
Una guía para la regresión lineal usando Scikit [con ejemplos]
Publicado: 2021-06-18Los algoritmos de aprendizaje supervisado son generalmente de dos tipos: regresión y clasificación con predicción de salidas continuas y discretas.
El siguiente artículo discutirá la regresión lineal y su implementación utilizando una de las bibliotecas de aprendizaje automático más populares de python, la biblioteca Scikit-learn. Las herramientas para el aprendizaje automático y los modelos estadísticos están disponibles en la biblioteca de python para la clasificación, la regresión, la agrupación en clústeres y la reducción de la dimensionalidad. Escrita en el lenguaje de programación python, la biblioteca se basa en las bibliotecas python NumPy, SciPy y Matplotlib.
Tabla de contenido
Regresión lineal
La regresión lineal realiza la tarea de regresión bajo el método de aprendizaje supervisado. Sobre la base de variables independientes, se predice un valor objetivo. El método se utiliza principalmente para pronosticar e identificar una relación entre las variables.
En álgebra, el término linealidad significa una relación lineal entre variables. Se deduce una línea recta entre las variables en un espacio bidimensional.
Si una línea es una gráfica entre las variables independientes en el eje X y las variables dependientes en el eje Y, se logra una línea recta a través de la regresión lineal que mejor se ajusta a los puntos de datos.
La ecuación de una línea recta está en la forma de

Y = mx + b
Donde, b= intersección
m= pendiente de la recta
Por lo tanto, a través de la regresión lineal,
- Los valores más óptimos para el intercepto y la pendiente se determinan en dos dimensiones.
- No hay cambios en las variables x e y, ya que son las características de los datos y, por lo tanto, siguen siendo las mismas.
- Solo se pueden controlar los valores de intersección y pendiente.
- Pueden existir múltiples líneas rectas basadas en los valores de pendiente e intersección, sin embargo, a través del algoritmo de regresión lineal, se ajustan múltiples líneas en los puntos de datos y se devuelve la línea con el menor error.
Regresión lineal con Python
Para implementar la regresión lineal en python, se deben aplicar los paquetes adecuados junto con sus funciones y clases. El paquete NumPy en Python es de código abierto y permite varias operaciones sobre los arreglos, tanto arreglos simples como multidimensionales.
Otra biblioteca ampliamente utilizada en python es Scikit-learn, que se utiliza para problemas de aprendizaje automático.
Scikit-learN
La biblioteca Scikit-learn ofrece a los desarrolladores algoritmos basados en aprendizaje supervisado y no supervisado. La biblioteca de código abierto de python está diseñada para tareas de aprendizaje automático.
Los científicos de datos pueden importar los datos, preprocesarlos, trazarlos y predecir datos mediante el uso de scikit-learn.
David Cournapeau desarrolló scikit-learn por primera vez en 2007, y la biblioteca ha experimentado un crecimiento desde hace décadas.
Las herramientas proporcionadas por scikit-learn son:
- Regresión: Incluye la Regresión Logística y la Regresión Lineal
- Clasificación: Incluye el método de K-Vecinos Más Cercanos
- Selección de un modelo
- Agrupación: incluye K-Means++ y K-Means
- preprocesamiento
Las ventajas de la biblioteca son:
- El aprendizaje y la implementación de la biblioteca son fáciles.
- Es una biblioteca de código abierto y, por lo tanto, gratuita.
- Los aspectos del aprendizaje automático se pueden cubrir, incluido el aprendizaje profundo.
- Es un paquete potente y versátil.
- La biblioteca dispone de documentación detallada.
- Uno de los kits de herramientas más utilizados para el aprendizaje automático.
Importación de scikit-learn
El scikit-learn debe instalarse primero mediante pip o mediante conda.
- Requisitos: versión de 64 bits de python 3 con bibliotecas instaladas NumPy y Scipy. También para la visualización de gráficos de datos, se requiere matplotlib.
