
Google CloudPlatformを使用したサーバーレスフロントエンドアプリケーションの構築
公開: 2022-03-10最近、アプリケーションの開発パラダイムは、アプリケーション内で使用されるリソースを手動で展開、スケーリング、更新する必要があることから、これらのリソースの管理のほとんどをサードパーティのクラウドサービスプロバイダーに依存することへと移行し始めています。
可能な限り迅速に市場に適合したアプリケーションを構築したい開発者または組織として、構成、展開、およびストレステストに費やす時間を短縮しながら、コアアプリケーションサービスをユーザーに提供することに主な焦点を当てることができます。あなたの申請。 これがユースケースである場合、サーバーレスの方法でアプリケーションのビジネスロジックを処理することが最善の選択肢かもしれません。 しかし、どのように?
この記事は、アプリケーション内で特定の機能を構築したいフロントエンドエンジニア、またはGoogleCloudPlatformにデプロイされたサーバーレスアプリケーションを使用して既存のバックエンドサービスから特定の機能を抽出して処理したいバックエンドエンジニアにとって有益です。
注:ここで取り上げる内容を活用するには、Reactの使用経験が必要です。 サーバーレスアプリケーションの経験は必要ありません。
始める前に、サーバーレスアプリケーションとは何か、フロントエンドエンジニアのコンテキスト内でアプリケーションを構築するときにサーバーレスアーキテクチャをどのように使用できるかを理解しましょう。
サーバーレスアプリケーション
サーバーレスアプリケーションは、再利用可能な小さなイベント駆動型機能に分割されたアプリケーションであり、アプリケーションの作成者に代わってパブリッククラウド内のサードパーティのクラウドサービスプロバイダーによってホストおよび管理されます。 これらは特定のイベントによってトリガーされ、オンデマンドで実行されます。 サーバーレスワードに付けられた「 less 」サフィックスはサーバーがないことを示しますが、これは100%の場合ではありません。 これらのアプリケーションは引き続きサーバーやその他のハードウェアリソースで実行されますが、この場合、これらのリソースは開発者によってプロビジョニングされるのではなく、サードパーティのクラウドサービスプロバイダーによってプロビジョニングされます。 したがって、これらはアプリケーション作成者にとってサーバーレスですが、サーバー上で実行され、パブリックインターネット経由でアクセスできます。
サーバーレスアプリケーションの使用例の例は、ランディングページにアクセスし、製品発売メールの受信をサブスクライブする潜在的なユーザーにメールを送信することです。 この段階では、おそらくバックエンドサービスを実行しておらず、メールを送信する必要があるため、バックエンドサービスの作成、展開、管理に必要な時間とリソースを犠牲にしたくないでしょう。 ここでは、メールクライアントを使用する単一のファイルを作成し、サーバーレスアプリケーションをサポートするクラウドプロバイダーにデプロイして、このサーバーレスアプリケーションをランディングページに接続している間、サーバーレスアプリケーションに代わってこのアプリケーションを管理させることができます。
サーバーレスアプリケーションやFunctionsAs A Service(FAAS)と呼ばれるものを活用することを検討する理由はたくさんありますが、フロントエンドアプリケーションでは、次のような非常に注目すべき理由を検討する必要があります。
- アプリケーションの自動スケーリング
サーバーレスアプリケーションは水平方向にスケーリングされ、この「スケールアウト」は呼び出しの量に基づいてクラウドプロバイダーによって自動的に実行されるため、アプリケーションに大きな負荷がかかっている場合、開発者はリソースを手動で追加または削除する必要はありません。 - 費用対効果
イベント駆動型であるため、サーバーレスアプリケーションは必要な場合にのみ実行されます。これは、呼び出された時間に基づいて請求されるため、料金に反映されます。 - 柔軟性
サーバーレスアプリケーションは再利用性が高くなるように構築されているため、単一のプロジェクトやアプリケーションに縛られることはありません。 特定の機能をサーバーレスアプリケーションに抽出し、複数のプロジェクトまたはアプリケーションに展開して使用できます。 サーバーレスアプリケーションは、アプリケーション作成者の優先言語で作成することもできますが、一部のクラウドプロバイダーは少数の言語しかサポートしていません。
サーバーレスアプリケーションを利用する場合、すべての開発者は、パブリッククラウド内に利用できるクラウドプロバイダーの膨大な配列を持っています。 この記事のコンテキスト内で、Google Cloud Platform上のサーバーレスアプリケーションに焦点を当てます。それらがどのように作成、管理、デプロイされ、GoogleCloud上の他の製品とどのように統合されるかについて説明します。 これを行うために、次のプロセスを実行しながら、この既存のReactアプリケーションに新しい機能を追加します。
- クラウド上でのユーザーのデータの保存と取得。
- GoogleCloudでのcronジョブの作成と管理。
- CloudFunctionsをGoogleCloudにデプロイします。
注:サーバーレスアプリケーションはReactのみにバインドされていません。優先するフロントエンドフレームワークまたはライブラリがHTTPリクエストを作成できる限り、サーバーレスアプリケーションを使用できます。
Google CloudFunctions
Google Cloudを使用すると、開発者はCloud Functionsを使用してサーバーレスアプリケーションを作成し、FunctionsFrameworkを使用してそれらを実行できます。 クラウド関数と呼ばれるものは、Google Cloudにデプロイされた再利用可能なイベント駆動型関数であり、6つの使用可能なイベントトリガーのうち特定のトリガーをリッスンし、実行するように記述された操作を実行します。
短命のクラウド関数(デフォルトの実行タイムアウトは60秒、最大9分)は、JavaScript、Python、Golang、およびJavaを使用して記述し、それらのランタイムを使用して実行できます。 JavaScriptでは、Nodeランタイムのいくつかの利用可能なバージョンを使用してのみ実行でき、Google Cloudで実行される主要な関数としてエクスポートされるため、プレーンJavaScriptを使用してCommonJSモジュールの形式で記述されます。
クラウド関数の例は、ユーザーのデータを処理する関数の空のボイラープレートである以下の関数です。
