
Creación de un servicio de registro central interno
Publicado: 2022-03-10Todos sabemos lo importante que es la depuración para mejorar el rendimiento y las características de las aplicaciones. ¡BrowserStack ejecuta un millón de sesiones al día en una pila de aplicaciones altamente distribuida! Cada uno involucra varias partes móviles, ya que la sesión única de un cliente puede abarcar múltiples componentes en varias regiones geográficas.
Sin el marco y las herramientas adecuados, el proceso de depuración puede ser una pesadilla. En nuestro caso, necesitábamos una forma de recopilar eventos que sucedieran durante las diferentes etapas de cada proceso para obtener una comprensión profunda de todo lo que sucede durante una sesión. Con nuestra infraestructura, resolver este problema se volvió complicado ya que cada componente podría tener múltiples eventos de su ciclo de vida de procesamiento de una solicitud.
Es por eso que desarrollamos nuestra propia herramienta interna de Servicio de registro central (CLS) para registrar todos los eventos importantes registrados durante una sesión. Estos eventos ayudan a nuestros desarrolladores a identificar las condiciones en las que algo sale mal en una sesión y ayudan a realizar un seguimiento de ciertas métricas clave del producto.
Los datos de depuración van desde cosas simples como la latencia de respuesta de la API hasta el monitoreo del estado de la red de un usuario. En este artículo, compartimos nuestra historia de creación de nuestra herramienta CLS que recopila 70 G de datos cronológicos relevantes por día de más de 100 componentes de manera confiable, a escala y con dos instancias EC2 M3.large.
La decisión de construir internamente
Primero, consideremos por qué construimos nuestra herramienta CLS internamente en lugar de usar una solución existente. Cada una de nuestras sesiones envía 15 eventos en promedio, desde múltiples componentes al servicio, lo que se traduce en aproximadamente 15 millones de eventos en total por día.
Nuestro servicio necesitaba la capacidad de almacenar todos estos datos. Buscamos una solución completa para respaldar el almacenamiento, el envío y la consulta de eventos entre eventos. Como consideramos soluciones de terceros como Amplitude y Keen, nuestras métricas de evaluación incluyeron el costo, el rendimiento en el manejo de solicitudes paralelas altas y la facilidad de adopción. Desafortunadamente, no pudimos encontrar uno que cumpliera con todos nuestros requisitos dentro del presupuesto, aunque los beneficios habrían incluido el ahorro de tiempo y la minimización de alertas. Si bien requeriría un esfuerzo adicional, decidimos desarrollar una solución interna nosotros mismos.

Detalles técnicos
En términos de arquitectura para nuestro componente, describimos los siguientes requisitos básicos:
- Rendimiento del cliente
No afecta el rendimiento del cliente/componente que envía los eventos. - Escala
Capaz de manejar una gran cantidad de solicitudes en paralelo. - El rendimiento del servicio
Rápido para procesar todos los eventos que se le envían. - Información sobre los datos
Cada evento registrado debe tener cierta metainformación para poder identificar de forma única el componente o usuario, la cuenta o el mensaje y brindar más información para ayudar al desarrollador a depurar más rápido. - Interfaz consultable
Los desarrolladores pueden consultar todos los eventos de una sesión en particular, lo que ayuda a depurar una sesión en particular, crear informes de estado de componentes o generar estadísticas de rendimiento significativas de nuestros sistemas. - Adopción más rápida y sencilla
Fácil integración con un componente existente o nuevo sin sobrecargar a los equipos ni consumir sus recursos. - Bajo mantenimiento
Somos un pequeño equipo de ingeniería, por lo que buscamos una solución para minimizar las alertas.
