
Arquitectura Apache Kafka: guía completa para principiantes [2022]
Publicado: 2021-12-23Antes de profundizar en los detalles de la arquitectura Apache Kafka, es pertinente aclarar por qué Kafka aparece en los titulares en primer lugar. Para empezar, Apache Kafka encuentra uso principalmente en arquitecturas de transmisión de datos en tiempo real para proporcionar análisis en tiempo real. Duradero, rápido, escalable y tolerante a fallas, el sistema de mensajería de publicación y suscripción de Kafka tiene casos de uso para cosas como el seguimiento de datos de sensores de IoT o el seguimiento de llamadas de servicio.
Empresas como LinkedIn, Netflix, Microsoft, Uber, Spotify, Goldman Sachs, Cisco, PayPal y muchas otras emplean Apache Kafka para procesar datos de transmisión en tiempo real. Por ejemplo, LinkedIn, donde se originó Kafka, lo usa para rastrear métricas operativas y datos de actividad. Del mismo modo, para Netflix, Apache Kafka es el estándar de facto para sus necesidades de mensajería, eventos y procesamiento de transmisiones.
Obtenga capacitación en desarrollo de software en línea de las mejores universidades del mundo. Obtenga programas Executive PG, programas de certificados avanzados o programas de maestría para acelerar su carrera.
La utilidad de Apache Kafka se aprecia mejor si se comprende la arquitectura de Apache Kafka y sus componentes subyacentes. Entonces, exploremos los detalles de la arquitectura de Kafka.
Tabla de contenido
Conceptos fundamentales de la arquitectura Kafka
Los siguientes conceptos son básicos para comprender la arquitectura de Apache Kafka:
1. Temas
Los temas de Kafka definen los canales a través de los cuales se transmiten los datos. Así, los productores publican mensajes a los temas y los consumidores leen mensajes de los temas a los que se suscriben. No hay limitación en la cantidad de temas creados dentro de un clúster de Kafka y un nombre único identifica cada tema.

2. Corredores
Los intermediarios son servidores en un clúster de Kafka que funcionan como contenedores y contienen varios temas con distintas particiones. Un ID de número entero único identifica a los intermediarios en un clúster de Kafka, y una conexión con cualquiera de estos intermediarios significa conectarse con todo el clúster.
3. Particiones
Los temas de Kafka se dividen en muchas partes conocidas como particiones. Las particiones están separadas en orden y permiten que múltiples consumidores lean datos de un tema en particular en forma paralela. Las particiones de un tema se distribuyen en varios servidores del clúster de Kafka, y cada servidor administra los datos y las solicitudes de su lote de particiones. Los mensajes llegan al intermediario ya una clave, y la clave determina la partición a la que irá el mensaje en particular. Por lo tanto, los mensajes con la misma clave van a la misma partición. En caso de que no se especifique la clave, la partición se decide siguiendo un enfoque de turno rotativo.
4. Réplicas
En Kafka, las réplicas son como copias de seguridad de particiones para garantizar que no se pierdan datos en caso de un cierre o falla planificada. En otras palabras, las réplicas son copias de particiones.
5. Compensaciones de partición
Dado que los mensajes o registros en Kafka se asignan a particiones, cada registro tiene un desplazamiento para especificar su posición dentro de la partición. Por lo tanto, el valor de compensación asociado con un registro ayuda en su fácil identificación dentro de la partición. Un desplazamiento de partición tiene significado solo dentro de esa partición en particular, y dado que los registros se agregan a los extremos de la partición, los registros más antiguos tendrán valores de desplazamiento más bajos.
6. Productores
Los productores de Kafka publican mensajes en uno o más temas y envían datos al clúster de Kafka. Tan pronto como un productor publica un mensaje en un tema de Kafka, el intermediario recibe el mensaje y lo agrega a una partición específica. Luego, los productores pueden elegir la partición donde quieren publicar su mensaje.
7. Consumidores y Grupos de Consumidores
Los consumidores leen mensajes del clúster de Kafka. Cuando un consumidor está listo para recibir el mensaje, los datos se extraen del corredor. Los consumidores pertenecen a un grupo de consumidores, y cada consumidor dentro de un grupo en particular es responsable de leer un subconjunto de las particiones de cada tema al que está suscrito.
