
Cree una aplicación de marcadores con FaunaDB, Netlify y 11ty
Publicado: 2022-03-10La revolución JAMstack (JavaScript, API y Markup) está en pleno apogeo. Los sitios estáticos son seguros, rápidos, confiables y divertidos para trabajar. En el corazón de JAMstack se encuentran los generadores de sitios estáticos (SSG) que almacenan sus datos como archivos planos: Markdown, YAML, JSON, HTML, etc. A veces, administrar datos de esta manera puede ser demasiado complicado. A veces, todavía necesitamos una base de datos.
Con eso en mente, Netlify, un host de sitio estático y FaunaDB, una base de datos en la nube sin servidor, colaboraron para facilitar la combinación de ambos sistemas.
¿Por qué un sitio de marcadores?
El JAMstack es excelente para muchos usos profesionales, pero uno de mis aspectos favoritos de este conjunto de tecnología es su baja barrera de entrada para herramientas y proyectos personales.
Hay muchos buenos productos en el mercado para la mayoría de las aplicaciones que se me ocurren, pero ninguno estaría exactamente configurado para mí. Ninguno me daría control total sobre mi contenido. Ninguno vendría sin un costo (monetario o informativo).
Con eso en mente, podemos crear nuestros propios miniservicios usando métodos JAMstack. En este caso, crearemos un sitio para almacenar y publicar cualquier artículo interesante que encuentre en mi lectura diaria de tecnología.
Paso mucho tiempo leyendo artículos que se han compartido en Twitter. Cuando me gusta uno, presiono el ícono del "corazón". Luego, en unos pocos días, es casi imposible encontrarlo con la afluencia de nuevos favoritos. Quiero construir algo lo más cercano a la comodidad del "corazón", pero que poseo y controlo.
¿Cómo vamos a hacer eso? Me alegra que hayas preguntado.
¿Interesado en obtener el código? ¡Puede obtenerlo en Github o simplemente implementarlo directamente en Netlify desde ese repositorio! Echa un vistazo al producto terminado aquí.
Nuestras Tecnologías
Hosting y funciones sin servidor: Netlify
Para las funciones de alojamiento y sin servidor, utilizaremos Netlify. Como beneficio adicional, con la nueva colaboración mencionada anteriormente, la CLI de Netlify, "Netlify Dev", se conectará automáticamente a FaunaDB y almacenará nuestras claves API como variables de entorno.
Base de datos: FaunaDB
FaunaDB es una base de datos NoSQL "sin servidor". Lo usaremos para almacenar nuestros datos de marcadores.
Generador de sitio estático: 11ty
Soy un gran creyente en HTML. Debido a esto, el tutorial no usará JavaScript front-end para representar nuestros marcadores. En su lugar, utilizaremos 11ty como generador de sitios estáticos. 11ty tiene una funcionalidad de datos incorporada que hace que obtener datos de una API sea tan fácil como escribir un par de funciones breves de JavaScript.
Accesos directos de iOS
Necesitaremos una manera fácil de publicar datos en nuestra base de datos. En este caso, usaremos la aplicación de accesos directos de iOS. Esto también podría convertirse en un bookmarklet de Android o JavaScript de escritorio.
Configuración de FaunaDB a través de Netlify Dev
Ya sea que ya se haya registrado en FaunaDB o necesite crear una nueva cuenta, la forma más fácil de configurar un enlace entre FaunaDB y Netlify es a través de la CLI de Netlify: Netlify Dev. Puede encontrar instrucciones completas de FaunaDB aquí o seguirlas a continuación.
