
Cómo construir un raspador de productos de Amazon con Node.js
Publicado: 2022-03-10¿Alguna vez ha estado en una posición en la que necesita conocer íntimamente el mercado de un producto en particular? Tal vez esté lanzando algún software y necesite saber cómo ponerle precio. O tal vez ya tenga su propio producto en el mercado y quiera ver qué funciones agregar para obtener una ventaja competitiva. O tal vez solo quiera comprar algo para usted y quiera asegurarse de obtener el mejor valor por su dinero.
Todas estas situaciones tienen una cosa en común: necesitas datos precisos para tomar la decisión correcta . En realidad, hay otra cosa que comparten. Todos los escenarios pueden beneficiarse del uso de un raspador web.
El raspado web es la práctica de extraer grandes cantidades de datos web mediante el uso de software. Entonces, en esencia, es una forma de automatizar el tedioso proceso de presionar 'copiar' y luego 'pegar' 200 veces. Por supuesto, un bot puede hacer eso en el tiempo que le tomó leer esta oración, por lo que no solo es menos aburrido sino también mucho más rápido.
Pero la pregunta candente es: ¿por qué alguien querría raspar las páginas de Amazon?
¡Estás a punto de descubrirlo! Pero antes que nada, me gustaría dejar algo en claro en este momento: si bien el acto de extraer datos disponibles públicamente es legal, Amazon tiene algunas medidas para evitarlo en sus páginas. Como tal, le insto a que siempre tenga en cuenta el sitio web mientras raspa, tenga cuidado de no dañarlo y siga las pautas éticas.
Lectura recomendada : "La guía para el raspado ético de sitios web dinámicos con Node.js y Puppeteer" por Andreas Altheimer
Por qué debería extraer datos de productos de Amazon
Siendo el minorista en línea más grande del planeta, es seguro decir que si desea comprar algo, probablemente pueda obtenerlo en Amazon. Por lo tanto, no hace falta decir cuán grande es el tesoro de datos del sitio web.
Al raspar la web, su pregunta principal debería ser qué hacer con todos esos datos. Si bien hay muchas razones individuales, se reduce a dos casos de uso destacados: optimizar sus productos y encontrar las mejores ofertas.
“
Comencemos con el primer escenario. A menos que haya diseñado un nuevo producto verdaderamente innovador, lo más probable es que ya pueda encontrar algo al menos similar en Amazon. Raspar esas páginas de productos puede generarle datos invaluables como:
- La estrategia de precios de los competidores.
Por lo tanto, puede ajustar sus precios para ser competitivos y comprender cómo otros manejan las ofertas promocionales; - Opiniones de clientes
Para ver qué es lo que más le importa a su futura base de clientes y cómo mejorar su experiencia; - Características más comunes
Para ver qué ofrece tu competencia para saber qué funcionalidades son cruciales y cuáles se pueden dejar para más adelante.
En esencia, Amazon tiene todo lo que necesita para un análisis profundo del mercado y del producto. Estará mejor preparado para diseñar, lanzar y expandir su línea de productos con esos datos.
El segundo escenario puede aplicarse tanto a empresas como a personas normales. La idea es bastante similar a lo que mencioné anteriormente. Puede raspar los precios, las características y las reseñas de todos los productos que puede elegir y, por lo tanto, podrá elegir el que ofrece la mayor cantidad de beneficios por el precio más bajo. Después de todo, ¿a quién no le gustan las buenas ofertas?
No todos los productos merecen este nivel de atención al detalle, pero puede marcar una gran diferencia con compras caras. Desafortunadamente, si bien los beneficios son claros, muchas dificultades acompañan el raspado de Amazon.
Los desafíos de extraer datos de productos de Amazon
No todos los sitios web son iguales. Como regla general, cuanto más complejo y extendido es un sitio web, más difícil es rasparlo. ¿Recuerdas cuando dije que Amazon era el sitio de comercio electrónico más destacado? Bueno, eso lo hace extremadamente popular y razonablemente complejo.