// index.js exports.firestoreFunction = function (req, res) { return res.status(200).send({ data: `Hello ${req.query.name}` }); } 上記には、関数をエクスポートするモジュールがあります。 実行されると、 HTTPルートと同様の要求引数と応答引数を受け取ります。
注:クラウド関数は、リクエストが行われるときにすべてのHTTPプロトコルに一致します。 クラウド関数の実行をリクエストするときに添付されるデータは、 GETリクエストのクエリ本文に存在するのに対し、 POSTリクエストのリクエスト本文に存在するため、リクエスト引数にデータを期待する場合は注意が必要です。
クラウド関数は、作成した関数が配置されているのと同じフォルダー内に@google-cloud/functions-frameworkパッケージをインストールするか、 npm i -g @google-cloud/functions-frameworkを実行して複数の関数に使用するグローバルインストールを実行することにより、開発中にローカルで実行できます。 npm i -g @google-cloud/functions-framework 。 インストールしたら、以下のようなエクスポートされたモジュールの名前でpackage.jsonスクリプトに追加する必要があります。
"scripts": { "start": "functions-framework --target=firestoreFunction --port=8000", } 上記のfirestoreFunctionのスクリプト内には、functions-frameworkを実行し、ポート8000でローカルに実行されるターゲット関数としてpackage.jsonを指定する単一のコマンドがあります。
curlを使用してローカルホストのポート8000にGETリクエストを行うことで、この関数のエンドポイントをテストできます。 以下のコマンドを端末に貼り付けると、それが実行され、応答が返されます。
curl https://localhost:8000?name="Smashing Magazine Author" 上記のコマンドは、 GET HTTPメソッドを使用してリクエストを行い、 200ステータスコードとクエリに追加された名前を含むオブジェクトデータで応答します。
クラウド機能のデプロイ
利用可能な展開方法のうち、ローカルマシンからクラウド機能を展開する簡単な方法の1つは、インストール後にクラウドSdkを使用することです。 GoogleCloud上のプロジェクトでgcloudsdkを認証した後、ターミナルから以下のコマンドを実行すると、ローカルで作成された関数がCloudFunctionサービスにデプロイされます。
gcloud functions deploy "demo-function" --runtime nodejs10 --trigger-http --entry-point=demo --timeout=60 --set-env-vars=[name="Developer"] --allow-unauthenticated以下で説明するフラグを使用して、上記のコマンドは「 demo-function 」という名前のHTTPトリガー関数をGoogleCloudにデプロイします。
- 名前
これは、クラウド関数をデプロイするときに付けられる名前であり、必須です。 -
region
これは、クラウド機能が展開されるリージョンです。 デフォルトでは、us-central1にデプロイされます。 -
trigger-http
これにより、関数のトリガータイプとしてHTTPが選択されます。 -
allow-unauthenticated
これにより、発信者が認証されているかどうかを確認せずに、生成されたエンドポイントを使用してインターネット経由でGoogleCloudの外部で関数を呼び出すことができます。 -
source
端末からデプロイする関数を含むファイルへのローカルパス。 -
entry-point
これは、関数が記述されたファイルからデプロイされる特定のエクスポートされたモジュールです。 -
runtime
これは、受け入れられたランタイムのこのリストの中で関数に使用される言語ランタイムです。 -
timeout
これは、タイムアウトする前に関数を実行できる最大時間です。 デフォルトでは60秒で、最大9分に設定できます。
注:関数で認証されていない要求を許可するということは、関数のエンドポイントを持っている人なら誰でも、許可せずに要求を行うことができることを意味します。 これを軽減するために、環境変数を介してエンドポイントを使用するか、各リクエストで承認ヘッダーをリクエストすることで、エンドポイントをプライベートに保つことができます。
デモ関数がデプロイされ、エンドポイントができたので、autocannonのグローバルインストールを使用して、実際のアプリケーションで使用されているかのようにこの関数をテストできます。 開いた端末からautocannon -d=5 -c=300 CLOUD_FUNCTION_URLを実行すると、5秒以内にクラウド機能への300の同時リクエストが生成されます。 これは、クラウド関数を開始し、関数のダッシュボードで探索できるいくつかのメトリックを生成するのに十分すぎるほどです。
注:関数のエンドポイントは、展開後にターミナルに出力されます。 そうでない場合は、ターミナルからgcloud function describe FUNCTION_NAMEを実行して、エンドポイントを含むデプロイされた関数の詳細を取得します。
ダッシュボードの[メトリック]タブを使用すると、最後のリクエストから、呼び出された回数、継続時間、関数のメモリフットプリント、および行われたリクエストを処理するためにスピンされたインスタンスの数で構成される視覚的な表現を確認できます。
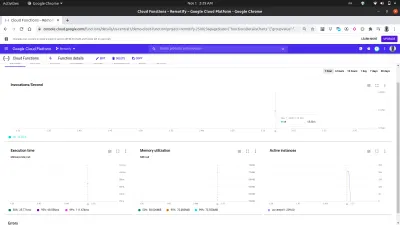
上の画像内のアクティブインスタンスチャートを詳しく見ると、Cloud Functionsの水平スケーリング容量が示されています。これは、オートキャノンを使用して行われたリクエストを処理するために、209個のインスタンスが数秒以内にスピンアップされたことがわかります。
クラウド機能ログ
Googleクラウドにデプロイされたすべての関数にはログがあり、この関数が実行されるたびに、そのログに新しいエントリが作成されます。 関数のダッシュボードの[ログ]タブから、クラウド関数からのすべてのログエントリのリストを確認できます。
以下は、 autocannonを使用して行ったリクエストの結果として作成されたデプロイdemo-functionのログエントリです。
