
ソフトウェア製品のデータオンボーディングの課題を克服する方法
公開: 2022-03-10この記事は、人とデータの間の障壁を取り除くために、人間中心の美しい体験を生み出すFlatfileの親愛なる友人たちによって親切にサポートされています。 ありがとう!

新しいソフトウェアに多額のお金を払っても構わないと思っている企業は、ほとんどの場合、ゼロから始めているわけではありません。 彼らは確立されたビジネスを運営しており、十分に構築され、文書化されたプロセスを備えています。 したがって、持ち越すデータは大量にあります。
結果として、新しいアプリを導入するという決定は、彼らが軽視するものではありません。 内部プロセスを変更する必要があります。 チームに新しいソリューションを採用させるには時間がかかる場合があります。 既存のシステムや外部ツールとの統合が問題になる可能性があります。 そうそう、そして心配すべきコンプライアンスの問題もあります。
これは、最初から一流のエクスペリエンスを提供するために、新しいソフトウェアに多くのプレッシャーがあることを意味します。 データをオンボーディングするためのシンプルで直感的な方法を企業に提供することに失敗すると、結果として顧客の解約率が高くなることが予想されます。
価値を高めるために顧客からのデータを必要とする製品を設計している場合、データのオンボーディングプロセスを構築するために知っておくべきことは次のとおりです。
データのオンボーディングとユーザーの満足度の相関関係
ビジネスソフトウェアは、基本的に、ユーザーのデータが入力されるのを待っている単なる空のボックスです。 ユーザーのデータを完璧にオンボードする機能がなければ、ソフトウェアは本質的に役に立たなくなります。
データのオンボーディングプロセスを正しく行うとどうなるかを見てみましょう。
エンドユーザーのメリット
データのオンボーディング部分を釘付けにすることができる場合は、エンドユーザーが次のメリットを享受することを期待してください。
- 彼らは彼らの決定により自信を持つでしょう。
完全で正確なデータがソフトウェアに転送されると、ユーザーはサインアップ後すぐにその価値を実際に確認できます。 これは彼らの決定を二度と推測する余地をほとんど残さず、それは製品に対する全体的な満足度を高め、最終的にはあなたのビジネスのためにより多くのお金をもたらします。 - チームの賛同が得られます。
ポジティブなデータオンボーディングエクスペリエンスにより、顧客は製品をより速く使用でき、価値を得るのに必要な時間を短縮できます。 したがって、実際には、データのオンボーディングは、顧客とそのチームがアプリの残りの部分をどのように表示するかについての段階を設定します。 - 彼らはソフトウェアでより多くの成功を経験するでしょう。
ユーザーは、データのフォーマットやクリーンアップ、エラーの多いインポートプロセスのトラブルシューティングについてストレスを感じる必要がないため、製品とその機能をさらに活用できます。
ソフトウェア開発者のメリット
ソフトウェアプロバイダー(あなたおよび/またはあなたのクライアント)にもメリットがあります:
- ユーザーの満足度を向上させます。
エンドユーザーは、データを製品にオンボードする方法を理解するために技術的なウィザードである必要はありません。 これを軽視すると、解約率が低下し、より多くのユーザーを引き付け、長期にわたってより多くの忠実なユーザーを維持できます。 - カスタマーサービスに費やす時間を減らします。
