
6 características que cambian el juego de Apache Spark en 2022 [Cómo debe usar]
Publicado: 2021-01-07Desde que Big Data irrumpió en el mundo de la tecnología y los negocios, ha habido un enorme aumento de las herramientas y plataformas de Big Data, en particular de Apache Hadoop y Apache Spark. Hoy nos centraremos únicamente en Apache Spark y hablaremos en detalle sobre sus beneficios comerciales y aplicaciones.
Apache Spark saltó a la fama en 2009 y, desde entonces, se ha ido haciendo un hueco en la industria. Según Apache org., Spark es un "motor de análisis unificado ultrarrápido" diseñado para procesar cantidades colosales de Big Data. Gracias a una comunidad activa, hoy Spark es una de las plataformas de Big Data de código abierto más grandes del mundo.
Tabla de contenido
¿Qué es Apache Spark?
Desarrollado originalmente en el AMPLab de la Universidad de California (Berkeley), Spark fue diseñado como un motor de procesamiento robusto para datos de Hadoop, con un enfoque especial en la velocidad y la facilidad de uso. Es una alternativa de código abierto a MapReduce de Hadoop. Esencialmente, Spark es un marco de procesamiento de datos en paralelo que puede colaborar con Apache Hadoop para facilitar el desarrollo fluido y rápido de aplicaciones sofisticadas de Big Data en Hadoop.
Spark incluye una amplia gama de bibliotecas para algoritmos de aprendizaje automático (ML) y algoritmos gráficos. No solo eso, también es compatible con la transmisión en tiempo real y las aplicaciones SQL a través de Spark Streaming y Shark, respectivamente. La mejor parte de usar Spark es que puede escribir aplicaciones Spark en Java, Scala o incluso Python, y estas aplicaciones se ejecutarán casi diez veces más rápido (en el disco) y 100 veces más rápido (en la memoria) que las aplicaciones de MapReduce.
Apache Spark es bastante versátil, ya que se puede implementar de muchas maneras y también ofrece enlaces nativos para los lenguajes de programación Java, Scala, Python y R. Admite SQL, procesamiento de gráficos, transmisión de datos y aprendizaje automático. Es por eso que Spark se usa ampliamente en varios sectores de la industria, incluidos bancos, empresas de telecomunicaciones, empresas de desarrollo de juegos, agencias gubernamentales y, por supuesto, en todas las principales empresas del mundo tecnológico: Apple, Facebook, IBM y Microsoft.
Las 6 mejores características de Apache Spark
Las características que hacen de Spark una de las plataformas de Big Data más utilizadas son:

1. Velocidad de procesamiento ultrarrápida
El procesamiento de Big Data tiene que ver con el procesamiento de grandes volúmenes de datos complejos. Por lo tanto, cuando se trata de procesamiento de Big Data, las organizaciones y empresas quieren marcos que puedan procesar cantidades masivas de datos a alta velocidad. Como mencionamos anteriormente, las aplicaciones de Spark pueden ejecutarse hasta 100 veces más rápido en memoria y 10 veces más rápido en disco en clústeres de Hadoop.
Se basa en Resilient Distributed Dataset (RDD) que permite a Spark almacenar datos de forma transparente en la memoria y leerlos/escribirlos en el disco solo si es necesario. Esto ayuda a reducir la mayor parte del tiempo de lectura y escritura del disco durante el procesamiento de datos.
2. Facilidad de uso
Spark le permite escribir aplicaciones escalables en Java, Scala, Python y R. Por lo tanto, los desarrolladores obtienen el alcance para crear y ejecutar aplicaciones Spark en sus lenguajes de programación preferidos. Además, Spark está equipado con un conjunto integrado de más de 80 operadores de alto nivel. Puede usar Spark de forma interactiva para consultar datos de shells de Scala, Python, R y SQL.
3. Ofrece soporte para análisis sofisticados
Spark no solo admite operaciones simples de "mapa" y "reducción", sino que también admite consultas SQL, transmisión de datos y análisis avanzados, incluidos algoritmos gráficos y de aprendizaje automático. Viene con una poderosa pila de bibliotecas como SQL & DataFrames y MLlib (para ML), GraphX y Spark Streaming. Lo fascinante es que Spark le permite combinar las capacidades de todas estas bibliotecas dentro de un solo flujo de trabajo/aplicación.
4. Procesamiento de flujo en tiempo real
Spark está diseñado para manejar la transmisión de datos en tiempo real. Si bien MapReduce está diseñado para manejar y procesar los datos que ya están almacenados en los clústeres de Hadoop, Spark puede hacer ambas cosas y también manipular datos en tiempo real a través de Spark Streaming.
A diferencia de otras soluciones de transmisión, Spark Streaming puede recuperar el trabajo perdido y entregar la semántica exacta lista para usar sin necesidad de código o configuración adicional. Además, también le permite reutilizar el mismo código para el procesamiento por lotes y de transmisión e incluso para unir datos de transmisión a datos históricos.