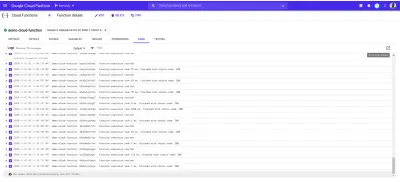
上記の各ログエントリは、関数がいつ実行されたか、実行にかかった時間、および関数が終了したステータスコードを正確に示しています。 関数に起因するエラーがある場合、発生した行を含むエラーの詳細がここのログに表示されます。
Google Cloudのログエクスプローラーを使用すると、クラウド機能からのログに関するより包括的な詳細を確認できます。
フロントエンドアプリケーションを使用したクラウド機能
クラウド機能は、フロントエンドエンジニアにとって非常に便利で強力です。 バックエンドアプリケーションの管理の知識がないフロントエンドエンジニアは、機能をクラウド機能に抽出し、Google Cloudにデプロイして、エンドポイントを介してクラウド機能にHTTPリクエストを送信することでフロントエンドアプリケーションで使用できます。
フロントエンドアプリケーションでクラウド機能をどのように使用できるかを示すために、このReactアプリケーションにさらに機能を追加します。 アプリケーションには、認証とホームページのセットアップの間の基本的なルーティングがすでにあります。 作成されたクラウド関数の使用はアプリケーションレデューサー内で行われるため、React ContextAPIを使用してアプリケーションの状態を管理するように拡張します。
まず、 createContext APIを使用してアプリケーションのコンテキストを作成し、アプリケーション内のアクションを処理するためのレデューサーも作成します。
// state/index.js import { createContext } from “react”;export const UserReducer =(action、state)=> {switch(action.type){case“ CREATE-USER”:break; ケース「UPLOAD-USER-IMAGE」:ブレーク; ケース「FETCH-DATA」:ブレークケース「LOGOUT」:ブレーク; デフォルト:console.log(
${action.type} is not recognized)}};export const userState = {user:null、isLoggedIn:false};
export const UserContext = createContext(userState);
上記では、switchステートメントを含むUserReducer関数を作成することから始めました。これにより、ディスパッチされたアクションのタイプに基づいて操作を実行できます。 switchステートメントには4つのケースがあり、これらは処理するアクションです。 今のところ、彼らはまだ何もしていませんが、クラウド機能との統合を開始すると、それらで実行されるアクションを段階的に実装します。
また、React createContext APIを使用してアプリケーションのコンテキストを作成およびエクスポートし、 userStateオブジェクトのデフォルト値を指定しました。このオブジェクトには、認証後にnullからユーザーのデータに現在更新されるユーザー値とisLoggedInブール値が含まれています。ユーザーがログインしているかどうか。
これでコンテキストの使用に進むことができますが、その前に、子コンポーネントがコンテキストの値の変更にサブスクライブできるように、 UserContextにアタッチされたプロバイダーでアプリケーションツリー全体をラップする必要があります。
// index.js import React from "react"; import ReactDOM from "react-dom"; import "./index.css"; import App from "./app"; import { UserContext, userState } from "./state/"; ReactDOM.render( <React.StrictMode> <UserContext.Provider value={userState}> <App /> </UserContext.Provider> </React.StrictMode>, document.getElementById("root") ); serviceWorker.unregister(); EnterアプリケーションをルートコンポーネントのUserContextプロバイダーでラップし、以前に作成したuserStateのデフォルト値をvaluepropに渡しました。
アプリケーションの状態が完全にセットアップされたので、クラウド機能を介してGoogle CloudFirestoreを使用したユーザーのデータモデルの作成に進むことができます。
アプリケーションデータの処理
このアプリケーション内のユーザーのデータは、一意のID、電子メール、パスワード、および画像へのURLで構成されます。 クラウド機能を使用すると、このデータはGoogleCloudPlatformで提供されるCloudFirestoreServiceを使用してクラウドに保存されます。
柔軟なNoSQLデータベースであるGoogleCloud Firestoreは、Firebase Realtime Databaseから作成されたもので、オフラインデータのサポートに加えてより豊富で高速なクエリを可能にする新しい拡張機能を備えています。 Firestoreサービス内のデータは、MongoDBなどの他のNoSQLデータベースと同様のコレクションとドキュメントに編成されます。
Firestoreには、Google CloudConsoleから視覚的にアクセスできます。 起動するには、左側のナビゲーションペインを開き、[データベース]セクションまでスクロールして、[Firestore]をクリックします。 これにより、既存のデータを持つユーザーのコレクションのリストが表示されるか、既存のコレクションがない場合にユーザーに新しいコレクションを作成するように求められます。 アプリケーションで使用するユーザーコレクションを作成します。
Google Cloud Platformの他のサービスと同様に、Cloud Firestoreにもノード環境で使用するために構築されたJavaScriptクライアントライブラリがあります(ブラウザで使用するとエラーがスローされます)。 即興では、 @google-cloud/firestoreパッケージを使用してクラウド関数でCloudFirestoreを使用します。
クラウド機能でクラウドファイヤーストアを使用する