Construyendo nuestra solución CLS
Decisión 1: elegir una interfaz para exponer
Al desarrollar CLS, obviamente no queríamos perder ninguno de nuestros datos, pero tampoco queríamos que el rendimiento de los componentes se viera afectado. Sin mencionar el factor adicional de evitar que los componentes existentes se vuelvan más complicados, ya que retrasaría la adopción y el lanzamiento general. Al determinar nuestra interfaz, consideramos las siguientes opciones:
- Almacenamiento de eventos en Redis local en cada componente, ya que un procesador en segundo plano lo envía a CLS. Sin embargo, esto requiere un cambio en todos los componentes, junto con la introducción de Redis para los componentes que aún no lo contenían.
- Un modelo de publicador - suscriptor, donde Redis está más cerca del CLS. Como todos publican eventos, nuevamente tenemos el factor de los componentes que se ejecutan en todo el mundo. Durante el tiempo de mucho tráfico, esto retrasaría los componentes. Además, esta escritura podría saltar intermitentemente hasta cinco segundos (solo debido a Internet).
- Envío de eventos sobre UDP, lo que ofrece un menor impacto en el rendimiento de la aplicación. En este caso, los datos se enviarían y se olvidarían, sin embargo, la desventaja aquí sería la pérdida de datos.
Curiosamente, nuestra pérdida de datos sobre UDP fue inferior al 0,1 por ciento, que era una cantidad aceptable para que consideráramos la creación de dicho servicio. Pudimos convencer a todos los equipos de que esta cantidad de pérdida valía la pena y seguimos adelante para aprovechar una interfaz UDP que escuchaba todos los eventos que se enviaban.
Si bien un resultado fue un impacto menor en el rendimiento de una aplicación, enfrentamos un problema ya que el tráfico UDP no estaba permitido desde todas las redes, principalmente de nuestros usuarios, lo que provocó que en algunos casos no recibiéramos ningún dato. Como solución temporal, admitimos el registro de eventos mediante solicitudes HTTP. Todos los eventos provenientes del lado del usuario se enviarían a través de HTTP, mientras que todos los eventos registrados desde nuestros componentes se enviarían a través de UDP.
Decisión 2: Tech Stack (Idioma, marco y almacenamiento)
Somos una tienda Ruby. Sin embargo, no estábamos seguros de si Ruby sería una mejor opción para nuestro problema en particular. Nuestro servicio tendría que manejar muchas solicitudes entrantes, así como procesar muchas escrituras. Con el bloqueo de Global Interpreter, sería difícil lograr subprocesos múltiples o simultaneidad en Ruby (no se ofenda, ¡nos encanta Ruby!). Así que necesitábamos una solución que nos ayudara a lograr este tipo de concurrencia.
También estábamos ansiosos por evaluar un nuevo lenguaje en nuestra pila tecnológica, y este proyecto parecía perfecto para experimentar con cosas nuevas. Fue entonces cuando decidimos darle una oportunidad a Golang, ya que ofrecía soporte incorporado para la concurrencia y subprocesos ligeros y rutinas. Cada punto de datos registrado se asemeja a un par clave-valor donde 'clave' es el evento y 'valor' sirve como su valor asociado.
Pero tener una clave y un valor simples no es suficiente para recuperar los datos relacionados con una sesión: hay más metadatos. Para abordar esto, decidimos que cualquier evento que deba registrarse tendría una ID de sesión junto con su clave y valor. También agregamos campos adicionales como marca de tiempo, ID de usuario y el componente que registra los datos, para que sea más fácil obtener y analizar datos.

Ahora que decidimos nuestra estructura de carga útil, teníamos que elegir nuestro almacén de datos. Consideramos Elastic Search, pero también queríamos admitir solicitudes de actualización de claves. Esto provocaría que todo el documento se vuelva a indexar, lo que podría afectar el rendimiento de nuestras escrituras. MongoDB tenía más sentido como almacén de datos, ya que sería más fácil consultar todos los eventos en función de cualquiera de los campos de datos que se agregarían. ¡Esto fue fácil!
Decisión 3: ¡El tamaño de la base de datos es enorme y la consulta y el archivo apesta!
