var fs = require('fs'); // start new code const spawn = require("child_process").spawn; var utils = require('./utils.js'); En la función ui , agregue la siguiente llamada para volver a retrain al final del controlador de finalización.
function ui() { ... function completion() { ... retrain((data) => { var status = document.querySelector('#add-status'); accuracies = data.toString().split('\n')[0]; status.innerHTML = "Retraining succeeded: " + accuracies }); } ... } Después de la función ui , agregue la siguiente función de retrain . Esto genera un proceso secundario que ejecutará el script de python. Al finalizar, el proceso llama a un controlador de finalización. Si falla, registrará el mensaje de error.
function ui() { .. } function retrain(completion) { var filenames = utils.get_filenames() const pythonProcess = spawn('python', ["./model/train.py"].concat(filenames)); pythonProcess.stdout.on('data', completion); pythonProcess.stderr.on('data', (data) => { console.log(" * [ERROR] " + data.toString()) }) } Guardar y Salir. Abra scripts/utils.js .
nano scripts/utils.js Agregue la siguiente utilidad para obtener todos los conjuntos de datos en data/ .
var fs = require('fs'); module.exports = { get_filenames: get_filenames } function get_filenames() { filenames = new Set([]); fs.readdirSync("data/").forEach(function(filename) { filenames.add(filename.replace('_train', '').replace('_test', '').replace('.json', '' )) }); filenames = Array.from(filenames.values()) filenames.sort(); filenames.splice(filenames.indexOf('.DS_Store'), 1) return filenames }Guardar y Salir. Para la conclusión de este paso, muévase físicamente a una nueva ubicación. Idealmente, debería haber un muro entre su ubicación original y su nueva ubicación. Cuantas más barreras, mejor funcionará su aplicación de escritorio.
Una vez más, ejecute su aplicación de escritorio.
npm startAl igual que antes, ejecute el script de entrenamiento. Haga clic en "Agregar habitación".
Escriba un nombre de habitación que sea diferente al de su primera habitación. Usaremos la living room .
Haga clic en "Iniciar grabación" y verá el siguiente estado "Escuchando wifi...".
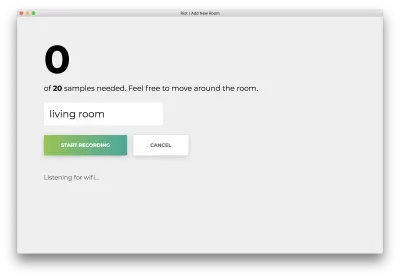
Una vez que se hayan registrado las 20 muestras, su aplicación coincidirá con lo siguiente. El estado será "Terminado. Modelo de reentrenamiento…”
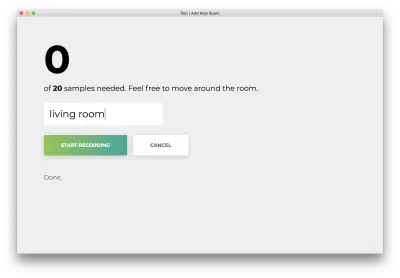
En el próximo paso, usaremos este modelo reentrenado para predecir la habitación en la que se encuentra, sobre la marcha.
Paso 6: Escriba el script de evaluación de Python
En este paso, cargaremos los parámetros del modelo previamente entrenados, buscaremos redes wifi y predeciremos la habitación según el escaneo.
Abra model/eval.py .
nano model/eval.pyImportar bibliotecas usadas y definidas en nuestro último script.
import numpy as np import sys import json import os import json from train import predict from train import softmax from train import create_dataset from train import evaluate Defina una utilidad para extraer los nombres de todos los conjuntos de datos. Esta función asume que todos los conjuntos de datos se almacenan en data/ como <dataset>_train.json y <dataset>_test.json .
from train import evaluate def get_datasets(): """Extract dataset names.""" return sorted(list({path.split('_')[0] for path in os.listdir('./data') if '.DS' not in path})) Defina la función main y comience cargando los parámetros guardados desde el script de entrenamiento.
def get_datasets(): ... def main(): w = np.load('w.npy') ordering = np.load('ordering.npy')Crear el conjunto de datos y predecir.
