
機械学習を使用した株式市場の予測[ステップバイステップの実装]
公開: 2021-02-26目次
序章
株式市場の予測と分析は、実行するのが最も複雑なタスクの一部です。 これにはいくつかの理由があります。たとえば、市場のボラティリティや、市場の特定の株式の価値を決定するための他の多くの依存および独立した要因などです。 これらの要因により、株式市場のアナリストが高精度で上昇と下降を予測することは非常に困難です。
ただし、機械学習とその堅牢なアルゴリズムの出現により、最新の市場分析と株式市場予測の開発により、株式市場データの理解にそのような手法が組み込まれ始めています。
つまり、機械学習アルゴリズムは、株価の分析と予測において多くの組織で広く使用されています。 この記事では、Pythonのいくつかの機械学習アルゴリズムを使用して、人気のある世界的なオンライン小売店の株価を分析および予測する簡単な実装について説明します。
問題文
株式市場の価値を予測するためのプログラムの実装に入る前に、作業するデータを視覚化しましょう。 ここでは、National Association of Securities Dealers Automated Quotations(NASDAQ)のMicrosoft Corporation(MSFT)の株価を分析します。 株価データは、Excelまたはスプレッドシートを使用して開いて表示できるコンマ区切りファイル(.csv)の形式で表示されます。
MSFTの株式はNASDAQに登録されており、その値は株式市場の毎日の営業日に更新されます。 市場では、土曜日と日曜日に取引を行うことは許可されていないことに注意してください。 したがって、2つの日付の間にギャップがあります。 各日付について、同じ日の株式の始値、その株式の最高値と最低値が、その日の終わりの終値とともに記録されます。
調整済み終値は、配当が転記された後の株式の値を示します(技術的すぎます!)。 さらに、市場の株式の総量も示されます。これらのデータを使用して、データを調査し、Microsoft Corporationの株式の履歴からパターンを抽出できるいくつかのアルゴリズムを実装するのは、機械学習/データサイエンティストの仕事です。データ。

長期短期記憶
Microsoft Corporationの株価を予測する機械学習モデルを開発するために、Long Short-Term Memory(LSTM)の手法を使用します。 これらは、乗算と加算によって情報に小さな変更を加えるために使用されます。 定義上、長期記憶(LSTM)は、深層学習で使用される人工リカレントニューラルネットワーク(RNN)アーキテクチャです。
標準のフィードフォワードニューラルネットワークとは異なり、LSTMにはフィードバック接続があります。 単一のデータポイント(画像など)とデータシーケンス全体(音声やビデオなど)を処理できます。 LSTMの背後にある概念を理解するために、携帯電話のオンラインカスタマーレビューの簡単な例を見てみましょう。
携帯電話を購入したい場合、通常は認定ユーザーによるネットレビューを参照します。 彼らの考えや意見に応じて、私たちはモバイルが良いか悪いかを判断し、それを購入します。 レビューを読み続けるうちに、「すごい」、「良いカメラ」、「最高のバッテリーバックアップ」など、携帯電話に関連する多くの用語を探します。
「it」、「gave」、「this」などの英語の一般的な単語を無視する傾向があります。したがって、携帯電話を購入するかどうかを決定するときは、上記で定義したこれらのキーワードのみを覚えています。 おそらく、他の言葉を忘れてしまいます。
これは、長短期記憶アルゴリズムが機能するのと同じ方法です。 関連する情報のみを記憶し、それを使用して、関連性のないデータを無視して予測を行います。 このようにして、その株式に関する重要なデータのみを本質的に認識し、その外れ値を除外するLSTMモデルを構築する必要があります。
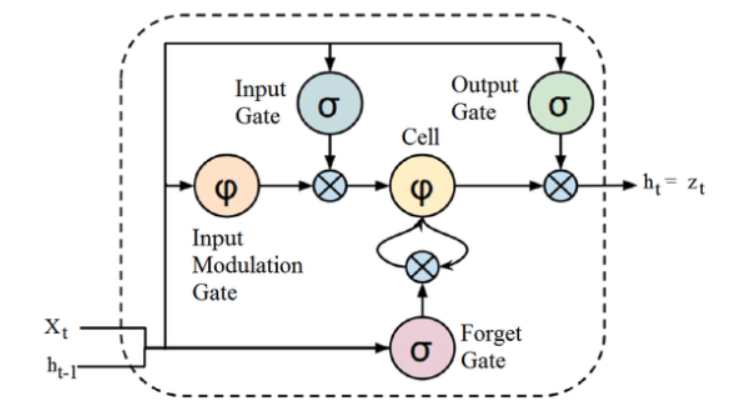
ソース
LSTMアーキテクチャの上記の構造は、最初は興味をそそられるように思われるかもしれませんが、LSTMは、データのシーケンスを処理するためにメモリを保持するリカレントニューラルネットワークの高度なバージョンであることを覚えておくだけで十分です。 ゲートと呼ばれる構造によって注意深く制御され、セルの状態に情報を削除または追加できます。
LSTMユニットは、セル、入力ゲート、出力ゲート、および忘却ゲートで構成されます。 セルは任意の時間間隔で値を記憶し、3つのゲートがセルに出入りする情報の流れを調整します。
