
Teorema de Bayes en aprendizaje automático: introducción, cómo aplicar y ejemplo
Publicado: 2021-02-04Tabla de contenido
Introducción: ¿Qué es el Teorema de Bayes?
El Teorema de Bayes lleva el nombre del matemático inglés Thomas Bayes, quien trabajó extensamente en la teoría de la decisión, el campo de las matemáticas que involucra probabilidades. El teorema de Bayes también se usa ampliamente en el aprendizaje automático, donde es una forma simple y efectiva de predecir clases con precisión y exactitud. El método bayesiano de cálculo de probabilidades condicionales se utiliza en aplicaciones de aprendizaje automático que implican tareas de clasificación.
Se utiliza una versión simplificada del Teorema de Bayes, conocida como Clasificación Naive Bayes, para reducir el tiempo y los costos de cálculo. En este artículo, lo llevamos a través de estos conceptos y discutimos las aplicaciones del Teorema de Bayes en el aprendizaje automático.
Únase al curso de aprendizaje automático en línea de las mejores universidades del mundo: maestrías, programas ejecutivos de posgrado y programa de certificado avanzado en ML e IA para acelerar su carrera.
¿Por qué usar el teorema de Bayes en el aprendizaje automático?
El teorema de Bayes es un método para determinar las probabilidades condicionales, es decir, la probabilidad de que ocurra un evento dado que ya ocurrió otro evento. Debido a que una probabilidad condicional incluye condiciones adicionales, en otras palabras, más datos, puede contribuir a obtener resultados más precisos.
Por lo tanto, las probabilidades condicionales son imprescindibles para determinar predicciones y probabilidades precisas en el aprendizaje automático. Dado que el campo se está volviendo cada vez más omnipresente en una variedad de dominios, es importante comprender el papel de los algoritmos y métodos como el teorema de Bayes en el aprendizaje automático.
Antes de entrar en el teorema en sí, entendamos algunos términos a través de un ejemplo. Digamos que el gerente de una librería tiene información sobre la edad y los ingresos de sus clientes. Quiere saber cómo se distribuyen las ventas de libros entre tres clases de edad de clientes: jóvenes (18-35), de mediana edad (35-60) y mayores (60+).

Llamemos a nuestros datos X. En la terminología bayesiana, X se llama evidencia. Tenemos alguna hipótesis H, donde tenemos algún X que pertenece a cierta clase C.
Nuestro objetivo es determinar la probabilidad condicional de nuestra hipótesis H dada X, es decir, P(H | X).
En términos simples, al determinar P(H | X), obtenemos la probabilidad de que X pertenezca a la clase C, dada X. X tiene atributos de edad e ingresos, digamos, por ejemplo, 26 años con un ingreso de $2000. H es nuestra hipótesis de que el cliente comprará el libro.
Preste mucha atención a los siguientes cuatro términos:
- Evidencia : como se discutió anteriormente, P (X) se conoce como evidencia. Es simplemente la probabilidad de que el cliente, en este caso, tenga 26 años y gane $2000.
- Probabilidad previa : P(H), conocida como probabilidad previa, es la probabilidad simple de nuestra hipótesis, es decir, que el cliente compre un libro. Esta probabilidad no se proporcionará con ningún aporte adicional en función de la edad y los ingresos. Dado que el cálculo se realiza con menos información, el resultado es menos preciso.
- Probabilidad posterior : P(H | X) se conoce como la probabilidad posterior. Aquí, P(H | X) es la probabilidad de que el cliente compre un libro (H) dado X (que tiene 26 años y gana $2000).
- Probabilidad – P(X | H) es la probabilidad de probabilidad. En este caso, dado que sabemos que el cliente comprará el libro, la probabilidad de verosimilitud es la probabilidad de que el cliente tenga 26 años y un ingreso de $2000.
Dado esto, el teorema de Bayes establece:
P(H | X) = [ P(X | H) * P(H) ] / P(X)
Tenga en cuenta la aparición de los cuatro términos anteriores en el teorema: probabilidad posterior, probabilidad de verosimilitud, probabilidad previa y evidencia.
Leer: Explicación de Naive Bayes
Cómo aplicar el teorema de Bayes en el aprendizaje automático
El Clasificador Naive Bayes, una versión simplificada del Teorema de Bayes, se utiliza como un algoritmo de clasificación para clasificar los datos en varias clases con precisión y velocidad.
Veamos cómo se puede aplicar el Clasificador Naive Bayes como un algoritmo de clasificación.