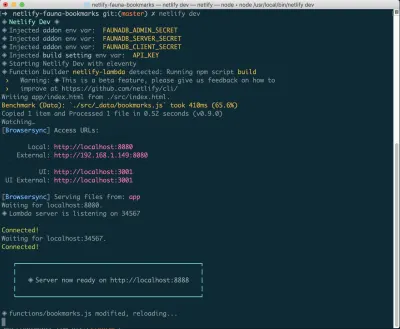
Si aún no lo tiene instalado, puede ejecutar el siguiente comando en la Terminal:
npm install netlify-cli -gDesde el directorio de su proyecto, ejecute los siguientes comandos:
netlify init // This will connect your project to a Netlify project netlify addons:create fauna // This will install the FaunaDB "addon" netlify addons:auth fauna // This command will run you through connecting your account or setting up an account Una vez que todo esté conectado, puede ejecutar netlify dev en su proyecto. Esto ejecutará cualquier script de compilación que configuremos, pero también se conectará a los servicios de Netlify y FaunaDB y tomará las variables de entorno necesarias. ¡Práctico!
Creando nuestros primeros datos
Desde aquí, iniciaremos sesión en FaunaDB y crearemos nuestro primer conjunto de datos. Comenzaremos creando una nueva base de datos llamada "marcadores". Dentro de una Base de Datos tenemos Colecciones, Documentos e Índices.
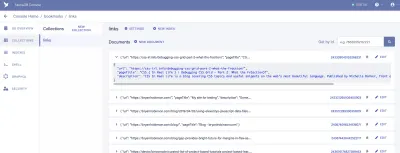
Una colección es un grupo categorizado de datos. Cada dato toma la forma de un Documento. Un documento es un "registro único y modificable dentro de una base de datos FaunaDB", según la documentación de Fauna. Puede pensar en Colecciones como una tabla de base de datos tradicional y un Documento como una fila.
Para nuestra aplicación, necesitamos una Colección, a la que llamaremos "enlaces". Cada documento dentro de la colección de "enlaces" será un objeto JSON simple con tres propiedades. Para comenzar, agregaremos un nuevo Documento que usaremos para construir nuestra primera obtención de datos.
{ "url": "https://css-irl.info/debugging-css-grid-part-2-what-the-fraction/", "pageTitle": "CSS { In Real Life } | Debugging CSS Grid – Part 2: What the Fr(action)?", "description": "CSS In Real Life is a blog covering CSS topics and useful snippets on the web's most beautiful language. Published by Michelle Barker, front end developer at Ordoo and CSS superfan." }Esto crea la base para la información que necesitaremos extraer de nuestros marcadores y nos proporciona nuestro primer conjunto de datos para incluir en nuestra plantilla.
Si eres como yo, querrás ver los frutos de tu trabajo de inmediato. ¡Pongamos algo en la página!
Instalar 11ty y extraer datos en una plantilla
Dado que queremos que los marcadores se representen en HTML y que el navegador no los obtenga, necesitaremos algo para hacer la representación. Hay muchas maneras excelentes de hacerlo, pero por facilidad y potencia, me encanta usar el generador de sitios estáticos 11ty.
Dado que 11ty es un generador de sitios estáticos de JavaScript, podemos instalarlo a través de NPM.
npm install --save @11ty/eleventy A partir de esa instalación, podemos ejecutar once u eleventy --serve eleventy nuestro proyecto para ponernos en marcha.
Netlify Dev a menudo detectará 11ty como un requisito y ejecutará el comando por nosotros. Para que esto funcione, y asegurarnos de que estamos listos para implementar, también podemos crear comandos "servir" y "compilar" en nuestro package.json .
"scripts": { "build": "npx eleventy", "serve": "npx eleventy --serve" }Archivos de datos de 11ty
La mayoría de los generadores de sitios estáticos tienen una idea de un "archivo de datos" incorporado. Por lo general, estos archivos serán archivos JSON o YAML que le permitirán agregar información adicional a su sitio.
En 11ty, puede usar archivos de datos JSON o archivos de datos JavaScript. Al utilizar un archivo JavaScript, podemos realizar nuestras llamadas a la API y devolver los datos directamente a una plantilla.
De forma predeterminada, 11ty desea que los archivos de datos se almacenen en un directorio _data . A continuación, puede acceder a los datos utilizando el nombre del archivo como una variable en sus plantillas. En nuestro caso, crearemos un archivo en _data/bookmarks.js y accederemos a él a través del nombre de variable {{ bookmarks }} .