プログラムの実施
Pythonの機械学習を使用して株価を予測する際にLSTMを使用する部分に移ります。
ステップ1-ライブラリのインポート
ご存知のとおり、最初のステップは、Microsoft Corporationの株式データを前処理するために必要なライブラリと、LSTMモデルの出力を構築および視覚化するために必要なその他のライブラリをインポートすることです。 このために、TensorFlowフレームワークの下でKerasライブラリを使用します。 必要なモジュールは、Kerasライブラリから個別にインポートされます。
#ライブラリのインポート
パンダをPDとしてインポートする
NumPyをnpとしてインポートします
%matplotlibインライン
matplotlibをインポートします。 pltとしてのpyplot
matplotlibをインポートする
sklearnから。 前処理インポートMinMaxScaler
Kerasから。 レイヤーはLSTM、Dense、Dropoutをインポートします
sklearn.model_selectionからインポートTimeSeriesSplit
sklearn.metricsからimportmean_squared_error、r2_score
matplotlibをインポートします。 義務としての日付
sklearnから。 前処理インポートMinMaxScaler
sklearnからimportlinear_model
Kerasから。 モデルはシーケンシャルをインポートします
Kerasから。 レイヤーは高密度をインポートします
Kerasをインポートします。 Kとしてのバックエンド
Kerasから。 コールバックはEarlyStoppingをインポートします
Kerasから。 オプティマイザーはアダムをインポートします
Kerasから。 モデルはload_modelをインポートします
Kerasから。 レイヤーはLSTMをインポートします
Kerasから。 utils.vis_utils import plot_model
ステップ2–データの視覚化を取得する
Pandasデータリーダーライブラリを使用して、ローカルシステムのストックデータをカンマ区切り値(.csv)ファイルとしてアップロードし、パンダDataFrameに保存します。 最後に、データも表示します。
#データセットを取得する
df = pd.read_csv(“ MicrosoftStockData.csv”、na_values = ['null']、index_col ='Date'、parse_dates = True、infer_datetime_format = True)
df.head()
世界のトップ大学(修士、大学院大学院プログラム、ML&AIの高度な証明書プログラム)からオンラインでAI認定を取得して、キャリアを早急に進めましょう。
ステップ3– DataFrameシェイプを印刷し、ヌル値をチェックします。
このさらに別の重要なステップでは、最初にデータセットの形状を印刷します。 データフレームにnull値がないことを確認するために、それらをチェックします。 データセットにnull値が存在すると、外れ値として機能し、トレーニングプロセスに大きな変動が生じるため、トレーニング中に問題が発生する傾向があります。
#データフレームの形状を印刷し、ヌル値をチェックする
print( "データフレーム形状:"、df。形状)
print( "Null Value Present:"、df.IsNull()。values.any())
>>データフレームの形状:(7334、6)
>> Null値が存在します:False
| 日にち | 開ける | 高い | 低い | 選ぶ | 調整閉じる | 音量 |
| 1990-01-02 | 0.605903 | 0.616319 | 0.598090 | 0.616319 | 0.447268 | 53033600 |
| 1990-01-03 | 0.621528 | 0.626736 | 0.614583 | 0.619792 | 0.449788 | 113772800 |
| 1990-01-04 | 0.619792 | 0.638889 | 0.616319 | 0.638021 | 0.463017 | 125740800 |
| 1990-01-05 | 0.635417 | 0.638889 | 0.621528 | 0.622396 | 0.451678 | 69564800 |
| 1990-01-08 | 0.621528 | 0.631944 | 0.614583 | 0.631944 | 0.458607 | 58982400 |