Comando de instalación: pip install -U scikit-learn
Luego verifique si la instalación está completa
Instalación de Numpy, Scipy y matplotlib
La instalación se puede confirmar a través de:
Fuente
Regresión lineal a través de Scikit-learn
La implementación de la regresión lineal a través del paquete scikit-learn implica los siguientes pasos.
- Los paquetes y las clases requeridas deben ser importados.
- Se requieren datos para trabajar y también para llevar a cabo las transformaciones apropiadas.
- Se debe crear un modelo de regresión y ajustarlo con los datos existentes.
- Se comprobarán los datos de ajuste del modelo para analizar si el modelo creado es satisfactorio.
- Las predicciones deben hacerse a través de la aplicación del modelo.
El paquete NumPy y la clase LinearRegression se importarán desde sklearn.linear_model.

Fuente
Las funcionalidades requeridas para la regresión lineal de sklearn están todas presentes para implementar finalmente la regresión lineal. La clase sklearn.linear_model.LinearRegression se utiliza para realizar análisis de regresión (tanto lineal como polinomial) y realizar predicciones.
Para cualquier algoritmo de aprendizaje automático y scikit learn regresión lineal , el conjunto de datos debe importarse primero. Hay tres opciones disponibles en Scikit-learn para obtener los datos:
- Conjuntos de datos como la clasificación del iris o el conjunto de regresión para el precio de la vivienda de Boston.
- Los conjuntos de datos del mundo real se pueden descargar de Internet directamente a través de las funciones predefinidas de Scikit-learn.
- Se puede generar un conjunto de datos aleatoriamente para compararlo con un patrón específico a través del generador de datos Scikit-learn.
Cualquiera que sea la opción seleccionada, los conjuntos de datos del módulo deben importarse.

importar sklearn.datasets como conjuntos de datos
1. El conjunto de clasificación de iris
iris = conjuntos de datos.load_iris()
El iris del conjunto de datos se almacena como un campo de datos de matriz 2D de n_samples * n_features. Su importación se realiza como objeto de un diccionario. Contiene todos los datos necesarios junto con los metadatos.
Las funciones DESCR, forma y _names se pueden usar para obtener descripciones y formato de los datos. La impresión de los resultados de la función mostrará la información del conjunto de datos que podría ser necesaria mientras se trabaja en el conjunto de datos del iris.
El siguiente código cargará la información del conjunto de datos del iris.
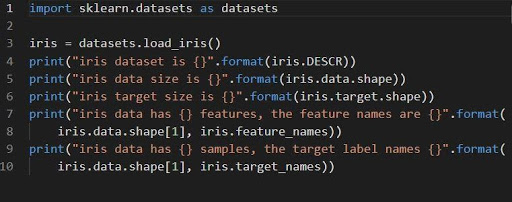
Fuente
2. Generación de datos de regresión
Si no hay ningún requisito de datos incorporados, entonces los datos se pueden generar a través de una distribución que se puede elegir.
Generando datos de regresión con un conjunto de 1 característica informativa y 1 característica.
X , Y = conjuntos de datos.make_regression(n_features=1, n_informative=1)
Los datos generados se guardan en un conjunto de datos 2D con los objetos x e y. Las características de los datos generados se pueden cambiar cambiando los parámetros de la función make_regression.
En este ejemplo, los parámetros de las funciones y funciones informativas se cambian de un valor predeterminado de 10 a 1.
Otros parámetros considerados son las muestras y los objetivos donde se controla el número de variables objetivo y de muestra rastreadas.
- Las funciones que proporcionan información útil a los algoritmos de ML se denominan funciones informativas, mientras que las que no son útiles se denominan funciones no informativas.
3. Trazado de datos
Los datos se trazan utilizando la biblioteca matplotlib. Primero, se debe importar matplotlib.