Si desea profundizar en la configuración de archivos de datos, puede leer ejemplos en la documentación de 11ty o consultar este tutorial sobre el uso de archivos de datos de 11ty con la API de Meetup.
El archivo será un módulo JavaScript. Entonces, para que algo funcione, necesitamos exportar nuestros datos o una función. En nuestro caso, exportaremos una función.
module.exports = async function() { const data = mapBookmarks(await getBookmarks()); return data.reverse() } Analicemos eso. Tenemos dos funciones haciendo nuestro trabajo principal aquí: mapBookmarks() y getBookmarks() .
La función getBookmarks() irá a buscar nuestros datos de nuestra base de datos FaunaDB y mapBookmarks() tomará una serie de marcadores y la reestructurará para que funcione mejor para nuestra plantilla.
Profundicemos más en getBookmarks() .
getBookmarks()
Primero, necesitaremos instalar e inicializar una instancia del controlador FaunaDB JavaScript.
npm install --save faunadbAhora que lo hemos instalado, agréguelo a la parte superior de nuestro archivo de datos. Este código es directamente de los documentos de Fauna.
// Requires the Fauna module and sets up the query module, which we can use to create custom queries. const faunadb = require('faunadb'), q = faunadb.query; // Once required, we need a new instance with our secret var adminClient = new faunadb.Client({ secret: process.env.FAUNADB_SERVER_SECRET }); Después de eso, podemos crear nuestra función. Comenzaremos creando nuestra primera consulta utilizando métodos integrados en el controlador. Este primer bit de código devolverá las referencias de la base de datos que podemos usar para obtener datos completos para todos nuestros enlaces marcados. Usamos el método Paginate , como ayuda para administrar el estado del cursor en caso de que decidamos paginar los datos antes de entregarlos a 11ty. En nuestro caso, solo devolveremos todas las referencias.
En este ejemplo, asumo que instaló y conectó FaunaDB a través de Netlify Dev CLI. Con este proceso, obtiene variables de entorno locales de los secretos de FaunaDB. Si no lo instaló de esta manera o no está ejecutando netlify dev en su proyecto, necesitará un paquete como dotenv para crear las variables de entorno. También deberá agregar sus variables de entorno a la configuración de su sitio de Netlify para que las implementaciones funcionen más adelante.
adminClient.query(q.Paginate( q.Match( // Match the reference below q.Ref("indexes/all_links") // Reference to match, in this case, our all_links index ) )) .then( response => { ... })Este código devolverá una matriz de todos nuestros enlaces en forma de referencia. Ahora podemos crear una lista de consultas para enviar a nuestra base de datos.
adminClient.query(...) .then((response) => { const linkRefs = response.data; // Get just the references for the links from the response const getAllLinksDataQuery = linkRefs.map((ref) => { return q.Get(ref) // Return a Get query based on the reference passed in }) return adminClient.query(getAllLinksDataQuery).then(ret => { return ret // Return an array of all the links with full data }) }).catch(...) A partir de aquí, solo tenemos que limpiar los datos devueltos. ¡Ahí es donde mapBookmarks() !
mapBookmarks()
En esta función, nos ocupamos de dos aspectos de los datos.
Primero, obtenemos un dateTime gratis en FaunaDB. Para cualquier dato creado, hay una propiedad de marca de tiempo ( ts ). No está formateado de una manera que haga feliz el filtro de fecha predeterminado de Liquid, así que arreglemos eso.
function mapBookmarks(data) { return data.map(bookmark => { const dateTime = new Date(bookmark.ts / 1000); ... }) } Con eso fuera del camino, podemos construir un nuevo objeto para nuestros datos. En este caso, tendrá una propiedad de time y usaremos el operador Spread para desestructurar nuestro objeto de data para que todos vivan en un nivel.
function mapBookmarks(data) { return data.map(bookmark => { const dateTime = new Date(bookmark.ts / 1000); return { time: dateTime, ...bookmark.data } }) }Aquí están nuestros datos antes de nuestra función:
{ ref: Ref(Collection("links"), "244778237839802888"), ts: 1569697568650000, data: { url: 'https://sample.com', pageTitle: 'Sample title', description: 'An escaped description goes here' } }Aquí están nuestros datos después de nuestra función:

{ time: 1569697568650, url: 'https://sample.com', pageTitle: 'Sample title' description: 'An escaped description goes here' }¡Ahora, tenemos datos bien formateados que están listos para nuestra plantilla!