まず、作成した最初の関数の名前をdemo-functionからfirestoreFunctionに変更し、それを展開してFirestoreに接続し、データをユーザーのコレクションに保存します。
require("dotenv").config(); const { Firestore } = require("@google-cloud/firestore"); const { SecretManagerServiceClient } = require("@google-cloud/secret-manager"); const client = new SecretManagerServiceClient(); exports.firestoreFunction = function (req, res) { return { const { email, password, type } = req.body; const firestore = new Firestore(); const document = firestore.collection("users"); console.log(document) // prints details of the collection to the function logs if (!type) { res.status(422).send("An action type was not specified"); } switch (type) { case "CREATE-USER": break case "LOGIN-USER": break; default: res.status(422).send(`${type} is not a valid function action`) } }; ファイヤーストアに関連するより多くの操作を処理するために、アプリケーションの認証ニーズを処理するための2つのケースを含むswitchステートメントを追加しました。 switchステートメントは、アプリケーションからこの関数にリクエストを行うときにリクエスト本文に追加するtype式を評価します。このtypeデータがリクエスト本文に存在しない場合、リクエストは不正なリクエストと400ステータスコードとして識別されます。欠落しているtypeを示すメッセージと一緒に応答として送信されます。
CloudFirestoreクライアントライブラリ内のApplicationDefaultCredentials(ADC)ライブラリを使用して、Firestoreとの接続を確立します。 次の行で、別の変数でコレクションメソッドを呼び出し、コレクションの名前を渡します。 これを使用して、含まれているドキュメントの収集に対して他の操作をさらに実行します。
注: Google Cloud上のサービスのクライアントライブラリは、コンストラクターの初期化時に渡された作成済みのサービスアカウントキーを使用して、それぞれのサービスに接続します。 サービスアカウントキーが存在しない場合、デフォルトでアプリケーションデフォルトクレデンシャルが使用され、クラウド機能に割り当てられたIAMロールを使用して接続されます。
Gcloud SDKを使用してローカルにデプロイされた関数のソースコードを編集した後、ターミナルから前のコマンドを再実行して、クラウド関数を更新および再デプロイできます。
接続が確立されたので、 CREATE-USERケースを実装して、リクエスト本文のデータを使用して新しいユーザーを作成できます。
require("dotenv").config(); const { Firestore } = require("@google-cloud/firestore"); const path = require("path"); const { v4 : uuid } = require("uuid") const cors = require("cors")({ origin: true }); const client = new SecretManagerServiceClient(); exports.firestoreFunction = function (req, res) { return cors(req, res, () => { const { email, password, type } = req.body; const firestore = new Firestore(); const document = firestore.collection("users"); if (!type) { res.status(422).send("An action type was not specified"); } switch (type) { case "CREATE-USER": if (!email || !password) { res.status(422).send("email and password fields missing"); } const id = uuid() return bcrypt.genSalt(10, (err, salt) => { bcrypt.hash(password, salt, (err, hash) => { document.doc(id) .set({ id : id email: email, password: hash, img_uri : null }) .then((response) => res.status(200).send(response)) .catch((e) => res.status(501).send({ error : e }) ); }); }); case "LOGIN": break; default: res.status(400).send(`${type} is not a valid function action`) } }); }; 保存しようとしているドキュメントのIDとして使用するuuidパッケージを使用して、ドキュメントのsetメソッドとユーザーのIDに渡すことでUUIDを生成しました。 デフォルトでは、挿入されたすべてのドキュメントでランダムIDが生成されますが、この場合、画像のアップロードを処理するときにドキュメントを更新します。UUIDは、特定のドキュメントを更新するために使用されます。 ユーザーのパスワードをプレーンテキストで保存するのではなく、最初にbcryptjsを使用してソルトし、次に結果のハッシュをユーザーのパスワードとして保存します。
firestoreFunctionクラウド関数をアプリに統合し、ユーザーレデューサー内のCREATE_USERケースから使用します。
[アカウントの作成]ボタンをクリックすると、 CREATE_USERタイプのレデューサーにアクションがディスパッチされ、タイプされた電子メールとパスワードを含むPOSTリクエストがfirestoreFunction関数のエンドポイントに送信されます。
