
Una interfaz de usuario de voz alternativa a los asistentes de voz
Publicado: 2022-03-10Para la mayoría de las personas, lo primero que les viene a la mente cuando piensan en las interfaces de usuario de voz son los asistentes de voz, como Siri, Amazon Alexa o Google Assistant. De hecho, los asistentes son el único contexto donde la mayoría de las personas alguna vez han usado la voz para interactuar con un sistema informático.
Si bien los asistentes de voz han llevado las interfaces de usuario de voz a la corriente principal, el paradigma del asistente no es la única, ni siquiera la mejor manera de usar, diseñar y crear interfaces de usuario de voz.
En este artículo, repasaré los problemas que sufren los asistentes de voz y presentaré un nuevo enfoque para las interfaces de usuario de voz que llamo interacciones de voz directas.
Los asistentes de voz son chatbots basados en voz
Un asistente de voz es una pieza de software que utiliza lenguaje natural en lugar de iconos y menús como interfaz de usuario. Los asistentes generalmente responden preguntas y, a menudo, intentan ayudar al usuario de manera proactiva.
En lugar de transacciones y comandos sencillos, los asistentes imitan una conversación humana y utilizan el lenguaje natural de forma bidireccional como modalidad de interacción, lo que significa que toma información del usuario y responde al usuario mediante el uso del lenguaje natural.
Los primeros asistentes fueron sistemas de preguntas y respuestas basados en diálogos. Un ejemplo temprano es Clippy de Microsoft, que infamemente trató de ayudar a los usuarios de Microsoft Office dándoles instrucciones basadas en lo que pensaba que el usuario estaba tratando de lograr. Hoy en día, un caso de uso típico para el paradigma del asistente son los chatbots, que a menudo se usan para la atención al cliente en una discusión de chat.
Los asistentes de voz, por otro lado, son chatbots que usan la voz en lugar de escribir y escribir . La entrada del usuario no son selecciones o texto, sino voz, y la respuesta del sistema también se pronuncia en voz alta. Estos asistentes pueden ser asistentes generales, como Google Assistant o Alexa, que pueden responder una multitud de preguntas de manera razonable, o asistentes personalizados creados para un propósito especial, como pedidos de comida rápida.
Aunque a menudo la entrada del usuario es solo una palabra o dos y se puede presentar como selecciones en lugar de texto real, a medida que la tecnología evoluciona, las conversaciones serán más abiertas y complejas . La primera característica definitoria de los chatbots y los asistentes es el uso del lenguaje natural y el estilo de conversación en lugar de los íconos, los menús y el estilo transaccional que define la experiencia típica del usuario de una aplicación móvil o un sitio web.
Lectura recomendada : Creación de un chatbot de IA simple con Web Speech API y Node.js
La segunda característica definitoria que se deriva de las respuestas del lenguaje natural es la ilusión de una persona. El tono, la calidad y el lenguaje que utiliza el sistema definen tanto la experiencia del asistente, la ilusión de empatía y susceptibilidad al servicio, como su personalidad. La idea de una buena experiencia de asistente es como estar comprometido con una persona real .
Dado que la voz es la forma más natural de comunicarnos, esto puede sonar increíble, pero existen dos problemas importantes con el uso de respuestas de lenguaje natural. Uno de estos problemas, relacionado con qué tan bien las computadoras pueden imitar a los humanos, podría solucionarse en el futuro con el desarrollo de tecnologías de inteligencia artificial conversacional , pero el problema de cómo los cerebros humanos manejan la información es un problema humano, no solucionable en un futuro previsible. Veamos estos problemas a continuación.
Dos problemas con las respuestas del lenguaje natural
Las interfaces de usuario de voz son, por supuesto, interfaces de usuario que utilizan la voz como modalidad. Pero la modalidad de voz se puede usar en ambas direcciones: para ingresar información del usuario y enviar información del sistema al usuario. Por ejemplo, algunos ascensores usan síntesis de voz para confirmar la selección del usuario después de que el usuario presiona un botón. Más adelante analizaremos las interfaces de usuario de voz que solo usan la voz para ingresar información y usan las interfaces de usuario gráficas tradicionales para mostrar la información al usuario.
