Guía para principiantes de redes neuronales convolucionales (CNN)
Publicado: 2021-07-05La última década ha visto un tremendo crecimiento en Inteligencia Artificial y máquinas más inteligentes. El campo ha dado lugar a muchas subdisciplinas que se especializan en distintos aspectos de la inteligencia humana. Por ejemplo, el procesamiento del lenguaje natural trata de comprender y modelar el habla humana, mientras que la visión por computadora tiene como objetivo proporcionar una visión similar a la humana para las máquinas.
Dado que hablaremos de redes neuronales convolucionales, nuestro enfoque se centrará principalmente en la visión por computadora. La visión por computadora tiene como objetivo permitir que las máquinas vean el mundo como lo hacemos nosotros y resuelvan problemas relacionados con el reconocimiento de imágenes, la clasificación de imágenes y mucho más. Las redes neuronales convolucionales se utilizan para lograr diversas tareas de visión artificial. También conocidas como CNN o ConvNet, siguen una arquitectura que se asemeja a los patrones y conexiones de las neuronas en el cerebro humano y se inspiran en varios procesos biológicos que ocurren en el cerebro para que se produzca la comunicación.
Tabla de contenido
La importancia biológica de una Red Neuronal Intrincada
Las CNN están inspiradas en nuestra corteza visual. Es el área de la corteza cerebral que está involucrada en el procesamiento visual en nuestro cerebro. La corteza visual tiene varias regiones celulares pequeñas que son sensibles a los estímulos visuales.
Esta idea fue ampliada en 1962 por Hubel y Wiesel en un experimento en el que se encontró que diferentes células neuronales distintas responden (se disparan) a la presencia de bordes distintos de una orientación específica. Por ejemplo, algunas neuronas se dispararían al detectar bordes horizontales, otras al detectar bordes diagonales y otras se dispararían al detectar bordes verticales. A través de este experimento. Hubel y Wiesel descubrieron que las neuronas están organizadas de manera modular, y todos los módulos juntos son necesarios para producir la percepción visual.
Este enfoque modular, la idea de que los componentes especializados dentro de un sistema tienen tareas específicas, es lo que forma la base de las CNN.
Con eso resuelto, pasemos a cómo las CNN aprenden a percibir entradas visuales.

Aprendizaje de redes neuronales convolucionales
Las imágenes se componen de píxeles individuales, que es una representación entre los números 0 y 255. Por lo tanto, cualquier imagen que vea se puede convertir en una representación digital adecuada mediante el uso de estos números, y así es como las computadoras también trabajan con imágenes.
Aquí hay algunas operaciones importantes que intervienen en hacer que una CNN aprenda para la detección o clasificación de imágenes. Esto le dará una idea de cómo se lleva a cabo el aprendizaje en las CNN.
1. Convolución
La convolución se puede entender matemáticamente como la integración combinada de dos funciones diferentes para averiguar cómo la influencia de la función diferente se modifica entre sí. Así es como se puede definir en términos matemáticos:
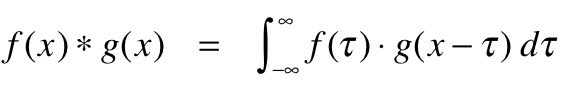
El propósito de la convolución es detectar diferentes características visuales en las imágenes, como líneas, bordes, colores, sombras y más. Esta es una propiedad muy útil porque una vez que su CNN ha aprendido las características de una característica particular en la imagen, más tarde puede reconocer esa característica en cualquier otra parte de la imagen.
Las CNN utilizan núcleos o filtros para detectar las diferentes características que están presentes en cualquier imagen. Los núcleos son solo una matriz de valores distintos (conocidos como pesos en el mundo de las redes neuronales artificiales) entrenados para detectar características específicas. El filtro se mueve sobre toda la imagen para comprobar si se detecta o no la presencia de alguna característica. El filtro lleva a cabo la operación de convolución para proporcionar un valor final que representa la confianza de que una característica en particular está presente.
Si una característica está presente en la imagen, el resultado de la operación de convolución es un número positivo con un valor alto. Si la función está ausente, la operación de convolución da como resultado 0 o un número de valor muy bajo.
Entendamos esto mejor usando un ejemplo. En la imagen de abajo, se ha entrenado un filtro para detectar un signo más. Luego, el filtro se pasa sobre la imagen original. Dado que una parte de la imagen original contiene las mismas características para las que se entrenó el filtro, los valores en cada celda donde existe la característica es un número positivo. Asimismo, el resultado de una operación de convolución también dará como resultado un gran número.
