
機械学習の背後にある数学:あなたが知る必要があることは?
公開: 2021-03-10機械学習はAIの一部門であり、利用可能なデータを正確に処理してアプリケーションを構築することに重点を置いています。 機械学習の主な目的は、人間の介入なしにコンピューターが計算を処理できるようにすることです。 これは、教師ありまたは教師なし学習方法を介して、機械が人間の知能を模倣することを学習できるようにすることで可能になります。
機械学習は、統計、確率、線形代数、計算などを含む多くのフィールドの組み合わせであり、これに基づいて、機械学習モデルは、人間の知性に従って即興するアルゴリズムを作成または提供できます。 アプリケーションが複雑になるほど、そのアルゴリズムは複雑になります。
デジタルアシスタントやスマートデバイスから、オンラインでのアクティビティに基づいてお気に入りの製品を推奨するWebサイト、フライトスケジュールを通知する携帯電話まで、機械学習ベースの製品やツールが私たちの周りにあります。 スマートデバイスやアプライアンスへの依存度が高まるにつれて、機械学習の実装の必要性も高まります。
そのために、この記事では、機械学習アルゴリズムの作成と実装に必要な数学的概念について説明します。
目次
機械学習における数学の重要性は何ですか?
機械学習アプリケーションは、利用可能なデータから収集された分析と洞察を提供し、ビジネスにおける実用的な意思決定に貢献します。 機械学習はアルゴリズムの学習と実装を中心に展開するため、数学のスキルを強化することが重要です。 不確実性を排除し、複雑なデータパラメータと機能が関係するデータ値を正確に予測するのに役立ちます。 また、偏りと分散のトレードオフをよりよく理解するのにも役立ちます。
機械学習を習得するには、線形代数、ベクトル微積分、解析幾何学、行列分解、確率、統計などの数学的概念の知識が必要です。 これらをしっかりと把握することで、直感的な機械学習アプリケーションを作成できます。

線形代数
線形代数はベクトルと行列に関係し、主に計算を中心に展開します。 機械学習と深層学習の手法で不可欠な役割を果たします。 スカイラー・スピークマンによれば、それは21世紀の数学です。
線形代数は通常、MLエンジニア、データサイエンティスト、または研究者が線形アルゴリズム、ロジスティック回帰、決定木、サポートベクターマシンを構築するために使用します。
微積分
Calculusは機械学習アルゴリズムを駆動します。 その概念の知識がなければ、特定のデータセットを使用して結果を予測することはできません。 微積分は、量が変化する速度を分析するのに役立ち、機械学習アルゴリズムの最適なパフォーマンスに関係しています。 統合、微分、制限、および導関数は、深いニューラルネットワークのトレーニングに役立つ微積分のいくつかの概念です。
確率
機械学習の確率は一連の結果を予測しますが、統計は好ましい結果を結論に導きます。 イベントはコインを投げるのと同じくらい簡単かもしれません。 確率は、条件付き確率と同時確率の2つのカテゴリに分類できます。 同時確率は、イベントが互いに独立している場合に発生しますが、条件付き確率は、一方のイベントが他方に優先する場合に発生します。
統計学
統計は、アルゴリズムの量的および質的側面に焦点を当てています。 簡潔に提示することで、目標を特定し、収集したデータを正確な観察結果に変換するのに役立ちます。 機械学習の統計は、記述統計と推論統計に焦点を当てています。
記述統計は、モデルが取り組んでいる小さなデータセットの記述と要約に関係しています。 ここで使用される方法は、平均、中央値、最頻値、標準偏差、および変動です。 最終結果は、画像表現として表示されます。
推論統計は、大規模なデータセットを操作しながら、特定のサンプルから洞察を抽出することを扱います。 推論統計により、マシンは提供された情報の範囲を超えてデータを分析できます。 仮説検定、サンプリング分布、分散分析は、推測統計のいくつかの側面です。
これらとは別に、コーディングの腕前は機械学習の重要な前提条件です。 PythonやJavaなどの言語の専門知識は、データモデリングの理解を深めるのに役立ちます。 文字列の書式設定、関数の定義、複数の変数イテレータを使用したループ、または条件式がその基本関数の一部である場合。
データモデリングに関しては、データセットの構造を推定し、考えられる変動やパターンを検出するプロセスです。 正確な予測を行うには、集合データのさまざまな特性に注意する必要があります。
機械学習をどのように学ぶことができますか?