def main(): ... classpaths = [sys.argv[1]] X, _, _ = create_dataset(classpaths, ordering) y = np.asscalar(predict(X, w))Calcule una puntuación de confianza basada en la diferencia entre las dos probabilidades principales.
def main(): ... sorted_y = sorted(softmax(X.dot(w)).flatten()) confidence = 1 if len(sorted_y) > 1: confidence = round(sorted_y[-1] - sorted_y[-2], 2) Finalmente, extraiga la categoría e imprima el resultado. Para concluir el script, invoque la función main .
def main() ... category = get_datasets()[y] print(json.dumps({"category": category, "confidence": confidence})) if __name__ == '__main__': main()Guardar y Salir. Vuelva a verificar que su código coincida con el siguiente (código fuente):
import numpy as np import sys import json import os import json from train import predict from train import softmax from train import create_dataset from train import evaluate def get_datasets(): """Extract dataset names.""" return sorted(list({path.split('_')[0] for path in os.listdir('./data') if '.DS' not in path})) def main(): w = np.load('w.npy') ordering = np.load('ordering.npy') classpaths = [sys.argv[1]] X, _, _ = create_dataset(classpaths, ordering) y = np.asscalar(predict(X, w)) sorted_y = sorted(softmax(X.dot(w)).flatten()) confidence = 1 if len(sorted_y) > 1: confidence = round(sorted_y[-1] - sorted_y[-2], 2) category = get_datasets()[y] print(json.dumps({"category": category, "confidence": confidence})) if __name__ == '__main__': main()A continuación, conectaremos este script de evaluación a la aplicación de escritorio. La aplicación de escritorio ejecutará escaneos wifi de forma continua y actualizará la interfaz de usuario con la habitación prevista.
Paso 7: Conecte la evaluación a la aplicación de escritorio
En este paso, actualizaremos la interfaz de usuario con una pantalla de "confianza". Luego, el script de NodeJS asociado ejecutará continuamente escaneos y predicciones, actualizando la interfaz de usuario en consecuencia.
Abra static/index.html .
nano static/index.htmlAgregue una línea de confianza justo después del título y antes de los botones.
<h1 class="title">(I dunno)</h1> <!-- start new code --> <p class="subtitle">with <span>0%</span> confidence</p> <!-- end new code --> <div class="buttons"> Justo después de main pero antes del final del body , agregue un nuevo script predict.js .
</main> <!-- start new code --> <script> require('../scripts/predict.js') </script> <!-- end new code --> </body> Guardar y Salir. Abra scripts/predict.js .
nano scripts/predict.jsImporte las utilidades de NodeJS necesarias para el sistema de archivos, las utilidades y el generador de procesos secundarios.
var fs = require('fs'); var utils = require('./utils'); const spawn = require("child_process").spawn; Defina una función de predict que invoque un proceso de nodo separado para detectar redes wifi y un proceso de Python separado para predecir la sala.
function predict(completion) { const nodeProcess = spawn('node', ["scripts/observe.js"]); const pythonProcess = spawn('python', ["-W", "ignore", "./model/eval.py", "samples.json"]); }Después de que se hayan generado ambos procesos, agregue devoluciones de llamada al proceso de Python tanto para los éxitos como para los errores. La devolución de llamada exitosa registra información, invoca la devolución de llamada de finalización y actualiza la interfaz de usuario con la predicción y la confianza. La devolución de llamada de error registra el error.
function predict(completion) { ... pythonProcess.stdout.on('data', (data) => { information = JSON.parse(data.toString()); console.log(" * [INFO] Room '" + information.category + "' with confidence '" + information.confidence + "'") completion() if (typeof document != "undefined") { document.querySelector('#predicted-room-name').innerHTML = information.category document.querySelector('#predicted-confidence').innerHTML = information.confidence } }); pythonProcess.stderr.on('data', (data) => { console.log(data.toString()); }) } Defina una función principal para invocar la función de predict de forma recursiva, para siempre.
function main() { f = function() { predict(f) } predict(f) } main();Por última vez, abra la aplicación de escritorio para ver la predicción en vivo.
npm startAproximadamente cada segundo, se completará un escaneo y la interfaz se actualizará con la última confianza y la habitación prevista. Felicidades; Ha completado un detector de habitación simple basado en todas las redes WiFi dentro del alcance.