- Considere un ejemplo general: X es un vector que consta de 'n' atributos, es decir, X = {x1, x2, x3, …, xn}.
- Digamos que tenemos 'm' clases {C1, C2, …, Cm}. Nuestro clasificador tendrá que predecir que X pertenece a una determinada clase. La clase que entregue la probabilidad posterior más alta será elegida como la mejor clase. Entonces, matemáticamente, el clasificador predecirá para la clase Ci iff P(Ci | X) > P(Cj | X). Aplicando el teorema de Bayes:
P(Ci | X) = [ P(X | Ci) * P(Ci) ] / P(X)
- P(X), al ser condición independiente, es constante para cada clase. Entonces, para maximizar P(Ci | X), debemos maximizar [P(X | Ci) * P(Ci)]. Considerando que todas las clases son igualmente probables, tenemos P(C1) = P(C2) = P(C3) … = P(Cn). Entonces, en última instancia, solo necesitamos maximizar P(X | Ci).
- Dado que es probable que el conjunto de datos grande típico tenga varios atributos, es computacionalmente costoso realizar la operación P(X | Ci) para cada atributo. Aquí es donde entra la independencia condicional de clase para simplificar el problema y reducir los costos de cálculo. Por independencia condicional de clase, queremos decir que consideramos que los valores del atributo son condicionalmente independientes entre sí. Esta es la Clasificación Naive Bayes.
P(Xi | C) = P(x1 | C) * P(x2 | C) *… * P(xn | C)
Ahora es fácil calcular las probabilidades más pequeñas. Una cosa importante a tener en cuenta aquí: dado que xk pertenece a cada atributo, también debemos verificar si el atributo con el que estamos tratando es categórico o continuo .
- Si tenemos un atributo categórico , las cosas son más sencillas. Podemos simplemente contar el número de instancias de la clase Ci que consisten en el valor xk para el atributo k y luego dividirlo por el número de instancias de la clase Ci.
- Si tenemos un atributo continuo, considerando que tenemos una función de distribución normal, aplicamos la siguiente fórmula, con media ? y la desviación estándar?:
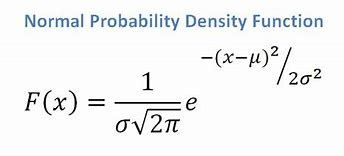

Fuente
En última instancia, tendremos P(x | Ci) = F(xk, ?k, ?k).
- Ahora, tenemos todos los valores que necesitamos para usar el Teorema de Bayes para cada clase Ci. Nuestra clase pronosticada será la clase que alcance la mayor probabilidad P(X | Ci) * P(Ci).
Ejemplo: clasificación predictiva de los clientes de una librería
Tenemos el siguiente conjunto de datos de una librería:
| Años | Ingreso | Estudiante | Calificación crediticia | Compras_Libro |
| Juventud | Elevado | No | Justo | No |
| Juventud | Elevado | No | Excelente | No |
| De edad mediana | Elevado | No | Justo | sí |
| Mayor | Medio | No | Justo | sí |
| Mayor | Bajo | sí | Justo | sí |
| Mayor | Bajo | sí | Excelente | No |
| De edad mediana | Bajo | sí | Excelente | sí |
| Juventud | Medio | No | Justo | No |
| Juventud | Bajo | sí | Justo | sí |
| Mayor | Medio | sí | Justo | sí |
| Juventud | Medio | sí | Excelente | sí |
| De edad mediana | Medio | No | Excelente | sí |
| De edad mediana | Elevado | sí | Justo | sí |
| Mayor | Medio | No | Excelente | No |
Tenemos atributos como edad, ingresos, estudiante y calificación crediticia. Nuestra clase, buys_book, tiene dos resultados: Sí o No.
Nuestro objetivo es clasificar en función de los siguientes atributos:
X = {edad = joven, estudiante = sí, ingreso = medio, calificación crediticia = regular}.
Como mostramos anteriormente, para maximizar P(Ci | X), necesitamos maximizar [ P(X | Ci) * P(Ci) ] para i = 1 e i = 2.
