
Javaを使用した機械学習とは何ですか? それを実装する方法は?
公開: 2021-03-10目次
機械学習とは何ですか?
機械学習は、利用可能なデータ、例、経験から学習して人間の行動や知能を模倣する人工知能の一部門です。 機械学習を使用して作成されたプログラムは、人間が手動でコードを記述しなくても、独自にロジックを構築できます。
それはすべて、1950年代初頭のチューリングテストで始まりました。アランターニングは、コンピューターが本当の知性を持つためには、それが人間でもあることを人間に操作または納得させる必要があると結論付けました。 機械学習は比較的古い概念ですが、コンピューターが複雑なアルゴリズムを処理できるようになったため、この新しい分野が実現の対象となるのは今日だけです。 機械学習アルゴリズムは過去10年間で進化し、複雑な計算スキルが含まれるようになりました。これにより、模倣機能が強化されました。
機械学習アプリケーションも驚くべき速さで増加しています。 医療、金融、分析、教育から製造、マーケティング、政府の業務に至るまで、機械学習テクノロジーを実装した後、すべての業界で品質と効率が大幅に向上しました。 世界中で質的な改善が広まっているため、機械学習の専門家の需要が高まっています。
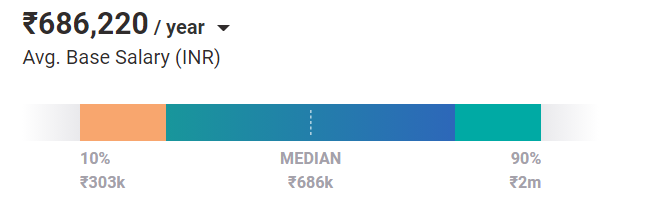
今日、機械学習エンジニアの平均給与は、年間686,220ポンドの価値があります。 そして、それはエントリーレベルのポジションの場合です。 経験とスキルがあれば、インドで年間最大200万ポンドを稼ぐことができます。
機械学習アルゴリズムの種類
機械学習アルゴリズムには次の3つのタイプがあります。
1.教師あり学習:このタイプの学習では、トレーニングデータセットがアルゴリズムを導き、正確な予測または分析的決定を行います。 過去のトレーニングデータセットからの学習を使用して、新しいデータを処理します。 教師あり学習機械学習モデルの例を次に示します。

- 線形回帰
- ロジスティック回帰
- デシジョンツリー
2.教師なし学習:このタイプの学習では、機械学習モデルはラベルのない情報から学習します。 オブジェクトをグループ化したり、オブジェクト間の関係を理解したり、それらの統計的特性を利用して分析を行ったりすることにより、データクラスタリングを採用しています。 教師なし学習アルゴリズムの例は次のとおりです。
- K-meansクラスタリング
- 階層的クラスタリング
3.強化学習:このプロセスは、ヒットとトライアルに基づいています。 それは、空間や環境と相互作用することによって学習しています。 RLアルゴリズムは、環境と相互作用し、最善の行動方針を決定することにより、過去の経験から学習します。
Javaで機械学習を実装する方法は?
Javaは、機械学習アルゴリズムの実装に使用されるトッププログラミング言語の1つです。 そのライブラリのほとんどはオープンソースであり、広範なドキュメントサポート、簡単なメンテナンス、市場性、および簡単な読みやすさを提供します。
人気に応じて、Javaで機械学習を実装するために使用される機械学習ライブラリのトップ10を次に示します。
1.アダムス
高度なデータマイニングと機械学習システム(ADAMS)は、斬新で柔軟なワークフローシステムの構築と、複雑な実世界のプロセスの管理に関係しています。 ADAMSは、手動の入出力接続を行う代わりに、ツリーのようなアーキテクチャを使用してデータフローを管理します。
明示的な接続が不要になります。 これは「少ないほど多い」という原則に基づいており、検索、視覚化、およびデータ駆動型の視覚化を実行します。 ADAMSは、データ処理、データストリーミング、データベースの管理、スクリプト作成、およびドキュメント作成に長けています。
2. JavaML
JavaMLは、ソフトウェアエンジニア、プログラマー、データサイエンティスト、および研究者をサポートするためにJava用に作成されたさまざまなMLおよびデータマイニングアルゴリズムを提供します。 すべてのアルゴリズムには、GUIがない場合でも、使いやすく、広範なドキュメントサポートを備えた共通のインターフェイスがあります。
他のクラスタリングアルゴリズムと比較して、実装はかなり単純で簡単です。 そのコア機能には、データ操作、ドキュメント化、データベース管理、データ分類、クラスタリング、特徴選択などが含まれます。
世界のトップ大学(修士、エグゼクティブ大学院プログラム、ML&AIの高度な証明書プログラム)からオンラインで機械学習コースに参加して、キャリアを早急に進めましょう。
3.WEKA
Wekaは、ディープラーニングをサポートするJava用に作成されたオープンソースの機械学習ライブラリでもあります。 一連の機械学習アルゴリズムを提供し、データマイニング、データ準備、データクラスタリング、データの視覚化、回帰などのデータ操作で幅広く使用されています。
例:小さな糖尿病データセットを使用してこれを示します。
ステップ1 :Wekaを使用してデータをロードする
| インポートweka.core.Instances; インポートweka.core.converters.ConverterUtils.DataSource; パブリッククラスメイン{ public static void main(String [] args)は例外をスローします{ //データソースを指定する DataSource dataSource = new DataSource(“ data.arff”); //データセットをロードします インスタンスdataInstances=dataSource.getDataSet(); //インスタンスの数を表示します log.info( "ロードされたインスタンスの数は次のとおりです:" + dataInstances.numInstances()); log.info(“ data:” + dataInstances.toString()); } } |