Los asistentes de voz, por otro lado, usan la voz tanto para la entrada como para la salida . Este enfoque tiene dos problemas principales:
Problema #1: La imitación de un ser humano falla
Como humanos, tenemos una inclinación innata a atribuir rasgos humanos a objetos no humanos. Vemos los rasgos de un hombre en una nube que pasa a la deriva o miramos un sándwich y parece que nos sonríe. Esto se llama antropomorfismo .

Este fenómeno también se aplica a los asistentes y se desencadena por sus respuestas de lenguaje natural. Si bien una interfaz gráfica de usuario puede construirse algo neutral, no hay forma de que un humano no pueda comenzar a pensar si la voz de alguien pertenece a una persona joven o mayor o si es hombre o mujer. Debido a esto, el usuario casi comienza a pensar que el asistente es realmente un humano.
Sin embargo, los humanos somos muy buenos detectando falsificaciones . Por extraño que parezca, cuanto más se acerca algo a parecerse a un ser humano, más nos empiezan a molestar las pequeñas desviaciones. Hay un sentimiento de escalofrío hacia algo que trata de parecerse a un humano pero que no está a la altura. En robótica y animaciones por computadora esto se conoce como el "valle inquietante".

Cuanto mejor y más humano intentemos hacer el asistente, más espeluznante y decepcionante puede ser la experiencia del usuario cuando algo sale mal. Todos los que han probado los asistentes probablemente se han topado con el problema de responder con algo que se siente idiota o incluso grosero.
El valle inquietante de los asistentes de voz plantea un problema de calidad en la experiencia del usuario asistente que es difícil de superar. De hecho, la prueba de Turing (llamada así por el famoso matemático Alan Turing) se pasa cuando un evaluador humano que exhibe una conversación entre dos agentes no puede distinguir entre cuál de ellos es una máquina y cuál es un humano. Hasta ahora, nunca se ha pasado.
Esto significa que el paradigma del asistente establece una promesa de una experiencia de servicio similar a la humana que nunca se puede cumplir y el usuario seguramente se decepcionará. Las experiencias exitosas solo aumentan la decepción final, ya que el usuario comienza a confiar en su asistente humano.
Problema 2: interacciones secuenciales y lentas
El segundo problema de los asistentes de voz es que la naturaleza por turnos de las respuestas del lenguaje natural provoca retrasos en la interacción. Esto se debe a cómo nuestro cerebro procesa la información.
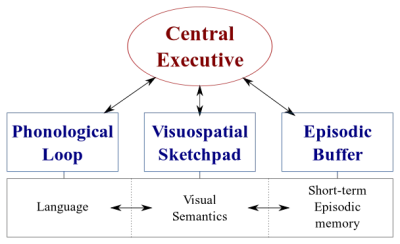
Hay dos tipos de sistemas de procesamiento de datos en nuestro cerebro:
- Un sistema lingüístico que procesa el habla;
- Un sistema visuoespacial que se especializa en el procesamiento de información visual y espacial.
Estos dos sistemas pueden operar en paralelo, pero ambos procesan solo una cosa a la vez . Es por eso que puede hablar y conducir un automóvil al mismo tiempo, pero no puede enviar mensajes de texto y conducir porque ambas actividades ocurrirían en el sistema visuoespacial.

Del mismo modo, cuando está hablando con el asistente de voz, el asistente debe permanecer en silencio y viceversa. Esto crea una conversación por turnos , donde la otra parte siempre es totalmente pasiva.
Sin embargo, considera un tema difícil que quieras discutir con tu amigo. Probablemente hablaría cara a cara en lugar de por teléfono, ¿verdad? Esto se debe a que en una conversación cara a cara usamos la comunicación no verbal para dar retroalimentación visual en tiempo real a nuestro interlocutor. Esto crea un ciclo de intercambio de información bidireccional y permite que ambas partes participen activamente en la conversación simultáneamente.