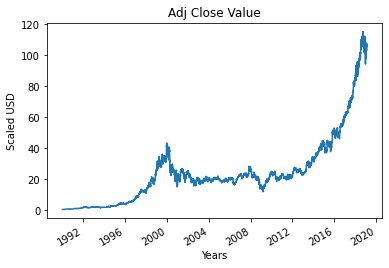
ステップ4–真の調整済みクローズ値をプロットする
機械学習モデルを使用して予測される最終的な出力値は、調整済みクローズ値です。 この値は、株式市場取引のその特定の日の株式の終値を表します。
#真の調整終了値をプロット
df ['Adj Close']。plot()
ステップ5–ターゲット変数の設定と機能の選択
次のステップでは、出力列をターゲット変数に割り当てます。 この場合、それはマイクロソフト株の調整された相対値です。 さらに、ターゲット変数(従属変数)の独立変数として機能する機能も選択します。 トレーニングの目的を説明するために、次の4つの特性を選択します。
- 開ける
- 高い
- 低い
- 音量
#ターゲット変数を設定
output_var = PD.DataFrame(df ['Adj Close'])
#機能の選択
features = ['Open'、'High'、'Low'、'Volume']

ステップ6–スケーリング
テーブル内のデータの計算コストを削減するために、ストック値を0〜1の値にスケールダウンします。これにより、多数のデータがすべて削減され、メモリ使用量が削減されます。 また、データが途方もない値に分散されないため、スケールダウンすることで精度を高めることができます。 これは、sci-kit-learnライブラリのMinMaxScalerクラスによって実行されます。
#スケーリング
scaler = MinMaxScaler()
feature_transform = scaler.fit_transform(df [features])
feature_transform = pd.DataFrame(columns = features、data = feature_transform、index = df.index)
feature_transform.head()
| 日にち | 開ける | 高い | 低い | 音量 |
| 1990-01-02 | 0.000129 | 0.000105 | 0.000129 | 0.064837 |
| 1990-01-03 | 0.000265 | 0.000195 | 0.000273 | 0.144673 |
| 1990-01-04 | 0.000249 | 0.000300 | 0.000288 | 0.160404 |
| 1990-01-05 | 0.000386 | 0.000300 | 0.000334 | 0.086566 |
| 1990-01-08 | 0.000265 | 0.000240 | 0.000273 | 0.072656 |
上記のように、特徴変数の値は、上記の実際の値と比較して小さい値に縮小されていることがわかります。
ステップ7–トレーニングセットとテストセットに分割します。
データをトレーニングモデルにフィードする前に、データセット全体をトレーニングセットとテストセットに分割する必要があります。 機械学習LSTMモデルは、トレーニングセットに存在するデータでトレーニングされ、テストセットで精度とバックプロパゲーションがテストされます。
このために、sci-kit-learnライブラリのTimeSeriesSplitクラスを使用します。 分割数を10に設定します。これは、データの10%がテストセットとして使用され、データの90%がLSTMモデルのトレーニングに使用されることを意味します。 この時系列分割を使用する利点は、分割された時系列データサンプルが一定の時間間隔で観測されることです。
#トレーニングセットとテストセットへの分割
timesplit = TimeSeriesSplit(n_splits = 10)
train_indexの場合、timesplit.split(feature_transform)のtest_index:
X_train、X_test = feature_transform [:len(train_index)]、feature_transform [len(train_index):( len(train_index)+ len(test_index))]
y_train、y_test = output_var [:len(train_index)]。values.ravel()、output_var [len(train_index):( len(train_index)+ len(test_index))]。values.ravel()
ステップ8–LSTMのデータを処理する