Por lo tanto, P(compra_libro = sí) = 9/14 = 0,643
P(compra_libro = no) = 5/14 = 0,357
P(edad = joven | compra_libro = sí) = 2/9 = 0,222
P(edad = joven | compra_libro = no) =3/5 = 0,600
P(ingreso = medio | compra_libro = sí) = 4/9 = 0,444
P(ingreso = medio | compra_libro = no) = 2/5 = 0,400
P(estudiante = sí | compra_libro = sí) = 6/9 = 0,667
P(estudiante = si | compra_libro = no) = 1/5 = 0,200
P(calificación_crediticia = justa | compra_libro = sí) = 6/9 = 0,667
P(calificación_crédito = regular | libro_de_compras = no) = 2/5 = 0,400
Usando las probabilidades calculadas anteriormente, tenemos
P(X | compra_libro = sí) = 0,222 x 0,444 x 0,667 x 0,667 = 0,044
Similar,
P(X | compra_libro = no) = 0,600 x 0,400 x 0,200 x 0,400 = 0,019
¿Qué clase proporciona Ci la máxima P(X|Ci)*P(Ci)? Calculamos:
P(X | compra_libro = sí)* P(compra_libro = sí) = 0,044 x 0,643 = 0,028
P(X | compra_libro = no)* P(compra_libro = no) = 0,019 x 0,357 = 0,007
Comparando los dos anteriores, dado que 0.028 > 0.007, el Clasificador Naive Bayes predice que el cliente con los atributos mencionados comprará un libro.
Pago: ideas y temas de proyectos de aprendizaje automático
¿Es el clasificador bayesiano un buen método?
Los algoritmos basados en el teorema de Bayes en el aprendizaje automático brindan resultados comparables a otros algoritmos, y los clasificadores bayesianos generalmente se consideran métodos simples de alta precisión. Sin embargo, se debe tener cuidado de recordar que los clasificadores bayesianos son particularmente apropiados cuando la suposición de independencia condicional de clase es válida, y no en todos los casos. Otra preocupación práctica es que la adquisición de todos los datos de probabilidad no siempre es factible.
Conclusión
El Teorema de Bayes tiene muchas aplicaciones en el aprendizaje automático, particularmente en problemas basados en clasificación. La aplicación de esta familia de algoritmos en el aprendizaje automático implica familiarizarse con términos como probabilidad previa y probabilidad posterior. En este artículo, discutimos los conceptos básicos del teorema de Bayes, su uso en problemas de aprendizaje automático y trabajamos a través de un ejemplo de clasificación.
Dado que el teorema de Bayes forma una parte crucial de los algoritmos basados en la clasificación en el aprendizaje automático, puede obtener más información sobre el Programa de certificado avanzado en aprendizaje automático y PNL de upGrad . Este curso se ha diseñado teniendo en cuenta varios tipos de estudiantes interesados en el aprendizaje automático, ofrece tutoría 1-1 y mucho más.
¿Por qué usamos el teorema de Bayes en Machine Learning?
El Teorema de Bayes es un método para calcular las probabilidades condicionales, o la probabilidad de que ocurra un evento si ha ocurrido otro previamente. Una probabilidad condicional puede conducir a resultados más precisos al incluir condiciones adicionales; en otras palabras, más datos. Para obtener estimaciones y probabilidades correctas en Machine Learning, se requieren probabilidades condicionales. Dada la creciente prevalencia del campo en una amplia gama de dominios, es fundamental comprender la importancia de los algoritmos y enfoques como el teorema de Bayes en el aprendizaje automático.
¿Es Bayesian Classifier una buena opción?
En el aprendizaje automático, los algoritmos basados en el teorema de Bayes producen resultados que son comparables a los de otros métodos, y los clasificadores bayesianos se consideran enfoques simples de alta precisión. Sin embargo, es importante tener en cuenta que los clasificadores bayesianos se utilizan mejor cuando la condición de independencia condicional de clase es correcta, no en todas las circunstancias. Otra consideración es que no siempre es posible obtener todos los datos de probabilidad.
¿Cómo se puede aplicar el teorema de Bayes en la práctica?
El teorema de Bayes calcula la probabilidad de ocurrencia en base a nueva evidencia que está o podría estar relacionada con ella. El método también se puede usar para ver cómo la nueva información hipotética afecta la probabilidad de un evento, suponiendo que la nueva información sea verdadera. Tomemos, por ejemplo, una sola carta seleccionada de una baraja de 52 cartas. La probabilidad de que la carta se convierta en rey es 4 dividido por 52, o 1/13, o aproximadamente 7,69 por ciento. Tenga en cuenta que la baraja contiene cuatro reyes. Digamos que se revela que la carta elegida es una carta con figuras. Debido a que hay 12 cartas con figuras en una baraja, la probabilidad de que la carta elegida sea un rey es 4 dividido por 12, o aproximadamente el 33,3 por ciento.