En primer lugar, Amazon sabe cómo actúan los bots de raspado, por lo que el sitio web tiene contramedidas. Es decir, si el raspador sigue un patrón predecible, enviando solicitudes a intervalos fijos, más rápido de lo que podría hacerlo un humano o con parámetros casi idénticos, Amazon lo notará y bloqueará la IP. Los proxies pueden resolver este problema, pero no los necesitaba ya que no eliminaremos demasiadas páginas en el ejemplo.
A continuación, Amazon utiliza deliberadamente estructuras de página variables para sus productos. Es decir, si inspecciona las páginas en busca de diferentes productos, es muy probable que encuentre diferencias significativas en su estructura y atributos. La razón detrás de esto es bastante simple. Debe adaptar el código de su raspador para un sistema específico , y si usa el mismo script en un nuevo tipo de página, tendrá que volver a escribir partes de él. Entonces, esencialmente te hacen trabajar más para los datos.
Por último, Amazon es un gran sitio web. Si desea recopilar grandes cantidades de datos, ejecutar el software de raspado en su computadora puede llevar demasiado tiempo para sus necesidades. Este problema se consolida aún más por el hecho de que ir demasiado rápido bloqueará el raspador. Entonces, si desea una gran cantidad de datos rápidamente, necesitará un raspador verdaderamente poderoso.
Bueno, basta de hablar de problemas, ¡centrémonos en las soluciones!
Cómo construir un raspador web para Amazon
Para mantener las cosas simples, tomaremos un enfoque paso a paso para escribir el código. Siéntase libre de trabajar en paralelo con la guía.
Busca los datos que necesitamos
Entonces, aquí hay un escenario: me mudaré en unos meses a un lugar nuevo y necesitaré un par de estantes nuevos para guardar libros y revistas. Quiero conocer todas mis opciones y conseguir el mejor trato posible. Entonces, vayamos al mercado de Amazon, busquemos "estantes" y veamos qué obtenemos.
La URL para esta búsqueda y la página que rasparemos está aquí.
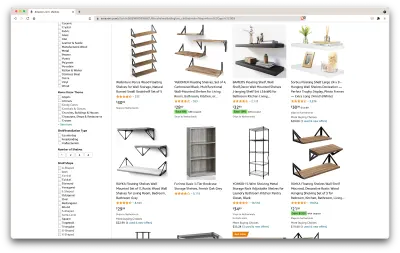
Bien, hagamos un balance de lo que tenemos aquí. Con solo echar un vistazo a la página, podemos obtener una buena imagen de:
- cómo se ven los estantes;
- qué incluye el paquete;
- cómo los califican los clientes;
- su precio;
- el enlace al producto;
- una sugerencia de una alternativa más barata para algunos de los artículos.
¡Eso es más de lo que podríamos pedir!
Consigue las herramientas necesarias
Asegurémonos de tener todas las siguientes herramientas instaladas y configuradas antes de continuar con el siguiente paso.
- Cromo
Podemos descargarlo desde aquí. - Código VSC
Siga las instrucciones de esta página para instalarlo en su dispositivo específico. - Nodo.js
Antes de comenzar a usar Axios o Cheerio, debemos instalar Node.js y Node Package Manager. La forma más fácil de instalar Node.js y NPM es obtener uno de los instaladores de la fuente oficial de Node.Js y ejecutarlo.
Ahora, creemos un nuevo proyecto NPM. Cree una nueva carpeta para el proyecto y ejecute el siguiente comando:
npm init -yPara crear el web scraper, necesitamos instalar un par de dependencias en nuestro proyecto:
- Cheerio
Una biblioteca de código abierto que nos ayuda a extraer información útil analizando el marcado y proporcionando una API para manipular los datos resultantes. Cheerio nos permite seleccionar etiquetas de un documento HTML usando selectores:$("div"). Este selector específico nos ayuda a elegir todos los elementos<div>en una página. Para instalar Cheerio, ejecute el siguiente comando en la carpeta de proyectos:
npm install cheerio- Axios
Una biblioteca de JavaScript utilizada para realizar solicitudes HTTP desde Node.js.
npm install axiosInspeccionar la fuente de la página
En los siguientes pasos, aprenderemos más sobre cómo se organiza la información en la página. La idea es obtener una mejor comprensión de lo que podemos extraer de nuestra fuente.