Para reducir el mantenimiento, nuestro servicio tendría que manejar tantos eventos como sea posible. Dado el ritmo con el que BrowserStack lanza funciones y productos, estábamos seguros de que la cantidad de nuestros eventos aumentaría a un ritmo mayor con el tiempo, lo que significa que nuestro servicio tendría que seguir funcionando bien. A medida que aumenta el espacio, las lecturas y escrituras toman más tiempo, lo que podría ser un gran impacto en el rendimiento del servicio.
La primera solución que exploramos fue mover los registros de un cierto período fuera de la base de datos (en nuestro caso, decidimos 15 días). Para hacer esto, creamos una base de datos diferente para cada día, lo que nos permite encontrar registros anteriores a un período en particular sin tener que escanear todos los documentos escritos. Ahora eliminamos continuamente las bases de datos con más de 15 días de Mongo y, por supuesto, mantenemos copias de seguridad por si acaso.
La única pieza sobrante fue una interfaz de desarrollador para consultar datos relacionados con la sesión. Honestamente, este fue el problema más fácil de resolver. Proporcionamos una interfaz HTTP, donde las personas pueden consultar eventos relacionados con la sesión en la base de datos correspondiente en MongoDB, para cualquier dato que tenga una ID de sesión particular.
Arquitectura
Hablemos de los componentes internos del servicio, considerando los siguientes puntos:
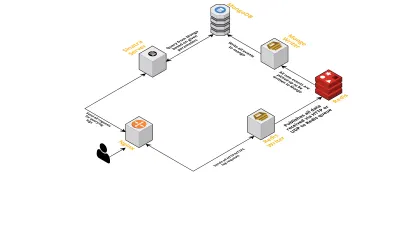
- Como se discutió anteriormente, necesitábamos dos interfaces: una escuchando sobre UDP y otra escuchando sobre HTTP. Entonces construimos dos servidores, nuevamente uno para cada interfaz, para escuchar eventos. Tan pronto como llega un evento, lo analizamos para verificar si tiene los campos obligatorios: ID de sesión, clave y valor. Si no es así, los datos se eliminan. De lo contrario, los datos se pasan a través de un canal Go a otra gorutina, cuya única responsabilidad es escribir en MongoDB.
- Una posible preocupación aquí es escribir en MongoDB. Si las escrituras en MongoDB son más lentas que la tasa de recepción de datos, esto crea un cuello de botella. Esto, a su vez, priva a otros eventos entrantes y significa datos perdidos. El servidor, por lo tanto, debe ser rápido en el procesamiento de registros entrantes y estar listo para procesar los próximos. Para solucionar el problema, dividimos el servidor en dos partes: la primera recibe todos los eventos y los pone en cola para la segunda, que los procesa y los escribe en MongoDB.
- Para hacer cola elegimos Redis. Al dividir todo el componente en estas dos partes, redujimos la carga de trabajo del servidor, dándole espacio para manejar más registros.
- Escribimos un pequeño servicio usando el servidor Sinatra para manejar todo el trabajo de consultar MongoDB con parámetros dados. Devuelve una respuesta HTML/JSON a los desarrolladores cuando necesitan información sobre una sesión en particular.
Todos estos procesos se ejecutan felizmente en una sola instancia de m3.large .
Peticiones de características
A medida que nuestra herramienta CLS vio más uso con el tiempo, necesitaba más funciones. A continuación, discutimos estos y cómo se agregaron.
Metadatos faltantes
Gradualmente, a medida que aumenta la cantidad de componentes en BrowserStack, exigimos más de CLS. Por ejemplo, necesitábamos la capacidad de registrar eventos de componentes que carecían de ID de sesión. De lo contrario, obtener uno sobrecargaría nuestra infraestructura, ya que afectaría el rendimiento de la aplicación e incurriría en tráfico en nuestros servidores principales.