障害のあるデータオンボーディングプロセスをサポートする必要があることや、データのフォーマットやユーザーの検証などのタスクを引き継ぐことについて心配する必要はありません。 代わりに、常に火を消すのではなく、顧客とのより良い関係を築くために時間とエネルギーを費やしてください。
Tableclothの共同創設者兼CTOであるKellyAbbottは、次のことを証明できます。「ファイルとのやり取りに費やす時間を95%削減しました。 基本的には、これらの問題を解決するためにすべての手が働いていました。」
- あなたの製品に大きな自信を持ってください。
柔軟で強力なデータオンボーディングソリューションがある場合、ユーザーがインポートできるデータとインポートできないデータを制限する必要はありません。 それはもはや制限ではありません。
アボットが説明するように:「これにより、クライアントに求めているデータについてより熟考することができました。 修正に時間がかかりすぎる可能性のあるデータを要求することを避ける必要がなくなりました。 Flatfileはその問題を排除し、分析に組み込むことができるさまざまなタイプのデータを実験する意欲を向上させました。 さまざまなデータ型をいじくり回す時間が長くなるほど、市場で付加価値を生み出す洞察を明らかにする可能性が高くなります。 それは私たちのようなスタートアップにとって不可欠です。」
- お金を節約します。
サードパーティのデータオンボーディングソリューションにお金をかける必要がありますが、カスタムビルドのデータインポーター、オンボーディングプロセス、およびクライアントとの関係を管理するために費やす時間とお金を節約できます。 (たとえば、テーブルクロスはFlatfileを採用したときに数万ドルを節約しました。)
ソフトウェア製品のデータオンボーディングの課題
データのオンボーディングにおける一般的な課題と、FlatfileConciergeがそれらをどのように取り除くかを見てみましょう。
課題1:集計するデータがたくさんある
新しいビジネスソフトウェアにサインアップするとき、ユーザーはおそらく、基本的なアカウント情報の入力、設定の構成、ユーザーの追加など、少し前もって作業を行うことを期待します。 あなたがしたい最後のことは、彼らのためにより多くの仕事を引き起こすであろうデータインポーターで彼らを驚かせることです。
たとえば、CRMを構築したとします。
ソフトウェアがスタートアップや他の新しいビジネスをターゲットにしていない限り、ユーザーは大量の外部データを持ち込むことになります。 例えば:
- クライアント、見込み客、ベンダー、パートナー、チームメンバーの連絡先情報。
- アカウントや販売履歴などの既存の顧客データ。
- 通信履歴などの見込みデータ。
- 販売パイプラインの詳細。
- チームおよび個人の目標と指標。
CRMがユーザーの以前のすべてのCRMと直接統合されていない限り、ユーザーはこのデータをどのように移動しますか? コピーアンドペースト? CSVテンプレート?
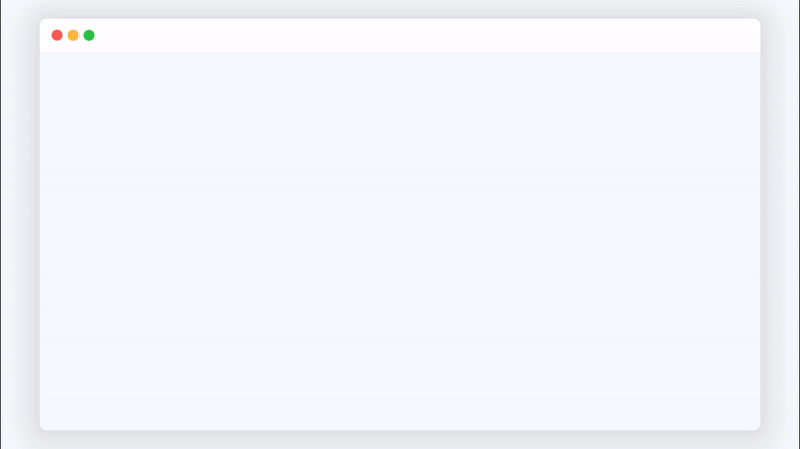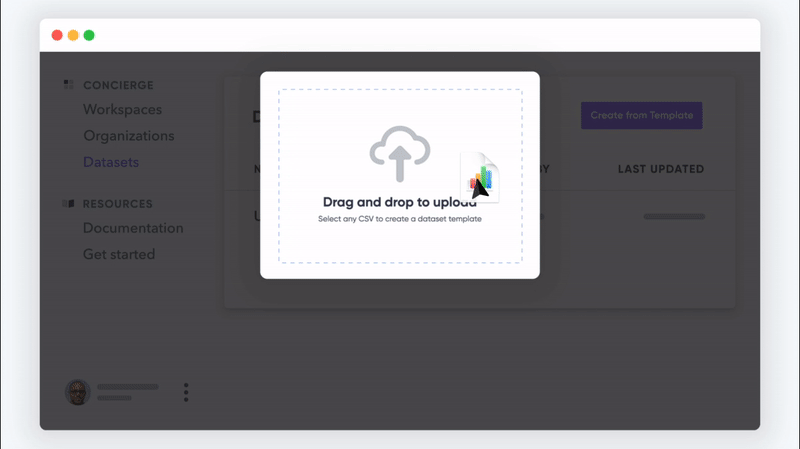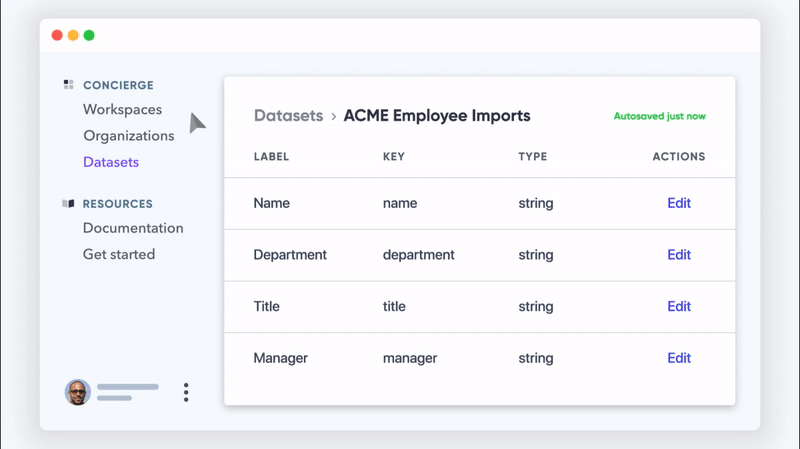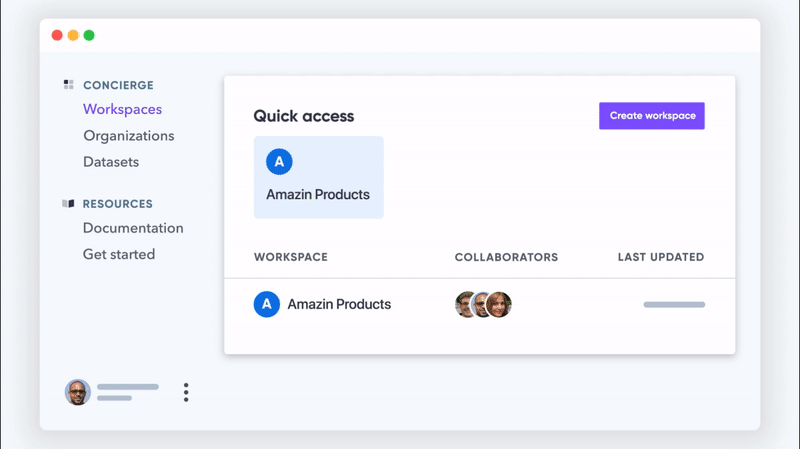