Los asistentes no brindan comentarios visuales en tiempo real. Se basan en una tecnología llamada end-pointing para decidir cuándo el usuario ha dejado de hablar y responde solo después de eso. Y cuando responden, no toman ninguna entrada del usuario al mismo tiempo. La experiencia es totalmente unidireccional y por turnos.
En una conversación cara a cara bidireccional y en tiempo real, ambas partes pueden reaccionar inmediatamente a las señales visuales y lingüísticas. Esto utiliza los diferentes sistemas de procesamiento de información del cerebro humano y la conversación se vuelve más fluida y eficiente.
Los asistentes de voz están atascados en el modo unidireccional porque usan lenguaje natural tanto como canales de entrada como de salida. Si bien la voz es hasta cuatro veces más rápida que escribir para ingresar, es significativamente más lenta de digerir que leer. Debido a que la información debe procesarse secuencialmente , este enfoque solo funciona bien para comandos simples como "apagar las luces" que no requieren mucho trabajo del asistente.

Anteriormente, prometí discutir las interfaces de usuario de voz que emplean voz solo para ingresar datos del usuario. Este tipo de interfaces de usuario de voz se beneficia de las mejores partes de las interfaces de usuario de voz: naturalidad, velocidad y facilidad de uso, pero no sufre las partes malas: un valle inquietante e interacciones secuenciales.
Consideremos esta alternativa.
Una mejor alternativa al asistente de voz
La solución para superar estos problemas en los asistentes de voz es dejar de lado las respuestas de lenguaje natural y reemplazarlas con comentarios visuales en tiempo real. Cambiar la retroalimentación a visual permitirá al usuario dar y recibir retroalimentación simultáneamente. Esto permitirá que la aplicación reaccione sin interrumpir al usuario y permitiendo un flujo de información bidireccional. Debido a que el flujo de información es bidireccional, su rendimiento es mayor.
Actualmente, los principales casos de uso de los asistentes de voz son configurar alarmas, reproducir música, consultar el clima y hacer preguntas simples. Todas estas son tareas de bajo riesgo que no frustran demasiado al usuario cuando fallan.
Como David Pierce del Wall Street Journal escribió una vez:
“No puedo imaginarme reservar un vuelo o administrar mi presupuesto a través de un asistente de voz, o hacer un seguimiento de mi dieta gritando ingredientes a mi altavoz”.
—David Pierce del Wall Street Journal
Estas son tareas con gran cantidad de información que deben realizarse correctamente.
Sin embargo, eventualmente, la interfaz de usuario de voz fallará. La clave es cubrir esto lo más rápido posible. Muchos errores ocurren al escribir en un teclado o incluso en una conversación cara a cara. Sin embargo, esto no es para nada frustrante ya que el usuario puede recuperarse simplemente haciendo clic en la tecla de retroceso e intentarlo de nuevo o pedir una aclaración.
Esta rápida recuperación de errores permite que el usuario sea más eficiente y no lo obliga a entablar una conversación extraña con un asistente.
Interacciones de voz directas
En la mayoría de las aplicaciones, las acciones se realizan manipulando elementos gráficos en la pantalla, empujando o deslizando (en pantallas táctiles), haciendo clic con el mouse y/o presionando botones en un teclado. La entrada de voz se puede agregar como una opción o modalidad adicional para manipular estos elementos gráficos. Este tipo de interacción se puede llamar interacción de voz directa .
La diferencia entre las interacciones de voz directas y los asistentes es que en lugar de pedirle a un avatar, el asistente, que realice una tarea, el usuario manipula directamente la interfaz gráfica de usuario con la voz.
“¿No es esto semántica?”, podrías preguntar. Si va a hablar con la computadora, ¿realmente importa si está hablando directamente con la computadora o a través de una persona virtual? En ambos casos, ¡solo estás hablando con una computadora!
