
2022年のHadoopインタビューの質問と回答のトップ15
公開: 2021-01-09データ分析が勢いを増しているため、ビッグデータの処理に長けた人々の需要が急増しています。 データアナリストからデータサイエンティストまで、ビッグデータは今日、一連のジョブプロファイルを作成しています。 何よりもまず実践することが期待されるのはHadoopです。
職務/プロファイルに関係なく、おそらく何らかの方法でHadoopに取り組んでいます。 したがって、インタビュアーがいくつかのHadoop質問を自分のやり方で撃つことを常に期待できます。
それ以上のことについては、あなたが座っているインタビューで予想される上位15のHadoopインタビューの質問を見てみましょう。
Hadoopとは何ですか? Hadoopの主要コンポーネントは何ですか?
Hadoopは、ビッグデータの処理と保存に必要な関連ツールとサービスを備えたインフラストラクチャです。 正確には、Hadoopはすべてのビッグデータの課題に対する「ソリューション」です。 さらに、Hadoopフレームワークは、組織がビッグデータを分析し、より良いビジネス上の意思決定を行うのにも役立ちます。
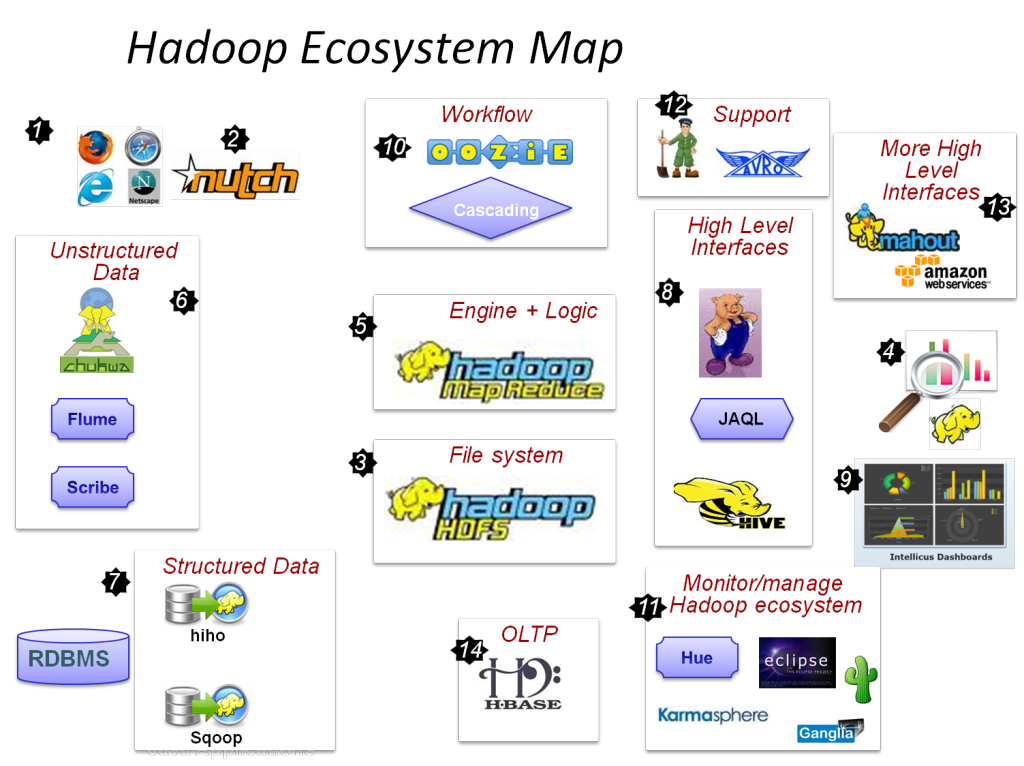
Hadoopの主要なコンポーネントは次のとおりです。
- HDFS
- Hadoop MapReduce
- Hadoop Common
- 糸
- PIGおよびHIVE–データアクセスコンポーネント。
- HBase –データストレージ用
- Ambari、Oozie、ZooKeeper –データ管理および監視コンポーネント
- ThriftおよびAvro–データシリアル化コンポーネント
- Apache Flume、Sqoop、Chukwa –データ統合コンポーネント
- Apache Mahout and Drill –データインテリジェンスコンポーネント
Hadoopフレームワークのコアコンセプトは何ですか?
