
Apache Kafka: arquitectura, conceptos, funciones y aplicaciones
Publicado: 2021-03-09Kafka se lanzó en 2011, todo gracias a LinkedIn. Desde entonces, ha sido testigo de un crecimiento increíble hasta el punto de que la mayoría de las empresas que figuran en Fortune 500 ahora lo utilizan. Es un producto altamente escalable, duradero y de alto rendimiento que puede manejar grandes cantidades de transmisión de datos. Pero, ¿es esa la única razón detrás de su tremenda popularidad? Bueno no. Ni siquiera hemos comenzado con sus características, la calidad que produce y la facilidad que brinda a los usuarios.
Nos sumergiremos en eso más tarde. Primero comprendamos qué es Kafka y dónde se usa.
Tabla de contenido
¿Qué es Apache Kafka?
Apache Kafka es un software de procesamiento de flujo de código abierto que tiene como objetivo ofrecer un alto rendimiento y una baja latencia mientras administra datos en tiempo real. Escrito en Java y Scala, Kafka brinda durabilidad a través de microservicios en memoria y tiene un papel integral que desempeñar en el mantenimiento de eventos de suministro para los servicios de transmisión de eventos complejos, también conocidos como CEP o sistemas de automatización.
Es un sistema distribuido excepcionalmente versátil ya prueba de fallos, que permite a empresas como Uber gestionar la correspondencia de pasajeros y conductores. También proporciona datos en tiempo real y mantenimiento proactivo para los productos domésticos inteligentes de British Gas, además de ayudar a LinkedIn a rastrear múltiples servicios en tiempo real.
A menudo empleado en la arquitectura de transmisión de datos en tiempo real para ofrecer análisis en tiempo real, Kafka es un sistema de mensajería rápido, robusto, escalable y de publicación y suscripción. Apache Kafka se puede utilizar como sustituto de MOM tradicional debido a su excelente compatibilidad y arquitectura flexible que le permite rastrear llamadas de servicio o datos de sensores de IoT.
Kafka funciona de manera brillante con Apache Flume/Flafka, Apache Spark Streaming, Apache Storm, HBase, Apache Flink y Apache Spark para la ingesta, investigación, análisis y procesamiento de datos de transmisión en tiempo real. Los intermediarios de Kafka también facilitan informes de seguimiento de baja latencia en Hadoop o Spark. Kafka también tiene un proyecto subsidiario llamado Kafka Stream que funciona como una herramienta efectiva para el análisis en tiempo real.

Arquitectura y componentes de Kafka
Kafka se utiliza para transmitir datos en tiempo real a múltiples sistemas de destinatarios. Kafka funciona como una capa central para desacoplar canalizaciones de datos en tiempo real. No encuentra mucho uso en cálculos directos. Es más compatible con los sistemas de alimentación de carril rápido, en tiempo real o basados en datos operativos, para transmitir una cantidad significativa de datos para el análisis de datos por lotes.
Los marcos Storm, Flink, Spark y CEP son algunos sistemas de datos con los que Kafka trabaja para realizar análisis en tiempo real, crear copias de seguridad, auditorías y más. También se puede integrar con grandes plataformas de datos o sistemas de bases de datos como RDBMS y Cassandra, Spark, etc., para procesamiento de datos, informes, etc.
El siguiente diagrama ilustra el ecosistema de Kafka:
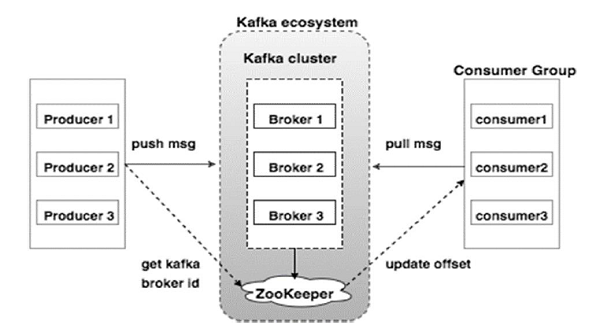
Fuente
Estos son los diversos componentes del ecosistema de Kafka, como se ilustra en el diagrama de arquitectura de Kafka:
1. Corredor Kafka
Kafka emula un clúster que comprende varios servidores, cada uno conocido como "intermediario". Cualquier comunicación entre clientes y servidores se adhiere a un protocolo TCP de alto rendimiento. Comprende más de un corredor sin estado para manejar cargas pesadas. Un único bróker de Kafka es capaz de administrar varios lacs de lecturas y escrituras cada segundo sin comprometer el rendimiento. Usan ZooKeeper para mantener grupos y elegir al corredor líder.
2. Guardián del zoológico de Kafka
Como se mencionó anteriormente, ZooKeeper está a cargo de administrar los corredores de Kafka. Cualquier nueva incorporación o falla de un corredor en el ecosistema de Kafka se notifica a un productor o consumidor a través de ZooKeeper.
3. Productores de Kafka
Ellos son los encargados de enviar los datos a los corredores. Los productores no dependen de intermediarios para acusar recibo de un mensaje. En cambio, determinan cuánto puede manejar un corredor y envían mensajes en consecuencia.