トレーニングセットとテストセットの準備ができたら、LSTMモデルが構築されたらデータをLSTMモデルにフィードできます。 その前に、トレーニングとテストセットのデータをLSTMモデルが受け入れるデータ型に変換する必要があります。 LSTMではデータを3D形式で提供する必要があるため、最初にトレーニングデータとテストデータをNumPy配列に変換してから、それらを形式(サンプル数、1、機能数)に再形成します。 ご存知のように、トレーニングセットのサンプル数は7334の90%である6667であり、特徴の数は4であり、トレーニングセットは(6667、1、4)に再形成されます。 同様に、テストセットも再形成されます。
#LSTMのデータを処理する
trainX = np.array(X_train)
testX = np.array(X_test)
X_train = trainX.reshape(X_train.shape [0]、1、X_train.shape [1])
X_test = testX.reshape(X_test.shape [0]、1、X_test.shape [1])
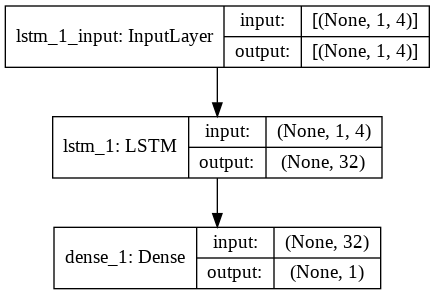
ステップ9–LSTMモデルの構築
最後に、LSTMモデルを構築する段階に到達します。 ここでは、1つのLSTMレイヤーを持つSequentialKerasモデルを作成します。 LSTM層には32ユニットがあり、その後に1ニューロンの高密度層が1つ続きます。
モデルをコンパイルするための損失関数として、AdamOptimizerと平均二乗誤差を使用します。 これら2つは、LSTMモデルに最も適した組み合わせです。 さらに、モデルもプロットされ、下に表示されます。
#LSTMモデルの構築
lstm = Sequential()
lstm.add(LSTM(32、input_shape =(1、trainX.shape [1])、activation ='relu'、return_sequences = False))
lstm.add(Dense(1))
lstm.compile(loss ='mean_squared_error'、optimizer ='adam')
plot_model(lstm、show_shapes = True、show_layer_names = True)
ステップ10–モデルのトレーニング
最後に、フィット関数を使用して、バッチサイズ8の100エポックのトレーニングデータで上記で設計されたLSTMモデルをトレーニングします。
#モデルトレーニング
history = lstm.fit(X_train、y_train、epochs = 100、batch_size = 8、verbose = 1、shuffle = False)
エポック1/100
834/834 [==============================] – 3秒2ミリ秒/ステップ–損失:67.1211
エポック2/100
834/834 [==============================] – 1秒2ミリ秒/ステップ–損失:70.4911
エポック3/100
834/834 [==============================] – 1秒2ミリ秒/ステップ–損失:48.8155
エポック4/100
834/834 [==============================] – 1秒2ミリ秒/ステップ–損失:21.5447
エポック5/100
834/834 [==============================] – 1秒2ミリ秒/ステップ–損失:6.1709
エポック6/100
834/834 [==============================] – 1秒2ミリ秒/ステップ–損失:1.8726
エポック7/100
834/834 [==============================] – 1秒2ミリ秒/ステップ–損失:0.9380
エポック8/100
834/834 [==============================] – 2秒2ミリ秒/ステップ–損失:0.6566
エポック9/100
834/834 [==============================] – 1秒2ミリ秒/ステップ–損失:0.5369
エポック10/100
834/834 [==============================] – 2秒2ミリ秒/ステップ–損失:0.4761
。
。
。
。
エポック95/100
834/834 [==============================] – 1秒2ミリ秒/ステップ–損失:0.4542