Hadoopは、基本的に2つのコアコンセプトに基づいています。 彼らです:
- HDFS:HDFSまたはHadoop分散ファイルシステムは、膨大なデータセットをブロック形式で保存するために使用されるJavaベースの信頼性の高いファイルシステムです。 マスタースレーブアーキテクチャがそれを支えています。
- MapReduce:MapReduceは、大規模なデータセットの処理を支援するプログラミング構造です。 この関数はさらに2つの部分に分けられます。「map」はデータセットをタプルに分離しますが、「reduce」はマップタプルを使用して、タプルの小さなチャンクの組み合わせを作成します。
Hadoopで最も一般的な入力形式に名前を付けますか?
Hadoopには、次の3つの一般的な入力形式があります。
- テキスト入力形式:これは、Hadoopのデフォルトの入力形式です。
- シーケンスファイル入力フォーマット:この入力フォーマットは、ファイルを順番に読み取るために使用されます。
- キー値入力形式:これは、プレーンテキストファイルを読み取るために使用されます。
YARNとは何ですか?
YARNは、Yet AnotherResourceNegotiatorの略語です。 データリソースを管理し、処理を成功させるための環境を作成するのは、Hadoopのデータ処理フレームワークです。 
「ラックアウェアネス」とは何ですか?
「RackAwareness」は、NameNodeがデータブロックとそのレプリカがHadoopクラスター内に格納されるパターンを決定するために使用するアルゴリズムです。 これは、同じラックに含まれるデータノード間の輻輳を軽減するラック定義の助けを借りて実現されます。

アクティブおよびパッシブNameNodeとは何ですか?
高可用性Hadoopシステムには、通常、アクティブNameNodeとパッシブNameNodeの2つのNameNodeが含まれています。
Hadoopクラスターを実行するNameNodeはアクティブNameNodeと呼ばれ、アクティブNameNodeのデータを格納するスタンバイNameNodeはパッシブNameNodeです。
2つのNameNodeを使用する目的は、Active NameNodeがクラッシュした場合に、PassiveNameNodeが主導権を握ることができるようにすることです。 したがって、NameNodeは常にクラスター内で実行されており、システムに障害が発生することはありません。
Hadoopフレームワークのさまざまなスケジューラーは何ですか?
Hadoopフレームワークには3つの異なるスケジューラーがあります。
- COSHH – COSHHは、異質性と組み合わされたクラスターとワークロードを確認することにより、スケジュールの決定を支援します。
- FIFOスケジューラー– FIFOは、異質性を使用せずに、到着時間に基づいてジョブをキューに並べます。
- フェアシェアリング–フェアシェアリングは、複数のマップを含む個々のユーザー用のプールを作成し、特定のジョブを実行するために使用できるリソースのスロットを減らします。
投機的実行とは何ですか?
多くの場合、Hadoopフレームワークでは、一部のノードの実行速度が他のノードよりも遅くなる場合があります。 これは、プログラム全体を制約する傾向があります。 これを克服するために、Hadoopは、タスクの実行速度が通常よりも遅い場合に最初に検出または「推測」し、次にそのタスクの同等のバックアップを起動します。 そのため、プロセスでは、マスターノードが両方のタスクを同時に実行し、最初に完了した方が受け入れられ、もう一方が強制終了されます。 Hadoopのこのバックアップ機能は、投機的実行として知られています。

Apache HBaseの主要コンポーネントに名前を付けますか?