さらに、CRMが情報を取り込む他のすべてのソースについて考える必要があります。 支払いゲートウェイ。 営業チームのドライブにあるスプレッドシート。 あなたの会社に電子メールまたはファックスで送信された署名済みの契約。 さまざまな場所や人々からのデータがたくさんあります。
修正
Flatfileコンシェルジュがこの問題を解決するために行うことはたくさんあります。
手始めに、さまざまなファイルタイプからデータをインポートできます。
- CSV、
- TSV、
- XLS、
- XML、
- もっと。
この種の柔軟性により、ユーザーはデータを1つの特定のファイルタイプに転送し、転送中に発生したエラーをクリーンアップすることを心配する必要がありません。 Flatfile Conciergeは、さまざまなデータタイプのさまざまなファイルタイプを処理し、すべてを簡単に検証できます。
考慮すべきもう1つのことは、インポートされた各ファイルとそれに対応するデータをソフトウェアがどのように追跡および整理するかです。
Flatfileでユーザーができることは、データを配置するための共同ワークスペースを作成することです。チームメンバーがワークスペースに新しいデータを追加すると、以下を含むレコードがキャプチャされます。
- アップロード日、
- ファイル名、
- データを送信したユーザー、
- 追加された行数、
- バージョン履歴、
- アップロードエラー。
これにより、物事を整理し、提供するデータに対して全員に説明責任を負わせることができます。 また、この情報は一元化されたダッシュボードからすぐに利用できるため、何が、誰によって、いつアップロードされたかについての秘密はありません。 スプレッドシートデータを再アップロードしなくても、インポートエラーを共同で修正することもできます。

課題2:データはさまざまな州にインポートされます
ソフトウェアユーザーにデータを製品に転送する機能を与える場合、エンドユーザーのデータを事前にフォーマットまたはクリーンアップすることに関して、あなたやソフトウェアチームができることは多くありません。 また、そうする必要はありません。 あなたの仕事は、顧客がソフトウェアの価値を確実に理解できるようにすることです。 データのインポートに苦労しないでください。
スプレッドシートテンプレートを提供することもできますが、その場合は、すべてのデータの再フォーマットに時間を費やす必要があります。 ナレッジベースを紹介することもできますが、これも、エンドユーザーがその余分な作業を進んで行うことを前提としています。
実際には、ユーザーは新しいソフトウェアの内部に入り、仕事に取り掛かるのを急いでいるでしょう。 彼らはこれに対処するために立ち止まるつもりはありません。 それがソフトウェアの仕事です。
ただし、多くのデータオンボーディングソリューションは、乱雑なスプレッドシートをうまく処理できません。 一部のデータが何であるかを認識するのに苦労するだけでなく(多くの場合、データモデルが自分のデータモデルと一致しないため)、アプリケーションは特定のスプレッドシート列の受け入れを拒否します。
データを適切に整理またはラベル付けしなかったり、チームにその方法を教えたりしなかった(または、そもそも何をすべきかわからなかった)ことがエンドユーザーの責任であるとしても、最終的には誰のせいになると思いますかデータがインポートされないのはいつですか?