Las herramientas para desarrolladores nos ayudan a explorar de forma interactiva el modelo de objeto del documento (DOM) del sitio web. Usaremos las herramientas para desarrolladores en Chrome, pero puede usar cualquier navegador web con el que se sienta cómodo.
Vamos a abrirlo haciendo clic derecho en cualquier parte de la página y seleccionando la opción "Inspeccionar":
Esto abrirá una nueva ventana que contiene el código fuente de la página. Como hemos dicho antes, buscamos raspar la información de cada estante.
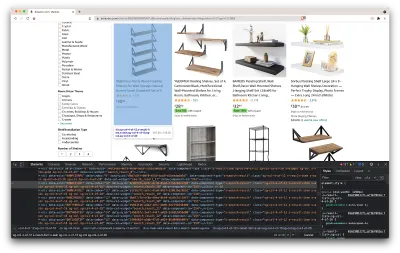
Como podemos ver en la captura de pantalla anterior, los contenedores que contienen todos los datos tienen las siguientes clases:
sg-col-4-of-12 s-result-item s-asin sg-col-4-of-16 sg-col sg-col-4-of-20En el siguiente paso, usaremos Cheerio para seleccionar todos los elementos que contengan los datos que necesitamos.

Obtener los datos
Después de instalar todas las dependencias presentadas anteriormente, creemos un nuevo archivo index.js y escribamos las siguientes líneas de código:
const axios = require("axios"); const cheerio = require("cheerio"); const fetchShelves = async () => { try { const response = await axios.get('https://www.amazon.com/s?crid=36QNR0DBY6M7J&k=shelves&ref=glow_cls&refresh=1&sprefix=s%2Caps%2C309'); const html = response.data; const $ = cheerio.load(html); const shelves = []; $('div.sg-col-4-of-12.s-result-item.s-asin.sg-col-4-of-16.sg-col.sg-col-4-of-20').each((_idx, el) => { const shelf = $(el) const title = shelf.find('span.a-size-base-plus.a-color-base.a-text-normal').text() shelves.push(title) }); return shelves; } catch (error) { throw error; } }; fetchShelves().then((shelves) => console.log(shelves)); Como podemos ver, importamos las dependencias que necesitamos en las dos primeras líneas, y luego creamos una función fetchShelves() que, usando Cheerio, obtiene todos los elementos que contienen la información de nuestros productos de la página.
Itera sobre cada uno de ellos y lo empuja a una matriz vacía para obtener un resultado con mejor formato.
La función fetchShelves() solo devolverá el título del producto en este momento, así que obtengamos el resto de la información que necesitamos. Agregue las siguientes líneas de código después de la línea donde definimos el title de la variable.
const image = shelf.find('img.s-image').attr('src') const link = shelf.find('aa-link-normal.a-text-normal').attr('href') const reviews = shelf.find('div.a-section.a-spacing-none.a-spacing-top-micro > div.a-row.a-size-small').children('span').last().attr('aria-label') const stars = shelf.find('div.a-section.a-spacing-none.a-spacing-top-micro > div > span').attr('aria-label') const price = shelf.find('span.a-price > span.a-offscreen').text() let element = { title, image, link: `https://amazon.com${link}`, price, } if (reviews) { element.reviews = reviews } if (stars) { element.stars = stars } Y reemplace shelves.push(title) con shelves.push(element) .
Ahora estamos seleccionando toda la información que necesitamos y agregándola a un nuevo objeto llamado element . Luego, cada elemento se envía a la matriz de shelves para obtener una lista de objetos que contienen solo los datos que estamos buscando.