4. Consumidores de Kafka
Es responsabilidad de los consumidores de Kafka mantener un registro de la cantidad de mensajes consumidos por el desplazamiento de la partición. El reconocimiento de un mensaje indica que los mensajes enviados antes de que se hayan consumido. Para garantizar que el intermediario tenga un búfer de bytes listo para enviar al consumidor, el consumidor inicia una solicitud de extracción asincrónica. El ZooKeeper tiene un papel que desempeñar en el mantenimiento del valor de desplazamiento de omitir o rebobinar un mensaje.
El mecanismo de Kafka implica el envío de mensajes entre aplicaciones en sistemas distribuidos. Kafka emplea un registro de compromiso, que cuando se suscribe publica los datos presentes en una variedad de aplicaciones de transmisión. El remitente envía mensajes a Kafka, mientras que el destinatario recibe mensajes del flujo distribuido por Kafka.
Los mensajes se ensamblan en temas: una deliberación efectiva de Kafka. Un tema determinado representa un flujo organizado de datos en función de un tipo o clasificación específicos. El productor escribe mensajes para que los consumidores los lean y se basan en un tema.
A cada tema se le asigna un nombre único. Cualquier mensaje de un tema determinado enviado por un remitente es recibido por todos los usuarios que sintonizan ese tema. Una vez publicados, los datos de un tema no se pueden actualizar ni modificar.
Características de Kafka
- Kafka consta de un registro de compromiso perpetuo que le permite suscribirse y, posteriormente, publicar datos en múltiples sistemas o aplicaciones en tiempo real.
- Brinda a las aplicaciones la capacidad de controlar esos datos a medida que llegan. La API Streams en Apache Kafka es una biblioteca poderosa y liviana que facilita el procesamiento de datos por lotes sobre la marcha.
- Es una aplicación Java que le permite regular su flujo de trabajo y reduce significativamente cualquier requisito de mantenimiento.
- Kafka funciona como un "almacenamiento de la verdad" que distribuye datos a múltiples nodos al permitir la implementación de datos a través de múltiples sistemas de datos.
- El registro de confirmación de Kafka lo convierte en un sistema de almacenamiento confiable. Kafka crea réplicas/copias de seguridad de una partición que ayudan a prevenir la pérdida de datos (las configuraciones correctas pueden dar como resultado una pérdida de datos cero). Esto también evita fallas en el servidor y mejora la durabilidad de Kafka.
- Los temas en Kafka tienen miles de particiones, lo que lo hace capaz de manejar una cantidad arbitraria de datos y una gran carga.
- Kafka depende del kernel del sistema operativo para mover los datos a un ritmo rápido. Estos grupos de información están cifrados de extremo a extremo, del productor al sistema de archivos y al consumidor final.
- El procesamiento por lotes en Kafka aumenta la eficiencia de la compresión de datos y reduce la latencia de E/S.
Aplicaciones de Kafka
Muchas empresas que manejan grandes cantidades de datos diariamente usan Kafka.

- LinkedIn usa Kafka para rastrear la actividad del usuario y las métricas de rendimiento. Twitter lo combina con Storm para habilitar un marco de procesamiento de flujo.
- Square usa Kafka para facilitar el movimiento de todos los eventos del sistema a otros centros de datos de Square. Esto incluye registros, eventos personalizados y métricas.
- Otras empresas populares que aprovechan los beneficios de Kafka incluyen Netflix, Spotify, Uber, Tumblr, CloudFlare y PayPal.
¿Por qué debería aprender Apache Kafka?
Kafka es una excelente plataforma de transmisión de eventos que puede manejar, rastrear y monitorear datos en tiempo real de manera eficiente. Su arquitectura tolerante a fallas y escalable permite la integración de datos de baja latencia, lo que resulta en un alto rendimiento de transmisión de eventos. Kafka reduce significativamente el "tiempo de valor" de los datos.
Funciona como el sistema fundamental que produce información para las organizaciones al eliminar los "registros" en torno a los datos. Esto permite a los científicos y especialistas de datos acceder fácilmente a la información en cualquier momento.
Por estas razones, es la principal plataforma de transmisión elegida por muchas de las principales empresas y, por lo tanto, los candidatos con una calificación en Apache Kafka son muy buscados.
Si está interesado en obtener más información sobre Kafka, Big Data, debe consultar el Diploma PG de upGrad en Especialización en desarrollo de software en Big Data que ofrece más de 7 estudios de casos y proyectos y tutoría de profesores de clase mundial y expertos de la industria. El programa de 13 meses cubre 14 lenguajes de programación y enseña procesamiento de datos, MapReduce, almacenamiento de datos, procesamiento en tiempo real, procesamiento de Big Data en la nube, entre otras habilidades.
Consulte nuestros otros cursos de ingeniería de software en upGrad.