修正
Flatfile ConciergeのインポーターはAIを利用しています。つまり、ソフトウェア(およびデータインポーター)は実際にエンドユーザーのために作業を行うことができます。
高度な検証ロジックを使用して、データインポーターはデータが何であるかとデータがどこに行くかを把握できます。
Flatfileは、列と対応するデータをソフトウェアの実際のデータフィールドに自動的に照合しますが、ユーザーは、システムに許可する前に、その場合を確認する機会があります。
これが発生する前に、バックエンドで少し作業を行って、Flatfileがユーザーのデータをどう処理するかを確実に認識できるようにすることができます。
- Flatfileが、ユーザーがインポートしようとする可能性のある複雑なスプレッドシート形式とデータ型をナビゲートできるように、ターゲットデータモデルを作成します。
- FlatfileのAIがすべてをマッピングする方法を正確に認識できるように、検証ルールを使用してテンプレートを作成します。
- インポートされたデータを他のデータベースに対して検証して、インポーターが時間の経過とともにデータをコンテキスト化、検証、およびクリーンアップできるようにします。
その前もっての作業を終えたら、残りは簡単です。
作業の大部分は、インポートされたデータをクリーンで便利なものに変換するときにFlatfileConciergeによって実行されます。 実際、Flatfileの機械学習とあいまいマッチングシステムのおかげで、インポートされた列の約95%が自動的にソフトウェアにマッピングされます。
エンドユーザーは、エラーを含むデータの部分を確認する機会があります。 見つかった場合は、スプレッドシートで修正して再インポートするのではなく、Flatfile内のエラーを修復できます。
課題3:複数のユーザーからのデータの取得と追跡
キッチンに料理人がたくさんいると、うまくいかないことがたくさんあります。
データはチームメンバーのコンピューターに保存されることもあり、さらに悪いことに、電子メールで送信されることもあります。これは、機密データのセキュリティ上の大きな懸念事項となる可能性があります。 これは、ユーザーがソフトウェアプラットフォームへのアクセスを許可されていない場合、またはデータインポーターが威圧的すぎて使用できない場合に発生する可能性があります。
逆に、データのオンボーディングプロセスが間違っていると、会社のデータに好きなものを追加する、誰でも自由に使えるようになる可能性があります。 データはインポートされますが、レビューフレームワークがないため、会社のデータベースはエラーや重複したエントリでいっぱいになります。
エンドユーザーは、会社のデータと同じくらい深刻なものを扱う場合、特にソフトウェアを使用可能にしたい場合は、順序、制御、およびセキュリティを維持できる必要があります。
修正
Flatfile Conciergeは、データのオンボーディングプロセスが共同作業になるように設計しました。
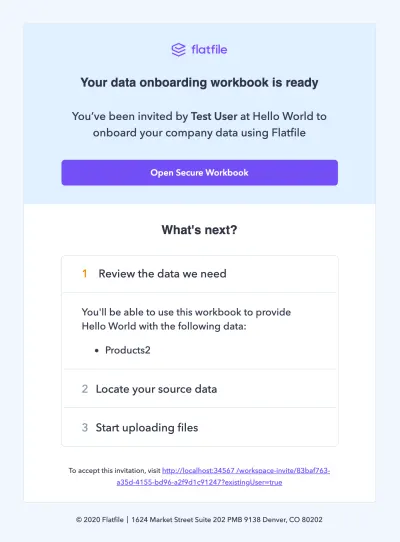
ご覧のとおり、会社の管理者は特定の共同作業者(つまり顧客)を招待して、ワークスペースにデータを追加できます。 しかし、これはデータをインポートするための包括的な招待ではありません。
管理者は、承認プロセスを作成することができます。 彼らは以下に到達します:
- チームメンバーに特定のデータセットを要求します。
- データのインポートを許可するワークスペースを制御します。
- 承認されたデータをプラットフォームに流す前に、すべてのデータ送信を確認してください。
管理者は、顧客に代わってデータをインポートすることもできます。 Flatfile Conciergeは、データのオンボーディングが顧客にとって行き詰まりにならないようにします。