Escribamos una plantilla simple. Recorreremos nuestros marcadores y pageTitle que cada uno tenga un título de página y una url para no parecer tontos.
<div class="bookmarks"> {% for link in bookmarks %} {% if link.url and link.pageTitle %} // confirms there's both title AND url for safety <div class="bookmark"> <h2><a href="{{ link.url }}">{{ link.pageTitle }}</a></h2> <p>Saved on {{ link.time | date: "%b %d, %Y" }}</p> {% if link.description != "" %} <p>{{ link.description }}</p> {% endif %} </div> {% endif %} {% endfor %} </div>Ahora estamos recopilando y mostrando datos de FaunaDB. ¡Tomemos un momento y pensemos en lo bueno que es que esto represente HTML puro y no hay necesidad de buscar datos en el lado del cliente!
Pero eso no es suficiente para hacer de esta una aplicación útil para nosotros. Averigüemos una mejor manera que agregar un marcador en la consola de FaunaDB.
Ingrese a las funciones de Netlify
El complemento Funciones de Netlify es una de las formas más sencillas de implementar las funciones de AWS lambda. Dado que no hay un paso de configuración, es perfecto para proyectos de bricolaje en los que solo desea escribir el código.
Esta función vivirá en una URL en su proyecto que se ve así: https://myproject.com/.netlify/functions/bookmarks suponiendo que el archivo que creamos en nuestra carpeta de funciones es bookmarks.js .
Flujo básico
- Pase una URL como parámetro de consulta a nuestra URL de función.
- Use la función para cargar la URL y extraiga el título y la descripción de la página, si están disponibles.
- Formatee los detalles para FaunaDB.
- Empuje los detalles a nuestra Colección FaunaDB.
- Reconstruir el sitio.
Requisitos
Tenemos algunos paquetes que necesitaremos a medida que construimos esto. Usaremos la CLI netlify-lambda para construir nuestras funciones localmente. request-promise es el paquete que usaremos para realizar solicitudes. Cheerio.js es el paquete que usaremos para raspar elementos específicos de nuestra página solicitada (piense en jQuery para Node). Y finalmente, necesitaremos FaunaDb (que ya debería estar instalado.
npm install --save netlify-lambda request-promise cheerioUna vez que esté instalado, configuremos nuestro proyecto para construir y servir las funciones localmente.
Modificaremos nuestros scripts de "construcción" y "servicio" en nuestro package.json para que se vean así:
"scripts": { "build": "npx netlify-lambda build lambda --config ./webpack.functions.js && npx eleventy", "serve": "npx netlify-lambda build lambda --config ./webpack.functions.js && npx eleventy --serve" } Advertencia: hay un error con el controlador NodeJS de Fauna al compilar con Webpack, que utilizan las funciones de Netlify para compilar. Para evitar esto, necesitamos definir un archivo de configuración para Webpack. Puede guardar el siguiente código en un webpack.config.js nuevo o existente .
const webpack = require('webpack'); module.exports = { plugins: [ new webpack.DefinePlugin({ "global.GENTLY": false }) ] }; Una vez que este archivo exista, cuando usemos el comando netlify-lambda , necesitaremos decirle que se ejecute desde esta configuración. Esta es la razón por la que nuestros scripts de "servicio" y "construcción" usan el valor --config para ese comando.
Función Limpieza
Para mantener nuestro archivo de función principal lo más limpio posible, crearemos nuestras funciones en un directorio de bookmarks separado y las importaremos a nuestro archivo de función principal.
import { getDetails, saveBookmark } from "./bookmarks/create"; getDetails(url)
La función getDetails() tomará una URL, pasada desde nuestro controlador exportado. A partir de ahí, nos comunicaremos con el sitio en esa URL y tomaremos las partes relevantes de la página para almacenarlas como datos para nuestro marcador.