Abordamos esto habilitando el registro de eventos usando otras claves, como ID de terminal y de usuario. Ahora, cada vez que se crea o actualiza una sesión, se informa a CLS con el ID de la sesión, así como los respectivos ID de usuario y terminal. Almacena un mapa que se puede recuperar mediante el proceso de escritura en MongoDB. Cada vez que se recupera un evento que contiene el ID del usuario o del terminal, se agrega el ID de la sesión.
Manejar el spam (problemas de código en otros componentes)
CLS también enfrentó las dificultades habituales con el manejo de eventos de spam. A menudo encontramos implementaciones en componentes que generaron un gran volumen de solicitudes enviadas a CLS. Otros registros sufrirían en el proceso, ya que el servidor estaba demasiado ocupado para procesarlos y se descartaban registros importantes.
En su mayor parte, la mayoría de los datos registrados se realizaron a través de solicitudes HTTP. Para controlarlos, habilitamos la limitación de velocidad en nginx (usando el módulo limit_req_zone), que bloquea las solicitudes de cualquier IP que encontremos solicitando más de un cierto número en una pequeña cantidad de tiempo. Por supuesto, aprovechamos los informes de salud en todas las IP bloqueadas e informamos a los equipos responsables.
escala v2
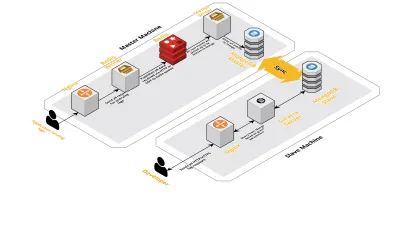
A medida que aumentaban nuestras sesiones diarias, también aumentaban los datos que se registraban en CLS. Esto afectó las consultas que nuestros desarrolladores ejecutaban a diario, y pronto el cuello de botella que tuvimos fue con la propia máquina. Nuestra configuración constaba de dos máquinas centrales que ejecutaban todos los componentes anteriores, junto con un montón de scripts para consultar a Mongo y realizar un seguimiento de las métricas clave de cada producto. Con el tiempo, los datos en la máquina aumentaron considerablemente y los scripts comenzaron a consumir mucho tiempo de CPU. Incluso después de intentar optimizar las consultas de Mongo, siempre volvíamos a los mismos problemas.
Para resolver esto, agregamos otra máquina para ejecutar scripts de informes de salud y la interfaz para consultar estas sesiones. El proceso implicó iniciar una nueva máquina y configurar un esclavo de Mongo que se ejecuta en la máquina principal. Esto ha ayudado a reducir los picos de CPU que vimos todos los días causados por estos scripts.
Conclusión
Crear un servicio para una tarea tan simple como el registro de datos puede complicarse a medida que aumenta la cantidad de datos. Este artículo analiza las soluciones que exploramos, junto con los desafíos que enfrentamos al resolver este problema. Experimentamos con Golang para ver qué tan bien encajaría con nuestro ecosistema y, hasta ahora, estamos satisfechos. Nuestra elección de crear un servicio interno en lugar de pagar por uno externo ha sido maravillosamente rentable. Tampoco tuvimos que escalar nuestra configuración a otra máquina hasta mucho más tarde, cuando aumentó el volumen de nuestras sesiones. Por supuesto, nuestras elecciones en el desarrollo de CLS se basaron completamente en nuestros requisitos y prioridades.
Hoy, CLS maneja hasta 15 millones de eventos todos los días, lo que constituye hasta 70 GB de datos. Estos datos se utilizan para ayudarnos a resolver cualquier problema que enfrenten nuestros clientes durante cualquier sesión. También utilizamos estos datos para otros fines. Dada la información que brindan los datos de cada sesión sobre diferentes productos y componentes internos, hemos comenzado a aprovechar estos datos para realizar un seguimiento de cada producto. Esto se logra extrayendo las métricas clave para todos los componentes importantes.
En general, hemos visto un gran éxito en la creación de nuestra propia herramienta CLS. Si tiene sentido para ti, ¡te recomiendo que consideres hacer lo mismo!