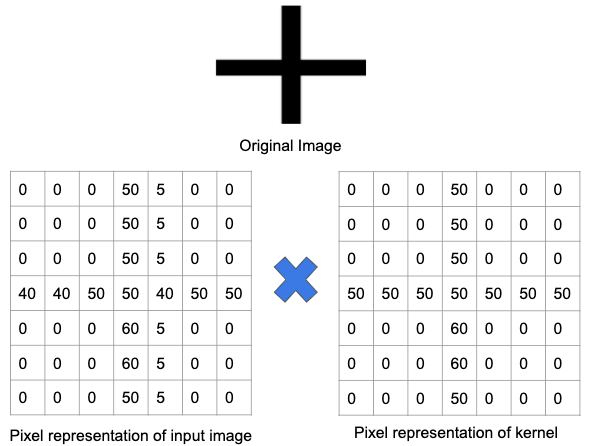
Sin embargo, cuando se pasa el mismo filtro sobre una imagen con un conjunto diferente de características y bordes, el resultado de una operación de convolución será menor, lo que implica que no hubo una fuerte presencia de ningún signo más en la imagen.
Entonces, en el caso de imágenes complejas que tengan varias características como curvas, bordes, colores, etc., necesitaremos un número N de tales detectores de características.
Cuando este filtro pasa a través de la imagen, se genera un mapa de características que es básicamente la matriz de salida que almacena las circunvoluciones de este filtro en diferentes partes de la imagen. En el caso de muchos filtros, terminaremos con una salida 3D. Este filtro debe tener el mismo número de canales que la imagen de entrada para que tenga lugar la operación de convolución.
Además, se puede deslizar un filtro sobre la imagen de entrada a diferentes intervalos, usando un valor de zancada. El valor de zancada informa cuánto debe moverse el filtro en cada paso.
Por lo tanto, el número de capas de salida de un bloque convolucional dado se puede determinar utilizando la siguiente fórmula:

2. Acolchado
Un problema al trabajar con capas convolucionales es que algunos píxeles tienden a perderse en el perímetro de la imagen original. Dado que, en general, los filtros utilizados son pequeños, los píxeles perdidos por filtro pueden ser unos pocos, pero esto se suma a medida que aplicamos diferentes capas convolucionales, lo que da como resultado una gran pérdida de píxeles.
El concepto de relleno consiste en agregar píxeles adicionales a la imagen mientras un filtro de CNN la procesa. Esta es una solución para ayudar al filtro en el procesamiento de imágenes: rellenando la imagen con ceros para permitir más espacio para que el kernel cubra toda la imagen. Al agregar cero rellenos a los filtros, el procesamiento de imágenes de CNN es mucho más preciso y exacto.

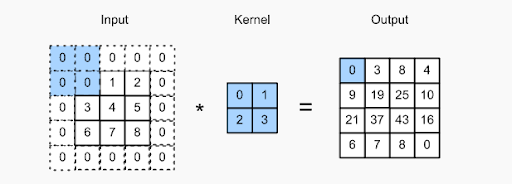
Verifique la imagen de arriba: el relleno se realizó agregando ceros adicionales en el límite de la imagen de entrada. Esto permite la captura de todas las características distintas sin perder ningún píxel.
3. Mapa de activación
Los mapas de características deben pasar a través de una función de mapeo que no es de naturaleza lineal. Los mapas de características se incluyen con un término de sesgo y luego se pasan a través de la función de activación (ReLu), que no es lineal. Esta función tiene como objetivo aportar cierta cantidad de no linealidad a la CNN, ya que las imágenes que se detectan y examinan también son de naturaleza no lineal y están compuestas por diferentes objetos.
4. Etapa de puesta en común
Una vez que finaliza la fase de activación, pasamos al paso de agrupación, en el que la CNN reduce la muestra de las funciones convolucionadas, lo que ayuda a ahorrar tiempo de procesamiento. Esto también ayuda a reducir el tamaño general de la imagen, el sobreajuste y otros problemas que ocurrirían si las redes neuronales complejas se alimentan con mucha información, especialmente si esa información no es demasiado relevante para clasificar o detectar la imagen.
La agrupación es básicamente de dos tipos: agrupación máxima y agrupación mínima. En el primero, se pasa una ventana sobre la imagen de acuerdo con un valor de zancada establecido y, en cada paso, el valor máximo incluido en la ventana se agrupa en la matriz de salida. En la agrupación mínima, los valores mínimos se agrupan en la matriz de salida.
La nueva matriz que se forma como resultado de los resultados se denomina mapa de características agrupadas.
Fuera de la agrupación mínima y máxima, un beneficio de la agrupación máxima es que permite que la CNN se centre en unas pocas neuronas que tienen valores altos en lugar de centrarse en todas las neuronas. Tal enfoque hace que sea menos probable que se sobreajusten los datos de entrenamiento y hace que la predicción general y la generalización funcionen bien.
5. Aplanamiento
Una vez finalizada la agrupación, la representación 3D de la imagen ahora se ha convertido en un vector de características. Esto luego se pasa a un perceptrón multicapa para producir la salida. Echa un vistazo a la imagen a continuación para comprender mejor la operación de aplanamiento:
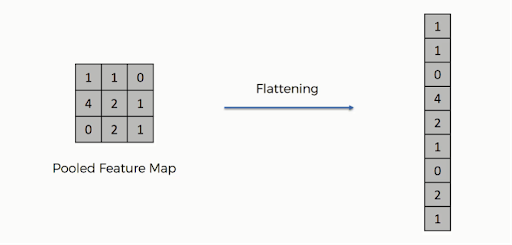
Como puede ver, las filas de la matriz se concatenan en un solo vector de características. Si hay varias capas de entrada, todas las filas se conectan para formar un vector de características plano más largo.