Importar matplotlib.pyplot como plt
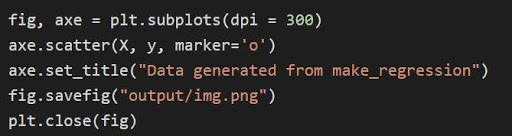
El gráfico anterior se traza a través de matplotlib a través del código
Fuente
En el código anterior:
- Las variables de tupla se desempaquetan y se guardan como variables separadas en la línea 1 del código. Por lo tanto, los atributos separados se pueden manipular y guardar.
- El conjunto de datos x, y se usa para generar un diagrama de dispersión a través de la línea 2. Con la disponibilidad del parámetro de marcador en matplotlib, las imágenes se mejoran al marcar los puntos de datos con un punto (o).
- El título de la trama generada se establece a través de la línea 3.
- La figura se puede guardar como un archivo de imagen .png y luego se cierra la figura actual.
El gráfico de regresión generado a través del código anterior es
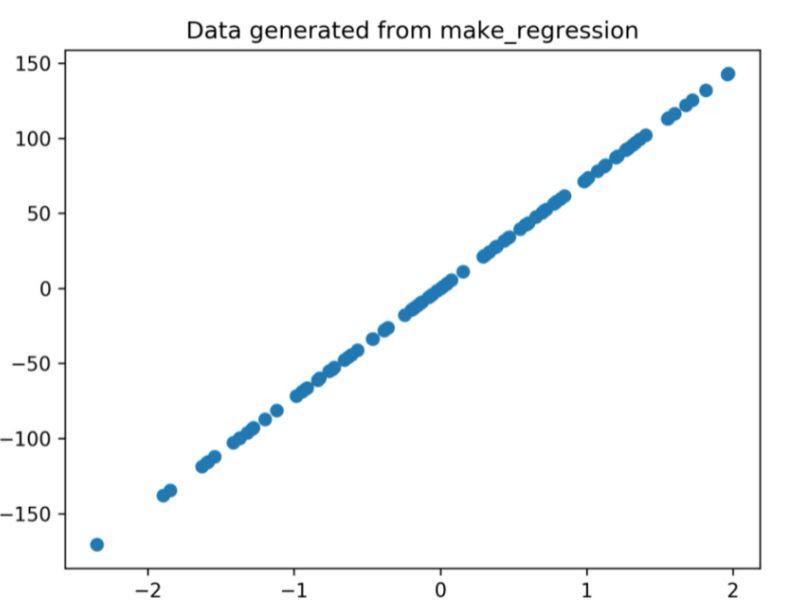
Figura 1: El gráfico de regresión generado a partir del código anterior.
4. Implementación del algoritmo de regresión lineal
Usando los datos de muestra del precio de la vivienda de Boston, el algoritmo de regresión lineal de Scikit-learn se implementa en el siguiente ejemplo. Al igual que otros algoritmos de ML, el conjunto de datos se importa y luego se entrena con los datos anteriores.
Las empresas utilizan el método de regresión lineal, ya que es un modelo predictivo que predice la relación entre una cantidad numérica y sus variables con el valor de salida con el significado de tener un valor en la realidad.
Cuando está presente un registro de datos anteriores, el modelo se puede aplicar mejor, ya que puede predecir los resultados futuros de lo que sucederá en el futuro si hay una continuación del patrón.
Matemáticamente, los datos se pueden ajustar para minimizar la suma de todos los residuos que existen entre los puntos de datos y el valor predicho.
El siguiente fragmento muestra la implementación de la regresión lineal de sklearn.