8. Líder y seguidor
Cada partición de Kafka tiene un servidor que desempeña el papel de líder. El líder realiza todas las tareas de lectura y escritura para esa partición en particular. Por otro lado, el trabajo del seguidor es replicar los datos del líder. Cuando falla un líder en una partición específica, uno de los nodos seguidores asume el rol de líder. Una partición puede tener muchos seguidores o ninguno.
El siguiente diagrama es una presentación simplificada de las interrelaciones entre los componentes de la arquitectura Apache Kafka discutidos anteriormente.
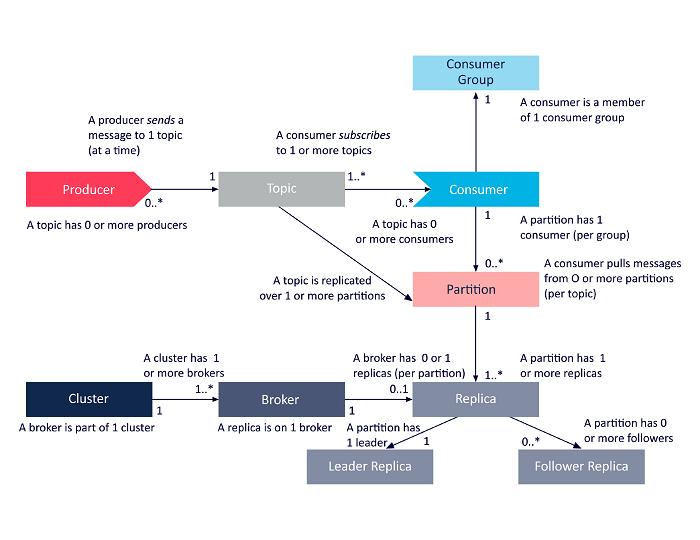
Fuente
Arquitectura de clúster de Apache Kafka
Aquí hay una mirada detallada a los principales componentes arquitectónicos de Kafka:

1. Corredores Kafka
Los clústeres de Kafka suelen contener varios nodos conocidos como intermediarios. Los intermediarios mantienen el equilibrio de carga. Cada corredor de Kafka puede manejar cientos y miles de lecturas y escrituras cada segundo. Un corredor sirve como líder para una partición en particular. El líder tiene uno o varios seguidores, con los datos del líder replicados entre los seguidores de esa partición en particular.
Los seguidores deben mantenerse actualizados con los datos del líder. El líder, a su vez, realiza un seguimiento de los seguidores que están sincronizados con él. Si un seguidor no alcanza al líder o ya no está vivo, se elimina de la lista de réplicas sincronizadas asociadas con el líder en particular. Se elige un nuevo líder entre los seguidores tras la muerte del líder, y ZooKeeper supervisa la elección. Dado que los intermediarios no tienen estado, ZooKeeper mantiene su estado de clúster. Los nodos en un clúster envían mensajes de latidos al ZooKeeper para informar a este último que están vivos.
2. Productores de Kafka
Los productores de Kafka envían datos directamente a los intermediarios que desempeñan el papel de líder para una partición en particular. Los intermediarios o nodos de los clústeres de Kafka ayudan a los productores a enviar mensajes directos. Lo hacen respondiendo solicitudes de metadatos sobre qué servidores están activos y el estado activo de los líderes de partición de un tema, lo que permite al productor dirigir sus solicitudes en consecuencia. El productor decide en qué partición quiere publicar los mensajes. Los mensajes en Kafka se envían en lotes, llamados lotes de registro. Los productores recopilan mensajes en la memoria y los envían en lotes después de que haya transcurrido un período fijo o después de que se haya acumulado una cierta cantidad de mensajes.
3. Consumidores de Kafka
Los consumidores de Kafka emiten solicitudes a los intermediarios indicando las particiones que desea consumir. El consumidor especifica el desplazamiento de partición en su solicitud y recibe un fragmento de registro (a partir de la posición de desplazamiento) del intermediario. Un registro contiene los registros de un período configurable conocido como el período de retención.