Así es como debería verse un objeto de shelf antes de agregarlo a nuestra lista:
{ title: 'SUPERJARE Wall Mounted Shelves, Set of 2, Display Ledge, Storage Rack for Room/Kitchen/Office - White', image: 'https://m.media-amazon.com/images/I/61fTtaQNPnL._AC_UL320_.jpg', link: 'https://amazon.com/gp/slredirect/picassoRedirect.html/ref=pa_sp_btf_aps_sr_pg1_1?ie=UTF8&adId=A03078372WABZ8V6NFP9L&url=%2FSUPERJARE-Mounted-Floating-Shelves-Display%2Fdp%2FB07H4NRT36%2Fref%3Dsr_1_59_sspa%3Fcrid%3D36QNR0DBY6M7J%26dchild%3D1%26keywords%3Dshelves%26qid%3D1627970918%26refresh%3D1%26sprefix%3Ds%252Caps%252C309%26sr%3D8-59-spons%26psc%3D1&qualifier=1627970918&id=3373422987100422&widgetName=sp_btf', price: '$32.99', reviews: '6,171', stars: '4.7 out of 5 stars' }Formatear los datos
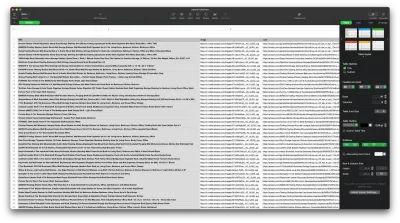
Ahora que logramos obtener los datos que necesitamos, es una buena idea guardarlos como un archivo .CSV para mejorar la legibilidad. Después de obtener todos los datos, usaremos el módulo fs proporcionado por Node.js y guardaremos un nuevo archivo llamado saved-shelves.csv en la carpeta del proyecto. Importe el módulo fs en la parte superior del archivo y copie o escriba las siguientes líneas de código:
let csvContent = shelves.map(element => { return Object.values(element).map(item => `"${item}"`).join(',') }).join("\n") fs.writeFile('saved-shelves.csv', "Title, Image, Link, Price, Reviews, Stars" + '\n' + csvContent, 'utf8', function (err) { if (err) { console.log('Some error occurred - file either not saved or corrupted.') } else{ console.log('File has been saved!') } }) Como podemos ver, en las primeras tres líneas, formateamos los datos que hemos recopilado previamente al unir todos los valores de un objeto de estantería usando una coma. Luego, usando el módulo fs , creamos un archivo llamado saved-shelves.csv , agregamos una nueva fila que contiene los encabezados de columna, agregamos los datos que acabamos de formatear y creamos una función de devolución de llamada que maneja los errores.
El resultado debería ser algo como esto:
¡Consejos adicionales!
Raspado de aplicaciones de una sola página
El contenido dinámico se está convirtiendo en el estándar hoy en día, ya que los sitios web son más complejos que nunca. Para brindar la mejor experiencia de usuario posible, los desarrolladores deben adoptar diferentes mecanismos de carga para el contenido dinámico , lo que complica un poco más nuestro trabajo. Si no sabe lo que eso significa, imagine un navegador sin una interfaz gráfica de usuario. Afortunadamente, existe Puppeteer, la biblioteca mágica de nodos que proporciona una API de alto nivel para controlar una instancia de Chrome a través del protocolo DevTools. Aún así, ofrece la misma funcionalidad que un navegador, pero debe controlarse mediante programación escribiendo un par de líneas de código. Veamos cómo funciona eso.
En el proyecto creado anteriormente, instale la biblioteca Puppeteer ejecutando npm install puppeteer , cree un nuevo archivo puppeteer.js y copie o escriba las siguientes líneas de código:
const puppeteer = require('puppeteer') (async () => { try { const chrome = await puppeteer.launch() const page = await chrome.newPage() await page.goto('https://www.reddit.com/r/Kanye/hot/') await page.waitForSelector('.rpBJOHq2PR60pnwJlUyP0', { timeout: 2000 }) const body = await page.evaluate(() => { return document.querySelector('body').innerHTML }) console.log(body) await chrome.close() } catch (error) { console.log(error) } })() En el ejemplo anterior, creamos una instancia de Chrome y abrimos una nueva página del navegador que se requiere para ir a este enlace. En la siguiente línea, le decimos al navegador sin cabeza que espere hasta que el elemento con la clase rpBJOHq2PR60pnwJlUyP0 aparezca en la página. También hemos especificado cuánto tiempo debe esperar el navegador para que se cargue la página (2000 milisegundos).