import { createContext } from "react"; import { navigate } from "@reach/router"; import Axios from "axios"; export const userState = { user : null, isLoggedIn: false, }; export const UserReducer = (state, action) => { switch (action.type) { case "CREATE_USER": const FIRESTORE_FUNCTION = process.env.REACT_APP_FIRESTORE_FUNCTION; const { userEmail, userPassword } = action; const data = { type: "CREATE-USER", email: userEmail, password: userPassword, }; Axios.post(`${FIRESTORE_FUNCTION}`, data) .then((res) => { navigate("/home"); return { ...state, isLoggedIn: true }; }) .catch((e) => console.log(`couldnt create user. error : ${e}`)); break; case "LOGIN-USER": break; case "UPLOAD-USER-IMAGE": break; case "FETCH-DATA" : break case "LOGOUT": navigate("/login"); return { ...state, isLoggedIn: false }; default: break; } }; export const UserContext = createContext(userState); 上記では、Axiosを使用してfirestoreFunctionにリクエストを送信し、このリクエストが解決された後、ユーザーの初期状態をnullからリクエストから返されたデータに設定し、最後にユーザーを認証済みユーザーとしてホームページにルーティングします。 。

この時点で、新しいユーザーはアカウントを正常に作成し、ホームページにルーティングできます。 このプロセスは、Firestoreを使用してクラウド機能からデータの基本的な作成を実行する方法を示しています。
ファイルストレージの処理
アプリケーションでのユーザーのファイルの保存と取得は、ほとんどの場合、アプリケーション内で非常に必要な機能です。 node.jsバックエンドに接続されたアプリケーションでは、アップロードされたファイルが入ってくるmultipart / form-dataを処理するミドルウェアとしてMulterがよく使用されます。ただし、node.jsバックエンドがない場合は、オンラインファイルを使用できます。静的アプリケーションアセットを保存するためのGoogleCloudStorageなどのストレージサービス。
Google Cloud Storageは、アプリケーションのオブジェクトとして任意の量のデータをバケットに保存するために使用される、グローバルに利用可能なファイルストレージサービスです。 小規模アプリケーションと大規模アプリケーションの両方の静的資産のストレージを処理するのに十分な柔軟性があります。
アプリケーション内でCloudStorageサービスを使用するには、利用可能なStorage APIエンドポイントを利用するか、公式ノードのStorageクライアントライブラリを使用します。 ただし、ノードストレージクライアントライブラリはブラウザウィンドウ内では機能しないため、ライブラリを使用するクラウド関数を利用できます。
この例は、作成されたクラウドバケットにファイルを接続してアップロードするクラウド関数です。
const cors = require("cors")({ origin: true }); const { Storage } = require("@google-cloud/storage"); const StorageClient = new Storage(); exports.Uploader = (req, res) => { const { file } = req.body; StorageClient.bucket("TEST_BUCKET") .file(file.name) .then((response) => { console.log(response); res.status(200).send(response) }) .catch((e) => res.status(422).send({error : e})); }); };上記のクラウド機能から、次の2つの主要な操作を実行しています。
まず、
Storage constructor内でCloud Storageへの接続を作成し、GoogleCloudのApplicationDefault Credentials(ADC)機能を使用してCloudStorageで認証します。次に、
.fileメソッドを呼び出してファイルの名前を渡すことにより、リクエスト本文に含まれているファイルをTEST_BUCKETにアップロードします。 これは非同期操作であるため、promiseを使用して、このアクションがいつ解決されたかを確認し、200応答を返送して、呼び出しのライフサイクルを終了します。
これで、上記のUploader Cloud関数を拡張して、ユーザーのプロファイル画像のアップロードを処理できます。 クラウド機能は、ユーザーのプロファイルイメージを受け取り、それをアプリケーションのクラウドバケット内に保存してから、Firestoreサービスのユーザーコレクション内のユーザーのimg_uriデータを更新します。