機械学習は有利な分野ですが、十分な練習と忍耐が必要です。 今日のほぼすべての業界でのアプリケーションを考えると、機械学習エンジニアは大きな需要があります。
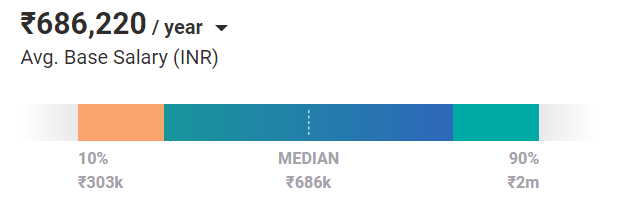
機械学習のバックグラウンドを持つエントリーレベルのエンジニアの平均給与は、年間686kルピーです。 そして、経験とスキルアップにより、より高い給与を得る可能性は飛躍的に高まります。
機械学習の知識ベースを強化したい人のために利用できるいくつかのコースがあります。 主題を習得するには、最低6か月から2年かかります。
少なくとも学士号と1年間の実務経験があり、数学または統計学の学位があれば、 upGradで次のコースのいずれかを受講して、フィールドで成功する可能性を高めることができます。

- IITバンガロアからの機械学習とディープラーニングの高度な証明書プログラム(6か月)
- IIT Bangaloreによる機械学習とNLPの高度な証明書プログラム(6か月)
- IIT Bangaloreの機械学習とAIのエグゼクティブPGプログラム(12か月)
- IITマドラスからの機械学習とクラウドの高度な認定(12か月)
- LJMUとIITバンガロアの機械学習とAIの理学修士(18か月)
これらのコースはすべて、最低240時間以上の学習と、少なくとも5つのケーススタディを提供します。これは、機械学習とそのさまざまな補助分野を深く理解するのに役立ちます。 コーディングのバックボーンを形成するPython、MySQL、Tensor、NLTK、statsmodels、Excelなどの重要なトピックをカバーできます。 機械学習のさまざまなupGradコースの詳細をご覧ください。これにより、最適なコースを選択できます。
世界のトップ大学であるマスター、エグゼクティブポストグラデュエイトプログラム、ML&AIの高度な証明書プログラムからオンラインで人工知能コースに参加して、キャリアを早めましょう。
機械学習のアプリケーション
機械学習は、職業と個人の両方の分野で、私たちの日常生活において重要な役割を果たしています。 その分析的で直感的な能力は、私たちが日常業務を遂行する方法に劇的な影響を与える可能性があります。 それは組織のためにお金と時間を節約するのに機知に富んでいることが証明されました。
機械学習はほぼすべての業界でアプリケーションを使用する幅広い分野ですが、ここにいくつかの最も顕著な例があります。
- 画像認識は、顔検出を支援するため、最も一般的に使用されるアプリケーションの1つであり、したがって、個人ごとに個別のデータベースを作成します。 手書きスタイルの識別にも使用できます。
- 医療セクターでの機械学習により、医療提供者の能力が向上しました。 より迅速な医療診断に使用できます。 多くの場合、AIは病気の早期診断に役立ち、医師が命を救う可能性のある治療法や予防策を提案できるようになりました。
- 機械学習は、投資、合併、買収が関係する金融セクターで主要なアプリケーションを持っています。 銀行やその他の経済機関が賢明な選択をするのを支援します。
- 機械学習は運用を合理化し、ソリューションを迅速かつ効率的に提供するため、その有効性はカスタマーケアおよびサービス業界でおそらく最も明白です。
- 機械学習は、フィールドで人間が実行する必要のあるタスクを自動化します。 たとえば、仮想アシスタントを検討する場合、パスワードを変更したり、銀行の残高を確認したりするのと同じくらい簡単な作業になる可能性があります。 機械学習により、複雑な意思決定や人間の手で行う必要のある、より差し迫ったタスクに人材を割り当てることができるようになりました。
機械学習の将来の範囲