ステップ2:データセットには768個のインスタンスがあります。 属性の数、つまり9にアクセスする必要があります。
| log.info( "データセット内の属性(機能)の数:" + dataInstances.numAttributes()); |
ステップ3 :モデルを作成してクラスの数を見つける前に、ターゲット列を決定する必要があります。
| //ラベルインデックスを特定する dataInstances.setClassIndex(dataInstances.numAttributes()– 1); //の数を取得する log.info( "クラスの数:" + dataInstances.numClasses()); |
ステップ4 :単純なツリー分類器J48を使用してモデルを構築します。
| //デシジョンツリー分類子を作成します J48 treeClassifier = new J48(); treeClassifier.setOptions(new String [] {“ -U”}); treeClassifier.buildClassifier(dataInstances); |
上記のコードは、モデルのトレーニングに必要なデータインスタンスで構成されるプルーニングされていないツリーを作成する方法を示しています。 モデルトレーニング後にツリー構造が印刷されると、ルールが内部でどのように構築されたかを判断できます。
| プラス<=127 | 質量<=26.4 | | preg <= 7:tested_negative(117.0 / 1.0) | | preg> 7 | | | 質量<=0:tested_positive(2.0) | | | 質量>0:tested_negative(13.0) | 質量>26.4 | | 年齢<=28:tested_negative(180.0 / 22.0) | | 28歳以上 | | | plas <= 99:tested_negative(55.0 / 10.0) | | | プラス>99 | | | | pedi <= 0.56:tested_negative(84.0 / 34.0) | | | | ペディ>0.56 | | | | | preg <= 6 | | | | | | 年齢<=30:tested_positive(4.0) | | | | | | 30歳以上 | | | | | | | 年齢<=34:tested_negative(7.0 / 1.0) | | | | | | | 34歳以上 | | | | | | | | 質量<=33.1:tested_positive(6.0) | | | | | | | | 質量>33.1:tested_negative(4.0 / 1.0) | | | | | preg> 6:tested_positive(13.0) プラス>127 | 質量<=29.9 | | plas <= 145:tested_negative(41.0 / 6.0) | | プラス>145 | | | 年齢<=25:tested_negative(4.0) | | | 25歳以上 | | | | 年齢<=61 | | | | | 質量<=27.1:tested_positive(12.0 / 1.0) | | | | | 質量>27.1 | | | | | | pres <= 82  | | | | | | | pedi <= 0.396:tested_positive(8.0 / 1.0) | | | | | | | pedi> 0.396:tested_negative(3.0) | | | | | | pres> 82:tested_negative(4.0) | | | | 61歳以上:tested_negative(4.0) | 質量>29.9 | | プラス<=157 | | | pres <= 61:tested_positive(15.0 / 1.0) | | | pres> 61 | | | | 年齢<=30:tested_negative(40.0 / 13.0) | | | | 30歳以上:tested_positive(60.0 / 17.0) | | plas> 157:tested_positive(92.0 / 12.0) 葉の数:22 木のサイズ:43 |
4. Apache Mahaut
Mahautは、Javaを使用した機械学習の実装を支援するアルゴリズムのコレクションです。 これは、開発者が数学、統計家の分析を実行できるスケーラブルな線形代数フレームワークです。 これは通常、データサイエンティスト、リサーチエンジニア、分析の専門家がエンタープライズ対応のアプリケーションを構築するために使用します。 そのスケーラビリティと柔軟性により、ユーザーはデータクラスタリング、レコメンデーションシステムを実装し、パフォーマンスの高い機械学習アプリをすばやく簡単に作成できます。
5. Deeplearning4j