require("dotenv").config(); const { Firestore } = require("@google-cloud/firestore"); const cors = require("cors")({ origin: true }); const { Storage } = require("@google-cloud/storage"); const StorageClient = new Storage(); const BucketName = process.env.STORAGE_BUCKET exports.Uploader = (req, res) => { return Cors(req, res, () => { const { file , userId } = req.body; const firestore = new Firestore(); const document = firestore.collection("users"); StorageClient.bucket(BucketName) .file(file.name) .on("finish", () => { StorageClient.bucket(BucketName) .file(file.name) .makePublic() .then(() => { const img_uri = `https://storage.googleapis.com/${Bucket}/${file.path}`; document .doc(userId) .update({ img_uri, }) .then((updateResult) => res.status(200).send(updateResult)) .catch((e) => res.status(500).send(e)); }) .catch((e) => console.log(e)); }); }); };これで、上記のアップロード機能が拡張され、次の追加操作が実行されました。
- まず、Firestoreサービスへの新しい接続を確立して、Firestoreコンストラクターを初期化することで
usersコレクションを取得し、Application Default Credentials(ADC)を使用してCloudStorageで認証します。 - リクエスト本文に追加されたファイルをアップロードした後、アップロードされたファイルの
makePublicメソッドを呼び出して、パブリックURLを介してアクセスできるように、ファイルをパブリックにします。 Cloud Storageのデフォルトのアクセス制御によると、ファイルを公開しないと、インターネット経由でファイルにアクセスできず、アプリケーションの読み込み時にこれを実行できます。
注:ファイルを公開するということは、アプリケーションを使用するすべての人がファイルリンクをコピーして、ファイルに無制限にアクセスできることを意味します。 これを防ぐ1つの方法は、署名付きURLを使用して、ファイルを完全に公開するのではなく、バケット内のファイルへの一時的なアクセスを許可することです。
- 次に、ユーザーの既存のデータを更新して、アップロードされたファイルのURLを含めます。 Firestoreの
WHEREクエリを使用して特定のユーザーのデータを検索し、リクエスト本文に含まれているuserIdを使用してから、新しく更新された画像のURLを含むようにimg_uriフィールドを設定します。
上記のクラウドのUpload機能は、Firestoreサービス内にユーザーを登録しているすべてのアプリケーションで使用できます。 エンドポイントにPOSTリクエストを送信し、ユーザーのISと画像をリクエスト本文に配置するために必要なすべてのこと。
アプリケーション内でのこの例は、 UPLOAD-FILEの場合です。これは、関数にPOSTリクエストを送信し、リクエストから返された画像リンクをアプリケーション状態にします。
# index.js import Axios from 'axios' const UPLOAD_FUNCTION = process.env.REACT_APP_UPLOAD_FUNCTION export const UserReducer = (state, action) => { switch (action.type) { case "CREATE-USER" : # .....CREATE-USER-LOGIC .... case "UPLOAD-FILE": const { file, id } = action return Axios.post(UPLOAD_FUNCTION, { file, id }, { headers: { "Content-Type": "image/png", }, }) .then((response) => {}) .catch((e) => console.log(e)); default : return console.log(`${action.type} case not recognized`) } } 上記のスイッチケースから、Axiosを使用してUPLOAD_FUNCTIONにPOSTリクエストを行い、追加されたファイルをリクエスト本文に含め、リクエストヘッダーに画像Content-Typeを追加しました。
アップロードが成功すると、クラウド関数から返される応答には、Googleクラウドストレージにアップロードされた画像の有効なURLを含むように更新されたユーザーのデータドキュメントが含まれます。 次に、ユーザーの状態を更新して新しいデータを含めることができます。これにより、プロファイルコンポーネントのユーザーのプロファイル画像のsrc要素も更新されます。
cronジョブの処理
ユーザーへの電子メールの送信や特定の時間に内部アクションを実行するなどの反復的な自動化されたタスクは、ほとんどの場合、アプリケーションに含まれている機能です。 通常のnode.jsアプリケーションでは、このようなタスクは、node-cronまたはnode-scheduleを使用してcronジョブとして処理できます。 Google Cloud Platformを使用してサーバーレスアプリケーションを構築する場合、CloudSchedulerはcron操作を実行するようにも設計されています。
注: CloudSchedulerは将来実行されるジョブの作成においてUnixcronユーティリティと同様に機能しますが、CloudSchedulerはcronユーティリティのようにコマンドを実行しないことに注意することが重要です。 むしろ、指定されたターゲットを使用して操作を実行します。
名前が示すように、Cloud Schedulerを使用すると、ユーザーは将来実行される操作をスケジュールできます。 各操作はジョブと呼ばれ、クラウドコンソールのスケジューラセクションから、視覚的に作成、更新、さらには破棄することができます。 名前と説明のフィールドに加えて、CloudSchedulerのジョブは次のもので構成されます。
- 周波数
これは、Cronジョブの実行をスケジュールするために使用されます。 スケジュールは、Linux環境でcronテーブルにバックグラウンドジョブを作成するときに元々使用されていたunix-cron形式を使用して指定されます。 unix-cron形式は、それぞれが時点を表す5つの値を持つ文字列で構成されます。 以下に、5つの文字列のそれぞれとそれらが表す値を示します。