Los consumidores también pueden volver a consumir datos siempre que el registro contenga los datos. Los consumidores de Kafka trabajan con un enfoque basado en extracción, lo que significa que los intermediarios no envían datos inmediatamente a los consumidores. En su lugar, primero, los consumidores envían solicitudes a los intermediarios indicando que están listos para consumir datos. Por lo tanto, el sistema basado en extracción garantiza que los consumidores no se sientan abrumados con los mensajes y puedan ponerse al día si se atrasan.
El siguiente es un diagrama de arquitectura de Apache Kafka simplificado:
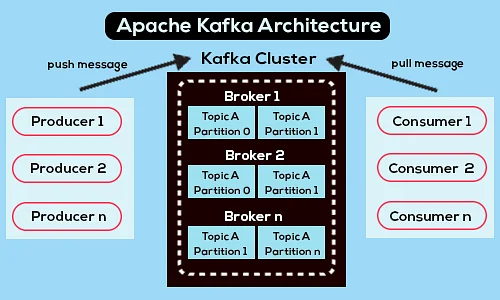
Fuente
Obtenga más información sobre Apache Kafka.
Arquitectura API de Apache Kafka
Apache Kafka tiene cuatro API clave: Streams API, Connector API, Producer API y Consumer API. Veamos qué papel tiene que desempeñar cada uno para mejorar las capacidades de Apache Kafka:
1. API de flujos
La API de flujos de Kafka permite que una aplicación procese datos mediante un algoritmo de procesamiento de flujos. Con la API de flujos, las aplicaciones pueden consumir flujos de entrada de uno o varios temas, procesarlos con operaciones de flujo, producir flujos de salida y, finalmente, enviarlos a uno o más temas. Por lo tanto, la API de Streams facilita la transformación de flujos de entrada en flujos de salida.
2. API del conector
La API Connector de Kafka es útil para crear, ejecutar y administrar productores y consumidores reutilizables que conectan temas de Kafka con sistemas de datos o aplicaciones existentes. Por ejemplo, un conector a una base de datos relacional podría capturar todas las actualizaciones y asegurarse de que los cambios estén disponibles dentro de un tema de Kafka.

3. API del productor
La API Producer de Kafka permite que las aplicaciones publiquen un flujo de registros en los temas de Kafka.
4. API de consumo
La API de consumo de Kafka permite que las aplicaciones se suscriban a los temas de Kafka. También permite que las aplicaciones procesen transmisiones de registros que se producen para esos temas de Kafka.
camino a seguir
La arquitectura Apache Kafka es solo una pequeña parte del vasto repertorio de herramientas y lenguajes que manejan los desarrolladores de software. Suponga que es un desarrollador de software en ciernes con una inclinación hacia Big Data. En ese caso, puedes dar el primer paso hacia tus objetivos con el Programa PG Ejecutivo en Desarrollo de Software – Especialización en Big Data de upGrad .
Aquí hay una descripción general del programa con algunos aspectos destacados clave:
- Executive PGP de IIIT Bangalore con certificaciones en Data Science e Infraestructura en la Nube
- Sesiones en línea y conferencias en vivo con más de 400 horas de contenido
- Más de 7 estudios de casos y proyectos
- Más de 14 lenguajes y herramientas de programación
- Apoyo profesional de 360 grados
- Redes de pares y de la industria
Regístrese para más detalles sobre el curso!
¿Para qué sirve Kafka?
Apache Kafka se usa principalmente para crear canalizaciones de datos de transmisión en tiempo real y aplicaciones que se adaptan a esos flujos de datos. Permite tanto el almacenamiento como el análisis de datos históricos y en tiempo real a través de una combinación de mensajería, almacenamiento y procesamiento de flujo.
¿Kafka es un marco?
Apache Kafka es un software de código abierto que proporciona un marco para almacenar, leer y analizar datos de transmisión. Dado que es de código abierto, Kafka es de uso gratuito con muchos desarrolladores y usuarios que contribuyen a nuevas funciones, actualizaciones y soporte para nuevos usuarios.
¿Por qué necesitamos flujos de Kafka?
Kafka Streams es una biblioteca cliente para crear microservicios y aplicaciones de transmisión donde los datos de entrada y salida se almacenan en el clúster de Apache Kafka. Por un lado, ofrece los beneficios de la tecnología de clúster del lado del servidor de Apache Kafka. Por otro lado, simplifica la escritura y la implementación de aplicaciones estándar de Scala y Java en el lado del cliente.