Usando el método de evaluate en la variable de la page , le indicamos a Titiritero que ejecutara los fragmentos de Javascript dentro del contexto de la página justo después de que finalmente se cargara el elemento. Esto nos permitirá acceder al contenido HTML de la página y devolver el cuerpo de la página como salida. Luego cerramos la instancia de Chrome llamando al método de close en la variable de chrome . El trabajo resultante debe consistir en todo el código HTML generado dinámicamente. Así es como Puppeteer puede ayudarnos a cargar contenido HTML dinámico .
Si no se siente cómodo usando Puppeteer, tenga en cuenta que existen un par de alternativas, como NightwatchJS, NightmareJS o CasperJS. Son ligeramente diferentes, pero al final, el proceso es bastante similar.
Configuración de encabezados user-agent
user-agent es un encabezado de solicitud que le informa al sitio web que está visitando sobre usted, es decir, su navegador y sistema operativo. Esto se usa para optimizar el contenido para su configuración, pero los sitios web también lo usan para identificar bots que envían toneladas de solicitudes, incluso si cambia el IPS.
Así es como se ve un encabezado user-agent :
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36En aras de no ser detectado y bloqueado, debe cambiar periódicamente este encabezado. Tenga mucho cuidado de no enviar un encabezado vacío u obsoleto, ya que esto nunca debería suceder para un usuario común y corriente, y se destacará.
Limitación de velocidad
Los rastreadores web pueden recopilar contenido extremadamente rápido, pero debe evitar ir a la máxima velocidad. Hay dos razones para esto:
- Demasiadas solicitudes en poco tiempo pueden ralentizar el servidor del sitio web o incluso deshabilitarlo, causando problemas para el propietario y otros visitantes. Esencialmente, puede convertirse en un ataque DoS.
- Sin proxies rotativos, es como anunciar en voz alta que está utilizando un bot, ya que ningún ser humano enviaría cientos o miles de solicitudes por segundo.
La solución es introducir un retraso entre sus solicitudes, una práctica llamada "limitación de velocidad". ( ¡También es bastante simple de implementar! )
En el ejemplo de Puppeteer proporcionado anteriormente, antes de crear la variable del body , podemos usar el método waitForTimeout proporcionado por Puppeteer para esperar un par de segundos antes de realizar otra solicitud:
await page.waitForTimeout(3000); Donde ms es el número de segundos que le gustaría esperar.
Además, si quisiéramos hacer lo mismo para el ejemplo de axios, podemos crear una promesa que llame al método setTimeout() , para ayudarnos a esperar el número deseado de milisegundos:
fetchShelves.then(result => new Promise(resolve => setTimeout(() => resolve(result), 3000)))De esta manera, puede evitar ejercer demasiada presión sobre el servidor de destino y también aportar un enfoque más humano al web scraping.
Pensamientos finales
¡Y ahí lo tiene, una guía paso a paso para crear su propio web scraper para los datos de productos de Amazon! Pero recuerda, esta fue solo una situación. Si desea raspar un sitio web diferente, tendrá que hacer algunos ajustes para obtener resultados significativos.
Lectura relacionada
Si aún desea ver más web scraping en acción, aquí hay material de lectura útil para usted:
- "La guía definitiva para raspado web con JavaScript y Node.Js", Robert Sfichi
- “Raspado web avanzado de Node.JS con Titiritero”, Gabriel Cioci
- "Python Web Scraping: la guía definitiva para construir su raspador", Raluca Penciuc