Sí, la diferencia es sutil, pero fundamental. Al hacer clic en un botón o elemento de menú en una GUI ( interfaz gráfica de usuario), es evidente que estamos operando una máquina. No hay ilusión de una persona. Al reemplazar ese clic con un comando de voz, estamos mejorando la interacción humano-computadora. Con el paradigma del asistente, por otro lado, estamos creando una versión deteriorada de la interacción de humano a humano y, por lo tanto, estamos viajando hacia el valle inquietante.
La combinación de funcionalidades de voz en la interfaz gráfica de usuario también ofrece el potencial de aprovechar el poder de diferentes modalidades. Si bien el usuario puede usar la voz para operar la aplicación, también tiene la capacidad de usar la interfaz gráfica tradicional. Esto permite al usuario cambiar entre el tacto y la voz sin problemas y elegir la mejor opción en función de su contexto y tarea.
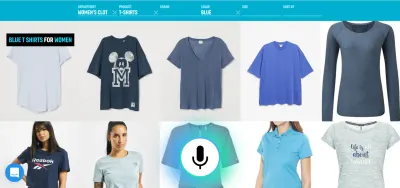
Por ejemplo, la voz es un método muy eficiente para ingresar información valiosa. Seleccionar entre un par de alternativas válidas, tocar o hacer clic probablemente sea mejor. Luego, el usuario puede reemplazar la escritura y la navegación diciendo algo como "Muéstrame los vuelos de Londres a Nueva York que salen mañana" y seleccionar la mejor opción de la lista usando el tacto.
Ahora puede preguntar: "Está bien, esto se ve muy bien, entonces, ¿por qué no hemos visto ejemplos de tales interfaces de usuario de voz antes? ¿Por qué las principales empresas tecnológicas no están creando herramientas para algo como esto? Bueno, probablemente hay muchas razones para eso. Una de las razones es que el paradigma actual de los asistentes de voz es probablemente la mejor manera de aprovechar los datos que obtienen de los usuarios finales. Otra razón tiene que ver con la forma en que se construye su tecnología de voz.
Una interfaz de usuario de voz que funcione bien requiere dos partes distintas:
- Reconocimiento de voz que convierte el habla en texto;
- Componentes de comprensión del lenguaje natural que extraen el significado de ese texto.
La segunda parte es la magia que convierte los enunciados “Apaga las luces de la sala de estar” y “Por favor, apaga las luces de la sala de estar” en la misma acción.
Lectura recomendada : Cómo crear su propia acción para Google Home usando API.AI
Si alguna vez usó un asistente con pantalla (como Siri o el Asistente de Google), probablemente haya notado que obtiene la transcripción casi en tiempo real, pero después de que deja de hablar, toma unos segundos antes de que el sistema realmente realiza la acción que ha solicitado. Esto se debe a que tanto el reconocimiento de voz como la comprensión del lenguaje natural tienen lugar secuencialmente.
Veamos cómo se podría cambiar esto.
Comprensión del lenguaje hablado en tiempo real: la salsa secreta para comandos de voz más eficientes
La rapidez con que una aplicación reacciona a la entrada del usuario es un factor importante en la experiencia general del usuario de la aplicación. La innovación más importante del iPhone original fue la pantalla táctil extremadamente receptiva y reactiva. La capacidad de una interfaz de usuario de voz para reaccionar instantáneamente a la entrada de voz es igualmente importante.
Para establecer un bucle de intercambio de información bidireccional rápido entre el usuario y la interfaz de usuario, la interfaz gráfica de usuario habilitada por voz debería poder reaccionar instantáneamente, incluso en medio de una oración, siempre que el usuario diga algo procesable. Esto requiere una técnica llamada transmisión de comprensión del lenguaje hablado .
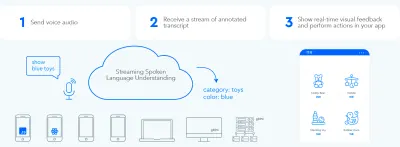
A diferencia de los sistemas tradicionales de asistente de voz por turnos que esperan a que el usuario deje de hablar antes de procesar la solicitud del usuario, los sistemas que utilizan la transmisión de comprensión del lenguaje hablado intentan comprender activamente la intención del usuario desde el momento en que comienza a hablar. Tan pronto como el usuario dice algo procesable, la interfaz de usuario reacciona instantáneamente.