機械学習は何十年も前から存在していますが、その応用は今日最も明白です。 業界はまだ繁栄しておらず、即興であるため、機械学習の未来は明るいことを意味します。 ほとんどの大規模企業は、機械学習のメリットをすでに享受しており、サービスと製品をスケーリングして成長を促進しています。
当然のことながら、MLエンジニアの需要は非常に高く、機械学習は有利なキャリアとしての地位を確立しています。 それは企業が必要とするエッジを意味します。 AIはこれまでに推定230万の雇用機会を生み出してきました。 2022年末までに、世界のML業界は42.2%のCAGRで成長し、90億米ドルに達すると予測されています。
機械学習の主なトレンドは次のとおりです。
- 教師なし実装に向けて学習するアルゴリズムはますます増えています。 企業は、機械学習を変革する可能性のあるこれらの教師なしアルゴリズムに基づく量子コンピューティングに投資しています。 これらは、意味のある洞察の分析と描画に貢献し、したがって、従来の機械学習技術では不可能だったより良い結果を企業が達成するのに役立ちます。
- AIを搭載したロボットは、事業運営を行うために配備されています。 ただし、これらのテクノロジーは初期段階にあり、企業がAIとMLの足場を確立するために投資するにつれて、ロボットはすぐに生産性を飛躍的に向上させるのに役立ちます。 例を挙げると、ドローンは消費者市場で強力なビジネスツールを装っており、商業活動や商品の配達などの簡単なタスクを実行するために使用されています。
- 機械学習アルゴリズムは、強化されたパーソナライズをサポートします。 これらのアルゴリズムは、潜在的な顧客のオンライン行動を調査し、企業に情報を送り返します。 次に、企業は製品とサービスの推奨事項を送信します。 これらの機械学習手法は、顧客の好き嫌いを特定するのに役立ちます。 機械学習を通じて、企業は顧客に希望するものを提供し、希望するときにそれを提供します。これにより、顧客維持率が向上し、組織により多くのビジネスが引き付けられます。 パーソナライズの改善は、機械学習の未来です。
- 強化された機械学習アルゴリズムのおかげで、モバイルおよびWebアプリケーションはこれまでになくスマートになりました。 改善されたコグニティブサービスにより、開発者は、視覚認識、音声、音声、音声などに基づいて、クライアントごとに個別のデータベースを作成できます。
これで記事は終わりです。 この情報がお役に立てば幸いです。
線形回帰で等分散性が必要なのはなぜですか?
等分散性は、データが平均からどれだけ類似しているか、またはどれだけ離れているかを表します。 パラメトリック統計テストは違いに敏感であるため、これは重要な仮定です。 不均一分散は、係数推定にバイアスを引き起こしませんが、精度を低下させます。 精度が低いと、係数の推定値が正しい母集団の値から外れる可能性が高くなります。 これを回避するには、等分散性を主張することが重要です。
線形回帰の多重共線性の2つのタイプは何ですか?
データと構造の多重共線性は、多重共線性の2つの基本的なタイプです。 他の項からモデル項を作成すると、構造的な多重共線性が得られます。 言い換えれば、それはデータ自体に存在するのではなく、私たちが提供するモデルの結果です。 データの多重共線性はモデルのアーティファクトではありませんが、データ自体に存在します。 データの多重共線性は、観察研究でより一般的です。
独立したテストにt検定を使用することの欠点は何ですか?
対応のあるサンプルのt検定を使用する場合、グループ設計間の違いではなく、測定を繰り返すことには問題があり、キャリーオーバー効果につながります。 タイプIのエラーのため、t検定を多重比較に使用することはできません。 一連のサンプルで対応のあるt検定を実行する場合、帰無仮説を棄却することは困難です。 サンプルデータの主題を取得することは、研究プロセスの時間と費用のかかる側面です。