- - - - - - - - - - - - - - - - minute ( - 59 ) | - - - - - - - - - - - - - hour ( 0 - 23 ) | | - - - - - - - - - - - - day of month ( 1 - 31 ) | | | - - - - - - - - - month ( 1 - 12 ) | | | | - - - - - -- day of week ( 0 - 6 ) | | | | | | | | | | | | | | | | | | | | | | | | | * * * * *Crontabジェネレーターツールは、ジョブの頻度-時間値を生成しようとするときに便利です。 時間の値をまとめるのが難しい場合は、Crontabジェネレーターに視覚的なドロップダウンがあり、スケジュールを構成する値を選択し、生成された値をコピーして頻度として使用できます。
- タイムゾーン
cronジョブが実行されるタイムゾーン。 タイムゾーン間の時間差により、指定されたタイムゾーンが異なるcronジョブの実行時間は異なります。 - 目標
これは、指定されたジョブの実行で使用されるものです。 ターゲットは、ジョブが指定された時間にURLにリクエストを送信するHTTPタイプ、またはジョブがメッセージを公開したり、AppEngineアプリケーションからメッセージをプルしたりできるPub / Subトピックである可能性があります。
クラウドスケジューラは、HTTPでトリガーされるクラウド機能と完全に組み合わされます。 ターゲットをHTTPに設定してCloudScheduler内のジョブを作成すると、このジョブを使用してクラウド機能を実行できます。 実行する必要があるのは、クラウド関数のエンドポイントを指定し、リクエストのHTTP動詞を指定してから、表示された本文フィールドに関数に渡す必要のあるデータを追加することだけです。 以下のサンプルに示すように:
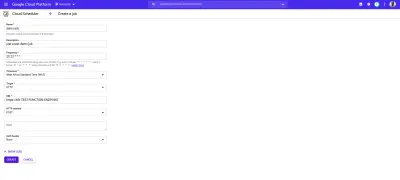
上の画像のcronジョブは、毎日午前9時までに実行され、クラウド関数のサンプルエンドポイントにPOSTリクエストを送信します。
cronジョブのより現実的な使用例は、Mailgunなどの外部メールサービスを使用して、指定された間隔でスケジュールされた電子メールをユーザーに送信することです。 これが実際に動作することを確認するために、nodemailerJavaScriptパッケージを使用して指定された電子メールアドレスにHTML電子メールを送信してMailgunに接続する新しいクラウド関数を作成します。
# index.js require("dotenv").config(); const nodemailer = require("nodemailer"); exports.Emailer = (req, res) => { let sender = process.env.SENDER; const { reciever, type } = req.body var transport = nodemailer.createTransport({ host: process.env.HOST, port: process.env.PORT, secure: false, auth: { user: process.env.SMTP_USERNAME, pass: process.env.SMTP_PASSWORD, }, }); if (!reciever) { res.status(400).send({ error: `Empty email address` }); } transport.verify(function (error, success) { if (error) { res .status(401) .send({ error: `failed to connect with stmp. check credentials` }); } }); switch (type) { case "statistics": return transport.sendMail( { from: sender, to: reciever, subject: "Your usage satistics of demo app", html: { path: "./welcome.html" }, }, (error, info) => { if (error) { res.status(401).send({ error : error }); } transport.close(); res.status(200).send({data : info}); } ); default: res.status(500).send({ error: "An available email template type has not been matched.", }); } };Using the cloud function above we can send an email to any user's email address specified as the receiver value in the request body. It performs the sending of emails through the following steps:
- It creates an SMTP transport for sending messages by passing the
host,userandpasswhich stands for password, all displayed on the user's Mailgun dashboard when a new account is created. - Next, it verifies if the SMTP transport has the credentials needed in order to establish a connection. If there's an error in establishing the connection, it ends the function's invocation and sends back a
401 unauthenticatedstatus code. - Next, it calls the
sendMailmethod to send the email containing the HTML file as the email's body to the receiver's email address specified in thetofield.