Apache HBaseは、次の3つのコンポーネントで構成されています。
- リージョンサーバー:テーブルが複数のリージョンに分割された後、これらのリージョンのクラスターはリージョンサーバーを介してクライアントに転送されます。
- HMaster:これはリージョンサーバーの管理と調整に役立つツールです。
- ZooKeeper:ZooKeeperは、HBase分散環境内のコーディネーターです。 セッションでの通信を通じて、クラスター内のサーバー状態を維持するのに役立ちます。
「チェックポインティング」とは何ですか? その利点は何ですか?
チェックポインティングとは、FsImageと編集ログを組み合わせて新しいFsImageを形成する手順を指します。 したがって、編集ログを再生する代わりに、NameNodeはFsImageから最終的なメモリ内の状態を直接ロードできます。 セカンダリNameNodeは、このプロセスを担当します。
チェックポインティングが提供する利点は、NameNodeの起動時間を最小限に抑え、それによってプロセス全体をより効率的にすることです。
ポップカルチャーにおけるビッグデータアプリケーション
Hadoopコードをデバッグする方法は?
Hadoopコードをデバッグするには、まず、現在実行中のMapReduceタスクのリストを確認する必要があります。 次に、孤立したタスクが同時に実行されているかどうかを確認する必要があります。 その場合は、次の簡単な手順に従って、ResourceManagerログの場所を見つける必要があります。
「ps–ef|」を実行しますgrep –I ResourceManager」と表示された結果で、特定のジョブIDに関連するエラーがあるかどうかを確認してください。
ここで、タスクの実行に使用されたワーカーノードを特定します。 ノードにログインして、「ps –ef|」を実行します。 grep –iNodeManager。」
最後に、ノードマネージャのログを精査します。 ほとんどのエラーは、各map-reduceジョブのユーザーレベルのログから生成されます。
HadoopのRecordReaderの目的は何ですか?
Hadoopはデータをブロック形式に分割します。 RecordReaderは、これらのデータブロックを単一の読み取り可能なレコードに統合するのに役立ちます。 たとえば、入力データが2つのブロックに分割されている場合–
行1–へようこそ
行2–アップグレード
RecordReaderは、これを「WelcometoUpGrad」と読みます。
Hadoopを実行できるモードは何ですか?
Hadoopを実行できるモードは次のとおりです。
- スタンドアロンモード–これはデバッグ目的で使用されるHadoopのデフォルトモードです。 HDFSはサポートしていません。
- 疑似分散モード–このモードでは、mapred-site.xml、core-site.xml、およびhdfs-site.xmlファイルの構成が必要でした。 ここでは、マスターノードとスレーブノードの両方が同じです。
- 完全分散モード–完全分散モードはHadoopの本番ステージであり、データはHadoopクラスター上のさまざまなノードに分散されます。 ここでは、マスターノードとスレーブノードが別々に割り当てられています。
Hadoopの実用的なアプリケーションをいくつか挙げてください。
Hadoopが違いを生み出している実際の例を次に示します。
- 道路交通の管理
- 不正の検出と防止
- 顧客データをリアルタイムで分析して、顧客サービスを向上させます
- 医師やHCPなどからの非構造化医療データにアクセスして、医療サービスを改善します。
ビッグデータのパフォーマンスを向上させることができる重要なHadoopツールは何ですか?
ビッグデータのパフォーマンスを大幅に向上させるHadoopツールは

•ハイブ
•HDFS
•HBase
•SQL
•NoSQL
•Oozie
•雲
•Avro
•Flume
•ZooKeeper
ビッグデータエンジニア:神話と現実
結論
これらのHadoopインタビューの質問は、次のインタビューで非常に役立ちます。 インタビュアーがHadoopインタビューの質問をひねる傾向がある場合もありますが、基本を整理しておけば、問題にはならないはずです。
ビッグデータについて詳しく知りたい場合は、ビッグデータプログラムのソフトウェア開発スペシャライゼーションのPGディプロマをチェックしてください。このプログラムは、働く専門家向けに設計されており、7つ以上のケーススタディとプロジェクトを提供し、14のプログラミング言語とツール、実践的なハンズオンをカバーしています。ワークショップ、トップ企業との400時間以上の厳格な学習と就職支援。