La respuesta instantánea valida de inmediato que el sistema comprende al usuario y lo alienta a continuar. Es análogo a un movimiento de cabeza o un breve "a-ha" en la comunicación de persona a persona. Esto da como resultado expresiones más largas y complejas admitidas. Respectivamente, si el sistema no entiende al usuario o si el usuario habla mal, la retroalimentación instantánea permite una recuperación rápida . El usuario puede corregir inmediatamente y continuar, o incluso corregirse verbalmente: "Quiero esto, no, quise decir, quiero eso". Puede probar este tipo de aplicación usted mismo en nuestra demostración de búsqueda por voz.
Como puede ver en la demostración, la retroalimentación visual en tiempo real permite al usuario corregirse a sí mismo de forma natural y lo alienta a continuar con la experiencia de voz. Como no están confundidos por una persona virtual, pueden relacionarse con posibles errores de manera similar a los errores tipográficos, no como insultos personales. La experiencia es más rápida y natural porque la información que recibe el usuario no está limitada por la velocidad típica del habla de unas 150 palabras por minuto.
Lectura recomendada : Diseño de experiencias de voz por Lyndon Cerejo
Conclusiones
Si bien los asistentes de voz han sido, con mucho, el uso más común para las interfaces de usuario de voz hasta el momento, el uso de respuestas en lenguaje natural los hace ineficientes y poco naturales. La voz es una excelente modalidad para ingresar información, pero escuchar a una máquina hablando no es muy inspirador. Este es el gran problema de los asistentes de voz.
Por lo tanto, el futuro de la voz no debe estar en las conversaciones con una computadora, sino en reemplazar las tediosas tareas del usuario con la forma más natural de comunicarse: el habla . Las interacciones de voz directas se pueden utilizar para mejorar la experiencia de llenado de formularios en aplicaciones web o móviles, para crear mejores experiencias de búsqueda y para permitir una forma más eficiente de controlar o navegar en una aplicación.
Los diseñadores y desarrolladores de aplicaciones buscan constantemente formas de reducir la fricción en sus aplicaciones o sitios web. Mejorar la interfaz gráfica de usuario actual con una modalidad de voz permitiría interacciones de usuario varias veces más rápidas, especialmente en ciertas situaciones, como cuando el usuario final está en el móvil y está en movimiento y escribir es difícil. De hecho, la búsqueda por voz puede ser hasta cinco veces más rápida que una interfaz de usuario de filtrado de búsqueda tradicional, incluso cuando se utiliza una computadora de escritorio.
La próxima vez, cuando esté pensando en cómo puede hacer que una determinada tarea de usuario en su aplicación sea más fácil de usar, más agradable de usar, o si está interesado en aumentar las conversiones, considere si esa tarea de usuario se puede describir con precisión en lenguaje natural. En caso afirmativo, complemente su interfaz de usuario con una modalidad de voz, pero no obligue a sus usuarios a conversar con una computadora.
Recursos
- “Voice First versus las interfaces de usuario multimodales del futuro”, Joan Palmiter Bajorek, UXmatters
- “Pautas para crear aplicaciones habilitadas para voz productivas”, Hannes Heikinheimo, Speechly
- "6 razones por las que sus aplicaciones de pantalla táctil deberían tener capacidades de voz", Ottomatias Peura, UXmatters
- Mezclando tangible e intangible: diseño de interfaces multimodales usando Adobe XD, Nick Babich, Smashing Magazine
( Adobe XD puede ser para crear prototipos de algo similar ) - "Eficiencia a la velocidad del sonido: la promesa de las operaciones habilitadas por voz", Eric Turkington, RAIN
- Una demostración que muestra comentarios visuales en tiempo real en el filtrado de búsqueda por voz de comercio electrónico (versión de video)
- Speechly proporciona herramientas de desarrollo para este tipo de interfaces de usuario.
- Alternativa de código abierto: voice2json