Note : We use a switch statement in the cloud function above to make it more reusable for sending several emails for different recipients. This way we can send different emails based on the type field included in the request body when calling this cloud function.
Now that there is a function that can send an email to a user; we are left with creating the cron job to invoke this cloud function. This time, the cron jobs are created dynamically each time a new user is created using the official Google cloud client library for the Cloud Scheduler from the initial firestoreFunction .
We expand the CREATE-USER case to create the job which sends the email to the created user at a one-day interval.
require("dotenv").config();cloc const { Firestore } = require("@google-cloud/firestore"); const scheduler = require("@google-cloud/scheduler") const cors = require("cors")({ origin: true }); const EMAILER = proccess.env.EMAILER_ENDPOINT const parent = ScheduleClient.locationPath( process.env.PROJECT_ID, process.env.LOCATION_ID ); exports.firestoreFunction = function (req, res) { return cors(req, res, () => { const { email, password, type } = req.body; const firestore = new Firestore(); const document = firestore.collection("users"); const client = new Scheduler.CloudSchedulerClient() if (!type) { res.status(422).send({ error : "An action type was not specified"}); } switch (type) { case "CREATE-USER":const job = { httpTarget: { uri: process.env.EMAIL_FUNCTION_ENDPOINT, httpMethod: "POST", body: { email: email, }, }, schedule: "*/30 */6 */5 10 4", timezone: "Africa/Lagos", }if (!email || !password) { res.status(422).send("email and password fields missing"); } return bcrypt.genSalt(10, (err, salt) => { bcrypt.hash(password, salt, (err, hash) => { document .add({ email: email, password: hash, }) .then((response) => {client.createJob({ parent : parent, job : job }).then(() => res.status(200).send(response)) .catch(e => console.log(`unable to create job : ${e}`) )}) .catch((e) => res.status(501).send(`error inserting data : ${e}`) ); }); }); default: res.status(422).send(`${type} is not a valid function action`) } }); };
From the snippet above, we can see the following:
- A connection to the Cloud Scheduler from the Scheduler constructor using the Application Default Credentials (ADC) is made.
- We create an object consisting of the following details which make up the cron job to be created:
-
uri
The endpoint of our email cloud function in which a request would be made to. -
body
This is the data containing the email address of the user to be included when the request is made. -
schedule
The unix cron format representing the time when this cron job is to be performed.
-
- After the promise from inserting the user's data document is resolved, we create the cron job by calling the
createJobmethod and passing in the job object and the parent. - The function's execution is ended with a
200status code after the promise from thecreateJoboperation has been resolved.
After the job is created, we'll see it listed on the scheduler page.
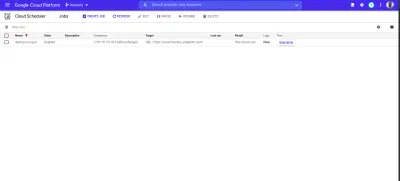
From the image above we can see the time scheduled for this job to be executed. We can decide to manually run this job or wait for it to be executed at the scheduled time.
結論
Within this article, we have had a good look into serverless applications and the benefits of using them. We also had an extensive look at how developers can manage their serverless applications on the Google Cloud using Cloud Functions so you now know how the Google Cloud is supporting the use of serverless applications.
Within the next years to come, we will certainly see a large number of developers adapt to the use of serverless applications when building applications. If you are using cloud functions in a production environment, it is recommended that you read this article from a Google Cloud advocate on “6 Strategies For Scaling Your Serverless Applications”.
The source code of the created cloud functions are available within this Github repository and also the used front-end application within this Github repository. The front-end application has been deployed using Netlify and can be tested live here.
参考文献
- Google Cloud
- クラウド機能
- クラウドソースリポジトリ
- Cloud Scheduler overview
- CloudFirestore
- “6 Strategies For Scaling Your Serverless Applications,” Preston Holmes