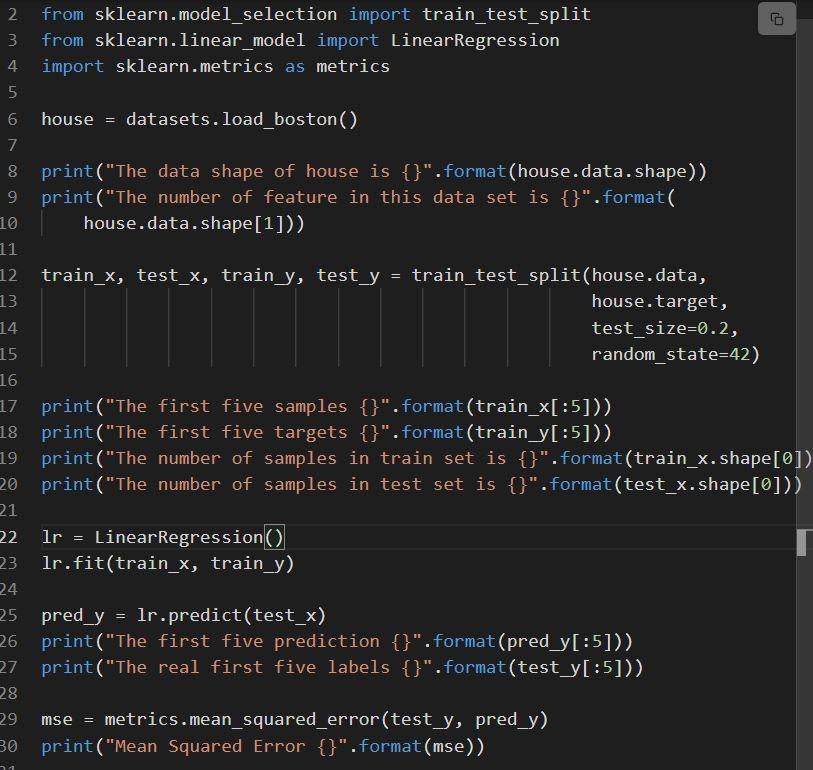
Fuente
El código se explica como:
- La línea 6 carga el conjunto de datos llamado load_boston.
- El conjunto de datos se divide en la línea 12, es decir, el conjunto de entrenamiento con un 80 % de datos y el conjunto de la prueba con un 20 % de datos.
- Creación de un modelo de regresión lineal en la línea 23 y luego entrenado en.
- El rendimiento del modelo se evalúa en la línea 29 llamando a mean_squared_error.
El gráfico de regresión lineal de Sklearn se muestra a continuación:
Modelo de regresión lineal de los datos de muestra de los precios de la vivienda en Boston
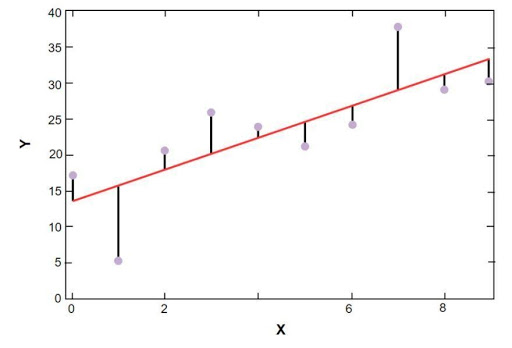
Fuente
En la figura anterior, la línea roja representa el modelo lineal que se resolvió para los datos de muestra del precio de la vivienda en Boston. Los puntos azules representan los datos originales y la distancia entre la línea roja y los puntos azules representan la suma del residual. El objetivo del modelo de regresión lineal de scikit-learn es reducir la suma de los residuos.
Conclusión
El artículo discutió la regresión lineal y su implementación mediante el uso de un paquete de Python de código abierto llamado scikit-learn. Por ahora, puede obtener el concepto de cómo implementar la regresión lineal a través de este paquete. Vale la pena aprender a usar la biblioteca para el análisis de datos.
Si tiene interés en explorar más el tema, como la implementación de paquetes de python en el aprendizaje automático y los problemas relacionados con la IA, puede consultar el curso Maestría en Ciencias en Aprendizaje Automático e IA ofrecido por upGrad . Dirigido a profesionales principiantes de 21 a 45 años, el curso tiene como objetivo capacitar a los estudiantes en aprendizaje automático a través de más de 650 horas de capacitación en línea, más de 25 estudios de casos y tareas. Certificado por LJMU , el curso ofrece la orientación perfecta y asistencia para la colocación laboral. Si tienes alguna duda o consulta, déjanos un mensaje, estaremos encantados de contactar contigo.