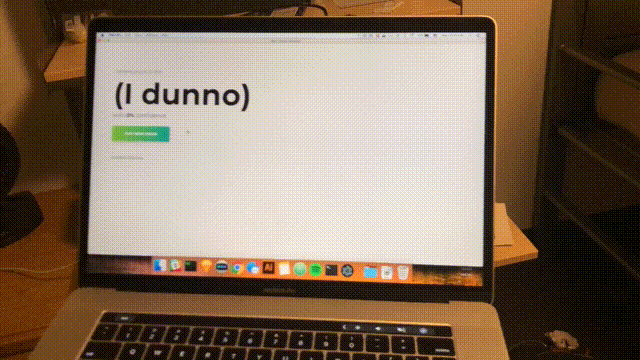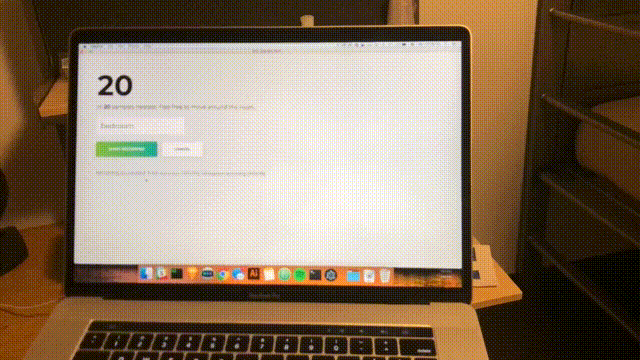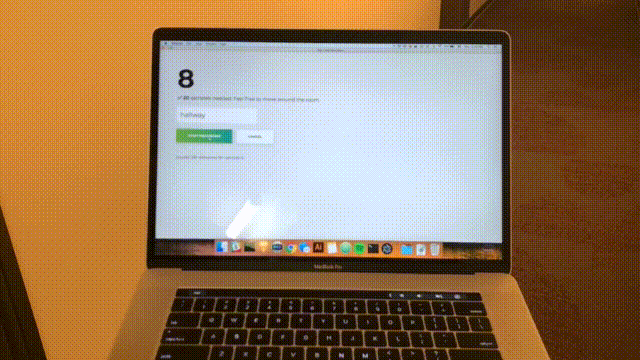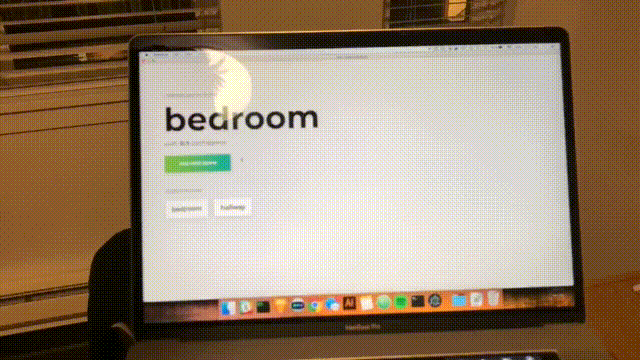
Conclusión
En este tutorial, creamos una solución utilizando solo su escritorio para detectar su ubicación dentro de un edificio. Creamos una aplicación de escritorio simple usando Electron JS y aplicamos un método de aprendizaje automático simple en todas las redes WiFi dentro del alcance. Esto allana el camino para las aplicaciones de Internet de las cosas sin la necesidad de conjuntos de dispositivos que son costosos de mantener (costo no en términos de dinero sino en términos de tiempo y desarrollo).
Nota : Puede ver el código fuente en su totalidad en Github.
Con el tiempo, es posible que descubra que estos mínimos cuadrados no funcionan espectacularmente. Intente encontrar dos ubicaciones dentro de una sola habitación o párese en las puertas. Los mínimos cuadrados serán grandes y no podrán distinguir entre casos extremos. ¿Podemos hacerlo mejor? Resulta que podemos, y en lecciones futuras, aprovecharemos otras técnicas y los fundamentos del aprendizaje automático para mejorar el rendimiento. Este tutorial sirve como un banco de pruebas rápido para los próximos experimentos.