
Distribución binomial en Python con ejemplos del mundo real [2022]
Publicado: 2021-01-09El valor de la probabilidad y las estadísticas en el campo de la ciencia de datos ha sido inmenso, y la inteligencia artificial y el aprendizaje automático dependen en gran medida de ellos. Usamos modelos de proceso de distribución normal cada vez que realizamos pruebas A/B y modelos de inversión.
Sin embargo, la distribución binomial en Python se aplica de múltiples formas para llevar a cabo varios procesos. Pero, antes de comenzar con la distribución binomial en Python , debe conocer la distribución binomial en general y su uso en la vida cotidiana. Si es un principiante y está interesado en obtener más información sobre la ciencia de datos, consulte nuestra capacitación en ciencia de datos de las mejores universidades.
Tabla de contenido
¿Qué es la Distribución Binomial ?
¿Alguna vez has lanzado una moneda? Si es así, entonces debe saber que la probabilidad de obtener cara o cruz es igual. Pero, ¿qué hay de la probabilidad de obtener siete cruces en un total de diez lanzamientos de una moneda? Aquí es donde la distribución binomial puede ayudar a calcular los resultados de cada lanzamiento y, por lo tanto, averiguar la probabilidad de obtener siete cruces en diez lanzamientos de una moneda.
El quid de la distribución de probabilidad proviene de la varianza de cualquier evento. Por cada conjunto de diez lanzamientos de monedas, la probabilidad de obtener cara y cruz puede ser entre una y diez veces, igualmente y probable. La incertidumbre en el resultado (también conocida como varianza) ayuda a generar la distribución de los resultados producidos.
En otras palabras, la distribución binomial es un proceso donde solo hay dos resultados posibles: verdadero o falso. Por lo tanto, tiene la misma probabilidad de ambos resultados en todos los eventos, ya que se realizan las mismas acciones cada vez. Solo hay una condición... Los pasos no deben verse afectados entre sí, y los resultados pueden o no ser igualmente probables.
Por tanto, la función de probabilidad de una distribución binomial es:
F F( k k , norte norte, pags ) = PAGS r Pr( k k; norte norte, pags ) = PAGS r Pr ( X X= k k) =
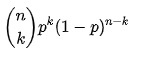
Fuente
Donde,
![]() = norte norte! k k !( n n! - k k!)
= norte norte! k k !( n n! - k k!)
Aquí, n = número total de ensayos
p = probabilidad de éxito
k = número objetivo de éxitos
Distribución Binomial en Python
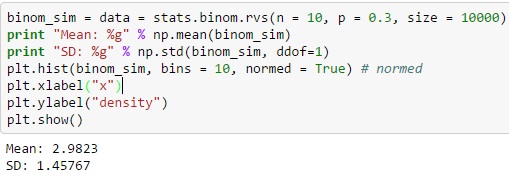
Para la distribución binomial a través de Python, puede producir la variable aleatoria distinta de la función binom.rvs (), donde 'n' se define como la frecuencia total de las pruebas y 'p' es igual a la probabilidad de éxito.
También puede mover la distribución usando la función loc, y el tamaño define la frecuencia de una acción que se repite en la serie. Agregar un estado aleatorio puede ayudar a mantener la reproducibilidad.
Fuente
Ejemplos del mundo real de distribución binomial en Python
Hay muchos más eventos (más grandes que los lanzamientos de monedas) que pueden abordarse mediante la distribución binomial en Python. Algunos de los casos de uso pueden ayudar a rastrear y mejorar el ROI (retorno de la inversión) para empresas grandes y pequeñas. Así es cómo:

- Piense en un centro de llamadas donde a cada empleado se le asignan 50 llamadas por día en promedio.
- La probabilidad de conversión sobre cada llamada es igual al 4%.
- La generación de ingresos promedio para la empresa basada en cada una de estas conversiones es de USD 20.
- Si analiza 100 de estos empleados, a quienes se les paga 200 USD por día, entonces
norte = 50
p = 4%
El código puede generar resultados de la siguiente manera:
- Tasa de conversión promedio para cada empleado = 2.13
- La desviación estándar de las conversiones para cada personal del centro de llamadas = 1.48
- Conversión bruta = 213
- Generación de ingresos brutos = USD 21 300
- Gasto bruto = USD 20,000
- Ganancias brutas = USD 1,300
Los modelos de distribución binomial y otras distribuciones de probabilidad solo pueden predecir una aproximación que puede acercarse al mundo real en términos de los parámetros de acción, 'n' y 'p'. Nos ayuda a comprender e identificar nuestras áreas de enfoque y mejorar las posibilidades generales de un mejor desempeño y efectividad.
Lea también: 13 interesantes ideas y temas de proyectos de estructura de datos para principiantes
¿Qué sigue?
Si tiene curiosidad por aprender sobre ciencia de datos, consulte el Programa ejecutivo PG en ciencia de datos de IIIT-B y upGrad, creado para profesionales que trabajan y ofrece más de 10 estudios de casos y proyectos, talleres prácticos, tutoría con expertos de la industria, 1 -on-1 con mentores de la industria, más de 400 horas de aprendizaje y asistencia laboral con las mejores empresas.
¿Cuál es la diferencia entre la distribución de probabilidad discreta y la distribución de probabilidad continua?
La distribución de probabilidad discreta o simplemente distribución discreta calcula las probabilidades de una variable aleatoria que puede ser discreta. Por ejemplo, si lanzamos una moneda dos veces, los valores probables de una variable aleatoria X que denota el número total de caras serán {0, 1, 2} y no cualquier valor aleatorio. Bernoulli, Binomial, Hypergeometric son algunos ejemplos de la distribución de probabilidad discreta. Por otro lado, la distribución de probabilidad continua proporciona las probabilidades de un valor aleatorio que puede ser cualquier número aleatorio. Por ejemplo, el valor de una variable aleatoria X que denota la altura de los ciudadanos de una ciudad podría ser cualquier número como 161,2, 150,9, etc. Normal, T de Student, Chi-cuadrado son algunos de los ejemplos de distribución continua.
¿Cuál es la importancia de la probabilidad en la ciencia de datos?
Como la ciencia de datos se trata de estudiar datos, la probabilidad juega un papel clave aquí. Las siguientes razones describen cómo la probabilidad es una parte indispensable de la ciencia de datos: ayuda a los analistas e investigadores a hacer predicciones a partir de conjuntos de datos. Este tipo de resultados estimados son la base para un análisis posterior de los datos. La probabilidad también se utiliza al desarrollar algoritmos utilizados en modelos de aprendizaje automático. Ayuda a analizar los conjuntos de datos utilizados para entrenar los modelos. Le permite cuantificar datos y derivar resultados como derivados, media y distribución. Todos los resultados obtenidos usando probabilidad finalmente resumen los datos. Este resumen también ayuda en la identificación de valores atípicos existentes en los conjuntos de datos.
Explique la distribución hipergeométrica. ¿En qué caso tiende a ser una distribución binomial?
éxitos sobre el número de ensayos sin ningún reemplazo. Digamos que tenemos una bolsa llena de bolas rojas y verdes y tenemos que encontrar la probabilidad de sacar una bola verde en 5 intentos, pero cada vez que sacamos una bola, no la devolvemos a la bolsa. Este es un buen ejemplo de la distribución hipergeométrica.
Para N más grande, es muy difícil calcular la distribución hipergeométrica, pero cuando N es pequeño, tiende a la distribución binomial en este caso.