Deeplearning4jは、Javaで記述されたプログラミングライブラリであり、ディープラーニングを広範囲にサポートします。 これは、ディープニューラルネットワークとディープ強化学習を組み合わせてビジネスオペレーションを提供するオープンソースフレームワークです。 Scala、Kotlin、Apache Spark、Hadoop、その他のJVM言語およびビッグデータコンピューティングフレームワークと互換性があります。
これは通常、音声、音声、および書かれたテキストのパターンと感情を検出するために使用されます。 トランザクションの不一致を発見し、複数のタスクを処理できるDIYツールとして機能します。 これは、オープンソースの性質のために詳細なAPIドキュメントを備えた商用グレードの分散ライブラリです。
Deeplearning4jを使用して機械学習を実装する方法の例を次に示します。
例:Deeplearning4jを使用して、畳み込みニューラルネットワーク(CNN)モデルを構築し、MNISTライブラリを使用して手書き数字を分類します。
ステップ1 :データセットをロードしてそのサイズを表示します。
| DataSetIterator MNISTTrain = new MnistDataSetIterator(batchSize、true、seed); DataSetIterator MNISTTest = new MnistDataSetIterator(batchSize、false、seed); |
ステップ2 :データセットが10個の一意のラベルを提供していることを確認します。
| log.info("トレーニングデータセットで見つかったラベルの総数"+ MNISTTrain.totalOutcomes()); log.info("テストデータセットで見つかったラベルの総数"+ MNISTTest.totalOutcomes()); |
ステップ3 :次に、2つの畳み込みレイヤーとフラット化されたレイヤーを使用してモデルアーキテクチャを構成し、出力を表示します。
Deeplearning4jには、重みスキームを初期化できるオプションがあります。
| //CNNモデルの構築 MultiLayerConfiguration conf = new NeuralNetConfiguration.Builder() .seed(seed)//ランダムシード .l2(0.0005)//正則化 .weightInit(WeightInit.XAVIER)//ウェイトスキームの初期化 .updater(new Adam(1e-3))//最適化アルゴリズムの設定 。リスト() .layer(new ConvolutionLayer.Builder(5、5) //ストライド、カーネルサイズ、およびアクティブ化関数を設定します。 .nIn(nChannels) .stride(1,1) .nOut(20) .activation(Activation.IDENTITY) 。建てる()) .layer(new SubsamplingLayer.Builder(PoolingType.MAX)//畳み込みのダウンサンプリング .kernelSize(2,2) .stride(2,2) 。建てる()) .layer(new ConvolutionLayer.Builder(5、5) //ストライド、カーネルサイズ、およびアクティブ化関数を設定します。 .stride(1,1) .nOut(50) .activation(Activation.IDENTITY) 。建てる()) .layer(new SubsamplingLayer.Builder(PoolingType.MAX)//畳み込みのダウンサンプリング .kernelSize(2,2) .stride(2,2) 。建てる()) .layer(new DenseLayer.Builder()。activation(Activation.RELU) .nOut(500).build()) .layer(new OutputLayer.Builder(LossFunctions.LossFunction.NEGATIVELOGLIKELIHOOD) .nOut(outputNum) .activation(Activation.SOFTMAX) 。建てる()) //最終的な出力レイヤーは28×28で、深さは1です。 .setInputType(InputType.convolutionalFlat(28,28,1)) 。建てる(); |
ステップ4 :アーキテクチャを構成した後、モードとトレーニングデータセットを初期化し、モデルトレーニングを開始します。
| MultiLayerNetworkモデル=新しいMultiLayerNetwork(conf); //モデルの重みを初期化します。 model.init(); log.info(“ステップ2:モデルのトレーニングを開始する”); // 10回の反復ごとにリスナーを設定し、すべてのエポックでテストセットを評価します model.setListeners(new ScoreIterationListener(10)、new EvaluativeListener(MNISTTest、1、InvocationType.EPOCH_END)); //モデルのトレーニング model.fit(MNISTTrain、nEpochs); |
モデルのトレーニングが開始されると、分類精度の混同行列が作成されます。
10回のトレーニングエポック後のモデルの精度は次のとおりです。