これにより、適切なデータがソフトウェアに保存されるだけでなく、フローが制御されるため、データがよりクリーンで正確になります。 これらすべてが、ユーザーにシームレスなデータオンボーディングエクスペリエンスを提供します。
課題4:データセキュリティは常に懸念事項です
ウェブとアプリの開発に関しては、ユーザーのプライバシーとセキュリティが最優先事項です。 私たちの顧客と訪問者が彼らの情報が詮索好きな目から安全であると信じていない場合(そして広告主に売り払われていない場合)、彼らはそもそも私たちのソリューションの使用をやめるでしょう。
ソフトウェアでも同じことが起こります。ただし、企業の個人データだけでなく、セキュリティについても心配する必要があります。
多くの場合、企業がデータをソフトウェアにインポートする場合(CRMの例のように)、顧客の個人データや機密データをインポートします。 それが危険にさらされるのを許してください、そして、あなたはあなたのソフトウェアに別れを告げることができます。
したがって、はい、ソフトウェア自体を保護する必要があります。 それは当然のことです。 しかし、データのオンボーディングプロセスも同様です。 チェックを外したままにすると、脆弱性の大きなポイントになります。
修正
Flatfile Conciergeが最初に行うことは、ユーザーフレンドリーなデータオンボーディングソリューションを提供することにより、ユーザーが電子メール、FTP、およびその他のセキュリティで保護されていないプラットフォームを介した機密データの共有から離れるように促すことです。
次に、ユーザーがデータをインポート、検証、およびソフトウェアに投稿するための認証済みの準拠ワークスペースを提供します。
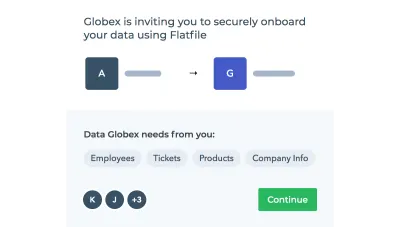
FlatfileConciergeがワークスペースを保護する方法は次のとおりです。
- 各共同編集者は、認証された招待状を介してデータインポーターに入ります。
- データは転送中に暗号化され、暗号化されたAmazonS3バケットに保存されます。
- データオンボーディングプラットフォームは、GDPRに100%準拠しています。
- FlatfileはHIPAAおよびSOC2に準拠しており、必要に応じて他のコンプライアンス要件に合わせて調整できます。
さらに、データがアプリケーションに正常に移行されると、フラットファイルから削除されます。 このように、あなたはあなたのソフトウェア内であなたのデータを保護することだけを心配する必要があり、それが触れられた以前のプラットフォームでは心配する必要はありません。
まとめ
データのオンボーディングプロセスが不十分またはエラーが発生しやすいため、ソフトウェアプロバイダーとそのエンドユーザーは、スプレッドシートの手動によるクリーニングと検証に多くの時間を費やすことになります。 これは、最初のユーザー登録時にも発生しません。 データインポーターがその任務を果たせない場合、既存の顧客からプラットフォームにデータをアップロードまたは転送する必要があるたびに、膨大な時間とリソースを無駄にすることになります。
もちろん、これはすべて、インポーターがユーザーデータをソフトウェアに取り込むことさえできることを前提としています。 (残念ながら、これはカスタムビルドのソリューションが多すぎる場合に発生します。)
言うまでもなく、データのオンボーディングプロセスは、チームと顧客にとって完璧でなければなりません。 これは、ユーザーの解約率を低く抑え、ユーザーの満足度を高く保つ唯一の方法です。
データのオンボーディングは、処理が非常に複雑なプロセスです。 独自のデータオンボーディングソリューションを開発しようとする手間と、それに関する問題のトラブルシューティングを試みる時間を節約できます。 Flatfile ConciergeのようなAIを利用したデータインポーターを使用すると、すべてが自動的に処理されます。