エポック96/100
834/834 [==============================] – 2秒2ミリ秒/ステップ–損失:0.4553
エポック97/100
834/834 [==============================] – 1秒2ミリ秒/ステップ–損失:0.4565
エポック98/100
834/834 [==============================] – 1秒2ミリ秒/ステップ–損失:0.4576
エポック99/100
834/834 [==============================] – 1秒2ミリ秒/ステップ–損失:0.4588
エポック100/100
834/834 [==============================] – 1秒2ミリ秒/ステップ–損失:0.4599
最後に、損失値は100エポックのトレーニングプロセス中に時間の経過とともに指数関数的に減少し、0.4599の値に達したことがわかります。
ステップ11–LSTM予測
モデルの準備ができたら、テストセットでLSTMネットワークを使用してトレーニングされたモデルを使用し、Microsoft株の隣接する終値を予測します。 これは、構築されたlstmモデルでpredictの単純な関数を使用して実行されます。
#LSTM予測
y_pred = lstm.predict(X_test)
ステップ12–真対予測調整終値– LSTM
最後に、テストセットの値を予測したので、グラフをプロットして、LSTMMachineLearningモデルによるAdjCloseの真の値とAdjCloseの予測値の両方を比較できます。
#True vs Predicted Adj Close Value – LSTM
plt.plot(y_test、label ='True Value')
plt.plot(y_pred、label ='LSTM値')
plt.title( "LSTMによる予測")
plt.xlabel('タイムスケール')
plt.ylabel('スケーリングされた米ドル')
plt.legend()
plt.show()
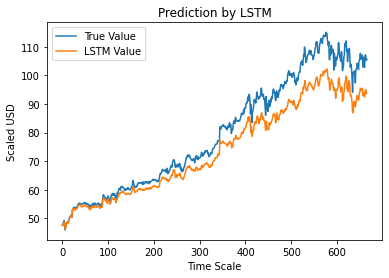
上のグラフは、上で構築された非常に基本的な単一のLSTMネットワークモデルによっていくつかのパターンが検出されたことを示しています。 いくつかのパラメーターを微調整し、モデルにLSTMレイヤーを追加することで、特定の企業の株価をより正確に表現できます。
結論
人工知能の例、機械学習について詳しく知りたい場合は、IIIT-BとupGradの機械学習とAIのエグゼクティブPGプログラムをご覧ください。このプログラムは、働く専門家向けに設計されており、450時間以上の厳格なトレーニング、30以上のケーススタディを提供しています。 &アサインメント、IIIT-B卒業生のステータス、5つ以上の実践的なキャップストーンプロジェクト、トップ企業との仕事の支援。
機械学習を使用して株式市場を予測できますか?
今日、私たちは市場動向を予測するのに役立つ多くの指標を持っています。 ただし、株式市場の最も正確な指標を見つけるには、高性能のコンピューターを探す必要があります。 株式市場はオープンシステムであり、複雑なネットワークと見ることができます。 ネットワークは、株式、企業、投資家、取引量の間の関係で構成されています。 サポートベクターマシンのようなデータマイニングアルゴリズムを使用することにより、数式を適用してこれらの変数間の関係を抽出できます。 株式市場は今や人間の予測を超えています。
株式市場の予測に最適なアルゴリズムはどれですか?
最良の結果を得るには、線形回帰を使用する必要があります。 線形回帰は、2つの異なる変数間の関係を決定するために使用される統計的アプローチです。 この例では、変数は価格と時間です。 株式市場の予測では、価格は独立変数であり、時間は従属変数です。 これら2つの変数間の線形関係を決定できれば、将来の任意の時点で株式の価値を正確に予測することができます。
株式市場の予測は分類または回帰の問題ですか?
答える前に、株式市場の予測が何を意味するのかを理解する必要があります。 それはバイナリ分類問題ですか、それとも回帰問題ですか? 株式の将来を予測したいとします。ここで、将来とは、翌日、週、月、または年を意味します。 ある時点での株式の過去のパフォーマンスが入力であり、将来が出力である場合、それは回帰問題です。 株式の過去のパフォーマンスと株式の将来が独立している場合、それは分類の問題です。