| =========================混同行列======================= == 0 1 2 3 4 5 6 7 8 9 ————————————————— 977 0 0 0 0 0 1 1 1 0 | 0 = 0 0 1131 0 1 0 1 2 0 0 0 | 1 = 1 1 2 1019 3 0 0 0 3 4 0 | 2 = 2 0 0 1 1004 0 1 0 1 3 0 | 3 = 3 0 0 0 0 977 0 2 0 1 2 | 4 = 4 1 0 0 9 0 879 1 0 1 1 | 5 = 5 4 2 0 0 1 1 949 0 1 0 | 6 = 6 0 4 2 1 1 0 0 1018 1 1 | 7 = 7 2 0 3 1 0 1 1 2 962 2 | 8 = 8 0 2 0 2 11 2 0 3 2 987 | 9 = 9 |
6.エルキ
KDDを開発するための環境-インデックス構造またはELKIでサポートされるアプリケーションは、データマイニングに使用される組み込みのアルゴリズムとプログラムのコレクションです。 Javaで記述された、アルゴリズムで高度に構成可能なパラメーターを含むオープンソースライブラリです。 これは通常、データセットへの洞察を得るために研究科学者や学生によって使用されます。 名前が示すように、インデックス構造を使用して高度なデータマイニングプログラムとデータベースを開発するための環境を提供します。
7. JSAT
Java統計分析ツールまたはJSATは、オブジェクト指向フレームワークを使用して、ユーザーがJavaで機械学習を実装できるようにするGPL3ライブラリです。 これは通常、学生や開発者による独学の目的で使用されます。 他のAI実装ライブラリと比較すると、JSATはMLアルゴリズムの数が最も多く、すべてのフレームワークの中で最速です。 外部依存関係がないため、柔軟性と効率性が高く、高いパフォーマンスを提供します。
8.Encog機械学習フレームワーク
EncogはJavaとC#で記述されており、機械学習アルゴリズムの実装に役立つライブラリで構成されています。 遺伝的アルゴリズム、ベイジアンネットワーク、隠れマルコフモデルなどの統計モデルの構築に使用されます。
9.マレット
言語ツールキットまたはマレットの機械学習は、自然言語処理(NLP)で使用されます。 他のほとんどのML実装フレームワークと同様に、Malletは、データモデリング、データクラスタリング、ドキュメント処理、ドキュメント分類などのサポートも提供します。
10. Spark MLlib
Spark MLlibは、ワークフロー管理の効率とスケーラビリティを強化するために企業で使用されます。 大量のデータを処理し、高負荷のMLアルゴリズムをサポートします。
チェックアウト:機械学習プロジェクトのアイデア
結論
これで記事は終わりです。 機械学習の概念の詳細については、upGradの機械学習とAIプログラムの科学のマスターを通じて、IIITバンガロアとリバプールジョンムーア大学のトップ教員に連絡してください。
機械学習と一緒にJavaを使用する必要があるのはなぜですか?
機械学習の専門家は、プロジェクトのプログラミング言語としてJavaを選択すると、現在のコードリポジトリとのインターフェースが簡単になります。 これは、使いやすさ、パッケージサービス、ユーザーインタラクションの向上、迅速なデバッグ、データのグラフィカルな図解などの機能により、機械学習に適した言語です。 Javaを使用すると、機械学習の開発者はシステムを簡単に拡張できるため、大きくて洗練された機械学習アプリケーションをゼロから構築するのに最適です。 Java仮想マシン(JVM)は、マシン学習者が新しいツールを迅速に設計できるようにする多数の統合開発環境(IDE)をサポートしています。
Javaの学習は簡単ですか?
Javaは高級言語であるため、理解するのは簡単です。 学習者は、初心者が理解できるほど単純な、適切に構造化されたオブジェクト指向言語であるため、詳細に立ち入る必要はありません。 自動的に動作する手順が多数あるため、すばやく習得できます。 そこでは、物事がどのように機能するかについて詳細に説明する必要はありません。 Javaは、プラットフォームに依存しないプログラミング言語です。 これにより、プログラマーは任意のデバイスで使用できるモバイルアプリケーションを作成できます。 これは、モノのインターネットの優先言語であり、エンタープライズレベルのアプリケーションを開発するための最良のツールです。
ADAMSとは何ですか?機械学習でどのように役立ちますか?
Advanced Data Mining And Machine Learning System(ADAMS)は、GPLv3ライセンスのワークフローエンジンであり、ビジネスプロセスに容易に組み込むことができる、データ駆動型の反応型ワークフローを迅速に作成および管理します。 less is moreの原則に従うワークフローエンジンは、ADAMSの中心にあります。 ADAMSは、ユーザーがオペレーター(またはADAMS専門用語のアクター)をキャンバス上に配置し、入力と出力を手動でリンクできるようにする代わりに、ツリーのような構造を採用しています。 この構造と制御アクターがプロセス内のデータの流れを決定するため、明示的な接続は必要ありません。 内部オブジェクト表現とオペレーターハンドラー内のサブオペレーターのネストにより、ツリーのような構造になります。 ADAMSは、データの取得、処理、マイニング、および表示のためのさまざまなエージェントのセットを提供します。