Comenzamos requiriendo los paquetes NPM que necesitamos:
const rp = require('request-promise'); const cheerio = require('cheerio'); Luego, usaremos el módulo request-promise para devolver una cadena HTML para la página solicitada y pasarla a cheerio para brindarnos una interfaz muy similar a jQuery.
const getDetails = async function(url) { const data = rp(url).then(function(htmlString) { const $ = cheerio.load(htmlString); ... }Desde aquí, necesitamos obtener el título de la página y una meta descripción. Para hacer eso, usaremos selectores como lo haría en jQuery.
Nota: En este código, usamos 'head > title' como selector para obtener el título de la página. Si no especifica esto, puede terminar obteniendo etiquetas <title> dentro de todos los SVG en la página, lo cual es menos que ideal.
const getDetails = async function(url) { const data = rp(url).then(function(htmlString) { const $ = cheerio.load(htmlString); const title = $('head > title').text(); // Get the text inside the tag const description = $('meta[name="description"]').attr('content'); // Get the text of the content attribute // Return out the data in the structure we expect return { pageTitle: title, description: description }; }); return data //return to our main function }Con los datos disponibles, ¡es hora de enviar nuestro marcador a nuestra Colección en FaunaDB!
saveBookmark(details)
Para nuestra función de guardar, querremos pasar los detalles que adquirimos de getDetails así como la URL como un objeto singular. ¡El operador Spread ataca de nuevo!
const savedResponse = await saveBookmark({url, ...details}); En nuestro archivo create.js , también necesitamos solicitar y configurar nuestro controlador FaunaDB. Esto debería parecer muy familiar a partir de nuestro archivo de datos 11ty.
const faunadb = require('faunadb'), q = faunadb.query; const adminClient = new faunadb.Client({ secret: process.env.FAUNADB_SERVER_SECRET });Una vez que tengamos eso fuera del camino, podemos codificar.
Primero, necesitamos formatear nuestros detalles en una estructura de datos que Fauna espera para nuestra consulta. Fauna espera un objeto con una propiedad de datos que contenga los datos que deseamos almacenar.
const saveBookmark = async function(details) { const data = { data: details }; ... }Luego abriremos una nueva consulta para agregar a nuestra Colección. En este caso, usaremos nuestro asistente de consultas y usaremos el método Create. Create() toma dos argumentos. El primero es la Colección en la que queremos almacenar nuestros datos y el segundo son los datos en sí.
Después de guardar, devolvemos el éxito o el fracaso a nuestro controlador.
const saveBookmark = async function(details) { const data = { data: details }; return adminClient.query(q.Create(q.Collection("links"), data)) .then((response) => { /* Success! return the response with statusCode 200 */ return { statusCode: 200, body: JSON.stringify(response) } }).catch((error) => { /* Error! return the error with statusCode 400 */ return { statusCode: 400, body: JSON.stringify(error) } }) }Echemos un vistazo al archivo de función completo.
import { getDetails, saveBookmark } from "./bookmarks/create"; import { rebuildSite } from "./utilities/rebuild"; // For rebuilding the site (more on that in a minute) exports.handler = async function(event, context) { try { const url = event.queryStringParameters.url; // Grab the URL const details = await getDetails(url); // Get the details of the page const savedResponse = await saveBookmark({url, ...details}); //Save the URL and the details to Fauna if (savedResponse.statusCode === 200) { // If successful, return success and trigger a Netlify build await rebuildSite(); return { statusCode: 200, body: savedResponse.body } } else { return savedResponse //or else return the error } } catch (err) { return { statusCode: 500, body: `Error: ${err}` }; } }; rebuildSite()
El ojo perspicaz notará que tenemos una función más importada en nuestro controlador: rebuildSite() . Esta función usará la funcionalidad Deploy Hook de Netlify para reconstruir nuestro sitio a partir de los nuevos datos cada vez que enviemos un nuevo marcador guardado con éxito.