6. Capa totalmente conectada (FCL)
En este paso, el mapa aplanado se envía a una red neuronal. La conexión completa de una red neuronal incluye una capa de entrada, la FCL, y una capa de salida final. La capa completamente conectada puede entenderse como las capas ocultas en las redes neuronales artificiales, excepto que, a diferencia de las capas ocultas, estas capas están completamente conectadas. La información pasa por toda la red y se calcula un error de predicción. Luego, este error se envía como retroalimentación (propagación hacia atrás) a través de los sistemas para ajustar los pesos y mejorar el resultado final, para que sea más preciso.
El resultado final obtenido de la capa anterior de la red neuronal generalmente no suma uno. Estas salidas deben reducirse a números en el rango de [0,1], que luego representarán las probabilidades de cada clase. Para ello se utiliza la función Softmax.
La salida obtenida de la capa densa se alimenta a la función de activación Softmax. A través de esto, todas las salidas finales se asignan a un vector donde la suma de todos los elementos resulta ser uno.
La capa completamente conectada funciona observando la salida de la capa anterior y luego determinando qué característica se correlaciona más con una clase específica. Por lo tanto, si el programa predice si una imagen contiene o no un gato, tendrá valores altos en los mapas de activación que representan características como cuatro patas, patas, cola, etc. Asimismo, si el programa está prediciendo otra cosa, tendrá diferentes tipos de mapas de activación. Una capa completamente conectada se ocupa de las diferentes características que se correlacionan fuertemente con clases y pesos particulares, de modo que el cálculo entre los pesos y la capa anterior sea preciso y obtenga las probabilidades correctas para distintas clases de salida.
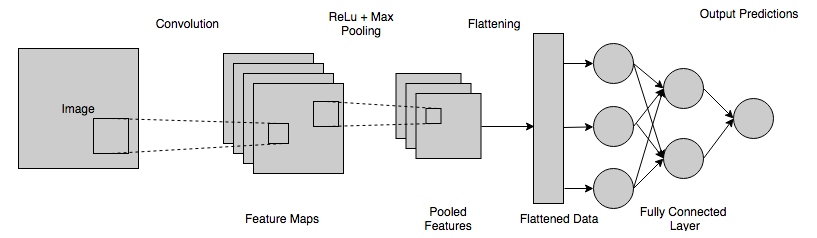
Un breve resumen del funcionamiento de las CNN
Aquí hay un resumen rápido de todo el proceso de cómo funciona CNN y ayuda en la visión por computadora:
- Los diferentes píxeles de la imagen se envían a la capa convolucional, donde se realiza una operación de convolución.
- El paso anterior da como resultado un mapa convolucionado.
- Este mapa se pasa a través de una función rectificadora para dar lugar a un mapa rectificado.
- La imagen se procesa con diferentes circunvoluciones y funciones de activación para localizar y detectar diferentes características.
- Las capas de agrupación se utilizan para identificar partes específicas y distintas de la imagen.
- La capa agrupada se aplana y se usa como entrada a la capa totalmente conectada.
- La capa completamente conectada calcula las probabilidades y da una salida en el rango de [0,1].
En conclusión
El funcionamiento interno de CNN es muy emocionante y abre muchas posibilidades para la innovación y la creación. Asimismo, otras tecnologías bajo el paraguas de la Inteligencia Artificial son fascinantes y están tratando de trabajar entre las capacidades humanas y la inteligencia artificial. En consecuencia, personas de todo el mundo, pertenecientes a diferentes dominios, se están dando cuenta de su interés en este campo y están dando los primeros pasos.
Afortunadamente, la industria de la IA es excepcionalmente acogedora y no distingue según su formación académica. Todo lo que necesita es un conocimiento práctico de las tecnologías junto con calificaciones básicas, ¡y ya está todo listo!
Si desea dominar el meollo de la ML y la IA, el curso de acción ideal sería inscribirse en un programa profesional de IA/ML. Por ejemplo, nuestro Programa Ejecutivo en Aprendizaje Automático e IA es el curso perfecto para los aspirantes a la ciencia de datos. El programa cubre temas como estadísticas y análisis de datos exploratorios, aprendizaje automático y procesamiento de lenguaje natural. Además, incluye más de 13 proyectos de la industria, más de 25 sesiones en vivo y 6 proyectos finales. La mejor parte de este curso es que puedes interactuar con compañeros de todo el mundo. Facilita el intercambio de ideas y ayuda a los alumnos a construir conexiones duraderas con personas de diversos orígenes. ¡Nuestra asistencia profesional de 360 grados es justo lo que necesita para sobresalir en su viaje de ML e IA!
Liderar la revolución tecnológica impulsada por la IA