5. Es flexible
Spark puede ejecutarse de forma independiente en modo de clúster y también puede ejecutarse en Hadoop YARN, Apache Mesos, Kubernetes e incluso en la nube. Además, puede acceder a diversas fuentes de datos. Por ejemplo, Spark puede ejecutarse en el administrador de clústeres de YARN y leer cualquier dato de Hadoop existente. Puede leer desde cualquier fuente de datos de Hadoop como HBase, HDFS, Hive y Cassandra. Este aspecto de Spark lo convierte en una herramienta ideal para migrar aplicaciones puras de Hadoop, siempre que el caso de uso de las aplicaciones sea compatible con Spark.
6. Comunidad activa y en expansión
Desarrolladores de más de 300 empresas han contribuido a diseñar y construir Apache Spark. ¡Desde 2009, más de 1200 desarrolladores han contribuido activamente a hacer de Spark lo que es hoy! Naturalmente, Spark cuenta con el respaldo de una comunidad activa de desarrolladores que trabajan para mejorar continuamente sus características y rendimiento. Para comunicarse con la comunidad de Spark, puede hacer uso de las listas de correo para cualquier consulta, y también puede asistir a grupos de reuniones y conferencias de Spark.
La anatomía de las aplicaciones Spark
Cada aplicación Spark se compone de dos procesos principales: un proceso controlador principal y una colección de procesos ejecutores .
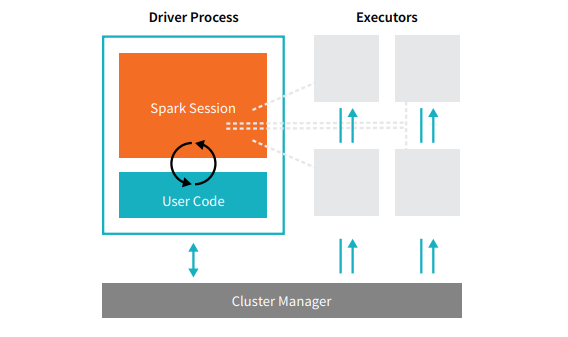
Fuente
El proceso del controlador que se encuentra en un nodo en el clúster es responsable de ejecutar la función main(). También maneja otras tres tareas: mantener información sobre la aplicación Spark, responder al código o la entrada de un usuario y analizar, distribuir y programar el trabajo entre los ejecutores. El proceso del controlador forma el corazón de una aplicación Spark: contiene y mantiene toda la información crítica que cubre la vida útil de la aplicación Spark.

Los ejecutores o procesos ejecutores son elementos secundarios que deben ejecutar la tarea que les asigna el controlador. Básicamente, cada ejecutor realiza dos funciones cruciales: ejecutar el código que le asignó el controlador e informar el estado de la computación (en ese ejecutor) al nodo del controlador. Los usuarios pueden decidir y configurar cuántos ejecutores debe tener cada nodo.
En una aplicación Spark, el administrador de clústeres controla todas las máquinas y asigna recursos a la aplicación. Aquí, el administrador de clústeres puede ser cualquiera de los administradores de clústeres centrales de Spark, incluido YARN (administrador de clústeres independiente de Spark) o Mesos. Esto implica que un clúster puede ejecutar varias aplicaciones Spark simultáneamente.
Aplicaciones Apache Spark del mundo real
Spark es una plataforma Big Dara ampliamente utilizada y mejor calificada en la industria moderna. Algunos de los ejemplos del mundo real más aclamados de aplicaciones Apache Spark son:
Spark para el aprendizaje automático
Apache Spark se jacta de una biblioteca de aprendizaje automático escalable: MLlib. Esta biblioteca está diseñada explícitamente para simplificar, escalar y facilitar la integración perfecta con otras herramientas. MLlib no solo posee la escalabilidad, la compatibilidad de idiomas y la velocidad de Spark, sino que también puede realizar una serie de tareas de análisis avanzadas como clasificación, agrupación en clústeres y reducción de dimensionalidad. Gracias a MLlib, Spark se puede utilizar para análisis predictivo, análisis de sentimientos, segmentación de clientes e inteligencia predictiva.
Otra característica impresionante de Apache Spark reside en el dominio de la seguridad de la red. Spark Streaming permite a los usuarios monitorear paquetes de datos en tiempo real antes de enviarlos al almacenamiento. Durante este proceso, puede identificar con éxito cualquier actividad sospechosa o maliciosa que surja de fuentes conocidas de amenazas. Incluso después de que los paquetes de datos se envían al almacenamiento, Spark usa MLlib para analizar más los datos e identificar riesgos potenciales para la red. Esta función también se puede utilizar para la detección de fraudes y eventos.