En la configuración de su sitio en Netlify, puede acceder a su configuración de Build & Deploy y crear un nuevo "Build Hook". Los ganchos tienen un nombre que aparece en la sección Implementar y una opción para implementar una rama no maestra si así lo desea. En nuestro caso, lo llamaremos "nuevo_enlace" e implementaremos nuestra rama principal.
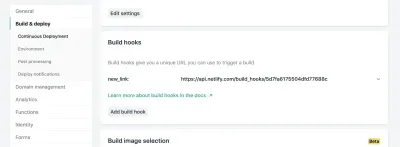
A partir de ahí, solo tenemos que enviar una solicitud POST a la URL proporcionada.
Necesitamos una forma de realizar solicitudes y, dado que ya instalamos request-promise , continuaremos usando ese paquete al solicitarlo en la parte superior de nuestro archivo.
const rp = require('request-promise'); const rebuildSite = async function() { var options = { method: 'POST', uri: 'https://api.netlify.com/build_hooks/5d7fa6175504dfd43377688c', body: {}, json: true }; const returned = await rp(options).then(function(res) { console.log('Successfully hit webhook', res); }).catch(function(err) { console.log('Error:', err); }); return returned } Configuración de un acceso directo de iOS
Entonces, tenemos una base de datos, una forma de mostrar datos y una función para agregar datos, pero aún no somos muy fáciles de usar.
Netlify proporciona direcciones URL para nuestras funciones de Lambda, pero no es divertido escribirlas en un dispositivo móvil. También tendríamos que pasarle una URL como parámetro de consulta. Eso es MUCHO esfuerzo. ¿Cómo podemos hacer esto con el menor esfuerzo posible?
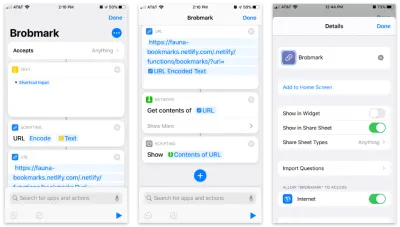
La aplicación Accesos directos de Apple permite la creación de elementos personalizados para incluirlos en su hoja para compartir. Dentro de estos accesos directos, podemos enviar varios tipos de solicitudes de datos recopilados en el proceso de compartir.
Aquí está el acceso directo paso a paso:
- Acepte cualquier artículo y guárdelo en un bloque de "texto".
- Pase ese texto a un bloque de "Scripting" para codificar URL (por si acaso).
- Pase esa cadena a un bloque de URL con la URL de nuestra función Netlify y un parámetro de consulta de
url. - Desde "Red", use un bloque "Obtener contenido" para POST a JSON a nuestra URL.
- Opcional: Desde “Scripting” “Mostrar” el contenido del último paso (para confirmar los datos que estamos enviando).
Para acceder a esto desde el menú para compartir, abrimos la configuración de este acceso directo y activamos la opción "Mostrar en hoja compartida".
A partir de iOS13, estas "acciones" compartidas se pueden marcar como favoritas y mover a una posición alta en el cuadro de diálogo.
¡Ahora tenemos una "aplicación" funcional para compartir marcadores en varias plataformas!
¡Hacer un esfuerzo adicional!
Si está inspirado para probar esto usted mismo, hay muchas otras posibilidades para agregar funcionalidad. La alegría de la web DIY es que puedes hacer que este tipo de aplicaciones funcionen para ti. Aqui hay algunas ideas:
- Use una "clave API" falsa para una autenticación rápida, de modo que otros usuarios no publiquen en su sitio (el mío usa una clave API, ¡así que no intente publicar en él!).
- Agregue la funcionalidad de etiquetas para organizar los marcadores.
- Agregue una fuente RSS para su sitio para que otros puedan suscribirse.
- Envíe un correo electrónico de resumen semanal mediante programación para los enlaces que ha agregado.
Realmente, el cielo es el límite, ¡así que comienza a experimentar!