Spark para computación en la niebla
Apache Spark es una excelente herramienta para la computación en la niebla, particularmente cuando se trata de Internet de las cosas (IoT). El IoT se basa en gran medida en el concepto de procesamiento paralelo a gran escala. Dado que la red IoT está formada por miles y millones de dispositivos conectados, los datos generados por esta red cada segundo están más allá de la comprensión.
Naturalmente, para procesar volúmenes tan grandes de datos producidos por dispositivos IoT, necesita una plataforma escalable que admita el procesamiento paralelo. ¡Y qué mejor que la arquitectura robusta de Spark y las capacidades de computación en la niebla para manejar cantidades tan grandes de datos!
La computación en la niebla descentraliza los datos y el almacenamiento y, en lugar de utilizar el procesamiento en la nube, realiza la función de procesamiento de datos en el borde de la red (principalmente integrado en los dispositivos IoT).
Para hacer esto, la computación en la niebla requiere tres capacidades, a saber, baja latencia, procesamiento paralelo de ML y algoritmos de análisis de gráficos complejos, cada uno de los cuales está presente en Spark. Además, la presencia de Spark Streaming, Shark (una herramienta de consulta interactiva que puede funcionar en tiempo real), MLlib y GraphX (un motor de análisis gráfico) mejora aún más la capacidad informática de niebla de Spark.
Spark para análisis interactivo
A diferencia de MapReduce, Hive o Pig, que tienen una velocidad de procesamiento relativamente baja, Spark puede presumir de análisis interactivos de alta velocidad. Es capaz de manejar consultas exploratorias sin requerir muestreo de los datos. Además, Spark es compatible con casi todos los lenguajes de desarrollo populares, incluidos R, Python, SQL, Java y Scala.
La última versión de Spark, Spark 2.0, presenta una nueva funcionalidad conocida como transmisión estructurada. Con esta característica, los usuarios pueden ejecutar consultas estructuradas e interactivas contra la transmisión de datos en tiempo real.
Usuarios de Spark
Ahora que conoce bien las características y capacidades de Spark, ¡hablemos de los cuatro usuarios destacados de Spark!
1.Yahoo
Yahoo usa Spark para dos de sus proyectos, uno para personalizar las páginas de noticias para los visitantes y el otro para ejecutar análisis para publicidad. Para personalizar las páginas de noticias, Yahoo utiliza algoritmos ML avanzados que se ejecutan en Spark para comprender los intereses, preferencias y necesidades de los usuarios individuales y categorizar las historias en consecuencia.
Para el segundo caso de uso, Yahoo aprovecha la capacidad interactiva de Hive on Spark (para integrarse con cualquier herramienta que se conecte a Hive) para ver y consultar los datos analíticos publicitarios de Yahoo recopilados en Hadoop.
2. Uber
Uber usa Spark Streaming en combinación con Kafka y HDFS para ETL (extraer, transformar y cargar) grandes cantidades de datos en tiempo real de eventos discretos en datos estructurados y utilizables para un análisis más detallado. Estos datos ayudan a Uber a diseñar soluciones mejoradas para los clientes.

3. Conviva
Como empresa de transmisión de video, Conviva obtiene un promedio de más de 4 millones de transmisiones de video cada mes, lo que lleva a una rotación masiva de clientes. Este desafío se ve agravado por el problema de administrar el tráfico de video en vivo. Para combatir estos desafíos de manera efectiva, Conviva utiliza Spark Streaming para conocer las condiciones de la red en tiempo real y optimizar su tráfico de video en consecuencia. Esto permite que Conviva brinde a los usuarios una experiencia de visualización consistente y de alta calidad.
4. Pinterest
En Pinterest, los usuarios pueden marcar sus temas favoritos cuando lo deseen mientras navegan por la web y las redes sociales. Para ofrecer una experiencia de cliente mejorada y personalizada, Pinterest utiliza las capacidades ETL de Spark para identificar las necesidades e intereses únicos de los usuarios individuales y brindarles recomendaciones relevantes en Pinterest.
Conclusión
Para concluir, Spark es una plataforma de Big Data extremadamente versátil con funciones diseñadas para impresionar. Dado que es un marco de código abierto, está mejorando y evolucionando continuamente, y se le agregan nuevas características y funcionalidades. A medida que las aplicaciones de Big Data se vuelven más diversas y expansivas, también lo harán los casos de uso de Apache Spark.
Si está interesado en saber más sobre Big Data, consulte nuestro programa PG Diploma in Software Development Specialization in Big Data, que está diseñado para profesionales que trabajan y proporciona más de 7 estudios de casos y proyectos, cubre 14 lenguajes y herramientas de programación, prácticas talleres, más de 400 horas de aprendizaje riguroso y asistencia para la colocación laboral con las mejores empresas.
Consulte nuestros otros cursos de ingeniería de software en upGrad.